 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cross-View Language Modeling: Towards Unified Cross-Lingual Cross-Modal Pre-training
Jun 01, 2022
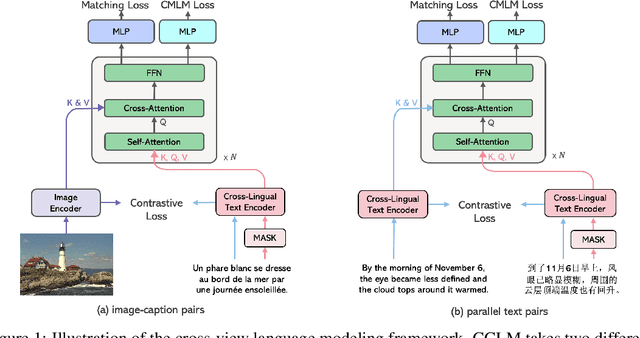
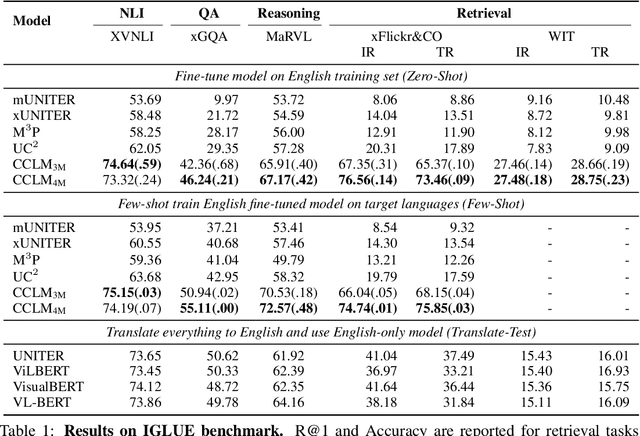
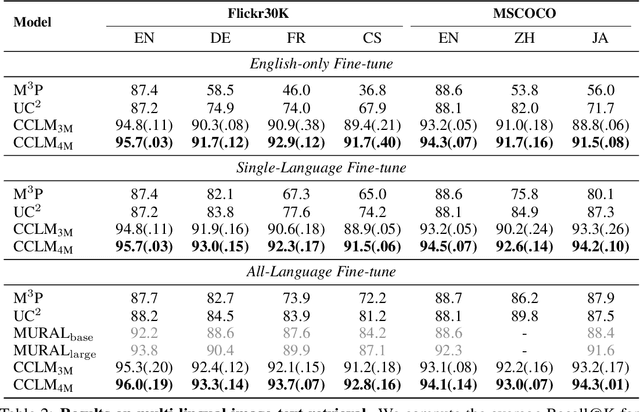
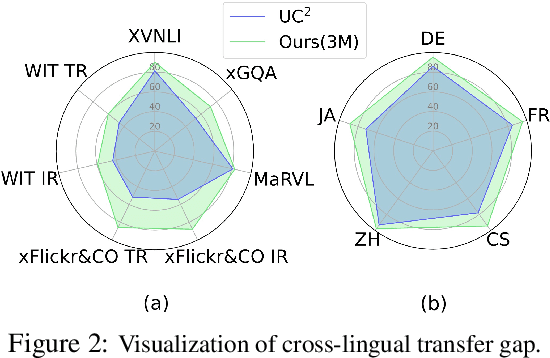
In this paper, we introduce Cross-View Language Modeling, a simple and effective language model pre-training framework that unifies cross-lingual cross-modal pre-training with shared architectures and objectives. Our approach is motivated by a key observation that cross-lingual and cross-modal pre-training share the same goal of aligning two different views of the same object into a common semantic space. To this end, the cross-view language modeling framework considers both multi-modal data (i.e., image-caption pairs) and multi-lingual data (i.e., parallel sentence pairs) as two different views of the same object, and trains the model to align the two views by maximizing the mutual information between them with conditional masked language modeling and contrastive learning. We pre-train CCLM, a Cross-lingual Cross-modal Language Model, with the cross-view language modeling framework. Empirical results on IGLUE, a multi-lingual multi-modal benchmark, and two multi-lingual image-text retrieval datasets show that while conceptually simpler, CCLM significantly outperforms the prior state-of-the-art with an average absolute improvement of over 10%. Notably, CCLM is the first multi-lingual multi-modal model that surpasses the translate-test performance of representative English vision-language models by zero-shot cross-lingual transfer.
