 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Autonomous Satellite Detection and Tracking using Optical Flow
Apr 14, 2022

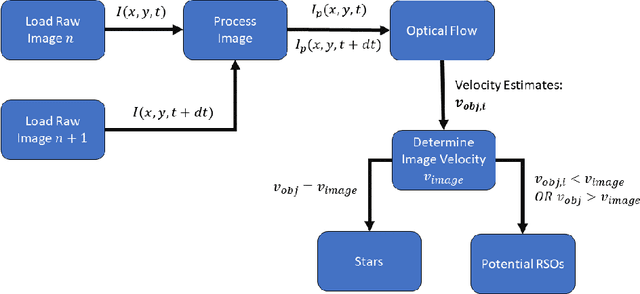

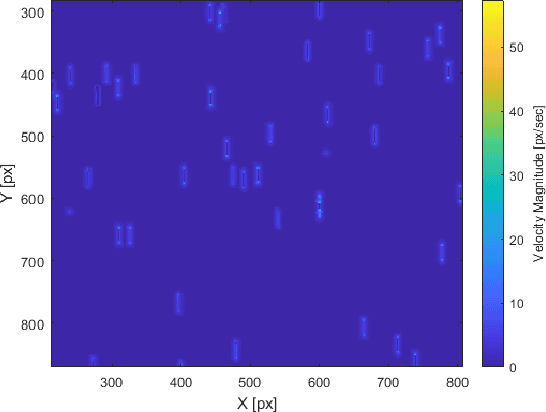
In this paper, an autonomous method of satellite detection and tracking in images is implemented using optical flow. Optical flow is used to estimate the image velocities of detected objects in a series of space images. Given that most objects in an image will be stars, the overall image velocity from star motion is used to estimate the image's frame-to-frame motion. Objects seen to be moving with velocity profiles distinct from the overall image velocity are then classified as potential resident space objects. The detection algorithm is exercised using both simulated star images and ground-based imagery of satellites. Finally, this algorithm will be tested and compared using a commercial and an open-source software approach to provide the reader with two different options based on their need.
SGEITL: Scene Graph Enhanced Image-Text Learning for Visual Commonsense Reasoning
Dec 16, 2021

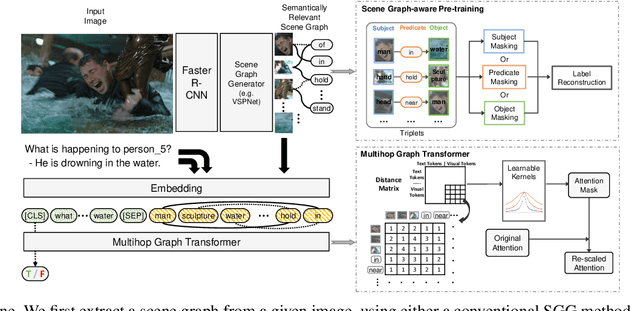

Answering complex questions about images is an ambitious goal for machine intelligence, which requires a joint understanding of images, text, and commonsense knowledge, as well as a strong reasoning ability. Recently, multimodal Transformers have made great progress in the task of Visual Commonsense Reasoning (VCR), by jointly understanding visual objects and text tokens through layers of cross-modality attention. However, these approaches do not utilize the rich structure of the scene and the interactions between objects which are essential in answering complex commonsense questions. We propose a Scene Graph Enhanced Image-Text Learning (SGEITL) framework to incorporate visual scene graphs in commonsense reasoning. To exploit the scene graph structure, at the model structure level, we propose a multihop graph transformer for regularizing attention interaction among hops. As for pre-training, a scene-graph-aware pre-training method is proposed to leverage structure knowledge extracted in the visual scene graph. Moreover, we introduce a method to train and generate domain-relevant visual scene graphs using textual annotations in a weakly-supervised manner. Extensive experiments on VCR and other tasks show a significant performance boost compared with the state-of-the-art methods and prove the efficacy of each proposed component.
