 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SoftDropConnect (SDC) -- Effective and Efficient Quantification of the Network Uncertainty in Deep MR Image Analysis
Jan 20, 2022
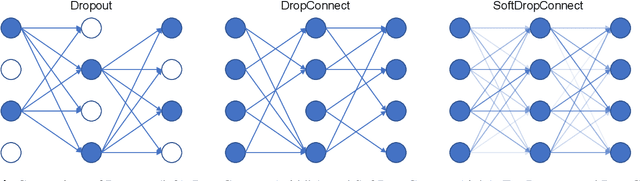
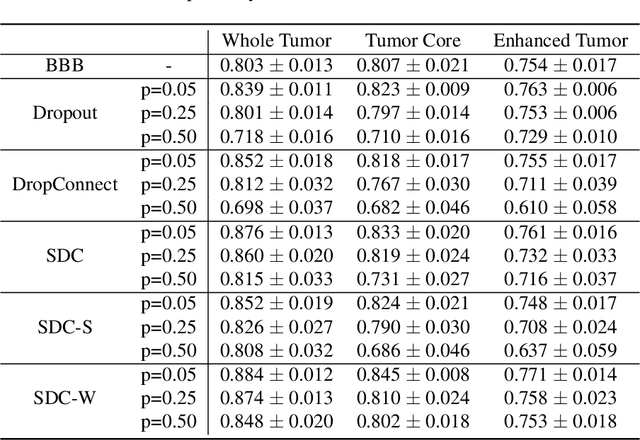
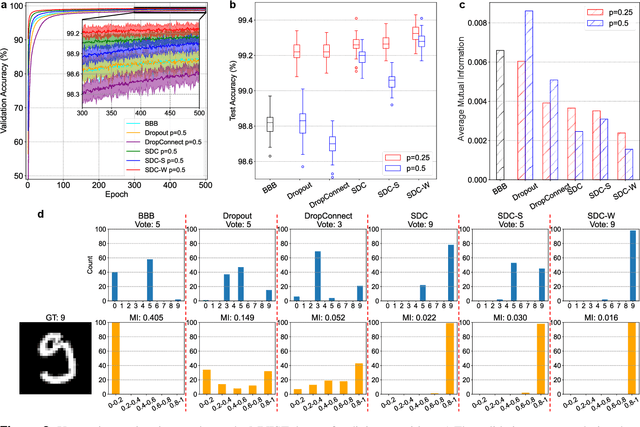
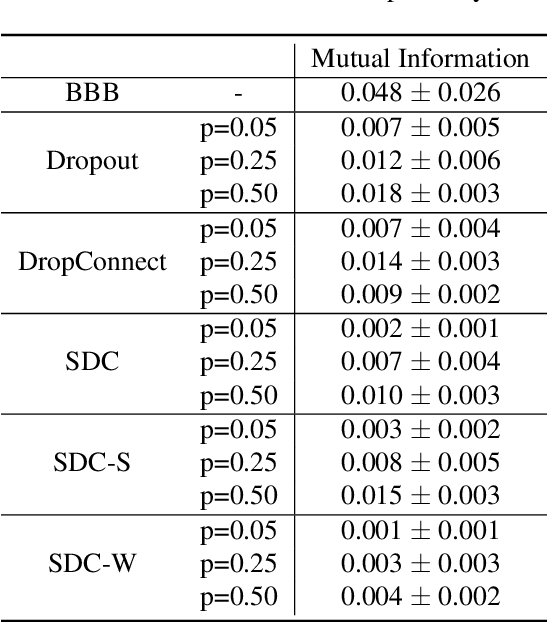
Recently, deep learning has achieved remarkable successes in medical image analysis. Although deep neural networks generate clinically important predictions, they have inherent uncertainty. Such uncertainty is a major barrier to report these predictions with confidence. In this paper, we propose a novel yet simple Bayesian inference approach called SoftDropConnect (SDC) to quantify the network uncertainty in medical imaging tasks with gliomas segmentation and metastases classification as initial examples. Our key idea is that during training and testing SDC modulates network parameters continuously so as to allow affected information processing channels still in operation, instead of disabling them as Dropout or DropConnet does. When compared with three popular Bayesian inference methods including Bayes By Backprop, Dropout, and DropConnect, our SDC method (SDC-W after optimization) outperforms the three competing methods with a substantial margin. Quantitatively, our proposed method generates results withsubstantially improved prediction accuracy (by 10.0%, 5.4% and 3.7% respectively for segmentation in terms of dice score; by 11.7%, 3.9%, 8.7% on classification in terms of test accuracy) and greatly reduced uncertainty in terms of mutual information (by 64%, 33% and 70% on segmentation; 98%, 88%, and 88% on classification). Our approach promises to deliver better diagnostic performance and make medical AI imaging more explainable and trustworthy.
