 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
3D High-Quality Magnetic Resonance Image Restoration in Clinics Using Deep Learning
Dec 09, 2021
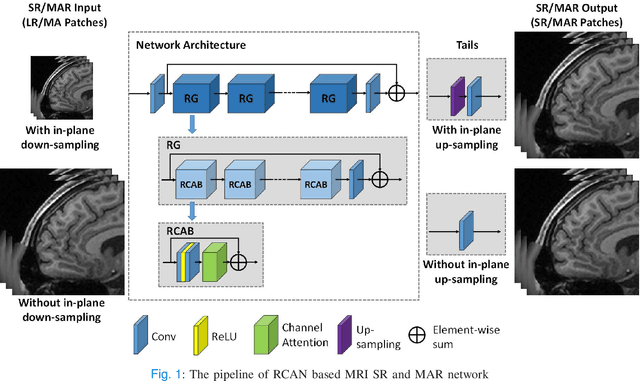
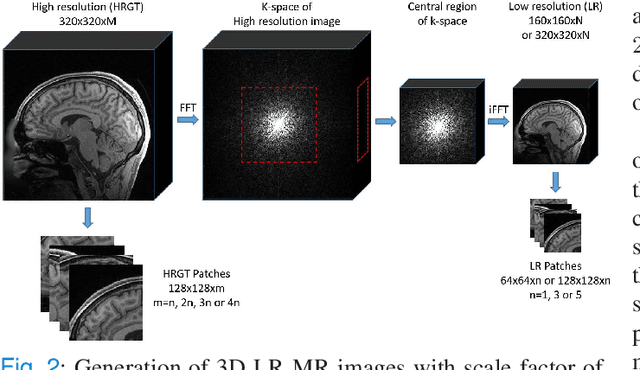
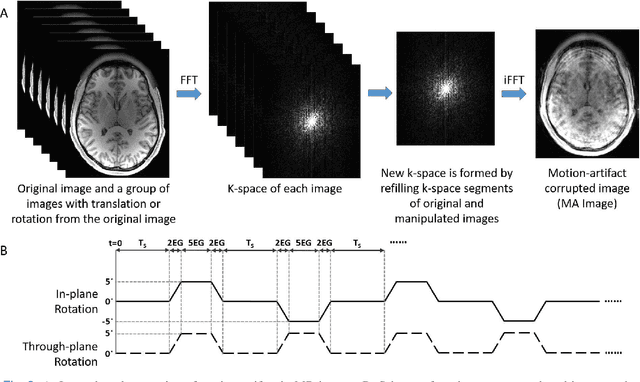

Shortening acquisition time and reducing the motion-artifact are two of the most essential concerns in magnetic resonance imaging. As a promising solution, deep learning-based high quality MR image restoration has been investigated to generate higher resolution and motion artifact-free MR images from lower resolution images acquired with shortened acquisition time, without costing additional acquisition time or modifying the pulse sequences. However, numerous problems still exist to prevent deep learning approaches from becoming practical in the clinic environment. Specifically, most of the prior works focus solely on the network model but ignore the impact of various downsampling strategies on the acquisition time. Besides, the long inference time and high GPU consumption are also the bottle neck to deploy most of the prior works in clinics. Furthermore, prior studies employ random movement in retrospective motion artifact generation, resulting in uncontrollable severity of motion artifact. More importantly, doctors are unsure whether the generated MR images are trustworthy, making diagnosis difficult. To overcome all these problems, we employed a unified 2D deep learning neural network for both 3D MRI super resolution and motion artifact reduction, demonstrating such a framework can achieve better performance in 3D MRI restoration task compared to other states of the art methods and remains the GPU consumption and inference time significantly low, thus easier to deploy. We also analyzed several downsampling strategies based on the acceleration factor, including multiple combinations of in-plane and through-plane downsampling, and developed a controllable and quantifiable motion artifact generation method. At last, the pixel-wise uncertainty was calculated and used to estimate the accuracy of generated image, providing additional information for reliable diagnosis.