Towards Highly Expressive Machine Learning Models of Non-Melanoma Skin Cancer
Jul 09, 2022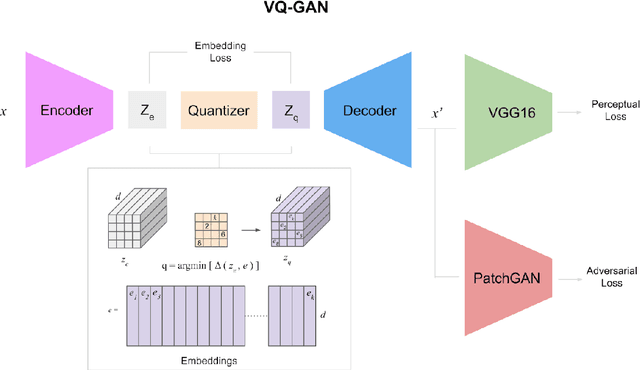
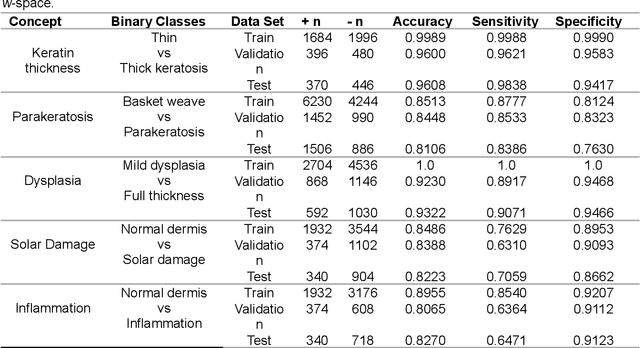
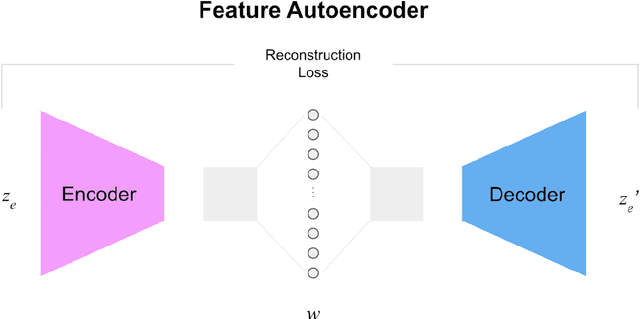
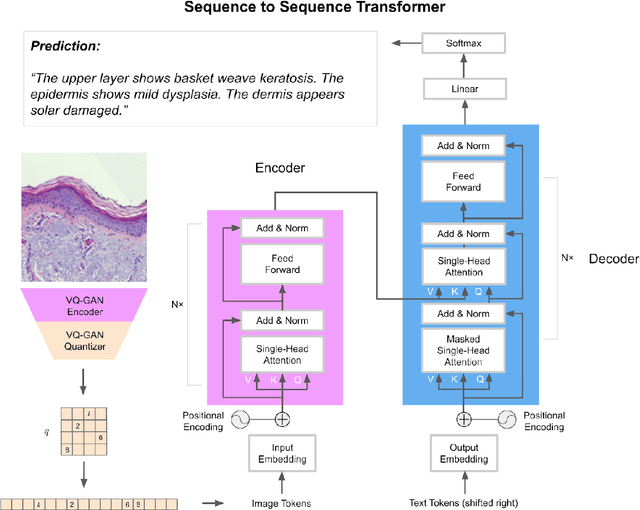
Pathologists have a rich vocabulary with which they can describe all the nuances of cellular morphology. In their world, there is a natural pairing of images and words. Recent advances demonstrate that machine learning models can now be trained to learn high-quality image features and represent them as discrete units of information. This enables natural language, which is also discrete, to be jointly modelled alongside the imaging, resulting in a description of the contents of the imaging. Here we present experiments in applying discrete modelling techniques to the problem domain of non-melanoma skin cancer, specifically, histological images of Intraepidermal Carcinoma (IEC). Implementing a VQ-GAN model to reconstruct high-resolution (256x256) images of IEC images, we trained a sequence-to-sequence transformer to generate natural language descriptions using pathologist terminology. Combined with the idea of interactive concept vectors available by using continuous generative methods, we demonstrate an additional angle of interpretability. The result is a promising means of working towards highly expressive machine learning systems which are not only useful as predictive/classification tools, but also means to further our scientific understanding of disease.
