 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Topologically-Aware Deformation Fields for Single-View 3D Reconstruction
May 21, 2022
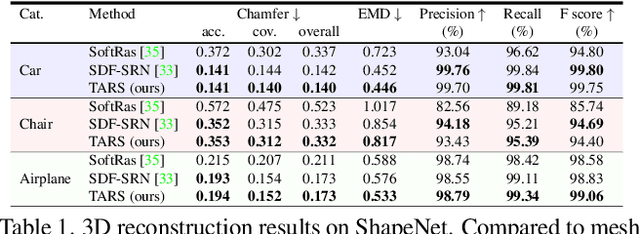
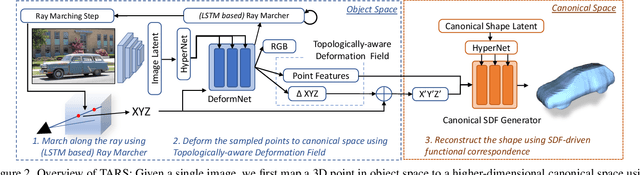

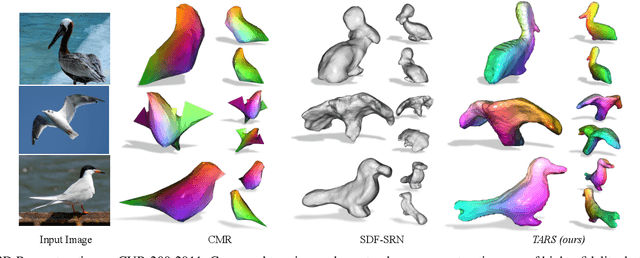
We present a framework for learning 3D object shapes and dense cross-object 3D correspondences from just an unaligned category-specific image collection. The 3D shapes are generated implicitly as deformations to a category-specific signed distance field and are learned in an unsupervised manner solely from unaligned image collections and their poses without any 3D supervision. Generally, image collections on the internet contain several intra-category geometric and topological variations, for example, different chairs can have different topologies, which makes the task of joint shape and correspondence estimation much more challenging. Because of this, prior works either focus on learning each 3D object shape individually without modeling cross-instance correspondences or perform joint shape and correspondence estimation on categories with minimal intra-category topological variations. We overcome these restrictions by learning a topologically-aware implicit deformation field that maps a 3D point in the object space to a higher dimensional point in the category-specific canonical space. At inference time, given a single image, we reconstruct the underlying 3D shape by first implicitly deforming each 3D point in the object space to the learned category-specific canonical space using the topologically-aware deformation field and then reconstructing the 3D shape as a canonical signed distance field. Both canonical shape and deformation field are learned end-to-end in an inverse-graphics fashion using a learned recurrent ray marcher (SRN) as a differentiable rendering module. Our approach, dubbed TARS, achieves state-of-the-art reconstruction fidelity on several datasets: ShapeNet, Pascal3D+, CUB, and Pix3D chairs. Result videos and code at https://shivamduggal4.github.io/tars-3D/
Realistic sources, receivers and walls improve the generalisability of virtually-supervised blind acoustic parameter estimators
Jul 19, 2022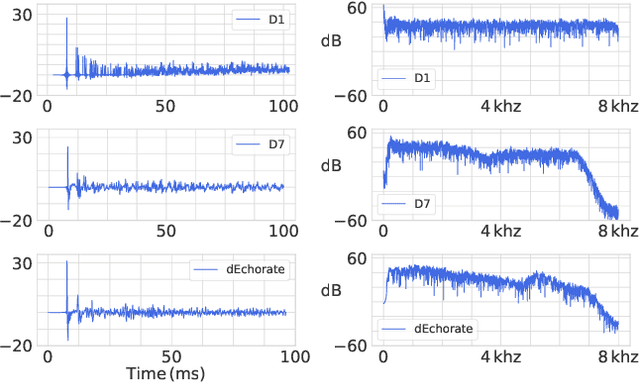

Blind acoustic parameter estimation consists in inferring the acoustic properties of an environment from recordings of unknown sound sources. Recent works in this area have utilized deep neural networks trained either partially or exclusively on simulated data, due to the limited availability of real annotated measurements. In this paper, we study whether a model purely trained using a fast image-source room impulse response simulator can generalize to real data. We present an ablation study on carefully crafted simulated training sets that account for different levels of realism in source, receiver and wall responses. The extent of realism is controlled by the sampling of wall absorption coefficients and by applying measured directivity patterns to microphones and sources. A state-of-the-art model trained on these datasets is evaluated on the task of jointly estimating the room's volume, total surface area, and octave-band reverberation times from multiple, multichannel speech recordings. Results reveal that every added layer of simulation realism at train time significantly improves the estimation of all quantities on real signals.
