 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning to translate by learning to communicate
Jul 14, 2022
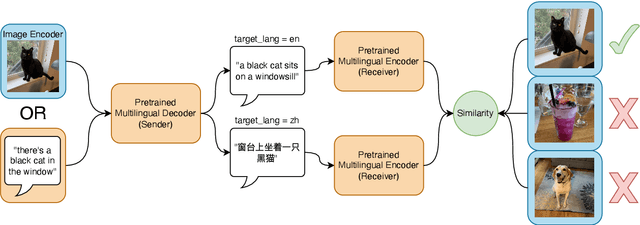
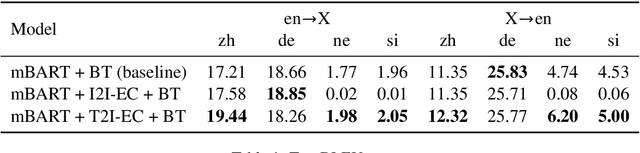
We formulate and test a technique to use Emergent Communication (EC) with a pretrained multilingual model to improve on modern Unsupervised NMT systems, especially for low-resource languages. It has been argued that the currently dominant paradigm in NLP of pretraining on text-only corpora will not yield robust natural language understanding systems, and the need for grounded, goal-oriented, and interactive language learning has been highlighted. In our approach, we embed a modern multilingual model (mBART, Liu et. al. 2020) into an EC image-reference game, in which the model is incentivized to use multilingual generations to accomplish a vision-grounded task, with the hypothesis that this will align multiple languages to a shared task space. We present two variants of EC Fine-Tuning (Steinert-Threlkeld et. al. 2022), one of which outperforms a backtranslation-based baseline in 6/8 translation settings, and proves especially beneficial for the very low-resource languages of Nepali and Sinhala.
SSEGEP: Small SEGment Emphasized Performance evaluation metric for medical image segmentation
Sep 08, 2021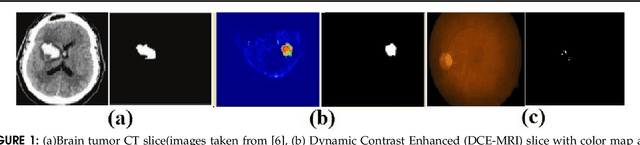


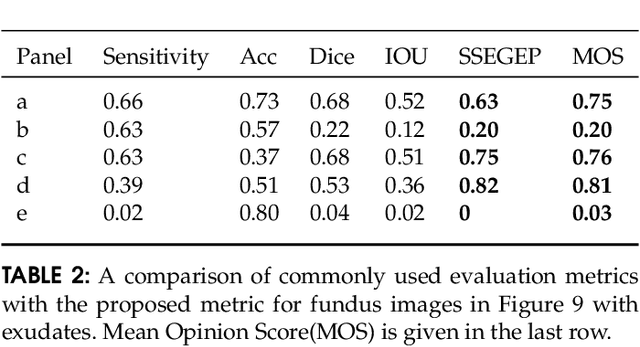
Automatic image segmentation is a critical component of medical image analysis, and hence quantifying segmentation performance is crucial. Challenges in medical image segmentation are mainly due to spatial variations of regions to be segmented and imbalance in distribution of classes. Commonly used metrics treat all detected pixels, indiscriminately. However, pixels in smaller segments must be treated differently from pixels in larger segments, as detection of smaller ones aid in early treatment of associated disease and are also easier to miss. To address this, we propose a novel evaluation metric for segmentation performance, emphasizing smaller segments, by assigning higher weightage to smaller segment pixels. Weighted false positives are also considered in deriving the new metric named, "SSEGEP"(Small SEGment Emphasized Performance evaluation metric), (range : 0(Bad) to 1(Good)). The experiments were performed on diverse anatomies(eye, liver, pancreas and breast) from publicly available datasets to show applicability of the proposed metric across different imaging techniques. Mean opinion score (MOS) and statistical significance testing is used to quantify the relevance of proposed approach. Across 33 fundus images, where the largest exudate is 1.41%, and the smallest is 0.0002% of the image, the proposed metric is 30% closer to MOS, as compared to Dice Similarity Coefficient (DSC). Statistical significance testing resulted in promising p-value of order 10^{-18} with SSEGEP for hepatic tumor compared to DSC. The proposed metric is found to perform better for the images having multiple segments for a single label.
