 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fully Transformer Networks for Semantic Image Segmentation
Jun 08, 2021
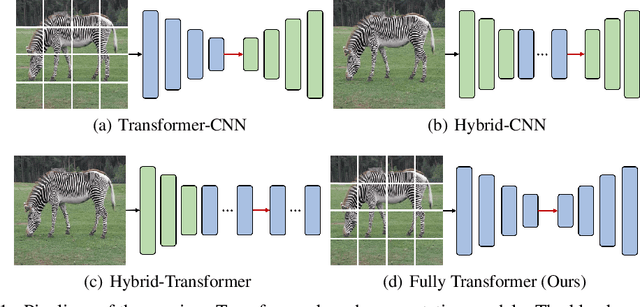
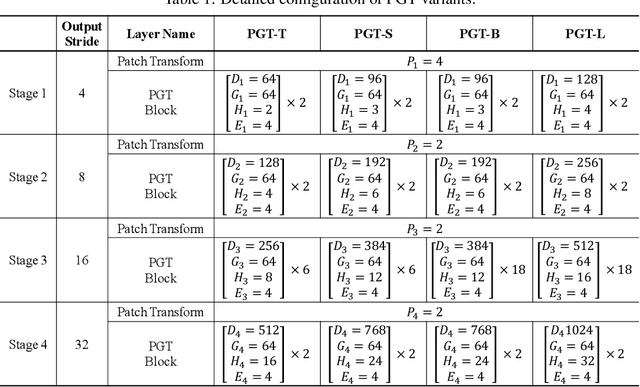
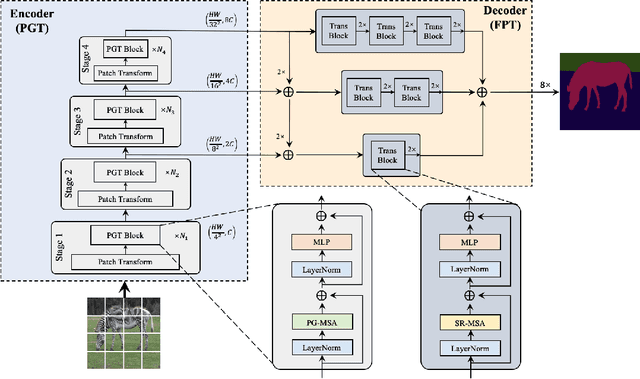
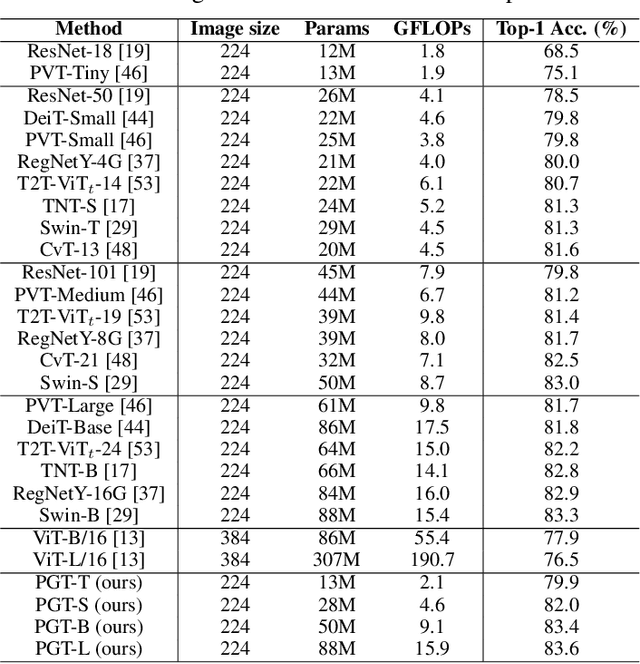
Transformers have shown impressive performance in various natural language processing and computer vision tasks, due to the capability of modeling long-range dependencies. Recent progress has demonstrated to combine such transformers with CNN-based semantic image segmentation models is very promising. However, it is not well studied yet on how well a pure transformer based approach can achieve for image segmentation. In this work, we explore a novel framework for semantic image segmentation, which is encoder-decoder based Fully Transformer Networks (FTN). Specifically, we first propose a Pyramid Group Transformer (PGT) as the encoder for progressively learning hierarchical features, while reducing the computation complexity of the standard visual transformer(ViT). Then, we propose a Feature Pyramid Transformer (FPT) to fuse semantic-level and spatial-level information from multiple levels of the PGT encoder for semantic image segmentation. Surprisingly, this simple baseline can achieve new state-of-the-art results on multiple challenging semantic segmentation benchmarks, including PASCAL Context, ADE20K and COCO-Stuff. The source code will be released upon the publication of this work.
