 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Mining Cross-Person Cues for Body-Part Interactiveness Learning in HOI Detection
Jul 28, 2022
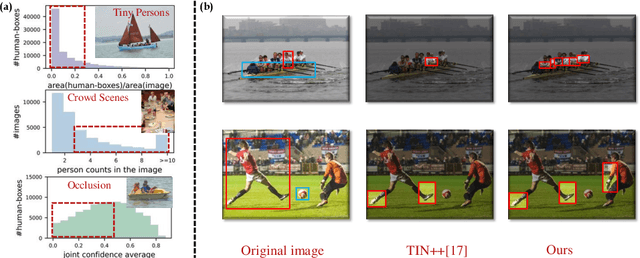

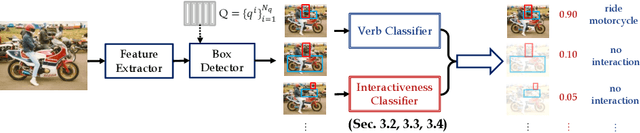
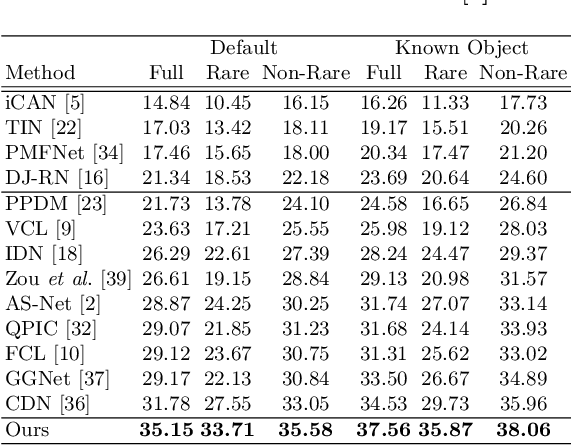
Human-Object Interaction (HOI) detection plays a crucial role in activity understanding. Though significant progress has been made, interactiveness learning remains a challenging problem in HOI detection: existing methods usually generate redundant negative H-O pair proposals and fail to effectively extract interactive pairs. Though interactiveness has been studied in both whole body- and part- level and facilitates the H-O pairing, previous works only focus on the target person once (i.e., in a local perspective) and overlook the information of the other persons. In this paper, we argue that comparing body-parts of multi-person simultaneously can afford us more useful and supplementary interactiveness cues. That said, to learn body-part interactiveness from a global perspective: when classifying a target person's body-part interactiveness, visual cues are explored not only from herself/himself but also from other persons in the image. We construct body-part saliency maps based on self-attention to mine cross-person informative cues and learn the holistic relationships between all the body-parts. We evaluate the proposed method on widely-used benchmarks HICO-DET and V-COCO. With our new perspective, the holistic global-local body-part interactiveness learning achieves significant improvements over state-of-the-art. Our code is available at https://github.com/enlighten0707/Body-Part-Map-for-Interactiveness.
