 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Orthonormal Convolutions for the Rotation Based Iterative Gaussianization
Jun 08, 2022
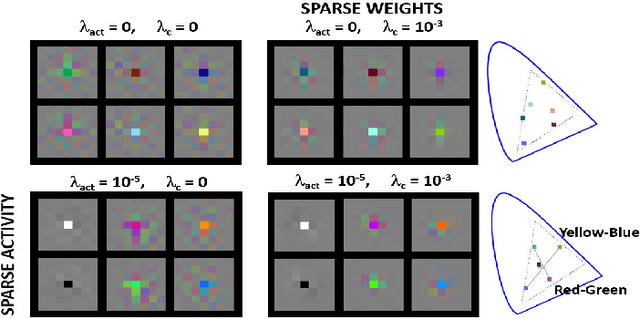
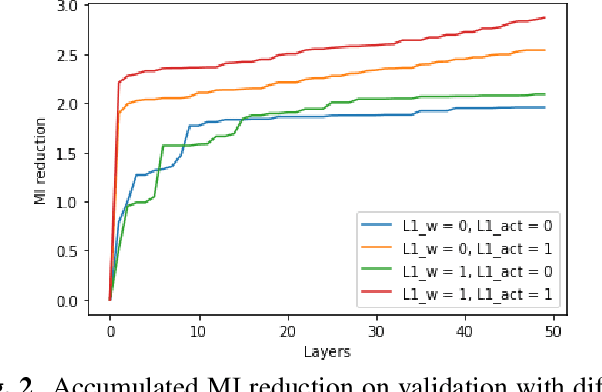
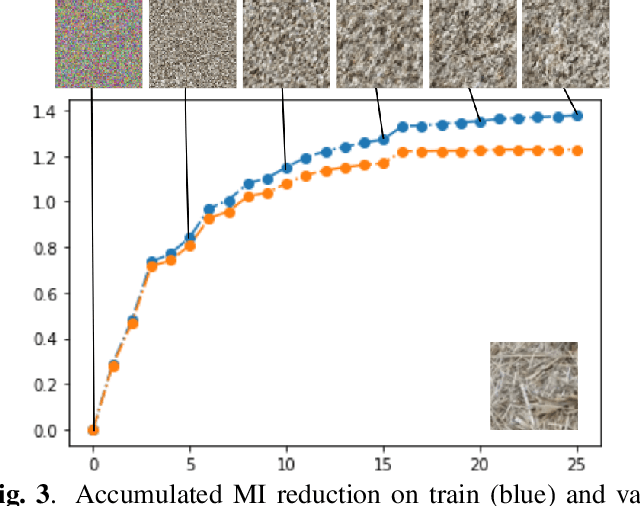

In this paper we elaborate an extension of rotation-based iterative Gaussianization, RBIG, which makes image Gaussianization possible. Although RBIG has been successfully applied to many tasks, it is limited to medium dimensionality data (on the order of a thousand dimensions). In images its application has been restricted to small image patches or isolated pixels, because rotation in RBIG is based on principal or independent component analysis and these transformations are difficult to learn and scale. Here we present the \emph{Convolutional RBIG}: an extension that alleviates this issue by imposing that the rotation in RBIG is a convolution. We propose to learn convolutional rotations (i.e. orthonormal convolutions) by optimising for the reconstruction loss between the input and an approximate inverse of the transformation using the transposed convolution operation. Additionally, we suggest different regularizers in learning these orthonormal convolutions. For example, imposing sparsity in the activations leads to a transformation that extends convolutional independent component analysis to multilayer architectures. We also highlight how statistical properties of the data, such as multivariate mutual information, can be obtained from \emph{Convolutional RBIG}. We illustrate the behavior of the transform with a simple example of texture synthesis, and analyze its properties by visualizing the stimuli that maximize the response in certain feature and layer.