SDNet: mutil-branch for single image deraining using swin
May 31, 2021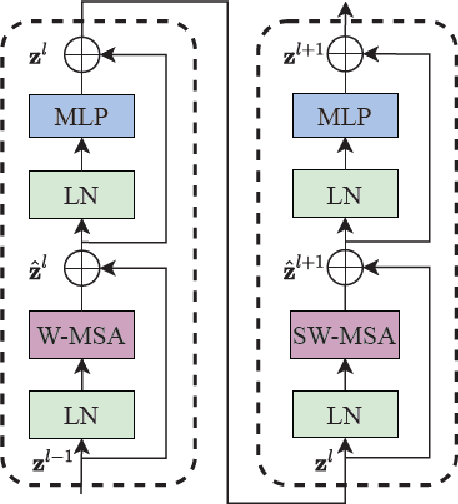
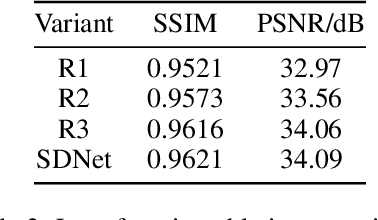
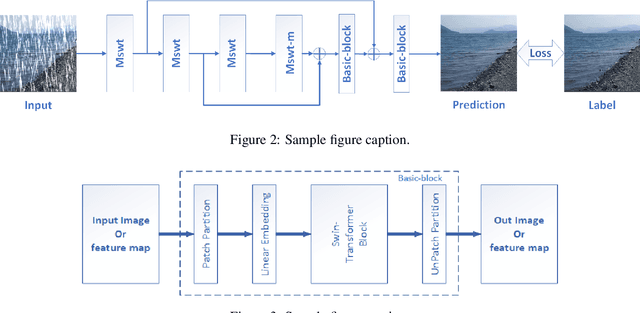
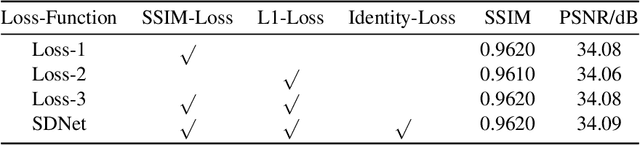
Rain streaks degrade the image quality and seriously affect the performance of subsequent computer vision tasks, such as autonomous driving, social security, etc. Therefore, removing rain streaks from a given rainy images is of great significance. Convolutional neural networks(CNN) have been widely used in image deraining tasks, however, the local computational characteristics of convolutional operations limit the development of image deraining tasks. Recently, the popular transformer has global computational features that can further facilitate the development of image deraining tasks. In this paper, we introduce Swin-transformer into the field of image deraining for the first time to study the performance and potential of Swin-transformer in the field of image deraining. Specifically, we improve the basic module of Swin-transformer and design a three-branch model to implement single-image rain removal. The former implements the basic rain pattern feature extraction, while the latter fuses different features to further extract and process the image features. In addition, we employ a jump connection to fuse deep features and shallow features. In terms of experiments, the existing public dataset suffers from image duplication and relatively homogeneous background. So we propose a new dataset Rain3000 to validate our model. Therefore, we propose a new dataset Rain3000 for validating our model. Experimental results on the publicly available datasets Rain100L, Rain100H and our dataset Rain3000 show that our proposed method has performance and inference speed advantages over the current mainstream single-image rain streaks removal models.The source code will be available at https://github.com/H-tfx/SDNet.
