 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Popeye: A Unified Visual-Language Model for Multi-Source Ship Detection from Remote Sensing Imagery
Mar 06, 2024

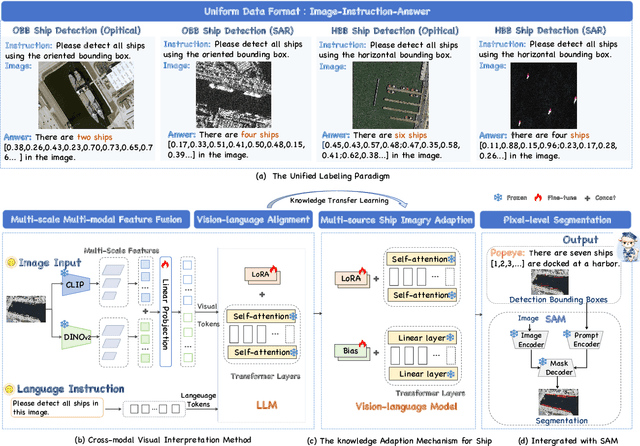

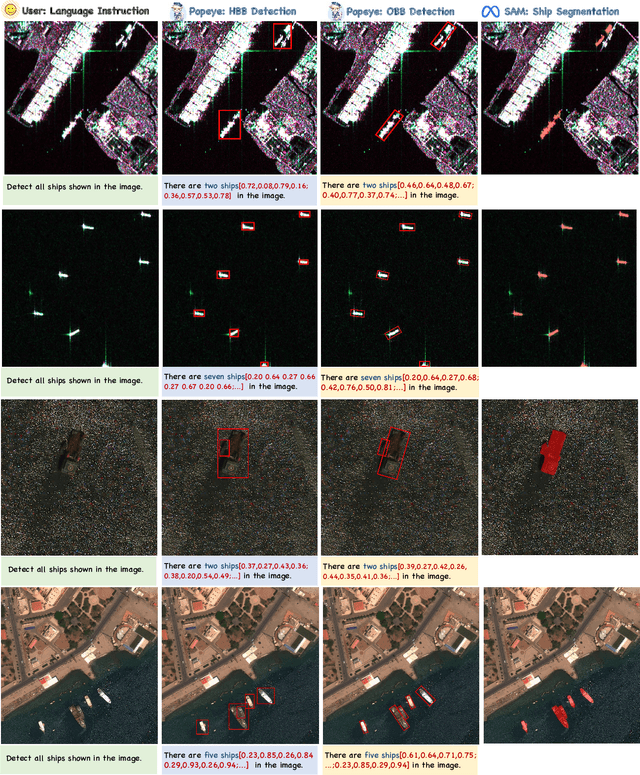
Ship detection needs to identify ship locations from remote sensing (RS) scenes. However, due to different imaging payloads, various appearances of ships, and complicated background interference from the bird's eye view, it is difficult to set up a unified paradigm for achieving multi-source ship detection. Therefore, in this article, considering that the large language models (LLMs) emerge the powerful generalization ability, a novel unified visual-language model called Popeye is proposed for multi-source ship detection from RS imagery. First, to bridge the interpretation gap between multi-source images for ship detection, a novel image-instruction-answer way is designed to integrate the various ship detection ways (e.g., horizontal bounding box (HBB), oriented bounding box (OBB)) into a unified labeling paradigm. Then, in view of this, a cross-modal image interpretation method is developed for the proposed Popeye to enhance interactive comprehension ability between visual and language content, which can be easily migrated into any multi-source ship detection task. Subsequently, owing to objective domain differences, a knowledge adaption mechanism is designed to adapt the pre-trained visual-language knowledge from the nature scene into the RS domain for multi-source ship detection. In addition, the segment anything model (SAM) is also seamlessly integrated into the proposed Popeye to achieve pixel-level ship segmentation without additional training costs. Finally, extensive experiments are conducted on the newly constructed instruction dataset named MMShip, and the results indicate that the proposed Popeye outperforms current specialist, open-vocabulary, and other visual-language models for zero-shot multi-source ship detection.
