 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
End-to-end optimized image compression with competition of prior distributions
Nov 17, 2021
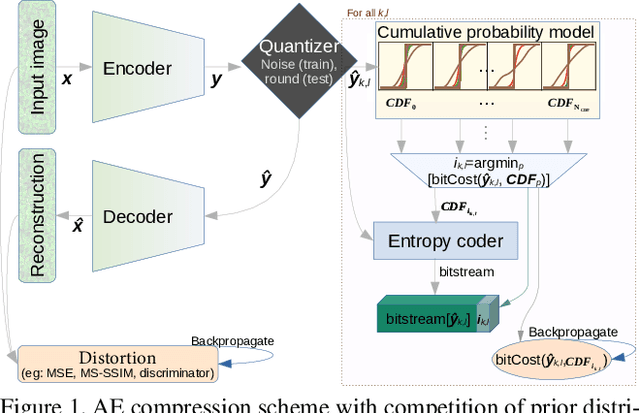
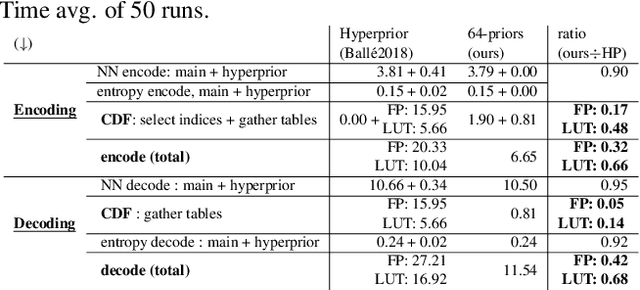

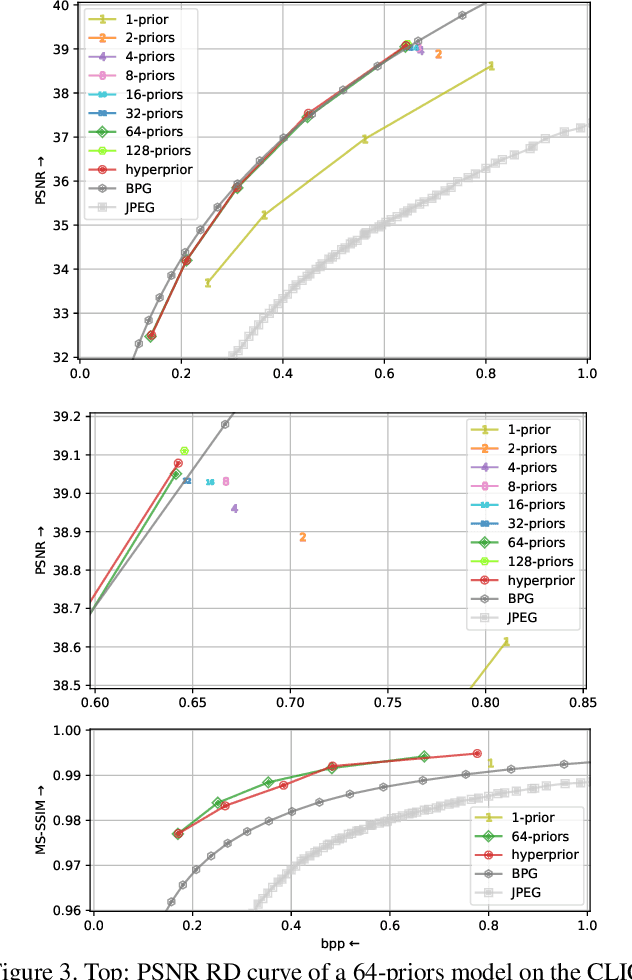
Convolutional autoencoders are now at the forefront of image compression research. To improve their entropy coding, encoder output is typically analyzed with a second autoencoder to generate per-variable parametrized prior probability distributions. We instead propose a compression scheme that uses a single convolutional autoencoder and multiple learned prior distributions working as a competition of experts. Trained prior distributions are stored in a static table of cumulative distribution functions. During inference, this table is used by an entropy coder as a look-up-table to determine the best prior for each spatial location. Our method offers rate-distortion performance comparable to that obtained with a predicted parametrized prior with only a fraction of its entropy coding and decoding complexity.
