 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Geometric Moment
May 24, 2022
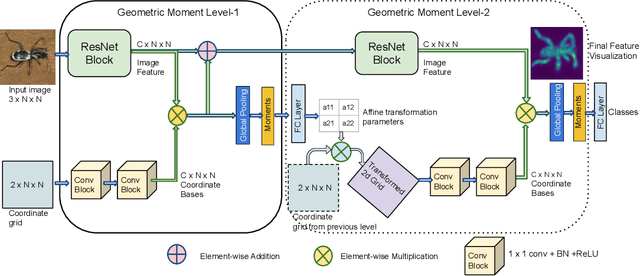


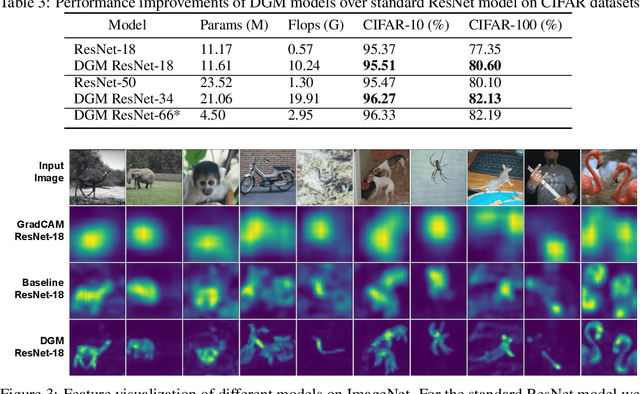
Deep networks for image classification often rely more on texture information than object shape. While efforts have been made to make deep-models shape-aware, it is often difficult to make such models simple, interpretable, or rooted in known mathematical definitions of shape. This paper presents a deep-learning model inspired by geometric moments, a classically well understood approach to measure shape-related properties. The proposed method consists of a trainable network for generating coordinate bases and affine parameters for making the features geometrically invariant, yet in a task-specific manner. The proposed model improves the final feature's interpretation. We demonstrate the effectiveness of our method on standard image classification datasets. The proposed model achieves higher classification performance as compared to the baseline and standard ResNet models while substantially improving interpretability.
Improvement of image classification by multiple optical scattering
Jul 12, 2021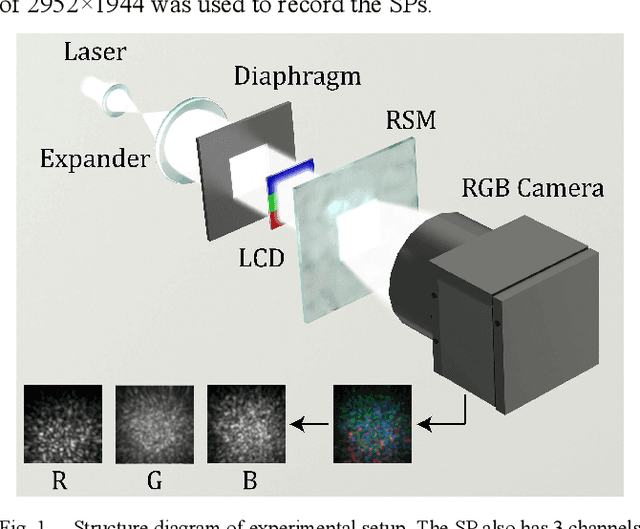
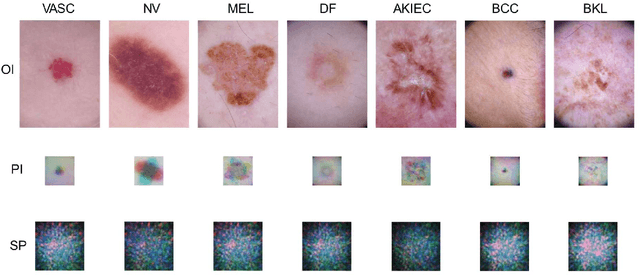
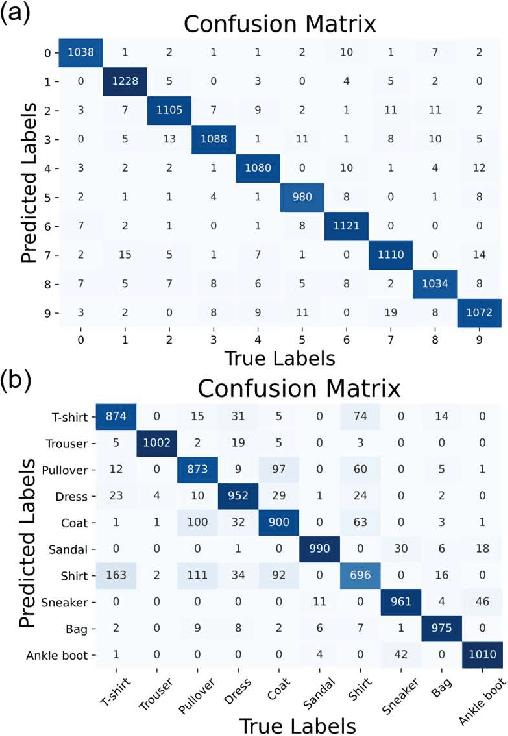
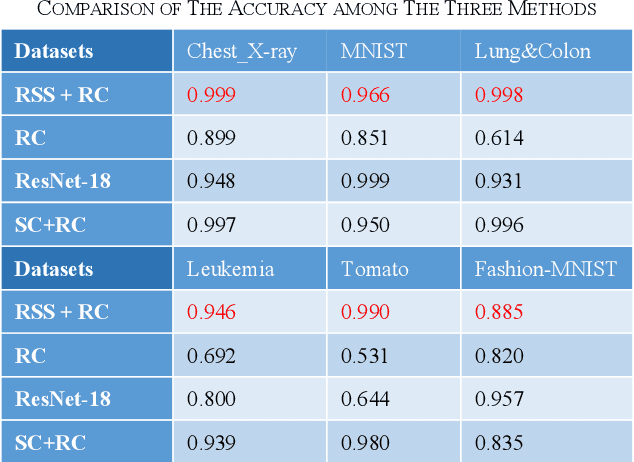
Multiple optical scattering occurs when light propagates in a non-uniform medium. During the multiple scattering, images were distorted and the spatial information they carried became scrambled. However, the image information is not lost but presents in the form of speckle patterns (SPs). In this study, we built up an optical random scattering system based on an LCD and an RGB laser source. We found that the image classification can be improved by the help of random scattering which is considered as a feedforward neural network