 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Similar Scenes arouse Similar Emotions: Parallel Data Augmentation for Stylized Image Captioning
Aug 26, 2021


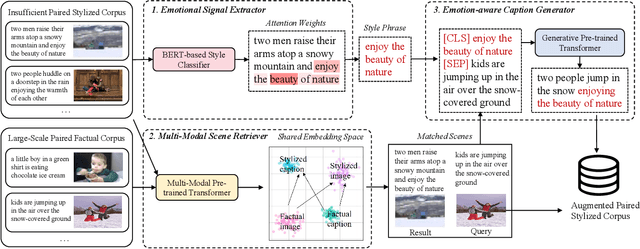
Stylized image captioning systems aim to generate a caption not only semantically related to a given image but also consistent with a given style description. One of the biggest challenges with this task is the lack of sufficient paired stylized data. Many studies focus on unsupervised approaches, without considering from the perspective of data augmentation. We begin with the observation that people may recall similar emotions when they are in similar scenes, and often express similar emotions with similar style phrases, which underpins our data augmentation idea. In this paper, we propose a novel Extract-Retrieve-Generate data augmentation framework to extract style phrases from small-scale stylized sentences and graft them to large-scale factual captions. First, we design the emotional signal extractor to extract style phrases from small-scale stylized sentences. Second, we construct the plugable multi-modal scene retriever to retrieve scenes represented with pairs of an image and its stylized caption, which are similar to the query image or caption in the large-scale factual data. In the end, based on the style phrases of similar scenes and the factual description of the current scene, we build the emotion-aware caption generator to generate fluent and diversified stylized captions for the current scene. Extensive experimental results show that our framework can alleviate the data scarcity problem effectively. It also significantly boosts the performance of several existing image captioning models in both supervised and unsupervised settings, which outperforms the state-of-the-art stylized image captioning methods in terms of both sentence relevance and stylishness by a substantial margin.
Making Images Real Again: A Comprehensive Survey on Deep Image Composition
Jun 28, 2021



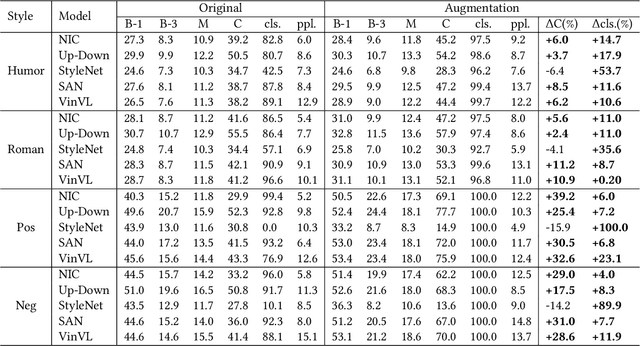
As a common image editing operation, image composition aims to cut the foreground from one image and paste it on another image, resulting in a composite image. However, there are many issues that could make the composite images unrealistic. These issues can be summarized as the inconsistency between foreground and background, which include appearance inconsistency (e.g., incompatible color and illumination) and geometry inconsistency (e.g., unreasonable size and location). Previous works on image composition target at one or more issues. Since each individual issue is a complicated problem, there are some research directions (e.g., image harmonization, object placement) which focus on only one issue. By putting all the efforts together, we can acquire realistic composite images. Sometimes, we expect the composite images to be not only realistic but also aesthetic, in which case aesthetic evaluation needs to be considered. In this survey, we summarize the datasets and methods for the above research directions. We also discuss the limitations and potential directions to facilitate the future research for image composition. Finally, as a double-edged sword, image composition may also have negative effect on our lives (e.g., fake news) and thus it is imperative to develop algorithms to fight against composite images. Datasets and codes for image composition are summarized at https://github.com/bcmi/Awesome-Image-Composition.