On Mitigating Hard Clusters for Face Clustering
Jul 25, 2022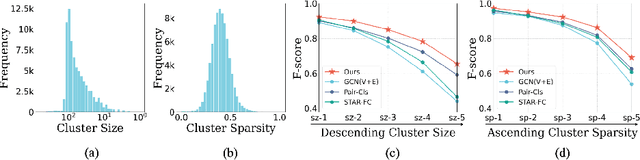
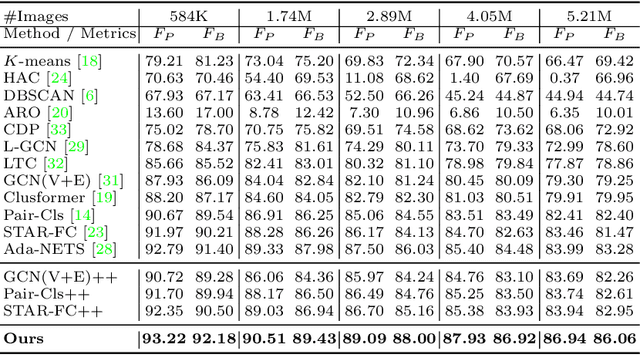
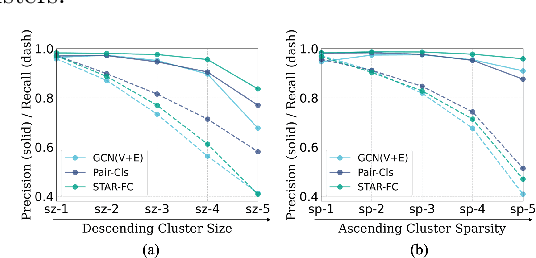
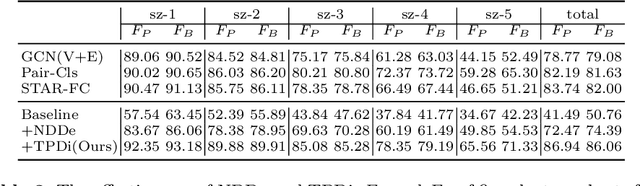
Face clustering is a promising way to scale up face recognition systems using large-scale unlabeled face images. It remains challenging to identify small or sparse face image clusters that we call hard clusters, which is caused by the heterogeneity, \ie, high variations in size and sparsity, of the clusters. Consequently, the conventional way of using a uniform threshold (to identify clusters) often leads to a terrible misclassification for the samples that should belong to hard clusters. We tackle this problem by leveraging the neighborhood information of samples and inferring the cluster memberships (of samples) in a probabilistic way. We introduce two novel modules, Neighborhood-Diffusion-based Density (NDDe) and Transition-Probability-based Distance (TPDi), based on which we can simply apply the standard Density Peak Clustering algorithm with a uniform threshold. Our experiments on multiple benchmarks show that each module contributes to the final performance of our method, and by incorporating them into other advanced face clustering methods, these two modules can boost the performance of these methods to a new state-of-the-art. Code is available at: https://github.com/echoanran/On-Mitigating-Hard-Clusters.
Inconsistency-aware Uncertainty Estimation for Semi-supervised Medical Image Segmentation
Oct 17, 2021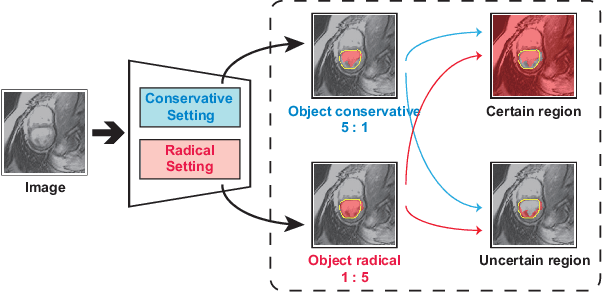
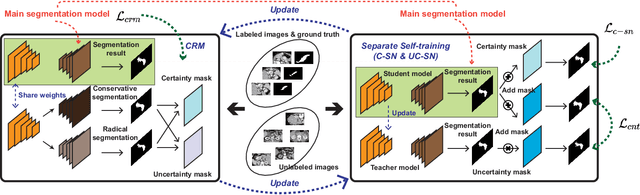
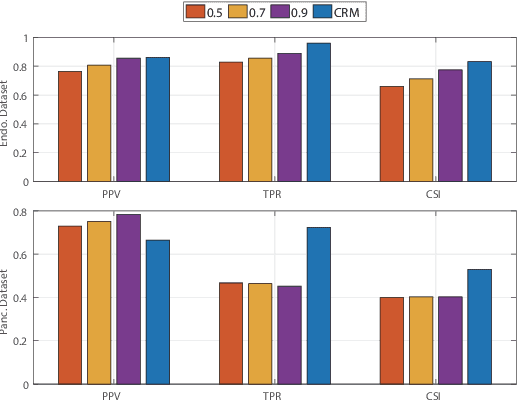

In semi-supervised medical image segmentation, most previous works draw on the common assumption that higher entropy means higher uncertainty. In this paper, we investigate a novel method of estimating uncertainty. We observe that, when assigned different misclassification costs in a certain degree, if the segmentation result of a pixel becomes inconsistent, this pixel shows a relative uncertainty in its segmentation. Therefore, we present a new semi-supervised segmentation model, namely, conservative-radical network (CoraNet in short) based on our uncertainty estimation and separate self-training strategy. In particular, our CoraNet model consists of three major components: a conservative-radical module (CRM), a certain region segmentation network (C-SN), and an uncertain region segmentation network (UC-SN) that could be alternatively trained in an end-to-end manner. We have extensively evaluated our method on various segmentation tasks with publicly available benchmark datasets, including CT pancreas, MR endocardium, and MR multi-structures segmentation on the ACDC dataset. Compared with the current state of the art, our CoraNet has demonstrated superior performance. In addition, we have also analyzed its connection with and difference from conventional methods of uncertainty estimation in semi-supervised medical image segmentation.
