 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Explainability of the Implications of Supervised and Unsupervised Face Image Quality Estimations Through Activation Map Variation Analyses in Face Recognition Models
Dec 09, 2021
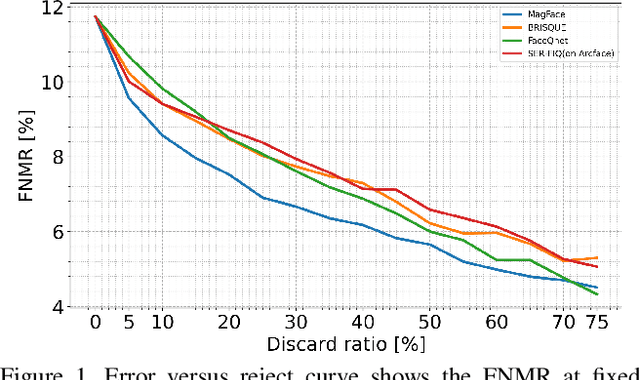
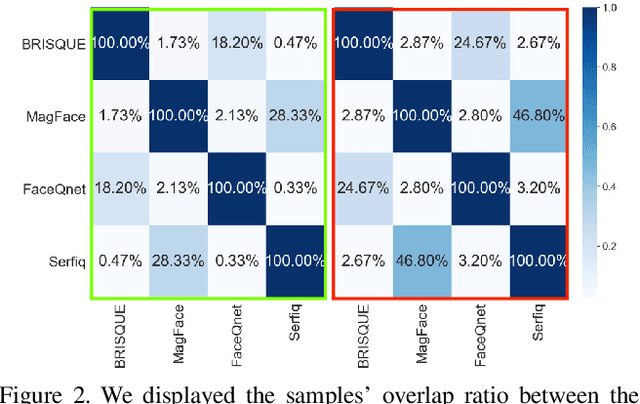
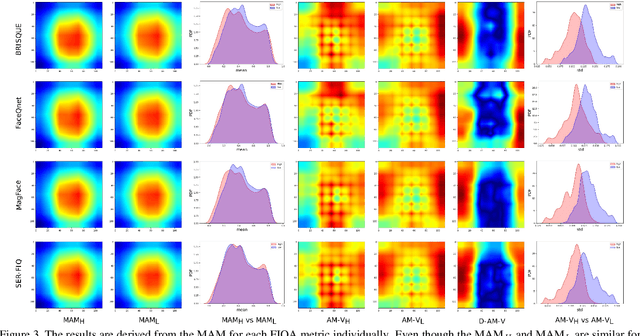
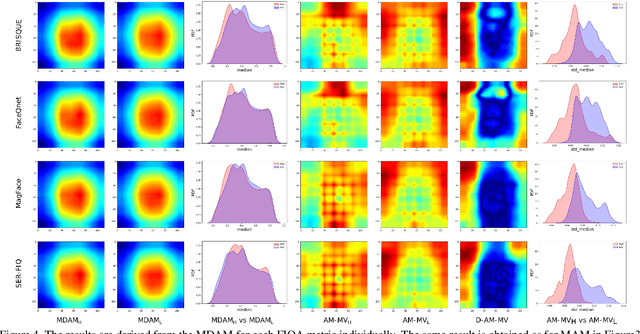
It is challenging to derive explainability for unsupervised or statistical-based face image quality assessment (FIQA) methods. In this work, we propose a novel set of explainability tools to derive reasoning for different FIQA decisions and their face recognition (FR) performance implications. We avoid limiting the deployment of our tools to certain FIQA methods by basing our analyses on the behavior of FR models when processing samples with different FIQA decisions. This leads to explainability tools that can be applied for any FIQA method with any CNN-based FR solution using activation mapping to exhibit the network's activation derived from the face embedding. To avoid the low discrimination between the general spatial activation mapping of low and high-quality images in FR models, we build our explainability tools in a higher derivative space by analyzing the variation of the FR activation maps of image sets with different quality decisions. We demonstrate our tools and analyze the findings on four FIQA methods, by presenting inter and intra-FIQA method analyses. Our proposed tools and the analyses based on them point out, among other conclusions, that high-quality images typically cause consistent low activation on the areas outside of the central face region, while low-quality images, despite general low activation, have high variations of activation in such areas. Our explainability tools also extend to analyzing single images where we show that low-quality images tend to have an FR model spatial activation that strongly differs from what is expected from a high-quality image where this difference also tends to appear more in areas outside of the central face region and does correspond to issues like extreme poses and facial occlusions. The implementation of the proposed tools is accessible here [link].