Towards Understanding and Mitigating Audio Adversarial Examples for Speaker Recognition
Jun 07, 2022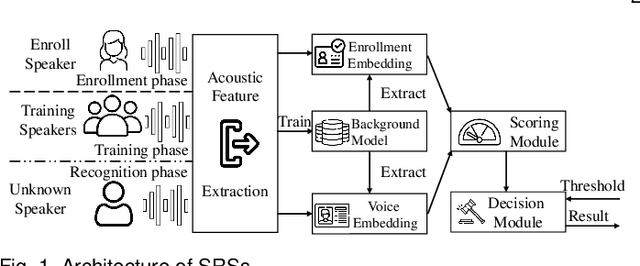
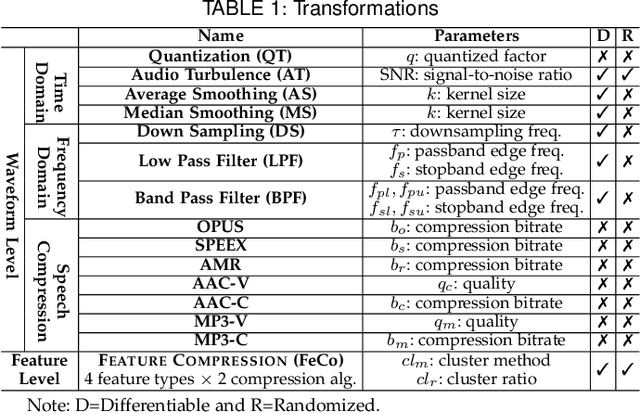
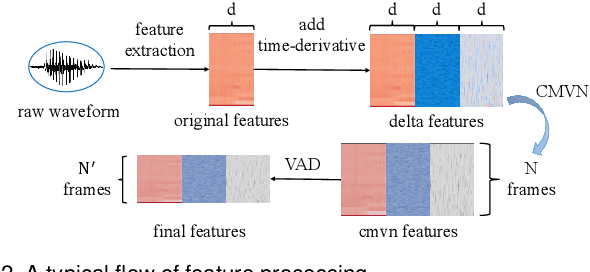
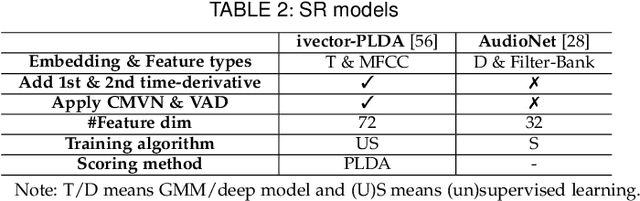
Speaker recognition systems (SRSs) have recently been shown to be vulnerable to adversarial attacks, raising significant security concerns. In this work, we systematically investigate transformation and adversarial training based defenses for securing SRSs. According to the characteristic of SRSs, we present 22 diverse transformations and thoroughly evaluate them using 7 recent promising adversarial attacks (4 white-box and 3 black-box) on speaker recognition. With careful regard for best practices in defense evaluations, we analyze the strength of transformations to withstand adaptive attacks. We also evaluate and understand their effectiveness against adaptive attacks when combined with adversarial training. Our study provides lots of useful insights and findings, many of them are new or inconsistent with the conclusions in the image and speech recognition domains, e.g., variable and constant bit rate speech compressions have different performance, and some non-differentiable transformations remain effective against current promising evasion techniques which often work well in the image domain. We demonstrate that the proposed novel feature-level transformation combined with adversarial training is rather effective compared to the sole adversarial training in a complete white-box setting, e.g., increasing the accuracy by 13.62% and attack cost by two orders of magnitude, while other transformations do not necessarily improve the overall defense capability. This work sheds further light on the research directions in this field. We also release our evaluation platform SPEAKERGUARD to foster further research.
