 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
GIRAFFE HD: A High-Resolution 3D-aware Generative Model
Mar 28, 2022

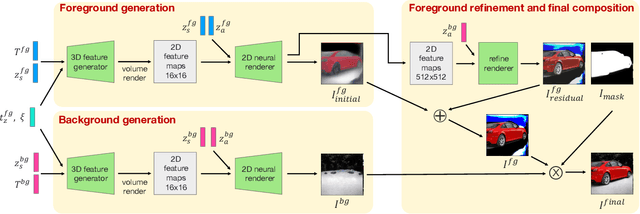

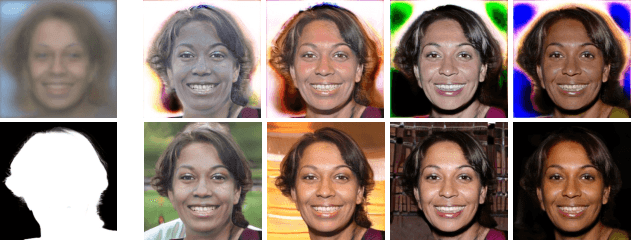
3D-aware generative models have shown that the introduction of 3D information can lead to more controllable image generation. In particular, the current state-of-the-art model GIRAFFE can control each object's rotation, translation, scale, and scene camera pose without corresponding supervision. However, GIRAFFE only operates well when the image resolution is low. We propose GIRAFFE HD, a high-resolution 3D-aware generative model that inherits all of GIRAFFE's controllable features while generating high-quality, high-resolution images ($512^2$ resolution and above). The key idea is to leverage a style-based neural renderer, and to independently generate the foreground and background to force their disentanglement while imposing consistency constraints to stitch them together to composite a coherent final image. We demonstrate state-of-the-art 3D controllable high-resolution image generation on multiple natural image datasets.
AutoDiCE: Fully Automated Distributed CNN Inference at the Edge
Jul 20, 2022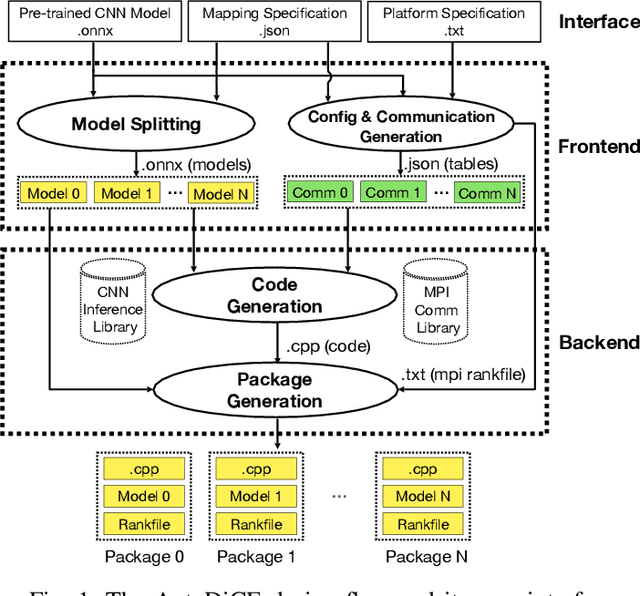
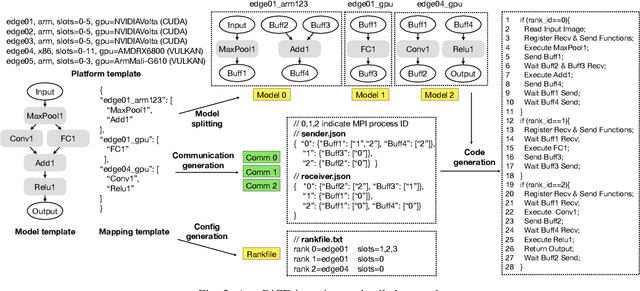
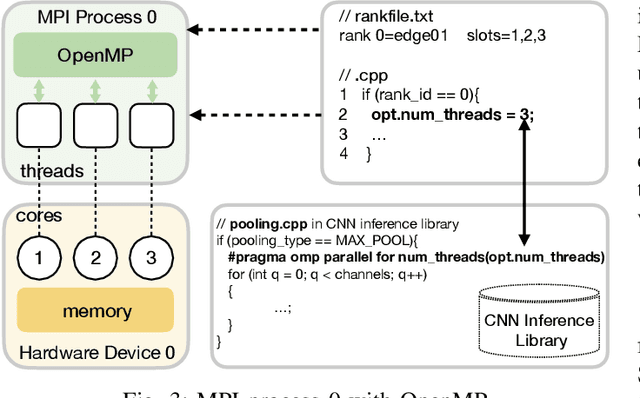
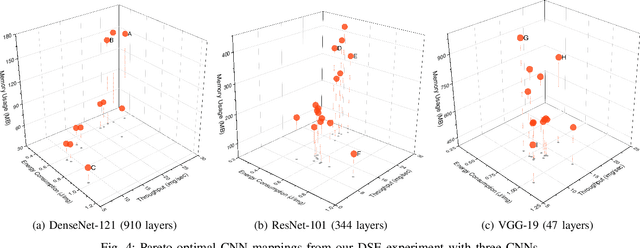
Deep Learning approaches based on Convolutional Neural Networks (CNNs) are extensively utilized and very successful in a wide range of application areas, including image classification and speech recognition. For the execution of trained CNNs, i.e. model inference, we nowadays witness a shift from the Cloud to the Edge. Unfortunately, deploying and inferring large, compute and memory intensive CNNs on edge devices is challenging because these devices typically have limited power budgets and compute/memory resources. One approach to address this challenge is to leverage all available resources across multiple edge devices to deploy and execute a large