 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hyperparameter optimization of hybrid quantum neural networks for car classification
May 10, 2022
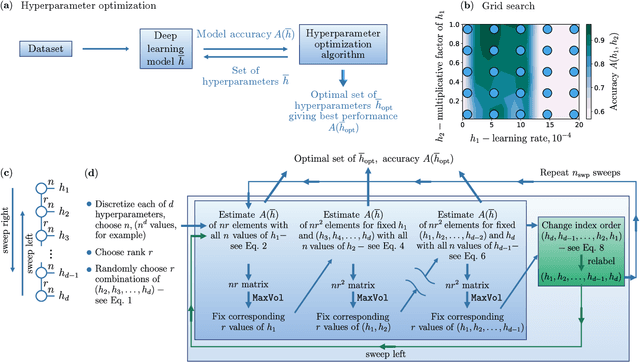
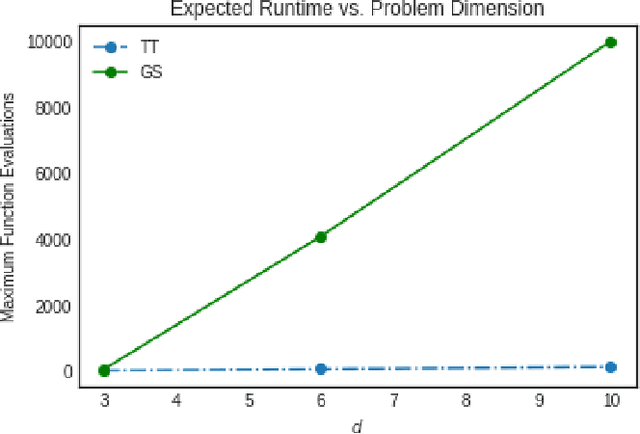
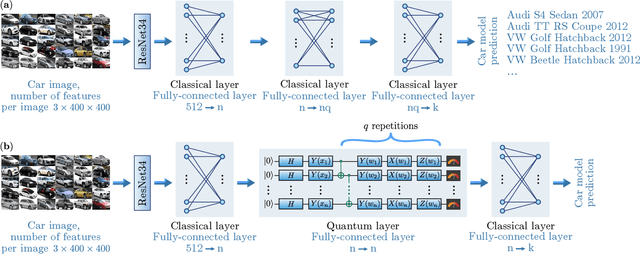
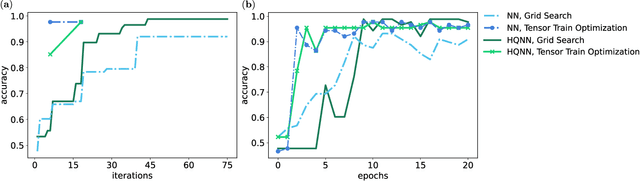
Image recognition is one of the primary applications of machine learning algorithms. Nevertheless, machine learning models used in modern image recognition systems consist of millions of parameters that usually require significant computational time to be adjusted. Moreover, adjustment of model hyperparameters leads to additional overhead. Because of this, new developments in machine learning models and hyperparameter optimization techniques are required. This paper presents a quantum-inspired hyperparameter optimization technique and a hybrid quantum-classical machine learning model for supervised learning. We benchmark our hyperparameter optimization method over standard black-box objective functions and observe performance improvements in the form of reduced expected run times and fitness in response to the growth in the size of the search space. We test our approaches in a car image classification task, and demonstrate a full-scale implementation of the hybrid quantum neural network model with the tensor train hyperparameter optimization. Our tests show a qualitative and quantitative advantage over the corresponding standard classical tabular grid search approach used with a deep neural network ResNet34. A classification accuracy of 0.97 was obtained by the hybrid model after 18 iterations, whereas the classical model achieved an accuracy of 0.92 after 75 iterations.