Sociable and Ergonomic Human-Robot Collaboration through Action Recognition and Augmented Hierarchical Quadratic Programming
Jul 07, 2022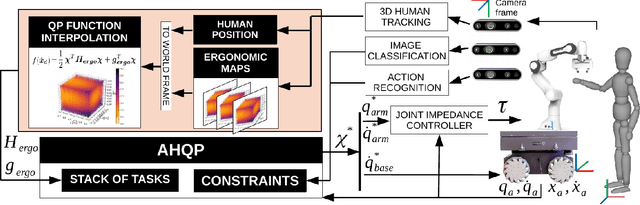
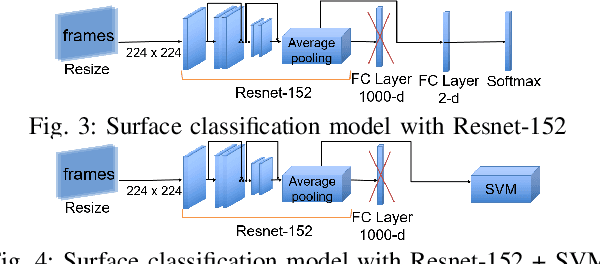
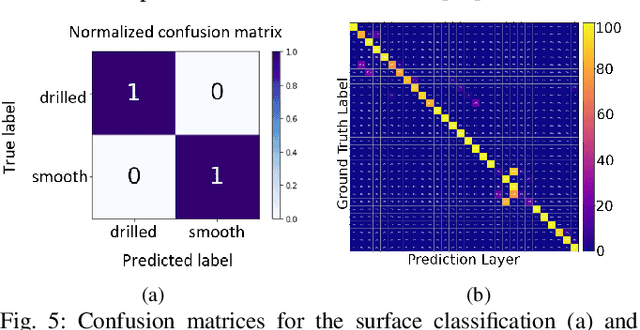
The recognition of actions performed by humans and the anticipation of their intentions are important enablers to yield sociable and successful collaboration in human-robot teams. Meanwhile, robots should have the capacity to deal with multiple objectives and constraints, arising from the collaborative task or the human. In this regard, we propose vision techniques to perform human action recognition and image classification, which are integrated into an Augmented Hierarchical Quadratic Programming (AHQP) scheme to hierarchically optimize the robot's reactive behavior and human ergonomics. The proposed framework allows one to intuitively command the robot in space while a task is being executed. The experiments confirm increased human ergonomics and usability, which are fundamental parameters for reducing musculoskeletal diseases and increasing trust in automation.