Learning Dual-Pixel Alignment for Defocus Deblurring
Apr 26, 2022



It is a challenging task to recover all-in-focus image from a single defocus blurry image in real-world applications. On many modern cameras, dual-pixel (DP) sensors create two-image views, based on which stereo information can be exploited to benefit defocus deblurring. Despite existing DP defocus deblurring methods achieving impressive results, they directly take naive concatenation of DP views as input, while neglecting the disparity between left and right views in the regions out of camera's depth of field (DoF). In this work, we propose a Dual-Pixel Alignment Network (DPANet) for defocus deblurring. Generally, DPANet is an encoder-decoder with skip-connections, where two branches with shared parameters in the encoder are employed to extract and align deep features from left and right views, and one decoder is adopted to fuse aligned features for predicting the all-in-focus image. Due to that DP views suffer from different blur amounts, it is not trivial to align left and right views. To this end, we propose novel encoder alignment module (EAM) and decoder alignment module (DAM). In particular, a correlation layer is suggested in EAM to measure the disparity between DP views, whose deep features can then be accordingly aligned using deformable convolutions. And DAM can further enhance the alignment of skip-connected features from encoder and deep features in decoder. By introducing several EAMs and DAMs, DP views in DPANet can be well aligned for better predicting latent all-in-focus image. Experimental results on real-world datasets show that our DPANet is notably superior to state-of-the-art deblurring methods in reducing defocus blur while recovering visually plausible sharp structures and textures.
Large-scale image segmentation based on distributed clustering algorithms
Jun 21, 2021
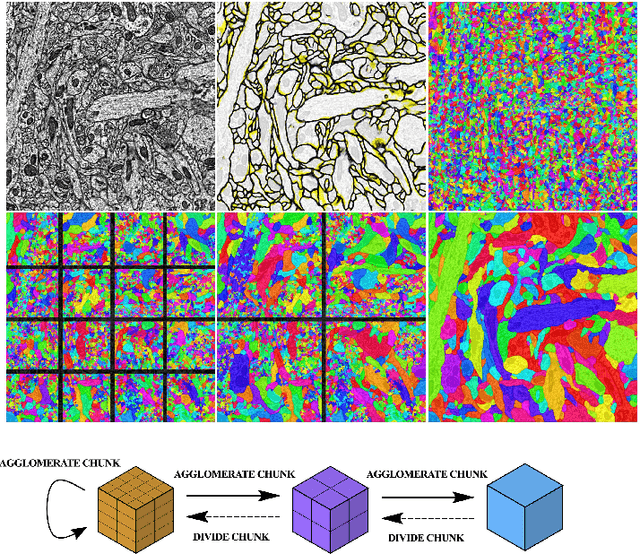
Many approaches to 3D image segmentation are based on hierarchical clustering of supervoxels into image regions. Here we describe a distributed algorithm capable of handling a tremendous number of supervoxels. The algorithm works recursively, the regions are divided into chunks that are processed independently in parallel by multiple workers. At each round of the recursive procedure, the chunk size in all dimensions are doubled until a single chunk encompasses the entire image. The final result is provably independent of the chunking scheme, and the same as if the entire image were processed without division into chunks. This is nontrivial because a pair of adjacent regions is scored by some statistical property (e.g. mean or median) of the affinities at the interface, and the interface may extend over arbitrarily many chunks. The trick is to delay merge decisions for regions that touch chunk boundaries, and only complete them in a later round after the regions are fully contained within a chunk. We demonstrate the algorithm by clustering an affinity graph with over 1.5 trillion edges between 135 billion supervoxels derived from a 3D electron microscopic brain image.
