 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ZoDIAC: Zoneout Dropout Injection Attention Calculation
Jun 28, 2022
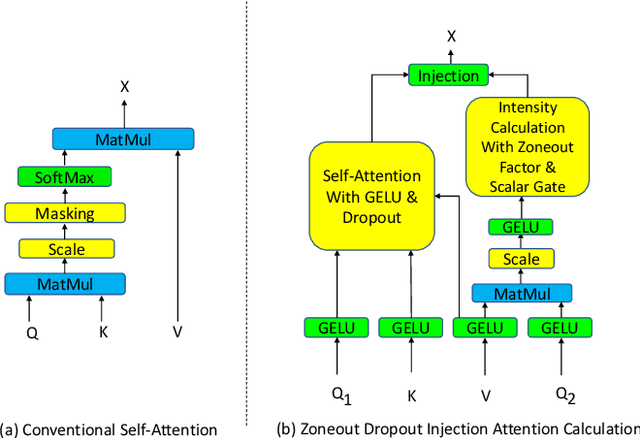
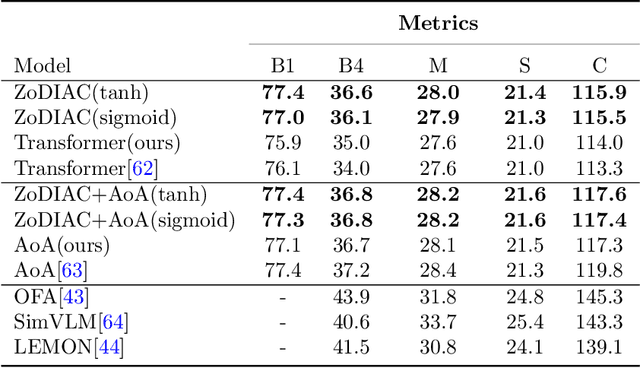
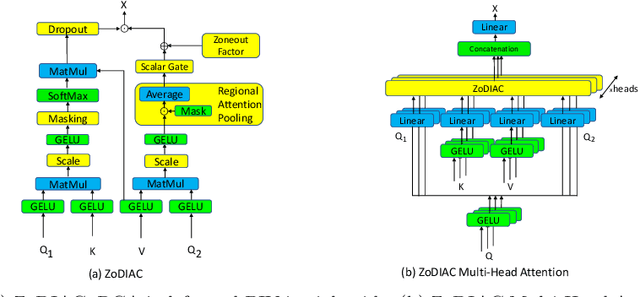
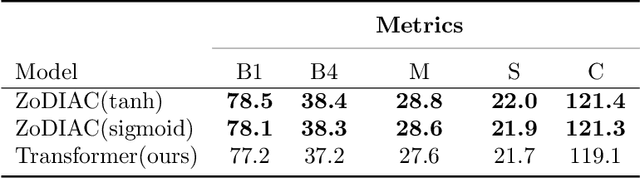
Recently the use of self-attention has yielded to state-of-the-art results in vision-language tasks such as image captioning as well as natural language understanding and generation (NLU and NLG) tasks and computer vision tasks such as image classification. This is since self-attention maps the internal interactions among the elements of input source and target sequences. Although self-attention successfully calculates the attention values and maps the relationships among the elements of input source and target sequence, yet there is no mechanism to control the intensity of attention. In real world, when communicating with each other face to face or vocally, we tend to express different visual and linguistic context with various amounts of intensity. Some words might carry (be spoken with) more stress and weight indicating the importance of that word in the context of the whole sentence. Based on this intuition, we propose Zoneout Dropout Injection Attention Calculation (ZoDIAC) in which the intensities of attention values in the elements of the input sequence are calculated with respect to the context of the elements of input sequence. The results of our experiments reveal that employing ZoDIAC leads to better performance in comparison with the self-attention module in the Transformer model. The ultimate goal is to find out if we could modify self-attention module in the Transformer model with a method that is potentially extensible to other models that leverage on self-attention at their core. Our findings suggest that this particular goal deserves further attention and investigation by the research community. The code for ZoDIAC is available on www.github.com/zanyarz/zodiac .
