 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-supervised High-fidelity and Re-renderable 3D Facial Reconstruction from a Single Image
Nov 16, 2021
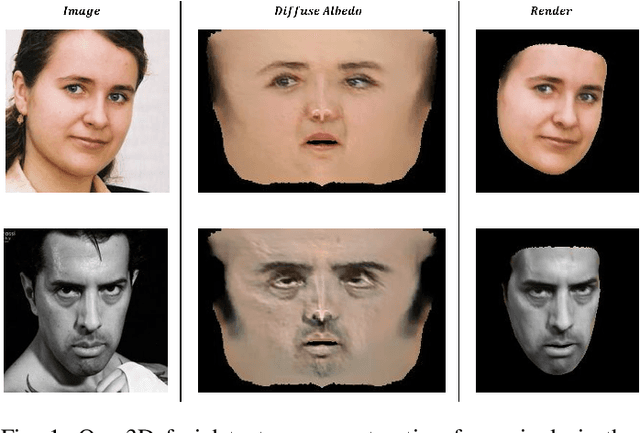

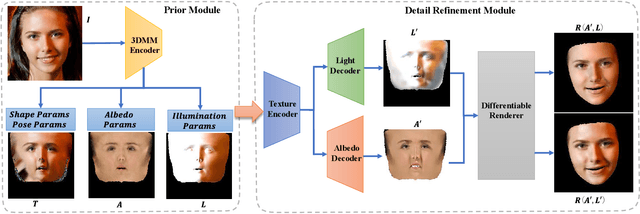

Reconstructing high-fidelity 3D facial texture from a single image is a challenging task since the lack of complete face information and the domain gap between the 3D face and 2D image. The most recent works tackle facial texture reconstruction problem by applying either generation-based or reconstruction-based methods. Although each method has its own advantage, none of them is capable of recovering a high-fidelity and re-renderable facial texture, where the term 're-renderable' demands the facial texture to be spatially complete and disentangled with environmental illumination. In this paper, we propose a novel self-supervised learning framework for reconstructing high-quality 3D faces from single-view images in-the-wild. Our main idea is to first utilize the prior generation module to produce a prior albedo, then leverage the detail refinement module to obtain detailed albedo. To further make facial textures disentangled with illumination, we present a novel detailed illumination representation which is reconstructed with the detailed albedo together. We also design several regularization loss functions on both the albedo side and illumination side to facilitate the disentanglement of these two factors. Finally, thanks to the differentiable rendering technique, our neural network can be efficiently trained in a self-supervised manner. Extensive experiments on challenging datasets demonstrate that our framework substantially outperforms state-of-the-art approaches in both qualitative and quantitative comparisons.
TBNet:Two-Stream Boundary-aware Network for Generic Image Manipulation Localization
Aug 10, 2021

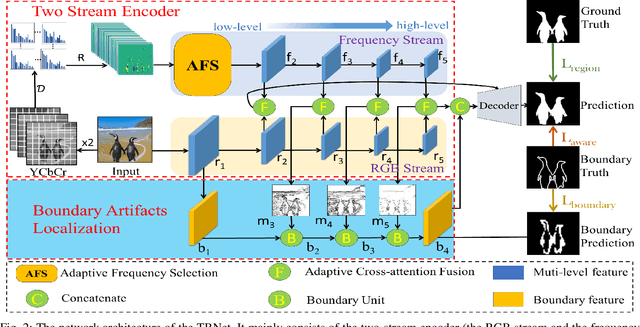
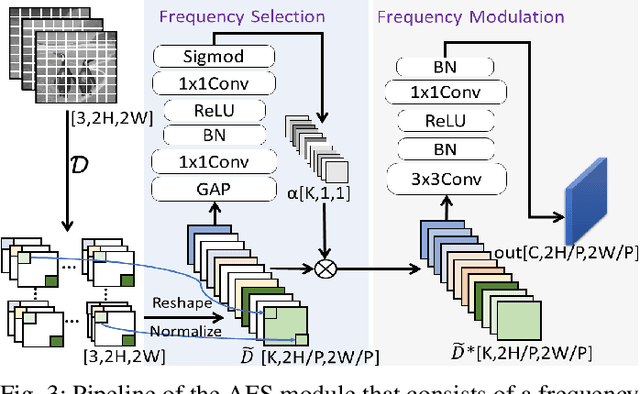
Finding tampered regions in images is a hot research topic in machine learning and computer vision. Although many image manipulation location algorithms have been proposed, most of them only focus on the RGB images with different color spaces, and the frequency information that contains the potential tampering clues is often ignored. In this work, a novel end-to-end two-stream