Nonuniform Defocus Removal for Image Classification
Jun 03, 2021
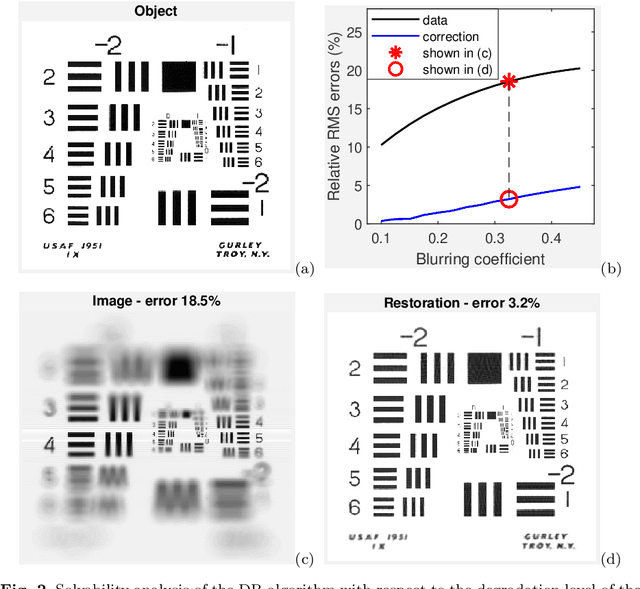
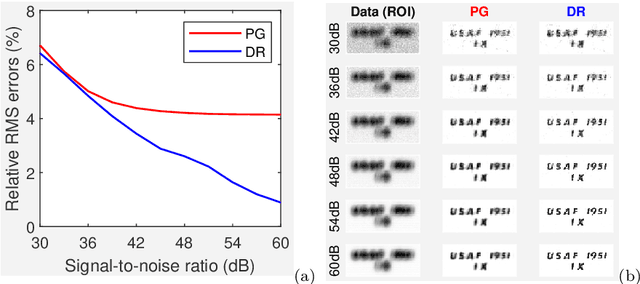
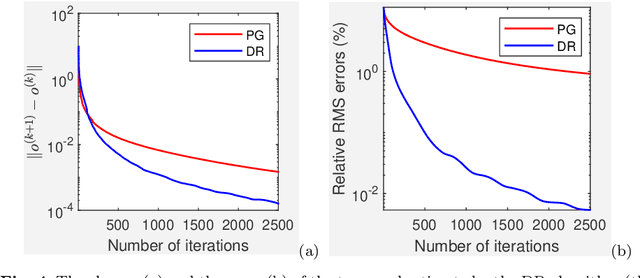
We propose and study the single-frame anisoplanatic deconvolution problem associated with image classification using machine learning algorithms, named the nonuniform defocus removal (NDR) problem. Mathematical analysis of the NDR problem is done and the so-called defocus removal (DR) algorithm for solving it is proposed. Global convergence of the DR algorithm is established without imposing any unverifiable assumption. Numerical results on simulation data show significant features of DR including solvability, noise robustness, convergence, model insensitivity and computational efficiency. Physical relevance of the NDR problem and practicability of the DR algorithm are tested on experimental data. Back to the application that originally motivated the investigation of the NDR problem, we show that the DR algorithm can improve the accuracy of classifying distorted images using convolutional neural networks. The key difference of this paper compared to most existing works on single-frame anisoplanatic deconvolution is that the new method does not require the data image to be decomposable into isoplanatic subregions. Therefore, solution approaches partitioning the image into isoplanatic zones are not applicable to the NDR problem and those handling the entire image such as the DR algorithm need to be developed and analyzed.