Multi-Fake Evolutionary Generative Adversarial Networks for Imbalance Hyperspectral Image Classification
Nov 07, 2021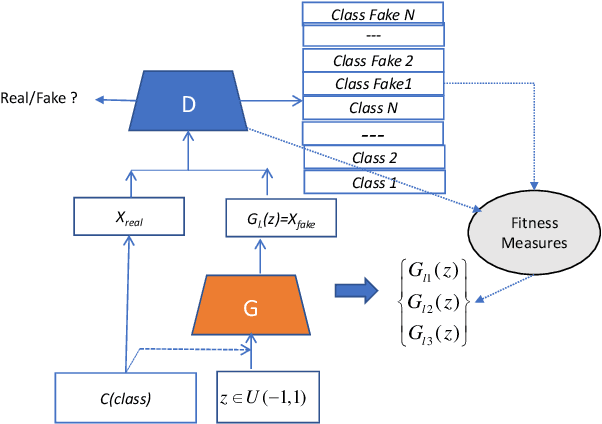
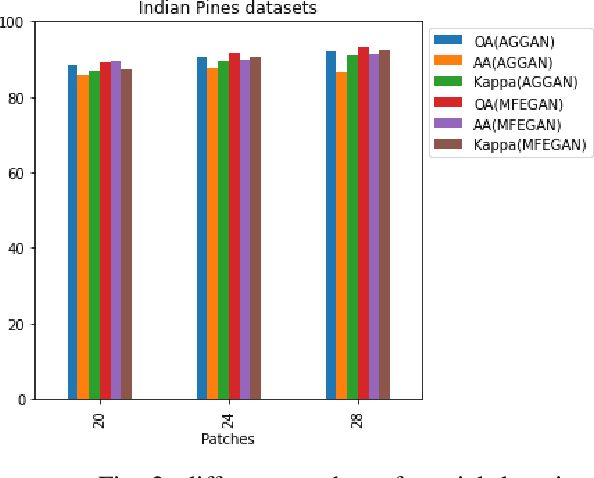
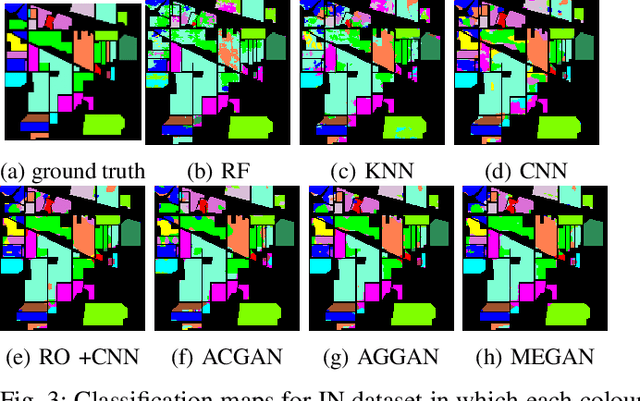
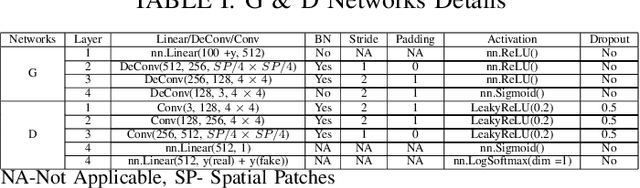
This paper presents a novel multi-fake evolutionary generative adversarial network(MFEGAN) for handling imbalance hyperspectral image classification. It is an end-to-end approach in which different generative objective losses are considered in the generator network to improve the classification performance of the discriminator network. Thus, the same discriminator network has been used as a standard classifier by embedding the classifier network on top of the discriminating function. The effectiveness of the proposed method has been validated through two hyperspectral spatial-spectral data sets. The same generative and discriminator architectures have been utilized with two different GAN objectives for a fair performance comparison with the proposed method. It is observed from the experimental validations that the proposed method outperforms the state-of-the-art methods with better classification performance.