boundary-aware network (abbreviated as TBNet) is proposed for generic image manipulation localization in which the RGB stream, the frequency stream, and the boundary artifact location are explored in a unified framework. Specifically, we first design an adaptive frequency selection module (AFS) to adaptively select the appropriate frequency to mine inconsistent statistics and eliminate the interference of redundant statistics. Then, an adaptive cross-attention fusion module (ACF) is proposed to adaptively fuse the RGB feature and the frequency feature. Finally, the boundary artifact location network (BAL) is designed to locate the boundary artifacts for which the parameters are jointly updated by the outputs of the ACF, and its results are further fed into the decoder. Thus, the parameters of the RGB stream, the frequency stream, and the boundary artifact location network are jointly optimized, and their latent complementary relationships are fully mined. The results of extensive experiments performed on four public benchmarks of the image manipulation localization task, namely, CASIA1.0, COVER, Carvalho, and In-The-Wild, demonstrate that the proposed TBNet can significantly outperform state-of-the-art generic image manipulation localization methods in terms of both MCC and F1.
Uncovering bias in the PlantVillage dataset
Jun 09, 2022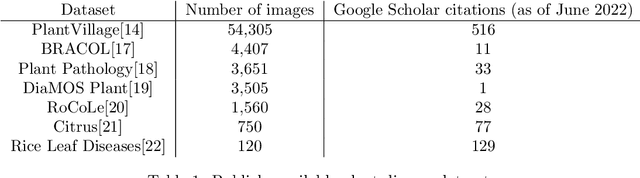



We report our investigation on the use of the popular PlantVillage dataset for training deep learning based plant disease detection models. We trained a machine learning model using only 8 pixels from the PlantVillage image backgrounds. The model achieved 49.0% accuracy on the held-out test set, well above the random guessing accuracy of 2.6%. This result indicates that the PlantVillage dataset contains noise correlated with the labels and deep learning models can easily exploit this bias to make predictions. Possible approaches to alleviate this problem are discussed.
BlobGAN: Spatially Disentangled Scene Representations
May 05, 2022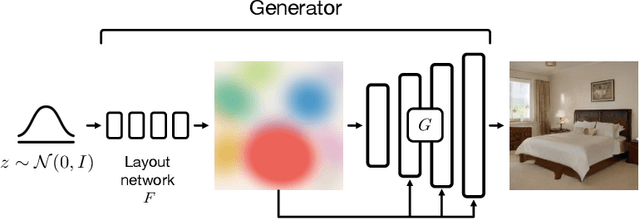
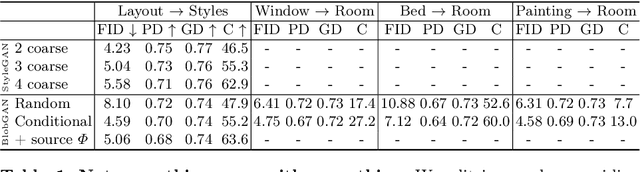
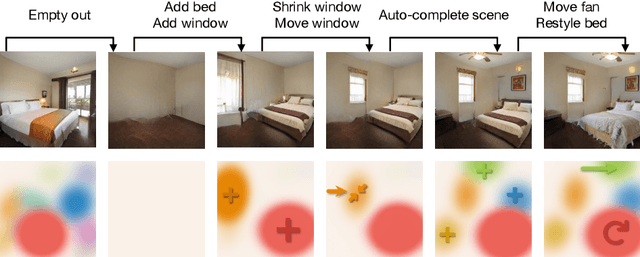
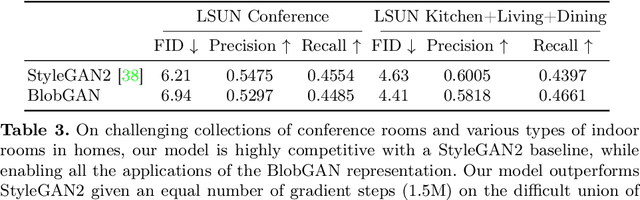
