 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image-to-Height Domain Translation for Synthetic Aperture Sonar
Dec 12, 2021
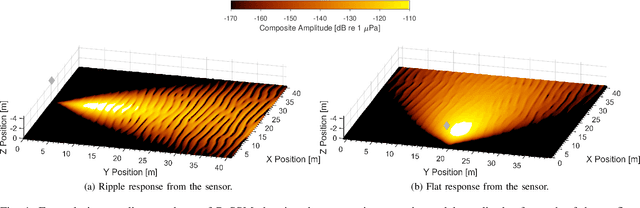


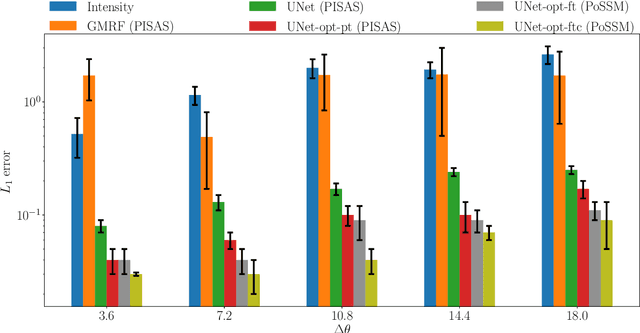
Observations of seabed texture with synthetic aperture sonar are dependent upon several factors. In this work, we focus on collection geometry with respect to isotropic and anisotropic textures. The low grazing angle of the collection geometry, combined with orientation of the sonar path relative to anisotropic texture, poses a significant challenge for image-alignment and other multi-view scene understanding frameworks. We previously proposed using features captured from estimated seabed relief to improve scene understanding. While several methods have been developed to estimate seabed relief via intensity, no large-scale study exists in the literature. Furthermore, a dataset of coregistered seabed relief maps and sonar imagery is nonexistent to learn this domain translation. We address these problems by producing a large simulated dataset containing coregistered pairs of seabed relief and intensity maps from two unique sonar data simulation techniques. We apply three types of models, with varying complexity, to translate intensity imagery to seabed relief: a Gaussian Markov Random Field approach (GMRF), a conditional Generative Adversarial Network (cGAN), and UNet architectures. Methods are compared in reference to the coregistered simulated datasets using L1 error. Additionally, predictions on simulated and real SAS imagery are shown. Finally, models are compared on two datasets of hand-aligned SAS imagery and evaluated in terms of L1 error across multiple aspects in comparison to using intensity. Our comprehensive experiments show that the proposed UNet architectures outperform the GMRF and pix2pix cGAN models on seabed relief estimation for simulated and real SAS imagery.
VisualTextRank: Unsupervised Graph-based Content Extraction for Automating Ad Text to Image Search
Aug 05, 2021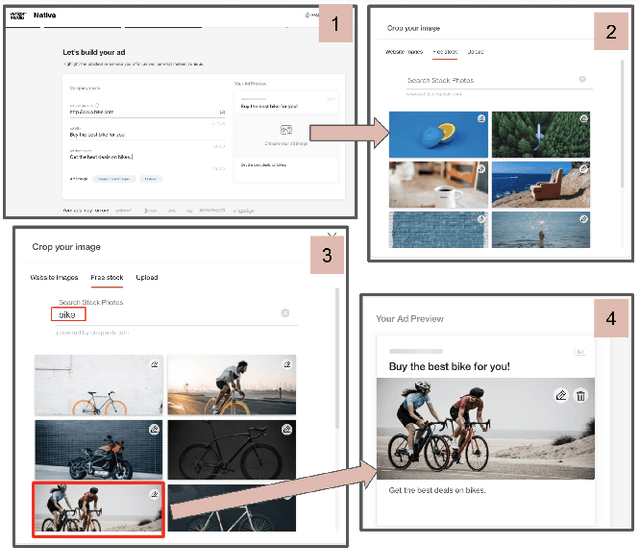
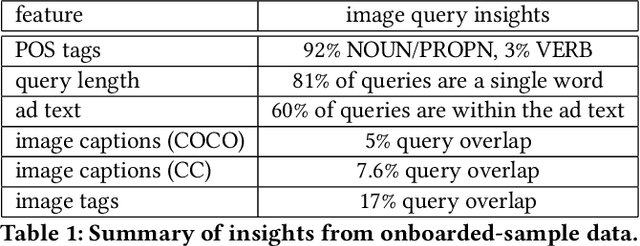
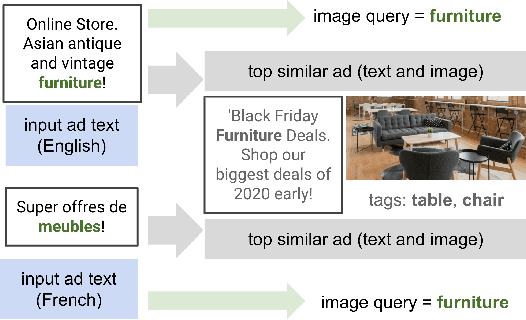
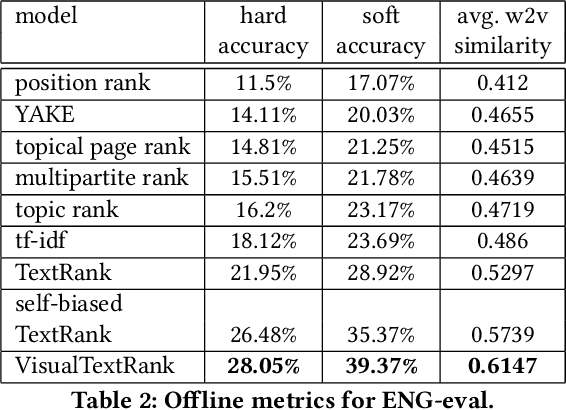
Numerous online stock image libraries offer high quality yet copyright free images for use in marketing campaigns. To assist advertisers in navigating such third party libraries, we study the problem of automatically fetching relevant ad images given the ad text (via a short textual query for images). Motivated by our observations in logged data on ad image search queries (given ad text), we formulate a keyword extraction problem, where a keyword