 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Two Souls in an Adversarial Image: Towards Universal Adversarial Example Detection using Multi-view Inconsistency
Oct 11, 2021
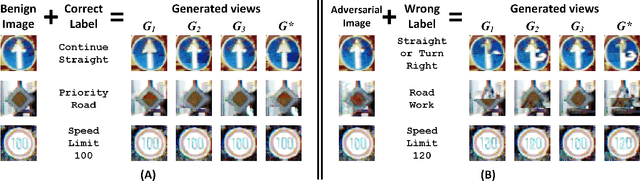
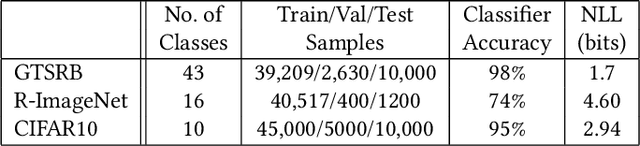
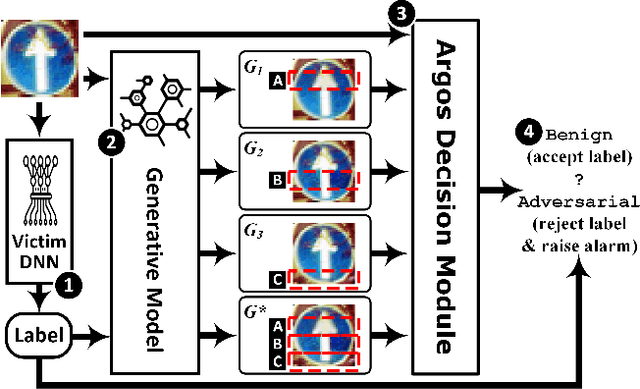
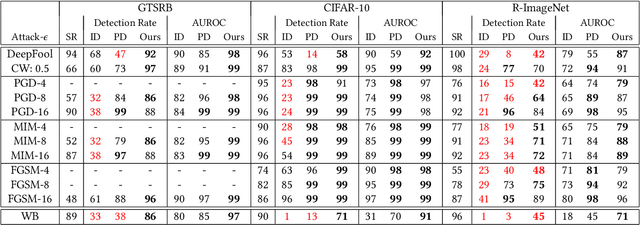
In the evasion attacks against deep neural networks (DNN), the attacker generates adversarial instances that are visually indistinguishable from benign samples and sends them to the target DNN to trigger misclassifications. In this paper, we propose a novel multi-view adversarial image detector, namely Argos, based on a novel observation. That is, there exist two "souls" in an adversarial instance, i.e., the visually unchanged content, which corresponds to the true label, and the added invisible perturbation, which corresponds to the misclassified label. Such inconsistencies could be further amplified through an autoregressive generative approach that generates images with seed pixels selected from the original image, a selected label, and pixel distributions learned from the training data. The generated images (i.e., the "views") will deviate significantly from the original one if the label is adversarial, demonstrating inconsistencies that Argos expects to detect. To this end, Argos first amplifies the discrepancies between the visual content of an image and its misclassified label induced by the attack using a set of regeneration mechanisms and then identifies an image as adversarial if the reproduced views deviate to a preset degree. Our experimental results show that Argos significantly outperforms two representative adversarial detectors in both detection accuracy and robustness against six well-known adversarial attacks. Code is available at: https://github.com/sohaib730/Argos-Adversarial_Detection