Dynamic Degradation for Image Restoration and Fusion
Apr 26, 2021
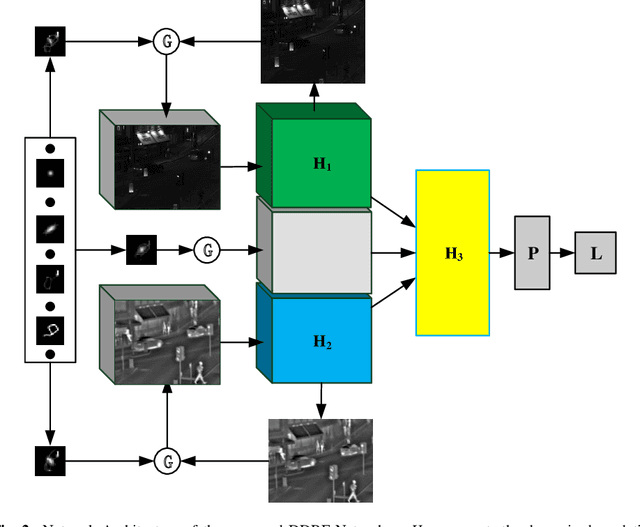


The deep-learning-based image restoration and fusion methods have achieved remarkable results. However, the existing restoration and fusion methods paid little research attention to the robustness problem caused by dynamic degradation. In this paper, we propose a novel dynamic image restoration and fusion neural network, termed as DDRF-Net, which is capable of solving two problems, i.e., static restoration and fusion, dynamic degradation. In order to solve the static fusion problem of existing methods, dynamic convolution is introduced to learn dynamic restoration and fusion weights. In addition, a dynamic degradation kernel is proposed to improve the robustness of image restoration and fusion. Our network framework can effectively combine image degradation with image fusion tasks, provide more detailed information for image fusion tasks through image restoration loss, and optimize image restoration tasks through image fusion loss. Therefore, the stumbling blocks of deep learning in image fusion, e.g., static fusion weight and specifically designed network architecture, are greatly mitigated. Extensive experiments show that our method is more superior compared with the state-of-the-art methods.
Deep Learning for Classification of Thyroid Nodules on Ultrasound: Validation on an Independent Dataset
Jul 27, 2022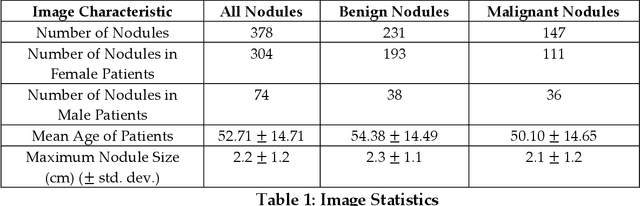
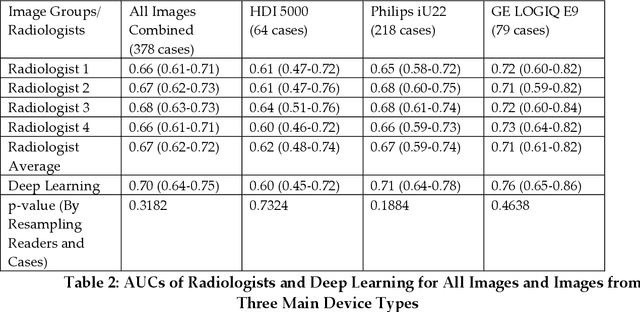
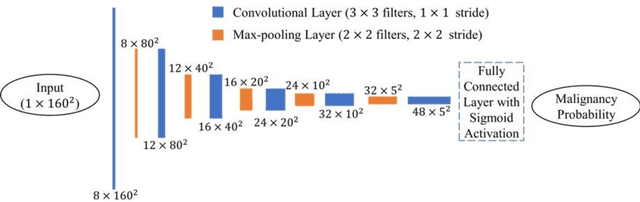
Objectives: The purpose is to apply a previously validated deep learning algorithm to a new thyroid nodule ultrasound image dataset and compare its performances with radiologists. Methods: Prior study presented an algorithm which is able to detect thyroid nodules and then make malignancy classifications with two ultrasound images. A multi-task deep convolutional neural network was trained from 1278 nodules and originally tested with 99 separate nodules. The results were comparable with that of radiologists. The algorithm was further tested with 378 nodules imaged with ultrasound machines from different manufacturers and product types than the training cases. Four experienced radiologists were requested to evaluate the nodules for comparison with deep learning. Results: The Area Under Curve (AUC) of the deep learning algorithm and four radiologists were calculated with parametric, binormal estimation. For the deep learning algorithm, the AUC was 0.70 (95% CI: 0.64 - 0.75). The AUC of radiologists were 0.66 (95% CI: 0.61 - 0.71), 0.67 (95% CI:0.62 - 0.73), 0.68 (95% CI: 0.63 - 0.73), and 0.66 (95%CI: 0.61 - 0.71). Conclusion: In the new testing dataset, the deep learning algorithm achieved similar performances with all four radiologists.