InsetGAN for Full-Body Image Generation
Mar 14, 2022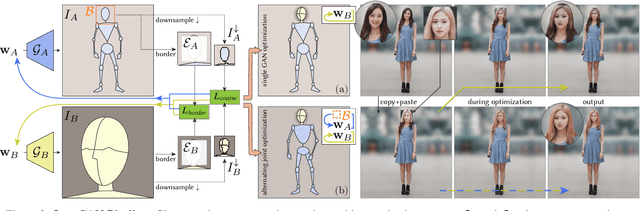



While GANs can produce photo-realistic images in ideal conditions for certain domains, the generation of full-body human images remains difficult due to the diversity of identities, hairstyles, clothing, and the variance in pose. Instead of modeling this complex domain with a single GAN, we propose a novel method to combine multiple pretrained GANs, where one GAN generates a global canvas (e.g., human body) and a set of specialized GANs, or insets, focus on different parts (e.g., faces, shoes) that can be seamlessly inserted onto the global canvas. We model the problem as jointly exploring the respective latent spaces such that the generated images can be combined, by inserting the parts from the specialized generators onto the global canvas, without introducing seams. We demonstrate the setup by combining a full body GAN with a dedicated high-quality face GAN to produce plausible-looking humans. We evaluate our results with quantitative metrics and user studies.
Uncertainty Quantification in Medical Image Segmentation with Multi-decoder U-Net
Sep 15, 2021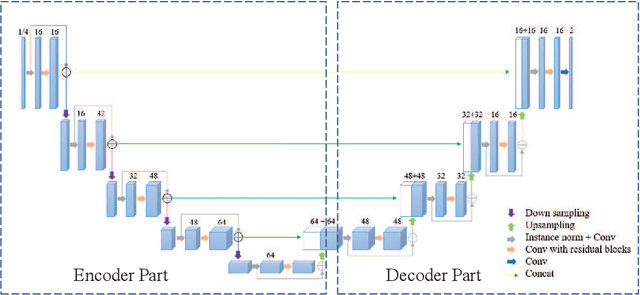
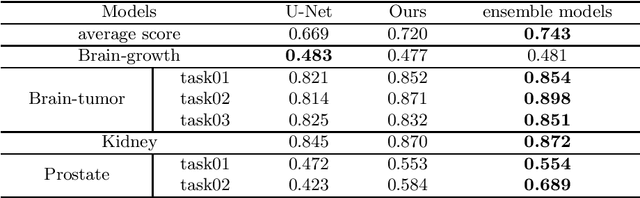
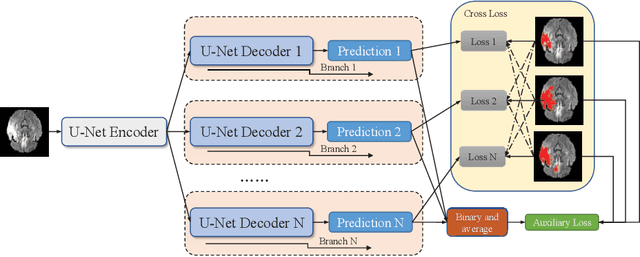
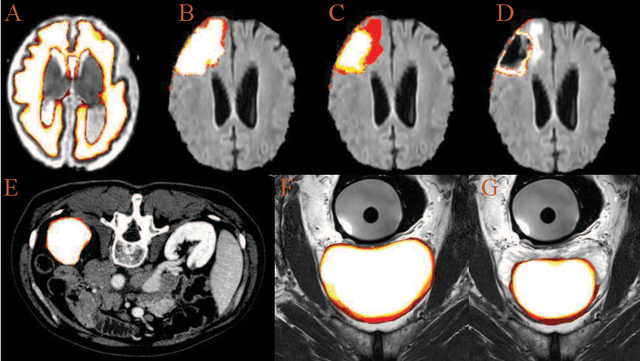
Accurate medical image segmentation is crucial for diagnosis and analysis. However, the models without calibrated uncertainty estimates might lead to errors in downstream analysis and exhibit low levels of robustness. Estimating the uncertainty in the measurement is vital to making definite, informed conclusions. Especially, it is difficult to make accurate predictions on ambiguous areas and focus boundaries for both models and radiologists, even harder to reach a consensus with multiple annotations. In this work, the uncertainty under these areas is studied, which introduces significant information with anatomical structure and is as important as segmentation performance. We exploit the medical image segmentation uncertainty quantification by measuring segmentation performance with multiple annotations in a supervised learning manner and propose a U-Net based architecture with multiple decoders, where the image representation is encoded with the same encoder, and segmentation referring to each annotation is estimated with multiple decoders. Nevertheless, a cross-loss function is proposed for bridging the gap between different branches. The proposed architecture is trained in an end-to-end manner and able to improve predictive uncertainty estimates. The model achieves comparable performance with fewer parameters to the integrated training model that ranked the runner-up in the MICCAI-QUBIQ 2020 challenge.
