 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pivoting Retail Supply Chain with Deep Generative Techniques: Taxonomy, Survey and Insights
Feb 29, 2024
Generative AI applications, such as ChatGPT or DALL-E, have shown the world their impressive capabilities in generating human-like text or image. Diving deeper, the science stakeholder for those AI applications are Deep Generative Models, a.k.a DGMs, which are designed to learn the underlying distribution of the data and generate new data points that are statistically similar to the original dataset. One critical question is raised: how can we leverage DGMs into morden retail supply chain realm? To address this question, this paper expects to provide a comprehensive review of DGMs and discuss their existing and potential usecases in retail supply chain, by (1) providing a taxonomy and overview of state-of-the-art DGMs and their variants, (2) reviewing existing DGM applications in retail supply chain from a end-to-end view of point, and (3) discussing insights and potential directions on how DGMs can be further utilized on solving retail supply chain problems.
Learning to Find Missing Video Frames with Synthetic Data Augmentation: A General Framework and Application in Generating Thermal Images Using RGB Cameras
Feb 29, 2024
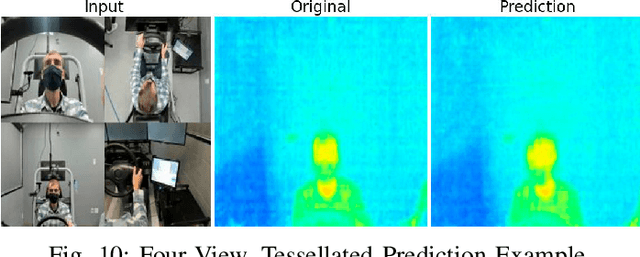
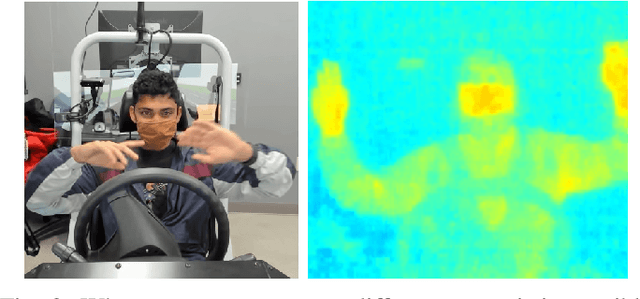
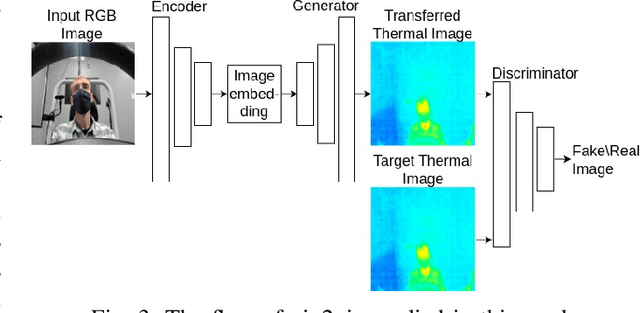
Advanced Driver Assistance Systems (ADAS) in intelligent vehicles rely on accurate driver perception within the vehicle cabin, often leveraging a combination of sensing modalities. However, these modalities operate at varying rates, posing challenges for real-time, comprehensive driver state monitoring. This paper addresses the issue of missing data due to sensor frame rate mismatches, introducing a generative model approach to create synthetic yet realistic thermal imagery. We propose using conditional generative adversarial networks (cGANs), specifically comparing the pix2pix and CycleGAN architectures. Experimental results demonstrate that pix2pix outperforms CycleGAN, and utilizing multi-view input styles, especially stacked views, enhances the accuracy of thermal image generation. Moreover, the study evaluates the model's generalizability across different subjects, revealing the importance of individualized training for optimal performance. The findings suggest the potential of generative models in addressing missing frames, advancing driver state monitoring for intelligent vehicles, and underscoring the need for continued research in model generalization and customization.
Training-free image style alignment for self-adapting domain shift on handheld ultrasound devices
Feb 17, 2024Handheld ultrasound devices face usage limitations due to user inexperience and cannot benefit from supervised deep learning without extensive expert annotations. Moreover, the models trained on standard ultrasound device data are constrained by training data distribution and perform poorly when directly applied to handheld device data. In this study, we propose the Training-free Image Style Alignment (TISA) framework to align the style of handheld device data to those of standard devices. The proposed TISA can directly infer handheld device images without extra training and is suited for clinical applications. We show that TISA performs better and more stably in medical detection and segmentation tasks for handheld device data. We further validate TISA as the clinical model for automatic measurements of spinal curvature and carotid intima-media thickness. The automatic measurements agree well with manual measurements made by human experts and the measurement errors remain within clinically acceptable ranges. We demonstrate the potential for TISA to facilitate automatic diagnosis on handheld ultrasound devices and expedite their eventual widespread use.