Layered Cost-Map-Based Traffic Management for Multiple Automated Mobile Robots via a Data Distribution Service
Jul 18, 2022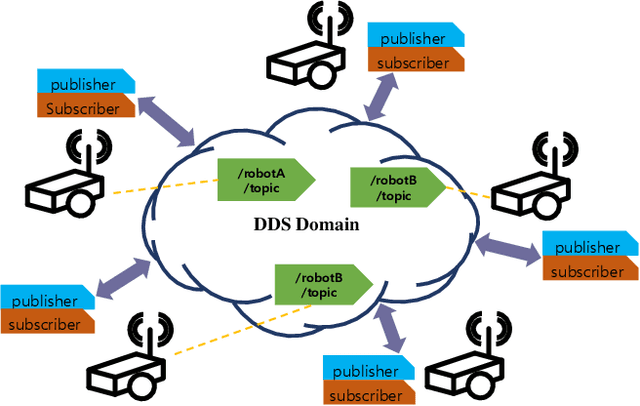
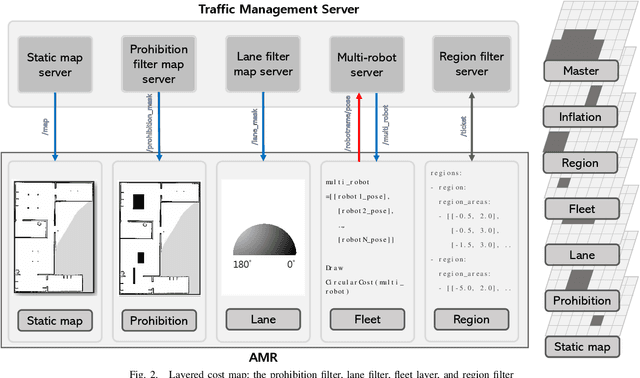

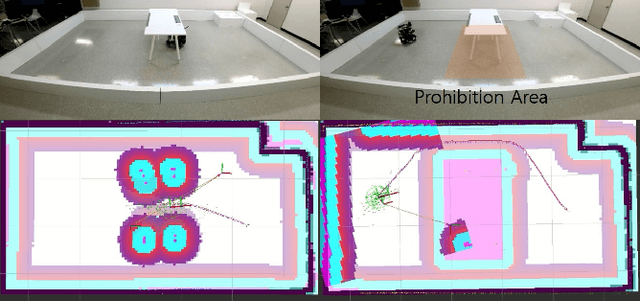
This letter proposes traffic management for multiple automated mobile robots (AMRs) based on a layered cost map. Multiple AMRs communicate via a data distribution service (DDS), which is shared by topics in the same DDS domain. The cost of each layer is manipulated by topics. The traffic management server in the domain sends or receives topics to each of AMRs. Using the layered cost map, the new concept of prohibition filter, lane filter, fleet layer, and region filter are proposed and implemented. The prohibition filter can help a user set an area that would prohibit an AMR from trespassing. The lane filter can help set one-way directions based on an angle image. The fleet layer can help AMRs share their locations via the traffic management server. The region filter requests for or receives an exclusive area, which can be occupied by only one AMR, from the traffic management server. All the layers are experimentally validated with real-world AMRs. Each area can be configured with user-defined images or text-based parameter files.
