 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Evolving Image Compositions for Feature Representation Learning
Jun 16, 2021
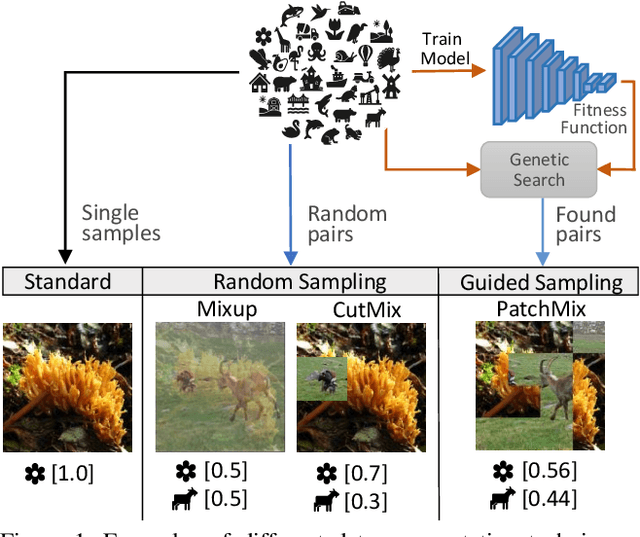
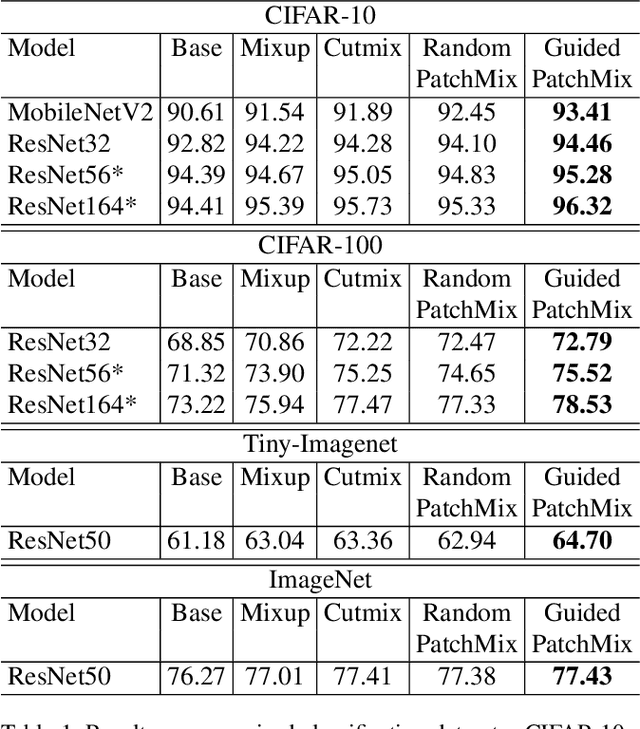
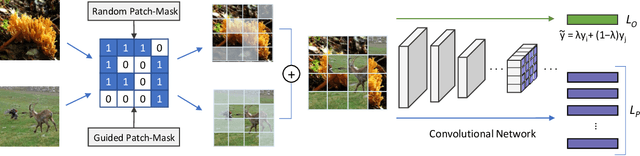
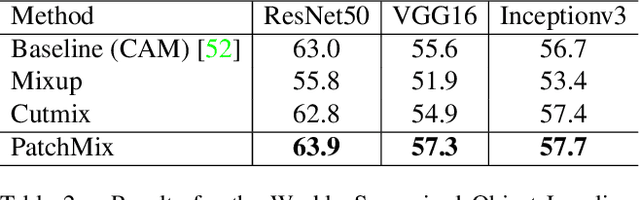
Convolutional neural networks for visual recognition require large amounts of training samples and usually benefit from data augmentation. This paper proposes PatchMix, a data augmentation method that creates new samples by composing patches from pairs of images in a grid-like pattern. These new samples' ground truth labels are set as proportional to the number of patches from each image. We then add a set of additional losses at the patch-level to regularize and to encourage good representations at both the patch and image levels. A ResNet-50 model trained on ImageNet using PatchMix exhibits superior transfer learning capabilities across a wide array of benchmarks. Although PatchMix can rely on random pairings and random grid-like patterns for mixing, we explore evolutionary search as a guiding strategy to discover optimal grid-like patterns and image pairing jointly. For this purpose, we conceive a fitness function that bypasses the need to re-train a model to evaluate each choice. In this way, PatchMix outperforms a base model on CIFAR-10 (+1.91), CIFAR-100 (+5.31), Tiny Imagenet (+3.52), and ImageNet (+1.16) by significant margins, also outperforming previous state-of-the-art pairwise augmentation strategies.