Audio-Visual Segmentation
Jul 11, 2022

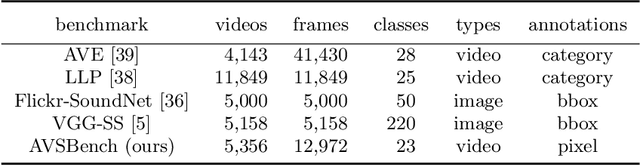
We propose to explore a new problem called audio-visual segmentation (AVS), in which the goal is to output a pixel-level map of the object(s) that produce sound at the time of the image frame. To facilitate this research, we construct the first audio-visual segmentation benchmark (AVSBench), providing pixel-wise annotations for the sounding objects in audible videos. Two settings are studied with this benchmark: 1) semi-supervised audio-visual segmentation with a single sound source and 2) fully-supervised audio-visual segmentation with multiple sound sources. To deal with the AVS problem, we propose a novel method that uses a temporal pixel-wise audio-visual interaction module to inject audio semantics as guidance for the visual segmentation process. We also design a regularization loss to encourage the audio-visual mapping during training. Quantitative and qualitative experiments on the AVSBench compare our approach to several existing methods from related tasks, demonstrating that the proposed method is promising for building a bridge between the audio and pixel-wise visual semantics. Code is available at https://github.com/OpenNLPLab/AVSBench.
Towards Zero-shot Cross-lingual Image Retrieval and Tagging
Sep 15, 2021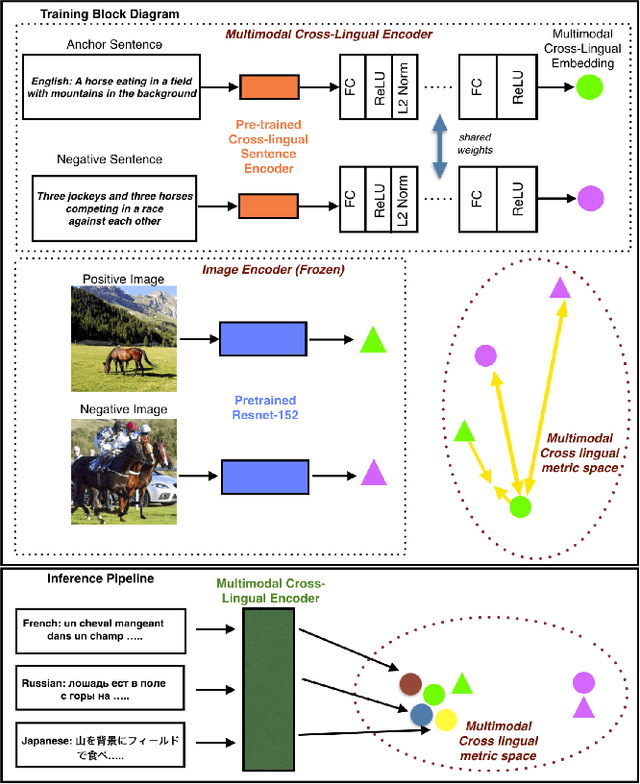
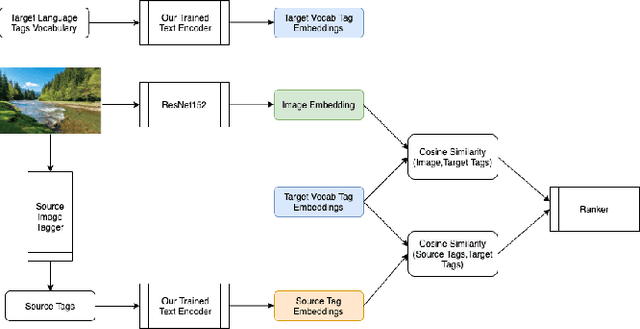

There has been a recent spike in interest in multi-modal Language and Vision problems. On the language side, most of these models primarily focus on English since most multi-modal datasets are monolingual. We try to bridge this gap with a zero-shot approach for learning multi-modal representations using cross-lingual pre-training on the text side. We present a simple yet practical approach for building a cross-lingual image retrieval model which trains on a monolingual training dataset but can be used in a zero-shot cross-lingual fashion during inference. We also introduce a new objective function which tightens the text embedding clusters by pushing dissimilar texts away from each other. For evaluation, we introduce a new 1K multi-lingual MSCOCO2014 caption test dataset (XTD10) in 7 languages that we collected using a crowdsourcing platform. We use this as the test set for zero-shot model performance across languages. We also demonstrate how a cross-lingual model can be used for downstream tasks like multi-lingual image tagging in a zero shot manner. XTD10 dataset is made publicly available here: https://github.com/adobe-research/Cross-lingual-Test-Dataset-XTD10.
