 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Orthonormal Convolutions for the Rotation Based Iterative Gaussianization
Jun 08, 2022
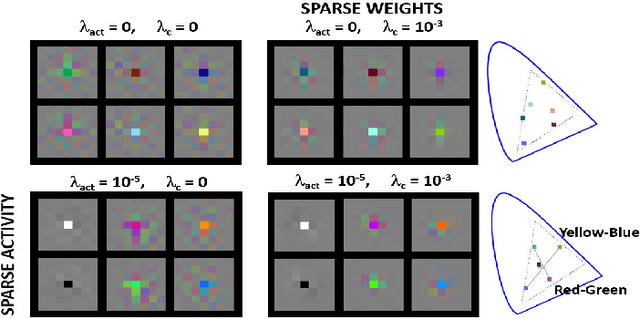
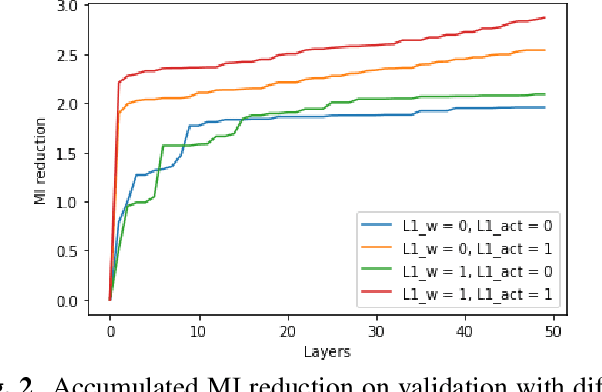
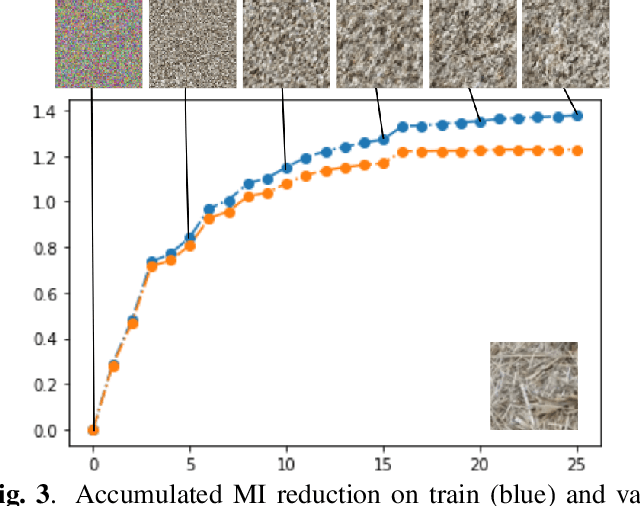

In this paper we elaborate an extension of rotation-based iterative Gaussianization, RBIG, which makes image Gaussianization possible. Although RBIG has been successfully applied to many tasks, it is limited to medium dimensionality data (on the order of a thousand dimensions). In images its application has been restricted to small image patches or isolated pixels, because rotation in RBIG is based on principal or independent component analysis and these transformations are difficult to learn and scale. Here we present the \emph{Convolutional RBIG}: an extension that alleviates this issue by imposing that the rotation in RBIG is a convolution. We propose to learn convolutional rotations (i.e. orthonormal convolutions) by optimising for the reconstruction loss between the input and an approximate inverse of the transformation using the transposed convolution operation. Additionally, we suggest different regularizers in learning these orthonormal convolutions. For example, imposing sparsity in the activations leads to a transformation that extends convolutional independent component analysis to multilayer architectures. We also highlight how statistical properties of the data, such as multivariate mutual information, can be obtained from \emph{Convolutional RBIG}. We illustrate the behavior of the transform with a simple example of texture synthesis, and analyze its properties by visualizing the stimuli that maximize the response in certain feature and layer.