Collaborative Filtering-Based Method for Low-Resolution and Details Preserving Image Denoising
Jul 10, 2021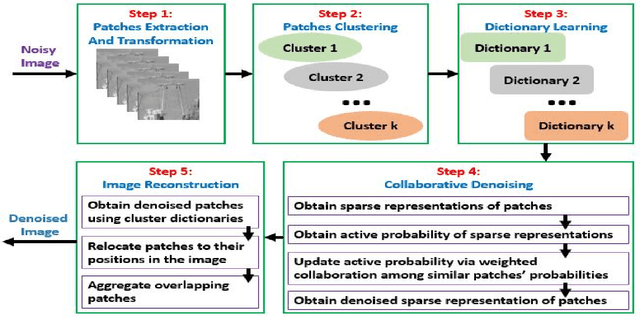
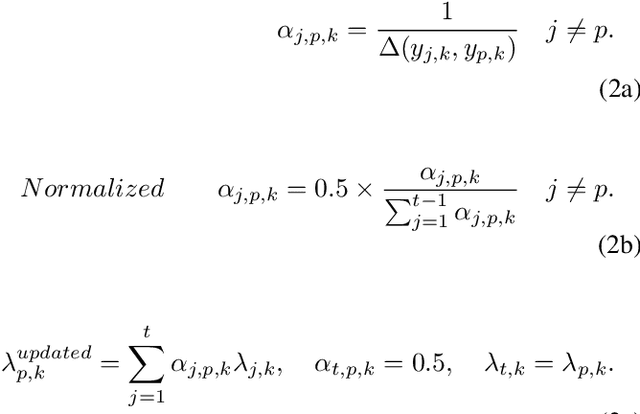
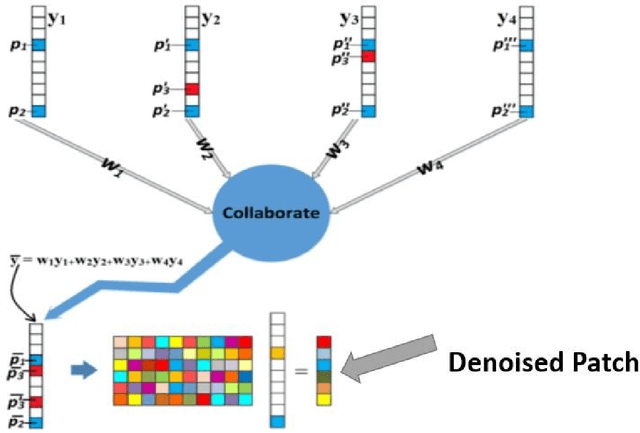
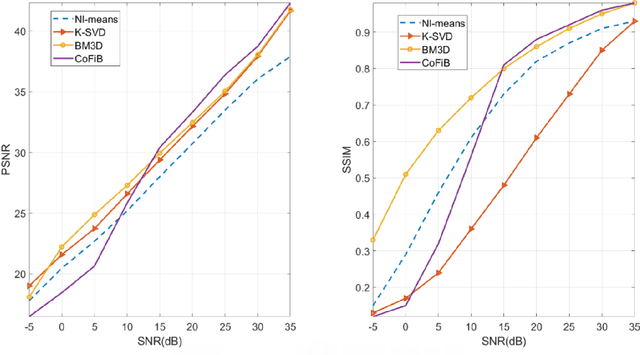
Over the years, progressive improvements in denoising performance have been achieved by several image denoising algorithms that have been proposed. Despite this, many of these state-of-the-art algorithms tend to smooth out the denoised image resulting in the loss of some image details after denoising. Many also distort images of lower resolution resulting in a partial or complete structural loss. In this paper, we address these shortcomings by proposing a collaborative filtering-based (CoFiB) denoising algorithm. Our proposed algorithm performs weighted sparse domain collaborative denoising by taking advantage of the fact that similar patches tend to have similar sparse representations in the sparse domain. This gives our algorithm the intelligence to strike a balance between image detail preservation and noise removal. Our extensive experiments showed that our proposed CoFiB algorithm does not only preserve the image details but also perform excellently for images of any given resolution where many denoising algorithms tend to struggle, specifically at low resolutions.