CNN by properly partitioning the CNN and running each CNN partition on a separate edge device. Although such distribution, deployment, and execution of large CNNs on multiple edge devices is a desirable and beneficial approach, there currently does not exist a design and programming framework that takes a trained CNN model, together with a CNN partitioning specification, and fully automates the CNN model splitting and deployment on multiple edge devices to facilitate distributed CNN inference at the Edge. Therefore, in this paper, we propose a novel framework, called AutoDiCE, for automated splitting of a CNN model into a set of sub-models and automated code generation for distributed and collaborative execution of these sub-models on multiple, possibly heterogeneous, edge devices, while supporting the exploitation of parallelism among and within the edge devices. Our experimental results show that AutoDiCE can deliver distributed CNN inference with reduced energy consumption and memory usage per edge device, and improved overall system throughput at the same time.
Compositional Mixture Representations for Vision and Text
Jun 13, 2022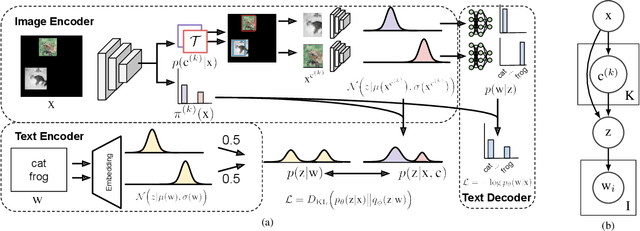
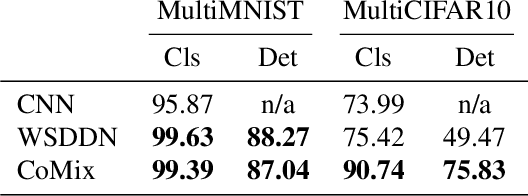
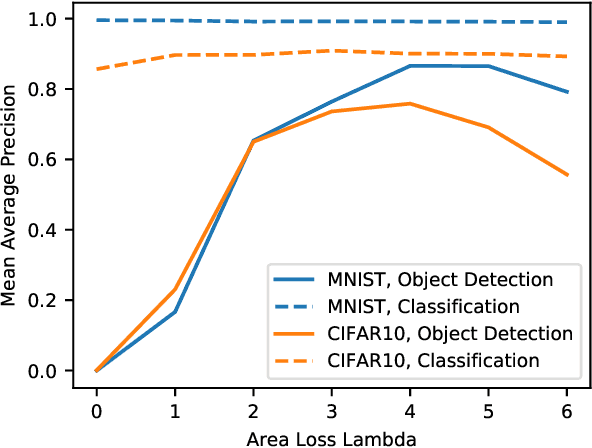
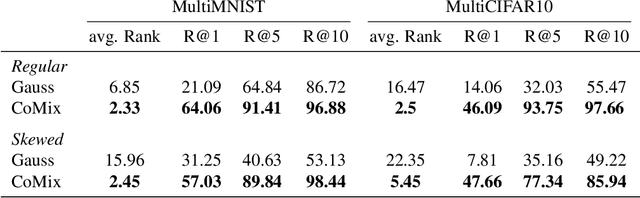
Learning a common representation space between vision and language allows deep networks to relate objects in the image to the corresponding semantic meaning. We present a model that learns a shared Gaussian mixture representation imposing the compositionality of the text onto the visual domain without having explicit location supervision. By combining the spatial transformer with a representation learning approach we learn to split images into separately encoded patches to associate visual and textual representations in an interpretable manner. On variations of MNIST and CIFAR10, our model is able to perform weakly supervised object detection and demonstrates its ability to extrapolate to unseen combination of objects.