No-Reference Image Quality Assessment via Transformers, Relative Ranking, and Self-Consistency
Aug 16, 2021
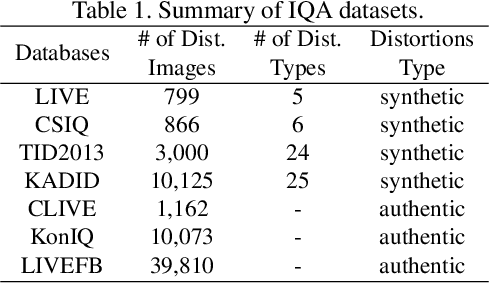
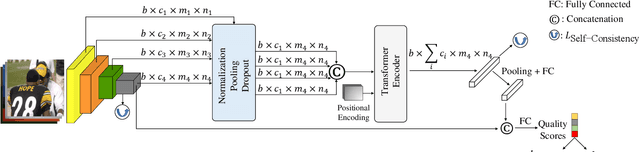
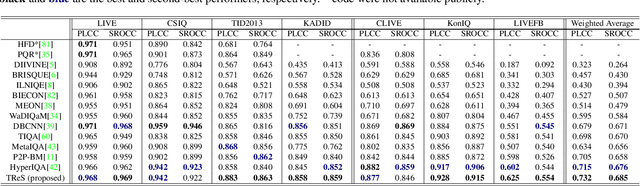
The goal of No-Reference Image Quality Assessment (NR-IQA) is to estimate the perceptual image quality in accordance with subjective evaluations, it is a complex and unsolved problem due to the absence of the pristine reference image. In this paper, we propose a novel model to address the NR-IQA task by leveraging a hybrid approach that benefits from Convolutional Neural Networks (CNNs) and self-attention mechanism in Transformers to extract both local and non-local features from the input image. We capture local structure information of the image via CNNs, then to circumvent the locality bias among the extracted CNNs features and obtain a non-local representation of the image, we utilize Transformers on the extracted features where we model them as a sequential input to the Transformer model. Furthermore, to improve the monotonicity correlation between the subjective and objective scores, we utilize the relative distance information among the images within each batch and enforce the relative ranking among them. Last but not least, we observe that the performance of NR-IQA models degrades when we apply equivariant transformations (e.g. horizontal flipping) to the inputs. Therefore, we propose a method that leverages self-consistency as a source of self-supervision to improve the robustness of NRIQA models. Specifically, we enforce self-consistency between the outputs of our quality assessment model for each image and its transformation (horizontally flipped) to utilize the rich self-supervisory information and reduce the uncertainty of the model. To demonstrate the effectiveness of our work, we evaluate it on seven standard IQA datasets (both synthetic and authentic) and show that our model achieves state-of-the-art results on various datasets.
Semi-supervised Contrastive Learning for Label-efficient Medical Image Segmentation
Sep 15, 2021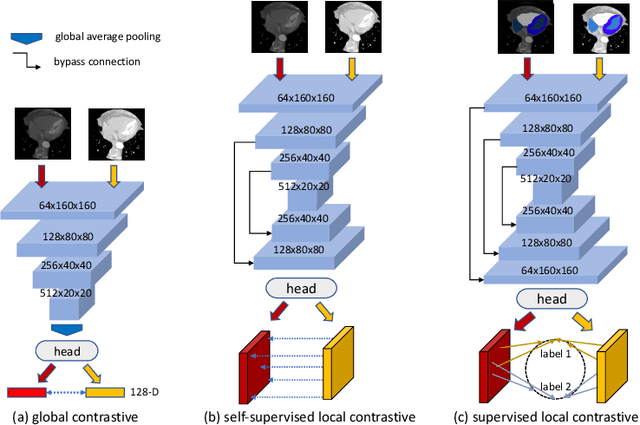
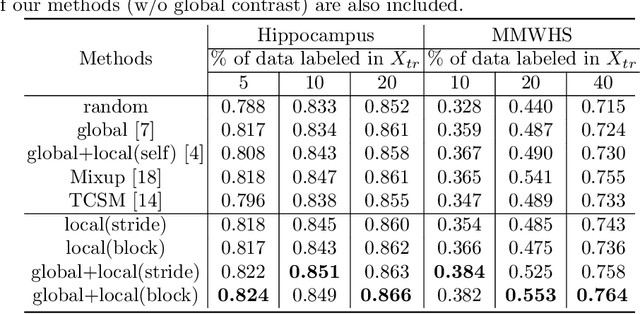
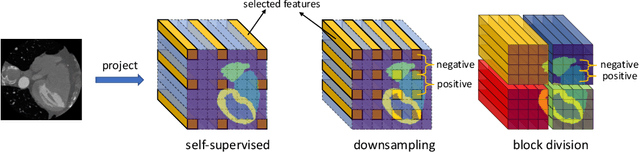
The success of deep learning methods in medical image segmentation tasks heavily depends on a large amount of labeled data to supervise the training. On the other hand, the annotation of biomedical images requires domain knowledge and can be laborious. Recently, contrastive learning has demonstrated great potential in learning latent representation of images even without any label. Existing works have explored its application to biomedical image segmentation where only a small portion of data is labeled, through a pre-training phase based on self-supervised contrastive learning without using any labels followed by a supervised fine-tuning phase on the labeled portion of data only. In this paper, we establish that by including the limited label in formation in the pre-training phase, it is possible to boost the performance of contrastive learning. We propose a supervised local contrastive loss that leverages limited pixel-wise annotation to force pixels with the same label to gather around in the embedding space. Such loss needs pixel-wise computation which can be expensive for large images, and we further propose two strategies, downsampling and block division, to address the issue. We evaluate our methods on two public biomedical image datasets of different modalities. With different amounts of labeled data, our methods consistently outperform the state-of-the-art contrast-based methods and other semi-supervised learning techniques.