Image-to-Height Domain Translation for Synthetic Aperture Sonar
Dec 12, 2021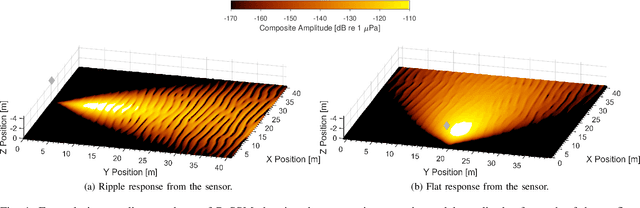


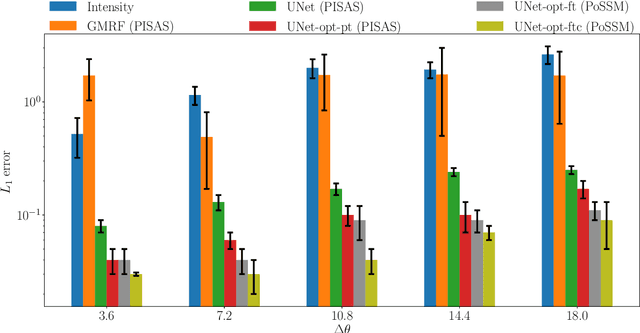
Observations of seabed texture with synthetic aperture sonar are dependent upon several factors. In this work, we focus on collection geometry with respect to isotropic and anisotropic textures. The low grazing angle of the collection geometry, combined with orientation of the sonar path relative to anisotropic texture, poses a significant challenge for image-alignment and other multi-view scene understanding frameworks. We previously proposed using features captured from estimated seabed relief to improve scene understanding. While several methods have been developed to estimate seabed relief via intensity, no large-scale study exists in the literature. Furthermore, a dataset of coregistered seabed relief maps and sonar imagery is nonexistent to learn this domain translation. We address these problems by producing a large simulated dataset containing coregistered pairs of seabed relief and intensity maps from two unique sonar data simulation techniques. We apply three types of models, with varying complexity, to translate intensity imagery to seabed relief: a Gaussian Markov Random Field approach (GMRF), a conditional Generative Adversarial Network (cGAN), and UNet architectures. Methods are compared in reference to the coregistered simulated datasets using L1 error. Additionally, predictions on simulated and real SAS imagery are shown. Finally, models are compared on two datasets of hand-aligned SAS imagery and evaluated in terms of L1 error across multiple aspects in comparison to using intensity. Our comprehensive experiments show that the proposed UNet architectures outperform the GMRF and pix2pix cGAN models on seabed relief estimation for simulated and real SAS imagery.
