 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Reference-based Magnetic Resonance Image Reconstruction Using Texture Transforme
Nov 18, 2021
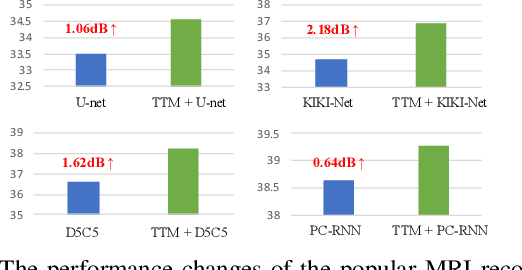

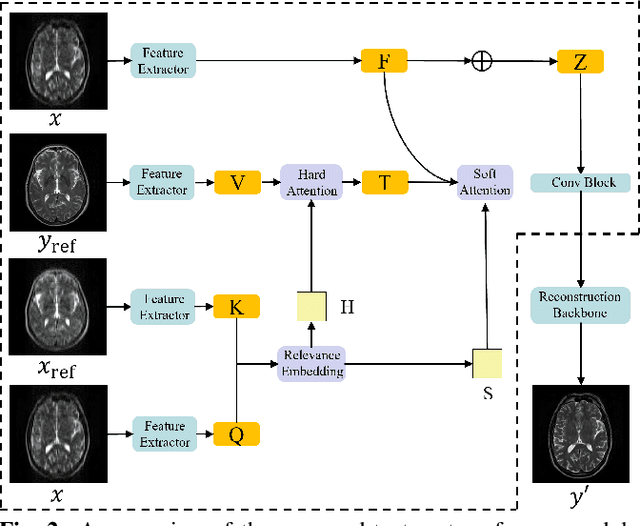

Deep Learning (DL) based methods for magnetic resonance (MR) image reconstruction have been shown to produce superior performance in recent years. However, these methods either only leverage under-sampled data or require a paired fully-sampled auxiliary modality to perform multi-modal reconstruction. Consequently, existing approaches neglect to explore attention mechanisms that can transfer textures from reference fully-sampled data to under-sampled data within a single modality, which limits these approaches in challenging cases. In this paper, we propose a novel Texture Transformer Module (TTM) for accelerated MRI reconstruction, in which we formulate the under-sampled data and reference data as queries and keys in a transformer. The TTM facilitates joint feature learning across under-sampled and reference data, so the feature correspondences can be discovered by attention and accurate texture features can be leveraged during reconstruction. Notably, the proposed TTM can be stacked on prior MRI reconstruction approaches to further improve their performance. Extensive experiments show that TTM can significantly improve the performance of several popular DL-based MRI reconstruction methods.
Egocentric Visual Self-Modeling for Legged Robot Locomotion
Jul 07, 2022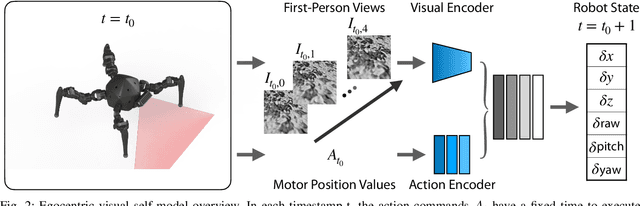

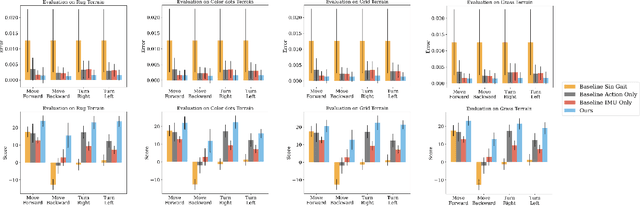

Inertial Measurement Unit (IMU) is ubiquitous in robotic research. It provides posture information for robots to realize balance and navigation. However, humans and animals can perceive the movement of their bodies in the environment without precise orientation or position values. This interaction inherently involves a fast feedback loop between perception and action. This work proposed an end-to-end approach that uses high dimension visual observation and action commands to train a visual self-model for legged locomotion. The visual self-model learns the spatial relationship between the robot body movement and the ground texture changes from image sequences. We demonstrate that the robot can leverage the visual self-model to achieve various locomotion tasks in the real-world environment that the robot does not see during training. With our proposed method, robots can do locomotion without IMU or in an environment with no GPS or weak geomagnetic fields like the indoor and urban canyons in the city.