Delving into Deep Image Prior for Adversarial Defense: A Novel Reconstruction-based Defense Framework
Jul 31, 2021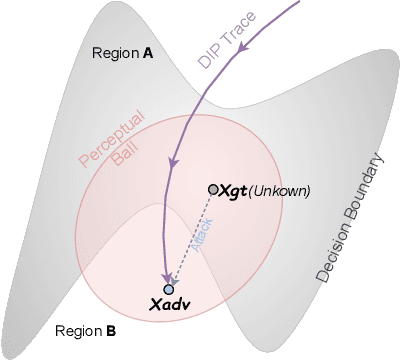
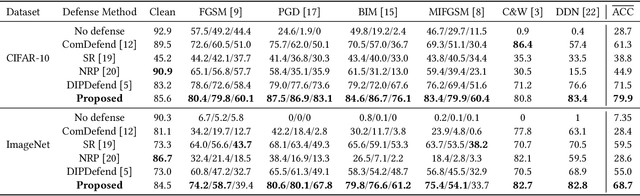
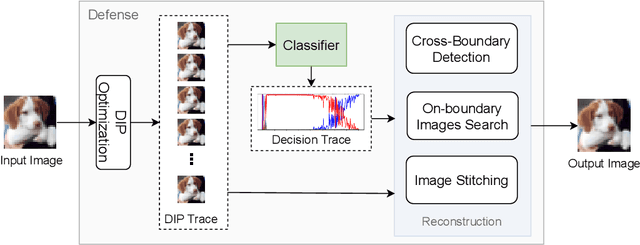
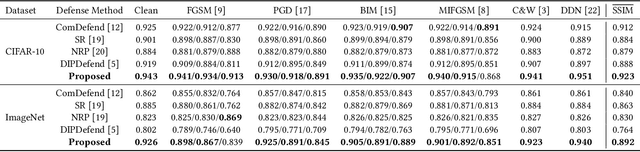
Deep learning based image classification models are shown vulnerable to adversarial attacks by injecting deliberately crafted noises to clean images. To defend against adversarial attacks in a training-free and attack-agnostic manner, this work proposes a novel and effective reconstruction-based defense framework by delving into deep image prior (DIP). Fundamentally different from existing reconstruction-based defenses, the proposed method analyzes and explicitly incorporates the model decision process into our defense. Given an adversarial image, firstly we map its reconstructed images during DIP optimization to the model decision space, where cross-boundary images can be detected and on-boundary images can be further localized. Then, adversarial noise is purified by perturbing on-boundary images along the reverse direction to the adversarial image. Finally, on-manifold images are stitched to construct an image that can be correctly predicted by the victim classifier. Extensive experiments demonstrate that the proposed method outperforms existing state-of-the-art reconstruction-based methods both in defending white-box attacks and defense-aware attacks. Moreover, the proposed method can maintain a high visual quality during adversarial image reconstruction.