Super-Resolution Image Reconstruction Based on Self-Calibrated Convolutional GAN
Jun 10, 2021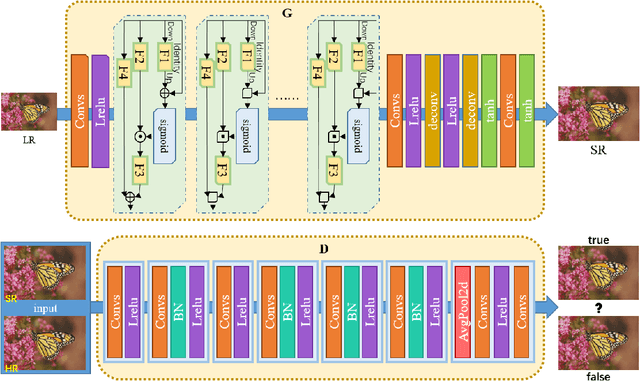
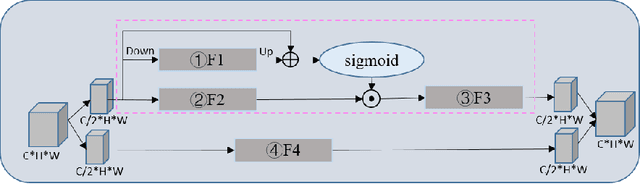

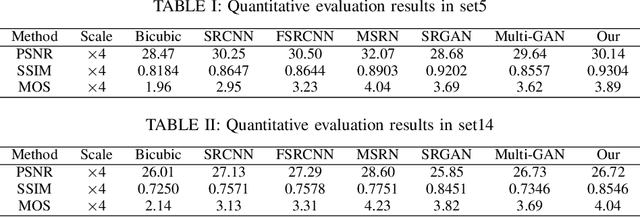
With the effective application of deep learning in computer vision, breakthroughs have been made in the research of super-resolution images reconstruction. However, many researches have pointed out that the insufficiency of the neural network extraction on image features may bring the deteriorating of newly reconstructed image. On the other hand, the generated pictures are sometimes too artificial because of over-smoothing. In order to solve the above problems, we propose a novel self-calibrated convolutional generative adversarial networks. The generator consists of feature extraction and image reconstruction. Feature extraction uses self-calibrated convolutions, which contains four portions, and each portion has specific functions. It can not only expand the range of receptive fields, but also obtain long-range spatial and inter-channel dependencies. Then image reconstruction is performed, and finally a super-resolution image is reconstructed. We have conducted thorough experiments on different datasets including set5, set14 and BSD100 under the SSIM evaluation method. The experimental results prove the effectiveness of the proposed network.
Self-Paced Contrastive Learning for Semi-supervised Medical Image Segmentation with Meta-labels
Aug 22, 2021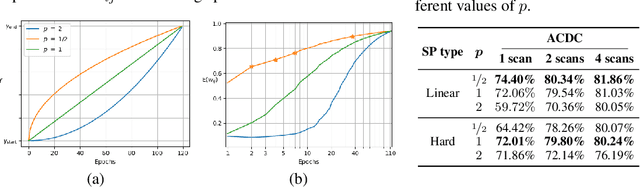
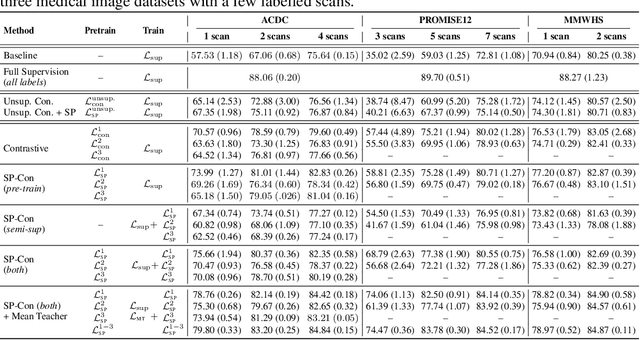
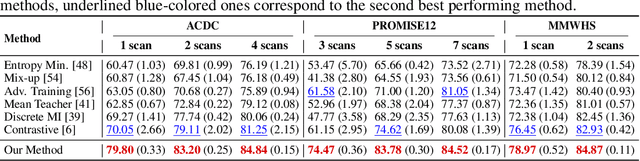
Pre-training a recognition model with contrastive learning on a large dataset of unlabeled data has shown great potential to boost the performance of a downstream task, e.g., image classification. However, in domains such as medical imaging, collecting unlabeled data can be challenging and expensive. In this work, we propose to adapt contrastive learning to work with meta-label annotations, for improving the model's performance in medical image segmentation even when no additional unlabeled data is available. Meta-labels such as the location of a 2D slice in a 3D MRI scan or the type of device used, often come for free during the acquisition process. We use the meta-labels for pre-training the image encoder as well as to regularize a semi-supervised training, in which a reduced set of annotated data is used for training. Finally, to fully exploit the weak annotations, a self-paced learning approach is used to help the learning and discriminate useful labels from noise. Results on three different medical image segmentation datasets show that our approach: i) highly boosts the performance of a model trained on a few scans, ii) outperforms previous contrastive and semi-supervised approaches, and iii) reaches close to the performance of a model trained on the full data.