We propose an unsupervised, mid-level representation for a generative model of scenes. The representation is mid-level in that it is neither per-pixel nor per-image; rather, scenes are modeled as a collection of spatial, depth-ordered "blobs" of features. Blobs are differentiably placed onto a feature grid that is decoded into an image by a generative adversarial network. Due to the spatial uniformity of blobs and the locality inherent to convolution, our network learns to associate different blobs with different entities in a scene and to arrange these blobs to capture scene layout. We demonstrate this emergent behavior by showing that, despite training without any supervision, our method enables applications such as easy manipulation of objects within a scene (e.g., moving, removing, and restyling furniture), creation of feasible scenes given constraints (e.g., plausible rooms with drawers at a particular location), and parsing of real-world images into constituent parts. On a challenging multi-category dataset of indoor scenes, BlobGAN outperforms StyleGAN2 in image quality as measured by FID. See our project page for video results and interactive demo: http://www.dave.ml/blobgan
Measuring Forgetting of Memorized Training Examples
Jun 30, 2022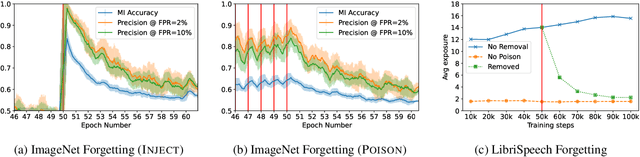
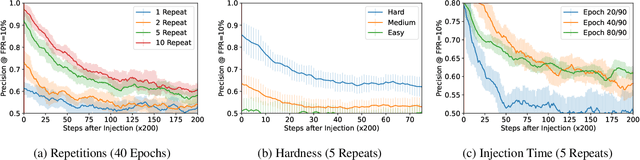
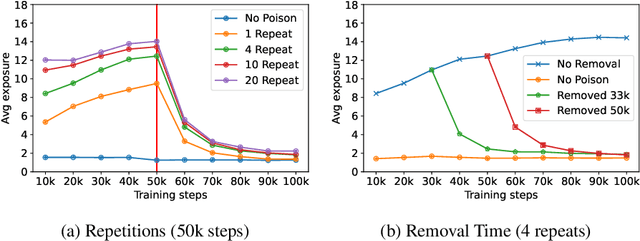
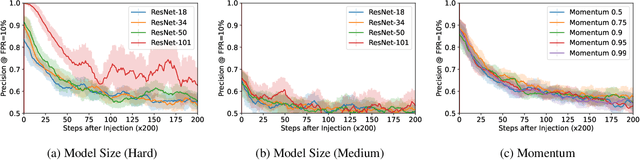
Machine learning models exhibit two seemingly contradictory phenomena: training data memorization and various forms of forgetting. In memorization, models overfit specific training examples and become susceptible to privacy attacks. In forgetting, examples which appeared early in training are forgotten by the end. In this work, we connect these phenomena. We propose a technique to measure to what extent models ``forget'' the specifics of training examples, becoming less susceptible to privacy attacks on examples they have not seen recently. We show that, while non-convexity can prevent forgetting from happening in the worst-case, standard image and speech models empirically do forget examples over time. We identify nondeterminism as a potential explanation, showing that deterministically trained models do not forget. Our results suggest that examples seen early when training with extremely large datasets -- for instance those examples used to pre-train a model -- may observe privacy benefits at the expense of examples seen later.