MKANet: A Lightweight Network with Sobel Boundary Loss for Efficient Land-cover Classification of Satellite Remote Sensing Imagery
Jul 28, 2022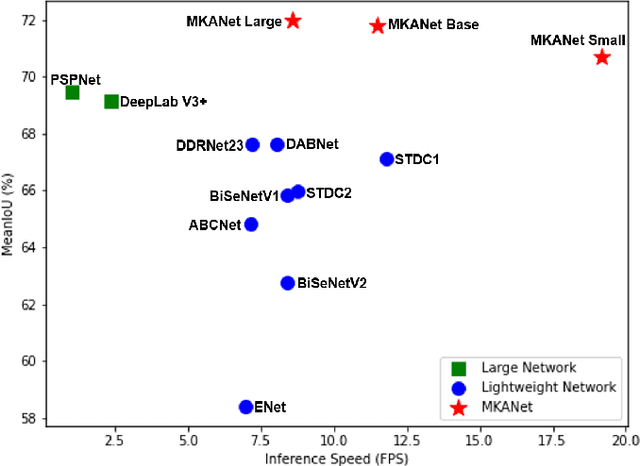
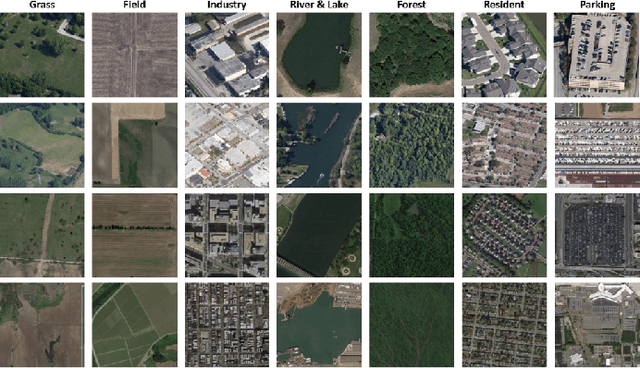
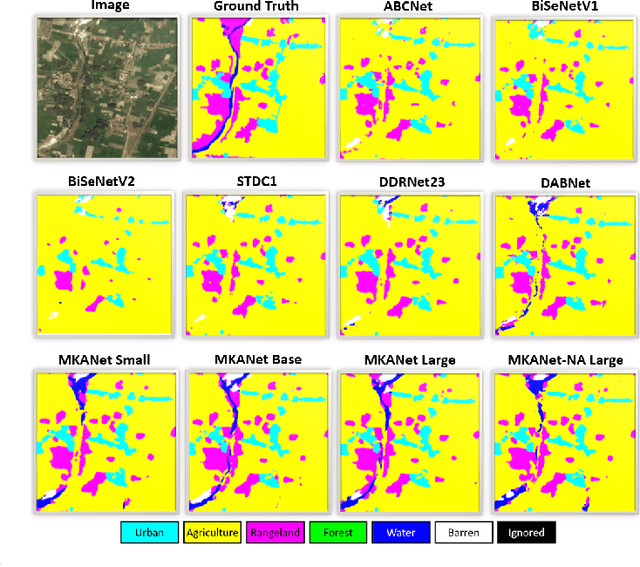
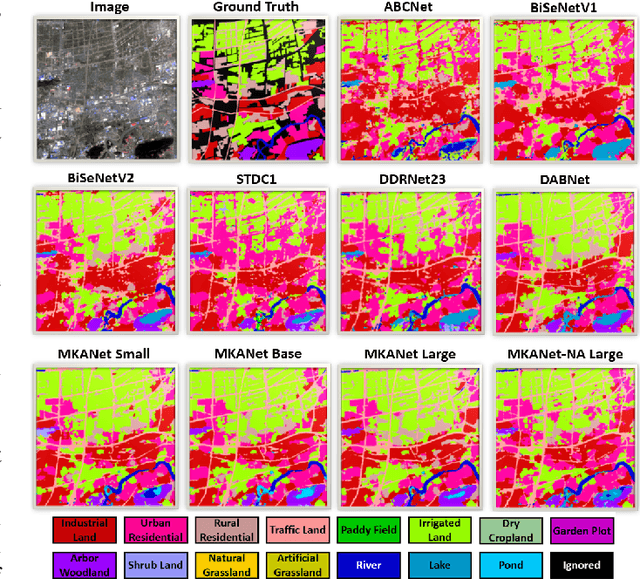
Land cover classification is a multi-class segmentation task to classify each pixel into a certain natural or man-made category of the earth surface, such as water, soil, natural vegetation, crops, and human infrastructure. Limited by hardware computational resources and memory capacity, most existing studies preprocessed original remote sensing images by down sampling or cropping them into small patches less than 512*512 pixels before sending them to a deep neural network. However, down sampling images incurs spatial detail loss, renders small segments hard to discriminate, and reverses the spatial resolution progress obtained by decades of years of efforts. Cropping images into small patches causes a loss of long-range context information, and restoring the predicted results to their original size brings extra latency. In response to the above weaknesses, we present an efficient lightweight semantic segmentation network termed MKANet. Aimed at the characteristics of top view high-resolution remote sensing imagery, MKANet utilizes sharing kernels to simultaneously and equally handle ground segments of inconsistent scales, and also employs parallel and shallow architecture to boost inference speed and friendly support image patches more than 10X larger. To enhance boundary and small segments discrimination, we also propose a method that captures category impurity