Direct Simultaneous Multi-Image Registration
May 21, 2021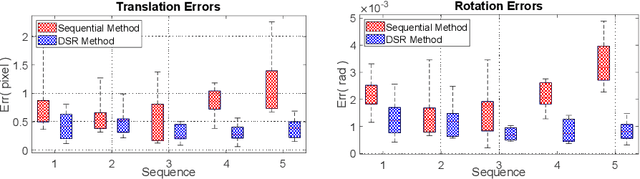
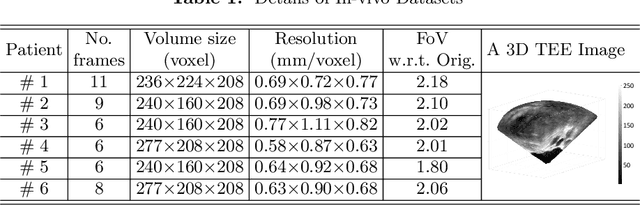
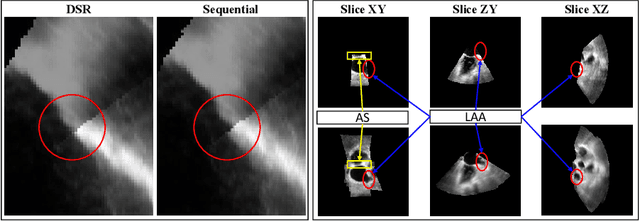
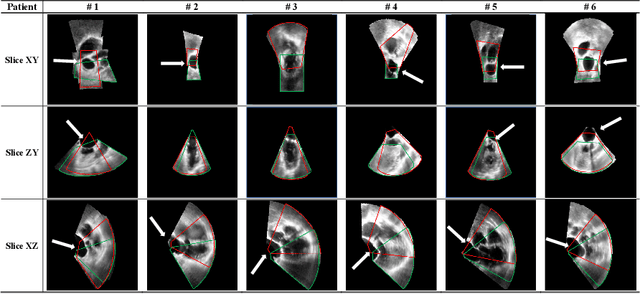
This paper presents a novel algorithm that registers a collection of mono-modal 3D images in a simultaneous fashion, named as Direct Simultaneous Registration (DSR). The algorithm optimizes global poses of local frames directly based on the intensities of images (without extracting features from the images). To obtain the optimal result, we start with formulating a Direct Bundle Adjustment (DBA) problem which jointly optimizes pose parameters of local frames and intensities of panoramic image. By proving the independence of the pose from panoramic image in the iterative process, DSR is proposed and proved to be able to generate the same optimal poses as DBA, but without optimizing the intensities of the panoramic image. The proposed DSR method is particularly suitable in mono-modal registration and in the scenarios where distinct features are not available, such as Transesophageal Echocardiography (TEE) images. The proposed method is validated via simulated and in-vivo 3D TEE images. It is shown that the proposed method outperforms conventional sequential registration method in terms of accuracy and the obtained results can produce good alignment in in-vivo images.