Calibrate to Interpret
Jul 07, 2022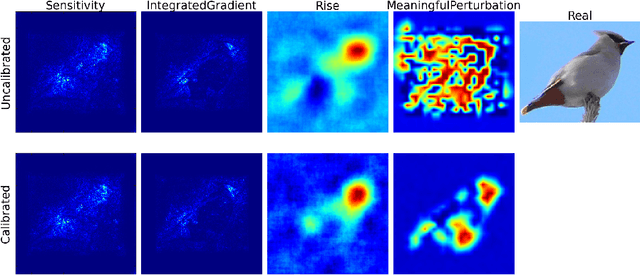
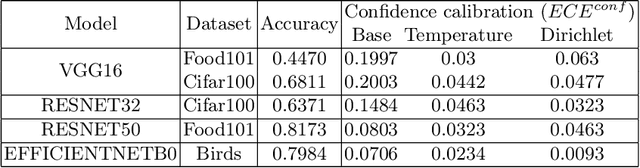
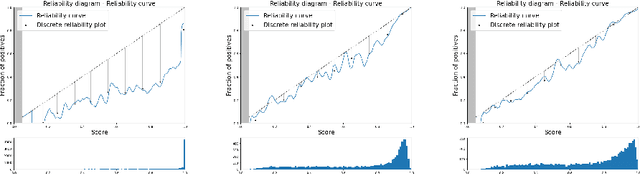
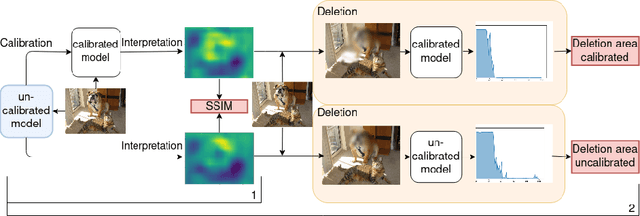
Trustworthy machine learning is driving a large number of ML community works in order to improve ML acceptance and adoption. The main aspect of trustworthy machine learning are the followings: fairness, uncertainty, robustness, explainability and formal guaranties. Each of these individual domains gains the ML community interest, visible by the number of related publications. However few works tackle the interconnection between these fields. In this paper we show a first link between uncertainty and explainability, by studying the relation between calibration and interpretation. As the calibration of a given model changes the way it scores samples, and interpretation approaches often rely on these scores, it seems safe to assume that the confidence-calibration of a model interacts with our ability to interpret such model. In this paper, we show, in the context of networks trained on image classification tasks, to what extent interpretations are sensitive to confidence-calibration. It leads us to suggest a simple practice to improve the interpretation outcomes: Calibrate to Interpret.
Fourier Transform Approximation as an Auxiliary Task for Image Classification
Jul 01, 2021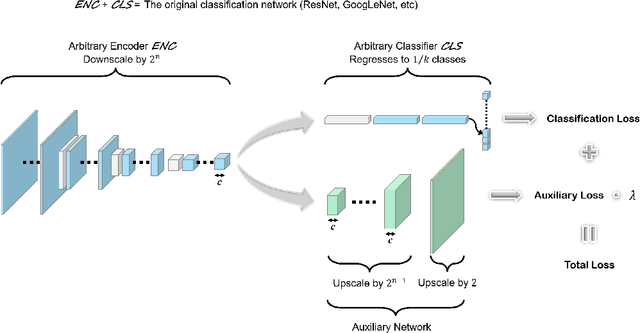
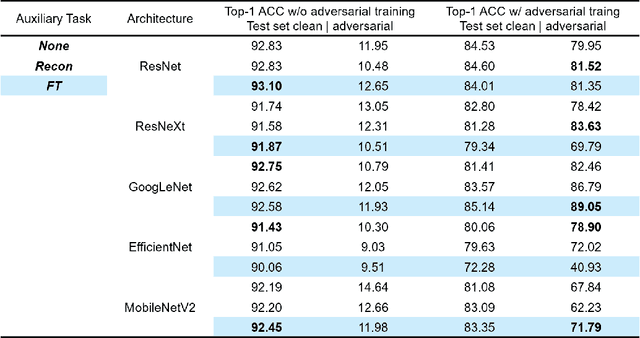
Image reconstruction is likely the most predominant auxiliary task for image classification, but we would like to think twice about this convention. In this paper, we investigated "approximating the Fourier Transform of the input image" as a potential alternative, in the hope that it may further boost the performances on the primary task or introduce novel constraints not well covered by image reconstruction. We experimented with five popular classification architectures on the CIFAR-10 dataset, and the empirical results indicated that our proposed auxiliary task generally improves the classification accuracy. More notably, the results showed that in certain cases our proposed auxiliary task may enhance the classifiers' resistance to adversarial attacks generated using the fast gradient sign method.