Subgroup Discovery in Unstructured Data
Jul 15, 2022


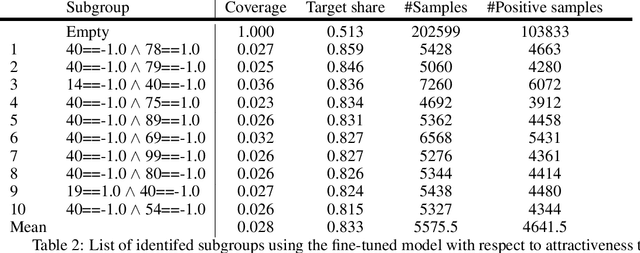
Subgroup discovery is a descriptive and exploratory data mining technique to identify subgroups in a population that exhibit interesting behavior with respect to a variable of interest. Subgroup discovery has numerous applications in knowledge discovery and hypothesis generation, yet it remains inapplicable for unstructured, high-dimensional data such as images. This is because subgroup discovery algorithms rely on defining descriptive rules based on (attribute, value) pairs, however, in unstructured data, an attribute is not well defined. Even in cases where the notion of attribute intuitively exists in the data, such as a pixel in an image, due to the high dimensionality of the data, these attributes are not informative enough to be used in a rule. In this paper, we introduce the subgroup-aware variational autoencoder, a novel variational autoencoder that learns a representation of unstructured data which leads to subgroups with higher quality. Our experimental results demonstrate the effectiveness of the method at learning subgroups with high quality while supporting the interpretability of the concepts.
Masked Autoencoders that Listen
Jul 13, 2022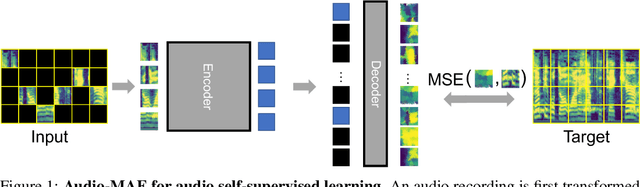
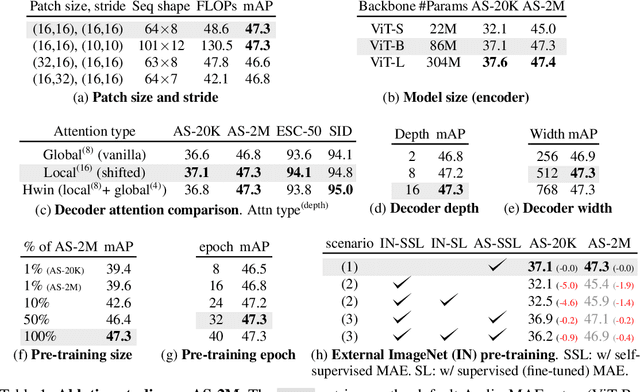

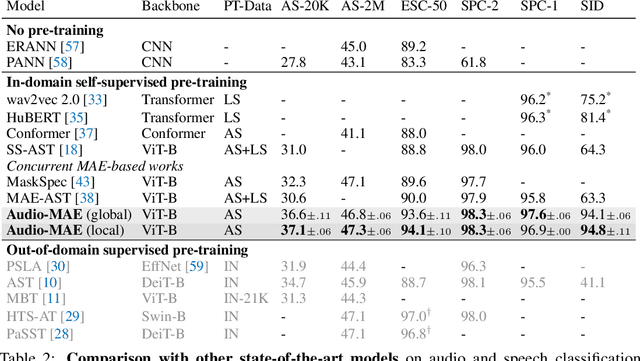
This paper studies a simple extension of image-based Masked Autoencoders (MAE) to self-supervised representation learning from audio spectrograms. Following the Transformer encoder-decoder design in MAE, our Audio-MAE first encodes audio spectrogram patches with a high masking ratio, feeding only the non-masked tokens through encoder layers. The decoder then re-orders and decodes the encoded context padded with mask tokens, in order to reconstruct the input spectrogram. We find it beneficial to incorporate local window attention in the decoder, as audio spectrograms are highly correlated in local time and frequency bands. We then fine-tune the encoder with a lower masking ratio on target datasets. Empirically, Audio-MAE sets new state-of-the-art performance on six audio and speech classification tasks, outperforming other recent models that use external supervised pre-training. The code and models will be at https://github.com/facebookresearch/AudioMAE.