A machine learning based approach to gravitational lens identification with the International LOFAR Telescope
Jul 21, 2022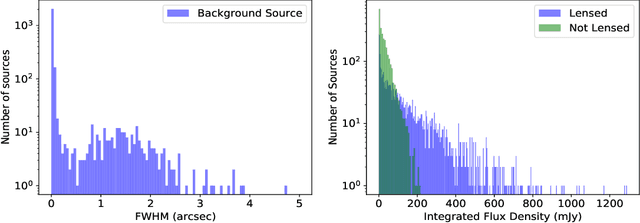

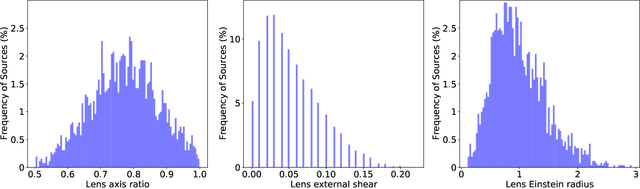
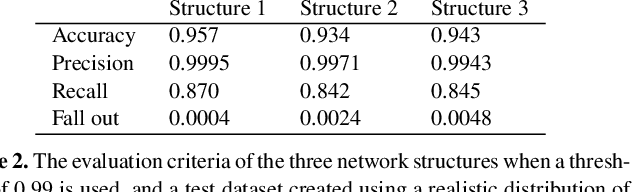
We present a novel machine learning based approach for detecting galaxy-scale gravitational lenses from interferometric data, specifically those taken with the International LOFAR Telescope (ILT), which is observing the northern radio sky at a frequency of 150 MHz, an angular resolution of 350 mas and a sensitivity of 90 uJy beam-1 (1 sigma). We develop and test several Convolutional Neural Networks to determine the probability and uncertainty of a given sample being classified as a lensed or non-lensed event. By training and testing on a simulated interferometric imaging data set that includes realistic lensed and non-lensed radio sources, we find that it is possible to recover 95.3 per cent of the lensed samples (true positive rate), with a contamination of just 0.008 per cent from non-lensed samples (false positive rate). Taking the expected lensing probability into account results in a predicted sample purity for lensed events of 92.2 per cent. We find that the network structure is most robust when the maximum image separation between the lensed images is greater than 3 times the synthesized beam size, and the lensed images have a total flux density that is equivalent to at least a 20 sigma (point-source) detection. For the ILT, this corresponds to a lens sample with Einstein radii greater than 0.5 arcsec and a radio source population with 150 MHz flux densities more than 2 mJy. By applying these criteria and our lens detection algorithm we expect to discover the vast majority of galaxy-scale gravitational lens systems contained within the LOFAR Two Metre Sky Survey.