Noise Level Adaptive Diffusion Model for Robust Reconstruction of Accelerated MRI
Mar 08, 2024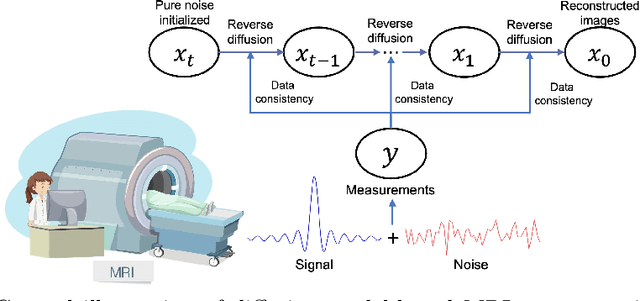
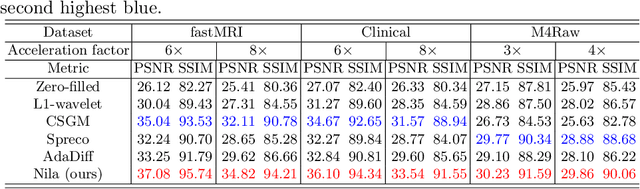
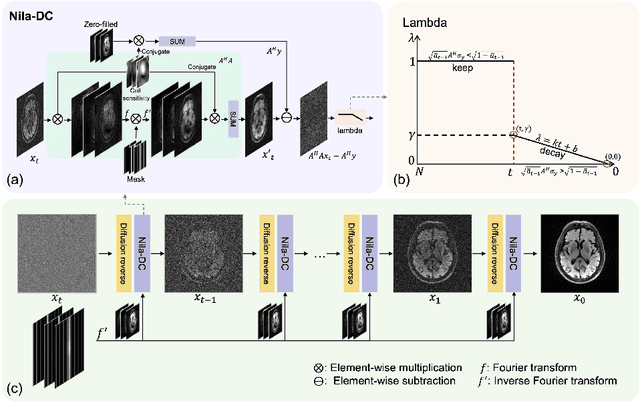
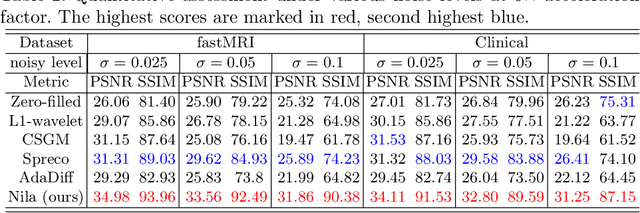
In general, diffusion model-based MRI reconstruction methods incrementally remove artificially added noise while imposing data consistency to reconstruct the underlying images. However, real-world MRI acquisitions already contain inherent noise due to thermal fluctuations. This phenomenon is particularly notable when using ultra-fast, high-resolution imaging sequences for advanced research, or using low-field systems favored by low- and middle-income countries. These common scenarios can lead to sub-optimal performance or complete failure of existing diffusion model-based reconstruction techniques. Specifically, as the artificially added noise is gradually removed, the inherent MRI noise becomes increasingly pronounced, making the actual noise level inconsistent with the predefined denoising schedule and consequently inaccurate image reconstruction. To tackle this problem, we propose a posterior sampling strategy with a novel NoIse Level Adaptive Data Consistency (Nila-DC) operation. Extensive experiments are conducted on two public datasets and an in-house clinical dataset with field strength ranging from 0.3T to 3T, showing that our method surpasses the state-of-the-art MRI reconstruction methods, and is highly robust against various noise levels. The code will be released after review.