ALBench: A Framework for Evaluating Active Learning in Object Detection
Jul 27, 2022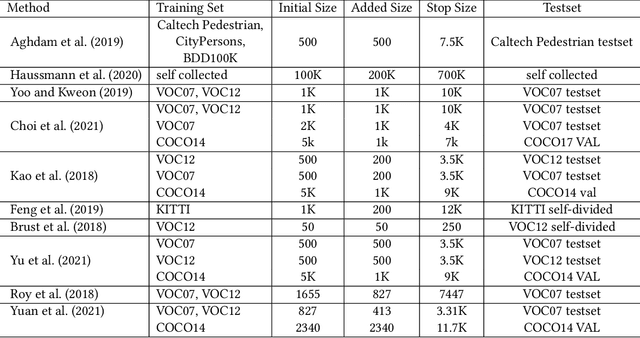
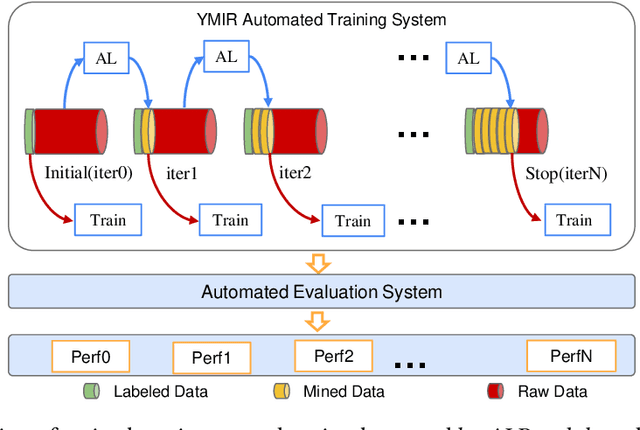
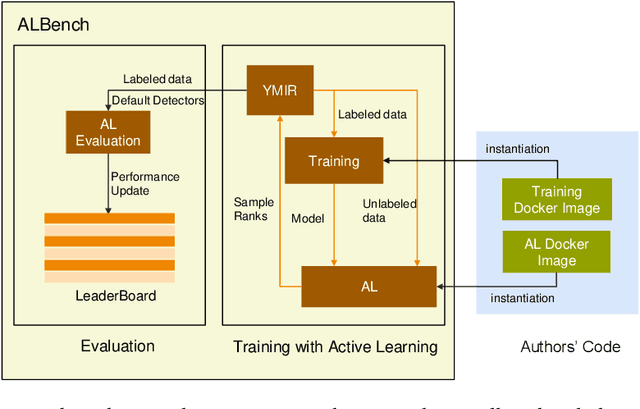
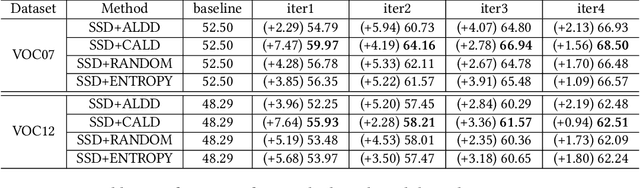
Active learning is an important technology for automated machine learning systems. In contrast to Neural Architecture Search (NAS) which aims at automating neural network architecture design, active learning aims at automating training data selection. It is especially critical for training a long-tailed task, in which positive samples are sparsely distributed. Active learning alleviates the expensive data annotation issue through incrementally training models powered with efficient data selection. Instead of annotating all unlabeled samples, it iteratively selects and annotates the most valuable samples. Active learning has been popular in image classification, but has not been fully explored in object detection. Most of current approaches on object detection are evaluated with different settings, making it difficult to fairly compare their performance. To facilitate the research in this field, this paper contributes an active learning benchmark framework named as ALBench for evaluating active learning in object detection. Developed on an automatic deep model training system, this ALBench framework is easy-to-use, compatible with different active learning algorithms, and ensures the same training and testing protocols. We hope this automated benchmark system help researchers to easily reproduce literature's performance and have objective comparisons with prior arts. The code will be release through Github.