Forgetting Data from Pre-trained GANs
Jun 29, 2022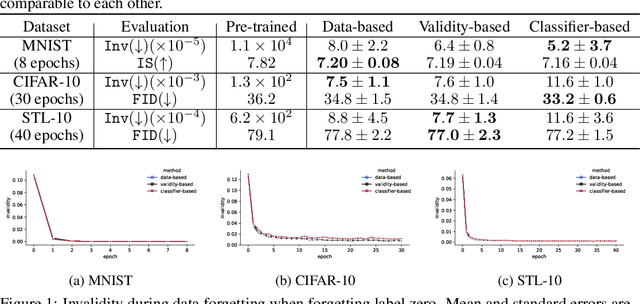
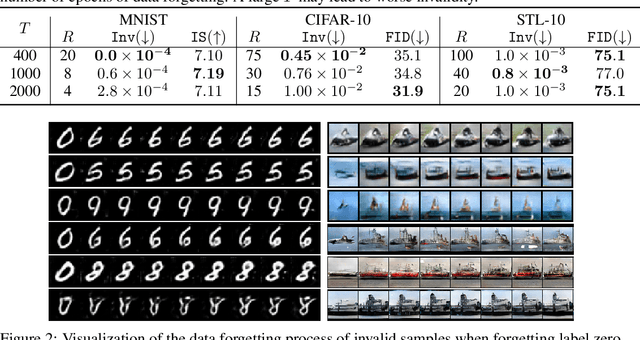


Large pre-trained generative models are known to occasionally provide samples that may be undesirable for various reasons. The standard way to mitigate this is to re-train the models differently. In this work, we take a different, more compute-friendly approach and investigate how to post-edit a model after training so that it forgets certain kinds of samples. We provide three different algorithms for GANs that differ on how the samples to be forgotten are described. Extensive evaluations on real-world image datasets show that our algorithms are capable of forgetting data while retaining high generation quality at a fraction of the cost of full re-training.
Unsupervised Deep Learning Meets Chan-Vese Model
Apr 14, 2022

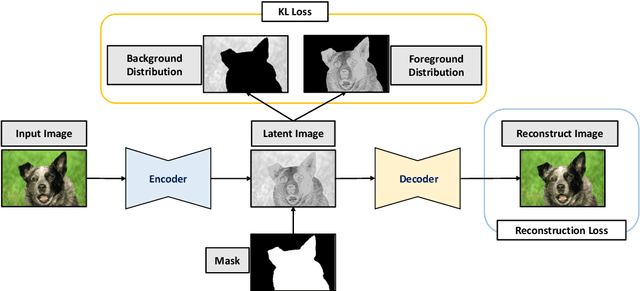
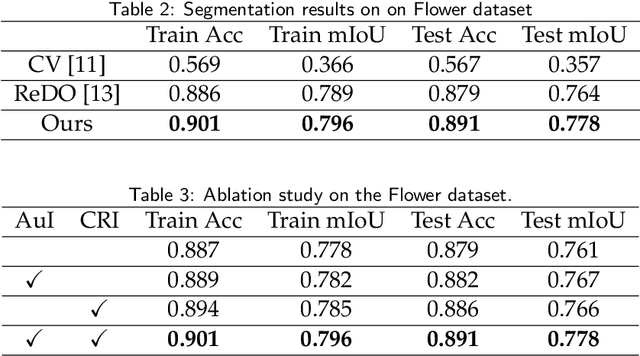
The Chan-Vese (CV) model is a classic region-based method in image segmentation. However, its piecewise constant assumption does not always hold for practical applications. Many improvements have been proposed but the issue is still far from well solved. In this work, we propose an unsupervised image segmentation approach that integrates the CV model with deep neural networks, which significantly improves the original CV model's segmentation accuracy. Our basic idea is to apply a deep neural network that maps the image into a latent space to alleviate the violation of the piecewise constant assumption in image space. We formulate this idea under the classic Bayesian framework by approximating the likelihood with an evidence lower bound (ELBO) term while keeping the prior term in the CV model. Thus, our model only needs the input image itself and does not require pre-training from external datasets. Moreover, we extend the idea to multi-phase case and dataset based unsupervised image segmentation. Extensive experiments validate the effectiveness of our model and show that the proposed method is noticeably better than other unsupervised segmentation approaches.