PIPsUS: Self-Supervised Dense Point Tracking in Ultrasound
Mar 08, 2024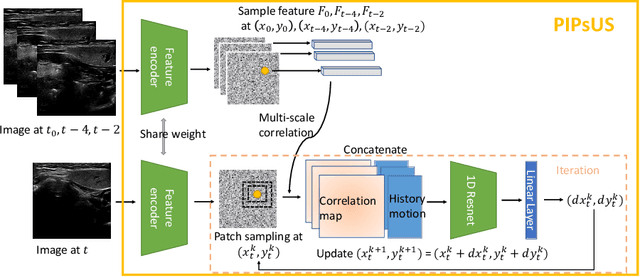
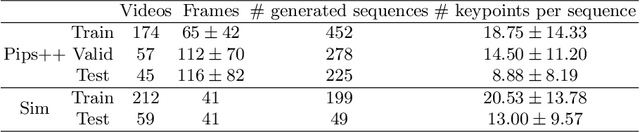
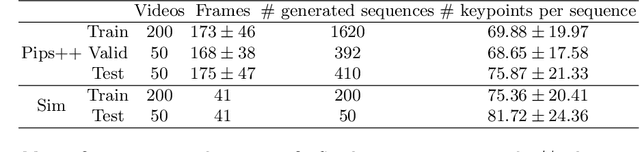
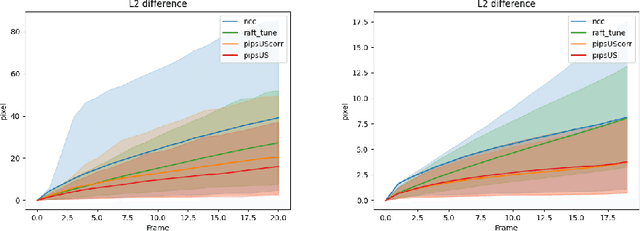
Finding point-level correspondences is a fundamental problem in ultrasound (US), since it can enable US landmark tracking for intraoperative image guidance in different surgeries, including head and neck. Most existing US tracking methods, e.g., those based on optical flow or feature matching, were initially designed for RGB images before being applied to US. Therefore domain shift can impact their performance. Training could be supervised by ground-truth correspondences, but these are expensive to acquire in US. To solve these problems, we propose a self-supervised pixel-level tracking model called PIPsUS. Our model can track an arbitrary number of points in one forward pass and exploits temporal information by considering multiple, instead of just consecutive, frames. We developed a new self-supervised training strategy that utilizes a long-term point-tracking model trained for RGB images as a teacher to guide the model to learn realistic motions and use data augmentation to enforce tracking from US appearance. We evaluate our method on neck and oral US and echocardiography, showing higher point tracking accuracy when compared with fast normalized cross-correlation and tuned optical flow. Code will be available once the paper is accepted.
DiffClass: Diffusion-Based Class Incremental Learning
Mar 08, 2024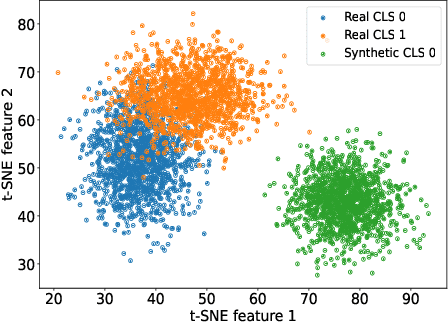
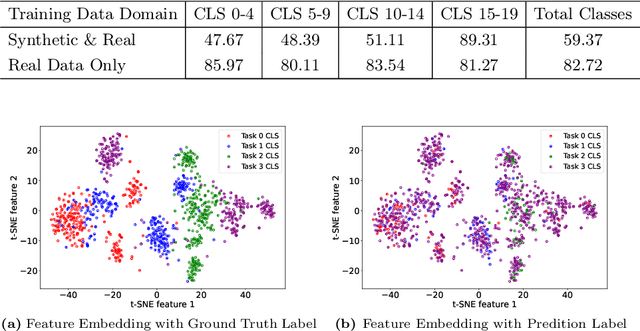
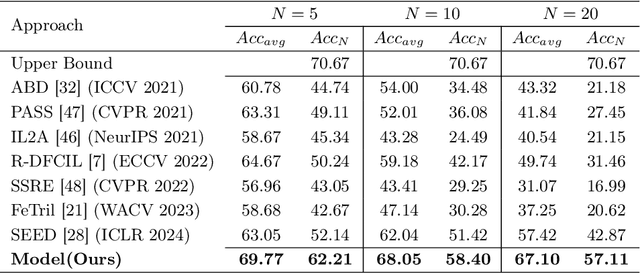
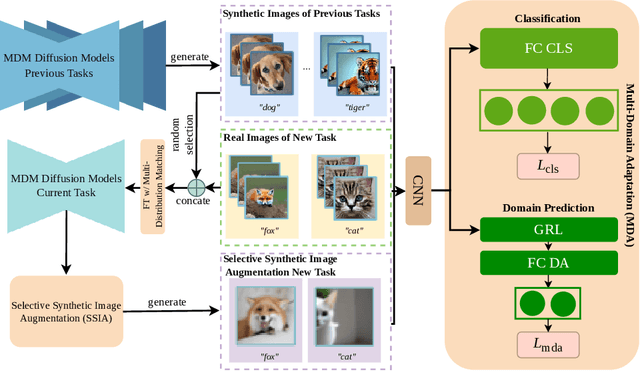
Class Incremental Learning (CIL) is challenging due to catastrophic forgetting. On top of that, Exemplar-free Class Incremental Learning is even more challenging due to forbidden access to previous task data. Recent exemplar-free CIL methods attempt to mitigate catastrophic forgetting by synthesizing previous task data. However, they fail to overcome the catastrophic forgetting due to the inability to deal with the significant domain gap between real and synthetic data. To overcome these issues, we propose a novel exemplar-free CIL