Augmented Imagefication: A Data-driven Fault Detection Method for Aircraft Air Data Sensors
Jun 18, 2022
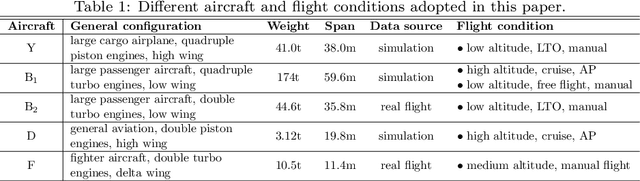
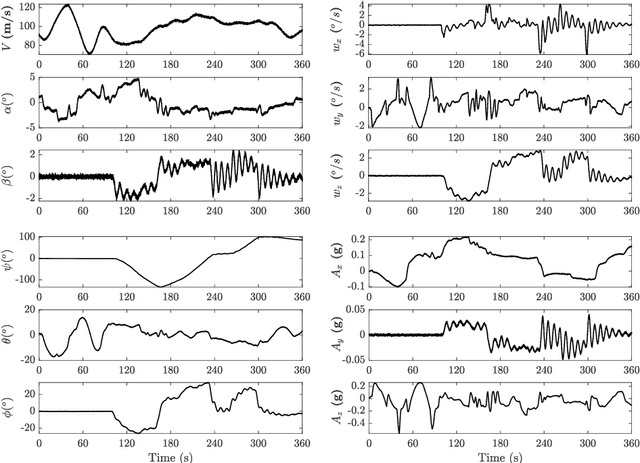

In this paper, a novel data-driven approach named Augmented Imagefication for Fault detection (FD) of aircraft air data sensors (ADS) is proposed. Exemplifying the FD problem of aircraft air data sensors, an online FD scheme on edge device based on deep neural network (DNN) is developed. First, the aircraft inertial reference unit measurements is adopted as equivalent inputs, which is scalable to different aircraft/flight cases. Data associated with 6 different aircraft/flight conditions are collected to provide diversity (scalability) in the training/testing database. Then Augmented Imagefication is proposed for the DNN-based prediction of flying conditions. The raw data are reshaped as a grayscale image for convolutional operation, and the necessity of augmentation is analyzed and pointed out. Different kinds of augmented method, i.e. Flip, Repeat, Tile and their combinations are discussed, the result shows that the All Repeat operation in both axes of image matrix leads to the best performance of DNN. The interpretability of DNN is studied based on Grad-CAM, which provide a better understanding and further solidifies the robustness of DNN. Next the DNN model, VGG-16 with augmented imagefication data is optimized for mobile hardware deployment. After pruning of DNN, a lightweight model (98.79% smaller than original VGG-16) with high accuracy (slightly up by 0.27%) and fast speed (time delay is reduced by 87.54%) is obtained. And the hyperparameters optimization of DNN based on TPE is implemented and the best combination of hyperparameters is determined (learning rate 0.001, iterative epochs 600, and batch size 100 yields the highest accuracy at 0.987). Finally, a online FD deployment based on edge device, Jetson Nano, is developed and the real time monitoring of aircraft is achieved. We believe that this method is instructive for addressing the FD problems in other similar fields.
Contrastive Semi-Supervised Learning for 2D Medical Image Segmentation
Jul 10, 2021



Contrastive Learning (CL) is a recent representation learning approach, which encourages inter-class separability and intra-class compactness in learned image representations. Since medical images often contain multiple semantic classes in an image, using CL to learn representations of local features (as opposed to global) is important. In this work, we present a novel semi-supervised 2D medical segmentation solution that applies CL on image patches, instead of full images. These patches are meaningfully constructed using the semantic information of different classes obtained via pseudo labeling. We also propose a novel consistency regularization (CR) scheme, which works in synergy with CL. It addresses the problem of confirmation bias, and encourages better clustering in the feature space. We evaluate our method on four public medical segmentation datasets and a novel histopathology dataset that we introduce. Our method obtains consistent improvements over state-of-the-art semi-supervised segmentation approaches for all datasets.