* AAAI 2022
Domain Adaptive Person Search
Jul 25, 2022
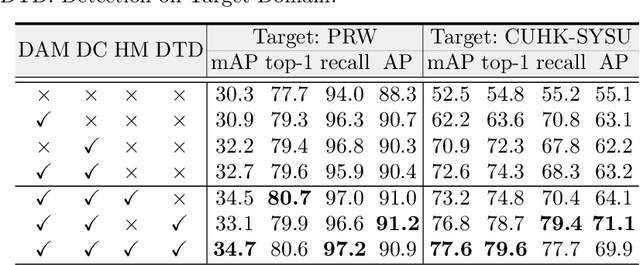
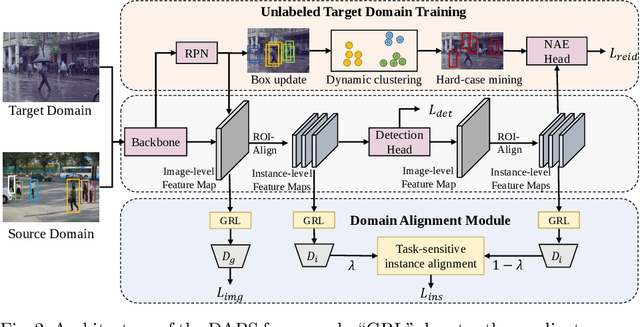

Person search is a challenging task which aims to achieve joint pedestrian detection and person re-identification (ReID). Previous works have made significant advances under fully and weakly supervised settings. However, existing methods ignore the generalization ability of the person search models. In this paper, we take a further step and present Domain Adaptive Person Search (DAPS), which aims to generalize the model from a labeled source domain to the unlabeled target domain. Two major challenges arises under this new setting: one is how to simultaneously solve the domain misalignment issue for both detection and Re-ID tasks, and the other is how to train the ReID subtask without reliable detection results on the target domain. To address these challenges, we propose a strong baseline framework with two dedicated designs. 1) We design a domain alignment module including image-level and task-sensitive instance-level alignments, to minimize the domain discrepancy. 2) We take full advantage of the unlabeled data with a dynamic clustering strategy, and employ pseudo bounding boxes to support ReID and detection training on the target domain. With the above designs, our framework achieves 34.7% in mAP and 80.6% in top-1 on PRW dataset, surpassing the direct transferring baseline by a large margin. Surprisingly, the performance of our unsupervised DAPS model even surpasses some of the fully and weakly supervised methods. The code is available at https://github.com/caposerenity/DAPS.
Towards Zero-shot Cross-lingual Image Retrieval and Tagging
Sep 15, 2021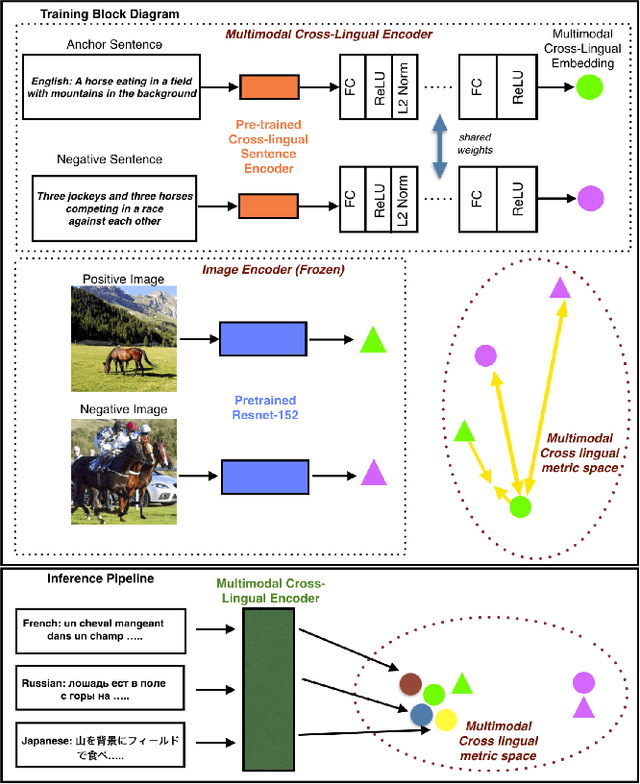
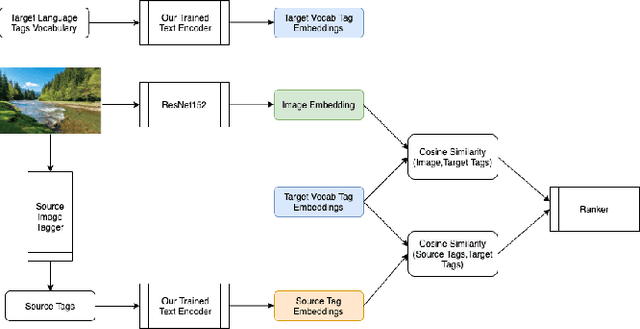

There has been a recent spike in interest in multi-modal Language and Vision problems. On the language side, most of these models primarily focus on English since most multi-modal datasets are monolingual. We try to bridge this gap with a zero-shot approach for learning multi-modal representations using cross-lingual pre-training on the text side. We present a simple yet practical approach for building a cross-lingual image retrieval model which trains on a monolingual training dataset but can be used in a zero-shot cross-lingual fashion during inference. We also introduce a new objective function which tightens the text embedding clusters by pushing dissimilar texts away from each other. For evaluation, we introduce a new 1K multi-lingual MSCOCO2014 caption test dataset (XTD10) in 7 languages that we collected using a crowdsourcing platform. We use this as the test set for zero-shot model performance across languages. We also demonstrate how a cross-lingual model can be used for downstream tasks like multi-lingual image tagging in a zero shot manner. XTD10 dataset is made publicly available here: https://github.com/adobe-research/Cross-lingual-Test-Dataset-XTD10.