Dermoscopic Image Classification with Neural Style Transfer
May 31, 2021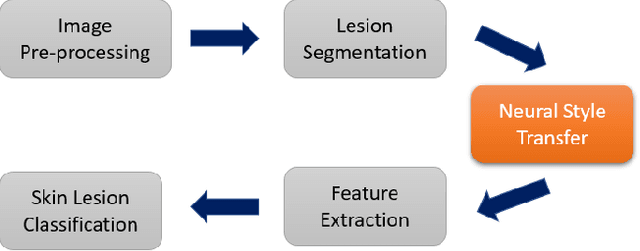

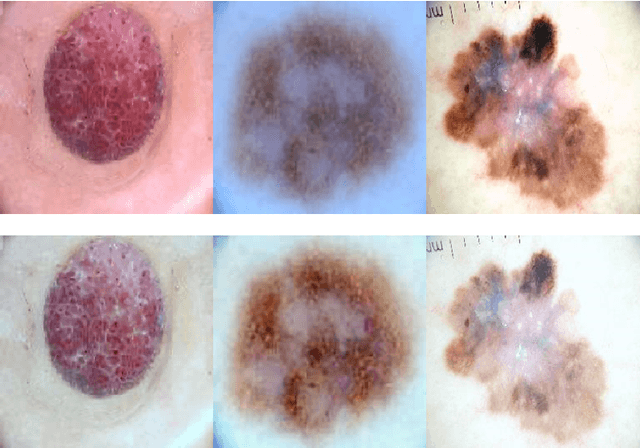

Skin cancer, the most commonly found human malignancy, is primarily diagnosed visually via dermoscopic analysis, biopsy, and histopathological examination. However, unlike other types of cancer, automated image classification of skin lesions is deemed more challenging due to the irregularity and variability in the lesions' appearances. In this work, we propose an adaptation of the Neural Style Transfer (NST) as a novel image pre-processing step for skin lesion classification problems. We represent each dermoscopic image as the style image and transfer the style of the lesion onto a homogeneous content image. This transfers the main variability of each lesion onto the same localized region, which allows us to integrate the generated images together and extract latent, low-rank style features via tensor decomposition. We train and cross-validate our model on a dermoscopic data set collected and preprocessed from the International Skin Imaging Collaboration (ISIC) database. We show that the classification performance based on the extracted tensor features using the style-transferred images significantly outperforms that of the raw images by more than 10%, and is also competitive with well-studied, pre-trained CNN models through transfer learning. Additionally, the tensor decomposition further identifies latent style clusters, which may provide clinical interpretation and insights.
A Self-Explainable Stylish Image Captioning Framework via Multi-References
Oct 20, 2021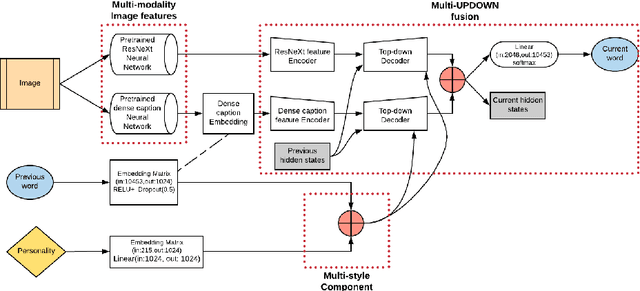

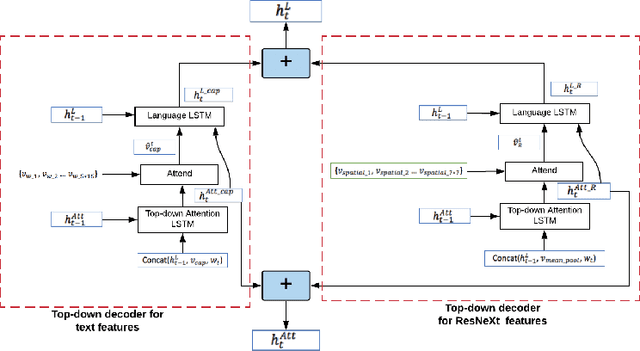

In this paper, we propose to build a stylish image captioning model through a Multi-style Multi modality mechanism (2M). We demonstrate that with 2M, we can build an effective stylish captioner and that multi-references produced by the model can also support explaining the model through identifying erroneous input features on faulty examples. We show how this 2M mechanism can be used to build stylish captioning models and show how these models can be utilized to provide explanations of likely errors in the models.