Object-Aware Self-supervised Multi-Label Learning
May 14, 2022
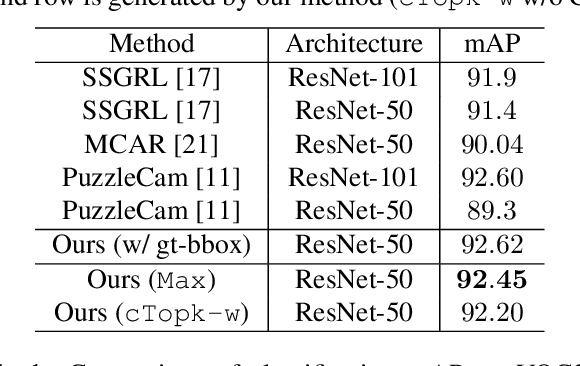
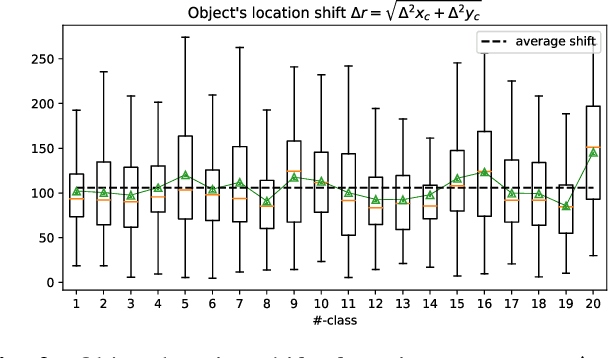

Multi-label Learning on Image data has been widely exploited with deep learning models. However, supervised training on deep CNN models often cannot discover sufficient discriminative features for classification. As a result, numerous self-supervision methods are proposed to learn more robust image representations. However, most self-supervised approaches focus on single-instance single-label data and fall short on more complex images with multiple objects. Therefore, we propose an Object-Aware Self-Supervision (OASS) method to obtain more fine-grained representations for multi-label learning, dynamically generating auxiliary tasks based on object locations. Secondly, the robust representation learned by OASS can be leveraged to efficiently generate Class-Specific Instances (CSI) in a proposal-free fashion to better guide multi-label supervision signal transfer to instances. Extensive experiments on the VOC2012 dataset for multi-label classification demonstrate the effectiveness of the proposed method against the state-of-the-art counterparts.
BRIMA: low-overhead BRowser-only IMage Annotation tool (Preprint)
Jul 13, 2021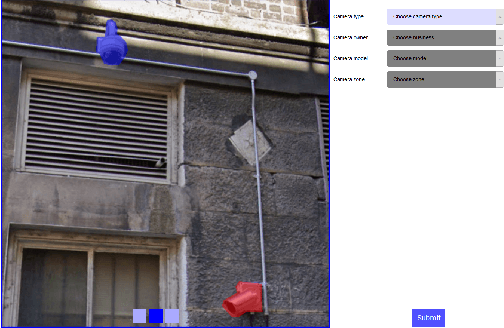

Image annotation and large annotated datasets are crucial parts within the Computer Vision and Artificial Intelligence fields.At the same time, it is well-known and acknowledged by the research community that the image annotation process is challenging, time-consuming and hard to scale. Therefore, the researchers and practitioners are always seeking ways to perform the annotations easier, faster, and at higher quality. Even though several widely used tools exist and the tools' landscape evolved considerably, most of the tools still require intricate technical setups and high levels of technical savviness from its operators and crowdsource contributors. In order to address such challenges, we develop and present BRIMA -- a flexible and open-source browser extension that allows BRowser-only IMage Annotation at considerably lower overheads. Once added to the browser, it instantly allows the user to annotate images easily and efficiently directly from the browser without any installation or setup on the client-side. It also features cross-browser and cross-platform functionality thus presenting itself as a neat tool for researchers within the Computer Vision, Artificial Intelligence, and privacy-related fields.