DeFlowSLAM: Self-Supervised Scene Motion Decomposition for Dynamic Dense SLAM
Jul 18, 2022

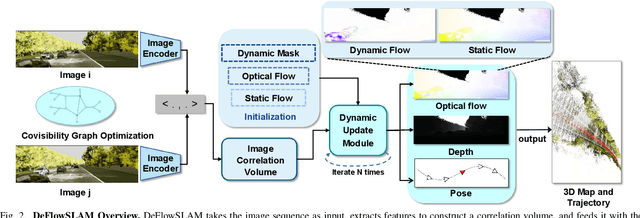
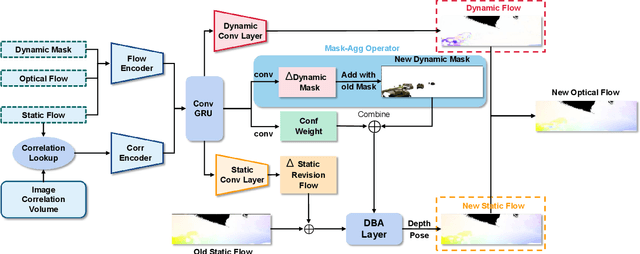
We present a novel dual-flow representation of scene motion that decomposes the optical flow into a static flow field caused by the camera motion and another dynamic flow field caused by the objects' movements in the scene. Based on this representation, we present a dynamic SLAM, dubbed DeFlowSLAM, that exploits both static and dynamic pixels in the images to solve the camera poses, rather than simply using static background pixels as other dynamic SLAM systems do. We propose a dynamic update module to train our DeFlowSLAM in a self-supervised manner, where a dense bundle adjustment layer takes in estimated static flow fields and the weights controlled by the dynamic mask and outputs the residual of the optimized static flow fields, camera poses, and inverse depths. The static and dynamic flow fields are estimated by warping the current image to the neighboring images, and the optical flow can be obtained by summing the two fields. Extensive experiments demonstrate that DeFlowSLAM generalizes well to both static and dynamic scenes as it exhibits comparable performance to the state-of-the-art DROID-SLAM in static and less dynamic scenes while significantly outperforming DROID-SLAM in highly dynamic environments. Code and data are available on the project webpage: \urlstyle{tt} \textcolor{url_color}{\url{https://zju3dv.github.io/deflowslam/}}.
Split Localized Conformal Prediction
Jun 27, 2022
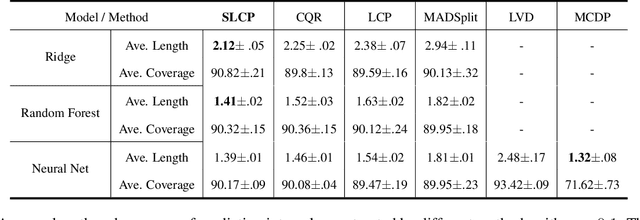
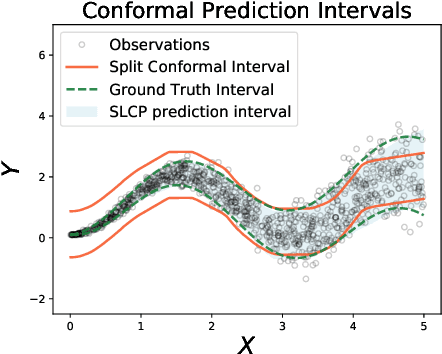

Conformal prediction is a simple and powerful tool that can quantify uncertainty without any distributional assumptions. However, existing methods can only provide an average coverage guarantee, which is not ideal compared to the stronger conditional coverage guarantee. Although achieving exact conditional coverage is proven to be impossible, approximating conditional coverage is still an important research direction. In this paper, we propose a modified non-conformity score by leveraging local approximation of the conditional distribution. The modified score inherits the spirit of split conformal methods, which is simple and efficient compared with full conformal methods but better approximates conditional coverage guarantee. Empirical results on various datasets, including a high dimension age regression on image, demonstrate that our method provides tighter intervals compared to existing methods.