SatMAE: Pre-training Transformers for Temporal and Multi-Spectral Satellite Imagery
Jul 17, 2022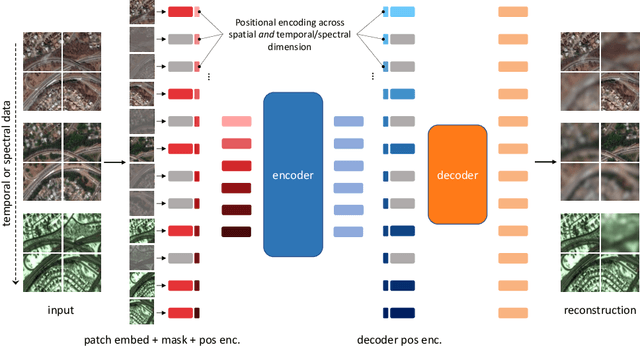

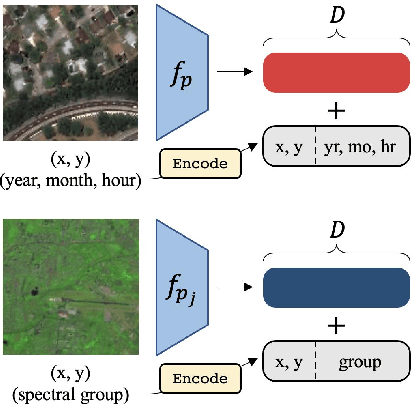
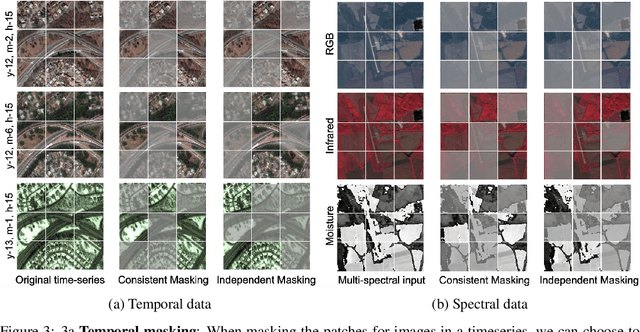
Unsupervised pre-training methods for large vision models have shown to enhance performance on downstream supervised tasks. Developing similar techniques for satellite imagery presents significant opportunities as unlabelled data is plentiful and the inherent temporal and multi-spectral structure provides avenues to further improve existing pre-training strategies. In this paper, we present SatMAE, a pre-training framework for temporal or multi-spectral satellite imagery based on Masked Autoencoder (MAE). To leverage temporal information, we include a temporal embedding along with independently masking image patches across time. In addition, we demonstrate that encoding multi-spectral data as groups of bands with distinct spectral positional encodings is beneficial. Our approach yields strong improvements over previous state-of-the-art techniques, both in terms of supervised learning performance on benchmark datasets (up to $\uparrow$ 7\%), and transfer learning performance on downstream remote sensing tasks, including land cover classification (up to $\uparrow$ 14\%) and semantic segmentation.