method. Our method adopts multi-distribution matching (MDM) diffusion models to unify quality and bridge domain gaps among all domains of training data. Moreover, our approach integrates selective synthetic image augmentation (SSIA) to expand the distribution of the training data, thereby improving the model's plasticity and reinforcing the performance of our method's ultimate component, multi-domain adaptation (MDA). With the proposed integrations, our method then reformulates exemplar-free CIL into a multi-domain adaptation problem to implicitly address the domain gap problem to enhance model stability during incremental training. Extensive experiments on benchmark class incremental datasets and settings demonstrate that our method excels previous exemplar-free CIL methods and achieves state-of-the-art performance.
Finding Waldo: Towards Efficient Exploration of NeRF Scene Spaces
Mar 08, 2024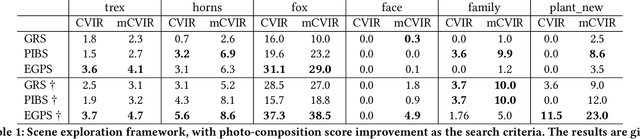

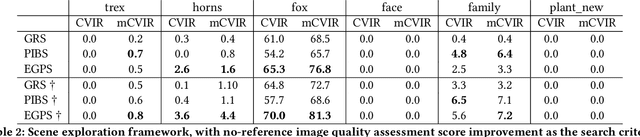

Neural Radiance Fields (NeRF) have quickly become the primary approach for 3D reconstruction and novel view synthesis in recent years due to their remarkable performance. Despite the huge interest in NeRF methods, a practical use case of NeRFs has largely been ignored; the exploration of the scene space modelled by a NeRF. In this paper, for the first time in the literature, we propose and formally define the scene exploration framework as the efficient discovery of NeRF model inputs (i.e. coordinates and viewing angles), using which one can render novel views that adhere to user-selected criteria. To remedy the lack of approaches addressing scene exploration, we first propose two baseline methods called Guided-Random Search (GRS) and Pose Interpolation-based Search (PIBS). We then cast scene exploration as an optimization problem, and propose the criteria-agnostic Evolution-Guided Pose Search (EGPS) for efficient exploration. We test all three approaches with various criteria (e.g. saliency maximization, image quality maximization, photo-composition quality improvement) and show that our EGPS performs more favourably than other baselines. We finally highlight key points and limitations, and outline directions for future research in scene exploration.