A Latent Encoder Coupled Generative Adversarial Network (LE-GAN) for Efficient Hyperspectral Image Super-resolution
Nov 16, 2021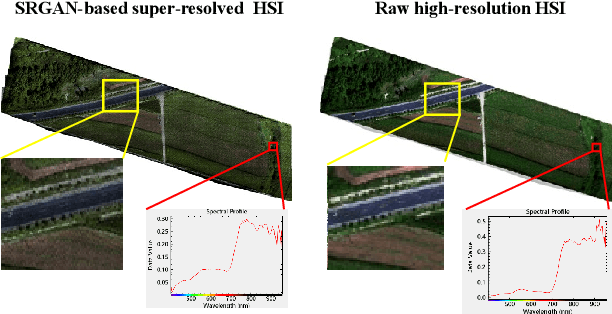
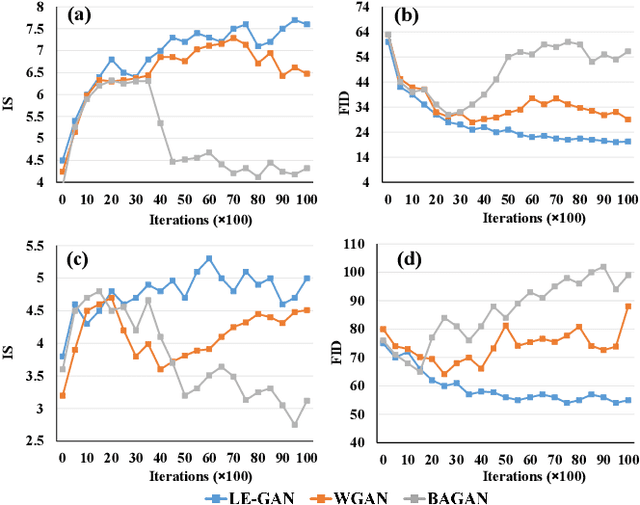
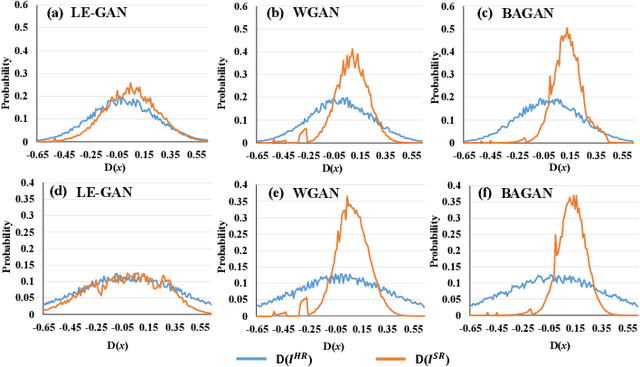
Realistic hyperspectral image (HSI) super-resolution (SR) techniques aim to generate a high-resolution (HR) HSI with higher spectral and spatial fidelity from its low-resolution (LR) counterpart. The generative adversarial network (GAN) has proven to be an effective deep learning framework for image super-resolution. However, the optimisation process of existing GAN-based models frequently suffers from the problem of mode collapse, leading to the limited capacity of spectral-spatial invariant reconstruction. This may cause the spectral-spatial distortion on the generated HSI, especially with a large upscaling factor. To alleviate the problem of mode collapse, this work has proposed a novel GAN model coupled with a latent encoder (LE-GAN), which can map the generated spectral-spatial features from the image space to the latent space and produce a coupling component to regularise the generated samples. Essentially, we treat an HSI as a high-dimensional manifold embedded in a latent space. Thus, the optimisation of GAN models is converted to the problem of learning the distributions of high-resolution HSI samples in the latent space, making the distributions of the generated super-resolution HSIs closer to those of their original high-resolution counterparts. We have conducted experimental evaluations on the model performance of super-resolution and its capability in alleviating mode collapse. The proposed approach has been tested and validated based on two real HSI datasets with different sensors (i.e. AVIRIS and UHD-185) for various upscaling factors and added noise levels, and compared with the state-of-the-art super-resolution models (i.e. HyCoNet, LTTR, BAGAN, SR- GAN, WGAN).