NTIRE 2021 Challenge on Image Deblurring
Apr 30, 2021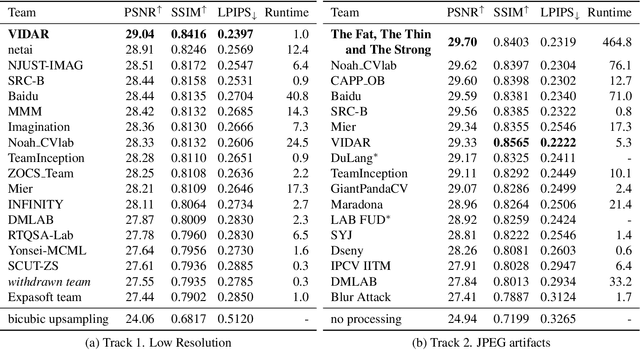


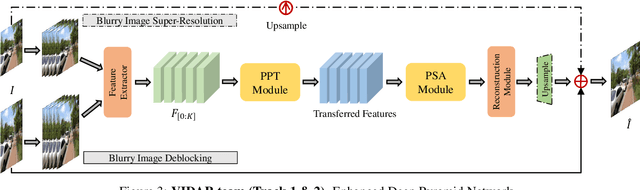
Motion blur is a common photography artifact in dynamic environments that typically comes jointly with the other types of degradation. This paper reviews the NTIRE 2021 Challenge on Image Deblurring. In this challenge report, we describe the challenge specifics and the evaluation results from the 2 competition tracks with the proposed solutions. While both the tracks aim to recover a high-quality clean image from a blurry image, different artifacts are jointly involved. In track 1, the blurry images are in a low resolution while track 2 images are compressed in JPEG format. In each competition, there were 338 and 238 registered participants and in the final testing phase, 18 and 17 teams competed. The winning methods demonstrate the state-of-the-art performance on the image deblurring task with the jointly combined artifacts.
Improvement of image classification by multiple optical scattering
Jul 12, 2021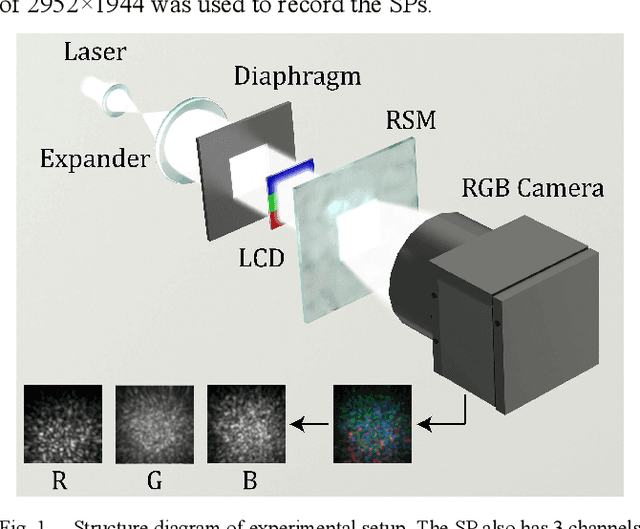
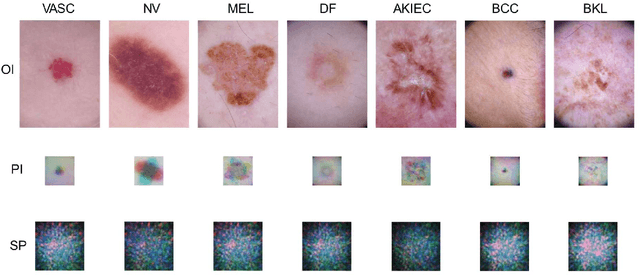
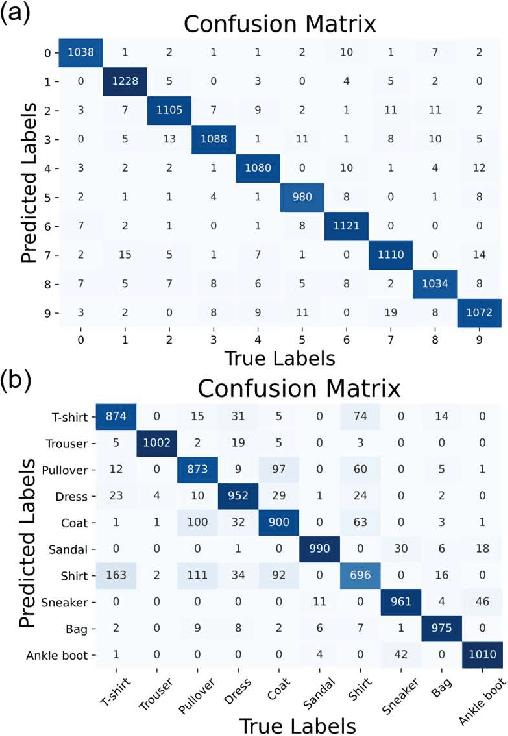
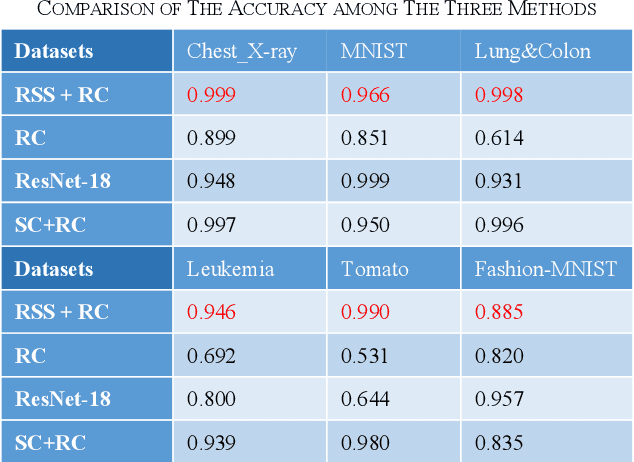
Multiple optical scattering occurs when light propagates in a non-uniform medium. During the multiple scattering, images were distorted and the spatial information they carried became scrambled. However, the image information is not lost but presents in the form of speckle patterns (SPs). In this study, we