Classification of Alzheimer's Disease Using the Convolutional Neural Network (CNN) with Transfer Learning and Weighted Loss
Jul 04, 2022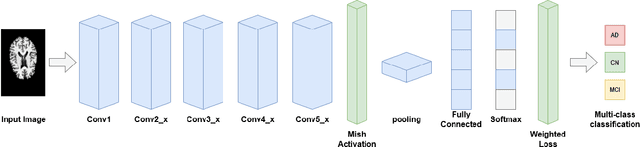
Alzheimer's disease is a progressive neurodegenerative disorder that gradually deprives the patient of cognitive function and can end in death. With the advancement of technology today, it is possible to detect Alzheimer's disease through Magnetic Resonance Imaging (MRI) scans. So that MRI is the technique most often used for the diagnosis and analysis of the progress of Alzheimer's disease. With this technology, image recognition in the early diagnosis of Alzheimer's disease can be achieved automatically using machine learning. Although machine learning has many advantages, currently the use of deep learning is more widely applied because it has stronger learning capabilities and is more suitable for solving image recognition problems. However, there are still several challenges that must be faced to implement deep learning, such as the need for large datasets, requiring large computing resources, and requiring careful parameter setting to prevent overfitting or underfitting. In responding to the challenge of classifying Alzheimer's disease using deep learning, this study propose the Convolutional Neural Network (CNN) method with the Residual Network 18 Layer (ResNet-18) architecture. To overcome the need for a large and balanced dataset, transfer learning from ImageNet is used and weighting the loss function values so that each class has the same weight. And also in this study conducted an experiment by changing the network activation function to a mish activation function to increase accuracy. From the results of the tests that have been carried out, the accuracy of the model is 88.3 % using transfer learning, weighted loss and the mish activation function. This accuracy value increases from the baseline model which only gets an accuracy of 69.1 %.
Panoramic Panoptic Segmentation: Insights Into Surrounding Parsing for Mobile Agents via Unsupervised Contrastive Learning
Jun 21, 2022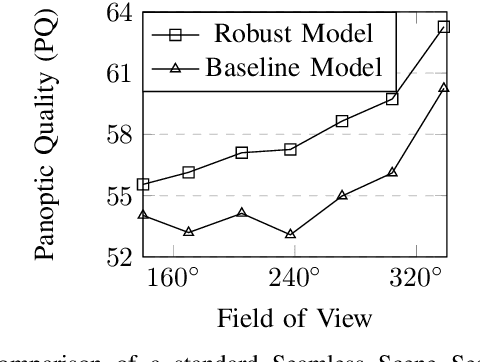
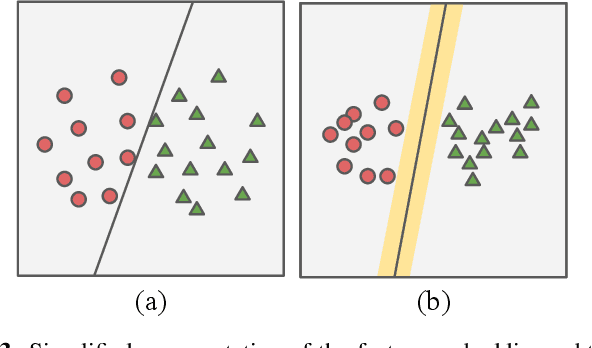
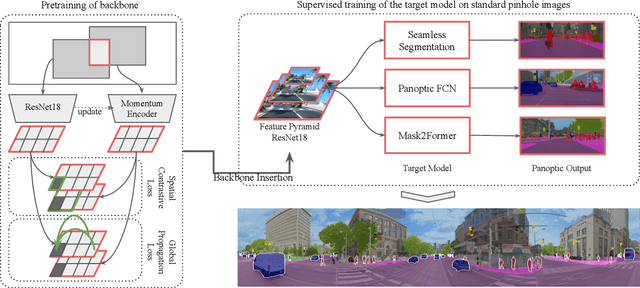
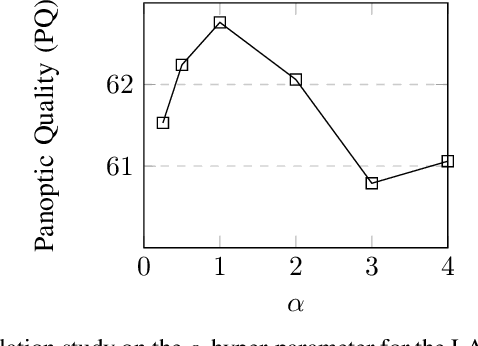
In this work, we introduce panoramic panoptic segmentation, as the most holistic scene understanding, both in terms of Field of View (FoV) and image-level understanding for standard camera-based input. A complete surrounding understanding provides a maximum of information to a mobile agent, which is essential for any intelligent vehicle in order to make informed decisions in a safety-critical dynamic environment such as real-world traffic. In order to overcome the lack of annotated panoramic images, we propose a framework which allows model training on standard pinhole images and transfers the