Explainable Face Verification via Feature-Guided Gradient Backpropagation
Mar 07, 2024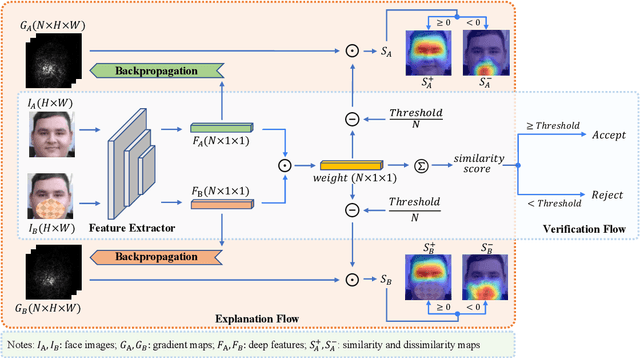
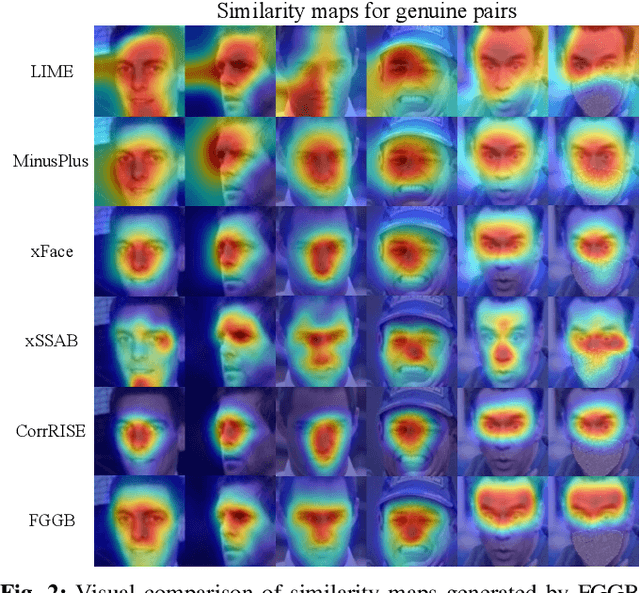
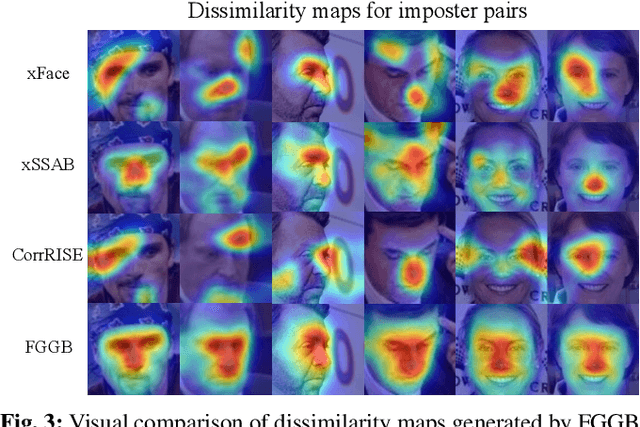
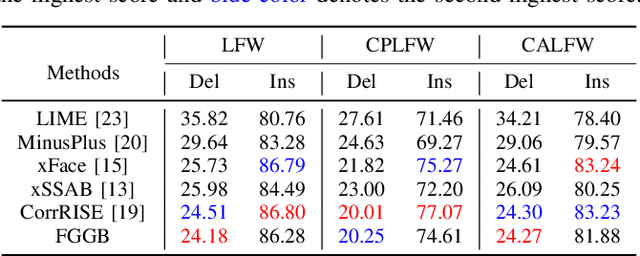
Recent years have witnessed significant advancement in face recognition (FR) techniques, with their applications widely spread in people's lives and security-sensitive areas. There is a growing need for reliable interpretations of decisions of such systems. Existing studies relying on various mechanisms have investigated the usage of saliency maps as an explanation approach, but suffer from different limitations. This paper first explores the spatial relationship between face image and its deep representation via gradient backpropagation. Then a new explanation approach FGGB has been conceived, which provides precise and insightful similarity and dissimilarity saliency maps to explain the "Accept" and "Reject" decision of an FR system. Extensive visual presentation and quantitative measurement have shown that FGGB achieves superior performance in both similarity and dissimilarity maps when compared to current state-of-the-art explainable face verification approaches.
Is in-domain data beneficial in transfer learning for landmarks detection in x-ray images?