extracted from the ad text (or its augmented version) serves as the ad image query. In this context, we propose VisualTextRank: an unsupervised method to (i) augment input ad text using semantically similar ads, and (ii) extract the image query from the augmented ad text. VisualTextRank builds on prior work on graph based context extraction (biased TextRank in particular) by leveraging both the text and image of similar ads for better keyword extraction, and using advertiser category specific biasing with sentence-BERT embeddings. Using data collected from the Verizon Media Native (Yahoo Gemini) ad platform's stock image search feature for onboarding advertisers, we demonstrate the superiority of VisualTextRank compared to competitive keyword extraction baselines (including an $11\%$ accuracy lift over biased TextRank). For the case when the stock image library is restricted to English queries, we show the effectiveness of VisualTextRank on multilingual ads (translated to English) while leveraging semantically similar English ads. Online tests with a simplified version of VisualTextRank led to a 28.7% increase in the usage of stock image search, and a 41.6% increase in the advertiser onboarding rate in the Verizon Media Native ad platform.
Region-aware Adaptive Instance Normalization for Image Harmonization
Jun 05, 2021
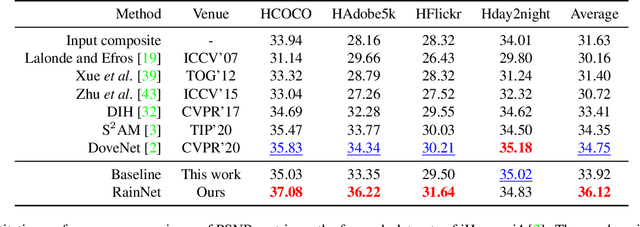
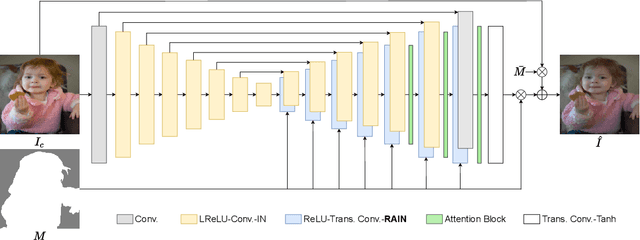
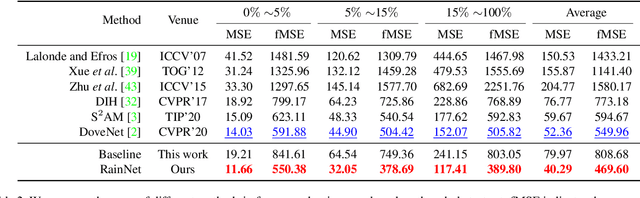
Image composition plays a common but important role in photo editing. To acquire photo-realistic composite images, one must adjust the appearance and visual style of the foreground to be compatible with the background. Existing deep learning methods for harmonizing composite images directly learn an image mapping network from the composite to the real one, without explicit exploration on visual style consistency between the background and the foreground images. To ensure the visual style consistency between the foreground and the background, in this paper, we treat image harmonization as a style transfer problem. In particular, we propose a simple yet effective Region-aware Adaptive Instance Normalization (RAIN) module, which explicitly formulates the visual style from the background and adaptively applies them to the foreground. With our settings, our RAIN module can be used as a drop-in module for existing image harmonization networks and is able to bring significant improvements. Extensive experiments on the existing image harmonization benchmark datasets show the superior capability of the proposed method. Code is available at {https://github.com/junleen/RainNet}.