areas, exploits boundary information and exerts an extra penalty on boundaries and small segment misjudgment. Both visual interpretations and quantitative metrics of extensive experiments demonstrate that MKANet acquires state-of-the-art accuracy on two land-cover classification datasets and infers 2X faster than other competitive lightweight networks. All these merits highlight the potential of MKANet in practical applications.
Cross-modal Prototype Driven Network for Radiology Report Generation
Jul 11, 2022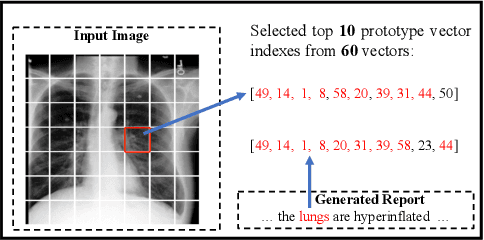
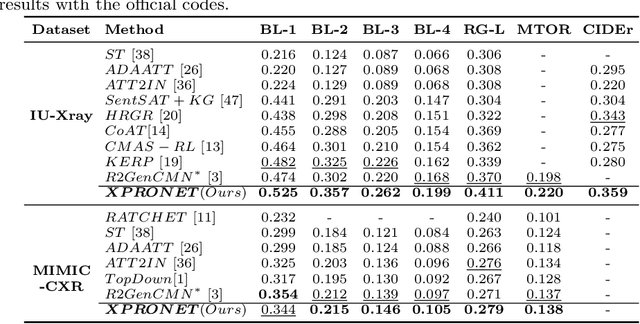
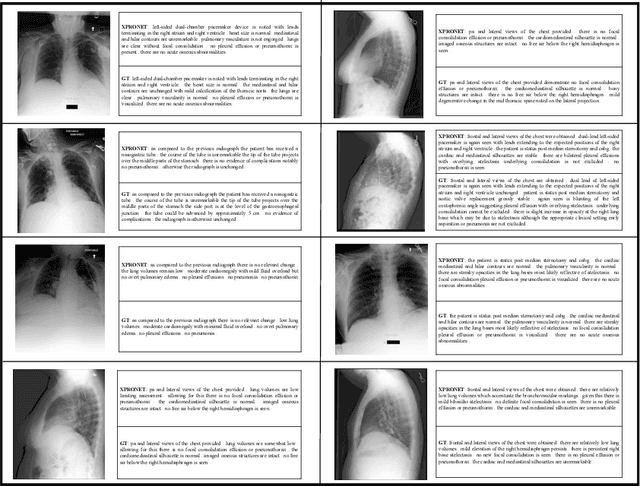
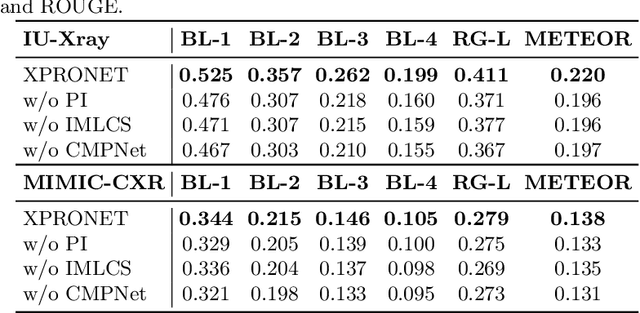
Radiology report generation (RRG) aims to describe automatically a radiology image with human-like language and could potentially support the work of radiologists, reducing the burden of manual reporting. Previous approaches often adopt an encoder-decoder architecture and focus on single-modal feature learning, while few studies explore cross-modal feature interaction. Here we propose a Cross-modal PROtotype driven NETwork (XPRONET) to promote cross-modal pattern learning and exploit it to improve the task of radiology report generation. This is achieved by three well-designed, fully differentiable and complementary modules: a shared cross-modal prototype matrix to record the cross-modal prototypes; a cross-modal prototype network to learn the cross-modal prototypes and embed the cross-modal information into the visual and textual features; and an improved multi-label contrastive loss to enable and enhance multi-label prototype learning. XPRONET obtains substantial improvements on the IU-Xray and MIMIC-CXR benchmarks, where its performance exceeds recent state-of-the-art approaches by a large margin on IU-Xray and comparable performance on MIMIC-CXR.