Geometry parameter estimation for sparse X-ray log imaging
Jun 29, 2022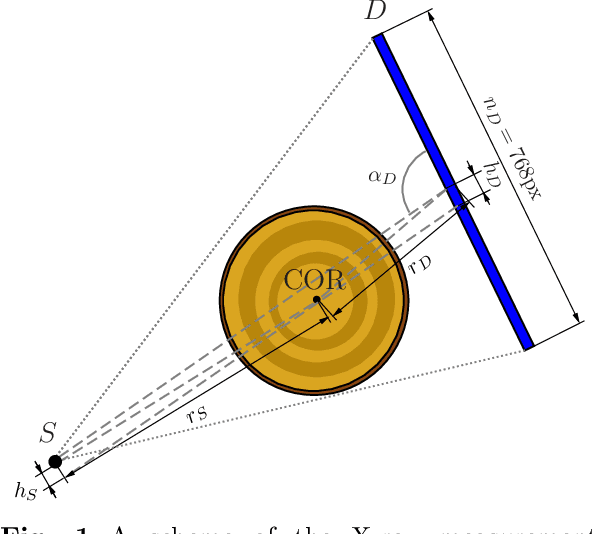

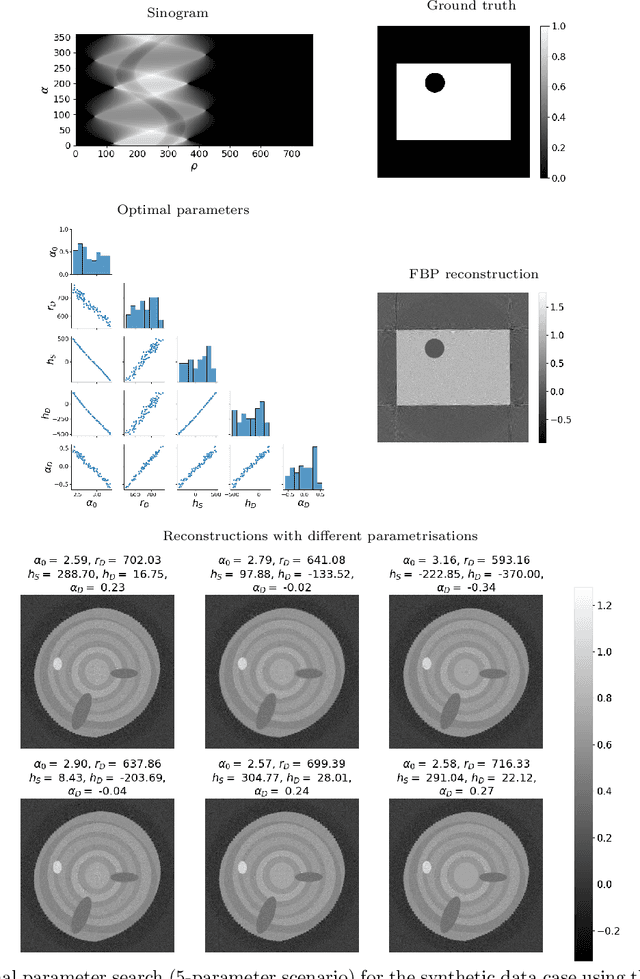
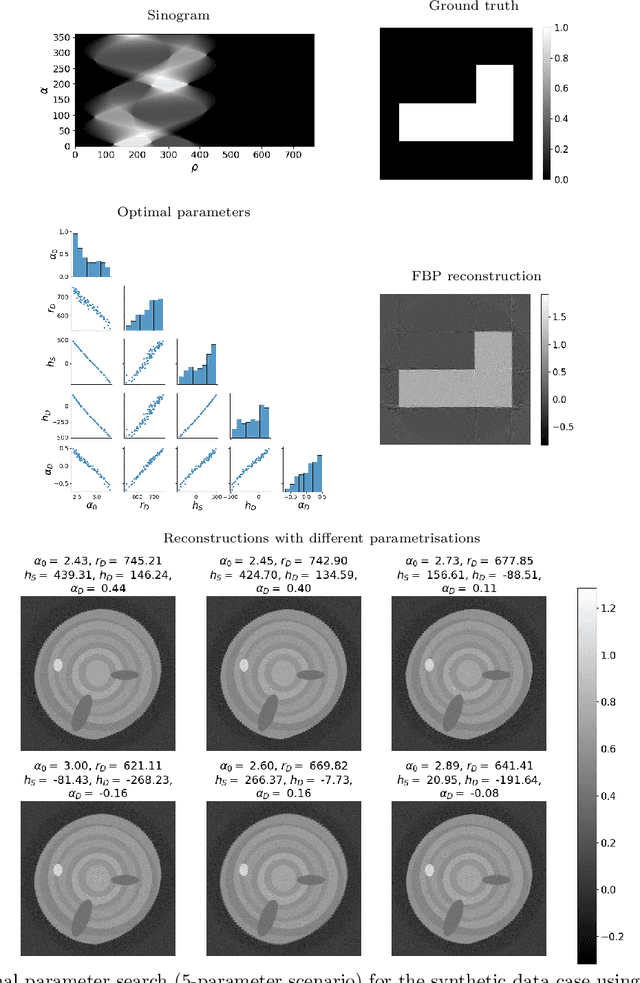
We consider geometry parameter estimation in industrial sawmill fan-beam X-ray tomography. In such industrial settings, scanners do not always allow identification of the location of the source-detector pair, which creates the issue of unknown geometry. This work considers two approaches for geometry estimation. Our first approach is a calibration object correlation method in which we calculate the maximum cross-correlation between a known-sized calibration object image and its filtered backprojection reconstruction and use differential evolution as an optimiser. The second approach is projection trajectory simulation, where we use a set of known intersection points and a sequential Monte Carlo method for estimating the posterior density of the parameters. We show numerically that a large set of parameters can be used for artefact-free reconstruction. We deploy Bayesian inversion with Cauchy priors for synthetic and real sawmill data for detection of knots with a very low number of measurements and uncertain measurement geometry.