Moment Centralization based Gradient Descent Optimizers for Convolutional Neural Networks
Jul 19, 2022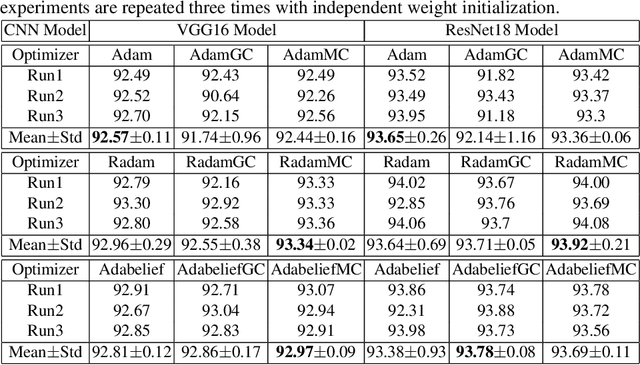

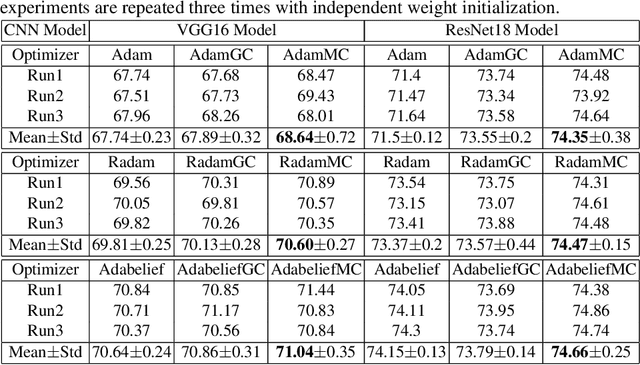
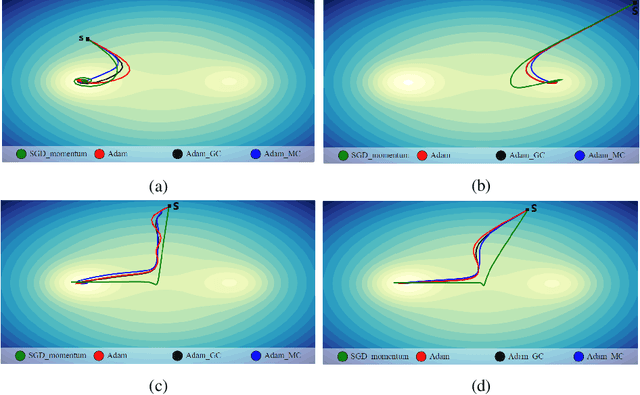
Convolutional neural networks (CNNs) have shown very appealing performance for many computer vision applications. The training of CNNs is generally performed using stochastic gradient descent (SGD) based optimization techniques. The adaptive momentum-based SGD optimizers are the recent trends. However, the existing optimizers are not able to maintain a zero mean in the first-order moment and struggle with optimization. In this paper, we propose a moment centralization-based SGD optimizer for CNNs. Specifically, we impose the zero mean constraints on the first-order moment explicitly. The proposed moment centralization is generic in nature and can be integrated with any of the existing adaptive momentum-based optimizers. The proposed idea is tested with three state-of-the-art optimization techniques, including Adam, Radam, and Adabelief on benchmark CIFAR10, CIFAR100, and TinyImageNet datasets for image classification. The performance of the existing optimizers is generally improved when integrated with the proposed moment centralization. Further, The results of the proposed moment centralization are also better than the existing gradient centralization. The analytical analysis using the toy example shows that the proposed method leads to a shorter and smoother optimization trajectory. The source code is made publicly available at \url{https://github.com/sumanthsadhu/MC-optimizer}.