No-Reference Image Quality Assessment by Hallucinating Pristine Features
Aug 09, 2021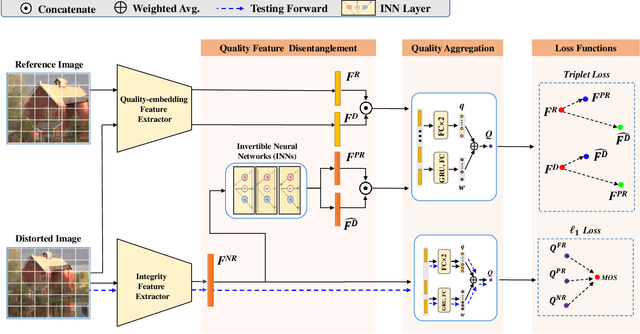

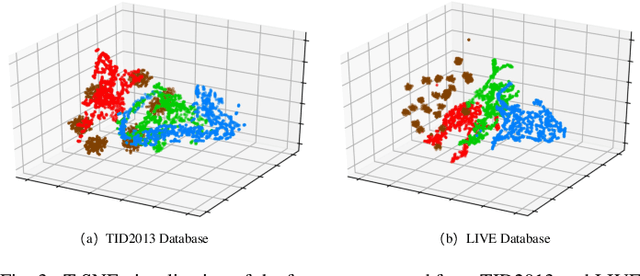
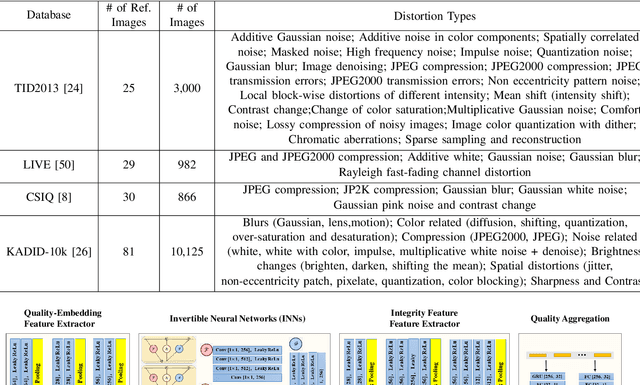
In this paper, we propose a no-reference (NR) image quality assessment (IQA) method via feature level pseudo-reference (PR) hallucination. The proposed quality assessment framework is grounded on the prior models of natural image statistical behaviors and rooted in the view that the perceptually meaningful features could be well exploited to characterize the visual quality. Herein, the PR features from the distorted images are learned by a mutual learning scheme with the pristine reference as the supervision, and the discriminative characteristics of PR features are further ensured with the triplet constraints. Given a distorted image for quality inference, the feature level disentanglement is performed with an invertible neural layer for final quality prediction, leading to the PR and the corresponding distortion features for comparison. The effectiveness of our proposed method is demonstrated on four popular IQA databases, and superior performance on cross-database evaluation also reveals the high generalization capability of our method. The implementation of our method is publicly available on https://github.com/Baoliang93/FPR.