built up an optical random scattering system based on an LCD and an RGB laser source. We found that the image classification can be improved by the help of random scattering which is considered as a feedforward neural network to extracts features from image. Along with the ridge classification deployed on computer, we achieved excellent classification accuracy higher than 94%, for a variety of data sets covering medical, agricultural, environmental protection and other fields. In addition, the proposed optical scattering system has the advantages of high speed, low power consumption, and miniaturization, which is suitable for deploying in edge computing applications.
Iterative Filter Adaptive Network for Single Image Defocus Deblurring
Aug 31, 2021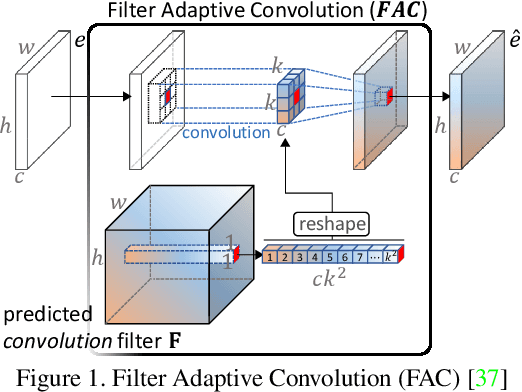
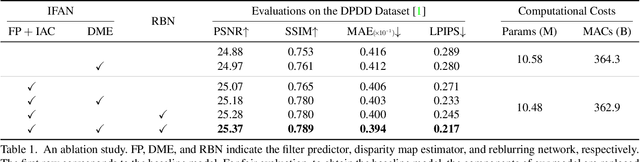
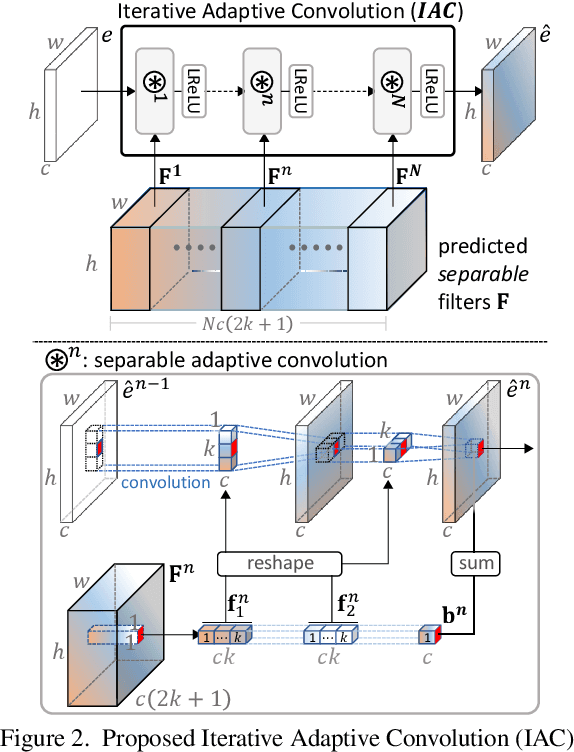
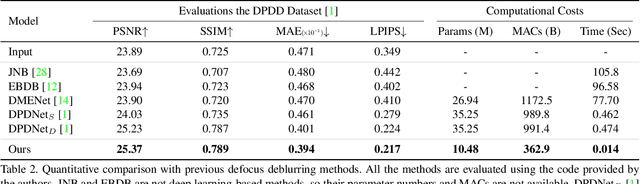
We propose a novel end-to-end learning-based approach for single image defocus deblurring. The proposed approach is equipped with a novel Iterative Filter Adaptive Network (IFAN) that is specifically designed to handle spatially-varying and large defocus blur. For adaptively handling spatially-varying blur, IFAN predicts pixel-wise deblurring filters, which are applied to defocused features of an input image to generate deblurred features. For effectively managing large blur, IFAN models deblurring filters as stacks of small-sized separable filters. Predicted separable deblurring filters are applied