Defending Against Image Corruptions Through Adversarial Augmentations
Apr 02, 2021
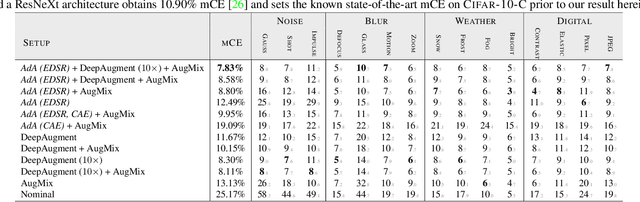
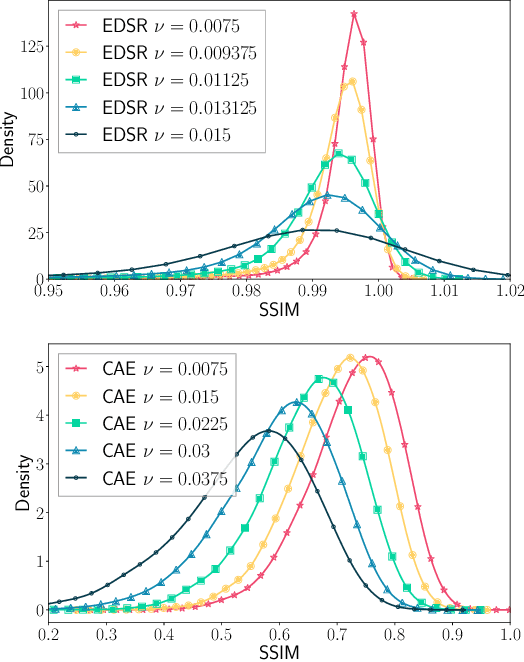
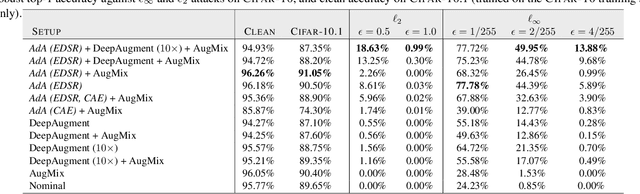
Modern neural networks excel at image classification, yet they remain vulnerable to common image corruptions such as blur, speckle noise or fog. Recent methods that focus on this problem, such as AugMix and DeepAugment, introduce defenses that operate in expectation over a distribution of image corruptions. In contrast, the literature on $\ell_p$-norm bounded perturbations focuses on defenses against worst-case corruptions. In this work, we reconcile both approaches by proposing AdversarialAugment, a technique which optimizes the parameters of image-to-image models to generate adversarially corrupted augmented images. We theoretically motivate our method and give sufficient conditions for the consistency of its idealized version as well as that of DeepAugment. Our classifiers improve upon the state-of-the-art on common image corruption benchmarks conducted in expectation on CIFAR-10-C and improve worst-case performance against $\ell_p$-norm bounded perturbations on both CIFAR-10 and ImageNet.