Text-Aware Single Image Specular Highlight Removal
Aug 16, 2021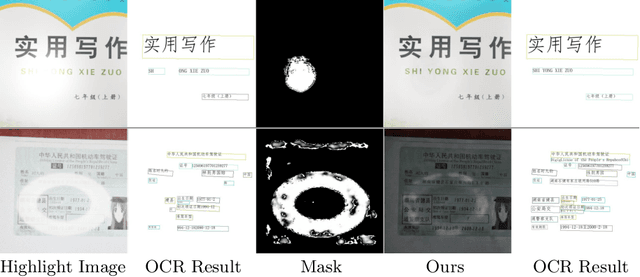
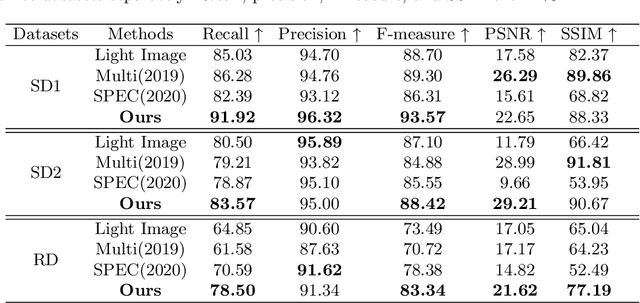

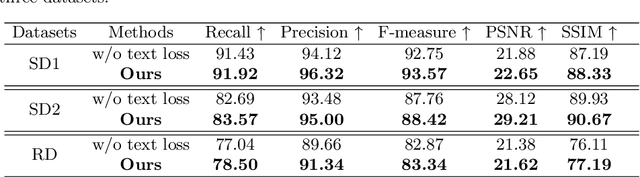
Removing undesirable specular highlight from a single input image is of crucial importance to many computer vision and graphics tasks. Existing methods typically remove specular highlight for medical images and specific-object images, however, they cannot handle the images with text. In addition, the impact of specular highlight on text recognition is rarely studied by text detection and recognition community. Therefore, in this paper, we first raise and study the text-aware single image specular highlight removal problem. The core goal is to improve the accuracy of text detection and recognition by removing the highlight from text images. To tackle this challenging problem, we first collect three high-quality datasets with fine-grained annotations, which will be appropriately released to facilitate the relevant research. Then, we design a novel two-stage network, which contains a highlight detection network and a highlight removal network. The output of highlight detection network provides additional information about highlight regions to guide the subsequent highlight removal network. Moreover, we suggest a measurement set including the end-to-end text detection and recognition evaluation and auxiliary visual quality evaluation. Extensive experiments on our collected datasets demonstrate the superior performance of the proposed method.
Learning Deep Latent Subspaces for Image Denoising
Apr 22, 2021
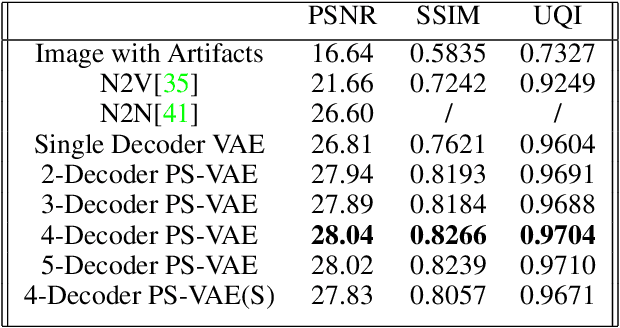
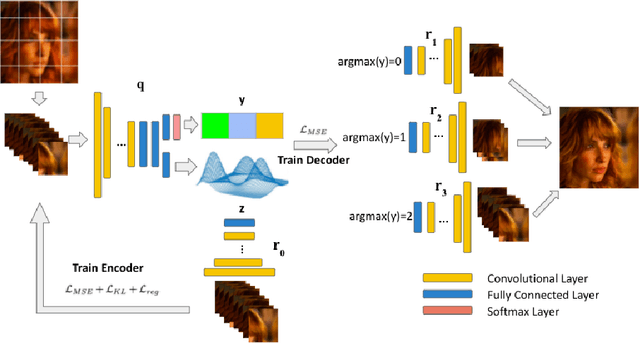

Heterogeneity exists in most camera images. This heterogeneity manifests itself across the image space as varied Moire ringing, motion-blur, color-bleaching or lens based projection distortions. Moreover, combinations of these image artifacts can be present in small or large pixel neighborhoods, within an acquired image. Current camera image processing pipelines, including deep trained versions, tend to rectify the issue applying a single filter that is homogeneously applied to the entire image. This is also particularly true when an encoder-decoder type deep architecture is trained for the task. In this paper, we present a structured deep learning model that solves the heterogeneous image artifact filtering problem. We call our deep trained model the Patch Subspace Variational Autoencoder (PS-VAE) for Camera ISP. PS-VAE does not necessarily assume uniform image distortion levels nor similar artifact types within the image. Rather, our model attempts to learn to cluster different patches extracted from images into artifact type and distortion levels, within multiple latent subspaces (e.g. Moire ringing artifacts are often a higher dimensional latent distortion than a Gaussian motion blur artifact). Each image's patches are encoded into soft-clusters in their appropriate latent sub-space, using a prior mixture model. The decoders of the PS-VAE are also trained in an unsupervised manner for each of the image patches in each soft-cluster. Our experimental results demonstrates the flexibility and performance that one can achieve through improved heterogeneous filtering. We compare our results to a conventional one-encoder-one-decoder architecture.