A Comparative Study of Confidence Calibration in Deep Learning: From Computer Vision to Medical Imaging
Jun 17, 2022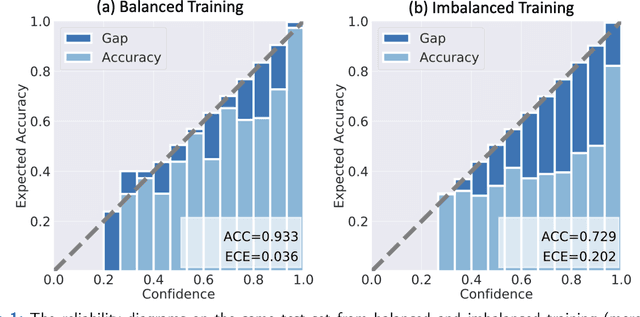
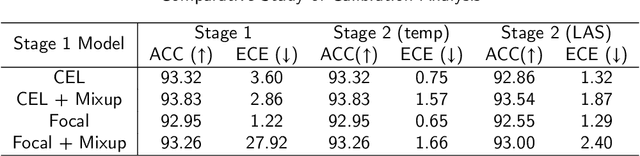
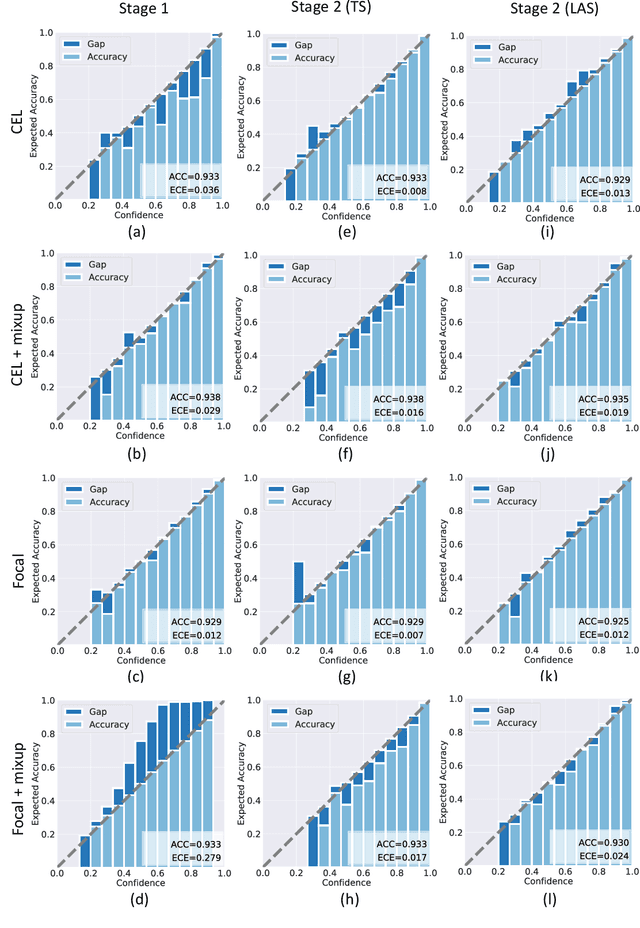
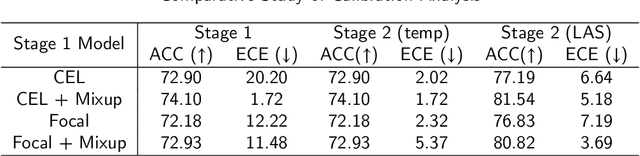
Although deep learning prediction models have been successful in the discrimination of different classes, they can often suffer from poor calibration across challenging domains including healthcare. Moreover, the long-tail distribution poses great challenges in deep learning classification problems including clinical disease prediction. There are approaches proposed recently to calibrate deep prediction in computer vision, but there are no studies found to demonstrate how the representative models work in different challenging contexts. In this paper, we bridge the confidence calibration from computer vision to medical imaging with a comparative study of four high-impact calibration models. Our studies are conducted in different contexts (natural image classification and lung cancer risk estimation) including in balanced vs. imbalanced training sets and in computer vision vs. medical imaging. Our results support key findings: (1) We achieve new conclusions which are not studied under different learning contexts, e.g., combining two calibration models that both mitigate the overconfident prediction can lead to under-confident prediction, and simpler calibration models from the computer vision domain tend to be more generalizable to medical