AdaptFormer: Adapting Vision Transformers for Scalable Visual Recognition
May 26, 2022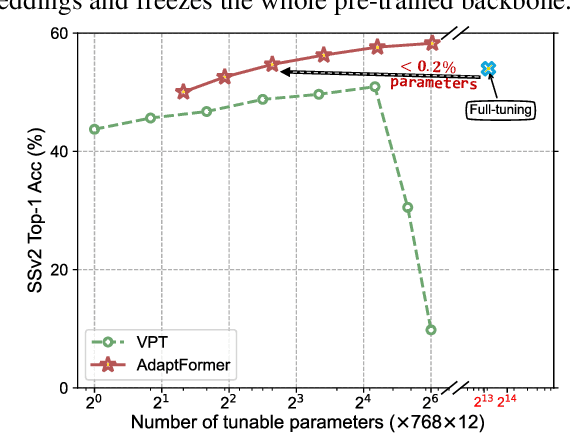
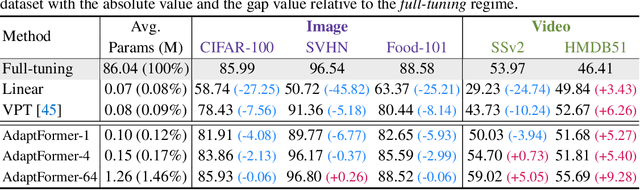


Although the pre-trained Vision Transformers (ViTs) achieved great success in computer vision, adapting a ViT to various image and video tasks is challenging because of its heavy computation and storage burdens, where each model needs to be independently and comprehensively fine-tuned to different tasks, limiting its transferability in different domains. To address this challenge, we propose an effective adaptation approach for Transformer, namely AdaptFormer, which can adapt the pre-trained ViTs into many different image and video tasks efficiently. It possesses several benefits more appealing than prior arts. Firstly, AdaptFormer introduces lightweight modules that only add less than 2% extra parameters to a ViT, while it is able to increase the ViT's transferability without updating its original pre-trained parameters, significantly outperforming the existing 100% fully fine-tuned models on action recognition benchmarks. Secondly, it can be plug-and-play in different Transformers and scalable to many visual tasks. Thirdly, extensive experiments on five image and video datasets show that AdaptFormer largely improves ViTs in the target domains. For example, when updating just 1.5% extra parameters, it achieves about 10% and 19% relative improvement compared to the fully fine-tuned models on Something-Something~v2 and HMDB51, respectively. Project page: http://www.shoufachen.com/adaptformer-page.
A Deep Dive into Deep Cluster
Jul 24, 2022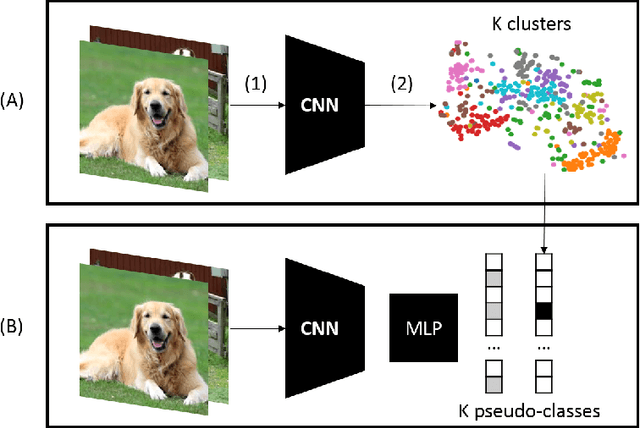

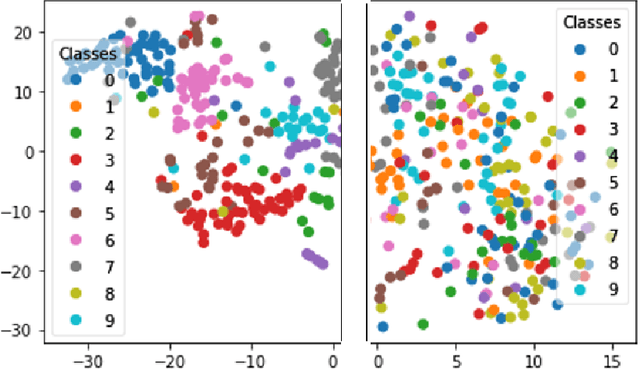
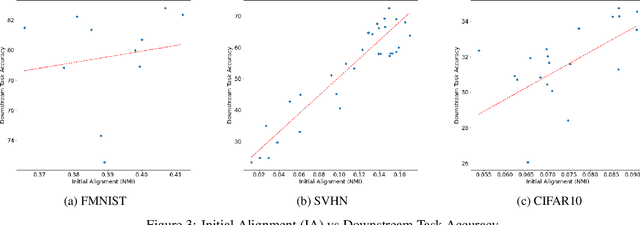
Deep Learning has demonstrated a significant improvement against traditional machine learning approaches in different domains such as image and speech recognition. Their success on benchmark datasets is transferred to the real-world through pretrained models by practitioners. Pretraining visual models using supervised learning requires a significant amount of expensive data annotation. To tackle this limitation, DeepCluster - a simple and scalable unsupervised pretraining of visual representations - has been proposed. However, the underlying work of the model is not yet well understood. In this paper, we analyze DeepCluster internals and exhaustively evaluate the impact of various hyperparameters over a wide range of values on three different datasets. Accordingly, we propose an explanation of why the algorithm works in practice. We also show that DeepCluster convergence and performance highly depend on the interplay between the quality of the randomly initialized filters of the convolutional layer and the selected number of clusters. Furthermore, we demonstrate that continuous clustering is not critical for DeepCluster convergence. Therefore, early stopping of the clustering phase will reduce the training time and allow the algorithm to scale to large datasets. Finally, we derive plausible hyperparameter selection criteria in a semi-supervised setting.