Moment Centralization based Gradient Descent Optimizers for Convolutional Neural Networks
Jul 19, 2022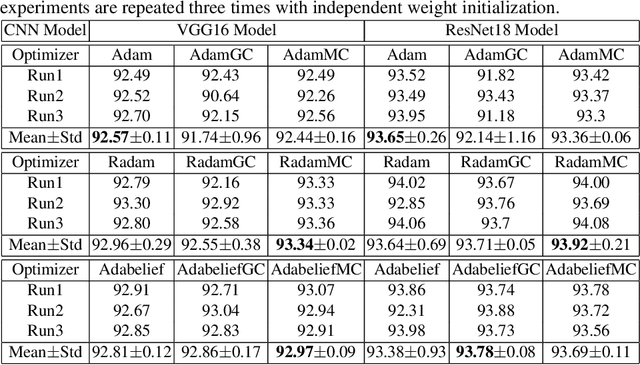

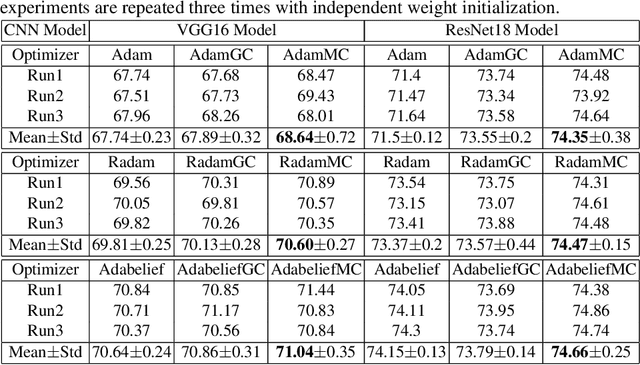
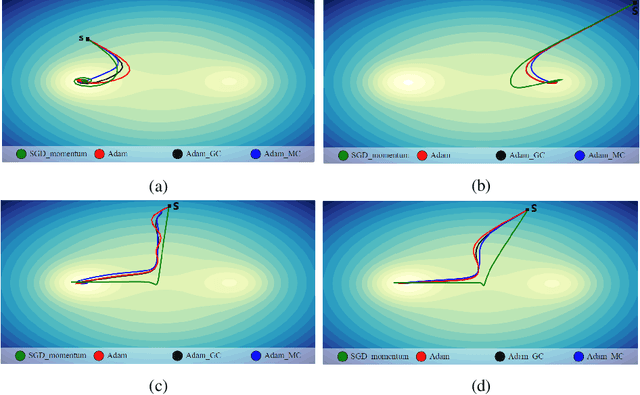
Convolutional neural networks (CNNs) have shown very appealing performance for many computer vision applications. The training of CNNs is generally performed using stochastic gradient descent (SGD) based optimization techniques. The adaptive momentum-based SGD optimizers are the recent trends. However, the existing optimizers are not able to maintain a zero mean in the first-order moment and struggle with optimization. In this paper, we propose a moment centralization-based SGD optimizer for CNNs. Specifically, we impose the zero mean constraints on the first-order moment explicitly. The proposed moment centralization is generic in nature and can be integrated with any of the existing adaptive momentum-based optimizers. The proposed idea is tested with three state-of-the-art optimization techniques, including Adam, Radam, and Adabelief on benchmark CIFAR10, CIFAR100, and TinyImageNet datasets for image classification. The performance of the existing optimizers is generally improved when integrated with the proposed moment centralization. Further, The results of the proposed moment centralization are also better than the existing gradient centralization. The analytical analysis using the toy example shows that the proposed method leads to a shorter and smoother optimization trajectory. The source code is made publicly available at \url{https://github.com/sumanthsadhu/MC-optimizer}.