imaging. (2) We highlight the gap between general computer vision tasks and medical imaging prediction, e.g., calibration methods ideal for general computer vision tasks may in fact damage the calibration of medical imaging prediction. (3) We also reinforce previous conclusions in natural image classification settings. We believe that this study has merits to guide readers to choose calibration models and understand gaps between general computer vision and medical imaging domains.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022



This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
Continuous wavelet transform of multiview images using wavelets based on voxel patterns
May 12, 2022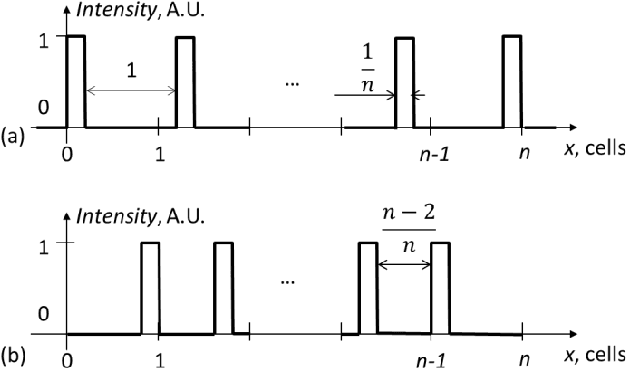
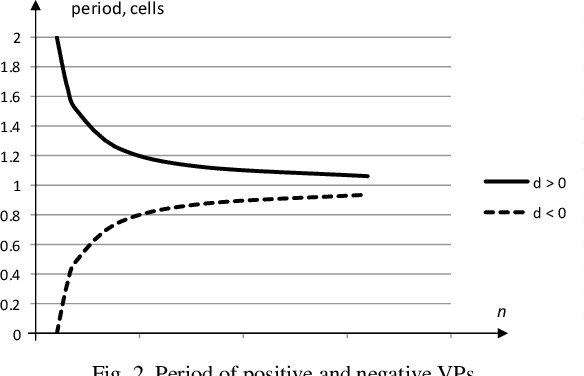
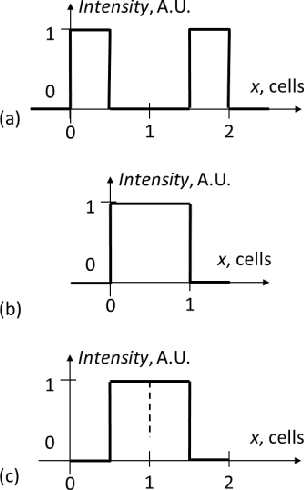
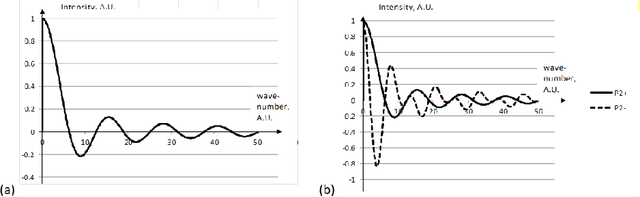
We propose the multiview wavelets based on voxel patterns of autostereoscopic multiview displays. Direct and inverse continuous wavelet transforms of binary and gray-scale images were performed. The input to the inverse wavelet transform was the array of wavelet coefficients of the direct transform. A restored image reproduces the structure of the multiview image correctly. Also, we modified the dimension of the parallax and the depth of 3D images. The restored and modified images were displayed in 3D using lenticular plates. In each case, the visual 3D picture corresponds to the applied modifications. The results can be applied to the autostereoscopic 3D displays.