Text-Aware Single Image Specular Highlight Removal
Aug 16, 2021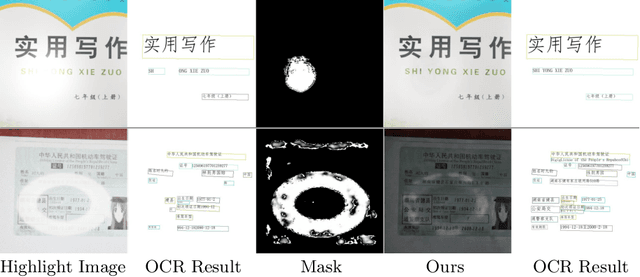
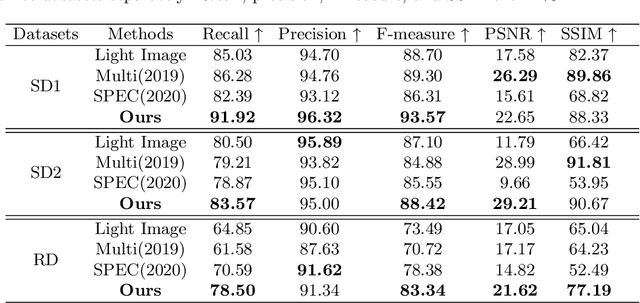

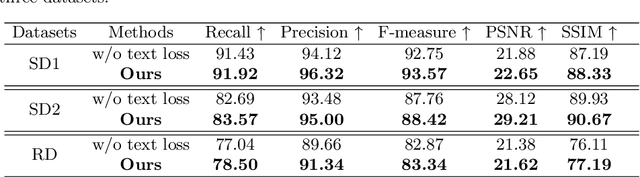
Removing undesirable specular highlight from a single input image is of crucial importance to many computer vision and graphics tasks. Existing methods typically remove specular highlight for medical images and specific-object images, however, they cannot handle the images with text. In addition, the impact of specular highlight on text recognition is rarely studied by text detection and recognition community. Therefore, in this paper, we first raise and study the text-aware single image specular highlight removal problem. The core goal is to improve the accuracy of text detection and recognition by removing the highlight from text images. To tackle this challenging problem, we first collect three high-quality datasets with fine-grained annotations, which will be appropriately released to facilitate the relevant research. Then, we design a novel two-stage network, which contains a highlight detection network and a highlight removal network. The output of highlight detection network provides additional information about highlight regions to guide the subsequent highlight removal network. Moreover, we suggest a measurement set including the end-to-end text detection and recognition evaluation and auxiliary visual quality evaluation. Extensive experiments on our collected datasets demonstrate the superior performance of the proposed method.