Augmented Imagefication: A Data-driven Fault Detection Method for Aircraft Air Data Sensors
Jun 18, 2022
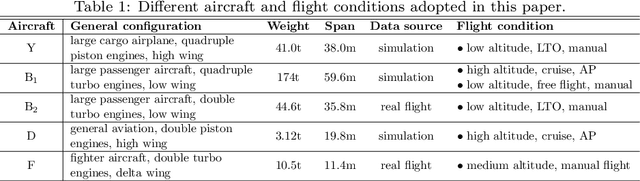
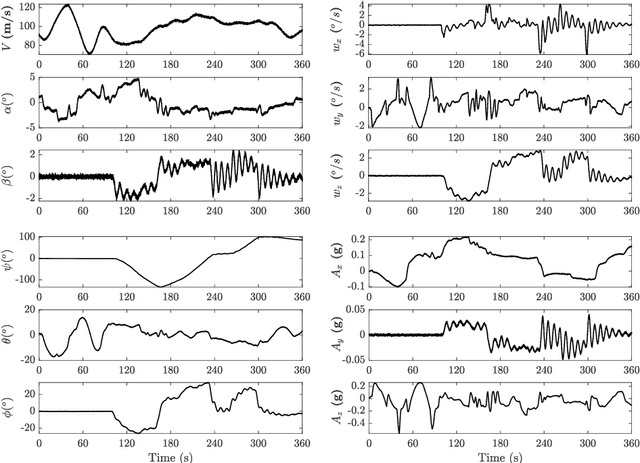

In this paper, a novel data-driven approach named Augmented Imagefication for Fault detection (FD) of aircraft air data sensors (ADS) is proposed. Exemplifying the FD problem of aircraft air data sensors, an online FD scheme on edge device based on deep neural network (DNN) is developed. First, the aircraft inertial reference unit measurements is adopted as equivalent inputs, which is scalable to different aircraft/flight cases. Data associated with 6 different aircraft/flight conditions are collected to provide diversity (scalability) in the training/testing database. Then Augmented Imagefication is proposed for the DNN-based prediction of flying conditions. The raw data are reshaped as a grayscale image for convolutional operation, and the necessity of augmentation is analyzed and pointed out. Different kinds of augmented method, i.e. Flip, Repeat, Tile and their combinations are discussed, the result shows that the All Repeat operation in both axes of image matrix leads to the best performance of DNN. The interpretability of DNN is studied based on Grad-CAM, which provide a better understanding and further solidifies the robustness of DNN. Next the DNN model, VGG-16 with augmented imagefication data is optimized for mobile hardware deployment. After pruning of DNN, a lightweight model (98.79% smaller than original VGG-16) with high accuracy (slightly up by 0.27%) and fast speed (time delay is reduced by 87.54%) is obtained. And the hyperparameters optimization of DNN based on TPE is implemented and the best combination of hyperparameters is determined (learning rate 0.001, iterative epochs 600, and batch size 100 yields the highest accuracy at 0.987). Finally, a online FD deployment based on edge device, Jetson Nano, is developed and the real time monitoring of aircraft is achieved. We believe that this method is instructive for addressing the FD problems in other similar fields.
Learning to Disentangle GAN Fingerprint for Fake Image Attribution
Jun 16, 2021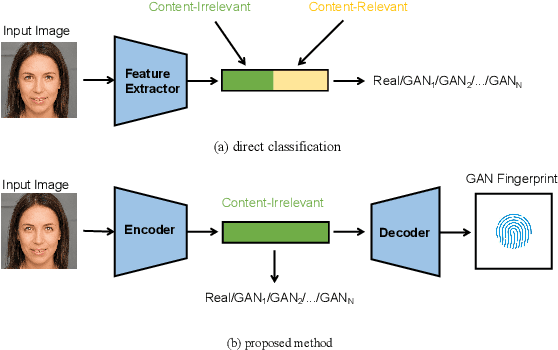
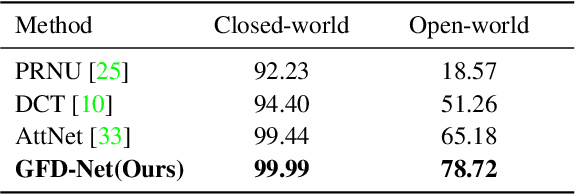
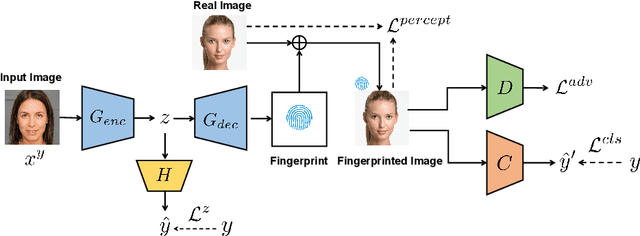

Rapid pace of generative models has brought about new threats to visual forensics such as malicious personation and digital copyright infringement, which promotes works on fake image attribution. Existing works on fake image attribution mainly rely on a direct classification framework. Without additional supervision, the extracted features could include many content-relevant components and generalize poorly. Meanwhile, how to obtain an interpretable GAN fingerprint to explain the decision remains an open question. Adopting a multi-task framework, we propose a GAN Fingerprint Disentangling Network (GFD-Net) to simultaneously disentangle the fingerprint from GAN-generated images and produce a content-irrelevant representation for fake image attribution. A series of constraints are provided to guarantee the stability and discriminability of the fingerprint, which in turn helps content-irrelevant feature extraction. Further, we perform comprehensive analysis on GAN fingerprint, providing some clues about the properties of GAN fingerprint and which factors dominate the fingerprint in GAN architecture. Experiments show that our GFD-Net achieves superior fake image attribution performance in both closed-world and open-world testing. We also apply our method in binary fake image detection and exhibit a significant generalization ability on unseen generators.