Exploring Generative Neural Temporal Point Process
Aug 04, 2022
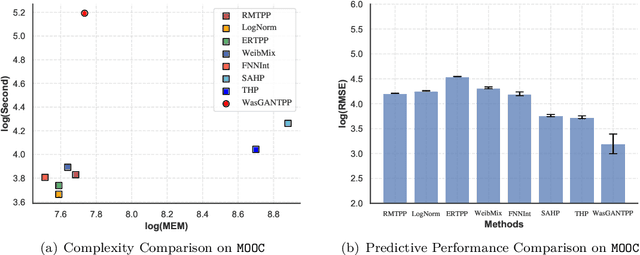
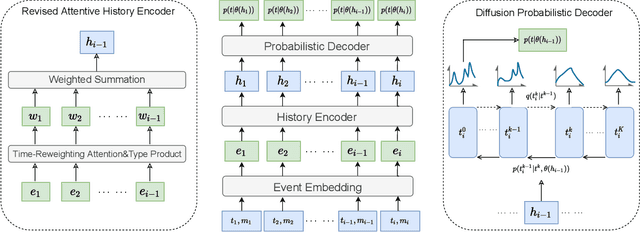

Temporal point process (TPP) is commonly used to model the asynchronous event sequence featuring occurrence timestamps and revealed by probabilistic models conditioned on historical impacts. While lots of previous works have focused on `goodness-of-fit' of TPP models by maximizing the likelihood, their predictive performance is unsatisfactory, which means the timestamps generated by models are far apart from true observations. Recently, deep generative models such as denoising diffusion and score matching models have achieved great progress in image generating tasks by demonstrating their capability of generating samples of high quality. However, there are no complete and unified works exploring and studying the potential of generative models in the context of event occurence modeling for TPP. In this work, we try to fill the gap by designing a unified \textbf{g}enerative framework for \textbf{n}eural \textbf{t}emporal \textbf{p}oint \textbf{p}rocess (\textsc{GNTPP}) model to explore their feasibility and effectiveness, and further improve models' predictive performance. Besides, in terms of measuring the historical impacts, we revise the attentive models which summarize influence from historical events with an adaptive reweighting term considering events' type relation and time intervals. Extensive experiments have been conducted to illustrate the improved predictive capability of \textsc{GNTPP} with a line of generative probabilistic decoders, and performance gain from the revised attention. To the best of our knowledge, this is the first work that adapts generative models in a complete unified framework and studies their effectiveness in the context of TPP. Our codebase including all the methods given in Section.5.1.1 is open in \url{https://github.com/BIRD-TAO/GNTPP}. We hope the code framework can facilitate future research in Neural TPPs.
3D-Aware Video Generation
Jun 29, 2022
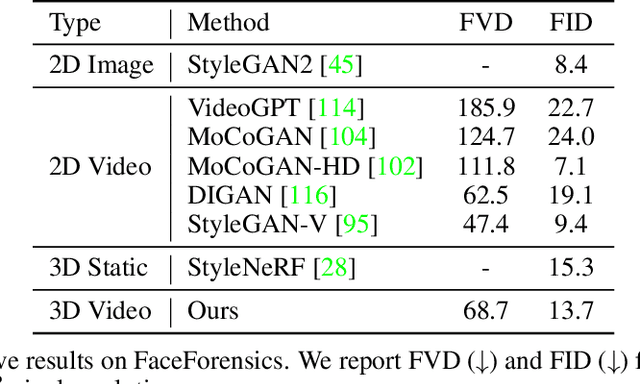
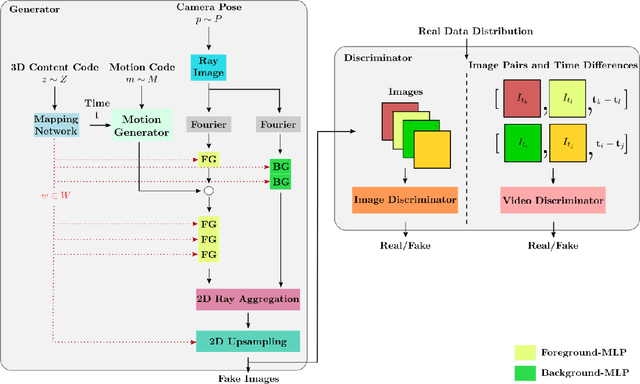

Generative models have emerged as an essential building block for many image synthesis and editing tasks. Recent advances in this field have also enabled high-quality 3D or video content to be generated that exhibits either multi-view or temporal consistency. With our work, we explore 4D generative adversarial networks (GANs) that learn unconditional generation of 3D-aware videos. By combining neural implicit representations with time-aware discriminator, we develop a GAN framework that synthesizes 3D video supervised only with monocular videos. We show that our method learns a rich embedding of decomposable 3D structures and motions that enables new visual effects of spatio-temporal renderings while producing imagery with quality comparable to that of existing 3D or video GANs.