Efficient View Clustering and Selection for City-Scale 3D Reconstruction
Jul 18, 2022Image datasets have been steadily growing in size, harming the feasibility and efficiency of large-scale 3D reconstruction methods. In this paper, a novel approach for scaling Multi-View Stereo (MVS) algorithms up to arbitrarily large collections of images is proposed. Specifically, the problem of reconstructing the 3D model of an entire city is targeted, starting from a set of videos acquired by a moving vehicle equipped with several high-resolution cameras. Initially, the presented method exploits an approximately uniform distribution of poses and geometry and builds a set of overlapping clusters. Then, an Integer Linear Programming (ILP) problem is formulated for each cluster to select an optimal subset of views that guarantees both visibility and matchability. Finally, local point clouds for each cluster are separately computed and merged. Since clustering is independent from pairwise visibility information, the proposed algorithm runs faster than existing literature and allows for a massive parallelization. Extensive testing on urban data are discussed to show the effectiveness and the scalability of this approach.
Diversity aware image generation
Feb 19, 2022
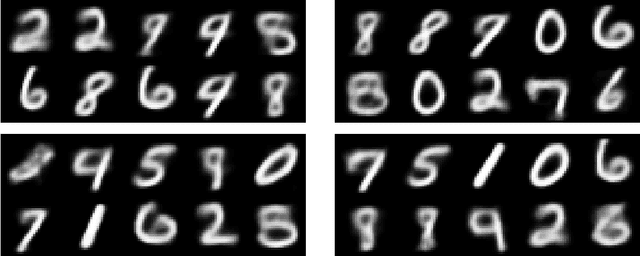
The machine learning generative algorithms such as GAN and VAE show impressive results in practice when constructing images similar to those in a training set. However, the generation of new images builds mainly on the understanding of the hidden structure of the training database followed by a mere sampling from a multi-dimensional normal variable. In particular each sample is independent from the other ones and can repeatedly propose same type of images. To cure this drawback we propose a kernel-based measure representation method that can produce new objects from a given target measure by approximating the measure as a whole and even staying away from objects already drawn from that distribution. This ensures a better variety of the produced images. The method is tested on some classic machine learning benchmarks.\end{abstract}
Learning Generalizable Latent Representations for Novel Degradations in Super Resolution
Jul 25, 2022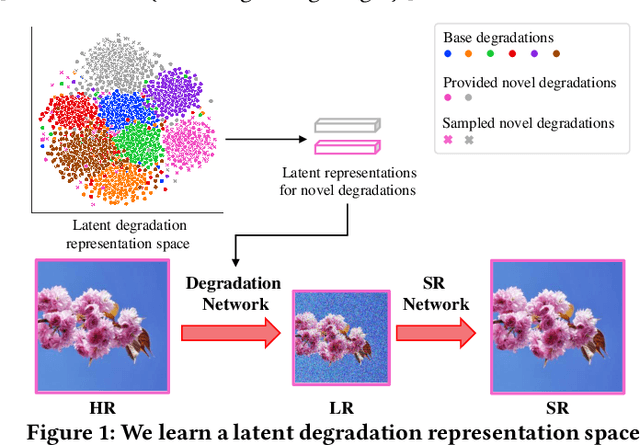

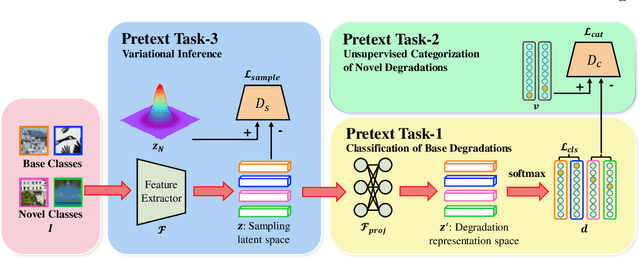
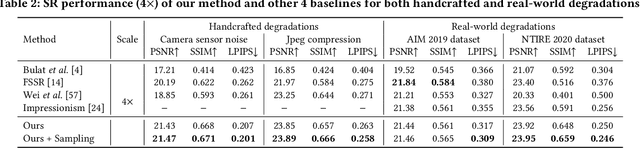