Cross-View Language Modeling: Towards Unified Cross-Lingual Cross-Modal Pre-training
Jun 01, 2022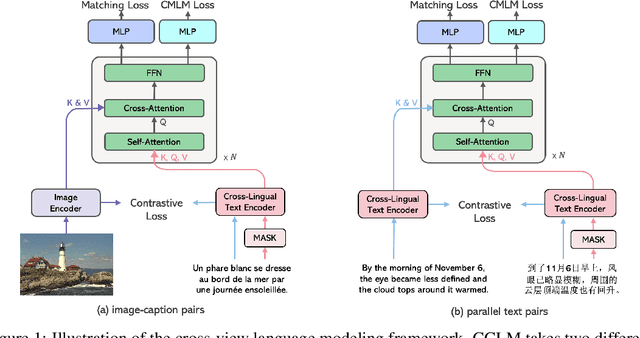
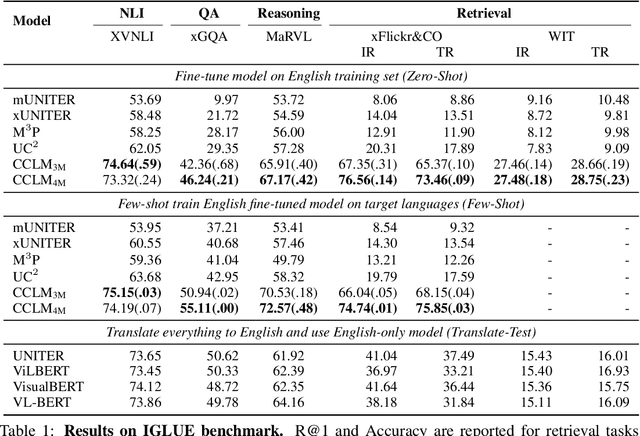
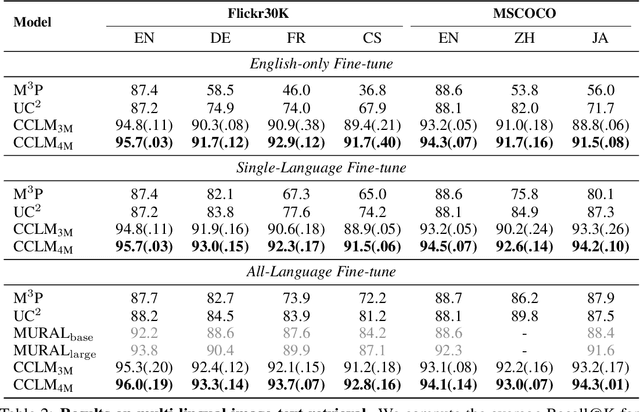
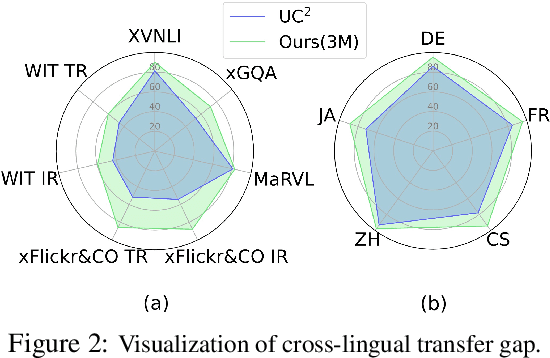
In this paper, we introduce Cross-View Language Modeling, a simple and effective language model pre-training framework that unifies cross-lingual cross-modal pre-training with shared architectures and objectives. Our approach is motivated by a key observation that cross-lingual and cross-modal pre-training share the same goal of aligning two different views of the same object into a common semantic space. To this end, the cross-view language modeling framework considers both multi-modal data (i.e., image-caption pairs) and multi-lingual data (i.e., parallel sentence pairs) as two different views of the same object, and trains the model to align the two views by maximizing the mutual information between them with conditional masked language modeling and contrastive learning. We pre-train CCLM, a Cross-lingual Cross-modal Language Model, with the cross-view language modeling framework. Empirical results on IGLUE, a multi-lingual multi-modal benchmark, and two multi-lingual image-text retrieval datasets show that while conceptually simpler, CCLM significantly outperforms the prior state-of-the-art with an average absolute improvement of over 10%. Notably, CCLM is the first multi-lingual multi-modal model that surpasses the translate-test performance of representative English vision-language models by zero-shot cross-lingual transfer.
Hyperspectral Pansharpening Based on Improved Deep Image Prior and Residual Reconstruction
Jul 06, 2021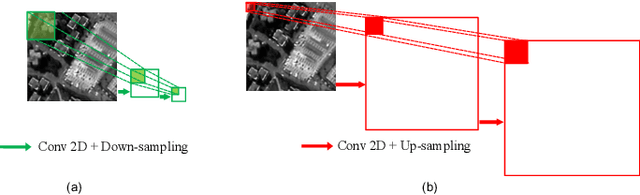


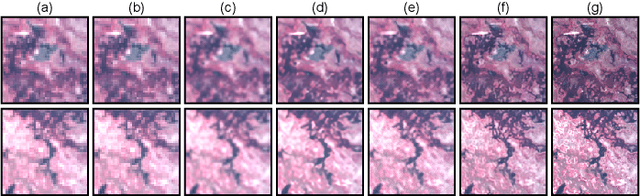