SGUIE-Net: Semantic Attention Guided Underwater Image Enhancement with Multi-Scale Perception
Jan 08, 2022



Due to the wavelength-dependent light attenuation, refraction and scattering, underwater images usually suffer from color distortion and blurred details. However, due to the limited number of paired underwater images with undistorted images as reference, training deep enhancement models for diverse degradation types is quite difficult. To boost the performance of data-driven approaches, it is essential to establish more effective learning mechanisms that mine richer supervised information from limited training sample resources. In this paper, we propose a novel underwater image enhancement network, called SGUIE-Net, in which we introduce semantic information as high-level guidance across different images that share common semantic regions. Accordingly, we propose semantic region-wise enhancement module to perceive the degradation of different semantic regions from multiple scales and feed it back to the global attention features extracted from its original scale. This strategy helps to achieve robust and visually pleasant enhancements to different semantic objects, which should thanks to the guidance of semantic information for differentiated enhancement. More importantly, for those degradation types that are not common in the training sample distribution, the guidance connects them with the already well-learned types according to their semantic relevance. Extensive experiments on the publicly available datasets and our proposed dataset demonstrated the impressive performance of SGUIE-Net. The code and proposed dataset are available at: https://trentqq.github.io/SGUIE-Net.html
Domain Adaptive Person Search
Jul 25, 2022
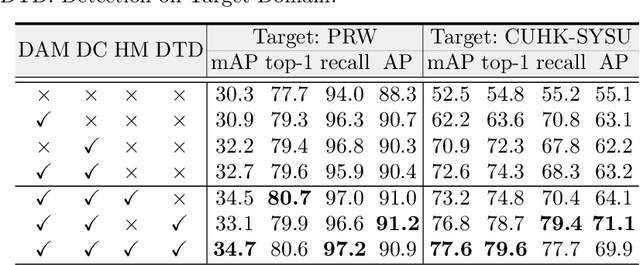
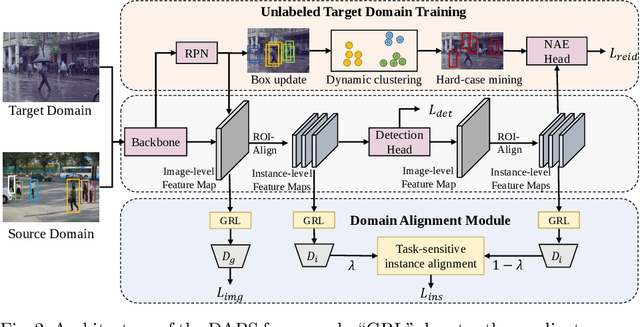

Person search is a challenging task which aims to achieve joint pedestrian detection and person re-identification (ReID). Previous works have made significant advances under fully and weakly supervised settings. However, existing methods ignore the generalization ability of the person search models. In this paper, we take a further step and present Domain Adaptive Person Search (DAPS), which aims to generalize the model from a labeled source domain to the unlabeled target domain. Two major challenges arises under this new setting: one is how to simultaneously solve the domain misalignment issue for both detection and Re-ID tasks, and the other is how to train the ReID subtask without reliable detection results on the target domain. To address these challenges, we propose a strong baseline framework with two dedicated designs. 1) We design a domain alignment module including image-level and task-sensitive instance-level alignments, to minimize the domain discrepancy. 2) We take full advantage of the unlabeled data with a dynamic clustering strategy, and employ pseudo bounding boxes to support ReID and detection training on the target domain. With the above designs, our framework achieves 34.7% in mAP and 80.6% in top-1 on PRW dataset, surpassing the direct transferring baseline by a large margin. Surprisingly, the performance of our unsupervised DAPS model even surpasses some of the fully and weakly supervised methods. The code is available at https://github.com/caposerenity/DAPS.
Face Morphing Attack Detection Using Privacy-Aware Training Data
Jul 02, 2022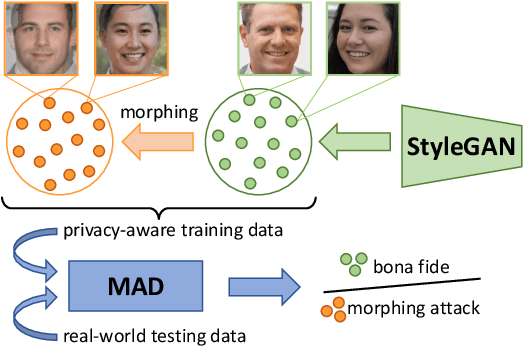


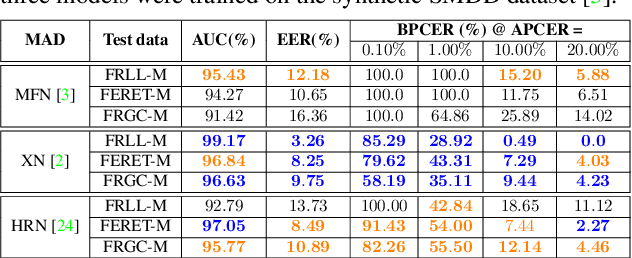
Images of morphed faces pose a serious threat to face recognition--based security systems, as they can be used to illegally verify the identity of multiple people with a single morphed image. Modern detection algorithms learn to identify such morphing attacks using authentic images of real individuals. This approach raises various privacy concerns and limits the amount of publicly available training data. In this paper, we explore the efficacy of detection algorithms that are trained only on faces of non--existing people and their respective morphs. To this end, two dedicated algorithms are trained with synthetic data and then evaluated on three real-world datasets, i.e.: FRLL-Morphs, FERET-Morphs and FRGC-Morphs. Our results show that synthetic facial images can be successfully employed for the training process of the detection algorithms and generalize well to real-world scenarios.