CVNets: High Performance Library for Computer Vision
Jun 04, 2022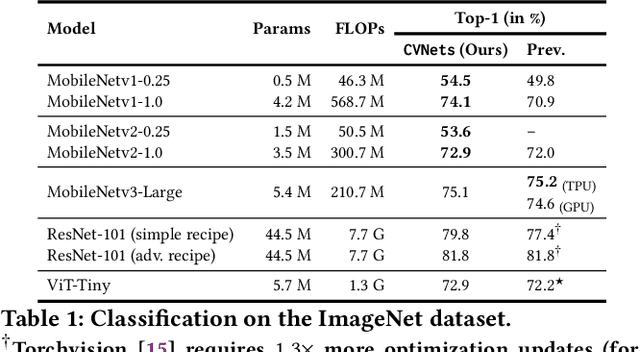
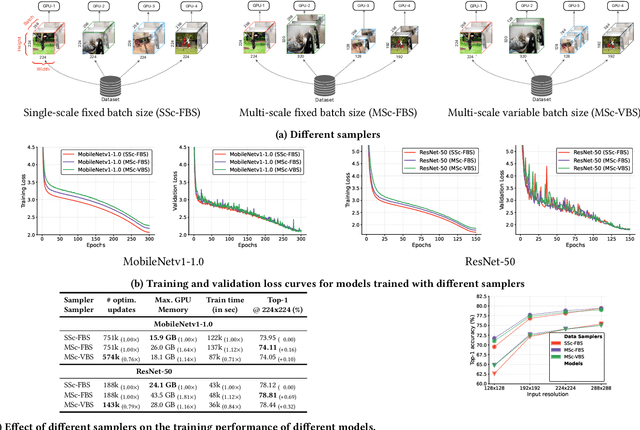
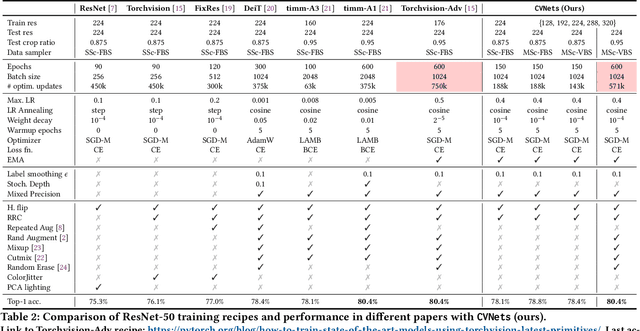
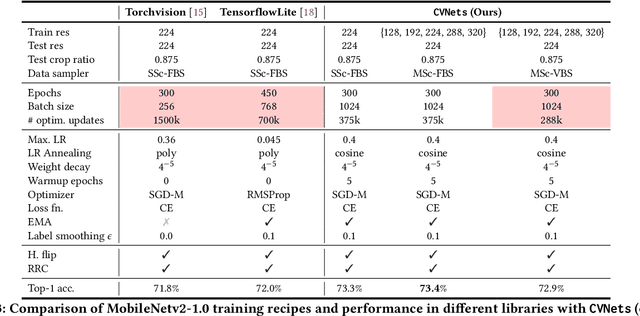
We introduce CVNets, a high-performance open-source library for training deep neural networks for visual recognition tasks, including classification, detection, and segmentation. CVNets supports image and video understanding tools, including data loading, data transformations, novel data sampling methods, and implementations of several standard networks with similar or better performance than previous studies. Our source code is available at: \url{https://github.com/apple/ml-cvnets}.
