 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Exploring Generative Neural Temporal Point Process
Aug 04, 2022

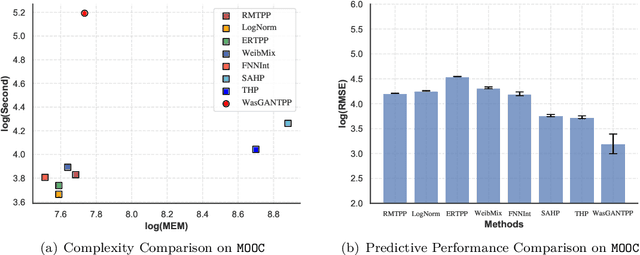
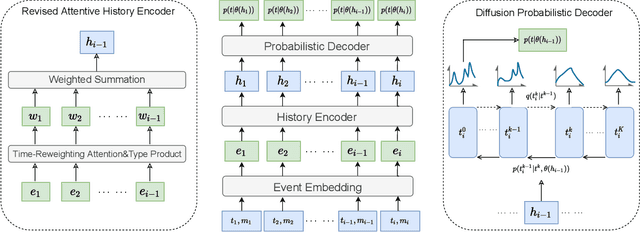

Temporal point process (TPP) is commonly used to model the asynchronous event sequence featuring occurrence timestamps and revealed by probabilistic models conditioned on historical impacts. While lots of previous works have focused on `goodness-of-fit' of TPP models by maximizing the likelihood, their predictive performance is unsatisfactory, which means the timestamps generated by models are far apart from true observations. Recently, deep generative models such as denoising diffusion and score matching models have achieved great progress in image generating tasks by demonstrating their capability of generating samples of high quality. However, there are no complete and unified works exploring and studying the potential of generative models in the context of event occurence modeling for TPP. In this work, we try to fill the gap by designing a unified \textbf{g}enerative framework for \textbf{n}eural \textbf{t}emporal \textbf{p}oint \textbf{p}rocess (\textsc{GNTPP}) model to explore their feasibility and effectiveness, and further improve models' predictive performance. Besides, in terms of measuring the historical impacts, we revise the attentive models which summarize influence from historical events with an adaptive reweighting term considering events' type relation and time intervals. Extensive experiments have been conducted to illustrate the improved predictive capability of \textsc{GNTPP} with a line of generative probabilistic decoders, and performance gain from the revised attention. To the best of our knowledge, this is the first work that adapts generative models in a complete unified framework and studies their effectiveness in the context of TPP. Our codebase including all the methods given in Section.5.1.1 is open in \url{https://github.com/BIRD-TAO/GNTPP}. We hope the code framework can facilitate future research in Neural TPPs.
Distributional loss for convolutional neural network regression and application to GNSS multi-path estimation
Jun 03, 2022
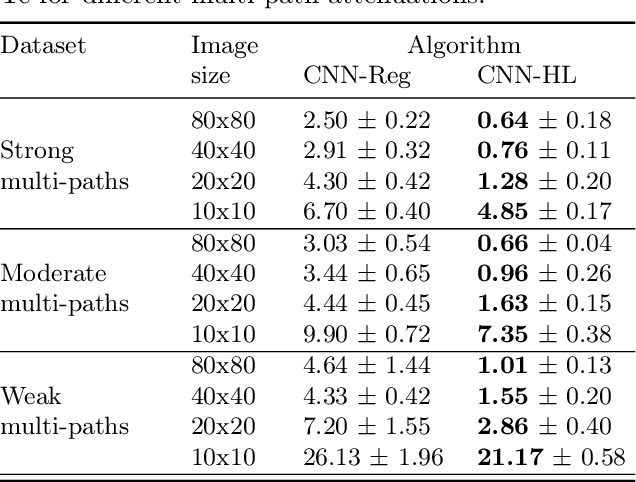
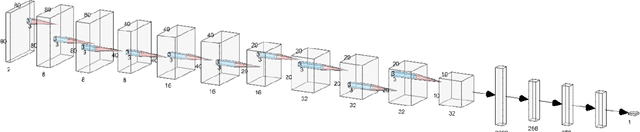
Convolutional Neural Network (CNN) have been widely used in image classification. Over the years, they have also benefited from various enhancements and they are now considered as state of the art techniques for image like data. However, when they are used for regression to estimate some function value from images, fewer recommendations are available. In this study, a novel CNN regression model is proposed. It combines convolutional neural layers to extract high level features representations from images with a soft labelling technique. More specifically, as the deep regression task is challenging, the idea is to account for some uncertainty in the targets that are seen as distributions around their mean. The estimations are carried out by the model in the form of distributions. Building from earlier work, a specific histogram loss function based on the Kullback-Leibler (KL) divergence is applied during training. The model takes advantage of the CNN feature representation and is able to carry out estimation from multi-channel input images. To assess and illustrate the technique, the model is applied to Global Navigation Satellite System (GNSS) multi-path estimation where multi-path signal parameters have to be estimated from correlator output images from the I and Q channels. The multi-path signal delay, magnitude, Doppler shift frequency and phase parameters are estimated from synthetically generated datasets of satellite signals. Experiments are conducted under various receiving conditions and various input images resolutions to test the estimation performances quality and robustness. The results show that the proposed soft labelling CNN technique using distributional loss outperforms classical CNN regression under all conditions. Furthermore, the extra learning performance achieved by the model allows the reduction of input image resolution from 80x80 down to 40x40 or sometimes 20x20.