to extracts features from image. Along with the ridge classification deployed on computer, we achieved excellent classification accuracy higher than 94%, for a variety of data sets covering medical, agricultural, environmental protection and other fields. In addition, the proposed optical scattering system has the advantages of high speed, low power consumption, and miniaturization, which is suitable for deploying in edge computing applications.
RHA-Net: An Encoder-Decoder Network with Residual Blocks and Hybrid Attention Mechanisms for Pavement Crack Segmentation
Jul 28, 2022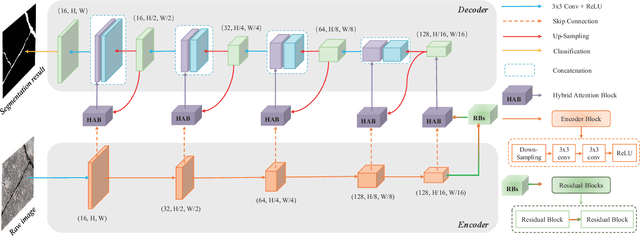

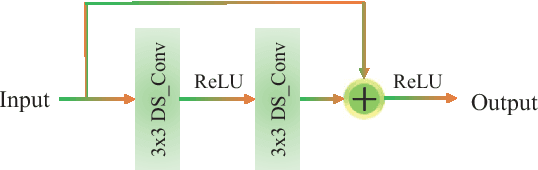
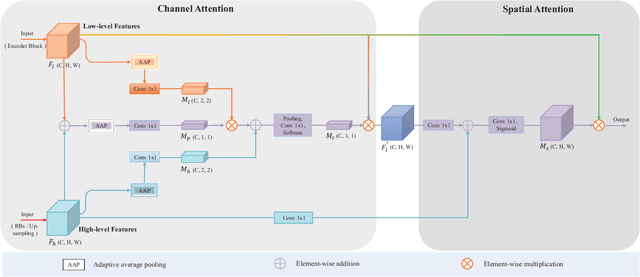
The acquisition and evaluation of pavement surface data play an essential role in pavement condition evaluation. In this paper, an efficient and effective end-to-end network for automatic pavement crack segmentation, called RHA-Net, is proposed to improve the pavement crack segmentation accuracy. The RHA-Net is built by integrating residual blocks (ResBlocks) and hybrid attention blocks into the encoder-decoder architecture. The ResBlocks are used to improve the ability of RHA-Net to extract high-level abstract features. The hybrid attention blocks are designed to fuse both low-level features and high-level features to help the model focus on correct channels and areas of cracks, thereby improving the feature presentation ability of RHA-Net. An image data set containing 789 pavement crack images collected by a self-designed mobile robot is constructed and used for training and evaluating the proposed model. Compared with other state-of-the-art networks, the proposed model achieves better performance and the functionalities of adding residual blocks and hybrid attention mechanisms are validated in a comprehensive ablation study. Additionally, a light-weighted