to defocused features using a novel Iterative Adaptive Convolution (IAC) layer. We also propose a training scheme based on defocus disparity estimation and reblurring, which significantly boosts the deblurring quality. We demonstrate that our method achieves state-of-the-art performance both quantitatively and qualitatively on real-world images.
* CVPR 2021
Object-wise Masked Autoencoders for Fast Pre-training
May 28, 2022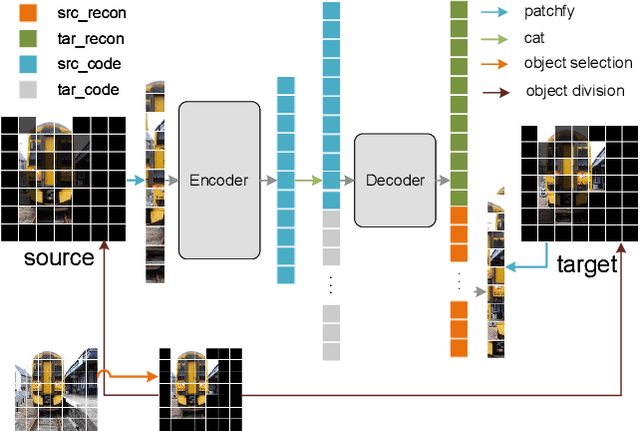
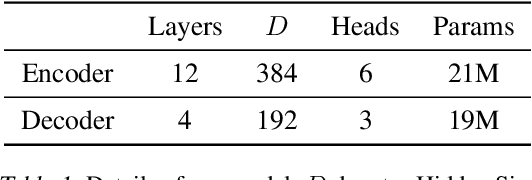
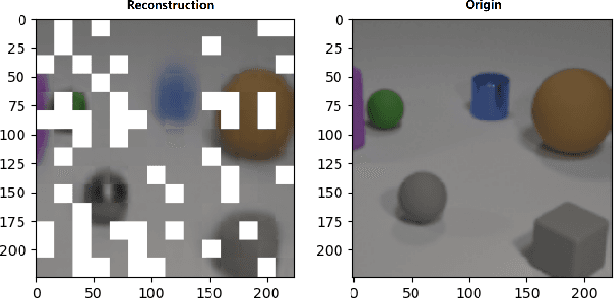
Self-supervised pre-training for images without labels has recently achieved promising performance in image classification. The success of transformer-based methods, ViT and MAE, draws the community's attention to the design of backbone architecture and self-supervised task. In this work, we show that current masked image encoding models learn the underlying relationship between all objects in the whole scene, instead of a single object representation. Therefore, those methods bring a lot of compute time for self-supervised pre-training. To solve this issue, we introduce a novel object selection and division strategy to drop non-object patches for learning object-wise representations by selective reconstruction with interested region masks. We refer to this method ObjMAE. Extensive experiments on four commonly-used datasets demonstrate the effectiveness of our model in reducing the compute cost by 72% while achieving competitive performance. Furthermore, we investigate the inter-object and intra-object relationship and find that the latter is crucial for self-supervised pre-training.