Zero-Shot Temporal Action Detection via Vision-Language Prompting
Jul 17, 2022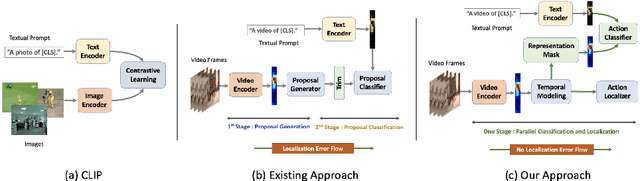
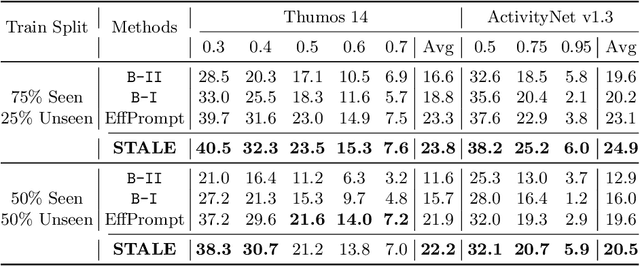
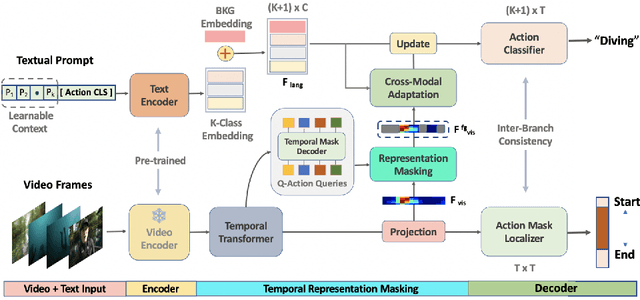
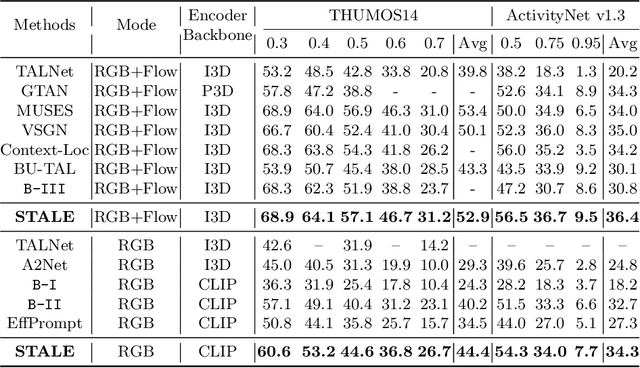
Existing temporal action detection (TAD) methods rely on large training data including segment-level annotations, limited to recognizing previously seen classes alone during inference. Collecting and annotating a large training set for each class of interest is costly and hence unscalable. Zero-shot TAD (ZS-TAD) resolves this obstacle by enabling a pre-trained model to recognize any unseen action classes. Meanwhile, ZS-TAD is also much more challenging with significantly less investigation. Inspired by the success of zero-shot image classification aided by vision-language (ViL) models such as CLIP, we aim to tackle the more complex TAD task. An intuitive method is to integrate an off-the-shelf proposal detector with CLIP style classification. However, due to the sequential localization (e.g, proposal generation) and classification design, it is prone to localization error propagation. To overcome this problem, in this paper we propose a novel zero-Shot Temporal Action detection model via Vision-LanguagE prompting (STALE). Such a novel design effectively eliminates the dependence between localization and classification by breaking the route for error propagation in-between. We further introduce an interaction mechanism between classification and localization for improved optimization. Extensive experiments on standard ZS-TAD video benchmarks show that our STALE significantly outperforms state-of-the-art alternatives. Besides, our model also yields superior results on supervised TAD over recent strong competitors. The PyTorch implementation of STALE is available at https://github.com/sauradip/STALE.