version of the model generated by introducing depthwise separable convolution achieves better a performance and a much faster processing speed with 1/30 of the number of U-Net parameters. The developed system can segment pavement crack in real-time on an embedded device Jetson TX2 (25 FPS). The video taken in real-time experiments is released at https://youtu.be/3XIogk0fiG4.
Pyramid Transformer for Traffic Sign Detection
Jul 22, 2022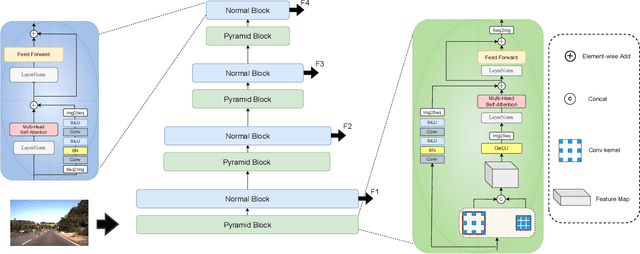
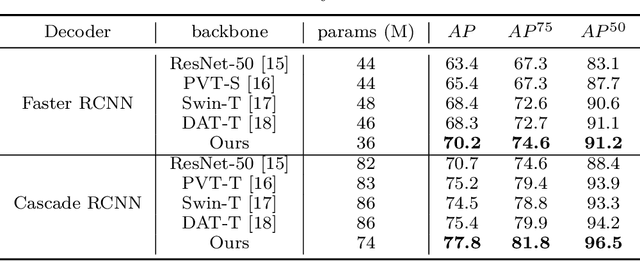
Traffic sign detection is a vital task in the visual system of self-driving cars and the automated driving system. Recently, novel Transformer-based models have achieved encouraging results for various computer vision tasks. We still observed that vanilla ViT could not yield satisfactory results in traffic sign detection because the overall size of the datasets is very small and the class distribution of traffic signs is extremely unbalanced. To overcome this problem, a novel Pyramid Transformer with locality mechanisms is proposed in this paper. Specifically, Pyramid Transformer has several spatial pyramid reduction layers to shrink and embed the input image into tokens with rich multi-scale context by using atrous convolutions. Moreover, it inherits an intrinsic scale invariance inductive bias and is able to learn local feature representation for objects at various scales, thereby enhancing the network robustness against the size discrepancy of traffic signs. The experiments are conducted on the German Traffic Sign Detection Benchmark (GTSDB). The results demonstrate the superiority of the proposed model in the traffic sign detection tasks. More specifically, Pyramid Transformer achieves 77.8% mAP on GTSDB when applied to the Cascade RCNN as the backbone, which surpasses most well-known and widely-used state-of-the-art models.