Estimating Model Performance under Domain Shifts with Class-Specific Confidence Scores
Jul 20, 2022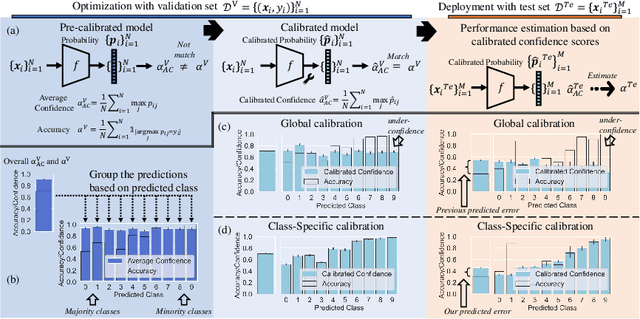
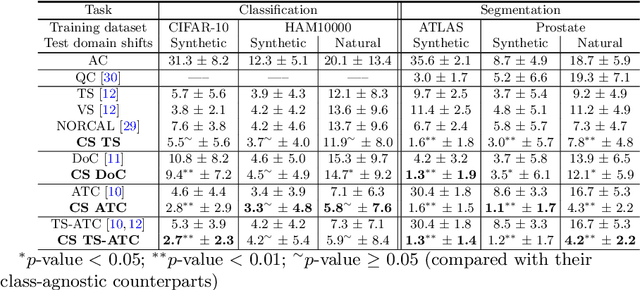
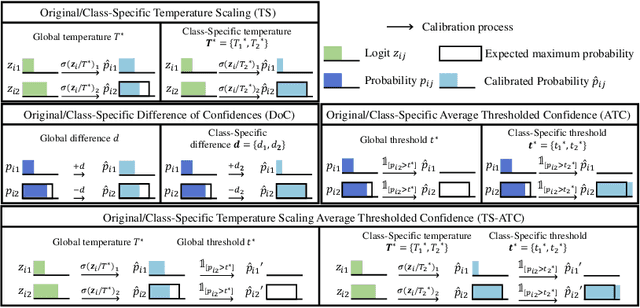
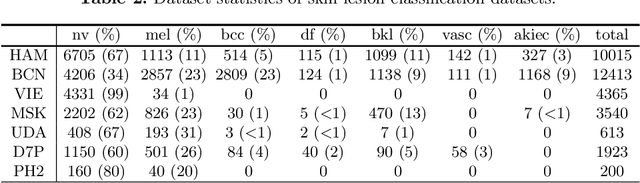
Machine learning models are typically deployed in a test setting that differs from the training setting, potentially leading to decreased model performance because of domain shift. If we could estimate the performance that a pre-trained model would achieve on data from a specific deployment setting, for example a certain clinic, we could judge whether the model could safely be deployed or if its performance degrades unacceptably on the specific data. Existing approaches estimate this based on the confidence of predictions made on unlabeled test data from the deployment's domain. We find existing methods struggle with data that present class imbalance, because the methods used to calibrate confidence do not account for bias induced by class imbalance, consequently failing to estimate class-wise accuracy. Here, we introduce class-wise calibration within the framework of performance estimation for imbalanced datasets. Specifically, we derive class-specific modifications of state-of-the-art confidence-based model evaluation methods including temperature scaling (TS), difference of confidences (DoC), and average thresholded confidence (ATC). We also extend the methods to estimate Dice similarity coefficient (DSC) in image segmentation. We conduct experiments on four tasks and find the proposed modifications consistently improve the estimation accuracy for imbalanced datasets. Our methods improve accuracy estimation by 18\% in classification under natural domain shifts, and double the estimation accuracy on segmentation tasks, when compared with prior methods.