Entropy-Based Feature Extraction For Real-Time Semantic Segmentation
Jul 07, 2022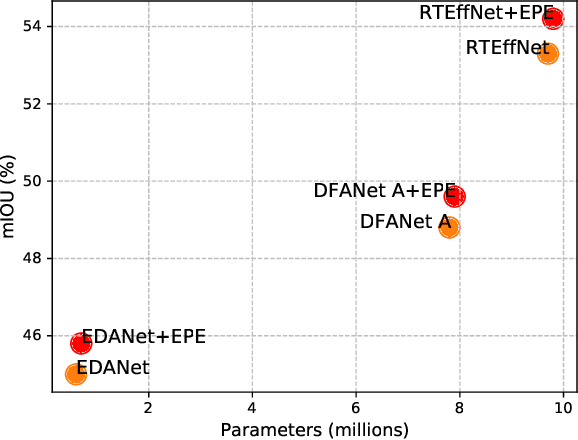
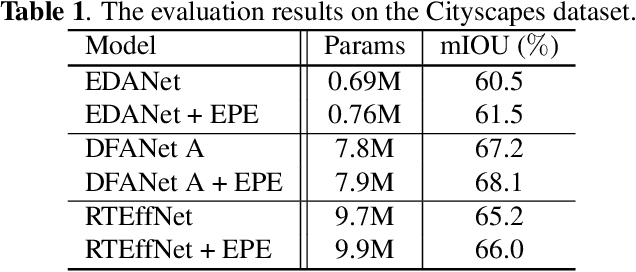
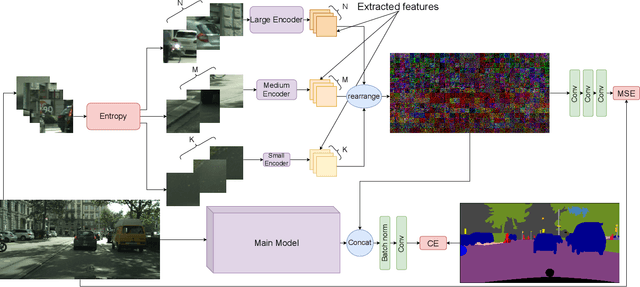

This paper introduces an efficient patch-based computational module, coined Entropy-based Patch Encoder (EPE) module, for resource-constrained semantic segmentation. The EPE module consists of three lightweight fully-convolutional encoders, each extracting features from image patches with a different amount of entropy. Patches with high entropy are being processed by the encoder with the largest number of parameters, patches with moderate entropy are processed by the encoder with a moderate number of parameters, and patches with low entropy are processed by the smallest encoder. The intuition behind the module is the following: as patches with high entropy contain more information, they need an encoder with more parameters, unlike low entropy patches, which can be processed using a small encoder. Consequently, processing part of the patches via the smaller encoder can significantly reduce the computational cost of the module. Experiments show that EPE can boost the performance of existing real-time semantic segmentation models with a slight increase in the computational cost. Specifically, EPE increases the mIOU performance of DFANet A by 0.9% with only 1.2% increase in the number of parameters and the mIOU performance of EDANet by 1% with 10% increase of the model parameters.
Super-resolution reconstruction of cytoskeleton image based on A-net deep learning network
Dec 17, 2021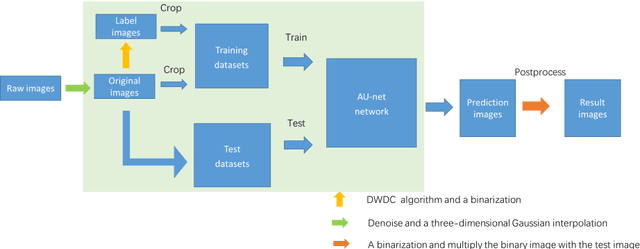
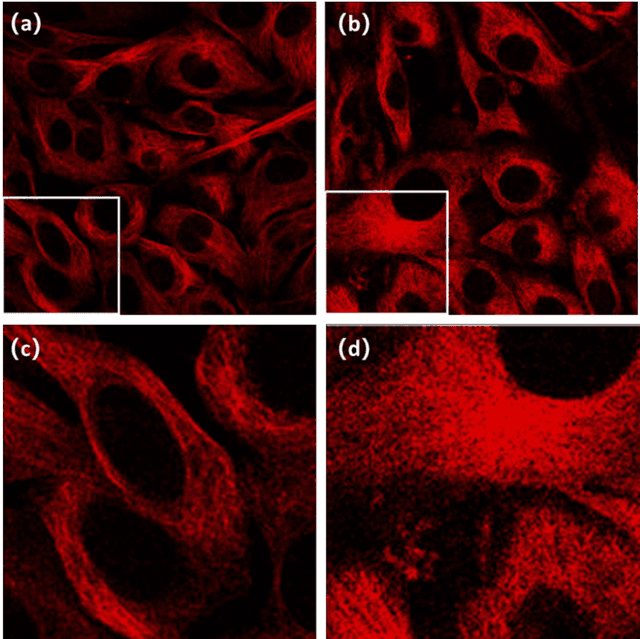
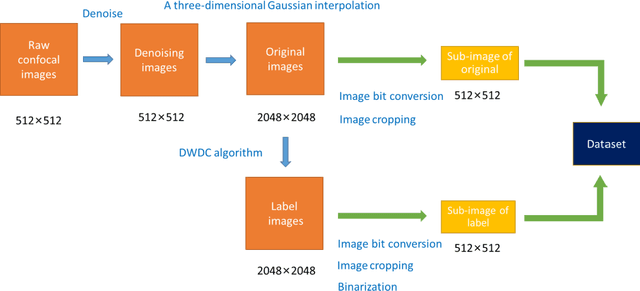
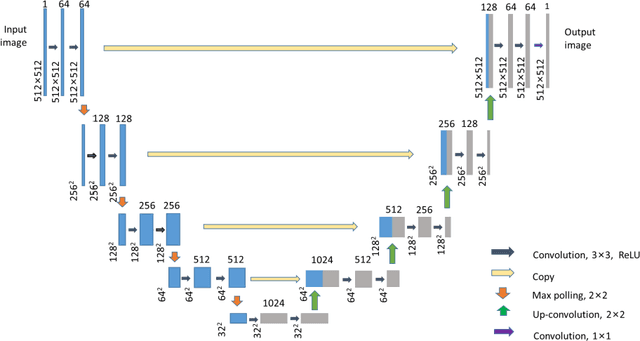
To date, live-cell imaging at the nanometer scale remains challenging. Even though super-resolution microscopy methods have enabled visualization of subcellular structures below the optical resolution limit, the spatial resolution is still far from enough for the structural reconstruction of biomolecules in vivo (i.e. ~24 nm thickness of microtubule fiber). In this study, we proposed an A-net network and showed that the resolution of