 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Scalable $\ell_\infty$-constrained Near-lossless Image Compression via Joint Lossy Image and Residual Compression
Mar 31, 2021
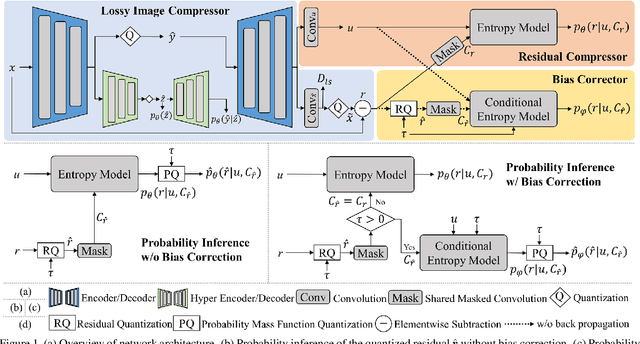
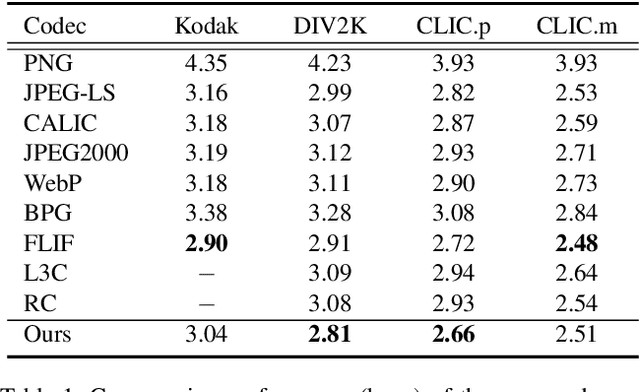
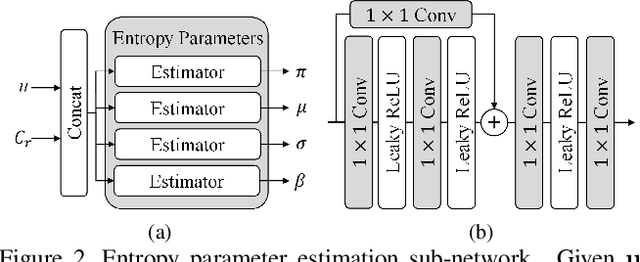
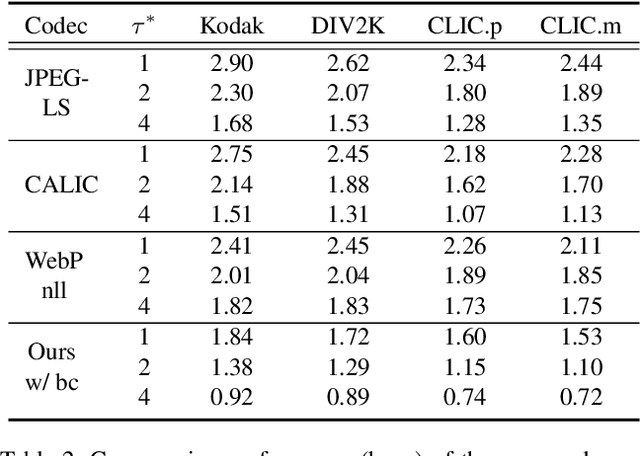
We propose a novel joint lossy image and residual compression framework for learning $\ell_\infty$-constrained near-lossless image compression. Specifically, we obtain a lossy reconstruction of the raw image through lossy image compression and uniformly quantize the corresponding residual to satisfy a given tight $\ell_\infty$ error bound. Suppose that the error bound is zero, i.e., lossless image compression, we formulate the joint optimization problem of compressing both the lossy image and the original residual in terms of variational auto-encoders and solve it with end-to-end training. To achieve scalable compression with the error bound larger than zero, we derive the probability model of the quantized residual by quantizing the learned probability model of the original residual, instead of training multiple networks. We further correct the bias of the derived probability model caused by the context mismatch between training and inference. Finally, the quantized residual is encoded according to the bias-corrected probability model and is concatenated with the bitstream of the compressed lossy image. Experimental results demonstrate that our near-lossless codec achieves the state-of-the-art performance for lossless and near-lossless image compression, and achieves competitive PSNR while much smaller $\ell_\infty$ error compared with lossy image codecs at high bit rates.