Large Neural Networks Learning from Scratch with Very Few Data and without Regularization
May 18, 2022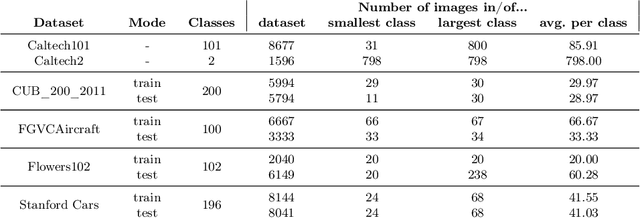


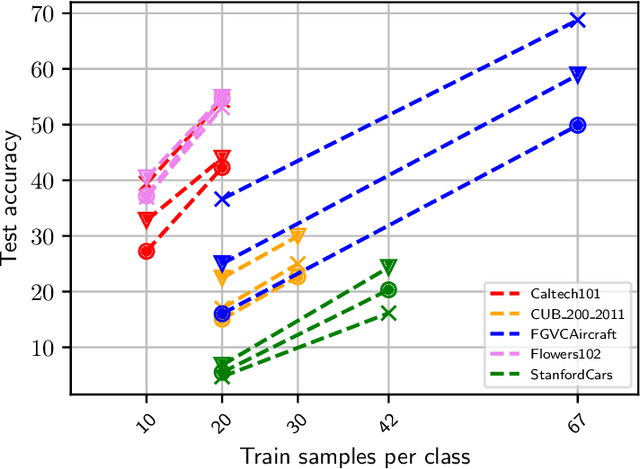
Recent findings have shown that Neural Networks generalize also in over-parametrized regimes with zero training error. This is surprising, since it is completely against traditional machine learning wisdom. In our empirical study we fortify these findings in the domain of fine-grained image classification. We show that very large Convolutional Neural Networks with millions of weights do learn with only a handful of training samples and without image augmentation, explicit regularization or pretraining. We train the architectures ResNet018, ResNet101 and VGG19 on subsets of the difficult benchmark datasets Caltech101, CUB_200_2011, FGVCAircraft, Flowers102 and StanfordCars with 100 classes and more, perform a comprehensive comparative study and draw implications for the practical application of CNNs. Finally, we show that VGG19 with 140 million weights learns to distinguish airplanes and motorbikes up to 95% accuracy with only 20 samples per class.
MixSyn: Learning Composition and Style for Multi-Source Image Synthesis
Nov 24, 2021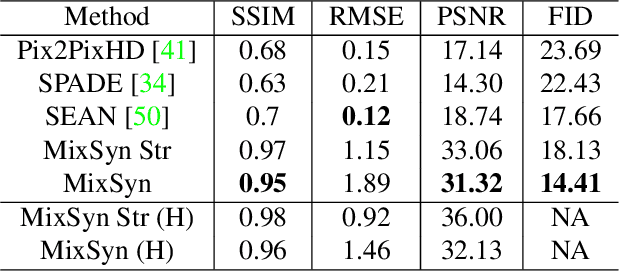
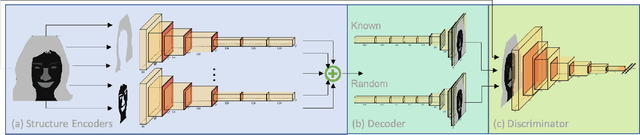
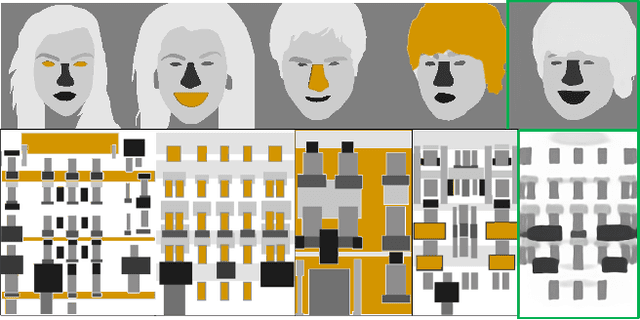
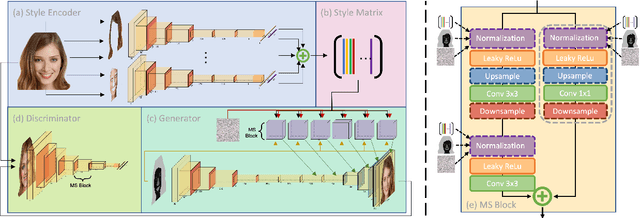
Synthetic images created by generative models increase in quality and expressiveness as newer models utilize larger datasets and novel architectures. Although this photorealism is a positive side-effect from a creative standpoint, it becomes problematic when such generative models are used for impersonation without consent. Most of these approaches are built on the partial transfer between source and target pairs, or they generate completely new samples based on an ideal distribution, still resembling the closest real sample in the dataset. We propose MixSyn (read as " mixin' ") for learning novel fuzzy compositions from multiple sources and creating novel images as a mix of image regions corresponding to the compositions. MixSyn not only combines uncorrelated regions from multiple source masks into a coherent semantic composition, but also generates mask-aware high quality reconstructions of non-existing images. We compare MixSyn to state-of-the-art single-source sequential generation and collage generation approaches in terms of quality, diversity, realism, and expressive power; while also showcasing interactive synthesis, mix & match, and edit propagation tasks, with no mask dependency.