Hyperspectral pansharpening aims to synthesize a low-resolution hyperspectral image (LR-HSI) with a registered panchromatic image (PAN) to generate an enhanced HSI with high spectral and spatial resolution. Recently proposed HS pansharpening methods have obtained remarkable results using deep convolutional networks (ConvNets), which typically consist of three steps: (1) up-sampling the LR-HSI, (2) predicting the residual image via a ConvNet, and (3) obtaining the final fused HSI by adding the outputs from first and second steps. Recent methods have leveraged Deep Image Prior (DIP) to up-sample the LR-HSI due to its excellent ability to preserve both spatial and spectral information, without learning from large data sets. However, we observed that the quality of up-sampled HSIs can be further improved by introducing an additional spatial-domain constraint to the conventional spectral-domain energy function. We define our spatial-domain constraint as the $L_1$ distance between the predicted PAN image and the actual PAN image. To estimate the PAN image of the up-sampled HSI, we also propose a learnable spectral response function (SRF). Moreover, we noticed that the residual image between the up-sampled HSI and the reference HSI mainly consists of edge information and very fine structures. In order to accurately estimate fine information, we propose a novel over-complete network, called HyperKite, which focuses on learning high-level features by constraining the receptive from increasing in the deep layers. We perform experiments on three HSI datasets to demonstrate the superiority of our DIP-HyperKite over the state-of-the-art pansharpening methods. The deployment codes, pre-trained models, and final fusion outputs of our DIP-HyperKite and the methods used for the comparisons will be publicly made available at https://github.com/wgcban/DIP-HyperKite.git.