Typical methods for blind image super-resolution (SR) focus on dealing with unknown degradations by directly estimating them or learning the degradation representations in a latent space. A potential limitation of these methods is that they assume the unknown degradations can be simulated by the integration of various handcrafted degradations (e.g., bicubic downsampling), which is not necessarily true. The real-world degradations can be beyond the simulation scope by the handcrafted degradations, which are referred to as novel degradations. In this work, we propose to learn a latent representation space for degradations, which can be generalized from handcrafted (base) degradations to novel degradations. The obtained representations for a novel degradation in this latent space are then leveraged to generate degraded images consistent with the novel degradation to compose paired training data for SR model. Furthermore, we perform variational inference to match the posterior of degradations in latent representation space with a prior distribution (e.g., Gaussian distribution). Consequently, we are able to sample more high-quality representations for a novel degradation to augment the training data for SR model. We conduct extensive experiments on both synthetic and real-world datasets to validate the effectiveness and advantages of our method for blind super-resolution with novel degradations.
Orthogonalization of data via Gromov-Wasserstein type feedback for clustering and visualization
Jul 25, 2022

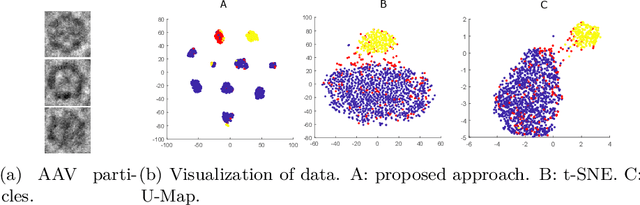
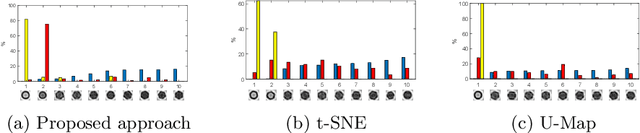
In this paper we propose an adaptive approach for clustering and visualization of data by an orthogonalization process. Starting with the data points being represented by a Markov process using the diffusion map framework, the method adaptively increase the orthogonality of the clusters by applying a feedback mechanism inspired by the Gromov-Wasserstein distance. This mechanism iteratively increases the spectral gap and refines the orthogonality of the data to achieve a clustering with high specificity. By using the diffusion map framework and representing the relation between data points using transition probabilities, the method is robust with respect to both the underlying distance, noise in the data and random initialization. We prove that the method converges globally to a unique fixpoint for certain parameter values. We also propose a related approach where the transition probabilities in the Markov process are required to be doubly stochastic, in which case the method generates a minimizer to a nonconvex optimization problem. We apply the method on cryo-electron microscopy image data from biopharmaceutical manufacturing where we can confirm biologically relevant insights related to therapeutic efficacy. We consider an example with morphological variations of gene packaging and confirm that the method produces biologically meaningful clustering results consistent with human expert classification.