A Spatial Guided Self-supervised Clustering Network for Medical Image Segmentation
Jul 11, 2021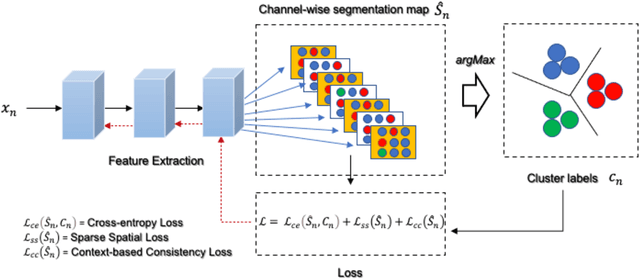
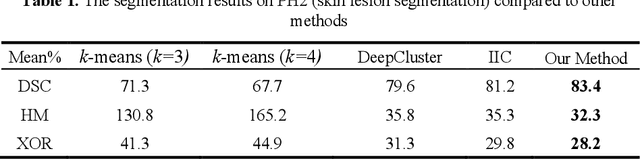
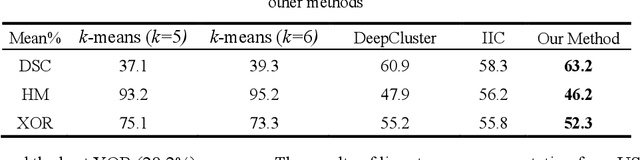

The segmentation of medical images is a fundamental step in automated clinical decision support systems. Existing medical image segmentation methods based on supervised deep learning, however, remain problematic because of their reliance on large amounts of labelled training data. Although medical imaging data repositories continue to expand, there has not been a commensurate increase in the amount of annotated data. Hence, we propose a new spatial guided self-supervised clustering network (SGSCN) for medical image segmentation, where we introduce multiple loss functions designed to aid in grouping image pixels that are spatially connected and have similar feature representations. It iteratively learns feature representations and clustering assignment of each pixel in an end-to-end fashion from a single image. We also propose a context-based consistency loss that better delineates the shape and boundaries of image regions. It enforces all the pixels belonging to a cluster to be spatially close to the cluster centre. We evaluated our method on 2 public medical image datasets and compared it to existing conventional and self-supervised clustering methods. Experimental results show that our method was most accurate for medical image segmentation.