Deep Fusion Prior for Multi-Focus Image Super Resolution Fusion
Oct 12, 2021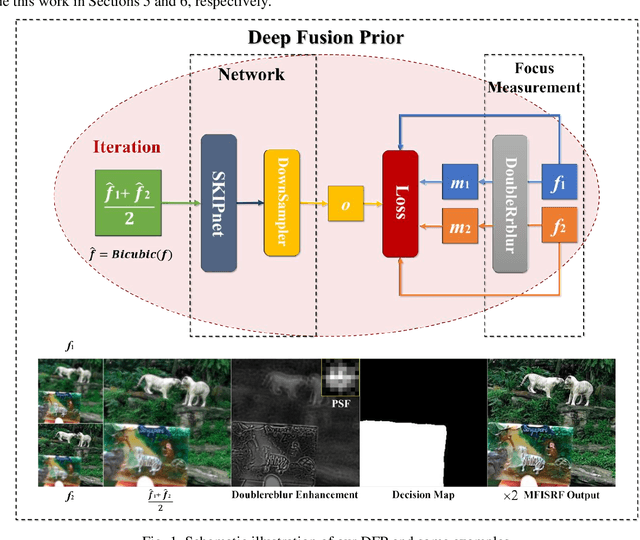
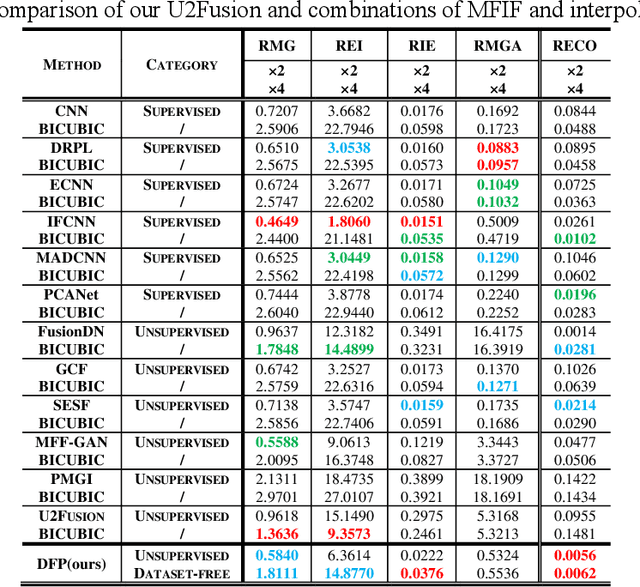
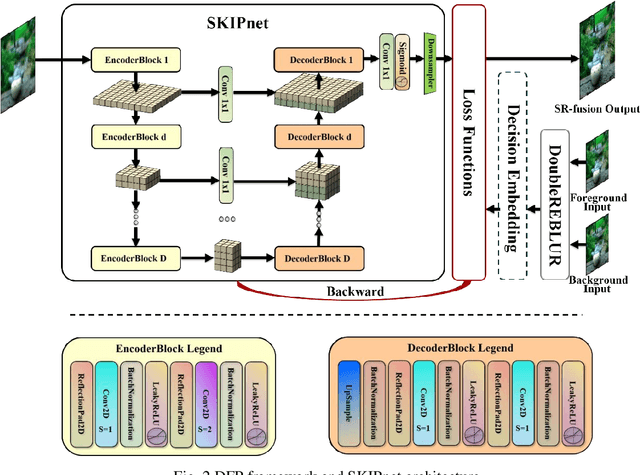
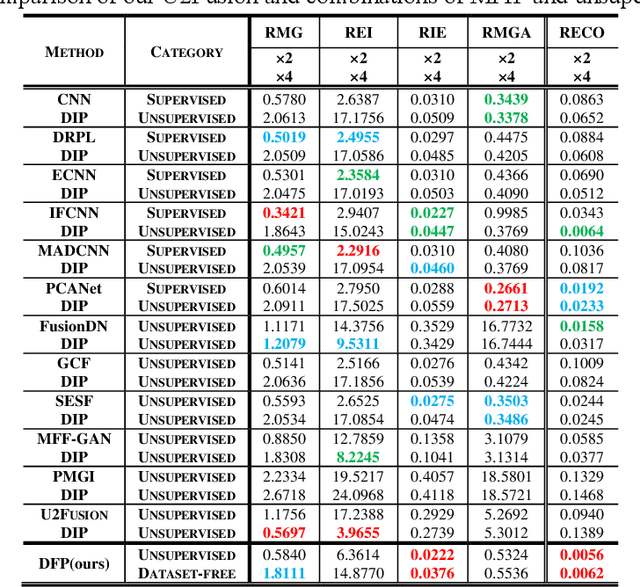
This paper unifies the multi-focus images fusion (MFIF) and blind super resolution (SR) problems as the multi-focus image super resolution fusion (MFISRF) task, and proposes a novel unified dataset-free unsupervised framework named deep fusion prior (DFP) to address such MFISRF task. DFP consists of SKIPnet network, DoubleReblur focus measurement tactic, decision embedding module and loss functions. In particular, DFP can obtain MFISRF only from two low-resolution inputs without any extent dataset; SKIPnet implementing unsupervised learning via deep image prior is an end-to-end generated network acting as the engine of DFP; DoubleReblur is used to determine the primary decision map without learning but based on estimated PSF and Gaussian kernels convolution; decision embedding module optimizes the decision map via learning; and DFP losses composed of content loss, joint gradient loss and gradient limit loss can obtain high-quality MFISRF results robustly. Experiments have proved that our proposed DFP approaches and even outperforms those state-of-art MFIF and SR method combinations. Additionally, DFP is a general framework, thus its networks and focus measurement tactics can be continuously updated to further improve the MFISRF performance. DFP codes are open source and will be available soon at http://github.com/GuYuanjie/DeepFusionPrior.
A model for full local image interpretation
Oct 17, 2021