Barbershop: GAN-based Image Compositing using Segmentation Masks
Jun 02, 2021
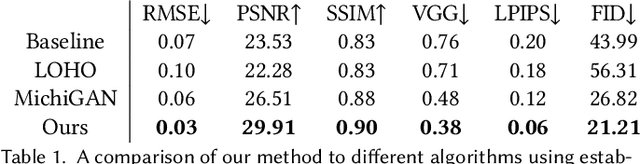

Seamlessly blending features from multiple images is extremely challenging because of complex relationships in lighting, geometry, and partial occlusion which cause coupling between different parts of the image. Even though recent work on GANs enables synthesis of realistic hair or faces, it remains difficult to combine them into a single, coherent, and plausible image rather than a disjointed set of image patches. We present a novel solution to image blending, particularly for the problem of hairstyle transfer, based on GAN-inversion. We propose a novel latent space for image blending which is better at preserving detail and encoding spatial information, and propose a new GAN-embedding algorithm which is able to slightly modify images to conform to a common segmentation mask. Our novel representation enables the transfer of the visual properties from multiple reference images including specific details such as moles and wrinkles, and because we do image blending in a latent-space we are able to synthesize images that are coherent. Our approach avoids blending artifacts present in other approaches and finds a globally consistent image. Our results demonstrate a significant improvement over the current state of the art in a user study, with users preferring our blending solution over 95 percent of the time.
PromptPose: Language Prompt Helps Animal Pose Estimation
Jun 23, 2022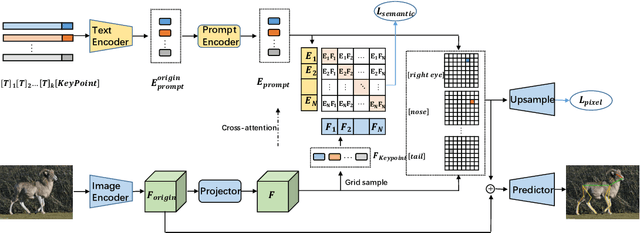
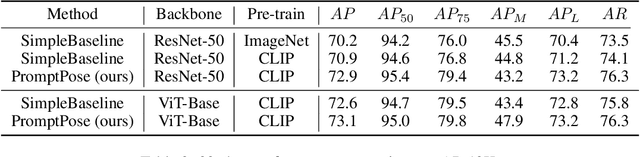
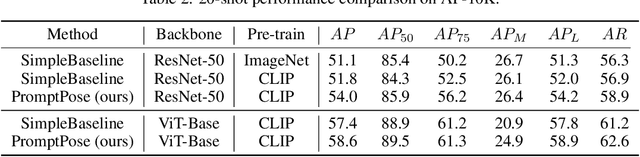
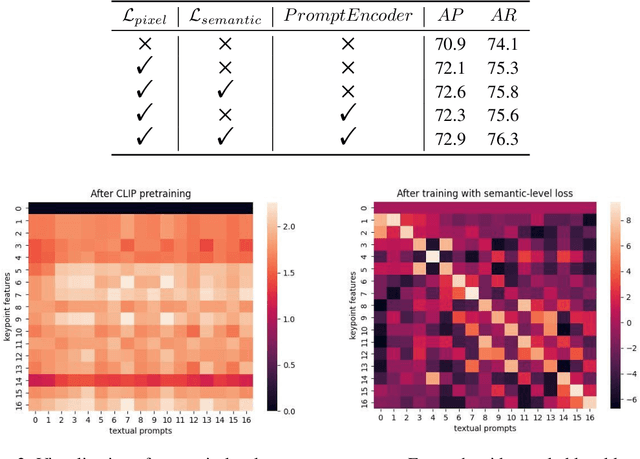
Recently, animal pose estimation is attracting increasing interest from the academia (e.g., wildlife and conservation biology) focusing on animal behavior understanding. However, currently animal pose estimation suffers from small datasets and large data variances, making it difficult to obtain robust performance. To tackle this problem, we propose that the rich knowledge about relations between pose-related semantics learned by language models can be utilized to improve the animal pose estimation. Therefore, in this study, we introduce a novel PromptPose framework to effectively apply language models for better understanding the animal poses based on prompt training. In PromptPose, we propose that adapting the language knowledge to the visual animal poses is key to achieve effective animal pose estimation. To this end, we first introduce textual prompts to build connections between textual semantic descriptions and supporting animal keypoint features. Moreover, we further devise a pixel-level contrastive loss to build dense connections between textual descriptions and local image features, as well as a semantic-level contrastive loss to bridge the gap between global contrasts in language-image cross-modal pre-training and local contrasts in dense prediction. In practice, the PromptPose has shown great benefits for improving animal pose estimation. By conducting extensive experiments, we show that our PromptPose achieves superior performance under both supervised and few-shot settings, outperforming representative methods by a large margin. The source code and models will be made publicly available.