AdaFace: Quality Adaptive Margin for Face Recognition
Apr 03, 2022
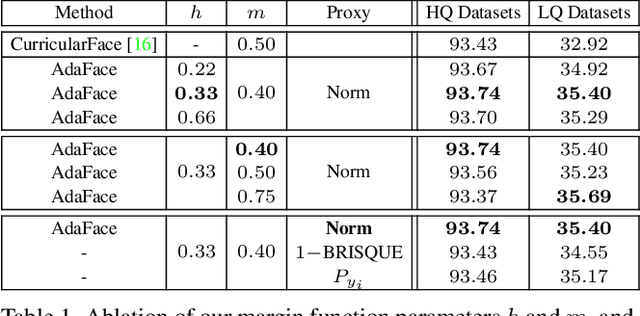


Recognition in low quality face datasets is challenging because facial attributes are obscured and degraded. Advances in margin-based loss functions have resulted in enhanced discriminability of faces in the embedding space. Further, previous studies have studied the effect of adaptive losses to assign more importance to misclassified (hard) examples. In this work, we introduce another aspect of adaptiveness in the loss function, namely the image quality. We argue that the strategy to emphasize misclassified samples should be adjusted according to their image quality. Specifically, the relative importance of easy or hard samples should be based on the sample's image quality. We propose a new loss function that emphasizes samples of different difficulties based on their image quality. Our method achieves this in the form of an adaptive margin function by approximating the image quality with feature norms. Extensive experiments show that our method, AdaFace, improves the face recognition performance over the state-of-the-art (SoTA) on four datasets (IJB-B, IJB-C, IJB-S and TinyFace). Code and models are released in https://github.com/mk-minchul/AdaFace.
Multi-scale Network with Attentional Multi-resolution Fusion for Point Cloud Semantic Segmentation
Jun 27, 2022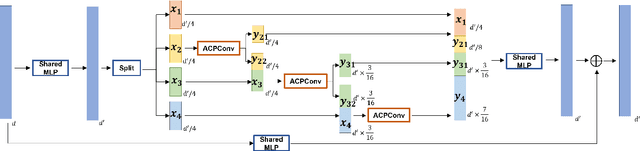
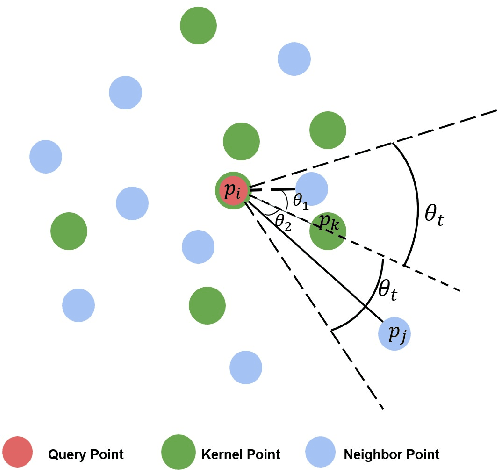
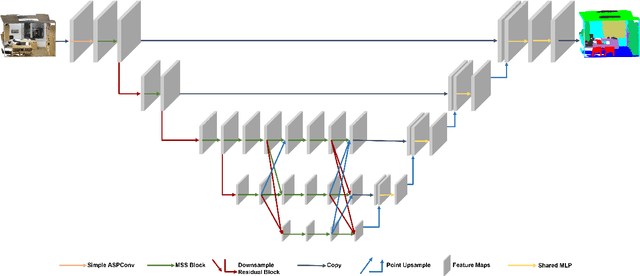
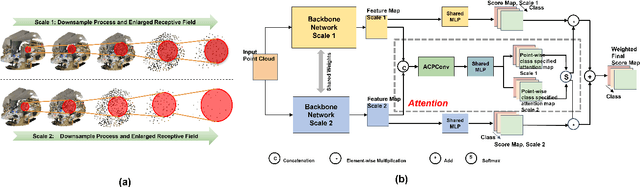
In this paper, we present a comprehensive point cloud semantic segmentation network that aggregates both local and global multi-scale information. First, we propose an Angle Correlation Point Convolution (ACPConv) module to effectively learn the local shapes of points. Second, based upon ACPConv, we introduce a local multi-scale split (MSS) block that hierarchically connects features within one single block and gradually enlarges the receptive field which is beneficial for exploiting the local context. Third, inspired by HRNet which has excellent performance on 2D image vision tasks, we build an HRNet customized for point cloud to learn global multi-scale context. Lastly, we introduce a point-wise attention fusion approach that fuses multi-resolution predictions and further improves point cloud semantic segmentation performance. Our experimental results and ablations on several benchmark datasets show that our proposed method is effective and able to achieve state-of-the-art performances compared to existing methods.