Water Surface Patch Classification Using Mixture Augmentation for River Scum Index
Jul 13, 2022
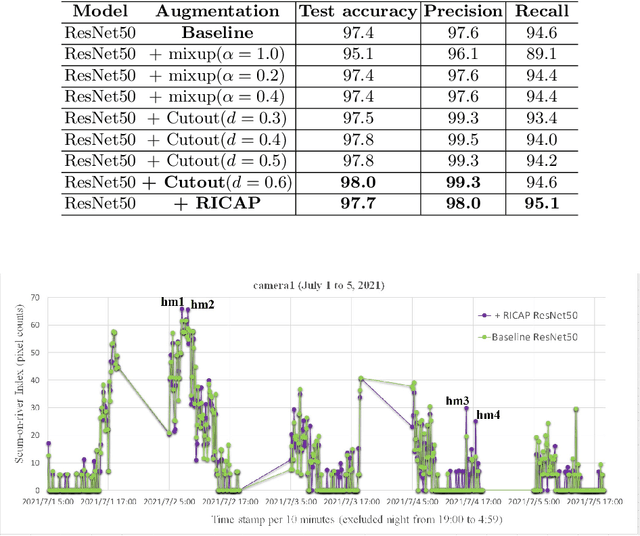
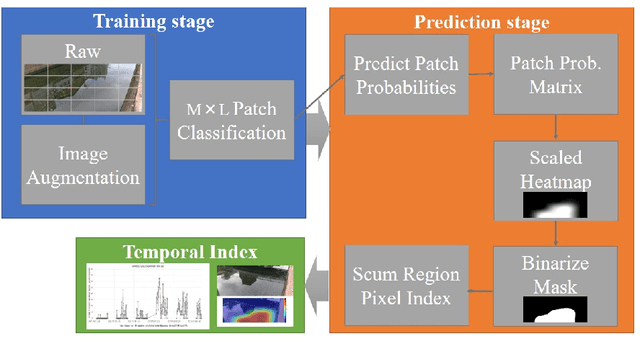

Urban rivers provide a water environment that influences residential living. River surface monitoring has become crucial for making decisions about where to prioritize cleaning and when to automatically start the cleaning treatment. We focus on the organic mud, or "scum" that accumulates on the river's surface and gives it its peculiar odor and external economic effects on the landscape. Because of its feature of a sparsely distributed and unstable pattern of organic shape, automating the monitoring has proved difficult. We propose a patch classification pipeline to detect scum features on the river surface using mixture image augmentation to increase the diversity between the scum floating on the river and the entangled background on the river surface reflected by nearby structures like buildings, bridges, poles, and barriers. Furthermore, we propose a scum index covered on rivers to help monitor worse grade online, collecting floating scum and deciding on chemical treatment policies. Finally, we show how to use our method on a time series dataset with frames every ten minutes recording river scum events over several days. We discuss the value of our pipeline and its experimental findings.
Uncertainty Quantified Deep Learning for Predicting Dice Coefficient of Digital Histopathology Image Segmentation
Aug 31, 2021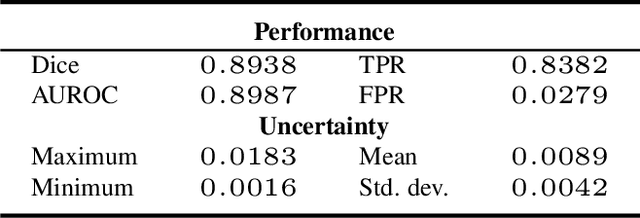
Deep learning models (DLMs) can achieve state of the art performance in medical image segmentation and classification tasks. However, DLMs that do not provide feedback for their predictions such as Dice coefficients (Dice) have limited deployment potential in real world clinical settings. Uncertainty estimates can increase the trust of these automated systems by identifying predictions that need further review but remain computationally prohibitive to deploy. In this study, we use a DLM with randomly initialized weights and Monte Carlo dropout (MCD) to segment tumors from microscopic Hematoxylin and Eosin (H&E) dye stained prostate core biopsy RGB images. We devise a novel approach that uses multiple clinical region based uncertainties from a single image (instead of the entire image) to predict Dice of the DLM model output by linear models. Image level uncertainty maps were generated and showed correspondence between imperfect model segmentation and high levels of uncertainty associated with specific prostate tissue regions with or without tumors. Results from this study suggest that linear models can learn coefficients of uncertainty quantified deep learning and correlations ((Spearman's correlation (p<0.05)) to predict Dice scores of specific regions of medical images.