Topologically-Aware Deformation Fields for Single-View 3D Reconstruction
May 12, 2022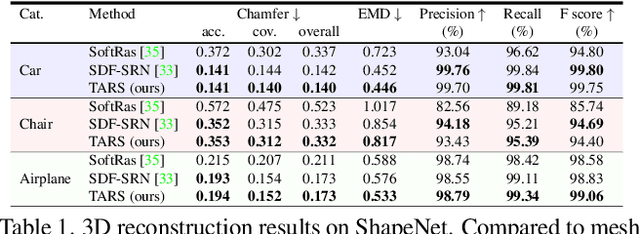
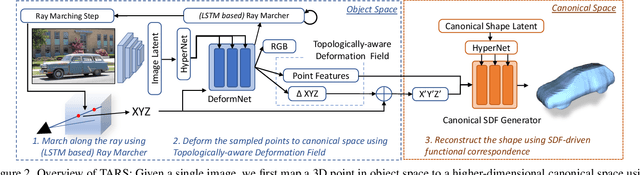

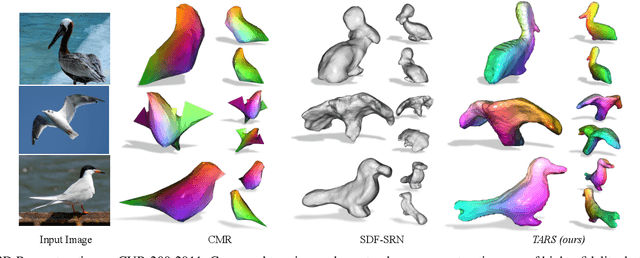
We present a new framework for learning 3D object shapes and dense cross-object 3D correspondences from just an unaligned category-specific image collection. The 3D shapes are generated implicitly as deformations to a category-specific signed distance field and are learned in an unsupervised manner solely from unaligned image collections without any 3D supervision. Generally, image collections on the internet contain several intra-category geometric and topological variations, for example, different chairs can have different topologies, which makes the task of joint shape and correspondence estimation much more challenging. Because of this, prior works either focus on learning each 3D object shape individually without modeling cross-instance correspondences or perform joint shape and correspondence estimation on categories with minimal intra-category topological variations. We overcome these restrictions by learning a topologically-aware implicit deformation field that maps a 3D point in the object space to a higher dimensional point in the category-specific canonical space. At inference time, given a single image, we reconstruct the underlying 3D shape by first implicitly deforming each 3D point in the object space to the learned category-specific canonical space using the topologically-aware deformation field and then reconstructing the 3D shape as a canonical signed distance field. Both canonical shape and deformation field are learned end-to-end in an inverse-graphics fashion using a learned recurrent ray marcher (SRN) as a differentiable rendering module. Our approach, dubbed TARS, achieves state-of-the-art reconstruction fidelity on several datasets: ShapeNet, Pascal3D+, CUB, and Pix3D chairs. Result videos and code at https://shivamduggal4.github.io/tars-3D/
Uncertainty-based Cross-Modal Retrieval with Probabilistic Representations
Apr 20, 2022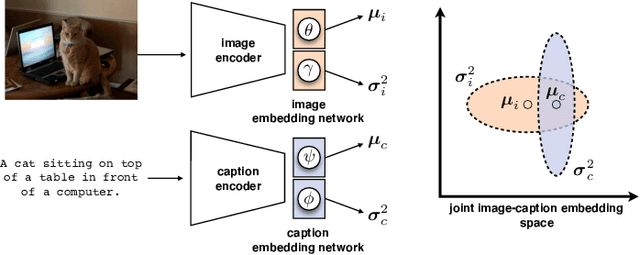
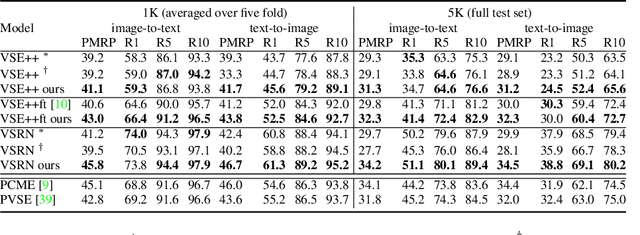
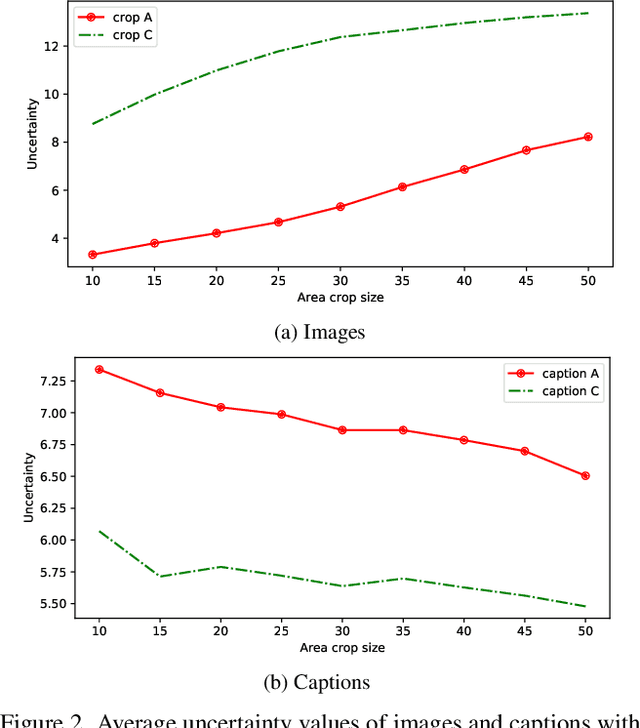
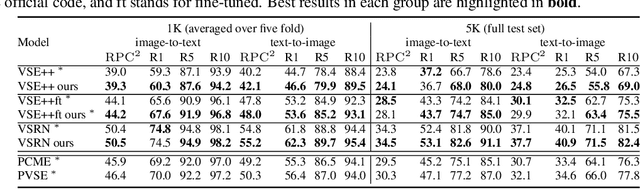