GCA-Net : Utilizing Gated Context Attention for Improving Image Forgery Localization and Detection
Dec 08, 2021


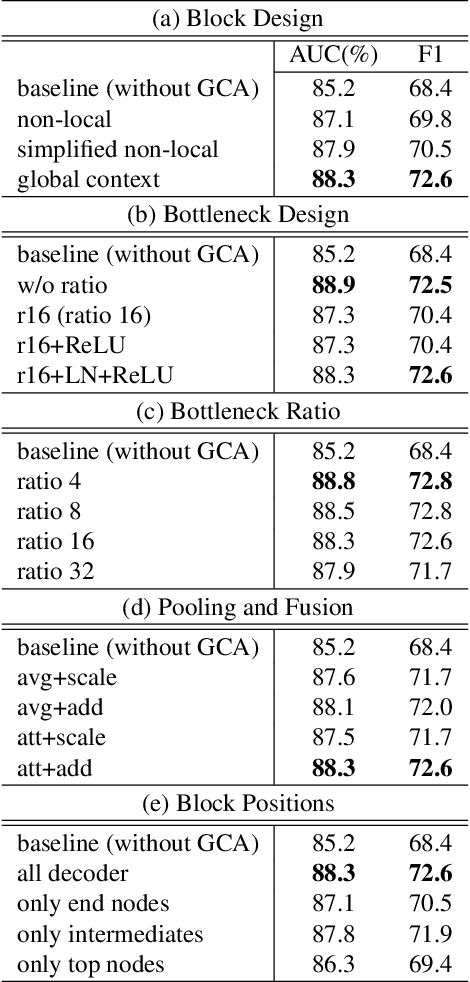
Forensic analysis depends on the identification of hidden traces from manipulated images. Traditional neural networks fail in this task because of their inability in handling feature attenuation and reliance on the dominant spatial features. In this work we propose a novel Gated Context Attention Network (GCA-Net) that utilizes the non-local attention block for global context learning. Additionally, we utilize a gated attention mechanism in conjunction with a dense decoder network to direct the flow of relevant features during the decoding phase, allowing for precise localization. The proposed attention framework allows the network to focus on relevant regions by filtering the coarse features. Furthermore, by utilizing multi-scale feature fusion and efficient learning strategies, GCA-Net can better handle the scale variation of manipulated regions. We show that our method outperforms state-of-the-art networks by an average of 4.2%-5.4% AUC on multiple benchmark datasets. Lastly, we also conduct extensive ablation experiments to demonstrate the method's robustness for image forensics.