On Analyzing Generative and Denoising Capabilities of Diffusion-based Deep Generative Models
May 31, 2022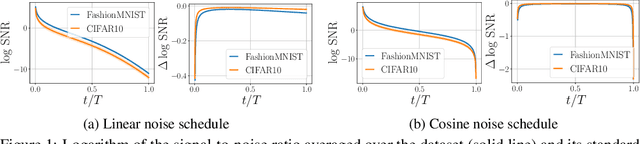
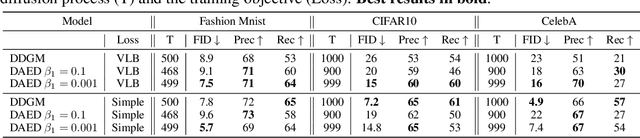
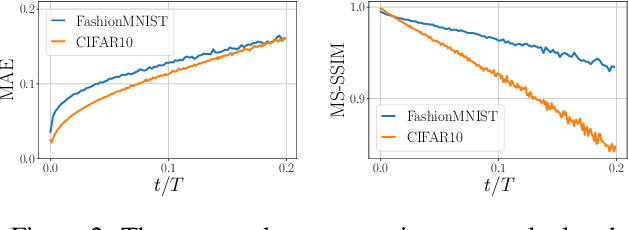
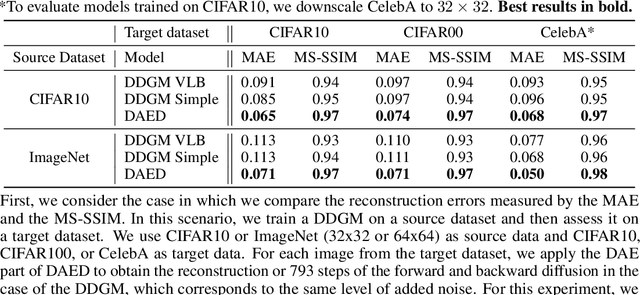
Diffusion-based Deep Generative Models (DDGMs) offer state-of-the-art performance in generative modeling. Their main strength comes from their unique setup in which a model (the backward diffusion process) is trained to reverse the forward diffusion process, which gradually adds noise to the input signal. Although DDGMs are well studied, it is still unclear how the small amount of noise is transformed during the backward diffusion process. Here, we focus on analyzing this problem to gain more insight into the behavior of DDGMs and their denoising and generative capabilities. We observe a fluid transition point that changes the functionality of the backward diffusion process from generating a (corrupted) image from noise to denoising the corrupted image to the final sample. Based on this observation, we postulate to divide a DDGM into two parts: a denoiser and a generator. The denoiser could be parameterized by a denoising auto-encoder, while the generator is a diffusion-based model with its own set of parameters. We experimentally validate our proposition, showing its pros and cons.
Audio-Visual Segmentation
Jul 11, 2022

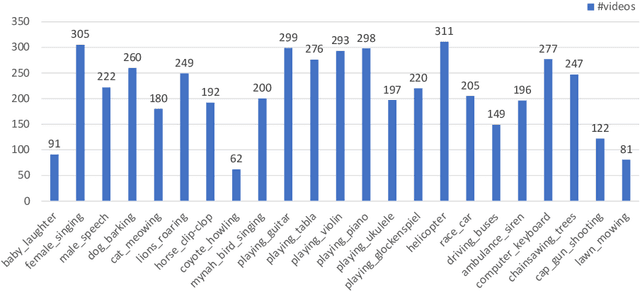
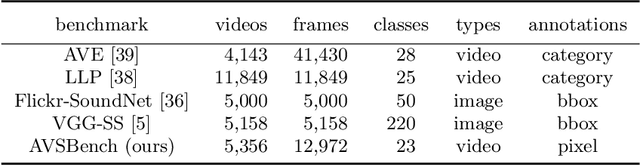
We propose to explore a new problem called audio-visual segmentation (AVS), in which the goal is to output a pixel-level map of the object(s) that produce sound at the time of the image frame. To facilitate this research, we construct the first audio-visual segmentation benchmark (AVSBench), providing pixel-wise annotations for the sounding objects in audible videos. Two settings are studied with this benchmark: 1) semi-supervised audio-visual segmentation with a single sound source and 2) fully-supervised audio-visual segmentation with multiple sound sources. To deal with the AVS problem, we propose a novel method that uses a temporal pixel-wise audio-visual interaction module to inject audio semantics as guidance for the visual segmentation process. We also design a regularization loss to encourage the audio-visual mapping during training. Quantitative and qualitative experiments on the AVSBench compare our approach to several existing methods from related tasks, demonstrating that the proposed method is promising for building a bridge between the audio and pixel-wise visual semantics. Code is available at https://github.com/OpenNLPLab/AVSBench.