Hot-Refresh Model Upgrades with Regression-Alleviating Compatible Training in Image Retrieval
Jan 24, 2022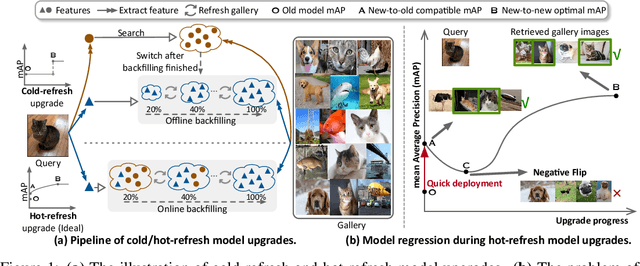
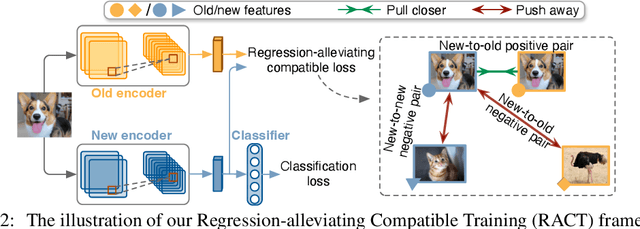
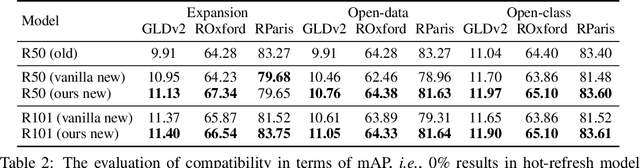
The task of hot-refresh model upgrades of image retrieval systems plays an essential role in the industry but has never been investigated in academia before. Conventional cold-refresh model upgrades can only deploy new models after the gallery is overall backfilled, taking weeks or even months for massive data. In contrast, hot-refresh model upgrades deploy the new model immediately and then gradually improve the retrieval accuracy by backfilling the gallery on-the-fly. Compatible training has made it possible, however, the problem of model regression with negative flips poses a great challenge to the stable improvement of user experience. We argue that it is mainly due to the fact that new-to-old positive query-gallery pairs may show less similarity than new-to-new negative pairs. To solve the problem, we introduce a Regression-Alleviating Compatible Training (RACT) method to properly constrain the feature compatibility while reducing negative flips. The core is to encourage the new-to-old positive pairs to be more similar than both the new-to-old negative pairs and the new-to-new negative pairs. An efficient uncertainty-based backfilling strategy is further introduced to fasten accuracy improvements. Extensive experiments on large-scale retrieval benchmarks (e.g., Google Landmark) demonstrate that our RACT effectively alleviates the model regression for one more step towards seamless model upgrades. The code will be available at https://github.com/binjiezhang/RACT_ICLR2022.