Transformers Improve Breast Cancer Diagnosis from Unregistered Multi-View Mammograms
Jun 21, 2022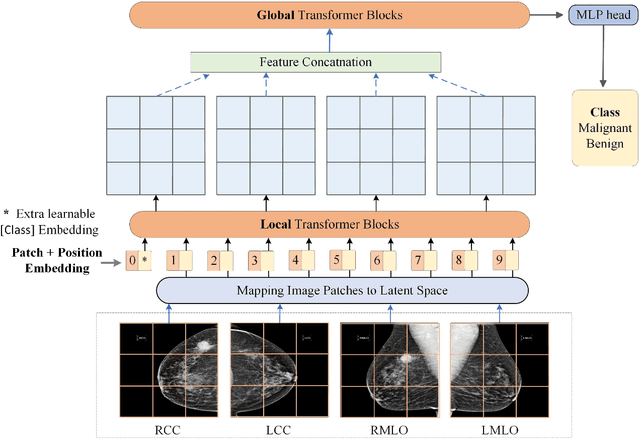
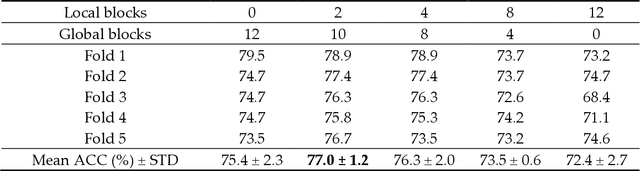
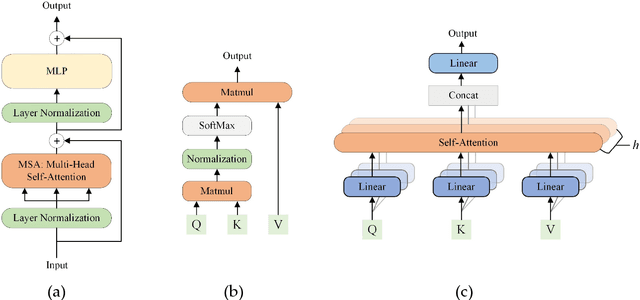
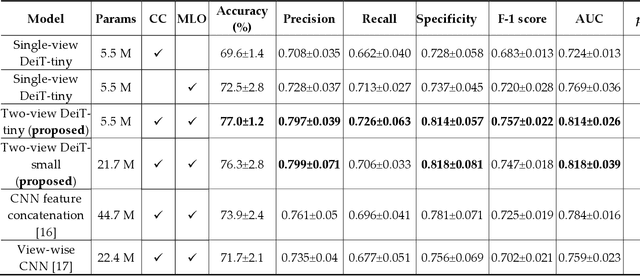
Deep convolutional neural networks (CNNs) have been widely used in various medical imaging tasks. However, due to the intrinsic locality of convolution operation, CNNs generally cannot model long-range dependencies well, which are important for accurately identifying or mapping corresponding breast lesion features computed from unregistered multiple mammograms. This motivates us to leverage the architecture of Multi-view Vision Transformers to capture long-range relationships of multiple mammograms from the same patient in one examination. For this purpose, we employ local Transformer blocks to separately learn patch relationships within four mammograms acquired from two-view (CC/MLO) of two-side (right/left) breasts. The outputs from different views and sides are concatenated and fed into global Transformer blocks, to jointly learn patch relationships between four images representing two different views of the left and right breasts. To evaluate the proposed model, we retrospectively assembled a dataset involving 949 sets of mammograms, which include 470 malignant cases and 479 normal or benign cases. We trained and evaluated the model using a five-fold cross-validation method. Without any arduous preprocessing steps (e.g., optimal window cropping, chest wall or pectoral muscle removal, two-view image registration, etc.), our four-image (two-view-two-side) Transformer-based model achieves case classification performance with an area under ROC curve (AUC = 0.818), which significantly outperforms AUC = 0.784 achieved by the state-of-the-art multi-view CNNs (p = 0.009). It also outperforms two one-view-two-side models that achieve AUC of 0.724 (CC view) and 0.769 (MLO view), respectively. The study demonstrates the potential of using Transformers to develop high-performing computer-aided diagnosis schemes that combine four mammograms.
Invertible Image Signal Processing
Mar 28, 2021



Unprocessed RAW data is a highly valuable image format for image editing and computer vision. However, since the file size of RAW data is huge, most users can only get access to processed and compressed sRGB images. To bridge this gap, we design an Invertible Image Signal Processing (InvISP) pipeline, which not only enables rendering visually appealing sRGB images but also allows recovering nearly perfect RAW data. Due to our framework's inherent reversibility, we can reconstruct realistic RAW data instead of synthesizing RAW data from sRGB images without any memory overhead. We also integrate a differentiable JPEG compression simulator that empowers our framework to reconstruct RAW data from JPEG images. Extensive quantitative and qualitative experiments on two DSLR demonstrate that our method obtains much higher quality in both rendered sRGB images and reconstructed RAW data than alternative methods.