3D-Aware Video Generation
Jun 29, 2022
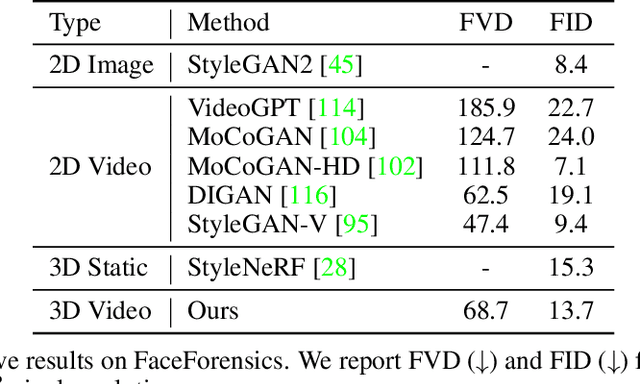
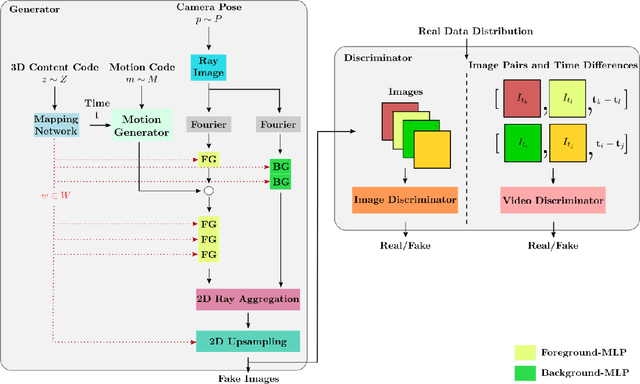

Generative models have emerged as an essential building block for many image synthesis and editing tasks. Recent advances in this field have also enabled high-quality 3D or video content to be generated that exhibits either multi-view or temporal consistency. With our work, we explore 4D generative adversarial networks (GANs) that learn unconditional generation of 3D-aware videos. By combining neural implicit representations with time-aware discriminator, we develop a GAN framework that synthesizes 3D video supervised only with monocular videos. We show that our method learns a rich embedding of decomposable 3D structures and motions that enables new visual effects of spatio-temporal renderings while producing imagery with quality comparable to that of existing 3D or video GANs.
Batch-efficient EigenDecomposition for Small and Medium Matrices
Jul 09, 2022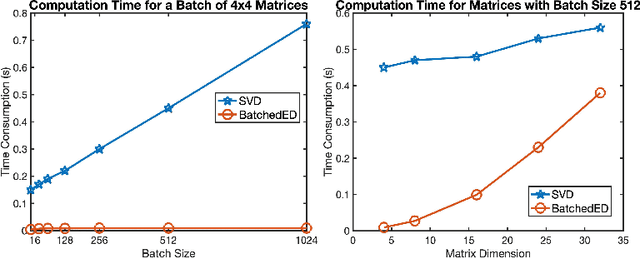

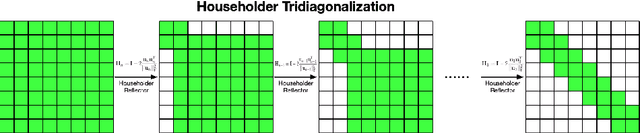
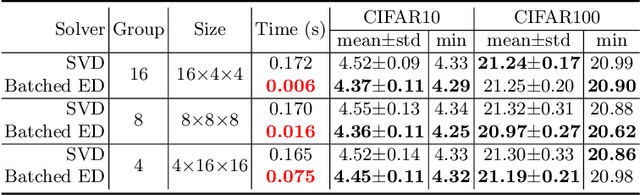
EigenDecomposition (ED) is at the heart of many computer vision algorithms and applications. One crucial bottleneck limiting its usage is the expensive computation cost, particularly for a mini-batch of matrices in the deep neural networks. In this paper, we propose a QR-based ED method dedicated to the application scenarios of computer vision. Our proposed method performs the ED entirely by batched matrix/vector multiplication, which processes all the matrices simultaneously and thus fully utilizes the power of GPUs. Our technique is based on the explicit QR iterations by Givens rotation with double Wilkinson shifts. With several acceleration techniques, the time complexity of QR iterations is reduced from $O{(}n^5{)}$ to $O{(}n^3{)}$. The numerical test shows that for small and medium batched matrices (\emph{e.g.,} $dim{<}32$) our method can be much faster than the Pytorch SVD function. Experimental results on visual recognition and image generation demonstrate that our methods also achieve competitive performances.