Measuring Perceptual Color Differences of Smartphone Photography
May 26, 2022

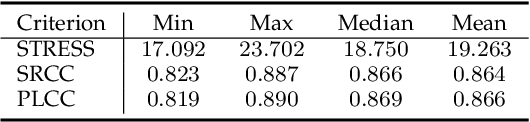

Measuring perceptual color differences (CDs) is of great importance in modern smartphone photography. Despite the long history, most CD measures have been constrained by psychophysical data of homogeneous color patches or a limited number of simplistic natural images. It is thus questionable whether existing CD measures generalize in the age of smartphone photography characterized by greater content complexities and learning-based image signal processors. In this paper, we put together so far the largest image dataset for perceptual CD assessment, in which the natural images are 1) captured by six flagship smartphones, 2) altered by Photoshop, 3) post-processed by built-in filters of the smartphones, and 4) reproduced with incorrect color profiles. We then conduct a large-scale psychophysical experiment to gather perceptual CDs of 30,000 image pairs in a carefully controlled laboratory environment. Based on the newly established dataset, we make one of the first attempts to construct an end-to-end learnable CD formula based on a lightweight neural network, as a generalization of several previous metrics. Extensive experiments demonstrate that the optimized formula outperforms 28 existing CD measures by a large margin, offers reasonable local CD maps without the use of dense supervision, generalizes well to color patch data, and empirically behaves as a proper metric in the mathematical sense.
Structure First Detail Next: Image Inpainting with Pyramid Generator
Jun 16, 2021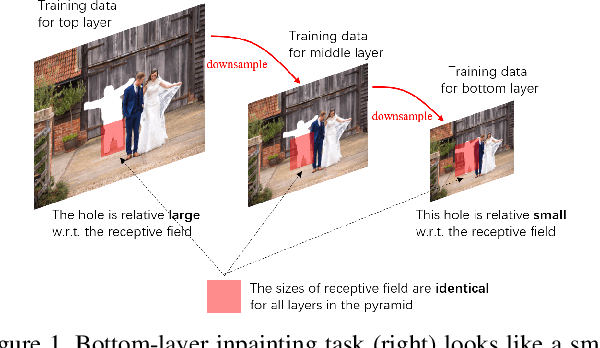

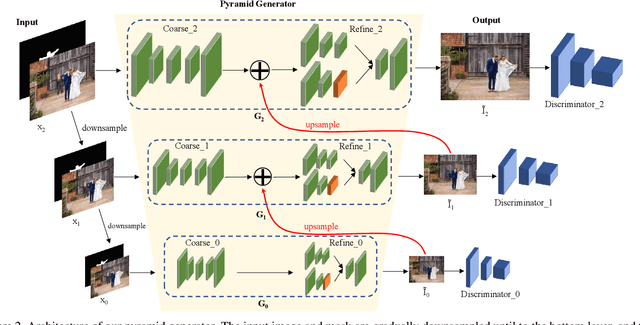
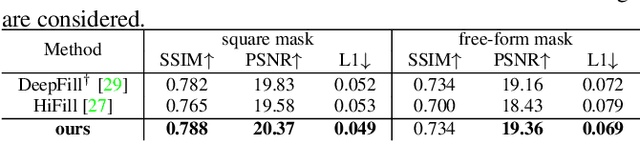
Recent deep generative models have achieved promising performance in image inpainting. However, it is still very challenging for a neural network to generate realistic image details and textures, due to its inherent spectral bias. By our understanding of how artists work, we suggest to adopt a `structure first detail next' workflow for image inpainting. To this end, we propose to build a Pyramid Generator by stacking several sub-generators, where lower-layer sub-generators focus on restoring image structures while the higher-layer sub-generators emphasize image details. Given an input image, it will be gradually restored by going through the entire pyramid in a bottom-up fashion. Particularly, our approach has a learning scheme of progressively increasing hole size, which allows it to restore large-hole images. In addition, our method could fully exploit the benefits of learning with high-resolution images, and hence is suitable for high-resolution image inpainting. Extensive experimental results on benchmark datasets have validated the effectiveness of our approach compared with state-of-the-art methods.