learned features to a different domain in a cost-minimizing way. Using our proposed method with dense contrastive learning, we manage to achieve significant improvements over a non-adapted approach. Depending on the efficient panoptic segmentation architecture, we can improve 3.5-6.5% measured in Panoptic Quality (PQ) over non-adapted models on our established Wild Panoramic Panoptic Segmentation (WildPPS) dataset. Furthermore, our efficient framework does not need access to the images of the target domain, making it a feasible domain generalization approach suitable for a limited hardware setting. As additional contributions, we publish WildPPS: The first panoramic panoptic image dataset to foster progress in surrounding perception and explore a novel training procedure combining supervised and contrastive training.
Slice-by-slice deep learning aided oropharyngeal cancer segmentation with adaptive thresholding for spatial uncertainty on FDG PET and CT images
Jul 04, 2022
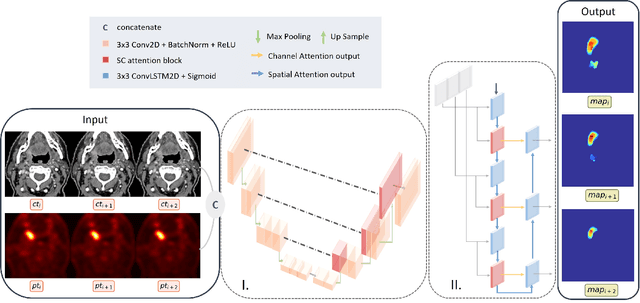
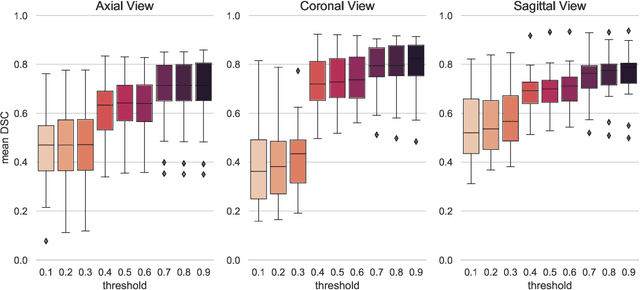
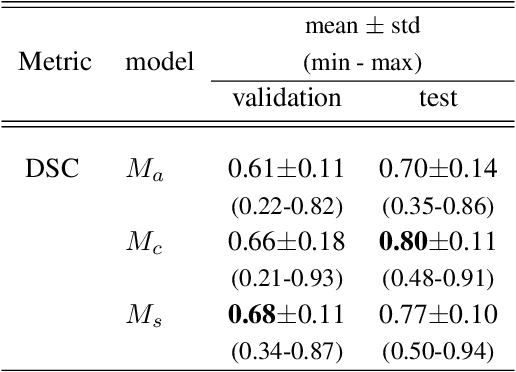
Tumor segmentation is a fundamental step for radiotherapy treatment planning. To define an accurate segmentation of the primary tumor (GTVp) of oropharyngeal cancer patients (OPC), simultaneous assessment of different image modalities is needed, and each image volume is explored slice-by-slice from different orientations. Moreover, the manual fixed boundary of segmentation neglects the spatial uncertainty known to occur in tumor delineation. This study proposes a novel automatic deep learning (DL) model to assist radiation oncologists in a slice-by-slice adaptive GTVp segmentation on registered FDG PET/CT images. We included 138 OPC patients treated with (chemo)radiation in our institute. Our DL framework exploits both inter and intra-slice context. Sequences of 3 consecutive 2D slices of concatenated FDG PET/CT images and GTVp contours were used as input. A 3-fold cross validation was performed three times, training on sequences extracted from the Axial (A), Sagittal (S), and Coronal (C) plane of 113 patients. Since consecutive sequences in a volume contain overlapping slices, each slice resulted in three outcome predictions that were averaged. In the A, S, and C planes, the output shows areas with different probabilities of predicting the tumor. The performance of the models was assessed on 25 patients at different probability thresholds using the mean Dice Score Coefficient (DSC). Predictions were the closest to the ground truth at a probability threshold of 0.9 (DSC of 0.70 in the A, 0.77 in the S, and 0.80 in the C plane). The promising results of the proposed DL model show that the probability maps on registered FDG PET/CT images could guide radiation oncologists in a slice-by-slice adaptive GTVp segmentation.