Self-Annotated Training for Controllable Image Captioning
Oct 16, 2021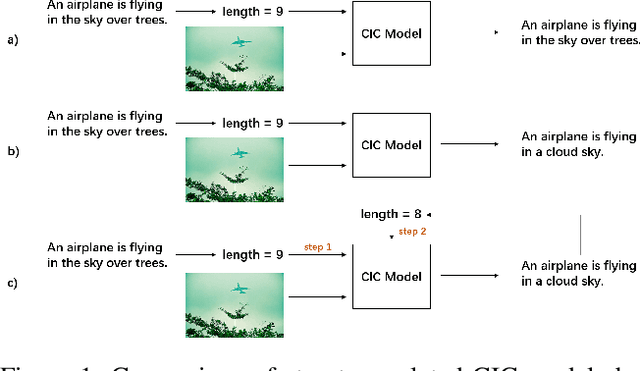
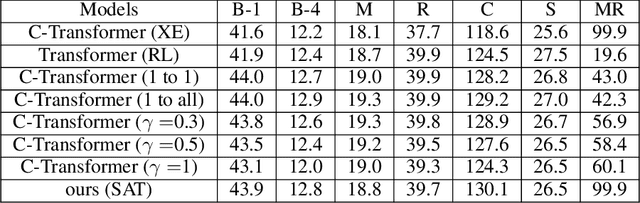
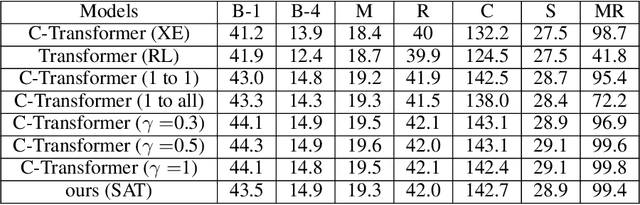
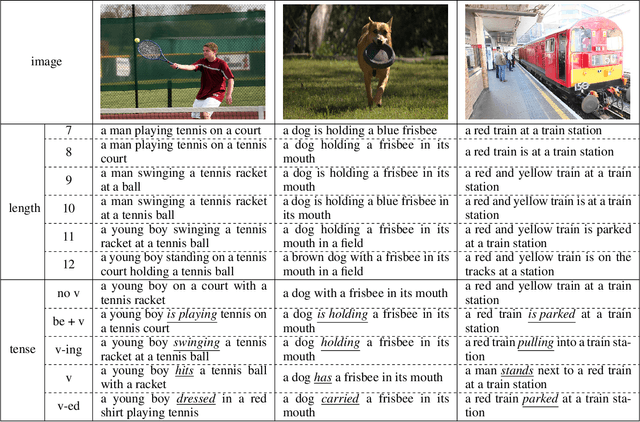
The Controllable Image Captioning (CIC) task aims to generate captions conditioned on designated control signals. In this paper, we improve CIC from two aspects: 1) Existing reinforcement training methods are not applicable to structure-related CIC models due to the fact that the accuracy-based reward focuses mainly on contents rather than semantic structures. The lack of reinforcement training prevents the model from generating more accurate and controllable sentences. To solve the problem above, we propose a novel reinforcement training method for structure-related CIC models: Self-Annotated Training (SAT), where a recursive sampling mechanism (RSM) is designed to force the input control signal to match the actual output sentence. Extensive experiments conducted on MSCOCO show that our SAT method improves C-Transformer (XE) on CIDEr-D score from 118.6 to 130.1 in the length-control task and from 132.2 to 142.7 in the tense-control task, while maintaining more than 99$\%$ matching accuracy with the control signal. 2) We introduce a new control signal: sentence quality. Equipped with it, CIC models are able to generate captions of different quality levels as needed. Experiments show that without additional information of ground truth captions, models controlled by the highest level of sentence quality perform much better in accuracy than baseline models.
Epicardial Adipose Tissue Segmentation from CT Images with A Semi-3D Neural Network
Apr 27, 2022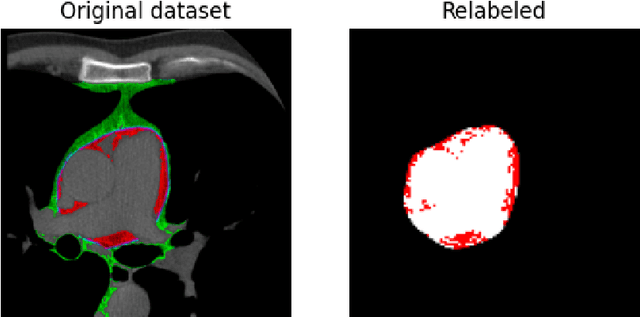


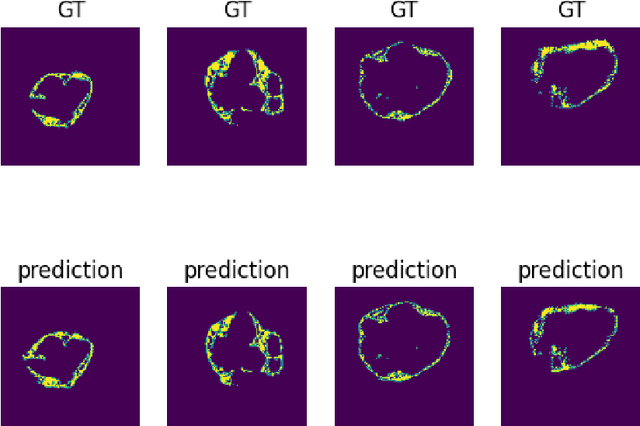
Epicardial adipose tissue is a type of adipose tissue located between the heart wall and a protective layer around the heart called the pericardium. The volume and thickness of epicardial adipose tissue are linked to various cardiovascular diseases. It is shown to be an independent cardiovascular disease risk factor. Fully automatic and reliable measurements of epicardial adipose tissue from CT scans could provide better disease risk assessment and enable the processing of large CT image data sets for a systemic epicardial adipose tissue study. This paper proposes a method for fully automatic semantic segmentation of epicardial adipose tissue from CT images using a deep neural network. The proposed network uses a U-Net-based architecture with slice depth information embedded in the input image to segment a pericardium region of interest, which is used to obtain an epicardial adipose tissue segmentation. Image augmentation is used to increase model robustness. Cross-validation of the proposed method yields a Dice score of 0.86 on the CT scans of 20 patients.