Improving Deep Neural Network Random Initialization Through Neuronal Rewiring
Jul 17, 2022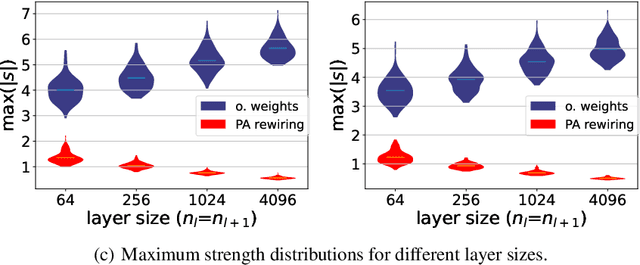
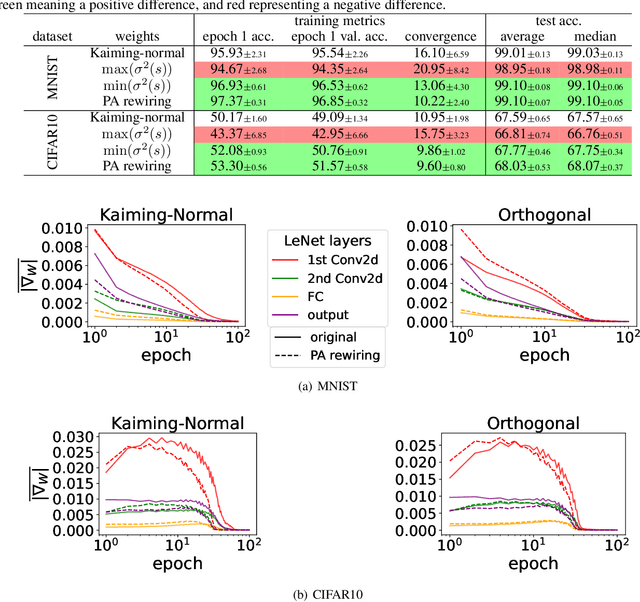
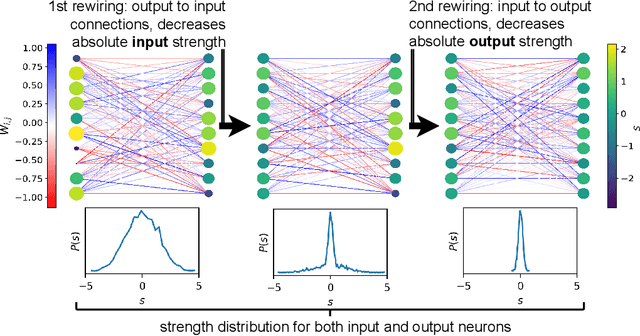
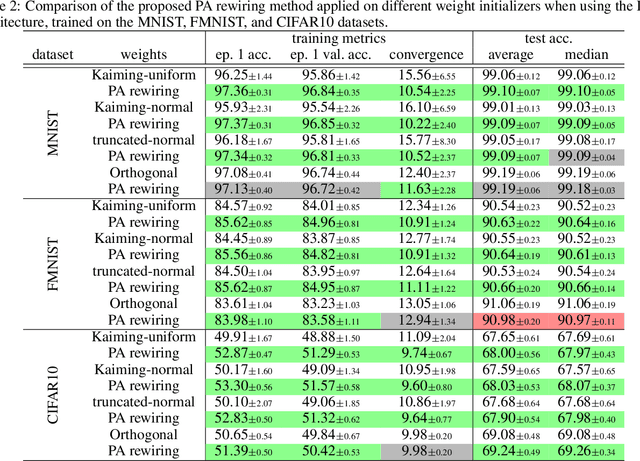
The deep learning literature is continuously updated with new architectures and training techniques. However, weight initialization is overlooked by most recent research, despite some intriguing findings regarding random weights. On the other hand, recent works have been approaching Network Science to understand the structure and dynamics of Artificial Neural Networks (ANNs) after training. Therefore, in this work, we analyze the centrality of neurons in randomly initialized networks. We show that a higher neuronal strength variance may decrease performance, while a lower neuronal strength variance usually improves it. A new method is then proposed to rewire neuronal connections according to a preferential attachment (PA) rule based on their strength, which significantly reduces the strength variance of layers initialized by common methods. In this sense, PA rewiring only reorganizes connections, while preserving the magnitude and distribution of the weights. We show through an extensive statistical analysis in image classification that performance is improved in most cases, both during training and testing, when using both simple and complex architectures and learning schedules. Our results show that, aside from the magnitude, the organization of the weights is also relevant for better initialization of deep ANNs.