Know your audience: specializing grounded language models with the game of Dixit
Jun 16, 2022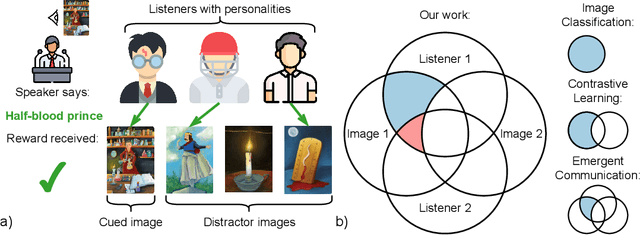
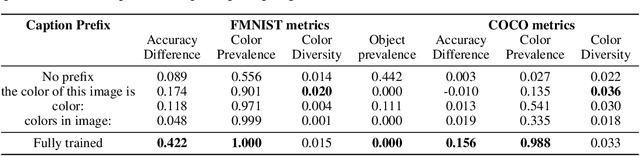
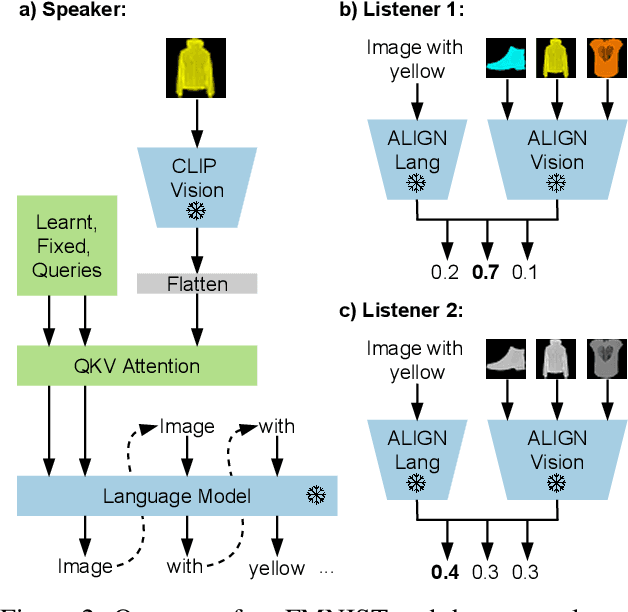
Effective communication requires adapting to the idiosyncratic common ground shared with each communicative partner. We study a particularly challenging instantiation of this problem: the popular game Dixit. We formulate a round of Dixit as a multi-agent image reference game where a (trained) speaker model is rewarded for describing a target image such that one (pretrained) listener model can correctly identify it from a pool of distractors, but another listener cannot. To adapt to this setting, the speaker must exploit differences in the common ground it shares with the different listeners. We show that finetuning an attention-based adapter between a CLIP vision encoder and a large language model in this contrastive, multi-agent setting gives rise to context-dependent natural language specialization from rewards only, without direct supervision. In a series of controlled experiments, we show that the speaker can adapt according to the idiosyncratic strengths and weaknesses of various pairs of different listeners. Furthermore, we show zero-shot transfer of the speaker's specialization to unseen real-world data. Our experiments offer a step towards adaptive communication in complex multi-partner settings and highlight the interesting research challenges posed by games like Dixit. We hope that our work will inspire creative new approaches to adapting pretrained models.