Fourier Transform Approximation as an Auxiliary Task for Image Classification
Jul 01, 2021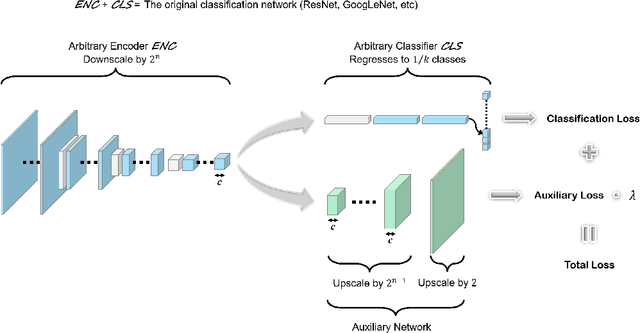
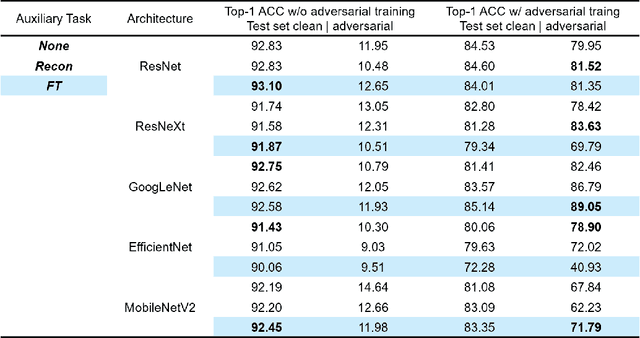
Image reconstruction is likely the most predominant auxiliary task for image classification, but we would like to think twice about this convention. In this paper, we investigated "approximating the Fourier Transform of the input image" as a potential alternative, in the hope that it may further boost the performances on the primary task or introduce novel constraints not well covered by image reconstruction. We experimented with five popular classification architectures on the CIFAR-10 dataset, and the empirical results indicated that our proposed auxiliary task generally improves the classification accuracy. More notably, the results showed that in certain cases our proposed auxiliary task may enhance the classifiers' resistance to adversarial attacks generated using the fast gradient sign method.
Domain Adaptive Person Search
Jul 25, 2022
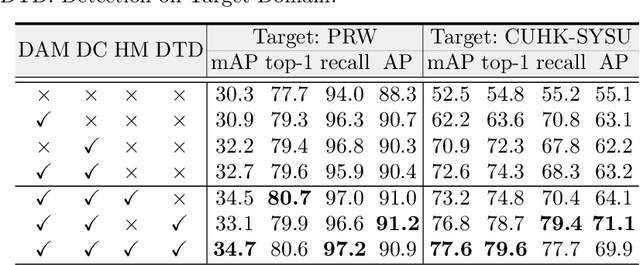
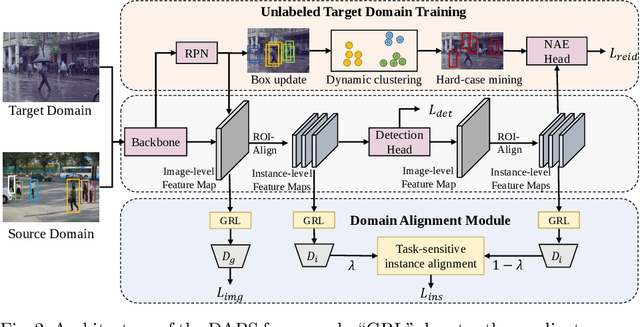

Person search is a challenging task which aims to achieve joint pedestrian detection and person re-identification (ReID). Previous works have made significant advances under fully and weakly supervised settings. However, existing methods ignore the generalization ability of the person search models. In this paper, we take a further step and present Domain Adaptive Person Search (DAPS), which aims to generalize the model from a labeled source domain to the unlabeled target domain. Two major challenges arises under this new setting: one is how to simultaneously solve the domain misalignment issue for both detection and Re-ID tasks, and the other is how to train the ReID subtask without reliable detection results on the target domain. To address these challenges, we propose a strong baseline framework with two dedicated designs. 1) We design a domain alignment module including image-level and task-sensitive instance-level alignments, to minimize the domain discrepancy. 2) We take full advantage of the unlabeled data with a dynamic clustering strategy, and employ pseudo bounding boxes to support ReID and detection training on the target domain. With the above designs, our framework achieves 34.7% in mAP and 80.6% in top-1 on PRW dataset, surpassing the direct transferring baseline by a large margin. Surprisingly, the performance of our unsupervised DAPS model even surpasses some of the fully and weakly supervised methods. The code is available at https://github.com/caposerenity/DAPS.