Understanding and Evaluating Racial Biases in Image Captioning
Jun 16, 2021
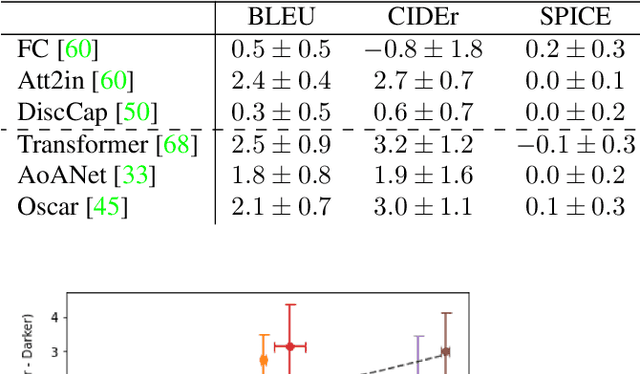
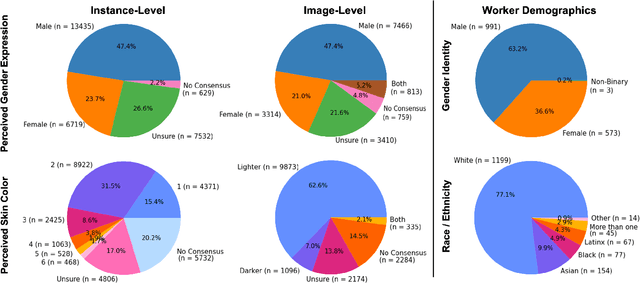
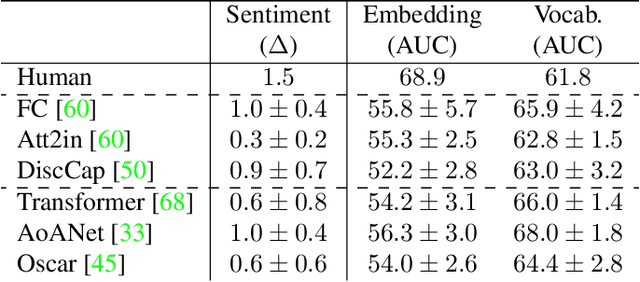
Image captioning is an important task for benchmarking visual reasoning and for enabling accessibility for people with vision impairments. However, as in many machine learning settings, social biases can influence image captioning in undesirable ways. In this work, we study bias propagation pathways within image captioning, focusing specifically on the COCO dataset. Prior work has analyzed gender bias in captions using automatically-derived gender labels; here we examine racial and intersectional biases using manual annotations. Our first contribution is in annotating the perceived gender and skin color of 28,315 of the depicted people after obtaining IRB approval. Using these annotations, we compare racial biases present in both manual and automatically-generated image captions. We demonstrate differences in caption performance, sentiment, and word choice between images of lighter versus darker-skinned people. Further, we find the magnitude of these differences to be greater in modern captioning systems compared to older ones, thus leading to concerns that without proper consideration and mitigation these differences will only become increasingly prevalent. Code and data is available at https://princetonvisualai.github.io/imagecaptioning-bias .