Probabilistic embeddings have proven useful for capturing polysemous word meanings, as well as ambiguity in image matching. In this paper, we study the advantages of probabilistic embeddings in a cross-modal setting (i.e., text and images), and propose a simple approach that replaces the standard vector point embeddings in extant image-text matching models with probabilistic distributions that are parametrically learned. Our guiding hypothesis is that the uncertainty encoded in the probabilistic embeddings captures the cross-modal ambiguity in the input instances, and that it is through capturing this uncertainty that the probabilistic models can perform better at downstream tasks, such as image-to-text or text-to-image retrieval. Through extensive experiments on standard and new benchmarks, we show a consistent advantage for probabilistic representations in cross-modal retrieval, and validate the ability of our embeddings to capture uncertainty.
PIRenderer: Controllable Portrait Image Generation via Semantic Neural Rendering
Sep 17, 2021
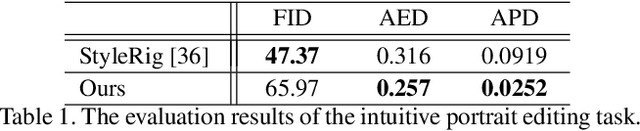
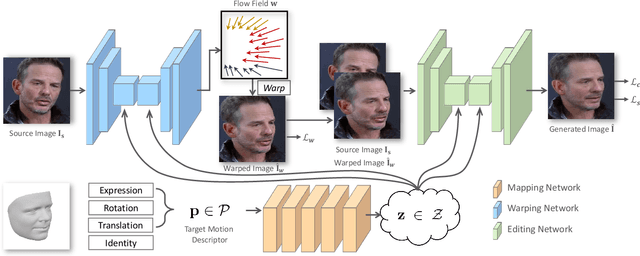

Generating portrait images by controlling the motions of existing faces is an important task of great consequence to social media industries. For easy use and intuitive control, semantically meaningful and fully disentangled parameters should be used as modifications. However, many existing techniques do not provide such fine-grained controls or use indirect editing methods i.e. mimic motions of other individuals. In this paper, a Portrait Image Neural Renderer (PIRenderer) is proposed to control the face motions with the parameters of three-dimensional morphable face models (3DMMs). The proposed model can generate photo-realistic portrait images with accurate movements according to intuitive modifications. Experiments on both direct and indirect editing tasks demonstrate the superiority of this model. Meanwhile, we further extend this model to tackle the audio-driven facial reenactment task by extracting sequential motions from audio inputs. We show that our model can generate coherent videos with convincing movements from only a single reference image and a driving audio stream. Our source code is available at https://github.com/RenYurui/PIRender.