Mar 03, 2024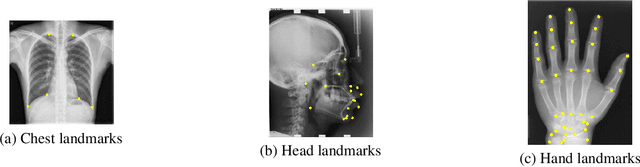
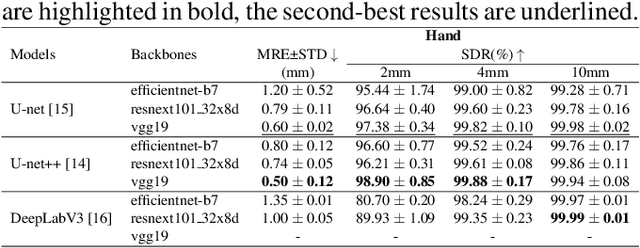
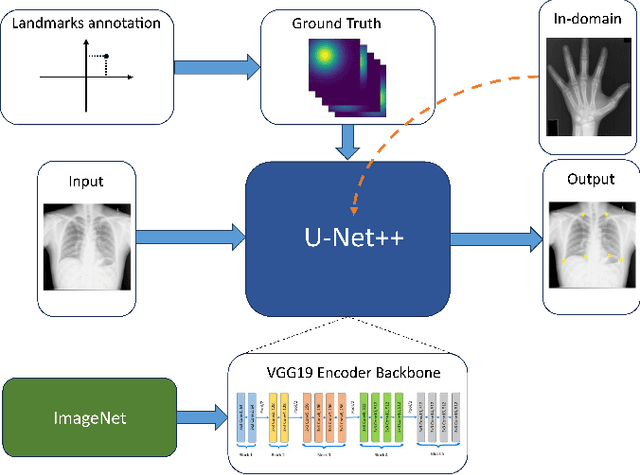
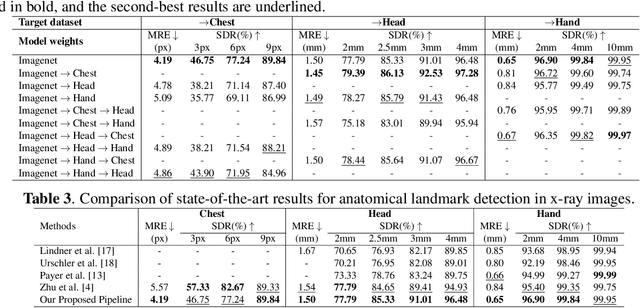
In recent years, deep learning has emerged as a promising technique for medical image analysis. However, this application domain is likely to suffer from a limited availability of large public datasets and annotations. A common solution to these challenges in deep learning is the usage of a transfer learning framework, typically with a fine-tuning protocol, where a large-scale source dataset is used to pre-train a model, further fine-tuned on the target dataset. In this paper, we present a systematic study analyzing whether the usage of small-scale in-domain x-ray image datasets may provide any improvement for landmark detection over models pre-trained on large natural image datasets only. We focus on the multi-landmark localization task for three datasets, including chest, head, and hand x-ray images. Our results show that using in-domain source datasets brings marginal or no benefit with respect to an ImageNet out-of-domain pre-training. Our findings can provide an indication for the development of robust landmark detection systems in medical images when no large annotated dataset is available.
OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on
Mar 07, 2024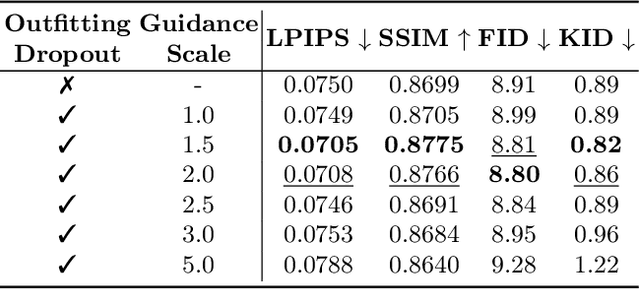
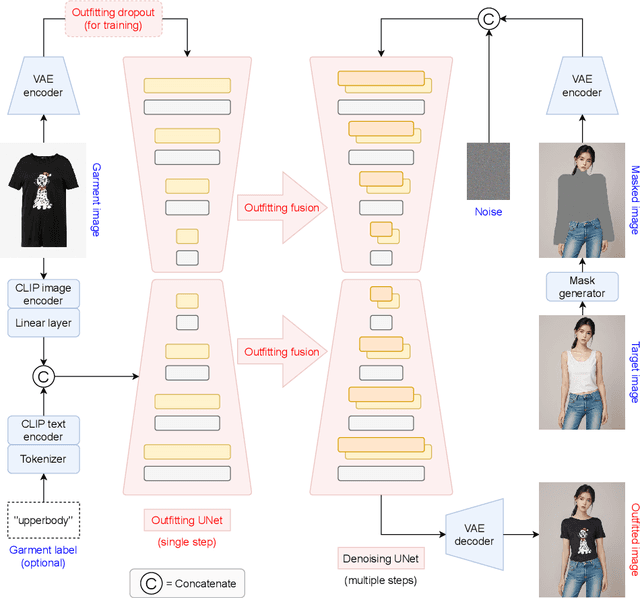
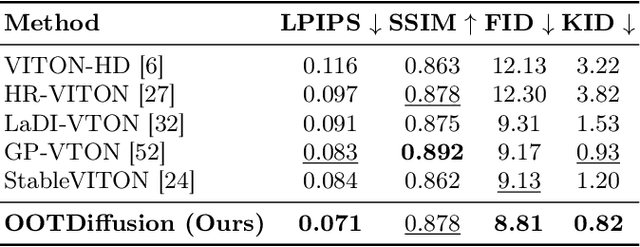

We present OOTDiffusion, a novel network architecture for realistic and controllable image-based virtual try-on (VTON). We leverage the power of pretrained latent diffusion models, designing an outfitting UNet to learn the garment detail features. Without a redundant warping process, the garment features are precisely aligned with the target human body via the proposed outfitting fusion in the self-attention layers of the denoising UNet. In order to further enhance the controllability, we introduce outfitting dropout to the training process, which enables us to adjust the strength of the garment features through classifier-free guidance. Our comprehensive experiments on the VITON-HD and Dress Code datasets demonstrate that OOTDiffusion efficiently generates high-quality try-on results for arbitrary human and garment images, which outperforms other VTON methods in both realism and controllability, indicating an impressive breakthrough in virtual try-on. Our source code is available at https://github.com/levihsu/OOTDiffusion.
Spatiotemporal Pooling on Appropriate Topological Maps Represented as Two-Dimensional Images for EEG Classification
Mar 07, 2024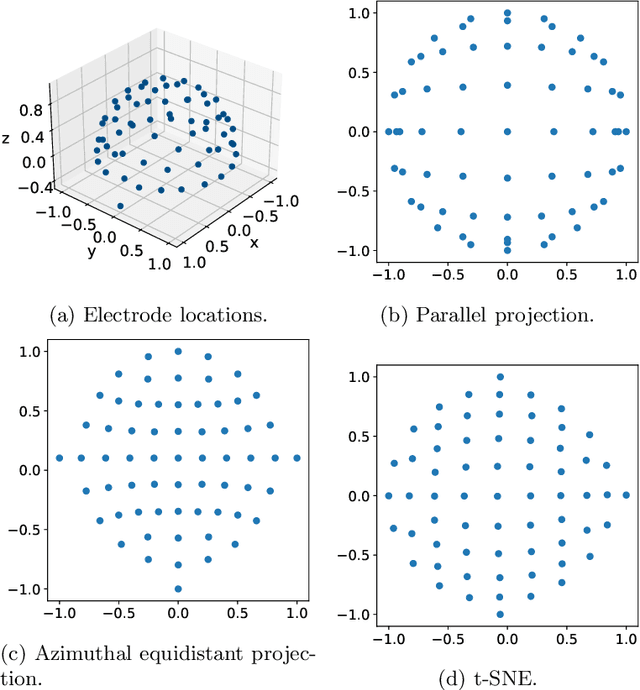

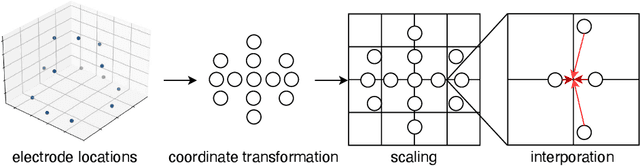
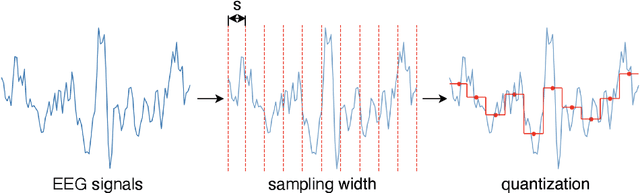
Motor imagery classification based on electroencephalography (EEG) signals is one of the most important brain-computer interface applications, although it needs further improvement. Several methods have attempted to obtain useful information from EEG signals by using recent deep learning techniques such as transformers. To improve the classification accuracy, this study proposes a novel EEG-based motor imagery classification method with three key features: generation of a topological map represented as a two-dimensional image from EEG signals with coordinate transformation based on t-SNE, use of the InternImage to extract spatial features, and use of spatiotemporal pooling inspired by PoolFormer to exploit spatiotemporal information concealed in a sequence of EEG images. Experimental results using the PhysioNet EEG Motor Movement/Imagery dataset showed that the proposed method achieved the best classification accuracy of 88.57%, 80.65%, and 70.17% on two-, three-, and four-class motor imagery tasks in cross-individual validation.