Persistent homology-based descriptor for machine-learning potential
Jun 28, 2022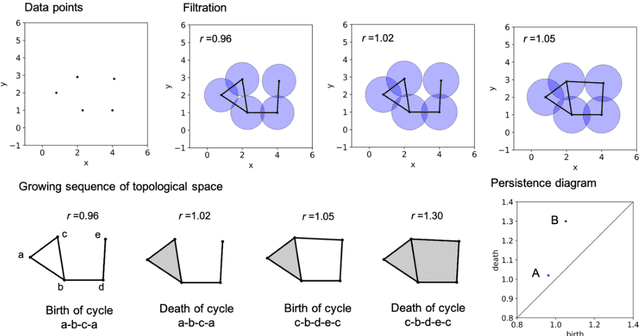
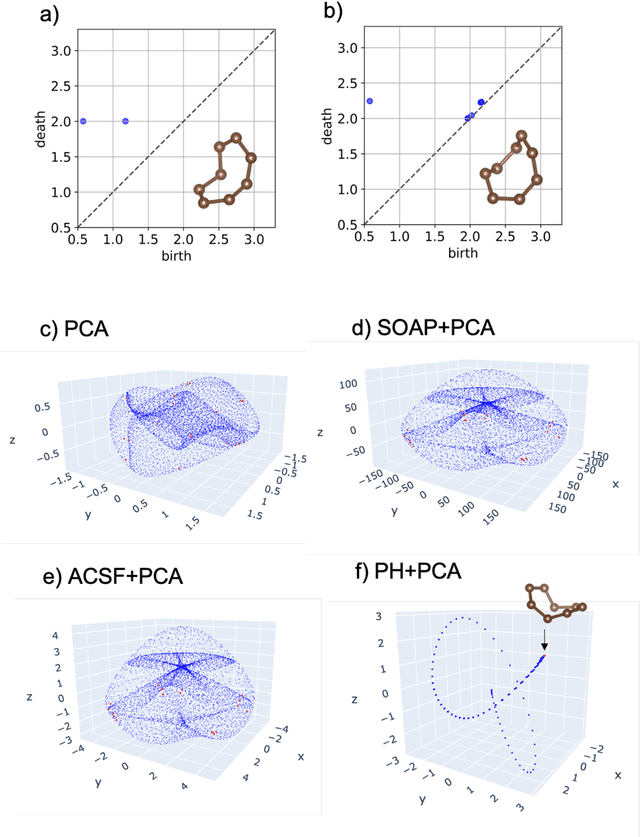
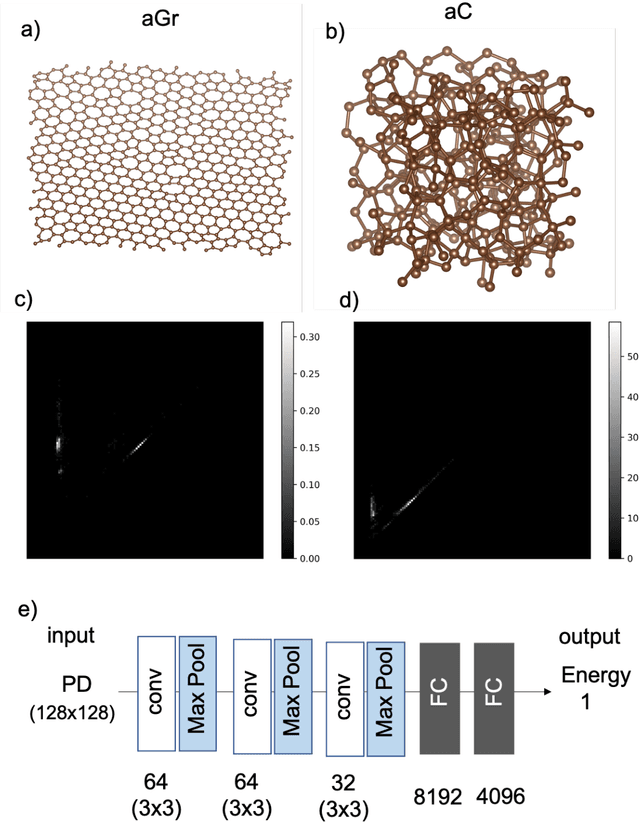
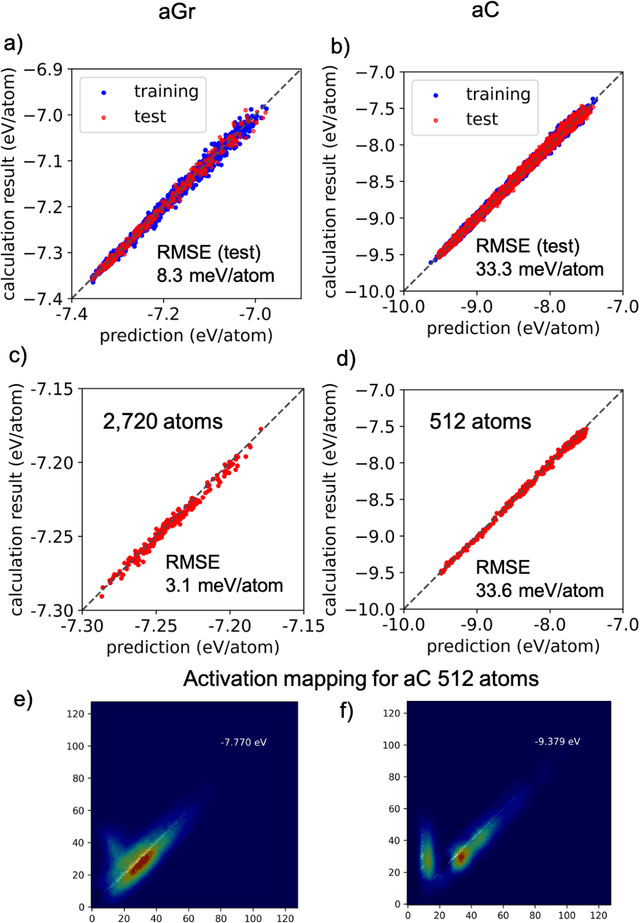
Constructing efficient descriptors that represent atomic configurations is crucial for developing a superior machine-learning potential. Widely used conventional descriptors are based on two- or three-body correlations of atomic distribution. Recently, several limitations of these many-body descriptors in classifying different configurations were revealed, which have detrimental effects on the prediction of physical properties. We proposed a new class of descriptors based on persistent homology. We focused on the two-dimensional visualization of persistent homology, that is, a persistence diagram, as a descriptor of atomic configurations in the form of an image. We demonstrated that convolutional neural network models based on this descriptor provide sufficient accuracy in predicting the mean energies per atom of amorphous graphene and amorphous carbon. Our results provide an avenue for improving machine-learning potential using descriptors that depict both topological and geometric information.
Learning-based Monocular 3D Reconstruction of Birds: A Contemporary Survey