Cross-modal Prototype Driven Network for Radiology Report Generation
Jul 11, 2022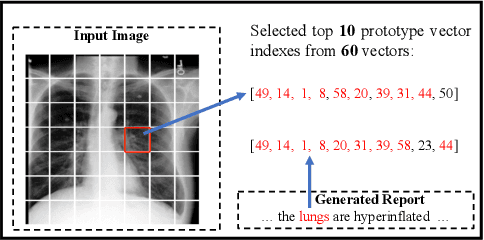
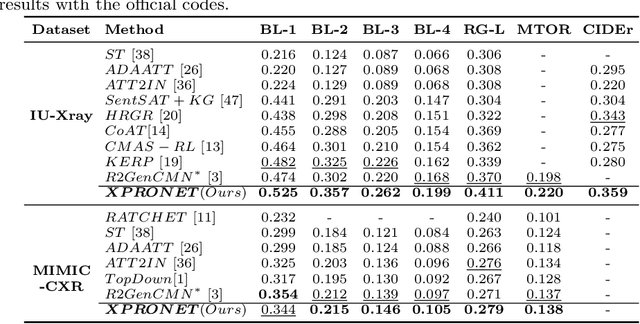
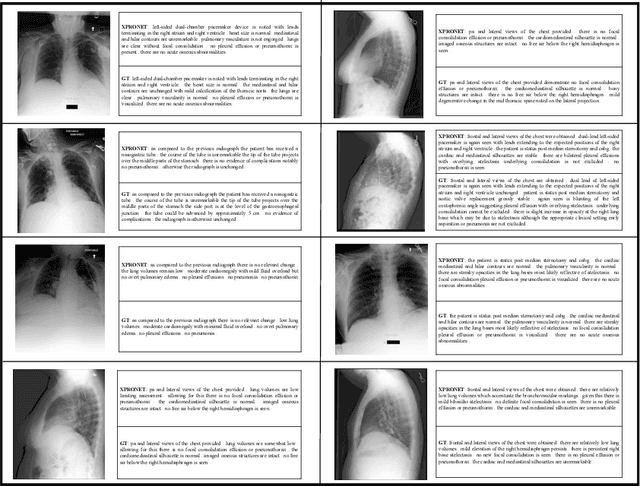
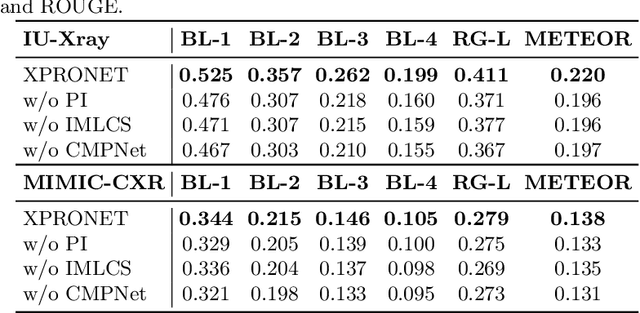
Radiology report generation (RRG) aims to describe automatically a radiology image with human-like language and could potentially support the work of radiologists, reducing the burden of manual reporting. Previous approaches often adopt an encoder-decoder architecture and focus on single-modal feature learning, while few studies explore cross-modal feature interaction. Here we propose a Cross-modal PROtotype driven NETwork (XPRONET) to promote cross-modal pattern learning and exploit it to improve the task of radiology report generation. This is achieved by three well-designed, fully differentiable and complementary modules: a shared cross-modal prototype matrix to record the cross-modal prototypes; a cross-modal prototype network to learn the cross-modal prototypes and embed the cross-modal information into the visual and textual features; and an improved multi-label contrastive loss to enable and enhance multi-label prototype learning. XPRONET obtains substantial improvements on the IU-Xray and MIMIC-CXR benchmarks, where its performance exceeds recent state-of-the-art approaches by a large margin on IU-Xray and comparable performance on MIMIC-CXR.