Symmetry-Aware Transformer-based Mirror Detection
Jul 13, 2022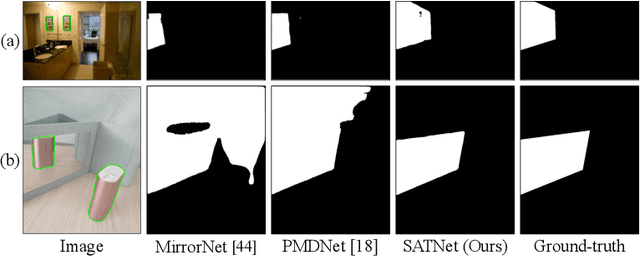
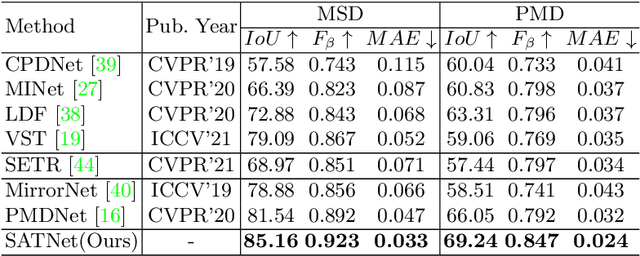
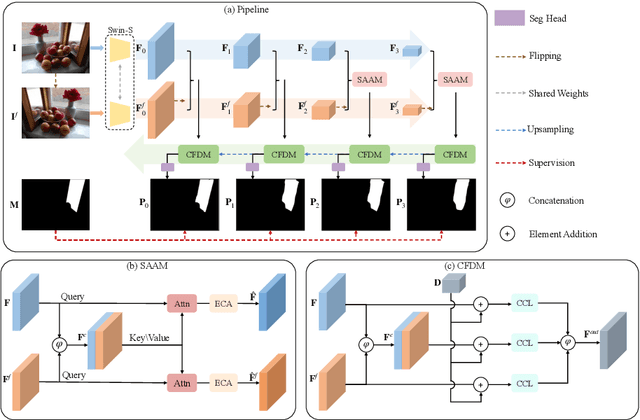
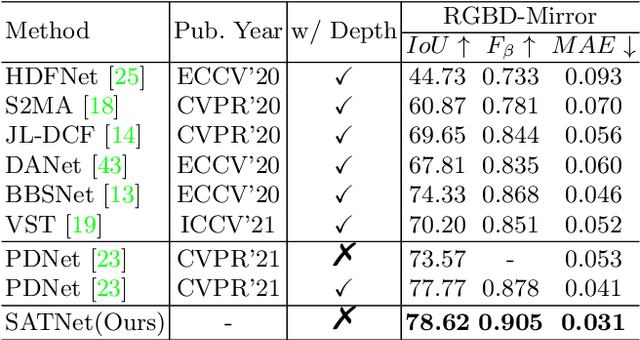
Mirror detection aims to identify the mirror regions in the given input image. Existing works mainly focus on integrating the semantic features and structural features to mine the similarity and discontinuity between mirror and non-mirror regions, or introducing depth information to help analyze the existence of mirrors. In this work, we observe that a real object typically forms a loose symmetry relationship with its corresponding reflection in the mirror, which is beneficial in distinguishing mirrors from real objects. Based on this observation, we propose a dual-path Symmetry-Aware Transformer-based mirror detection Network (SATNet), which includes two novel modules: Symmetry-Aware Attention Module (SAAM) and Contrast and Fusion Decoder Module (CFDM). Specifically, we first introduce the transformer backbone to model global information aggregation in images, extracting multi-scale features in two paths. We then feed the high-level dual-path features to SAAMs to capture the symmetry relations. Finally, we fuse the dual-path features and refine our prediction maps progressively with CFDMs to obtain the final mirror mask. Experimental results show that SATNet outperforms both RGB and RGB-D mirror detection methods on all available mirror detection datasets.
Masked Siamese Networks for Label-Efficient Learning
Apr 14, 2022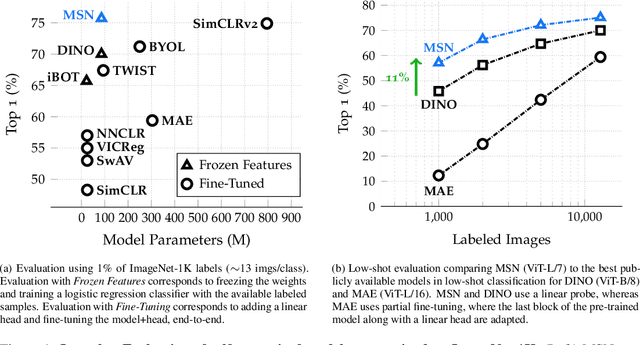
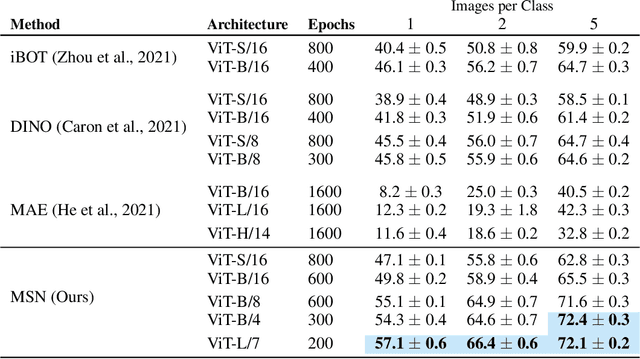

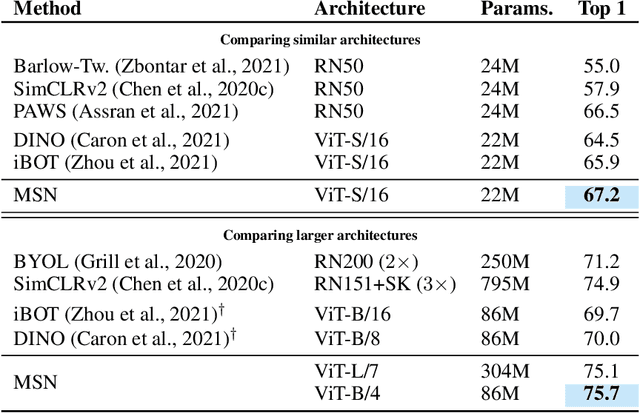
We propose Masked Siamese Networks (MSN), a self-supervised learning framework for learning image representations. Our approach matches the representation of an image view containing randomly masked patches to the representation of the original unmasked image. This self-supervised pre-training strategy is particularly scalable when applied to Vision Transformers since only the unmasked patches are processed by the network. As a result, MSNs improve the scalability of joint-embedding architectures, while producing representations of a high semantic level that perform competitively on low-shot image classification. For instance, on ImageNet-1K, with only 5,000 annotated images, our base MSN model achieves 72.4% top-1 accuracy, and with 1% of ImageNet-1K labels, we achieve 75.7% top-1 accuracy, setting a new state-of-the-art for self-supervised learning on this benchmark. Our code is publicly available.
RGB-D Robotic Pose Estimation For a Servicing Robotic Arm
Jul 23, 2022