Jul 10, 2022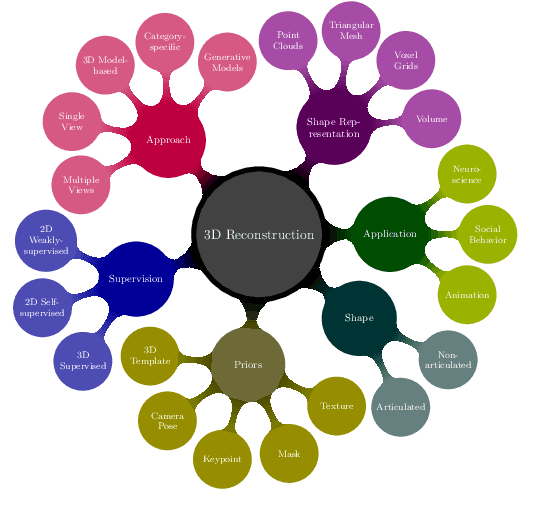
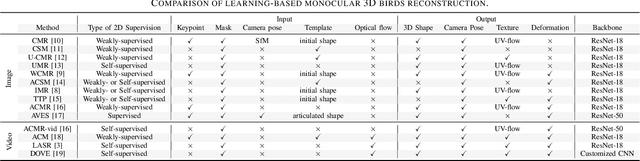
In nature, the collective behavior of animals, such as flying birds is dominated by the interactions between individuals of the same species. However, the study of such behavior among the bird species is a complex process that humans cannot perform using conventional visual observational techniques such as focal sampling in nature. For social animals such as birds, the mechanism of group formation can help ecologists understand the relationship between social cues and their visual characteristics over time (e.g., pose and shape). But, recovering the varying pose and shapes of flying birds is a highly challenging problem. A widely-adopted solution to tackle this bottleneck is to extract the pose and shape information from 2D image to 3D correspondence. Recent advances in 3D vision have led to a number of impressive works on the 3D shape and pose estimation, each with different pros and cons. To the best of our knowledge, this work is the first attempt to provide an overview of recent advances in 3D bird reconstruction based on monocular vision, give both computer vision and biology researchers an overview of existing approaches, and compare their characteristics.