Task-Driven Deep Image Enhancement Network for Autonomous Driving in Bad Weather
Oct 14, 2021
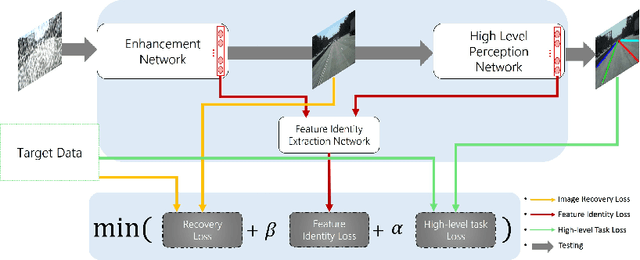
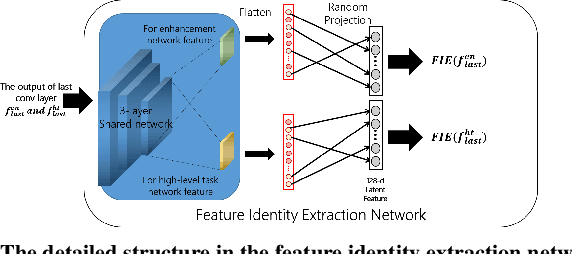

Visual perception in autonomous driving is a crucial part of a vehicle to navigate safely and sustainably in different traffic conditions. However, in bad weather such as heavy rain and haze, the performance of visual perception is greatly affected by several degrading effects. Recently, deep learning-based perception methods have addressed multiple degrading effects to reflect real-world bad weather cases but have shown limited success due to 1) high computational costs for deployment on mobile devices and 2) poor relevance between image enhancement and visual perception in terms of the model ability. To solve these issues, we propose a task-driven image enhancement network connected to the high-level vision task, which takes in an image corrupted by bad weather as input. Specifically, we introduce a novel low memory network to reduce most of the layer connections of dense blocks for less memory and computational cost while maintaining high performance. We also introduce a new task-driven training strategy to robustly guide the high-level task model suitable for both high-quality restoration of images and highly accurate perception. Experiment results demonstrate that the proposed method improves the performance among lane and 2D object detection, and depth estimation largely under adverse weather in terms of both low memory and accuracy.