WuDaoMM: A large-scale Multi-Modal Dataset for Pre-training models
Mar 30, 2022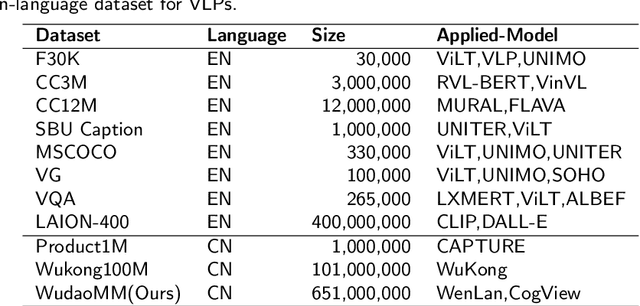


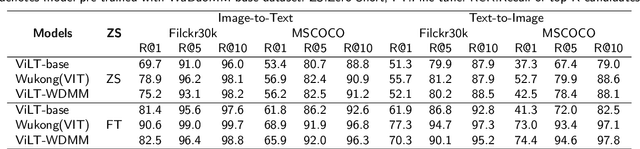
Compared with the domain-specific model, the vision-language pre-training models (VLPMs) have shown superior performance on downstream tasks with fast fine-tuning process. For example, ERNIE-ViL, Oscar and UNIMO trained VLPMs with a uniform transformers stack architecture and large amounts of image-text paired data, achieving remarkable results on downstream tasks such as image-text reference(IR and TR), vision question answering (VQA) and image captioning (IC) etc. During the training phase, VLPMs are always fed with a combination of multiple public datasets to meet the demand of large-scare training data. However, due to the unevenness of data distribution including size, task type and quality, using the mixture of multiple datasets for model training can be problematic. In this work, we introduce a large-scale multi-modal corpora named WuDaoMM, totally containing more than 650M image-text pairs. Specifically, about 600 million pairs of data are collected from multiple webpages in which image and caption present weak correlation, and the other 50 million strong-related image-text pairs are collected from some high-quality graphic websites. We also release a base version of WuDaoMM with 5 million strong-correlated image-text pairs, which is sufficient to support the common cross-modal model pre-training. Besides, we trained both an understanding and a generation vision-language (VL) model to test the dataset effectiveness. The results show that WuDaoMM can be applied as an efficient dataset for VLPMs, especially for the model in text-to-image generation task. The data is released at https://data.wudaoai.cn
Measuring Forgetting of Memorized Training Examples
Jun 30, 2022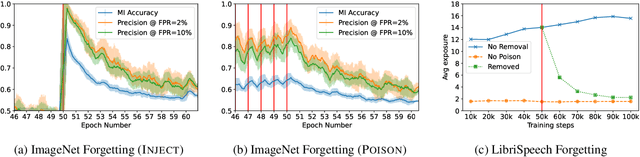
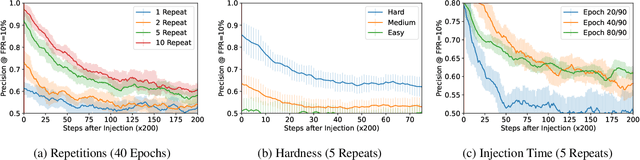
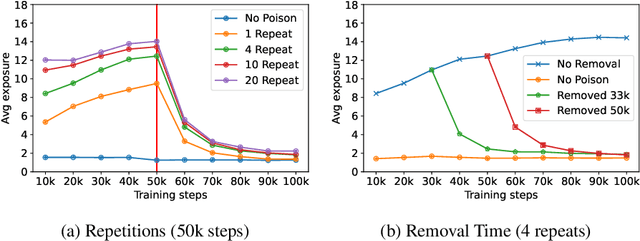
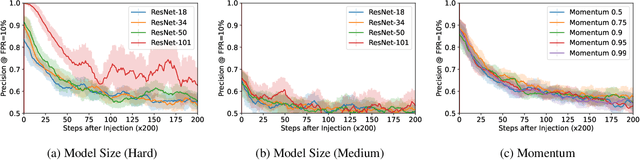
Machine learning models exhibit two seemingly contradictory phenomena: training data memorization and various forms of forgetting. In memorization, models overfit specific training examples and become susceptible to privacy attacks. In forgetting, examples which appeared early in training are forgotten by the end. In this work, we connect these phenomena. We propose a technique to measure to what extent models ``forget'' the specifics of training examples, becoming less susceptible to privacy attacks on examples they have not seen recently. We show that, while non-convexity can prevent forgetting from happening in the worst-case, standard image and speech models empirically do forget examples over time. We identify nondeterminism as a potential explanation, showing that deterministically trained models do not forget. Our results suggest that examples seen early when training with extremely large datasets -- for instance those examples used to pre-train a model -- may observe privacy benefits at the expense of examples seen later.