Mixed Supervision Learning for Whole Slide Image Classification
Jul 05, 2021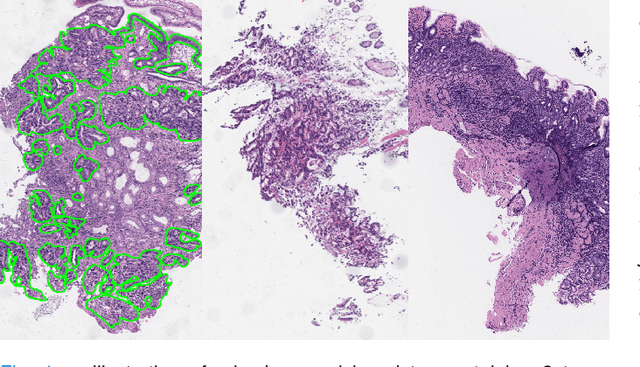
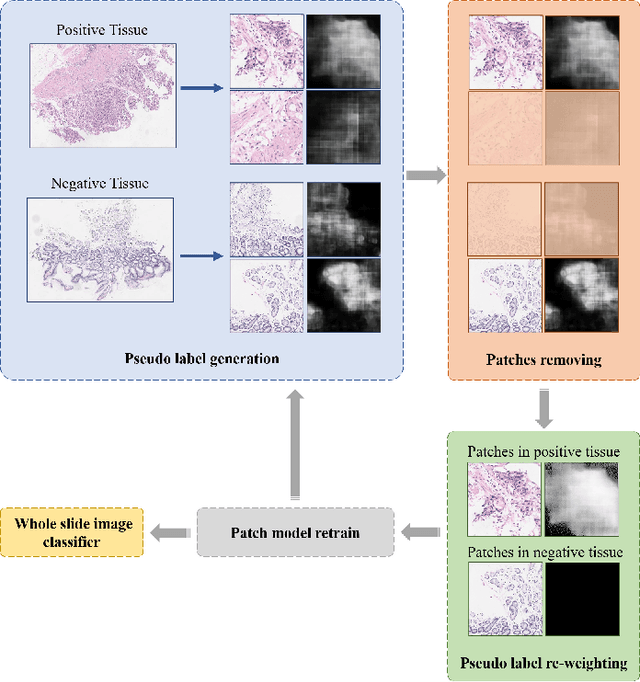
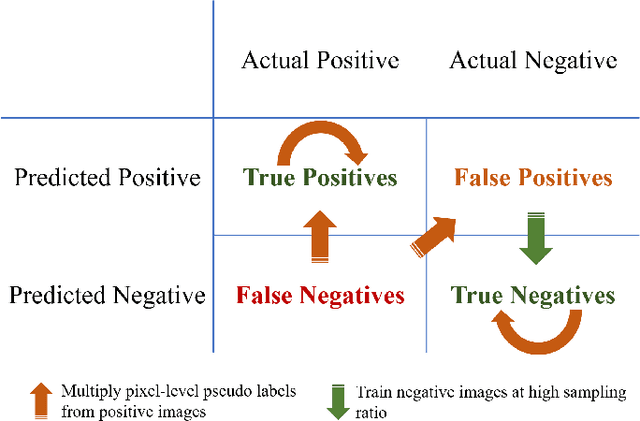
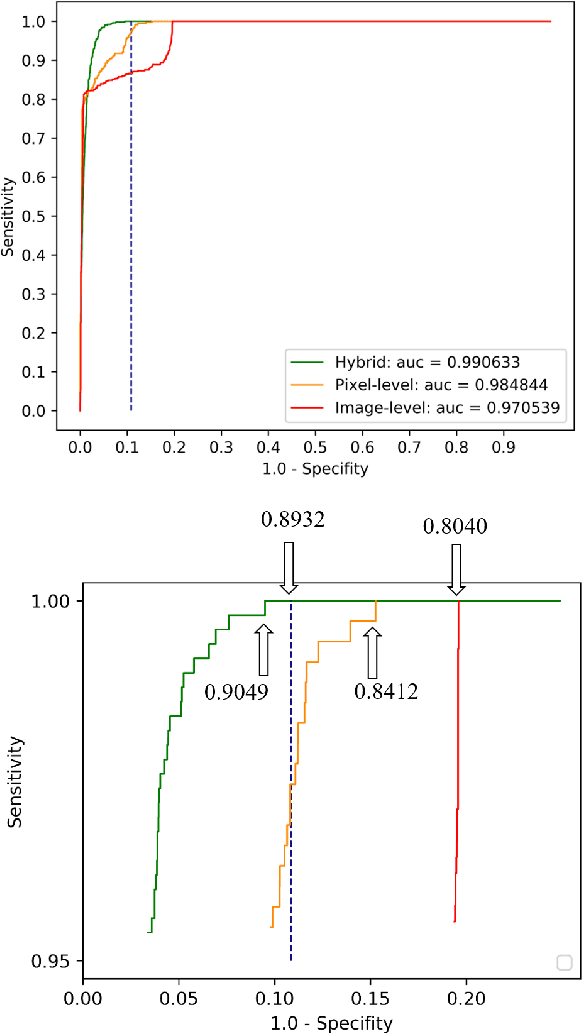
Weak supervision learning on classification labels has demonstrated high performance in various tasks. When a few pixel-level fine annotations are also affordable, it is natural to leverage both of the pixel-level (e.g., segmentation) and image level (e.g., classification) annotation to further improve the performance. In computational pathology, however, such weak or mixed supervision learning is still a challenging task, since the high resolution of whole slide images makes it unattainable to perform end-to-end training of classification models. An alternative approach is to analyze such data by patch-base model training, i.e., using self-supervised learning to generate pixel-level pseudo labels for patches. However, such methods usually have model drifting issues, i.e., hard to converge, because the noise accumulates during the self-training process. To handle those problems, we propose a mixed supervision learning framework for super high-resolution images to effectively utilize their various labels (e.g., sufficient image-level coarse annotations and a few pixel-level fine labels). During the patch training