Generalizable Cross-modality Medical Image Segmentation via Style Augmentation and Dual Normalization
Dec 21, 2021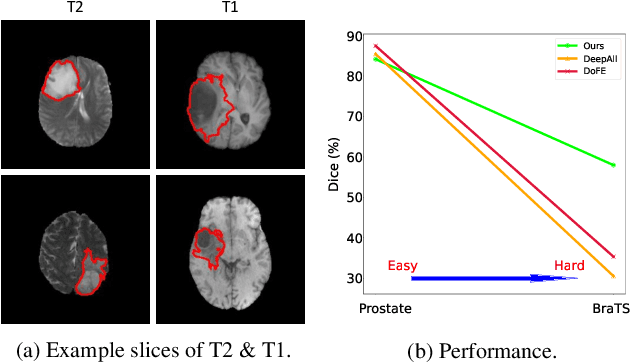
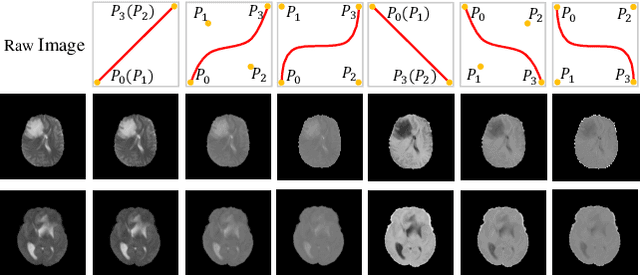
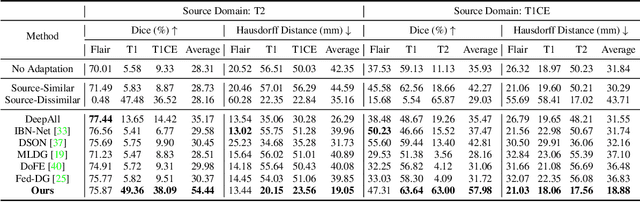
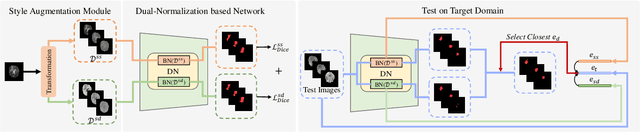
For medical image segmentation, imagine if a model was only trained using MR images in source domain, how about its performance to directly segment CT images in target domain? This setting, namely generalizable cross-modality segmentation, owning its clinical potential, is much more challenging than other related settings, e.g., domain adaptation. To achieve this goal, we in this paper propose a novel dual-normalization module by leveraging the augmented source-similar and source-dissimilar images during our generalizable segmentation. To be specific, given a single source domain, aiming to simulate the possible appearance change in unseen target domains, we first utilize a nonlinear transformation to augment source-similar and source-dissimilar images. Then, to sufficiently exploit these two types of augmentations, our proposed dual-normalization based model employs a shared backbone yet independent batch normalization layer for separate normalization. Afterwards, we put forward a style-based selection scheme to automatically choose the appropriate path in the test stage. Extensive experiments on three publicly available datasets, i.e., BraTS, Cross-Modality Cardiac and Abdominal Multi-Organ dataset, have demonstrated that our method outperforms other state-of-the-art domain generalization methods.