Learning Deep Latent Subspaces for Image Denoising
Apr 22, 2021
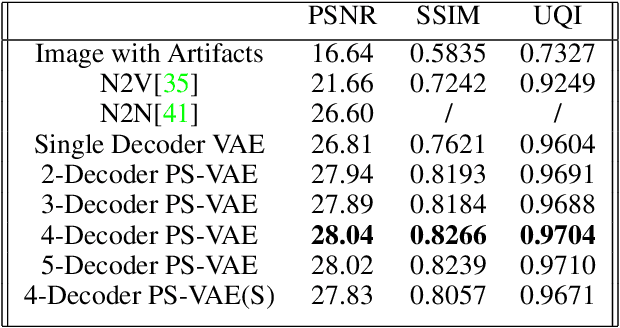
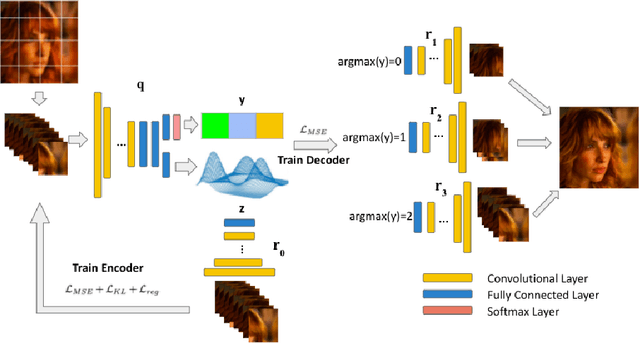

Heterogeneity exists in most camera images. This heterogeneity manifests itself across the image space as varied Moire ringing, motion-blur, color-bleaching or lens based projection distortions. Moreover, combinations of these image artifacts can be present in small or large pixel neighborhoods, within an acquired image. Current camera image processing pipelines, including deep trained versions, tend to rectify the issue applying a single filter that is homogeneously applied to the entire image. This is also particularly true when an encoder-decoder type deep architecture is trained for the task. In this paper, we present a structured deep learning model that solves the heterogeneous image artifact filtering problem. We call our deep trained model the Patch Subspace Variational Autoencoder (PS-VAE) for Camera ISP. PS-VAE does not necessarily assume uniform image distortion levels nor similar artifact types within the image. Rather, our model attempts to learn to cluster different patches extracted from images into artifact type and distortion levels, within multiple latent subspaces (e.g. Moire ringing artifacts are often a higher dimensional latent distortion than a Gaussian motion blur artifact). Each image's patches are encoded into soft-clusters in their appropriate latent sub-space, using a prior mixture model. The decoders of the PS-VAE are also trained in an unsupervised manner for each of the image patches in each soft-cluster. Our experimental results demonstrates the flexibility and performance that one can achieve through improved heterogeneous filtering. We compare our results to a conventional one-encoder-one-decoder architecture.