Corrosion Detection for Industrial Objects: From Multi-Sensor System to 5D Feature Space
May 14, 2022
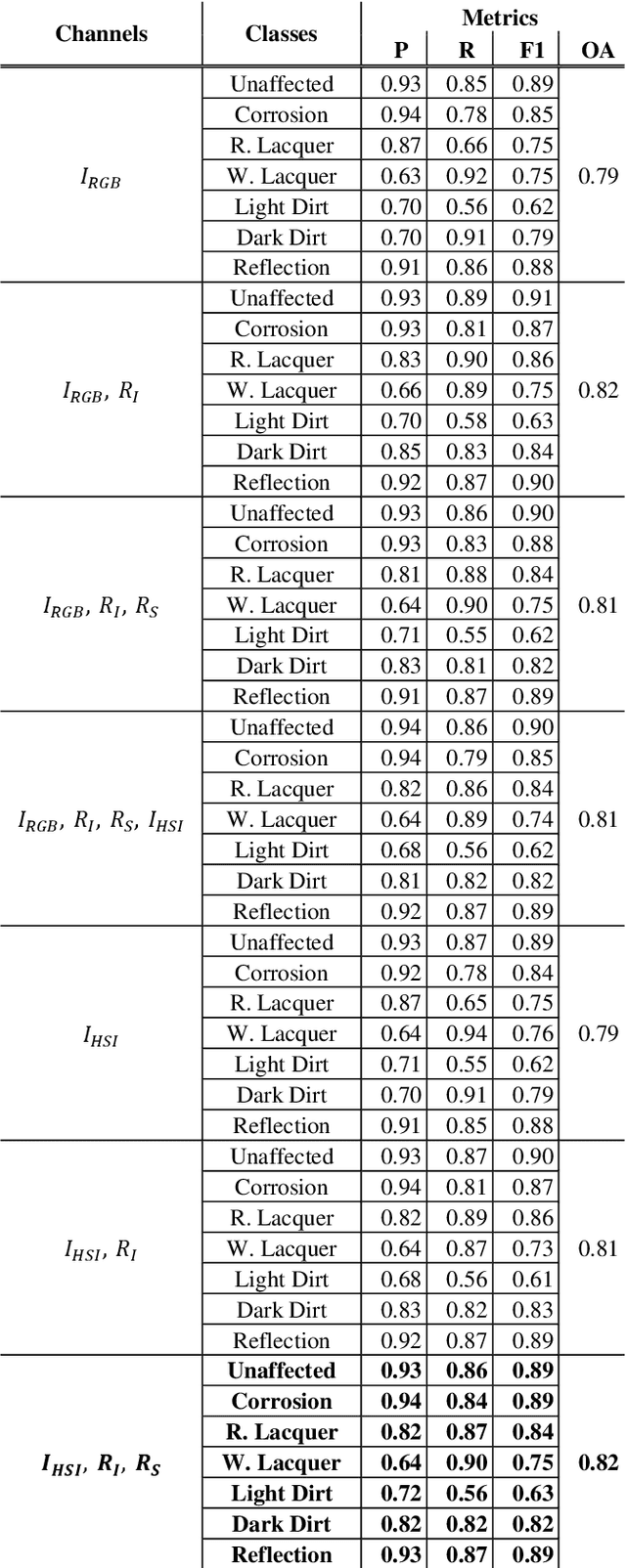

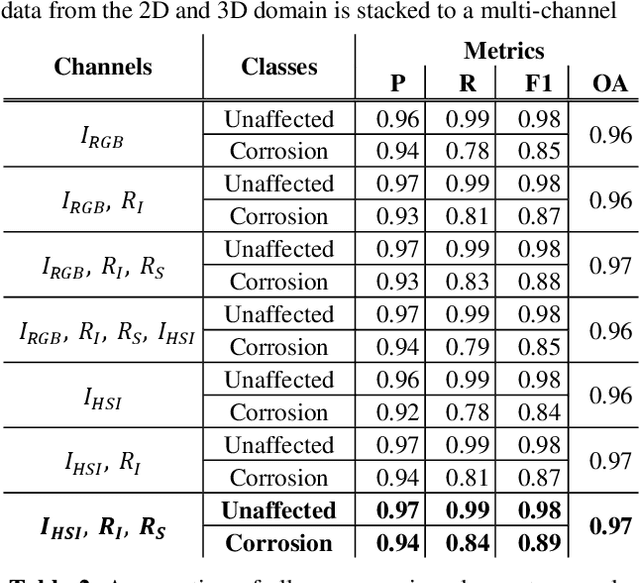
Corrosion is a form of damage that often appears on the surface of metal-made objects used in industrial applications. Those damages can be critical depending on the purpose of the used object. Optical-based testing systems provide a form of non-contact data acquisition, where the acquired data can then be used to analyse the surface of an object. In the field of industrial image processing, this is called surface inspection. We provide a testing setup consisting of a rotary table which rotates the object by 360 degrees, as well as industrial RGB cameras and laser triangulation sensors for the acquisition of 2D and 3D data as our multi-sensor system. These sensors acquire data while the object to be tested takes a full rotation. Further on, data augmentation is applied to prepare new data or enhance already acquired data. In order to evaluate the impact of a laser triangulation sensor for corrosion detection, one challenge is to at first fuse the data of both domains. After the data fusion process, 5 different channels can be utilized to create a 5D feature space. Besides the red, green and blue channels of the image (1-3), additional range data from the laser triangulation sensor is incorporated (4). As a fifth channel, said sensor provides additional intensity data (5). With a multi-channel image classification, a 5D feature space will lead to slightly superior results opposed to a 3D feature space, composed of only the RGB channels of the image.