We describe a computational model of humans' ability to provide a detailed interpretation of components in a scene. Humans can identify in an image meaningful components almost everywhere, and identifying these components is an essential part of the visual process, and of understanding the surrounding scene and its potential meaning to the viewer. Detailed interpretation is beyond the scope of current models of visual recognition. Our model suggests that this is a fundamental limitation, related to the fact that existing models rely on feed-forward but limited top-down processing. In our model, a first recognition stage leads to the initial activation of class candidates, which is incomplete and with limited accuracy. This stage then triggers the application of class-specific interpretation and validation processes, which recover richer and more accurate interpretation of the visible scene. We discuss implications of the model for visual interpretation by humans and by computer vision models.
* Published in the Proceedings of the 37th Annual Meeting of the Cognitive Science Society (CogSci), 2015
Invertible Image Signal Processing
Apr 06, 2021



Unprocessed RAW data is a highly valuable image format for image editing and computer vision. However, since the file size of RAW data is huge, most users can only get access to processed and compressed sRGB images. To bridge this gap, we design an Invertible Image Signal Processing (InvISP) pipeline, which not only enables rendering visually appealing sRGB images but also allows recovering nearly perfect RAW data. Due to our framework's inherent reversibility, we can reconstruct realistic RAW data instead of synthesizing RAW data from sRGB images without any memory overhead. We also integrate a differentiable JPEG compression simulator that empowers our framework to reconstruct RAW data from JPEG images. Extensive quantitative and qualitative experiments on two DSLR demonstrate that our method obtains much higher quality in both rendered sRGB images and reconstructed RAW data than alternative methods.