SGEITL: Scene Graph Enhanced Image-Text Learning for Visual Commonsense Reasoning
Dec 16, 2021

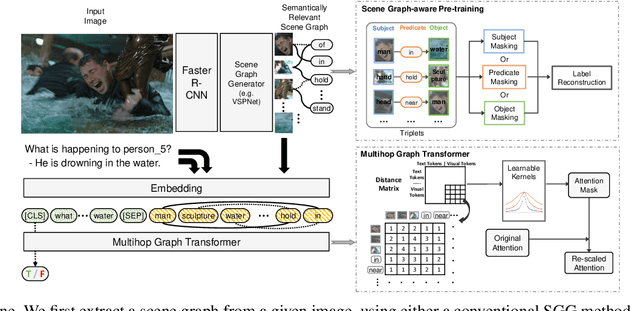

Answering complex questions about images is an ambitious goal for machine intelligence, which requires a joint understanding of images, text, and commonsense knowledge, as well as a strong reasoning ability. Recently, multimodal Transformers have made great progress in the task of Visual Commonsense Reasoning (VCR), by jointly understanding visual objects and text tokens through layers of cross-modality attention. However, these approaches do not utilize the rich structure of the scene and the interactions between objects which are essential in answering complex commonsense questions. We propose a Scene Graph Enhanced Image-Text Learning (SGEITL) framework to incorporate visual scene graphs in commonsense reasoning. To exploit the scene graph structure, at the model structure level, we propose a multihop graph transformer for regularizing attention interaction among hops. As for pre-training, a scene-graph-aware pre-training method is proposed to leverage structure knowledge extracted in the visual scene graph. Moreover, we introduce a method to train and generate domain-relevant visual scene graphs using textual annotations in a weakly-supervised manner. Extensive experiments on VCR and other tasks show a significant performance boost compared with the state-of-the-art methods and prove the efficacy of each proposed component.
* AAAI 2022
Rapid Lung Ultrasound COVID-19 Severity Scoring with Resource-Efficient Deep Feature Extraction
Jul 22, 2022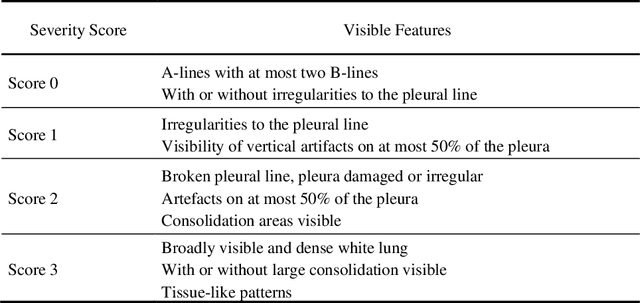
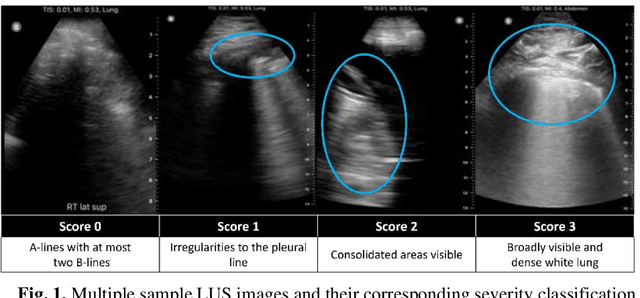
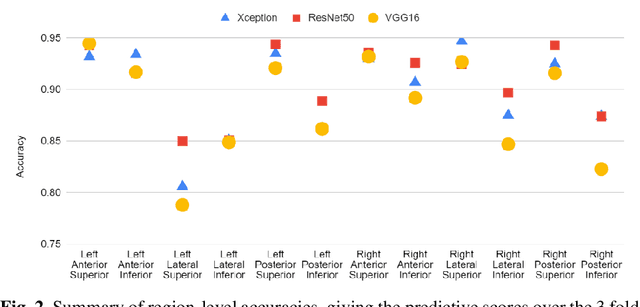
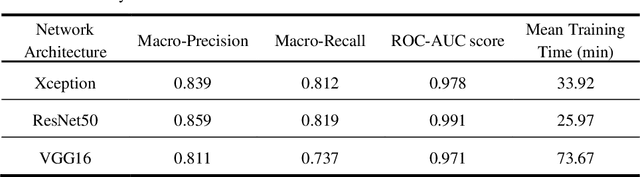
Artificial intelligence-based analysis of lung ultrasound imaging has been demonstrated as an effective technique for rapid diagnostic decision support throughout the COVID-19 pandemic. However, such techniques can require days- or weeks-long training processes and hyper-parameter tuning to develop intelligent deep learning image analysis models. This work focuses on leveraging 'off-the-shelf' pre-trained