Object-aware Long-short-range Spatial Alignment for Few-Shot Fine-Grained Image Classification
Aug 30, 2021The goal of few-shot fine-grained image classification is to recognize rarely seen fine-grained objects in the query set, given only a few samples of this class in the support set. Previous works focus on learning discriminative image features from a limited number of training samples for distinguishing various fine-grained classes, but ignore one important fact that spatial alignment of the discriminative semantic features between the query image with arbitrary changes and the support image, is also critical for computing the semantic similarity between each support-query pair. In this work, we propose an object-aware long-short-range spatial alignment approach, which is composed of a foreground object feature enhancement (FOE) module, a long-range semantic correspondence (LSC) module and a short-range spatial manipulation (SSM) module. The FOE is developed to weaken background disturbance and encourage higher foreground object response. To address the problem of long-range object feature misalignment between support-query image pairs, the LSC is proposed to learn the transferable long-range semantic correspondence by a designed feature similarity metric. Further, the SSM module is developed to refine the transformed support feature after the long-range step to align short-range misaligned features (or local details) with the query features. Extensive experiments have been conducted on four benchmark datasets, and the results show superior performance over most state-of-the-art methods under both 1-shot and 5-shot classification scenarios.
Cross-Image Region Mining with Region Prototypical Network for Weakly Supervised Segmentation
Aug 17, 2021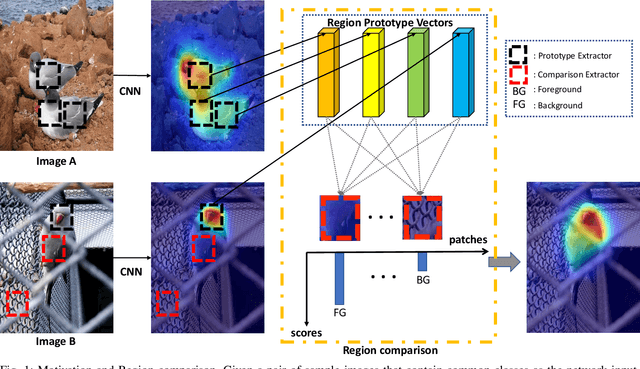
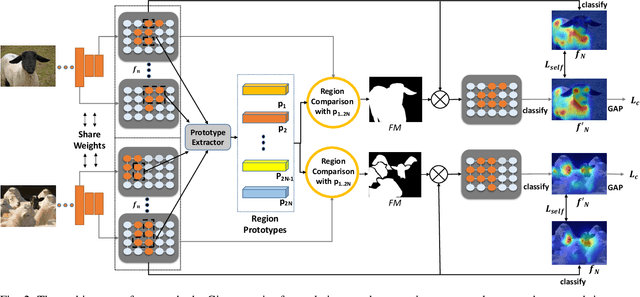
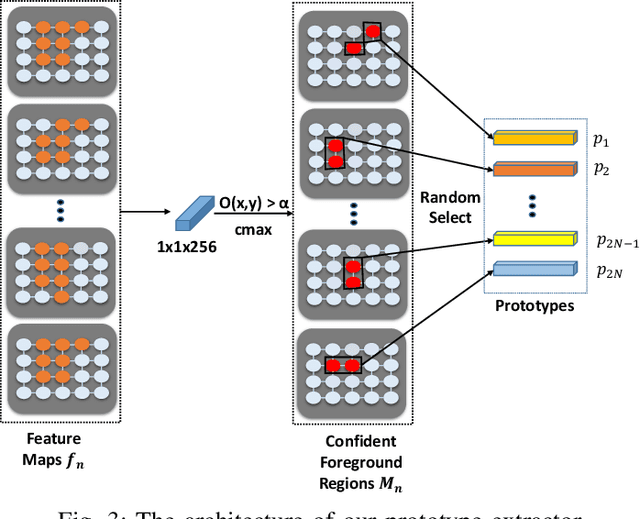
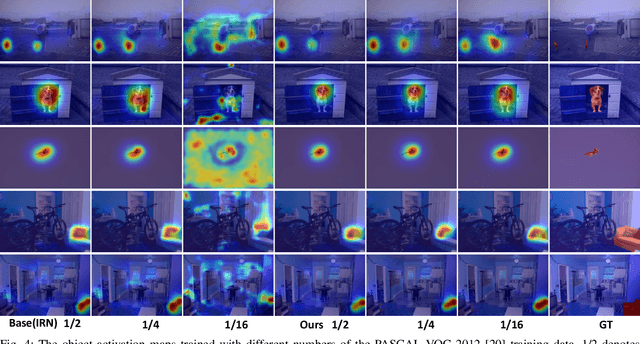
Weakly supervised image segmentation trained with image-level labels usually suffers from inaccurate coverage of object areas during the generation of the pseudo groundtruth. This is because the object activation maps are trained with the classification objective and lack the ability to generalize. To improve the generality of the objective activation maps, we propose a region prototypical network RPNet to explore the cross-image object diversity of the training set. Similar object parts across images are identified via region feature comparison. Object confidence is propagated between regions to discover new object areas while background regions are suppressed. Experiments show that the proposed method generates more complete and accurate pseudo object masks, while achieving state-of-the-art performance on PASCAL VOC 2012 and MS COCO. In addition, we investigate the robustness of the proposed method on reduced training sets.