Explaining Deep Neural Networks for Point Clouds using Gradient-based Visualisations
Jul 26, 2022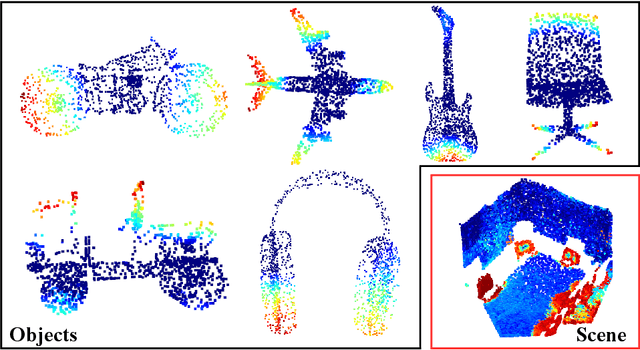
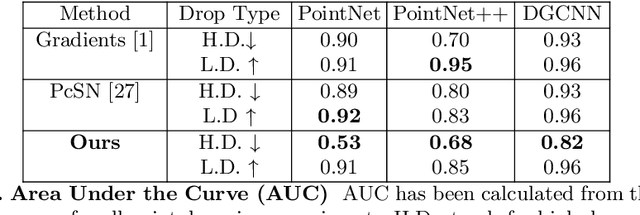
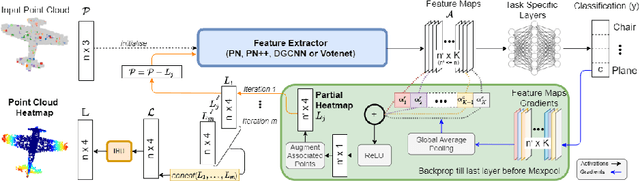

Explaining decisions made by deep neural networks is a rapidly advancing research topic. In recent years, several approaches have attempted to provide visual explanations of decisions made by neural networks designed for structured 2D image input data. In this paper, we propose a novel approach to generate coarse visual explanations of networks designed to classify unstructured 3D data, namely point clouds. Our method uses gradients flowing back to the final feature map layers and maps these values as contributions of the corresponding points in the input point cloud. Due to dimensionality disagreement and lack of spatial consistency between input points and final feature maps, our approach combines gradients with points dropping to compute explanations of different parts of the point cloud iteratively. The generality of our approach is tested on various point cloud classification networks, including 'single object' networks PointNet, PointNet++, DGCNN, and a 'scene' network VoteNet. Our method generates symmetric explanation maps that highlight important regions and provide insight into the decision-making process of network architectures. We perform an exhaustive evaluation of trust and interpretability of our explanation method against comparative approaches using quantitative, quantitative and human studies. All our code is implemented in PyTorch and will be made publicly available.