A large number of robotic and human-assisted missions to the Moon and Mars are forecast. NASA's efforts to learn about the geology and makeup of these celestial bodies rely heavily on the use of robotic arms. The safety and redundancy aspects will be crucial when humans will be working alongside the robotic explorers. Additionally, robotic arms are crucial to satellite servicing and planned orbit debris mitigation missions. The goal of this work is to create a custom Computer Vision (CV) based Artificial Neural Network (ANN) that would be able to rapidly identify the posture of a 7 Degree of Freedom (DoF) robotic arm from a single (RGB-D) image - just like humans can easily identify if an arm is pointing in some general direction. The Sawyer robotic arm is used for developing and training this intelligent algorithm. Since Sawyer's joint space spans 7 dimensions, it is an insurmountable task to cover the entire joint configuration space. In this work, orthogonal arrays are used, similar to the Taguchi method, to efficiently span the joint space with the minimal number of training images. This ``optimally'' generated database is used to train the custom ANN and its degree of accuracy is on average equal to twice the smallest joint displacement step used for database generation. A pre-trained ANN will be useful for estimating the postures of robotic manipulators used on space stations, spacecraft, and rovers as an auxiliary tool or for contingency plans.
Misleading Deep-Fake Detection with GAN Fingerprints
May 25, 2022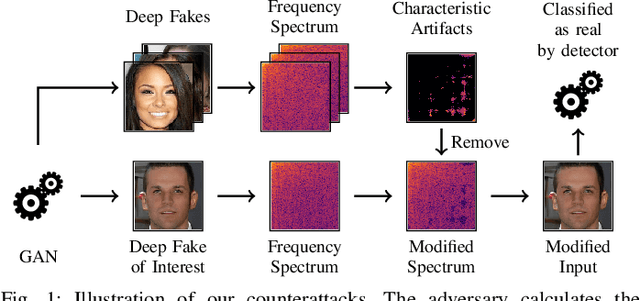
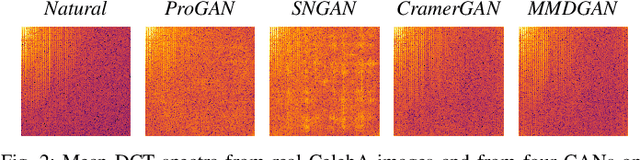
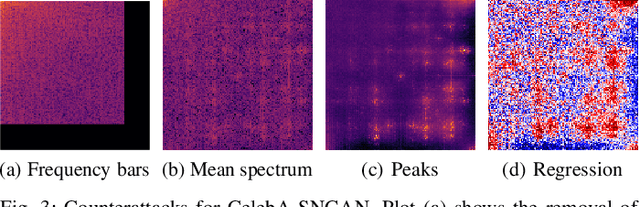

Generative adversarial networks (GANs) have made remarkable progress in synthesizing realistic-looking images that effectively outsmart even humans. Although several detection methods can recognize these deep fakes by checking for image artifacts from the generation process, multiple counterattacks have demonstrated their limitations. These attacks, however, still require certain conditions to hold, such as interacting with the detection method or adjusting the GAN directly. In this paper, we introduce a novel class of simple counterattacks that overcomes these limitations. In particular, we show that an adversary can remove indicative artifacts, the GAN fingerprint, directly from the frequency spectrum of a generated image. We explore different realizations of this removal, ranging from filtering high frequencies to more nuanced frequency-peak cleansing. We evaluate the performance of our attack with different detection methods, GAN architectures, and datasets. Our results show that an adversary can often remove GAN fingerprints and thus evade the detection of generated images.