Automatic Detection and Classification of Corona Infection (COVID-19) from X-ray Images Using Convolution Neural Network
Mar 09, 2024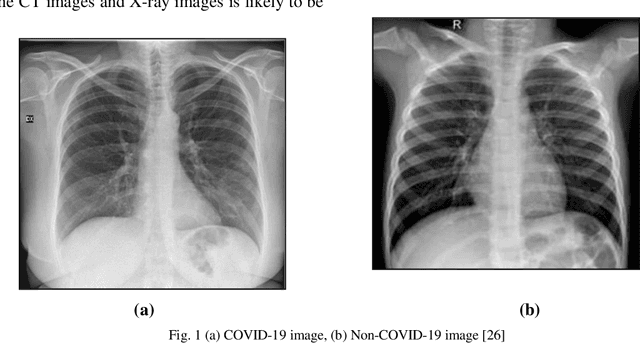
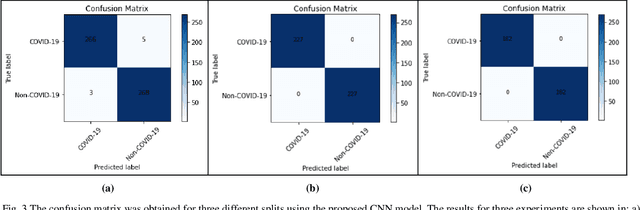
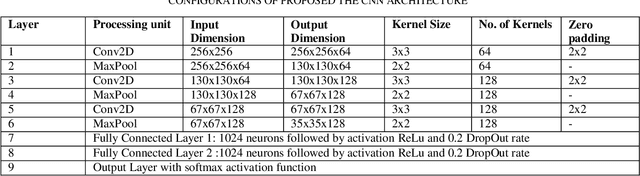

The novel coronavirus universally known as the COVID-19 outbreak arises at the end of 2019 in one of the East Asian countries and it is subjected to widespread discussion and debate. There are almost 200 countries affected across the globe by COVID-19 and it has ruined many lives and the global economy. The virus is spreading very rapidly at the pace of around 10 fold in less than a month. Also, in the case of COVID- 19 it is critical to detect the infection as it employs various symptoms which may differ from person to person. Hence, diagnosis in starting stage and treatment are very much important for such type of infectious disease. The chest x-ray is one of the primary techniques among blood tests and Computed Tomography contributes a major role in the early diagnosis of COVID-19. There is a rising need for automated and auxiliary diagnostic tools for early diagnosis, as there are no accurate and truthful automated tool kits on hand. In this research study, we have designed a Convolution Neural Network architecture a deep net for the classification of x-ray images of chest among two classes: COVID-19 or Non-COVID- 19 infection. The anticipated model is expected to provide accurate diagnostic results and produced classification accuracy of 99%, 100%, and 100% with 70%-30%,75%-25% and 80%-20% train-test data split respectively, for the binary classification of the x-ray image to be COVID-19 or Non-COVID-19 infection category. We have designed the CNN with optimized parameters with 3 convolution layers and optimized number of filters in each layer.