Semantic Segmentation for Autonomous Driving: Model Evaluation, Dataset Generation, Perspective Comparison, and Real-Time Capability
Jul 26, 2022
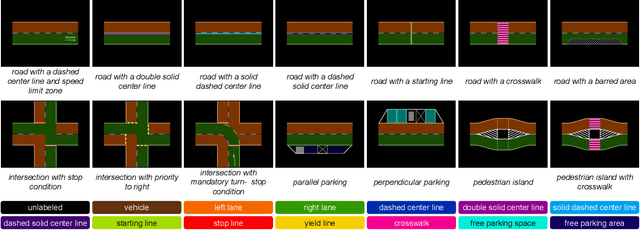

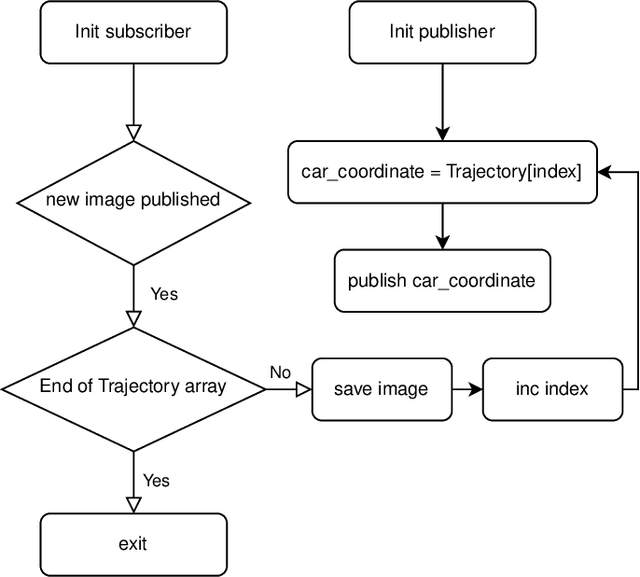
Environmental perception is an important aspect within the field of autonomous vehicles that provides crucial information about the driving domain, including but not limited to identifying clear driving areas and surrounding obstacles. Semantic segmentation is a widely used perception method for self-driving cars that associates each pixel of an image with a predefined class. In this context, several segmentation models are evaluated regarding accuracy and efficiency. Experimental results on the generated dataset confirm that the segmentation model FasterSeg is fast enough to be used in realtime on lowpower computational (embedded) devices in self-driving cars. A simple method is also introduced to generate synthetic training data for the model. Moreover, the accuracy of the first-person perspective and the bird's eye view perspective are compared. For a $320 \times 256$ input in the first-person perspective, FasterSeg achieves $65.44\,\%$ mean Intersection over Union (mIoU), and for a $320 \times 256$ input from the bird's eye view perspective, FasterSeg achieves $64.08\,\%$ mIoU. Both perspectives achieve a frame rate of $247.11$ Frames per Second (FPS) on the NVIDIA Jetson AGX Xavier. Lastly, the frame rate and the accuracy with respect to the arithmetic 16-bit Floating Point (FP16) and 32-bit Floating Point (FP32) of both perspectives are measured and compared on the target hardware.
Image Augmentation Based Momentum Memory Intrinsic Reward for Sparse Reward Visual Scenes
May 19, 2022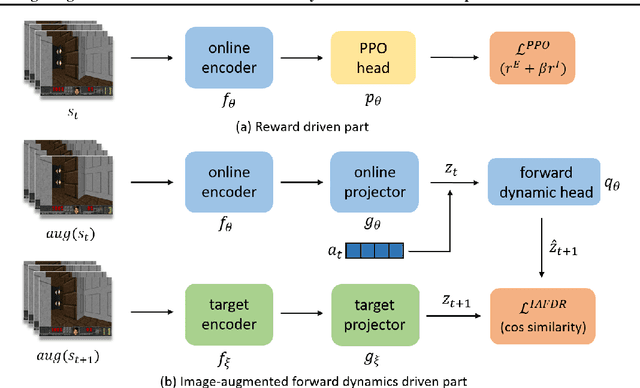

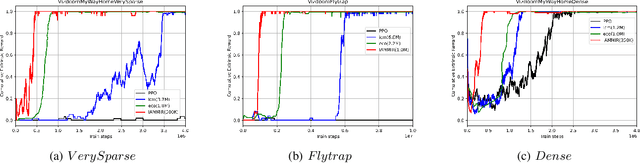
Many scenes in real life can be abstracted to the sparse reward visual scenes, where it is difficult for an agent to tackle the task under the condition of only accepting images and sparse rewards. We propose to decompose this problem into two sub-problems: the visual representation and the sparse reward. To address them, a novel framework IAMMIR combining the self-supervised representation learning with the intrinsic motivation is presented. For visual representation, a representation driven by a combination of the imageaugmented forward dynamics and the reward is acquired. For sparse rewards, a new type of intrinsic reward is designed, the Momentum Memory Intrinsic Reward (MMIR). It utilizes the difference of the outputs from the current model (online network) and the historical model (target network) to present the agent's state familiarity. Our method is evaluated on the visual navigation task with sparse rewards in Vizdoom. Experiments demonstrate that our method achieves the state of the art performance in sample efficiency, at least 2 times faster than the existing methods reaching 100% success rate.