models as deep feature extractors for scoring disease severity with minimal training time. We propose using pre-trained initializations of existing methods ahead of simple and compact neural networks to reduce reliance on computational capacity. This reduction of computational capacity is of critical importance in time-limited or resource-constrained circumstances, such as the early stages of a pandemic. On a dataset of 49 patients, comprising over 20,000 images, we demonstrate that the use of existing methods as feature extractors results in the effective classification of COVID-19-related pneumonia severity while requiring only minutes of training time. Our methods can achieve an accuracy of over 0.93 on a 4-level severity score scale and provides comparable per-patient region and global scores compared to expert annotated ground truths. These results demonstrate the capability for rapid deployment and use of such minimally-adapted methods for progress monitoring, patient stratification and management in clinical practice for COVID-19 patients, and potentially in other respiratory diseases.
Face Morphing Attack Detection Using Privacy-Aware Training Data
Jul 02, 2022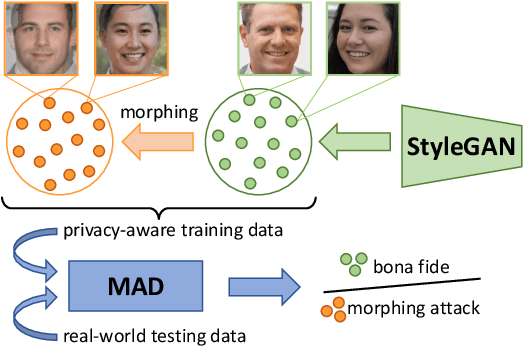


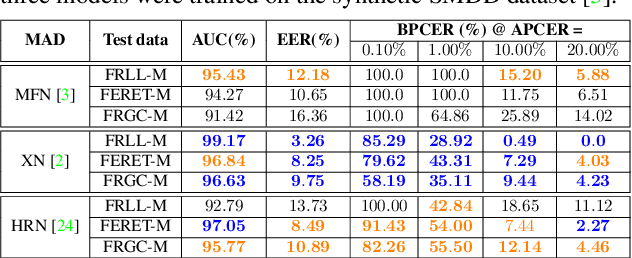
Images of morphed faces pose a serious threat to face recognition--based security systems, as they can be used to illegally verify the identity of multiple people with a single morphed image. Modern detection algorithms learn to identify such morphing attacks using authentic images of real individuals. This approach raises various privacy concerns and limits the amount of publicly available training data. In this paper, we explore the efficacy of detection algorithms that are trained only on faces of non--existing people and their respective morphs. To this end, two dedicated algorithms are trained with synthetic data and then evaluated on three real-world datasets, i.e.: FRLL-Morphs, FERET-Morphs and FRGC-Morphs. Our results show that synthetic facial images can be successfully employed for the training process of the detection algorithms and generalize well to real-world scenarios.