Uncertainty-aware Multi-modal Learning via Cross-modal Random Network Prediction
Jul 22, 2022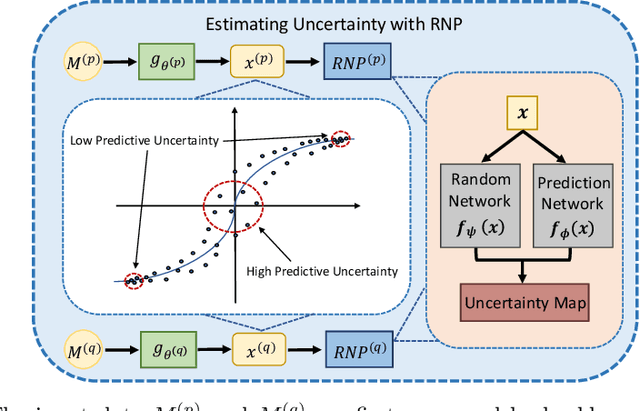
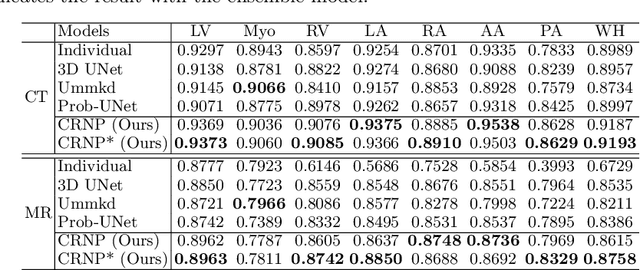
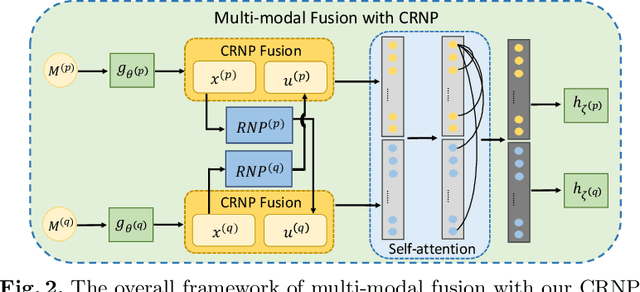
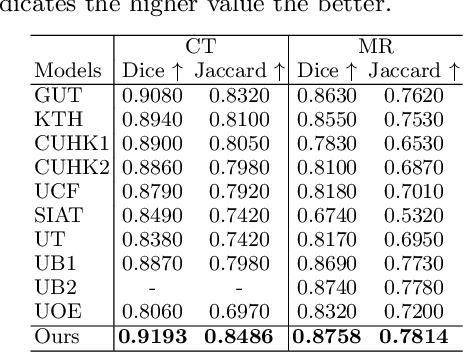
Multi-modal learning focuses on training models by equally combining multiple input data modalities during the prediction process. However, this equal combination can be detrimental to the prediction accuracy because different modalities are usually accompanied by varying levels of uncertainty. Using such uncertainty to combine modalities has been studied by a couple of approaches, but with limited success because these approaches are either designed to deal with specific classification or segmentation problems and cannot be easily translated into other tasks, or suffer from numerical instabilities. In this paper, we propose a new Uncertainty-aware Multi-modal Learner that estimates uncertainty by measuring feature density via Cross-modal Random Network Prediction (CRNP). CRNP is designed to require little adaptation to translate between different prediction tasks, while having a stable training process. From a technical point of view, CRNP is the first approach to explore random network prediction to estimate uncertainty and to combine multi-modal data. Experiments on two 3D multi-modal medical image segmentation tasks and three 2D multi-modal computer vision classification tasks show the effectiveness, adaptability and robustness of CRNP. Also, we provide an extensive discussion on different fusion functions and visualization to validate the proposed model.