Discriminative Feature Learning through Feature Distance Loss
May 23, 2022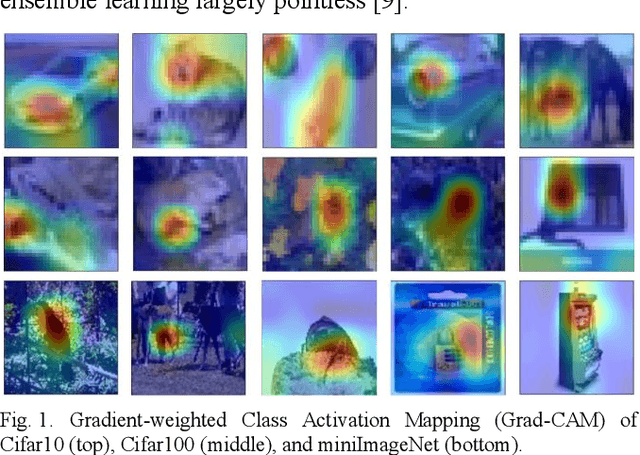
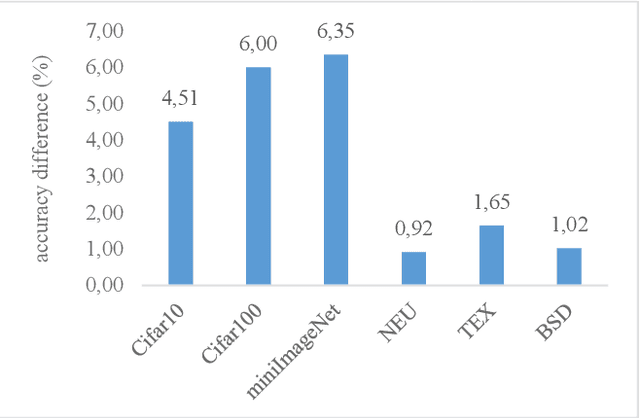
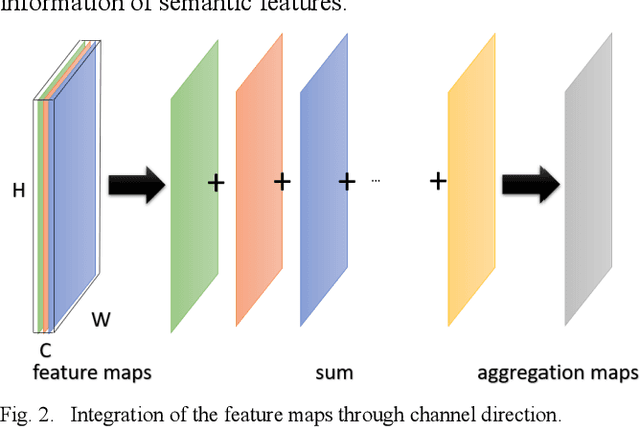
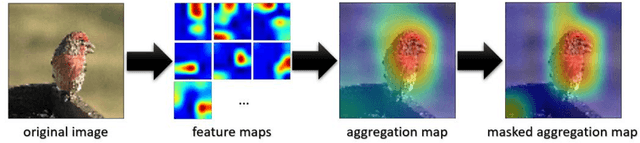
Convolutional neural networks have shown remarkable ability to learn discriminative semantic features in image recognition tasks. Though, for classification they often concentrate on specific regions in images. This work proposes a novel method that combines variant rich base models to concentrate on different important image regions for classification. A feature distance loss is implemented while training an ensemble of base models to force them to learn discriminative feature concepts. The experiments on benchmark convolutional neural networks (VGG16, ResNet, AlexNet), popular datasets (Cifar10, Cifar100, miniImageNet, NEU, BSD, TEX), and different training samples (3, 5, 10, 20, 50, 100 per class) show our methods effectiveness and generalization ability. Our method outperforms ensemble versions of the base models without feature distance loss, and the Class Activation Maps explicitly proves the ability to learn different discriminative feature concepts.
Iterative Filter Adaptive Network for Single Image Defocus Deblurring
Aug 31, 2021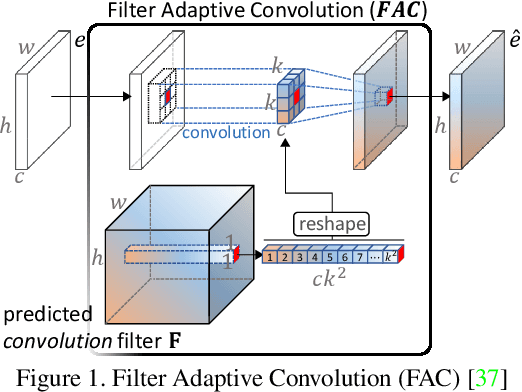
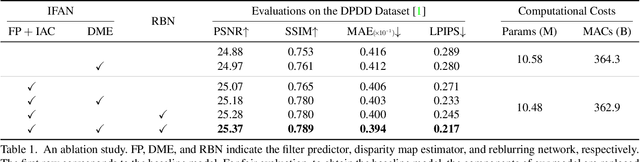
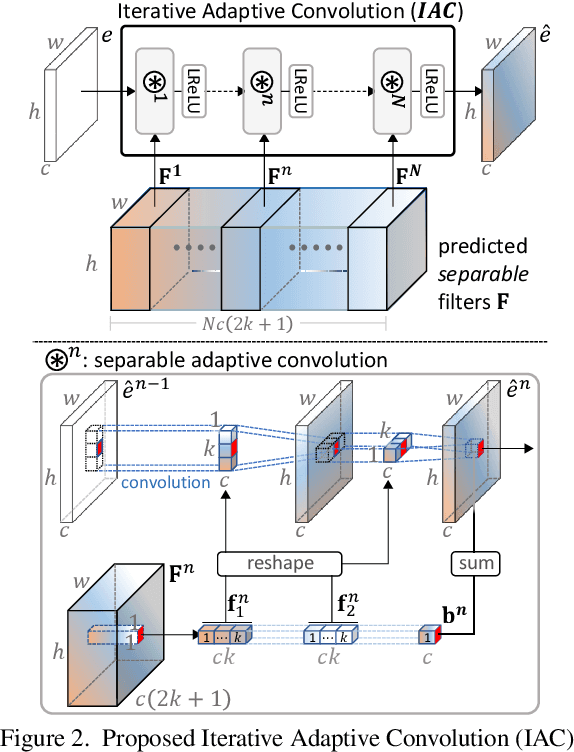
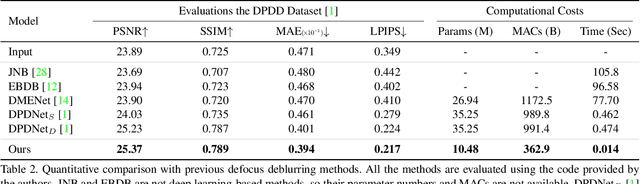
We propose a novel end-to-end learning-based approach for single image defocus deblurring. The proposed approach is equipped with a novel Iterative Filter Adaptive Network (IFAN) that is specifically designed to handle spatially-varying and large defocus blur. For adaptively handling spatially-varying blur, IFAN predicts pixel-wise deblurring filters, which are applied to defocused features of an input