Improving Deep Neural Network Random Initialization Through Neuronal Rewiring
Jul 17, 2022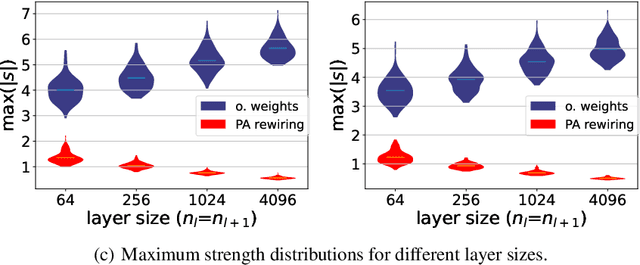
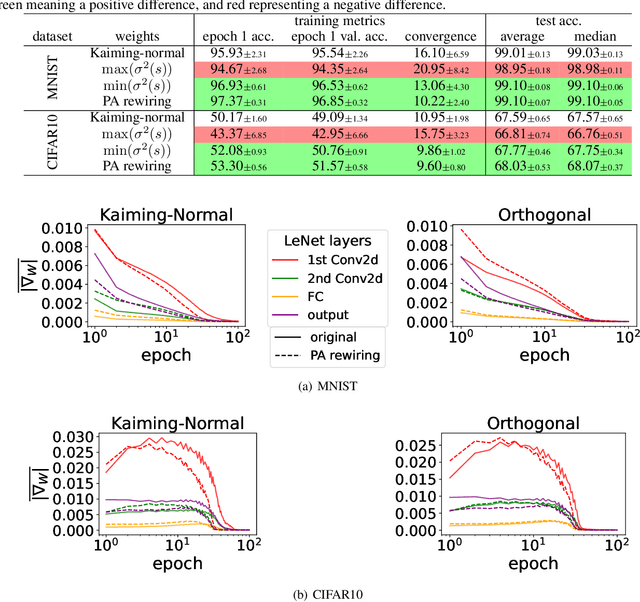
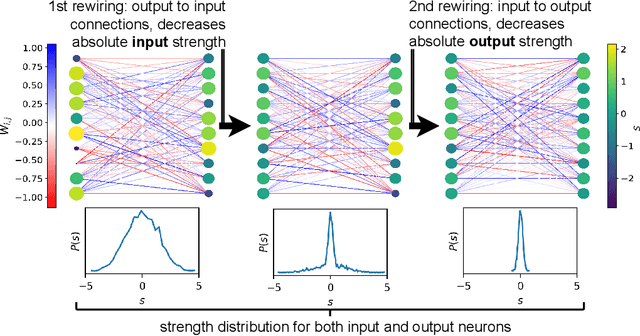
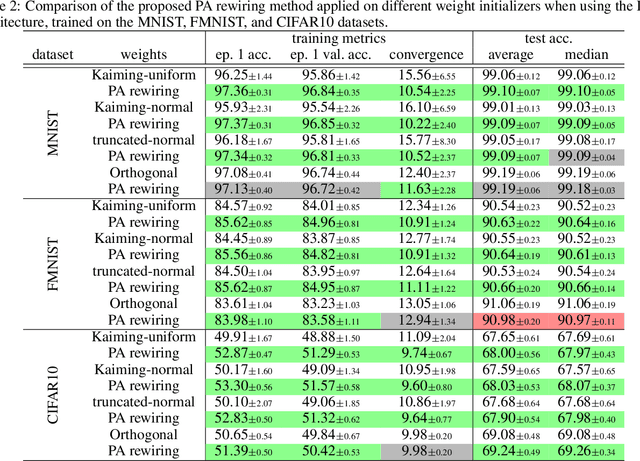
The deep learning literature is continuously updated with new architectures and training techniques. However, weight initialization is overlooked by most recent research, despite some intriguing findings regarding random weights. On the other hand, recent works have been approaching Network Science to understand the structure and dynamics of Artificial Neural Networks (ANNs) after training. Therefore, in this work, we analyze the centrality of neurons in randomly initialized networks. We show that a higher neuronal strength variance may decrease performance, while a lower neuronal strength variance usually improves it. A new method is then proposed to rewire neuronal connections according to a preferential attachment (PA) rule based on their strength, which significantly reduces the strength variance of layers initialized by common methods. In this sense, PA rewiring only reorganizes connections, while preserving the magnitude and distribution of the weights. We show through an extensive statistical analysis in image classification that performance is improved in most cases, both during training and testing, when using both simple and complex architectures and learning schedules. Our results show that, aside from the magnitude, the organization of the weights is also relevant for better initialization of deep ANNs.