Dynamic Time Warping based Adversarial Framework for Time-Series Domain
Jul 09, 2022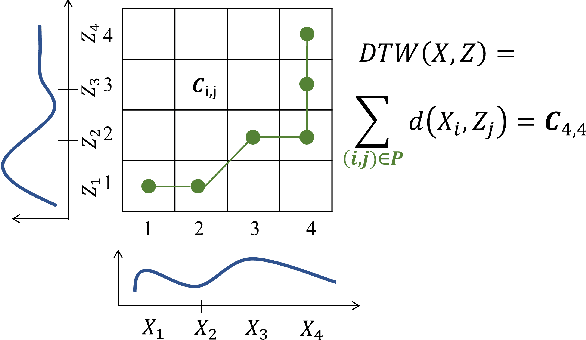
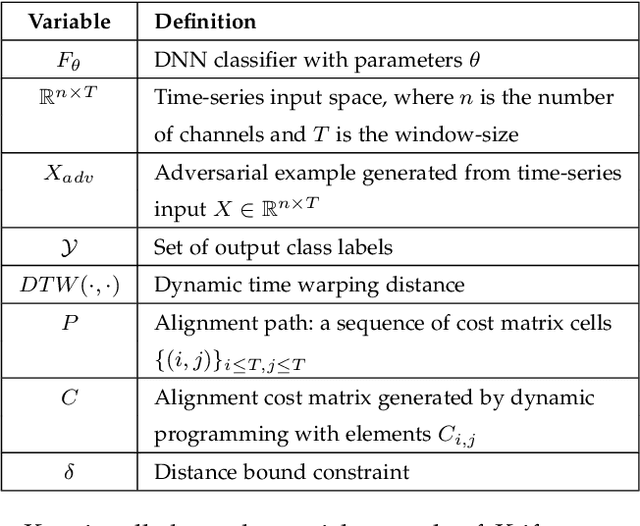
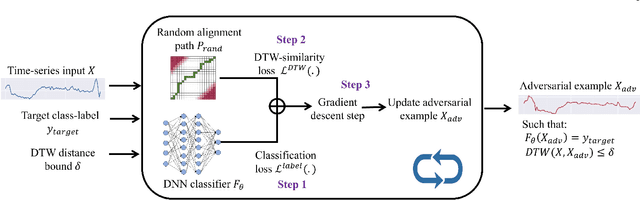
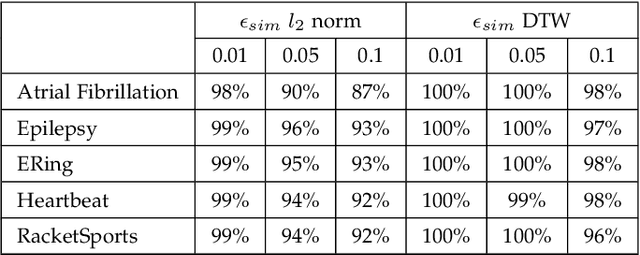
Despite the rapid progress on research in adversarial robustness of deep neural networks (DNNs), there is little principled work for the time-series domain. Since time-series data arises in diverse applications including mobile health, finance, and smart grid, it is important to verify and improve the robustness of DNNs for the time-series domain. In this paper, we propose a novel framework for the time-series domain referred as {\em Dynamic Time Warping for Adversarial Robustness (DTW-AR)} using the dynamic time warping measure. Theoretical and empirical evidence is provided to demonstrate the effectiveness of DTW over the standard Euclidean distance metric employed in prior methods for the image domain. We develop a principled algorithm justified by theoretical analysis to efficiently create diverse adversarial examples using random alignment paths. Experiments on diverse real-world benchmarks show the effectiveness of DTW-AR to fool DNNs for time-series data and to improve their robustness using adversarial training. The source code of DTW-AR algorithms is available at https://github.com/tahabelkhouja/DTW-AR
Dual-Branch Squeeze-Fusion-Excitation Module for Cross-Modality Registration of Cardiac SPECT and CT
Jun 10, 2022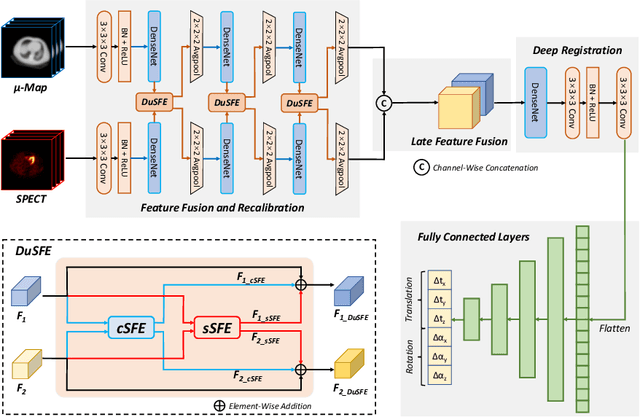
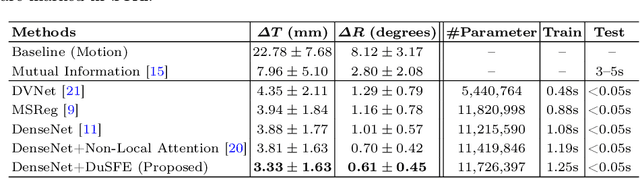