CellCentroidFormer: Combining Self-attention and Convolution for Cell Detection
Jun 01, 2022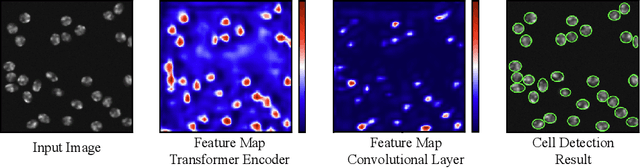
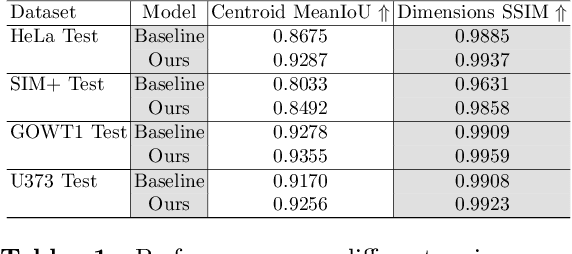
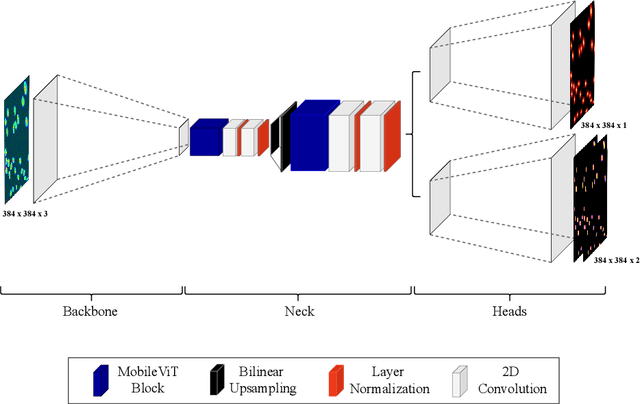

Cell detection in microscopy images is important to study how cells move and interact with their environment. Most recent deep learning-based methods for cell detection use convolutional neural networks (CNNs). However, inspired by the success in other computer vision applications, vision transformers (ViTs) are also used for this purpose. We propose a novel hybrid CNN-ViT model for cell detection in microscopy images to exploit the advantages of both types of deep learning models. We employ an efficient CNN, that was pre-trained on the ImageNet dataset, to extract image features and utilize transfer learning to reduce the amount of required training data. Extracted image features are further processed by a combination of convolutional and transformer layers, so that the convolutional layers can focus on local information and the transformer layers on global information. Our centroid-based cell detection method represents cells as ellipses and is end-to-end trainable. Furthermore, we show that our proposed model can outperform a fully convolutional baseline model on four different 2D microscopy datasets. Code is available at: https://github.com/roydenwa/cell-centroid-former