cytoskeleton images captured by a confocal microscope can be significantly improved by combining the A-net deep learning network with the DWDC algorithm based on degradation model. Utilizing the DWDC algorithm to construct new datasets and taking advantage of A-net neural network's features (i.e., considerably fewer layers), we successfully removed the noise and flocculent structures, which originally interfere with the cellular structure in the raw image, and improved the spatial resolution by 10 times using relatively small dataset. We, therefore, conclude that the proposed algorithm that combines A-net neural network with the DWDC method is a suitable and universal approach for exacting structural details of biomolecules, cells and organs from low-resolution images.
A multi-level interpretable sleep stage scoring system by infusing experts' knowledge into a deep network architecture
Jul 11, 2022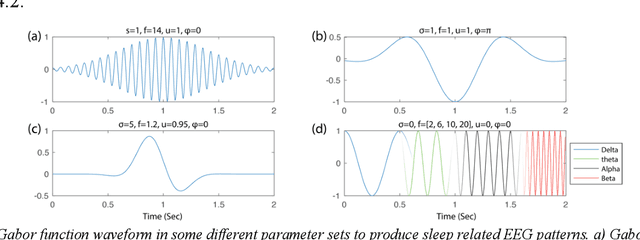
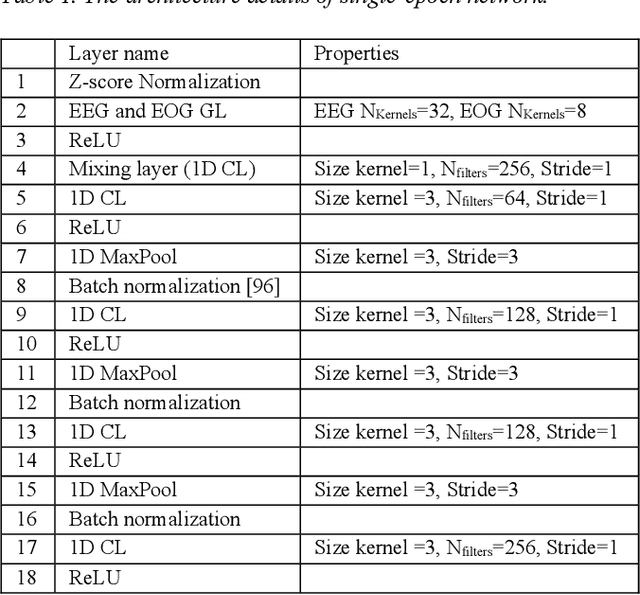
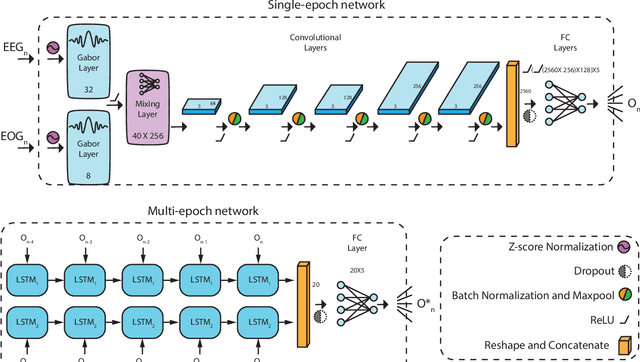
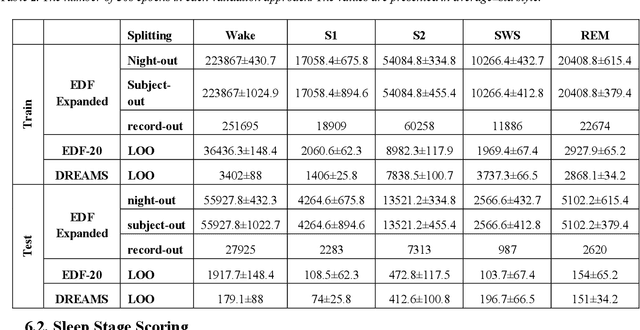
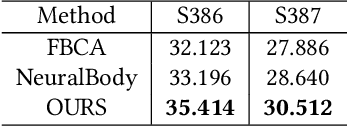
In recent years, deep learning has shown potential and efficiency in a wide area including computer vision, image and signal processing. Yet, translational challenges remain for user applications due to a lack of interpretability of algorithmic decisions and results. This black box problem is particularly problematic for high-risk applications such as medical-related decision-making. The current study goal was to design an interpretable deep learning system for time series classification of electroencephalogram (EEG) for sleep stage scoring as a step toward designing a transparent system. We have developed an interpretable deep neural network that includes a kernel-based layer based on a set of principles used for sleep scoring by human experts in the visual analysis of polysomnographic records. A kernel-based convolutional layer was defined and used as the first layer of the system and made available for user interpretation. The trained system and its results were interpreted in four levels from the microstructure of EEG signals, such as trained kernels and the effect of each kernel on the detected stages, to macrostructures, such as the transition between stages. The proposed system demonstrated greater performance than prior studies and the results of interpretation showed that the system learned information which was consistent with expert knowledge.