KTN: Knowledge Transfer Network for Learning Multi-person 2D-3D Correspondences
Jun 21, 2022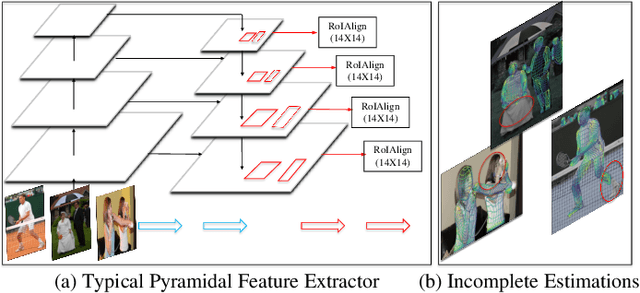
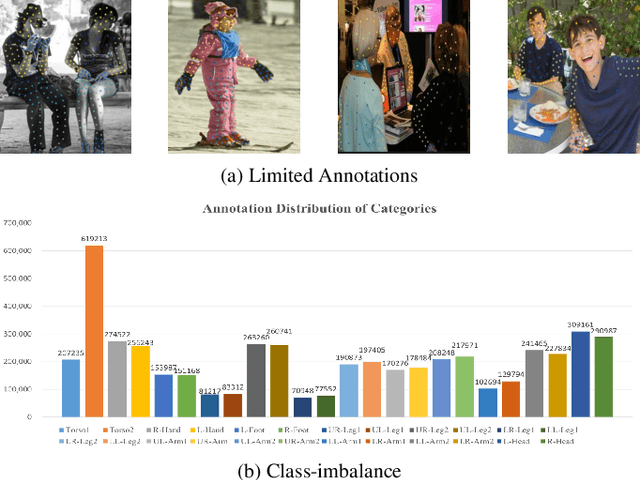
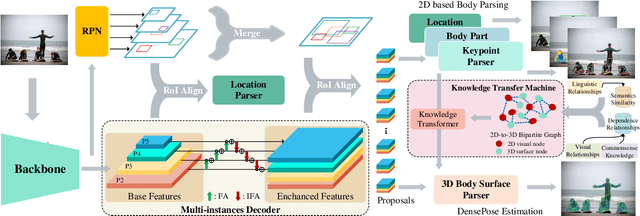
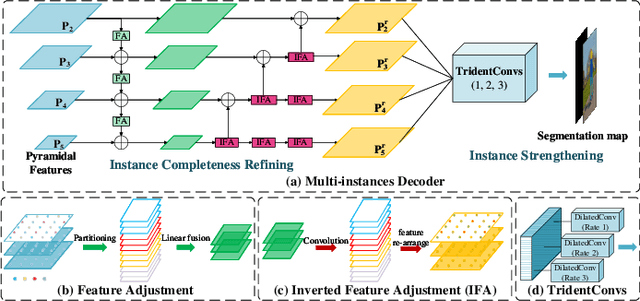
Human densepose estimation, aiming at establishing dense correspondences between 2D pixels of human body and 3D human body template, is a key technique in enabling machines to have an understanding of people in images. It still poses several challenges due to practical scenarios where real-world scenes are complex and only partial annotations are available, leading to incompelete or false estimations. In this work, we present a novel framework to detect the densepose of multiple people in an image. The proposed method, which we refer to Knowledge Transfer Network (KTN), tackles two main problems: 1) how to refine image representation for alleviating incomplete estimations, and 2) how to reduce false estimation caused by the low-quality training labels (i.e., limited annotations and class-imbalance labels). Unlike existing works directly propagating the pyramidal features of regions for densepose estimation, the KTN uses a refinement of pyramidal representation, where it simultaneously maintains feature resolution and suppresses background pixels, and this strategy results in a substantial increase in accuracy. Moreover, the KTN enhances the ability of 3D based body parsing with external knowledges, where it casts 2D based body parsers trained from sufficient annotations as a 3D based body parser through a structural body knowledge graph. In this way, it significantly reduces the adverse effects caused by the low-quality annotations. The effectiveness of KTN is demonstrated by its superior performance to the state-of-the-art methods on DensePose-COCO dataset. Extensive ablation studies and experimental results on representative tasks (e.g., human body segmentation, human part segmentation and keypoints detection) and two popular densepose estimation pipelines (i.e., RCNN and fully-convolutional frameworks), further indicate the generalizability of the proposed method.