ReGO: Reference-Guided Outpainting for Scenery Image
Jul 02, 2021
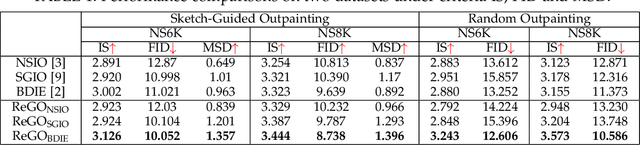

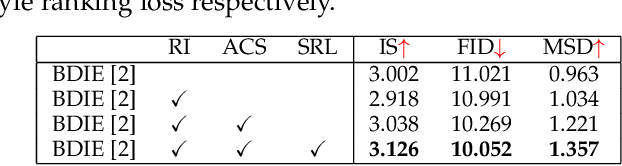
We aim to tackle the challenging yet practical scenery image outpainting task in this work. Recently, generative adversarial learning has significantly advanced the image outpainting by producing semantic consistent content for the given image. However, the existing methods always suffer from the blurry texture and the artifacts of the generative part, making the overall outpainting results lack authenticity. To overcome the weakness, this work investigates a principle way to synthesize texture-rich results by borrowing pixels from its neighbors (\ie, reference images), named \textbf{Re}ference-\textbf{G}uided \textbf{O}utpainting (ReGO). Particularly, the ReGO designs an Adaptive Content Selection (ACS) module to transfer the pixel of reference images for texture compensating of the target one. To prevent the style of the generated part from being affected by the reference images, a style ranking loss is further proposed to augment the ReGO to synthesize style-consistent results. Extensive experiments on two popular benchmarks, NS6K~\cite{yangzx} and NS8K~\cite{wang}, well demonstrate the effectiveness of our ReGO.
An IRS Backscatter Enabled Integrated Sensing, Communication and Computation System
Jul 20, 2022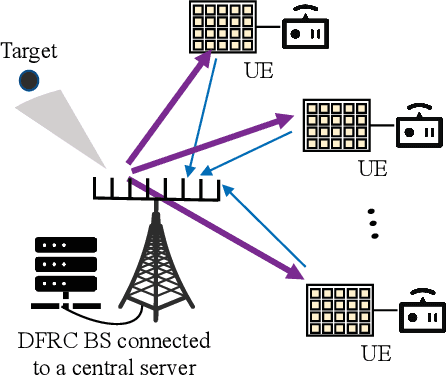
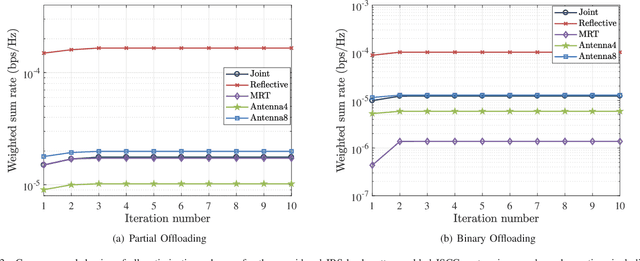
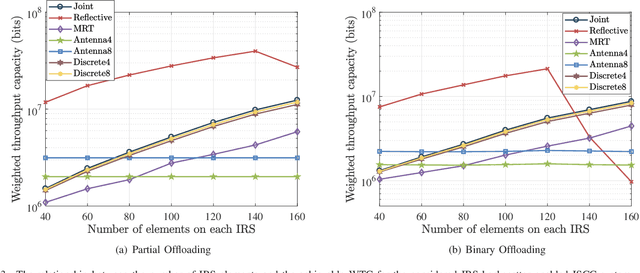
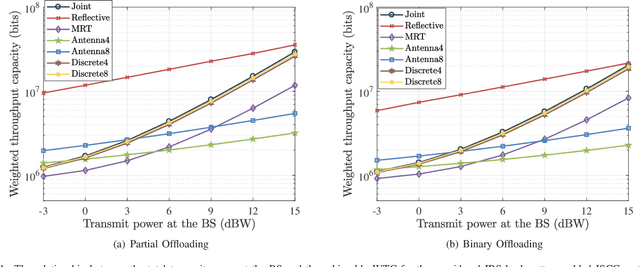
This paper proposes to leverage intelligent reflecting surface (IRS) backscatter to realize radio-frequency-chain-free uplink-transmissions (RFCF-UT). In this communication paradigm, IRS works as an information carrier, whose elements are capable of adjusting their amplitudes and phases to collaboratively portray an electromagnetic image