Fourier Imager Network (FIN): A deep neural network for hologram reconstruction with superior external generalization
Apr 22, 2022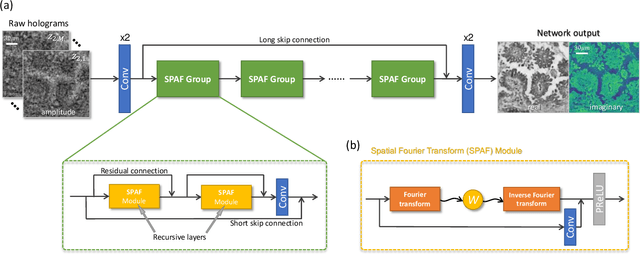
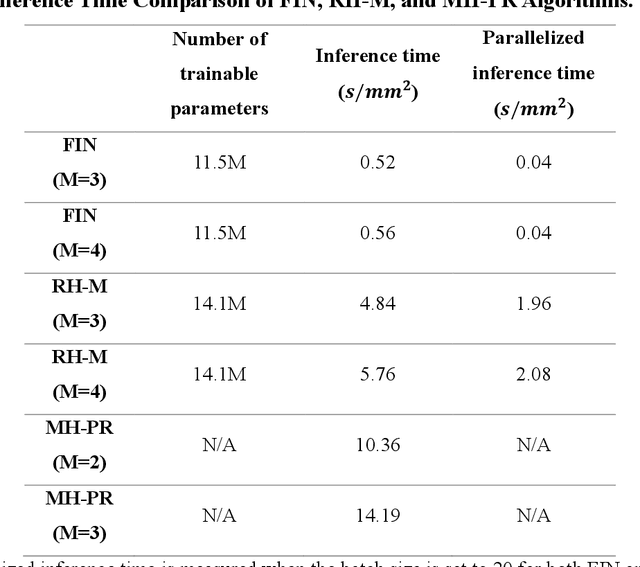

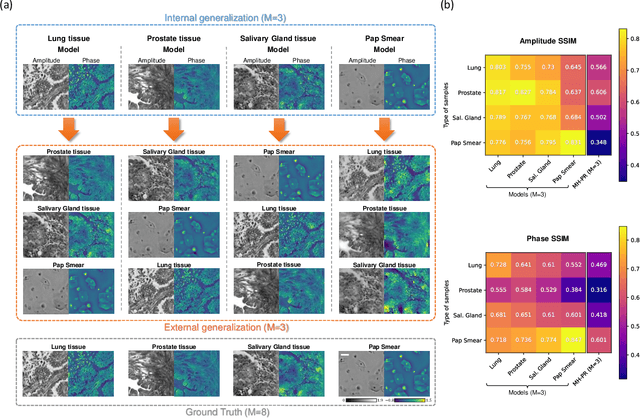
Deep learning-based image reconstruction methods have achieved remarkable success in phase recovery and holographic imaging. However, the generalization of their image reconstruction performance to new types of samples never seen by the network remains a challenge. Here we introduce a deep learning framework, termed Fourier Imager Network (FIN), that can perform end-to-end phase recovery and image reconstruction from raw holograms of new types of samples, exhibiting unprecedented success in external generalization. FIN architecture is based on spatial Fourier transform modules that process the spatial frequencies of its inputs using learnable filters and a global receptive field. Compared with existing convolutional deep neural networks used for hologram reconstruction, FIN exhibits superior generalization to new types of samples, while also being much faster in its image inference speed, completing the hologram reconstruction task in ~0.04 s per 1 mm^2 of the sample area. We experimentally validated the performance of FIN by training it using human lung tissue samples and blindly testing it on human prostate, salivary gland tissue and Pap smear samples, proving its superior external generalization and image reconstruction speed. Beyond holographic microscopy and quantitative phase imaging, FIN and the underlying neural network architecture might open up various new opportunities to design broadly generalizable deep learning models in computational imaging and machine vision fields.