Drivable Volumetric Avatars using Texel-Aligned Features
Jul 20, 2022
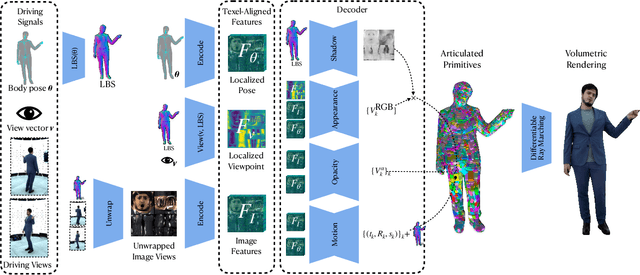
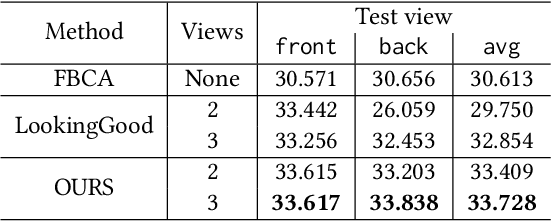
Photorealistic telepresence requires both high-fidelity body modeling and faithful driving to enable dynamically synthesized appearance that is indistinguishable from reality. In this work, we propose an end-to-end framework that addresses two core challenges in modeling and driving full-body avatars of real people. One challenge is driving an avatar while staying faithful to details and dynamics that cannot be captured by a global low-dimensional parameterization such as body pose. Our approach supports driving of clothed avatars with wrinkles and motion that a real driving performer exhibits beyond the training corpus. Unlike existing global state representations or non-parametric screen-space approaches, we introduce texel-aligned features -- a localised representation which can leverage both the structural prior of a skeleton-based parametric model and observed sparse image signals at the same time. Another challenge is modeling a temporally coherent clothed avatar, which typically requires precise surface tracking. To circumvent this, we propose a novel volumetric avatar representation by extending mixtures of volumetric primitives to articulated objects. By explicitly incorporating articulation, our approach naturally generalizes to unseen poses. We also introduce a localized viewpoint conditioning, which leads to a large improvement in generalization of view-dependent appearance. The proposed volumetric representation does not require high-quality mesh tracking as a prerequisite and brings significant quality improvements compared to mesh-based counterparts. In our experiments, we carefully examine our design choices and demonstrate the efficacy of our approach, outperforming the state-of-the-art methods on challenging driving scenarios.