like a dynamic quick response (QR) code, rather than a familiar reflection device, while a full-duplex base station (BS) is used as a scanner to collect and recognize the information on IRS. To elaborate it, an integrated sensing, communication and computation system as an example is presented, in which a dual-functional radar-communication BS simultaneously detects the target and collects the data from user equipments each connected to an IRS. Based on the established model, partial and binary data offloading strategies are respectively considered. By defining a performance metric named weighted throughput capacity (WTC), two maximization problems of WTC are formulated. According to the coupling degree of optimization variables in the objective function and the constraints, each optimization problem is firstly decomposed into two subproblems. Then, the methods of linear programming, fractional programming, integer programming and alternative optimization are developed to solve the subproblems. The simulation results demonstrate the achievable WTC of the considered system, thereby validating RFCF-UT.
Accelerating Magnetic Resonance Parametric Mapping Using Simultaneously Spatial Patch-based and Parametric Group-based Low-rank Tensors (SMART)
Jul 17, 2022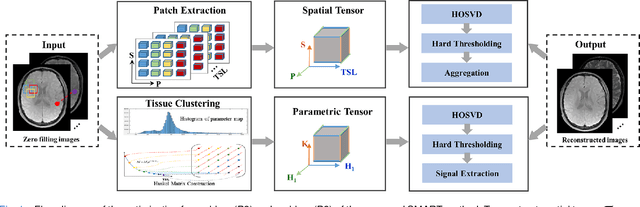
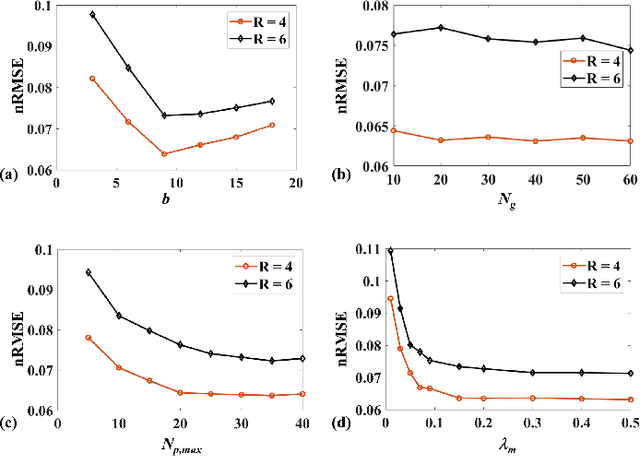
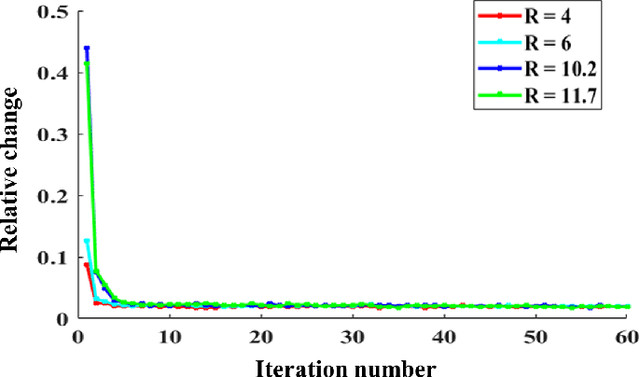
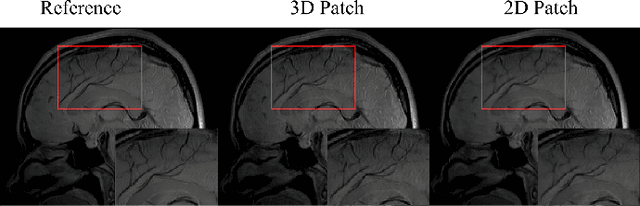
Quantitative magnetic resonance (MR) parametric mapping is a promising approach for characterizing intrinsic tissue-dependent information. However, long scan time significantly hinders its widespread applications. Recently, low-rank tensor has been employed and demonstrated good performance in accelerating MR parametricmapping. In this study, we propose a novel method that uses spatial patch-based and parametric group-based low rank