TotalSegmentator: robust segmentation of 104 anatomical structures in CT images
Aug 11, 2022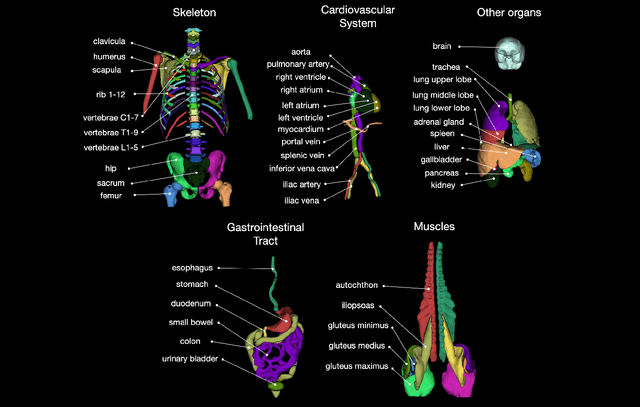
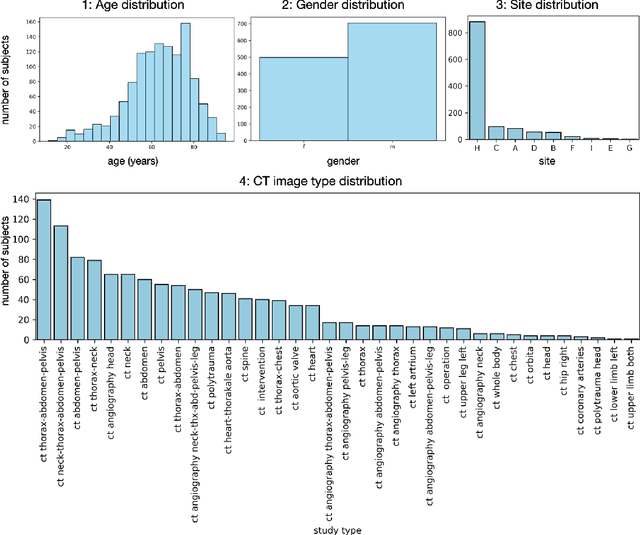

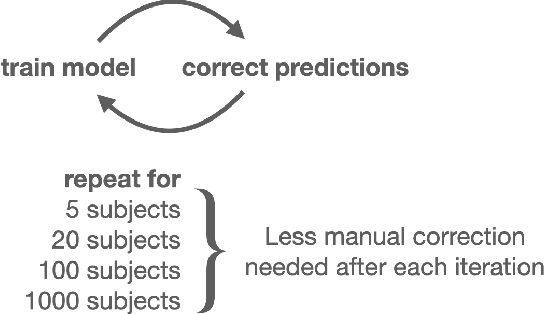
In this work we focus on automatic segmentation of multiple anatomical structures in (whole body) CT images. Many segmentation algorithms exist for this task. However, in most cases they suffer from 3 problems: 1. They are difficult to use (the code and data is not publicly available or difficult to use). 2. They do not generalize (often the training dataset was curated to only contain very clean images which do not reflect the image distribution found during clinical routine), 3. The algorithm can only segment one anatomical structure. For more structures several algorithms have to be used which increases the effort required to set up the system. In this work we publish a new dataset and segmentation toolkit which solves all three of these problems: In 1204 CT images we segmented 104 anatomical structures (27 organs, 59 bones, 10 muscles, 8 vessels) covering a majority of relevant classes for most use cases. We show an improved workflow for the creation of ground truth segmentations which speeds up the process by over 10x. The CT images were randomly sampled from clinical routine, thus representing a real world dataset which generalizes to clinical application. The dataset contains a wide range of different pathologies, scanners, sequences and sites. Finally, we train a segmentation algorithm on this new dataset. We call this algorithm TotalSegmentator and make it easily available as a pretrained python pip package (pip install totalsegmentator). Usage is as simple as TotalSegmentator -i ct.nii.gz -o seg and it works well for most CT images. The code is available at https://github.com/wasserth/TotalSegmentator and the dataset at https://doi.org/10.5281/zenodo.6802613.