Pixel Distillation: A New Knowledge Distillation Scheme for Low-Resolution Image Recognition
Dec 17, 2021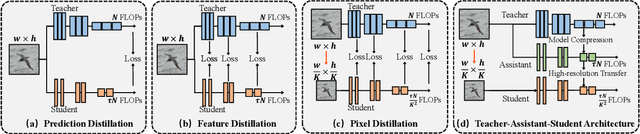
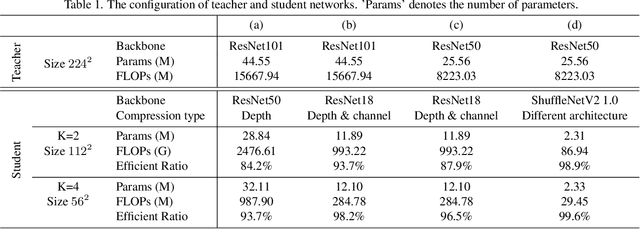
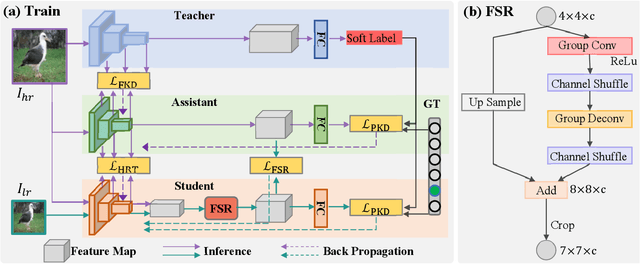
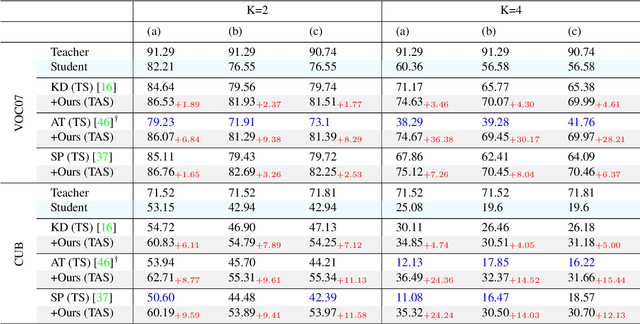
The great success of deep learning is mainly due to the large-scale network architecture and the high-quality training data. However, it is still challenging to deploy recent deep models on portable devices with limited memory and imaging ability. Some existing works have engaged to compress the model via knowledge distillation. Unfortunately, these methods cannot deal with images with reduced image quality, such as the low-resolution (LR) images. To this end, we make a pioneering effort to distill helpful knowledge from a heavy network model learned from high-resolution (HR) images to a compact network model that will handle LR images, thus advancing the current knowledge distillation technique with the novel pixel distillation. To achieve this goal, we propose a Teacher-Assistant-Student (TAS) framework, which disentangles knowledge distillation into the model compression stage and the high resolution representation transfer stage. By equipping a novel Feature Super Resolution (FSR) module, our approach can learn lightweight network model that can achieve similar accuracy as the heavy teacher model but with much fewer parameters, faster inference speed, and lower-resolution inputs. Comprehensive experiments on three widely-used benchmarks, \ie, CUB-200-2011, PASCAL VOC 2007, and ImageNetSub, demonstrate the effectiveness of our approach.