Reconstruction of images taken by a pair of non-regular sampling sensors using correlation based matching
Apr 07, 2022
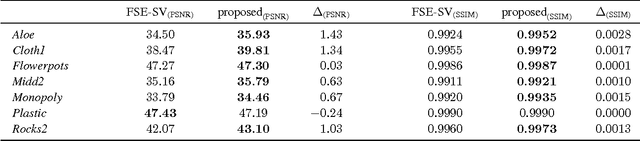
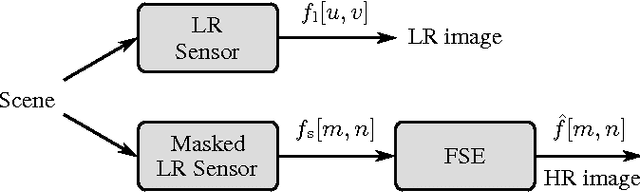
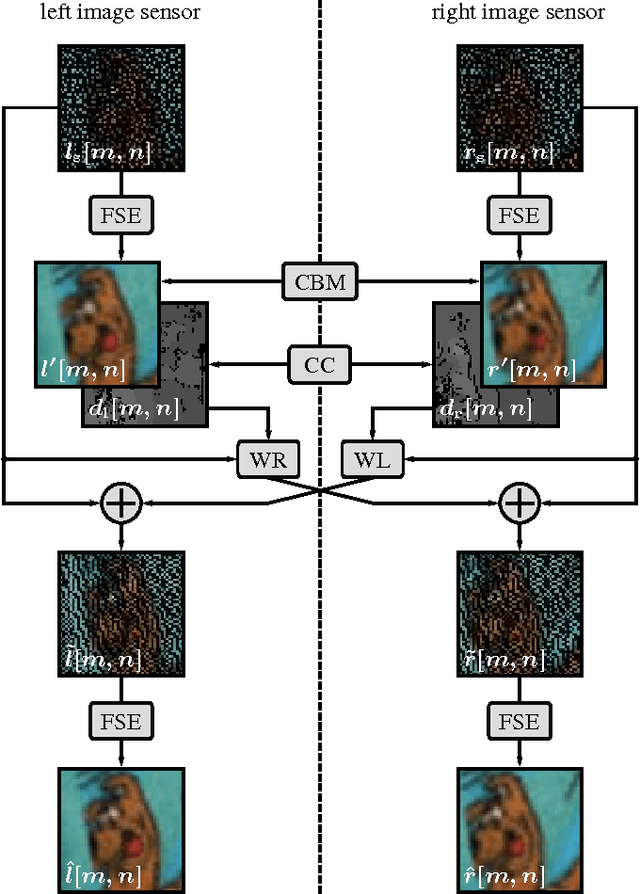
Multi-view image acquisition systems with two or more cameras can be rather costly due to the number of high resolution image sensors that are required. Recently, it has been shown that by covering a low resolution sensor with a non-regular sampling mask and by using an efficient algorithm for image reconstruction, a high resolution image can be obtained. In this paper, a stereo image reconstruction setup for multi-view scenarios is proposed. A scene is captured by a pair of non-regular sampling sensors and by incorporating information from the adjacent view, the reconstruction quality can be increased. Compared to a state-of-the-art single-view reconstruction algorithm, this leads to a visually noticeable average gain in PSNR of 0.74 dB.
Lossless Image Compression Using a Multi-Scale Progressive Statistical Model
Aug 24, 2021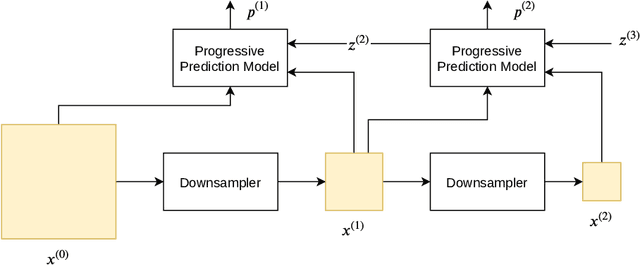

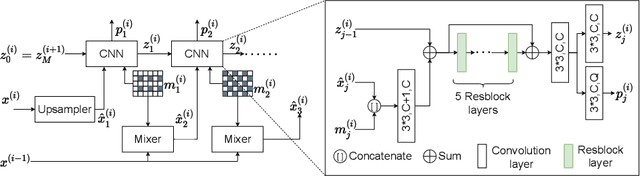

Lossless image compression is an important technique for image storage and transmission when information loss is not allowed. With the fast development of deep learning techniques, deep neural networks have been used in this field to achieve a higher compression rate. Methods based on pixel-wise autoregressive statistical models have shown good performance. However, the sequential processing way prevents these methods to be used in practice. Recently, multi-scale autoregressive models have been proposed to address this limitation. Multi-scale approaches can use parallel computing systems efficiently and build practical systems. Nevertheless, these approaches sacrifice compression performance in exchange for speed. In this paper, we propose a multi-scale progressive statistical model that takes advantage of the pixel-wise approach and the multi-scale approach. We developed a flexible mechanism where the processing order of the pixels can be adjusted easily. Our proposed method outperforms the state-of-the-art lossless image compression methods on two large benchmark datasets by a significant margin without degrading the inference speed dramatically.