DEXTER: An end-to-end system to extract table contents from electronic medical health documents
Jul 18, 2022
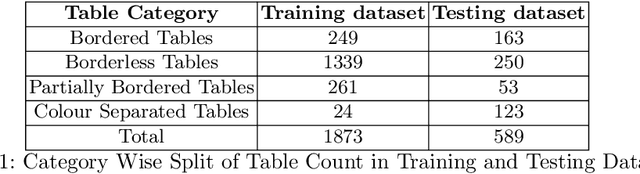
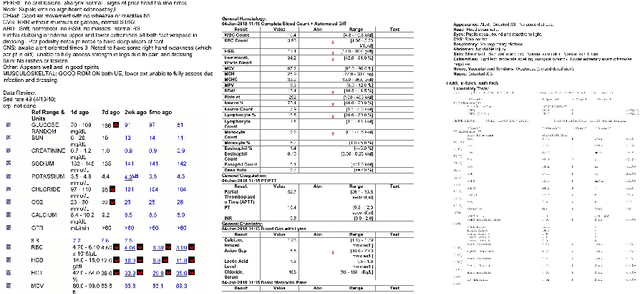
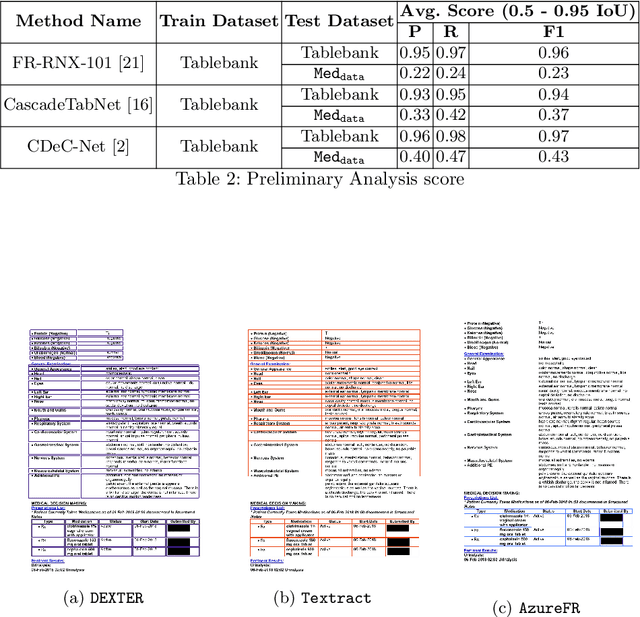
In this paper, we propose DEXTER, an end to end system to extract information from tables present in medical health documents, such as electronic health records (EHR) and explanation of benefits (EOB). DEXTER consists of four sub-system stages: i) table detection ii) table type classification iii) cell detection; and iv) cell content extraction. We propose a two-stage transfer learning-based approach using CDeC-Net architecture along with Non-Maximal suppression for table detection. We design a conventional computer vision-based approach for table type classification and cell detection using parameterized kernels based on image size for detecting rows and columns. Finally, we extract the text from the detected cells using pre-existing OCR engine Tessaract. To evaluate our system, we manually annotated a sample of the real-world medical dataset (referred to as Meddata) consisting of wide variations of documents (in terms of appearance) covering different table structures, such as bordered, partially bordered, borderless, or coloured tables. We experimentally show that DEXTER outperforms the commercially available Amazon Textract and Microsoft Azure Form Recognizer systems on the annotated real-world medical dataset
Learning Convolutional Neural Networks in the Frequency Domain
Apr 28, 2022
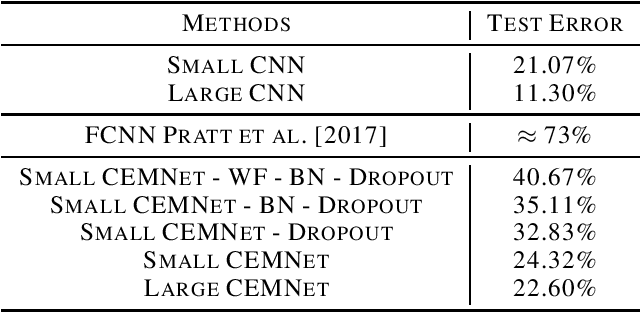
Convolutional neural network (CNN) has achieved impressive success in computer vision during the past few decades. The image convolution operation helps CNNs to get good performance on image-related tasks. However, the image convolution has high computation complexity and hard to be implemented. This paper proposes the CEMNet, which can be trained in the frequency domain. The most important motivation of this research is that we can use the straightforward element-wise multiplication operation to replace the image convolution in the frequency domain based on the Cross-Correlation Theorem, which obviously reduces the computation complexity. We further introduce a Weight Fixation mechanism to alleviate the problem of over-fitting, and analyze the working behavior of Batch Normalization, Leaky ReLU, and Dropout in the frequency domain to design their counterparts for CEMNet. Also, to deal with complex inputs brought by Discrete Fourier Transform, we design a two-branches network structure for CEMNet. Experimental results imply that CEMNet achieves good performance on MNIST and CIFAR-10 databases.