stage, this framework can make use of coarse image-level labels to refine self-supervised learning and generate high-quality pixel-level pseudo labels. A comprehensive strategy is proposed to suppress pixel-level false positives and false negatives. Three real-world datasets with very large number of images (i.e., more than 10,000 whole slide images) and various types of labels are used to evaluate the effectiveness of mixed supervision learning. We reduced the false positive rate by around one third compared to state of the art while retaining 100% sensitivity, in the task of image-level classification.
HIFI-Net: A Novel Network for Enhancement to Underwater Images
Jun 06, 2022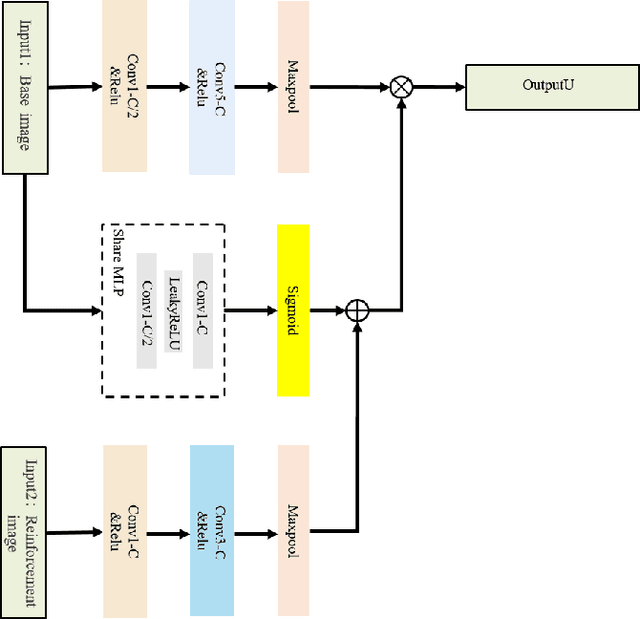
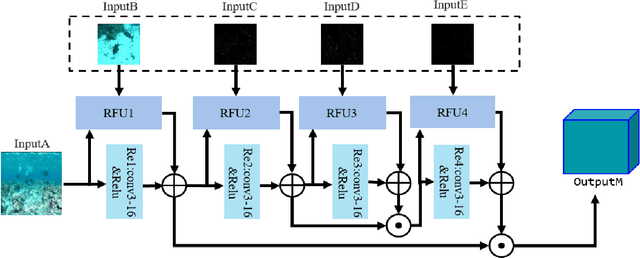
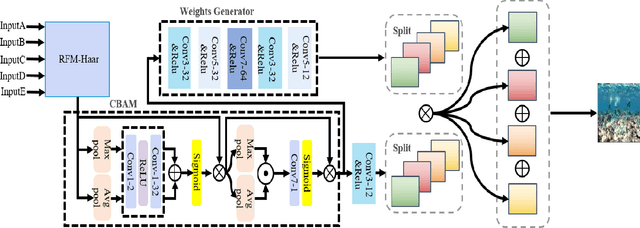

A novel network for enhancement to underwater images is proposed in this paper. It contains a Reinforcement Fusion Module for Haar wavelet images (RFM-Haar) based on Reinforcement Fusion Unit (RFU), which is used to fuse an original image and some important information within it. Fusion is achieved for better enhancement. As this network make "Haar Images into Fusion Images", it is called HIFI-Net. The experimental results show the proposed HIFI-Net performs best among many state-of-the-art methods on three datasets at three normal metrics and a new metric.