DeFlowSLAM: Self-Supervised Scene Motion Decomposition for Dynamic Dense SLAM
Jul 18, 2022

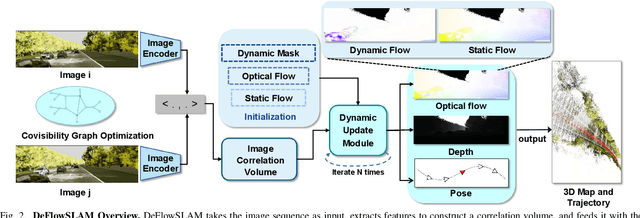
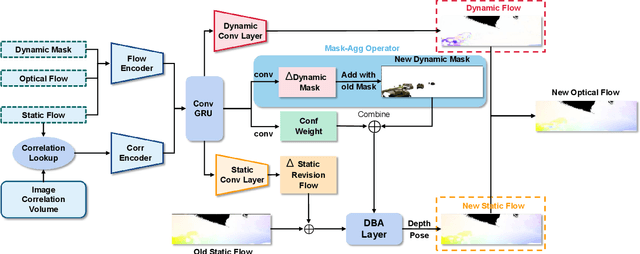
We present a novel dual-flow representation of scene motion that decomposes the optical flow into a static flow field caused by the camera motion and another dynamic flow field caused by the objects' movements in the scene. Based on this representation, we present a dynamic SLAM, dubbed DeFlowSLAM, that exploits both static and dynamic pixels in the images to solve the camera poses, rather than simply using static background pixels as other dynamic SLAM systems do. We propose a dynamic update module to train our DeFlowSLAM in a self-supervised manner, where a dense bundle adjustment layer takes in estimated static flow fields and the weights controlled by the dynamic mask and outputs the residual of the optimized static flow fields, camera poses, and inverse depths. The static and dynamic flow fields are estimated by warping the current image to the neighboring images, and the optical flow can be obtained by summing the two fields. Extensive experiments demonstrate that DeFlowSLAM generalizes well to both static and dynamic scenes as it exhibits comparable performance to the state-of-the-art DROID-SLAM in static and less dynamic scenes while significantly outperforming DROID-SLAM in highly dynamic environments. Code and data are available on the project webpage: \urlstyle{tt} \textcolor{url_color}{\url{https://zju3dv.github.io/deflowslam/}}.
Adaptive Unfolding Total Variation Network for Low-Light Image Enhancement
Oct 07, 2021
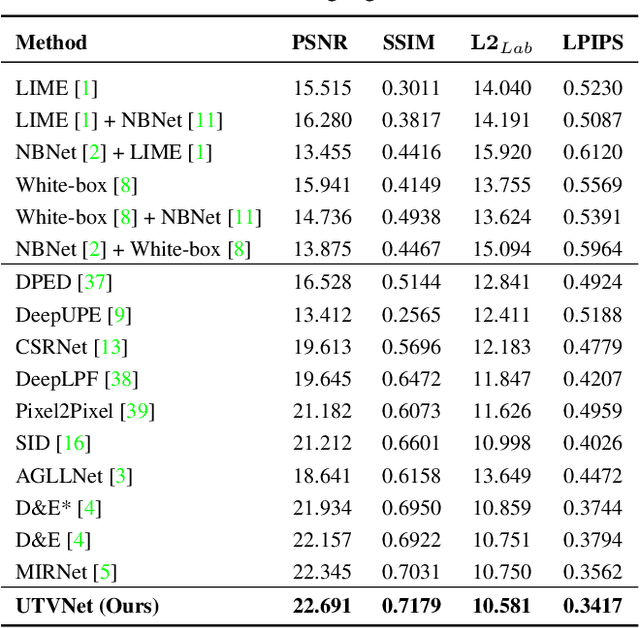
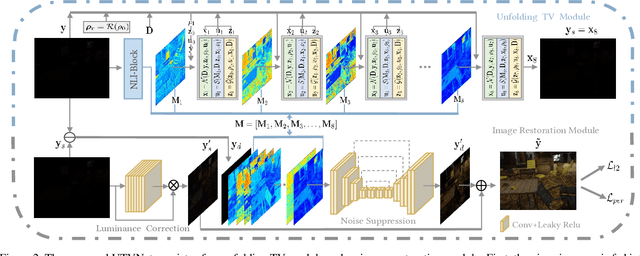