tensors simultaneously (SMART) to reconstruct images from highly undersampled k-space data. The spatial patch-based low-rank tensor exploits the high local and nonlocal redundancies and similarities between the contrast images in parametric mapping. The parametric group based low-rank tensor, which integrates similar exponential behavior of the image signals, is jointly used to enforce the multidimensional low-rankness in the reconstruction process. In vivo brain datasets were used to demonstrate the validity of the proposed method. Experimental results have demonstrated that the proposed method achieves 11.7-fold and 13.21-fold accelerations in two-dimensional and three-dimensional acquisitions, respectively, with more accurate reconstructed images and maps than several state-of-the-art methods. Prospective reconstruction results further demonstrate the capability of the SMART method in accelerating MR quantitative imaging.
Image-Based Parking Space Occupancy Classification: Dataset and Baseline
Jul 26, 2021
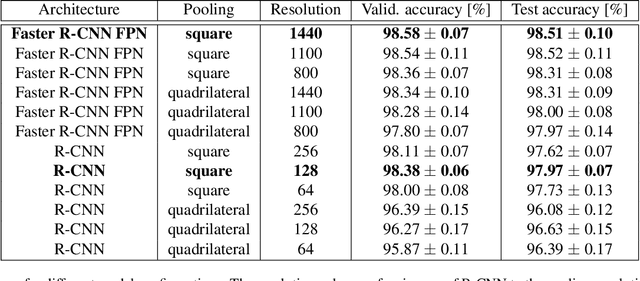

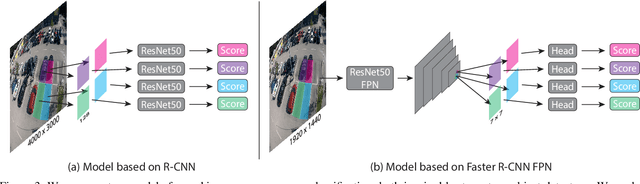
We introduce a new dataset for image-based parking space occupancy classification: ACPDS. Unlike in prior datasets, each image is taken from a unique view, systematically annotated, and the parking lots in the train, validation, and test sets are unique. We use this dataset to propose a simple baseline model for parking space occupancy classification, which achieves 98% accuracy on unseen parking lots, significantly outperforming existing models. We share our dataset, code, and trained models under the MIT license.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022



This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
Continuous wavelet transform of multiview images using wavelets based on voxel patterns
May 12, 2022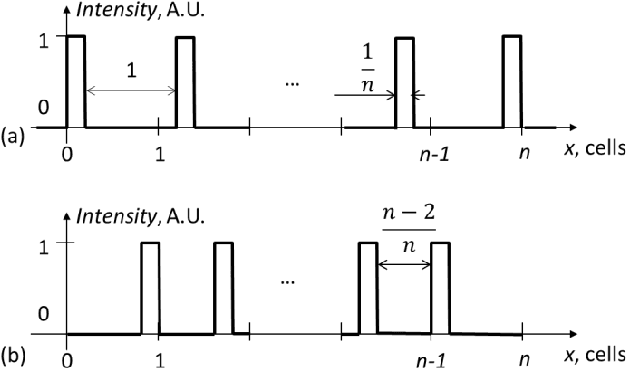