image to generate deblurred features. For effectively managing large blur, IFAN models deblurring filters as stacks of small-sized separable filters. Predicted separable deblurring filters are applied to defocused features using a novel Iterative Adaptive Convolution (IAC) layer. We also propose a training scheme based on defocus disparity estimation and reblurring, which significantly boosts the deblurring quality. We demonstrate that our method achieves state-of-the-art performance both quantitatively and qualitatively on real-world images.
* CVPR 2021
Scene Text Recognition with Permuted Autoregressive Sequence Models
Jul 14, 2022

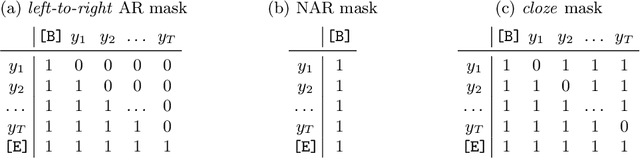
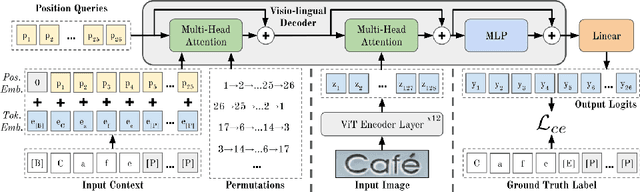
Context-aware STR methods typically use internal autoregressive (AR) language models (LM). Inherent limitations of AR models motivated two-stage methods which employ an external LM. The conditional independence of the external LM on the input image may cause it to erroneously rectify correct predictions, leading to significant inefficiencies. Our method, PARSeq, learns an ensemble of internal AR LMs with shared weights using Permutation Language Modeling. It unifies context-free non-AR and context-aware AR inference, and iterative refinement using bidirectional context. Using synthetic training data, PARSeq achieves state-of-the-art (SOTA) results in STR benchmarks (91.9% accuracy) and more challenging datasets. It establishes new SOTA results (96.0% accuracy) when trained on real data. PARSeq is optimal on accuracy vs parameter count, FLOPS, and latency because of its simple, unified structure and parallel token processing. Due to its extensive use of attention, it is robust on arbitrarily-oriented text which is common in real-world images. Code, pretrained weights, and data are available at: https://github.com/baudm/parseq.