Reinforcement Learning as a Parsimonious Alternative to Prediction Cascades: A Case Study on Image Segmentation
Feb 19, 2024Deep learning architectures have achieved state-of-the-art (SOTA) performance on computer vision tasks such as object detection and image segmentation. This may be attributed to the use of over-parameterized, monolithic deep learning architectures executed on large datasets. Although such architectures lead to increased accuracy, this is usually accompanied by a large increase in computation and memory requirements during inference. While this is a non-issue in traditional machine learning pipelines, the recent confluence of machine learning and fields like the Internet of Things has rendered such large architectures infeasible for execution in low-resource settings. In such settings, previous efforts have proposed decision cascades where inputs are passed through models of increasing complexity until desired performance is achieved. However, we argue that cascaded prediction leads to increased computational cost due to wasteful intermediate computations. To address this, we propose PaSeR (Parsimonious Segmentation with Reinforcement Learning) a non-cascading, cost-aware learning pipeline as an alternative to cascaded architectures. Through experimental evaluation on real-world and standard datasets, we demonstrate that PaSeR achieves better accuracy while minimizing computational cost relative to cascaded models. Further, we introduce a new metric IoU/GigaFlop to evaluate the balance between cost and performance. On the real-world task of battery material phase segmentation, PaSeR yields a minimum performance improvement of 174% on the IoU/GigaFlop metric with respect to baselines. We also demonstrate PaSeR's adaptability to complementary models trained on a noisy MNIST dataset, where it achieved a minimum performance improvement on IoU/GigaFlop of 13.4% over SOTA models. Code and data are available at https://github.com/scailab/paser .
Deep Learning for Medical Image Segmentation with Imprecise Annotation
Feb 11, 2024Medical image segmentation (MIS) plays an instrumental role in medical image analysis, where considerable efforts have been devoted to automating the process. Currently, mainstream MIS approaches are based on deep neural networks (DNNs) which are typically trained on a dataset that contains annotation masks produced by doctors. However, in the medical domain, the annotation masks generated by different doctors can inherently vary because a doctor may unnecessarily produce precise and unique annotations to meet the goal of diagnosis. Therefore, the DNN model trained on the data annotated by certain doctors, often just a single doctor, could undesirably favour those doctors who annotate the training data, leading to the unsatisfaction of a new doctor who will use the trained model. To address this issue, this work investigates the utilization of multi-expert annotation to enhance the adaptability of the model to a new doctor and we conduct a pilot study on the MRI brain segmentation task. Experimental results demonstrate that the model trained on a dataset with multi-expert annotation can efficiently cater for a new doctor, after lightweight fine-tuning on just a few annotations from the new doctor.
Accelerated Real-time Cine and Flow under In-magnet Staged Exercise
Feb 27, 2024Background: Cardiovascular magnetic resonance imaging (CMR) is a well-established imaging tool for diagnosing and managing cardiac conditions. The integration of exercise stress with CMR (ExCMR) can enhance its diagnostic capacity. Despite recent advances in CMR technology, ExCMR remains technically challenging due to motion artifacts and limited spatial and temporal resolution. Methods: This study investigates the feasibility of biventricular functional and hemodynamic assessment using real-time (RT) ExCMR during a staged exercise protocol in 26 healthy volunteers. We introduce a coil reweighting technique to minimize motion artifacts. In addition, we identify and analyze heartbeats from the end-expiratory phase to enhance the repeatability of cardiac function quantification. To demonstrate clinical feasibility, qualitative results from five patients are also presented. Results: Our findings indicate a consistent decrease in end-systolic volume (ESV) and stable end-diastolic volume (EDV) across exercise intensities, leading to increased stroke volume (SV) and ejection fraction (EF). Coil reweighting effectively reduces motion artifacts, improving image quality in both healthy volunteers and patients. The repeatability of cardiac function parameters, demonstrated by scan-rescan tests in nine volunteers, improves with the selection of end-expiratory beats. Conclusions: The study demonstrates that RT ExCMR with in-magnet exercise is a feasible and effective method for dynamic cardiac function monitoring during exercise. The proposed coil reweighting technique and selection of end-expiratory beats significantly enhance image quality and repeatability.
Zero-Shot Unsupervised and Text-Based Audio Editing Using DDPM Inversion
Feb 25, 2024Editing signals using large pre-trained models, in a zero-shot manner, has recently seen rapid advancements in the image domain. However, this wave has yet to reach the audio domain. In this paper, we explore two zero-shot editing techniques for audio signals, which use DDPM inversion on pre-trained diffusion models. The first, adopted from the image domain, allows text-based editing. The second, is a novel approach for discovering semantically meaningful editing directions without supervision. When applied to music signals, this method exposes a range of musically interesting modifications, from controlling the participation of specific instruments to improvisations on the melody. Samples and code can be found on our examples page in https://hilamanor.github.io/AudioEditing/ .