Room geometry blind inference based on the localization of real sound source and first order reflections
Jul 22, 2022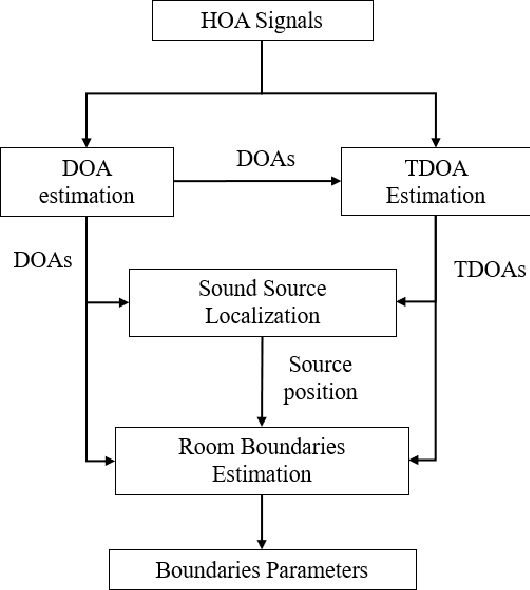
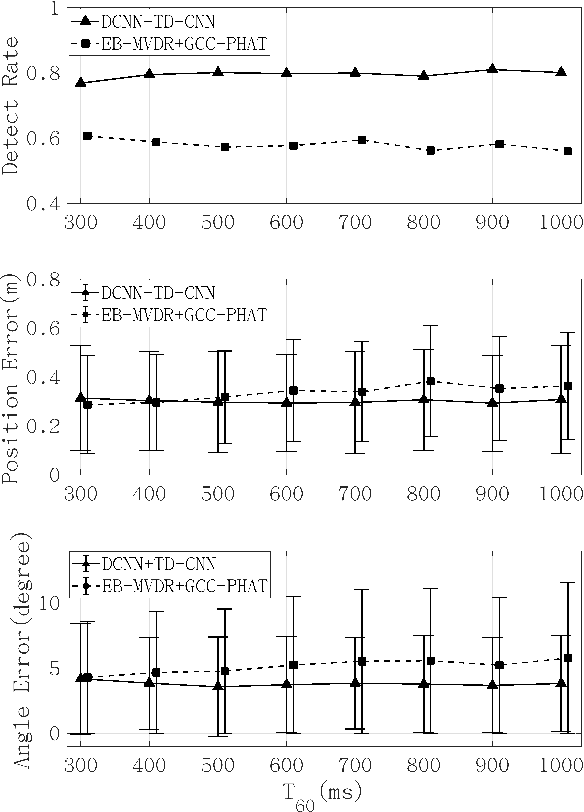

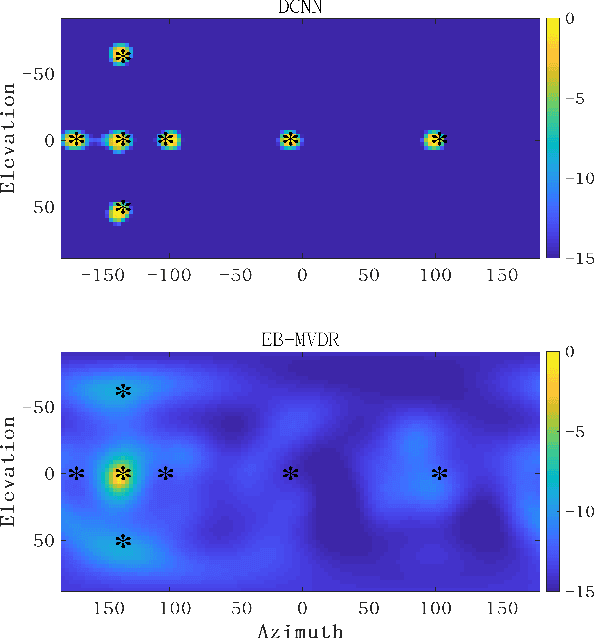
The conventional room geometry blind inference techniques with acoustic signals are conducted based on the prior knowledge of the environment, such as the room impulse response (RIR) or the sound source position, which will limit its application under unknown scenarios. To solve this problem, we have proposed a room geometry reconstruction method in this paper by using the geometric relation between the direct signal and first-order reflections. In addition to the information of the compact microphone array itself, this method does not need any precognition of the environmental parameters. Besides, the learning-based DNN models are designed and used to improve the accuracy and integrity of the localization results of the direct source and first-order reflections. The direction of arrival (DOA) and time difference of arrival (TDOA) information of the direct and reflected signals are firstly estimated using the proposed DCNN and TD-CNN models, which have higher sensitivity and accuracy than the conventional methods. Then the position of the sound source is inferred by integrating the DOA, TDOA and array height using the proposed DNN model. After that, the positions of image sources and corresponding boundaries are derived based on the geometric relation. Experimental results of both simulations and real measurements verify the effectiveness and accuracy of the proposed techniques compared with the conventional methods under different reverberant environments.