Invertible Image Signal Processing
Apr 06, 2021



Unprocessed RAW data is a highly valuable image format for image editing and computer vision. However, since the file size of RAW data is huge, most users can only get access to processed and compressed sRGB images. To bridge this gap, we design an Invertible Image Signal Processing (InvISP) pipeline, which not only enables rendering visually appealing sRGB images but also allows recovering nearly perfect RAW data. Due to our framework's inherent reversibility, we can reconstruct realistic RAW data instead of synthesizing RAW data from sRGB images without any memory overhead. We also integrate a differentiable JPEG compression simulator that empowers our framework to reconstruct RAW data from JPEG images. Extensive quantitative and qualitative experiments on two DSLR demonstrate that our method obtains much higher quality in both rendered sRGB images and reconstructed RAW data than alternative methods.
Positional Contrastive Learning for Volumetric Medical Image Segmentation
Jun 18, 2021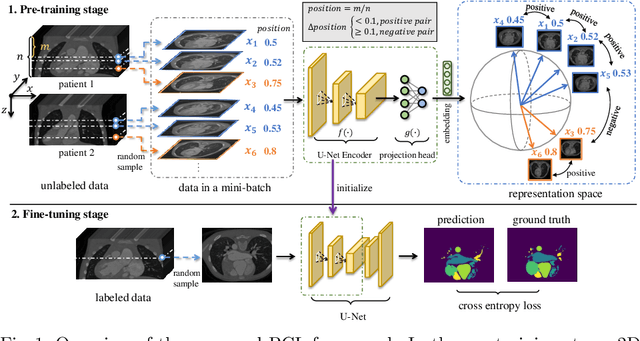
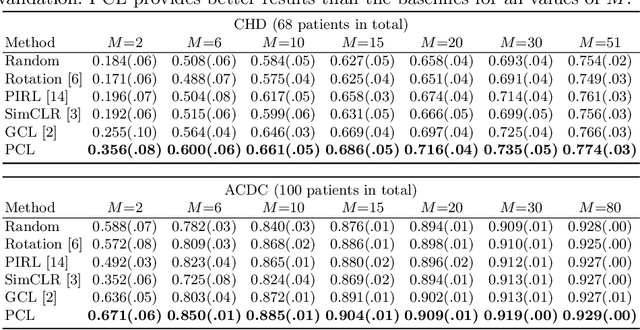
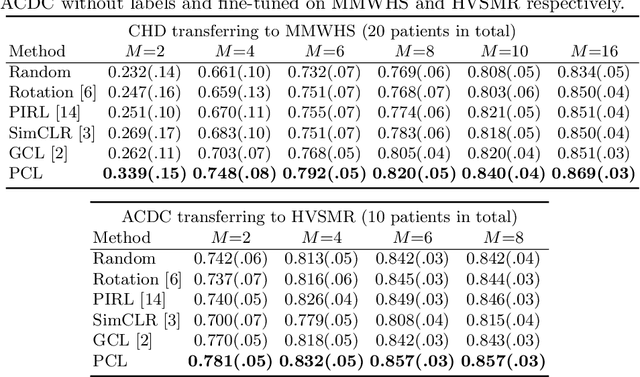
The success of deep learning heavily depends on the availability of large labeled training sets. However, it is hard to get large labeled datasets in medical image domain because of the strict privacy concern and costly labeling efforts. Contrastive learning, an unsupervised learning technique, has been proved powerful in learning image-level representations from unlabeled data. The learned encoder can then be transferred or fine-tuned to improve the performance of downstream tasks with limited labels. A critical step in contrastive learning is the generation of contrastive data pairs, which is relatively simple for natural image classification but quite challenging for medical image segmentation due to the existence of the same tissue or organ across the dataset. As a result, when applied to medical image segmentation, most state-of-the-art contrastive learning frameworks inevitably introduce a lot of false-negative pairs and result in degraded segmentation quality. To address this issue, we propose a novel positional contrastive learning (PCL) framework to generate contrastive data pairs by leveraging the position information in volumetric medical images. Experimental results on CT and MRI datasets demonstrate that the proposed PCL method can substantially improve the segmentation performance compared to existing methods in both semi-supervised setting and transfer learning setting.