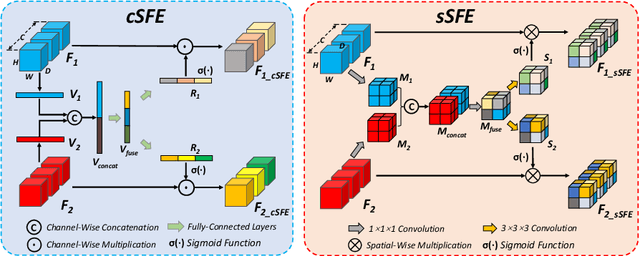
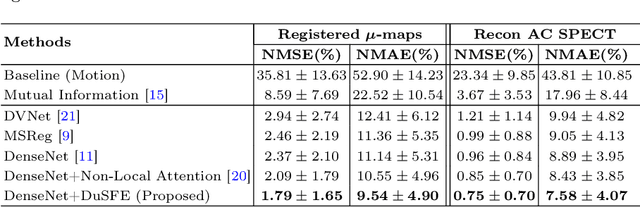
Single-photon emission computed tomography (SPECT) is a widely applied imaging approach for diagnosis of coronary artery diseases. Attenuation maps (u-maps) derived from computed tomography (CT) are utilized for attenuation correction (AC) to improve diagnostic accuracy of cardiac SPECT. However, SPECT and CT are obtained sequentially in clinical practice, which potentially induces misregistration between the two scans. Convolutional neural networks (CNN) are powerful tools for medical image registration. Previous CNN-based methods for cross-modality registration either directly concatenated two input modalities as an early feature fusion or extracted image features using two separate CNN modules for a late fusion. These methods do not fully extract or fuse the cross-modality information. Besides, deep-learning-based rigid registration of cardiac SPECT and CT-derived u-maps has not been investigated before. In this paper, we propose a Dual-Branch Squeeze-Fusion-Excitation (DuSFE) module for the registration of cardiac SPECT and CT-derived u-maps. DuSFE fuses the knowledge from multiple modalities to recalibrate both channel-wise and spatial features for each modality. DuSFE can be embedded at multiple convolutional layers to enable feature fusion at different spatial dimensions. Our studies using clinical data demonstrated that a network embedded with DuSFE generated substantial lower registration errors and therefore more accurate AC SPECT images than previous methods.