Hybrid Spatial-Temporal Entropy Modelling for Neural Video Compression
Jul 13, 2022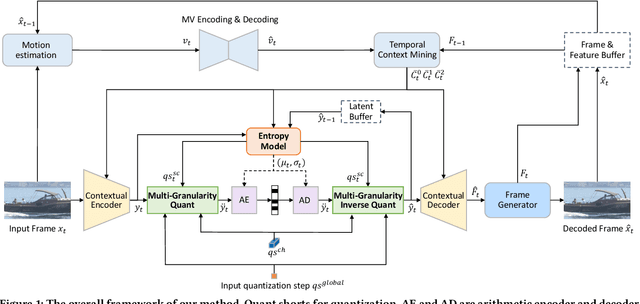
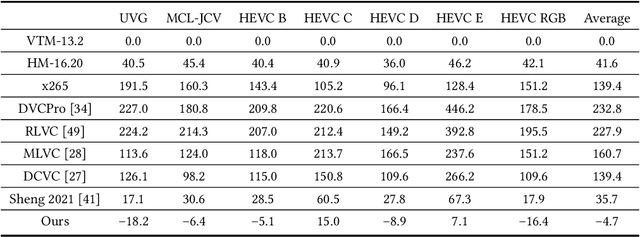
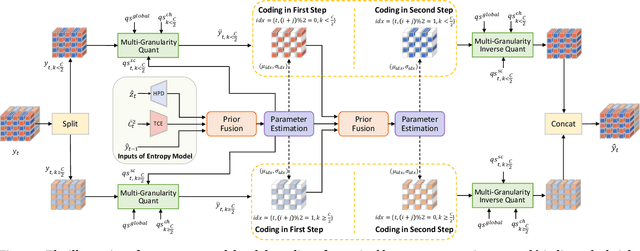
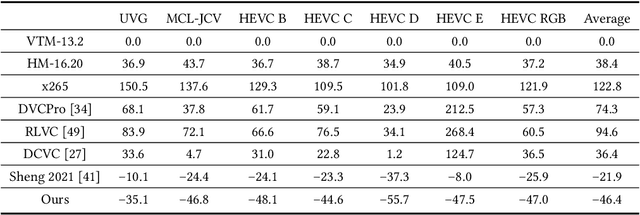
For neural video codec, it is critical, yet challenging, to design an efficient entropy model which can accurately predict the probability distribution of the quantized latent representation. However, most existing video codecs directly use the ready-made entropy model from image codec to encode the residual or motion, and do not fully leverage the spatial-temporal characteristics in video. To this end, this paper proposes a powerful entropy model which efficiently captures both spatial and temporal dependencies. In particular, we introduce the latent prior which exploits the correlation among the latent representation to squeeze the temporal redundancy. Meanwhile, the dual spatial prior is proposed to reduce the spatial redundancy in a parallel-friendly manner. In addition, our entropy model is also versatile. Besides estimating the probability distribution, our entropy model also generates the quantization step at spatial-channel-wise. This content-adaptive quantization mechanism not only helps our codec achieve the smooth rate adjustment in single model but also improves the final rate-distortion performance by dynamic bit allocation. Experimental results show that, powered by the proposed entropy model, our neural codec can achieve 18.2% bitrate saving on UVG dataset when compared with H.266 (VTM) using the highest compression ratio configuration. It makes a new milestone in the development of neural video codec. The codes are at https://github.com/microsoft/DCVC.