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022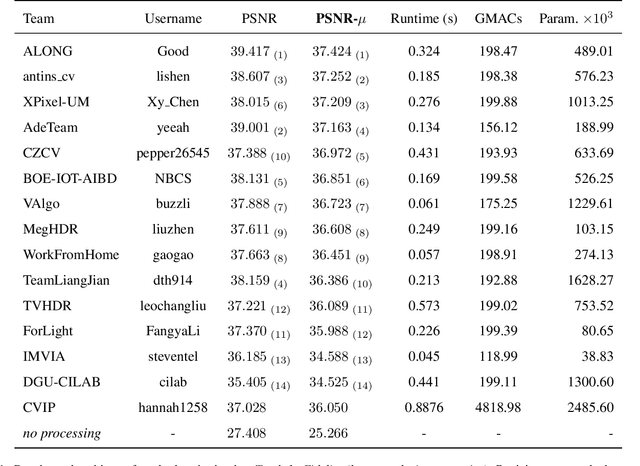
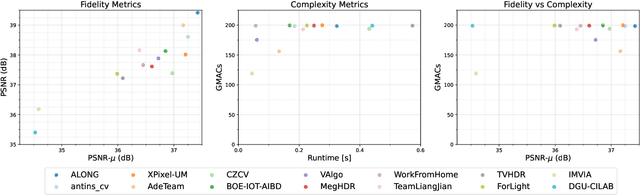
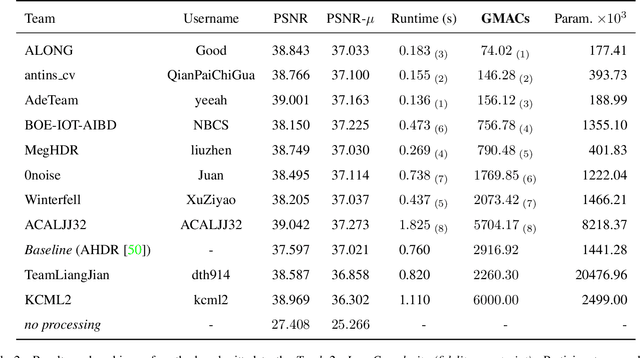
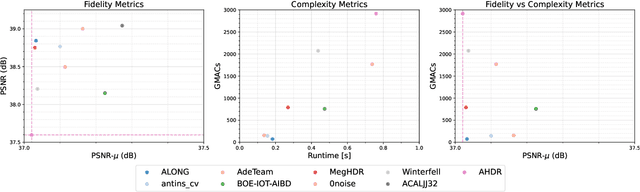
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables
Self-Supervised Learning of Echocardiogram Videos Enables Data-Efficient Clinical Diagnosis
Jul 23, 2022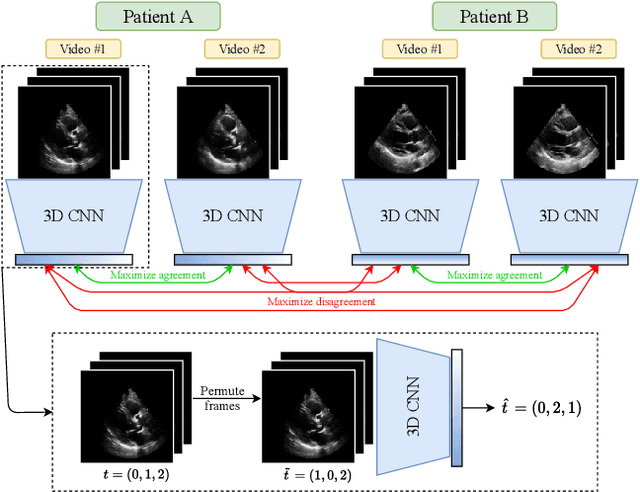
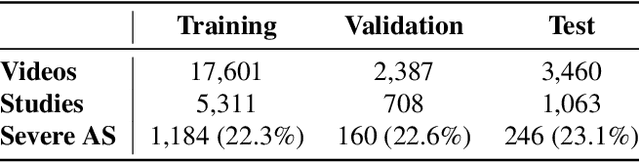
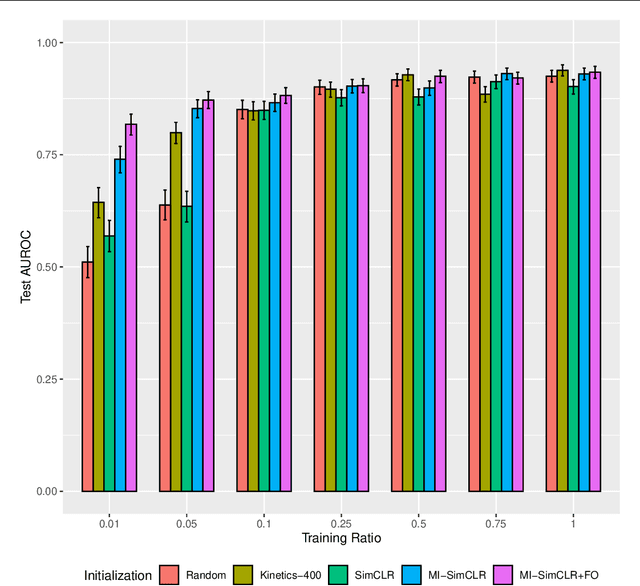
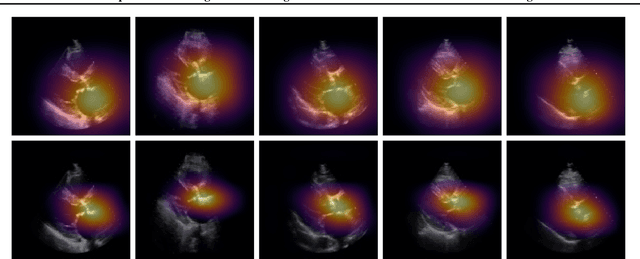
Given the difficulty of obtaining high-quality labels for medical image recognition tasks, there is a need for deep learning techniques that can be adequately fine-tuned on small labeled data sets. Recent advances in self-supervised learning techniques have shown that such an in-domain representation learning approach can provide a strong initialization for supervised fine-tuning, proving much more data-efficient than standard transfer learning from a supervised pretraining task. However, these applications are not adapted to applications to medical diagnostics captured in a video format. With this progress in mind, we developed a self-supervised learning approach catered to echocardiogram videos with the goal of learning strong representations for downstream fine-tuning on the task of diagnosing aortic stenosis (AS), a common and dangerous disease of the aortic valve. When fine-tuned on 1% of the training data, our best self-supervised learning model achieves 0.818 AUC (95% CI: 0.794, 0.840), while the standard transfer learning approach reaches 0.644 AUC (95% CI: 0.610, 0.677). We also find that our self-supervised model attends more closely to the aortic valve when predicting severe AS as demonstrated by saliency map visualizations.