Multimodal-GuideNet: Gaze-Probe Bidirectional Guidance in Obstetric Ultrasound Scanning
Jul 26, 2022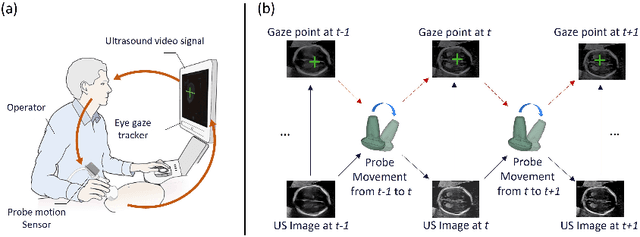
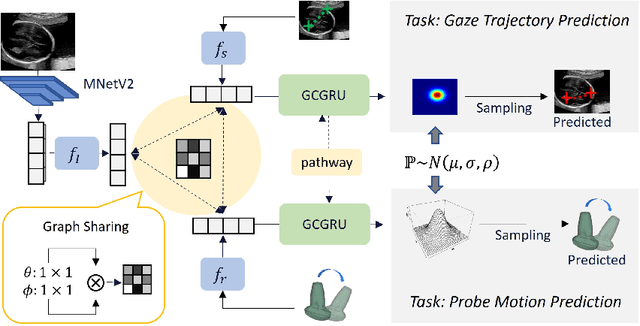
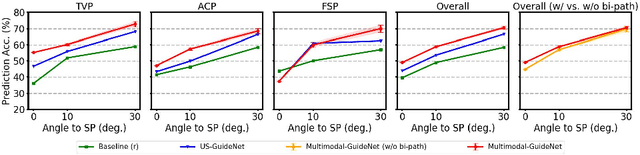
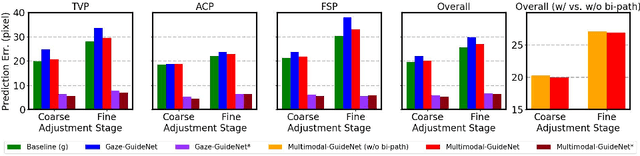
Eye trackers can provide visual guidance to sonographers during ultrasound (US) scanning. Such guidance is potentially valuable for less experienced operators to improve their scanning skills on how to manipulate the probe to achieve the desired plane. In this paper, a multimodal guidance approach (Multimodal-GuideNet) is proposed to capture the stepwise dependency between a real-world US video signal, synchronized gaze, and probe motion within a unified framework. To understand the causal relationship between gaze movement and probe motion, our model exploits multitask learning to jointly learn two related tasks: predicting gaze movements and probe signals that an experienced sonographer would perform in routine obstetric scanning. The two tasks are associated by a modality-aware spatial graph to detect the co-occurrence among the multi-modality inputs and share useful cross-modal information. Instead of a deterministic scanning path, Multimodal-GuideNet allows for scanning diversity by estimating the probability distribution of real scans. Experiments performed with three typical obstetric scanning examinations show that the new approach outperforms single-task learning for both probe motion guidance and gaze movement prediction. Multimodal-GuideNet also provides a visual guidance signal with an error rate of less than 10 pixels for a 224x288 US image.