SHARP: Shape-Aware Reconstruction of People in Loose Clothing
May 24, 2022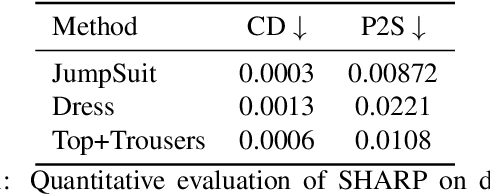
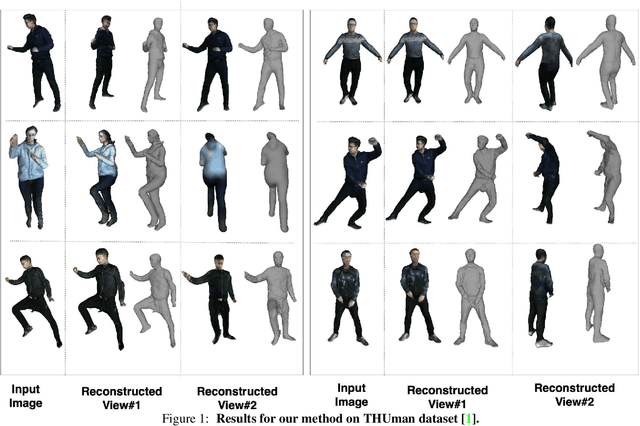
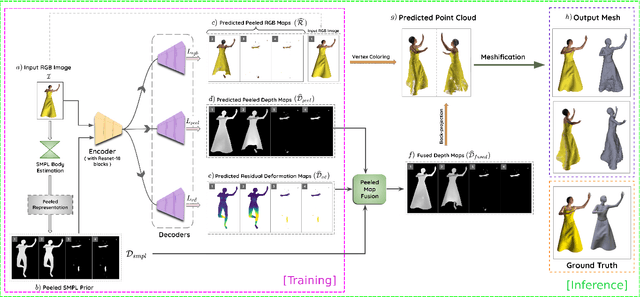
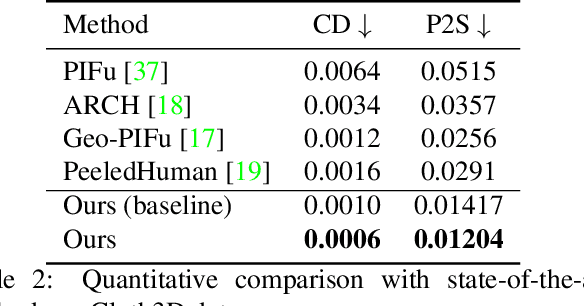
Recent advancements in deep learning have enabled 3D human body reconstruction from a monocular image, which has broad applications in multiple domains. In this paper, we propose SHARP (SHape Aware Reconstruction of People in loose clothing), a novel end-to-end trainable network that accurately recovers the 3D geometry and appearance of humans in loose clothing from a monocular image. SHARP uses a sparse and efficient fusion strategy to combine parametric body prior with a non-parametric 2D representation of clothed humans. The parametric body prior enforces geometrical consistency on the body shape and pose, while the non-parametric representation models loose clothing and handle self-occlusions as well. We also leverage the sparseness of the non-parametric representation for faster training of our network while using losses on 2D maps. Another key contribution is 3DHumans, our new life-like dataset of 3D human body scans with rich geometrical and textural details. We evaluate SHARP on 3DHumans and other publicly available datasets and show superior qualitative and quantitative performance than existing state-of-the-art methods.