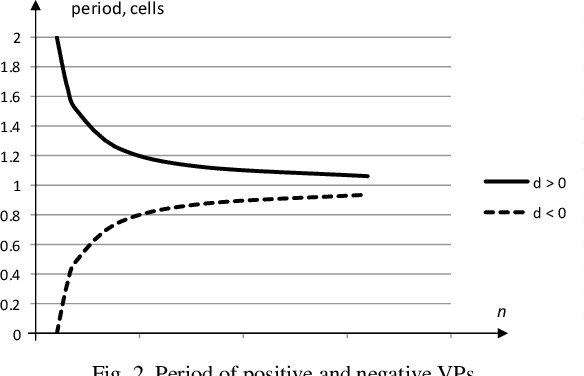
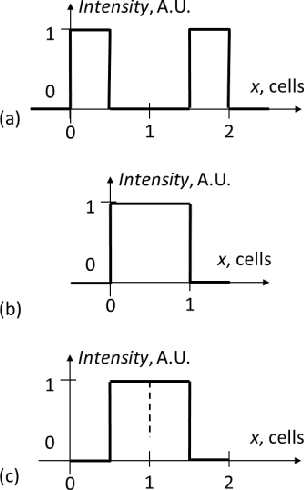
We propose the multiview wavelets based on voxel patterns of autostereoscopic multiview displays. Direct and inverse continuous wavelet transforms of binary and gray-scale images were performed. The input to the inverse wavelet transform was the array of wavelet coefficients of the direct transform. A restored image reproduces the structure of the multiview image correctly. Also, we modified the dimension of the parallax and the depth of 3D images. The restored and modified images were displayed in 3D using lenticular plates. In each case, the visual 3D picture corresponds to the applied modifications. The results can be applied to the autostereoscopic 3D displays.
Thermal Image Processing via Physics-Inspired Deep Networks
Aug 18, 2021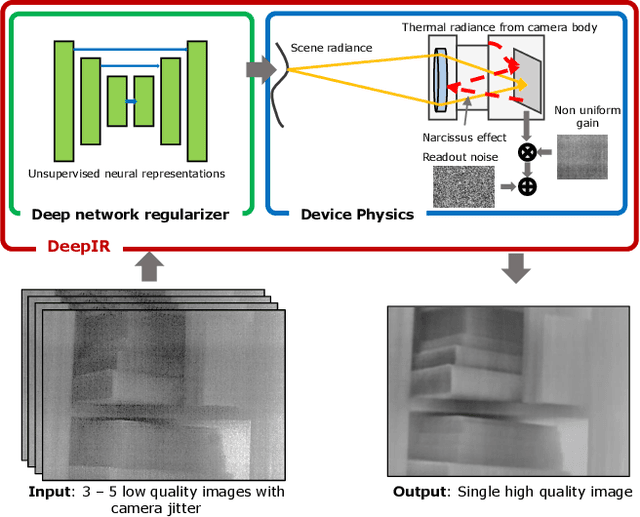



We introduce DeepIR, a new thermal image processing framework that combines physically accurate sensor modeling with deep network-based image representation. Our key enabling observations are that the images captured by thermal sensors can be factored into slowly changing, scene-independent sensor non-uniformities (that can be accurately modeled using physics) and a scene-specific radiance flux (that is well-represented using a deep network-based regularizer). DeepIR requires neither training data nor periodic ground-truth calibration with a known black body target--making it well suited for practical computer vision tasks. We demonstrate the power of going DeepIR by developing new denoising and super-resolution algorithms that exploit multiple images of the scene captured with camera jitter. Simulated and real data experiments demonstrate that DeepIR can perform high-quality non-uniformity correction with as few as three images, achieving a 10dB PSNR improvement over competing approaches.