ReMix: Towards Image-to-Image Translation with Limited Data
Mar 31, 2021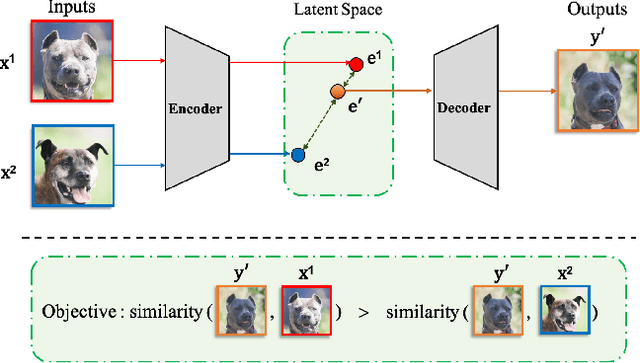
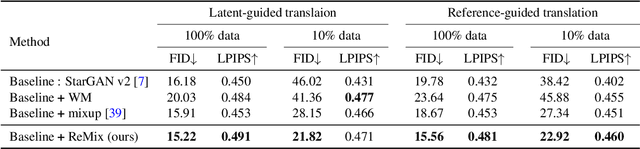
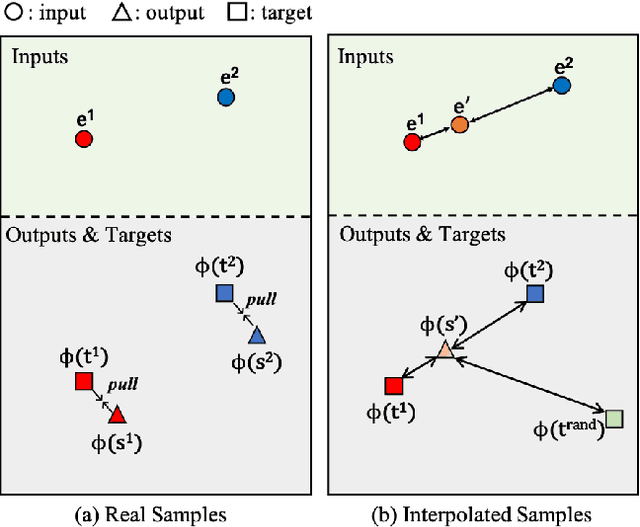
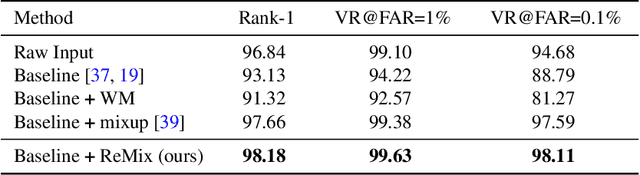
Image-to-image (I2I) translation methods based on generative adversarial networks (GANs) typically suffer from overfitting when limited training data is available. In this work, we propose a data augmentation method (ReMix) to tackle this issue. We interpolate training samples at the feature level and propose a novel content loss based on the perceptual relations among samples. The generator learns to translate the in-between samples rather than memorizing the training set, and thereby forces the discriminator to generalize. The proposed approach effectively reduces the ambiguity of generation and renders content-preserving results. The ReMix method can be easily incorporated into existing GAN models with minor modifications. Experimental results on numerous tasks demonstrate that GAN models equipped with the ReMix method achieve significant improvements.