Rapid Lung Ultrasound COVID-19 Severity Scoring with Resource-Efficient Deep Feature Extraction
Jul 22, 2022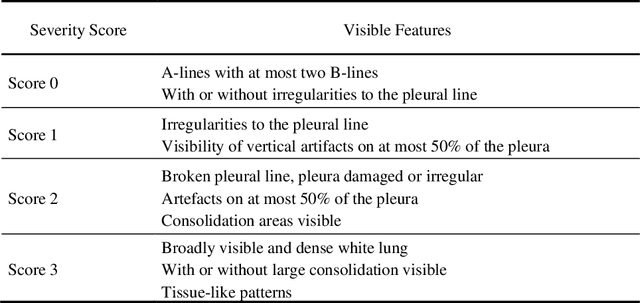
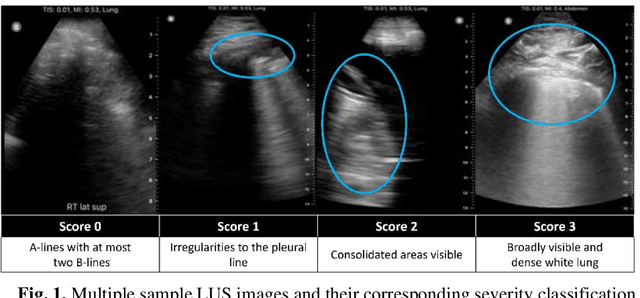
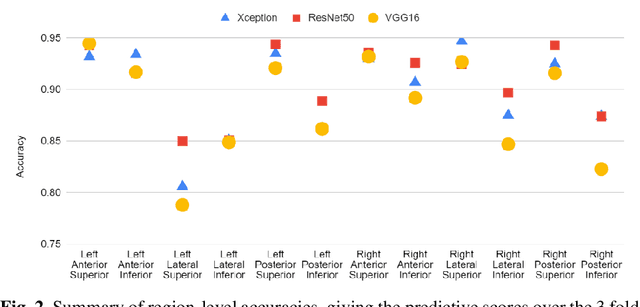
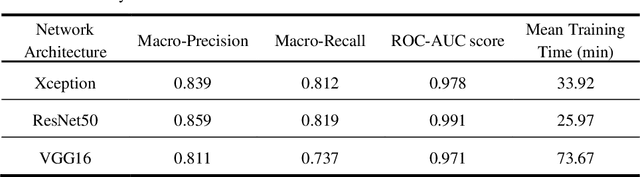
Artificial intelligence-based analysis of lung ultrasound imaging has been demonstrated as an effective technique for rapid diagnostic decision support throughout the COVID-19 pandemic. However, such techniques can require days- or weeks-long training processes and hyper-parameter tuning to develop intelligent deep learning image analysis models. This work focuses on leveraging 'off-the-shelf' pre-trained models as deep feature extractors for scoring disease severity with minimal training time. We propose using pre-trained initializations of existing methods ahead of simple and compact neural networks to reduce reliance on computational capacity. This reduction of computational capacity is of critical importance in time-limited or resource-constrained circumstances, such as the early stages of a pandemic. On a dataset of 49 patients, comprising over 20,000 images, we demonstrate that the use of existing methods as feature extractors results in the effective classification of COVID-19-related pneumonia severity while requiring only minutes of training time. Our methods can achieve an accuracy of over 0.93 on a 4-level severity score scale and provides comparable per-patient region and global scores compared to expert annotated ground truths. These results demonstrate the capability for rapid deployment and use of such minimally-adapted methods for progress monitoring, patient stratification and management in clinical practice for COVID-19 patients, and potentially in other respiratory diseases.