A Convolutional Neural Network Approach to Supernova Time-Series Classification
Jul 19, 2022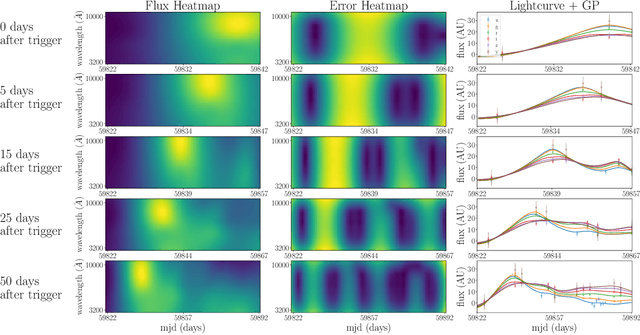
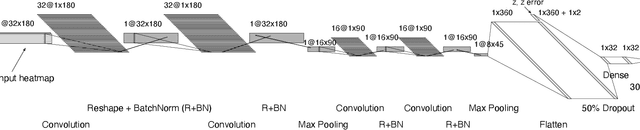
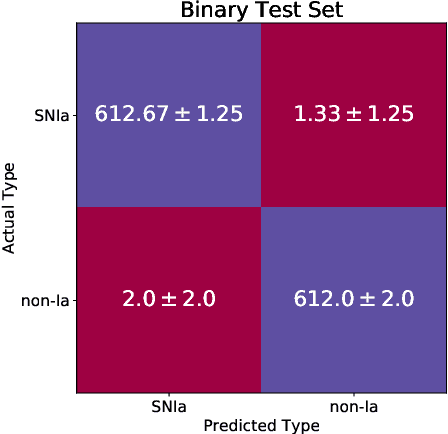
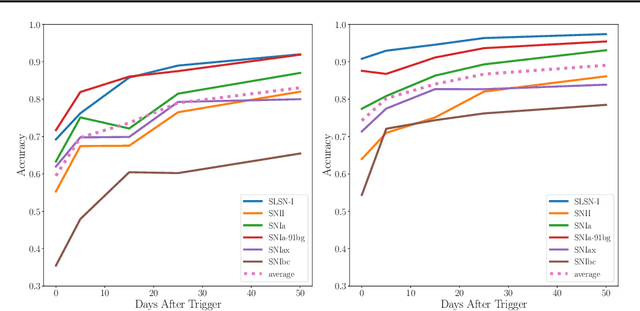
One of the brightest objects in the universe, supernovae (SNe) are powerful explosions marking the end of a star's lifetime. Supernova (SN) type is defined by spectroscopic emission lines, but obtaining spectroscopy is often logistically unfeasible. Thus, the ability to identify SNe by type using time-series image data alone is crucial, especially in light of the increasing breadth and depth of upcoming telescopes. We present a convolutional neural network method for fast supernova time-series classification, with observed brightness data smoothed in both the wavelength and time directions with Gaussian process regression. We apply this method to full duration and truncated SN time-series, to simulate retrospective as well as real-time classification performance. Retrospective classification is used to differentiate cosmologically useful Type Ia SNe from other SN types, and this method achieves >99% accuracy on this task. We are also able to differentiate between 6 SN types with 60% accuracy given only two nights of data and 98% accuracy retrospectively.
Efficient large-scale image retrieval with deep feature orthogonality and Hybrid-Swin-Transformers
Oct 27, 2021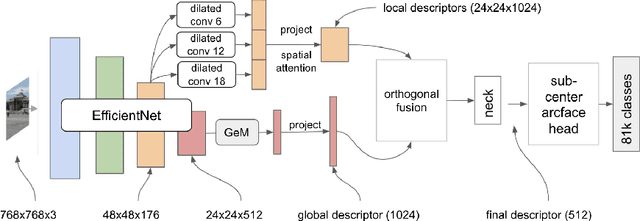
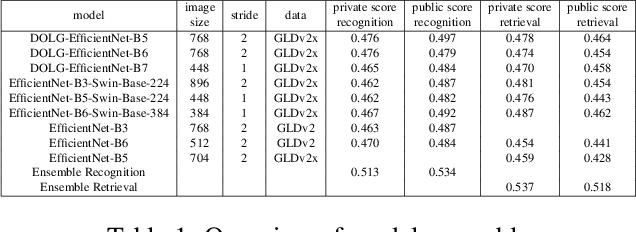
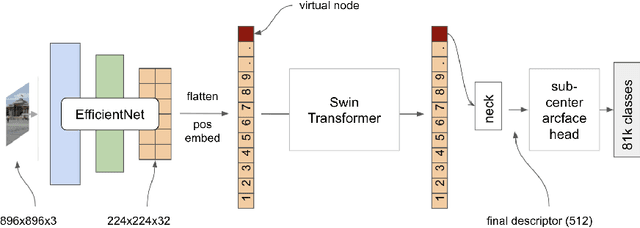
We present an efficient end-to-end pipeline for largescale landmark recognition and retrieval. We show how to combine and enhance concepts from recent research in image retrieval and introduce two architectures especially suited for large-scale landmark identification. A model with deep orthogonal fusion of local and global features (DOLG) using an EfficientNet backbone as well as a novel Hybrid-Swin-Transformer is discussed and details how to train both architectures efficiently using a step-wise approach and a sub-center arcface loss with dynamic margins are provided. Furthermore, we elaborate a novel discriminative re-ranking methodology for image retrieval. The superiority of our approach was demonstrated by winning the recognition and retrieval track of the Google Landmark Competition 2021.