Integrating Preprocessing Methods and Convolutional Neural Networks for Effective Tumor Detection in Medical Imaging
Feb 25, 2024This research presents a machine-learning approach for tumor detection in medical images using convolutional neural networks (CNNs). The study focuses on preprocessing techniques to enhance image features relevant to tumor detection, followed by developing and training a CNN model for accurate classification. Various image processing techniques, including Gaussian smoothing, bilateral filtering, and K-means clustering, are employed to preprocess the input images and highlight tumor regions. The CNN model is trained and evaluated on a dataset of medical images, with augmentation and data generators utilized to enhance model generalization. Experimental results demonstrate the effectiveness of the proposed approach in accurately detecting tumors in medical images, paving the way for improved diagnostic tools in healthcare.
Graph Convolutional Neural Networks for Automated Echocardiography View Recognition: A Holistic Approach
Mar 01, 2024To facilitate diagnosis on cardiac ultrasound (US), clinical practice has established several standard views of the heart, which serve as reference points for diagnostic measurements and define viewports from which images are acquired. Automatic view recognition involves grouping those images into classes of standard views. Although deep learning techniques have been successful in achieving this, they still struggle with fully verifying the suitability of an image for specific measurements due to factors like the correct location, pose, and potential occlusions of cardiac structures. Our approach goes beyond view classification and incorporates a 3D mesh reconstruction of the heart that enables several more downstream tasks, like segmentation and pose estimation. In this work, we explore learning 3D heart meshes via graph convolutions, using similar techniques to learn 3D meshes in natural images, such as human pose estimation. As the availability of fully annotated 3D images is limited, we generate synthetic US images from 3D meshes by training an adversarial denoising diffusion model. Experiments were conducted on synthetic and clinical cases for view recognition and structure detection. The approach yielded good performance on synthetic images and, despite being exclusively trained on synthetic data, it already showed potential when applied to clinical images. With this proof-of-concept, we aim to demonstrate the benefits of graphs to improve cardiac view recognition that can ultimately lead to better efficiency in cardiac diagnosis.
HyperSDFusion: Bridging Hierarchical Structures in Language and Geometry for Enhanced 3D Text2Shape Generation
Mar 01, 2024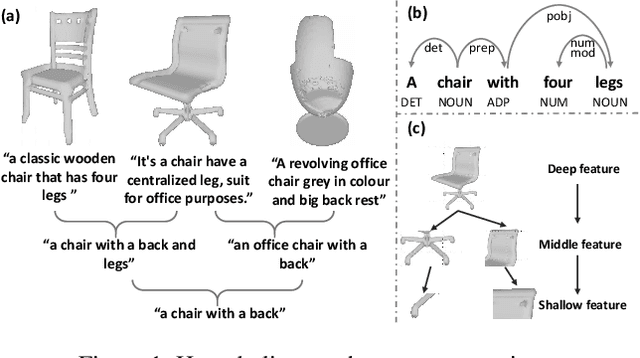

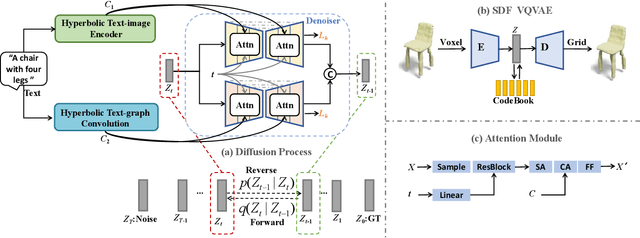
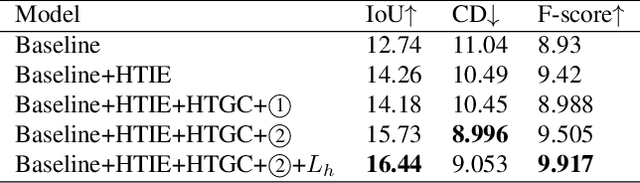
3D shape generation from text is a fundamental task in 3D representation learning. The text-shape pairs exhibit a hierarchical structure, where a general text like "chair" covers all 3D shapes of the chair, while more detailed prompts refer to more specific shapes. Furthermore, both text and 3D shapes are inherently hierarchical structures. However, existing Text2Shape methods, such as SDFusion, do not exploit that. In this work, we propose HyperSDFusion, a dual-branch diffusion model that generates 3D shapes from a given text. Since hyperbolic space is suitable for handling hierarchical data, we propose to learn the hierarchical representations of text and 3D shapes in hyperbolic space. First, we introduce a hyperbolic text-image encoder to learn the sequential and multi-modal hierarchical features of text in hyperbolic space. In addition, we design a hyperbolic text-graph convolution module to learn the hierarchical features of text in hyperbolic space. In order to fully utilize these text features, we introduce a dual-branch structure to embed text features in 3D feature space. At last, to endow the generated 3D shapes with a hierarchical structure, we devise a hyperbolic hierarchical loss. Our method is the first to explore the hyperbolic hierarchical representation for text-to-shape generation. Experimental results on the existing text-to-shape paired dataset, Text2Shape, achieved state-of-the-art results.