Preservational Learning Improves Self-supervised Medical Image Models by Reconstructing Diverse Contexts
Sep 09, 2021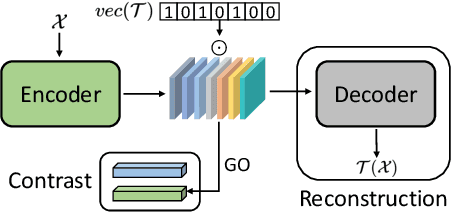
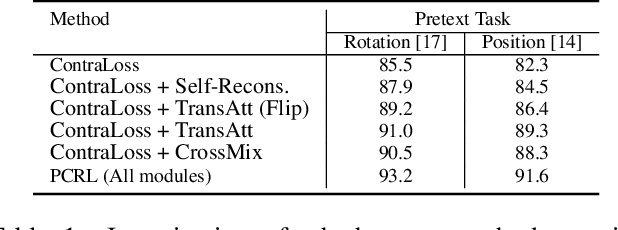
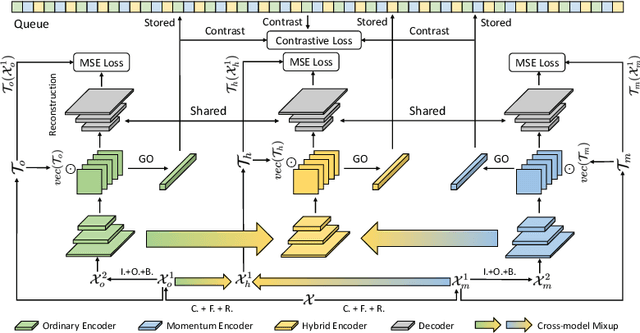
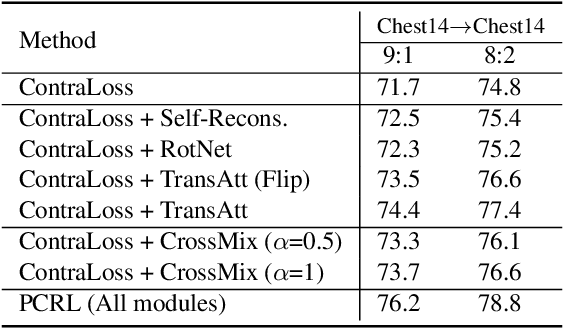
Preserving maximal information is one of principles of designing self-supervised learning methodologies. To reach this goal, contrastive learning adopts an implicit way which is contrasting image pairs. However, we believe it is not fully optimal to simply use the contrastive estimation for preservation. Moreover, it is necessary and complemental to introduce an explicit solution to preserve more information. From this perspective, we introduce Preservational Learning to reconstruct diverse image contexts in order to preserve more information in learned representations. Together with the contrastive loss, we present Preservational Contrastive Representation Learning (PCRL) for learning self-supervised medical representations. PCRL provides very competitive results under the pretraining-finetuning protocol, outperforming both self-supervised and supervised counterparts in 5 classification/segmentation tasks substantially.
SNeRF: Stylized Neural Implicit Representations for 3D Scenes
Jul 05, 2022
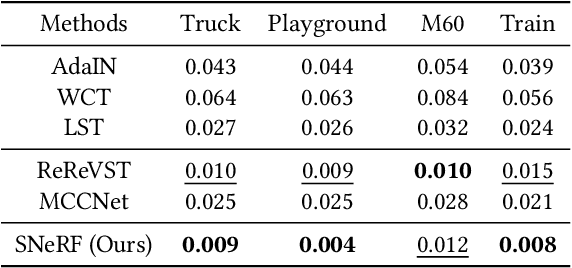
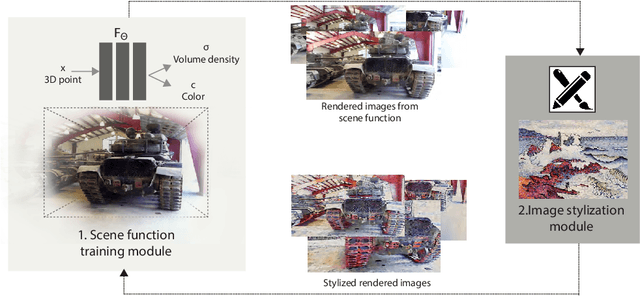
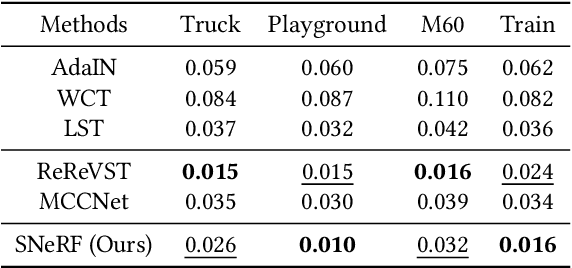
This paper presents a stylized novel view synthesis method. Applying state-of-the-art stylization methods to novel views frame by frame often causes jittering artifacts due to the lack of cross-view consistency. Therefore, this paper investigates 3D scene stylization that provides a strong inductive bias for consistent novel view synthesis. Specifically, we adopt the emerging neural radiance fields (NeRF) as our choice of 3D scene representation for their capability to render high-quality novel views for a variety of scenes. However, as rendering a novel view from a NeRF requires a large number of samples, training a stylized NeRF requires a large amount of GPU memory that goes beyond an off-the-shelf GPU capacity. We introduce a new training method to address this problem by alternating the NeRF and stylization optimization steps. Such a method enables us to make full use of our hardware memory capacity to both generate images at higher resolution and adopt more expressive image style transfer methods. Our experiments show that our method produces stylized NeRFs for a wide range of content, including indoor, outdoor and dynamic scenes, and synthesizes high-quality novel views with cross-view consistency.