Certified Adversarial Robustness via Anisotropic Randomized Smoothing
Jul 12, 2022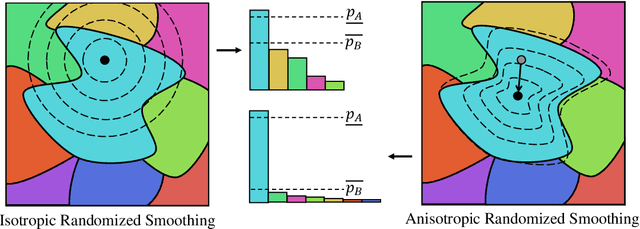



Randomized smoothing has achieved great success for certified robustness against adversarial perturbations. Given any arbitrary classifier, randomized smoothing can guarantee the classifier's prediction over the perturbed input with provable robustness bound by injecting noise into the classifier. However, all of the existing methods rely on fixed i.i.d. probability distribution to generate noise for all dimensions of the data (e.g., all the pixels in an image), which ignores the heterogeneity of inputs and data dimensions. Thus, existing randomized smoothing methods cannot provide optimal protection for all the inputs. To address this limitation, we propose the first anisotropic randomized smoothing method which ensures provable robustness guarantee based on pixel-wise noise distributions. Also, we design a novel CNN-based noise generator to efficiently fine-tune the pixel-wise noise distributions for all the pixels in each input. Experimental results demonstrate that our method significantly outperforms the state-of-the-art randomized smoothing methods.
QueryProp: Object Query Propagation for High-Performance Video Object Detection
Jul 22, 2022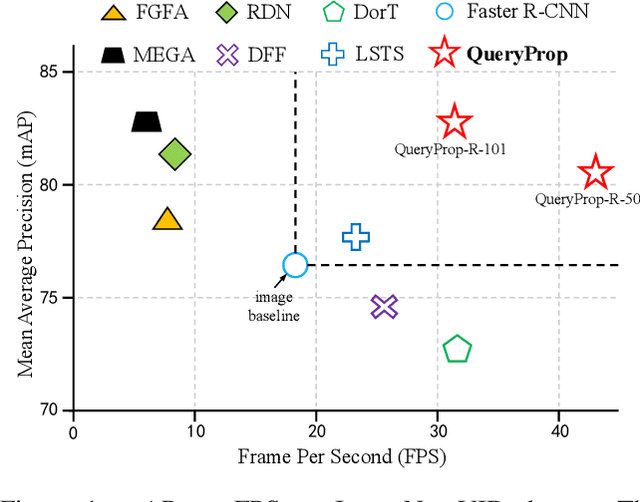
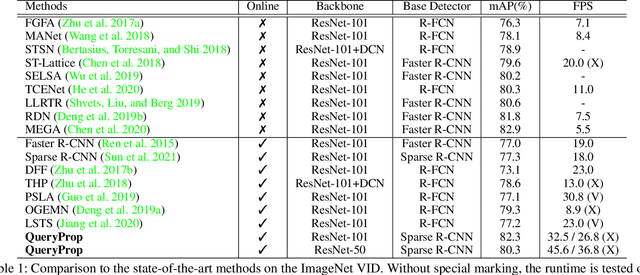
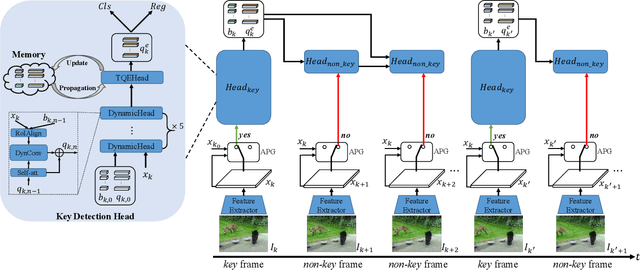
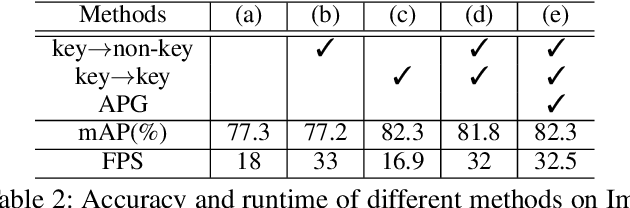
Video object detection has been an important yet challenging topic in computer vision. Traditional methods mainly focus on designing the image-level or box-level feature propagation strategies to exploit temporal information. This paper argues that with a more effective and efficient feature propagation framework, video object detectors can gain improvement in terms of both accuracy and speed. For this purpose, this paper studies object-level feature propagation, and proposes an object query propagation (QueryProp) framework for high-performance video object detection. The proposed QueryProp contains two propagation strategies: 1) query propagation is performed from sparse key frames to dense non-key frames to reduce the redundant computation on non-key frames; 2) query propagation is performed from previous key frames to the current key frame to improve feature representation by temporal context modeling. To further facilitate query propagation, an adaptive propagation gate is designed to achieve flexible key frame selection. We conduct extensive experiments on the ImageNet VID dataset. QueryProp achieves comparable accuracy with state-of-the-art methods and strikes a decent accuracy/speed trade-off. Code is available at https://github.com/hf1995/QueryProp.