Real-world low-light images suffer from two main degradations, namely, inevitable noise and poor visibility. Since the noise exhibits different levels, its estimation has been implemented in recent works when enhancing low-light images from raw Bayer space. When it comes to sRGB color space, the noise estimation becomes more complicated due to the effect of the image processing pipeline. Nevertheless, most existing enhancing algorithms in sRGB space only focus on the low visibility problem or suppress the noise under a hypothetical noise level, leading them impractical due to the lack of robustness. To address this issue,we propose an adaptive unfolding total variation network (UTVNet), which approximates the noise level from the real sRGB low-light image by learning the balancing parameter in the model-based denoising method with total variation regularization. Meanwhile, we learn the noise level map by unrolling the corresponding minimization process for providing the inferences of smoothness and fidelity constraints. Guided by the noise level map, our UTVNet can recover finer details and is more capable to suppress noise in real captured low-light scenes. Extensive experiments on real-world low-light images clearly demonstrate the superior performance of UTVNet over state-of-the-art methods.
Single Underwater Image Restoration by Contrastive Learning
Apr 15, 2021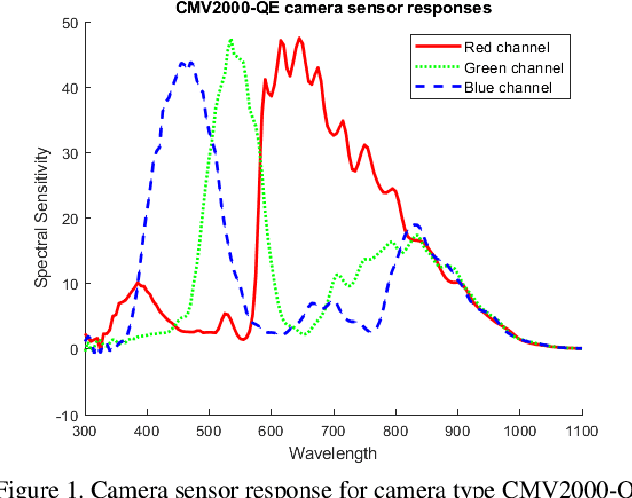
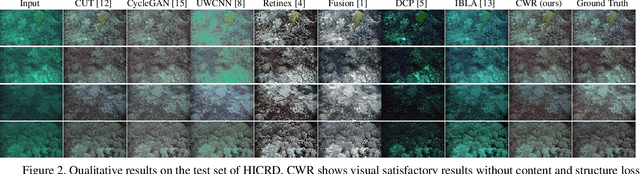
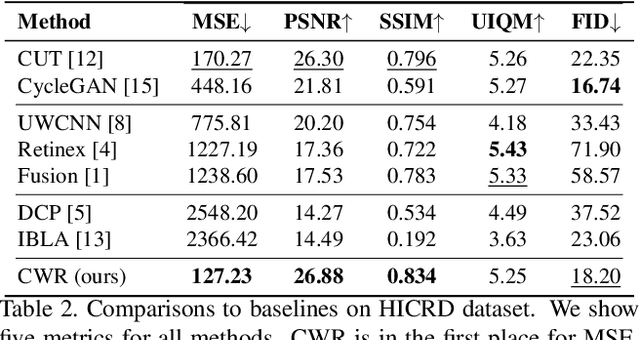
Underwater image restoration attracts significant attention due to its importance in unveiling the underwater world. This paper elaborates on a novel method that achieves state-of-the-art results for underwater image restoration based on the unsupervised image-to-image translation framework. We design our method by leveraging from contrastive learning and generative adversarial networks to maximize mutual information between raw and restored images. Additionally, we release a large-scale real underwater image dataset to support both paired and unpaired training modules. Extensive experiments with comparisons to recent approaches further demonstrate the superiority of our proposed method.