SurfaceNet: Adversarial SVBRDF Estimation from a Single Image
Jul 23, 2021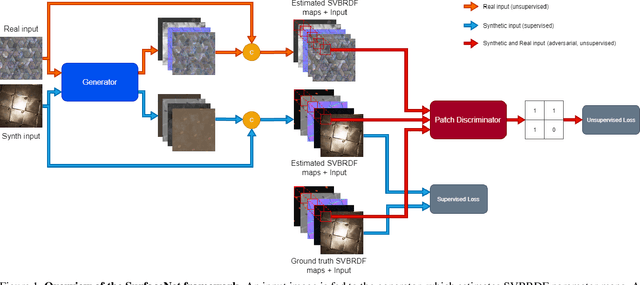
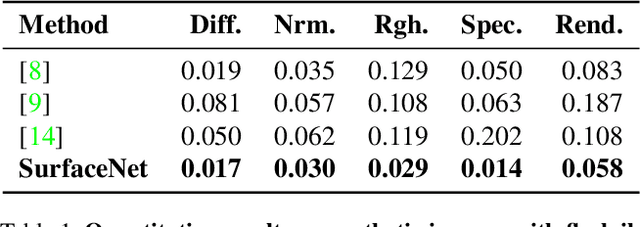
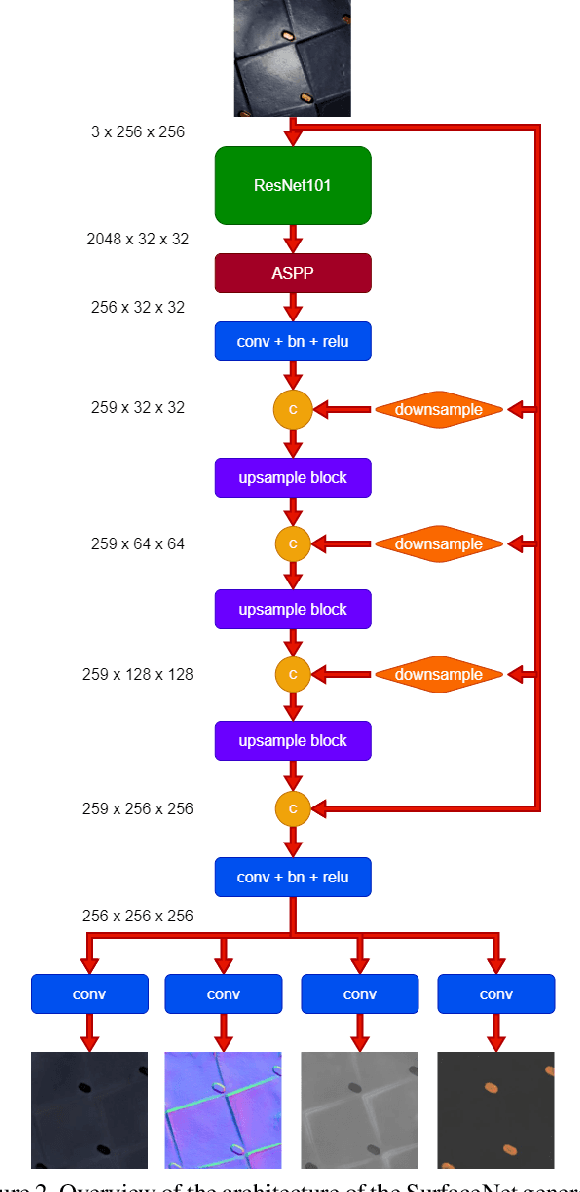
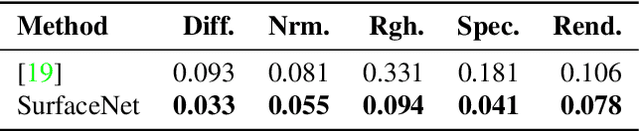
In this paper we present SurfaceNet, an approach for estimating spatially-varying bidirectional reflectance distribution function (SVBRDF) material properties from a single image. We pose the problem as an image translation task and propose a novel patch-based generative adversarial network (GAN) that is able to produce high-quality, high-resolution surface reflectance maps. The employment of the GAN paradigm has a twofold objective: 1) allowing the model to recover finer details than standard translation models; 2) reducing the domain shift between synthetic and real data distributions in an unsupervised way. An extensive evaluation, carried out on a public benchmark of synthetic and real images under different illumination conditions, shows that SurfaceNet largely outperforms existing SVBRDF reconstruction methods, both quantitatively and qualitatively. Furthermore, SurfaceNet exhibits a remarkable ability in generating high-quality maps from real samples without any supervision at training time.