MIPR:Automatic Annotation of Medical Images with Pixel Rearrangement
Apr 22, 2022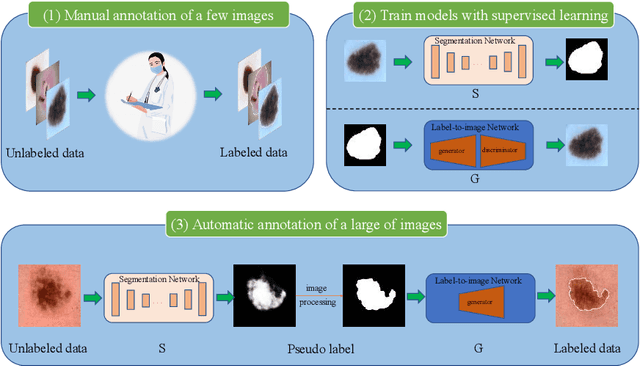
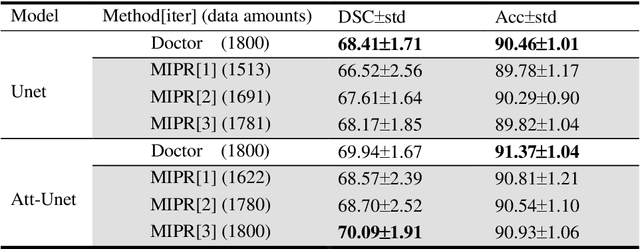
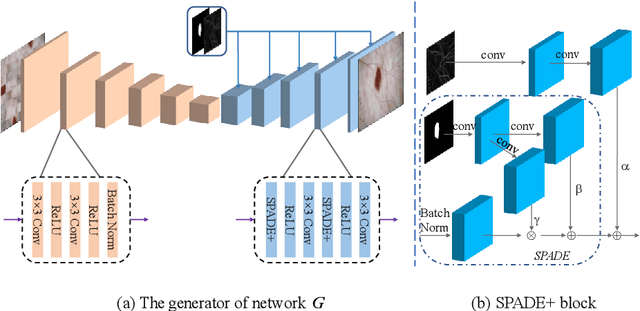
Most of the state-of-the-art semantic segmentation reported in recent years is based on fully supervised deep learning in the medical domain. How?ever, the high-quality annotated datasets require intense labor and domain knowledge, consuming enormous time and cost. Previous works that adopt semi?supervised and unsupervised learning are proposed to address the lack of anno?tated data through assisted training with unlabeled data and achieve good perfor?mance. Still, these methods can not directly get the image annotation as doctors do. In this paper, inspired by self-training of semi-supervised learning, we pro?pose a novel approach to solve the lack of annotated data from another angle, called medical image pixel rearrangement (short in MIPR). The MIPR combines image-editing and pseudo-label technology to obtain labeled data. As the number of iterations increases, the edited image is similar to the original image, and the labeled result is similar to the doctor annotation. Therefore, the MIPR is to get labeled pairs of data directly from amounts of unlabled data with pixel rearrange?ment, which is implemented with a designed conditional Generative Adversarial Networks and a segmentation network. Experiments on the ISIC18 show that the effect of the data annotated by our method for segmentation task is is equal to or even better than that of doctors annotations