An Empirical Investigation of Representation Learning for Imitation
May 16, 2022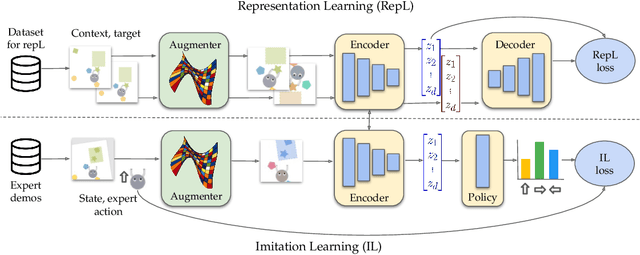
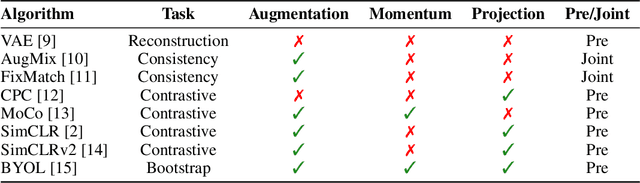

Imitation learning often needs a large demonstration set in order to handle the full range of situations that an agent might find itself in during deployment. However, collecting expert demonstrations can be expensive. Recent work in vision, reinforcement learning, and NLP has shown that auxiliary representation learning objectives can reduce the need for large amounts of expensive, task-specific data. Our Empirical Investigation of Representation Learning for Imitation (EIRLI) investigates whether similar benefits apply to imitation learning. We propose a modular framework for constructing representation learning algorithms, then use our framework to evaluate the utility of representation learning for imitation across several environment suites. In the settings we evaluate, we find that existing algorithms for image-based representation learning provide limited value relative to a well-tuned baseline with image augmentations. To explain this result, we investigate differences between imitation learning and other settings where representation learning has provided significant benefit, such as image classification. Finally, we release a well-documented codebase which both replicates our findings and provides a modular framework for creating new representation learning algorithms out of reusable components.
Diversity aware image generation
Feb 19, 2022
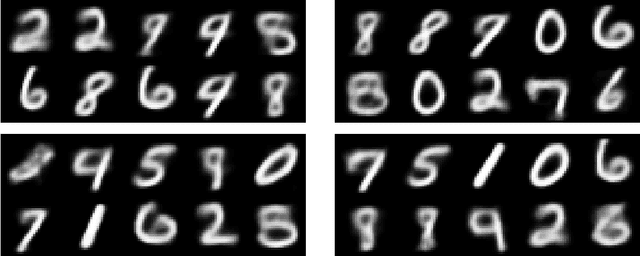
The machine learning generative algorithms such as GAN and VAE show impressive results in practice when constructing images similar to those in a training set. However, the generation of new images builds mainly on the understanding of the hidden structure of the training database followed by a mere sampling from a multi-dimensional normal variable. In particular each sample is independent from the other ones and can repeatedly propose same type of images. To cure this drawback we propose a kernel-based measure representation method that can produce new objects from a given target measure by approximating the measure as a whole and even staying away from objects already drawn from that distribution. This ensures a better variety of the produced images. The method is tested on some classic machine learning benchmarks.\end{abstract}