Parallel Structure from Motion for UAV Images via Weighted Connected Dominating Set
Jun 24, 2022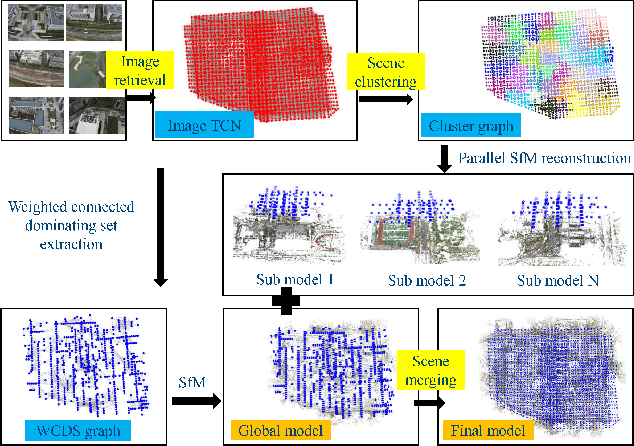

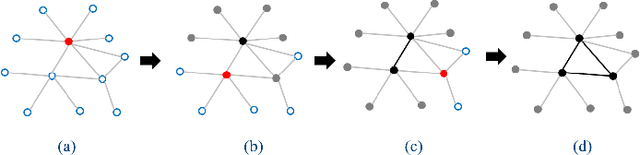
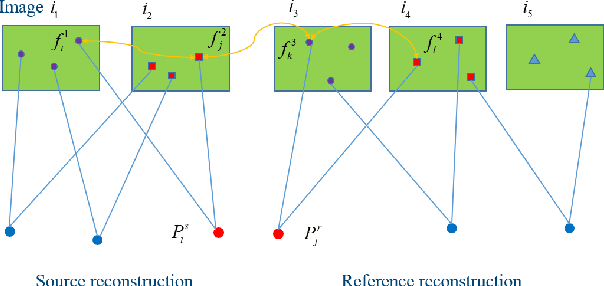
Incremental Structure from Motion (ISfM) has been widely used for UAV image orientation. Its efficiency, however, decreases dramatically due to the sequential constraint. Although the divide-and-conquer strategy has been utilized for efficiency improvement, cluster merging becomes difficult or depends on seriously designed overlap structures. This paper proposes an algorithm to extract the global model for cluster merging and designs a parallel SfM solution to achieve efficient and accurate UAV image orientation. First, based on vocabulary tree retrieval, match pairs are selected to construct an undirected weighted match graph, whose edge weights are calculated by considering both the number and distribution of feature matches. Second, an algorithm, termed weighted connected dominating set (WCDS), is designed to achieve the simplification of the match graph and build the global model, which incorporates the edge weight in the graph node selection and enables the successful reconstruction of the global model. Third, the match graph is simultaneously divided into compact and non-overlapped clusters. After the parallel reconstruction, cluster merging is conducted with the aid of common 3D points between the global and cluster models. Finally, by using three UAV datasets that are captured by classical oblique and recent optimized views photogrammetry, the validation of the proposed solution is verified through comprehensive analysis and comparison. The experimental results demonstrate that the proposed parallel SfM can achieve 17.4 times efficiency improvement and comparative orientation accuracy. In absolute BA, the geo-referencing accuracy is approximately 2.0 and 3.0 times the GSD (Ground Sampling Distance) value in the horizontal and vertical directions, respectively. For parallel SfM, the proposed solution is a more reliable alternative.