Chat-to-Design: AI Assisted Personalized Fashion Design
Jul 03, 2022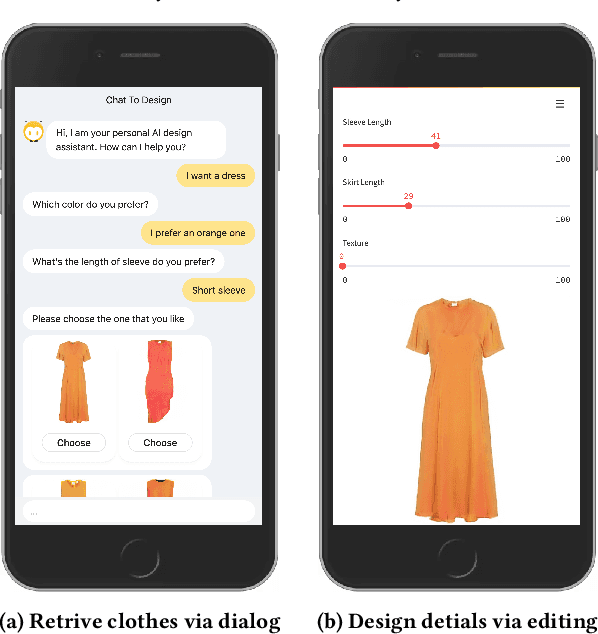
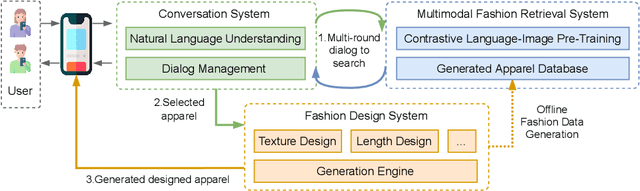

In this demo, we present Chat-to-Design, a new multimodal interaction system for personalized fashion design. Compared to classic systems that recommend apparel based on keywords, Chat-to-Design enables users to design clothes in two steps: 1) coarse-grained selection via conversation and 2) fine-grained editing via an interactive interface. It encompasses three sub-systems to deliver an immersive user experience: A conversation system empowered by natural language understanding to accept users' requests and manages dialogs; A multimodal fashion retrieval system empowered by a large-scale pretrained language-image network to retrieve requested apparel; A fashion design system empowered by emerging generative techniques to edit attributes of retrieved clothes.
Achieving Utility, Fairness, and Compactness via Tunable Information Bottleneck Measures
Jun 20, 2022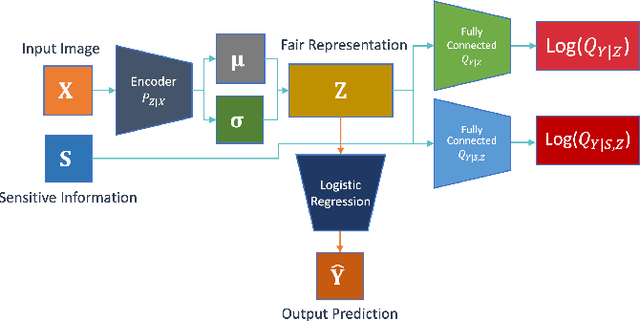

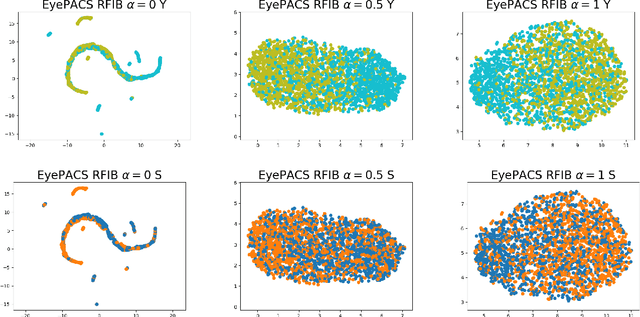

Designing machine learning algorithms that are accurate yet fair, not discriminating based on any sensitive attribute, is of paramount importance for society to accept AI for critical applications. In this article, we propose a novel fair representation learning method termed the R\'enyi Fair Information Bottleneck Method (RFIB) which incorporates constraints for utility, fairness, and compactness of representation, and apply it to image classification. A key attribute of our approach is that we consider - in contrast to most prior work - both demographic parity and equalized odds as fairness constraints, allowing for a more nuanced satisfaction of both criteria. Leveraging a variational approach, we show that our objectives yield a loss function involving classical Information Bottleneck (IB) measures and establish an upper bound in terms of the R\'enyi divergence of order $\alpha$ on the mutual information IB term measuring compactness between the input and its encoded embedding. Experimenting on three different image datasets (EyePACS, CelebA, and FairFace), we study the influence of the $\alpha$ parameter as well as two other tunable IB parameters on achieving utility/fairness trade-off goals, and show that the $\alpha$ parameter gives an additional degree of freedom that can be used to control the compactness of the representation. We evaluate the performance of our method using various utility, fairness, and compound utility/fairness metrics, showing that RFIB outperforms current state-of-the-art approaches.