Discriminative Feature Learning through Feature Distance Loss
May 25, 2022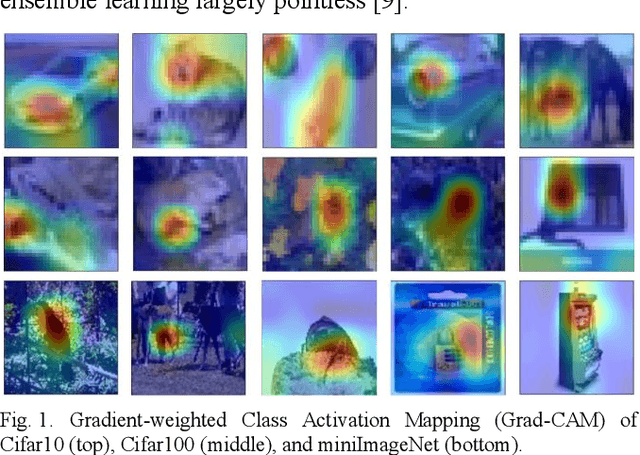
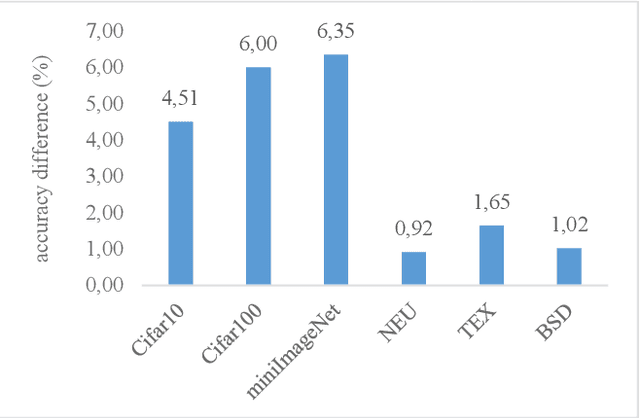
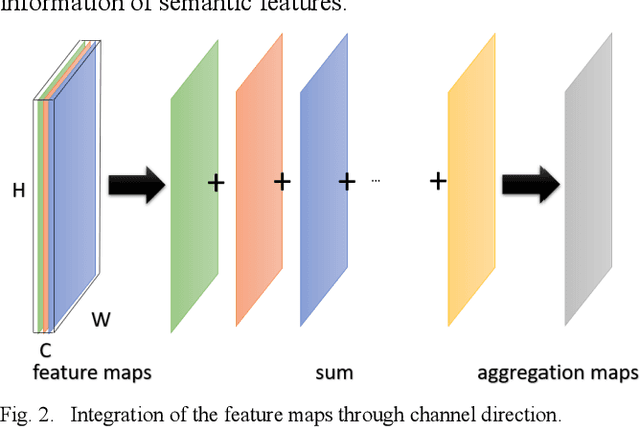
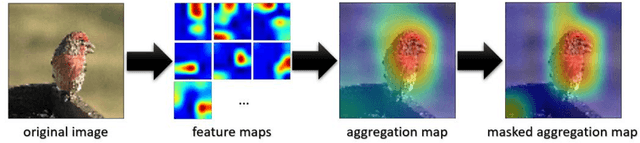
Convolutional neural networks have shown remarkable ability to learn discriminative semantic features in image recognition tasks. Though, for classification they often concentrate on specific regions in images. This work proposes a novel method that combines variant rich base models to concentrate on different important image regions for classification. A feature distance loss is implemented while training an ensemble of base models to force them to learn discriminative feature concepts. The experiments on benchmark convolutional neural networks (VGG16, ResNet, AlexNet), popular datasets (Cifar10, Cifar100, miniImageNet, NEU, BSD, TEX), and different training samples (3, 5, 10, 20, 50, 100 per class) show our methods effectiveness and generalization ability. Our method outperforms ensemble versions of the base models without feature distance loss, and the Class Activation Maps explicitly proves the ability to learn different discriminative feature concepts.
Does deep learning model calibration improve performance in class-imbalanced medical image classification?
Oct 11, 2021
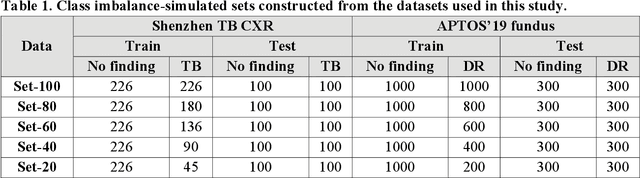
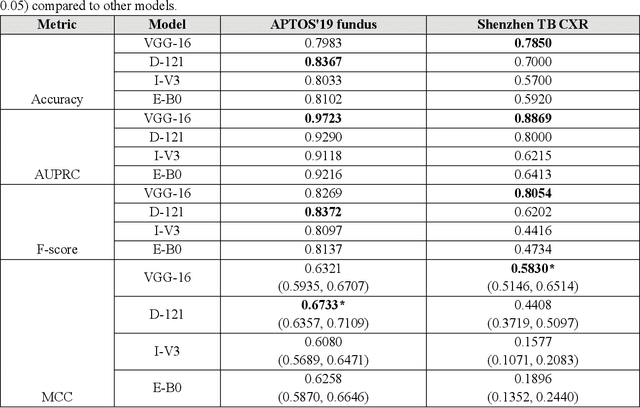
In medical image classification tasks, it is common to find that the number of normal samples far exceeds the number of abnormal samples. In such class-imbalanced situations, reliable training of deep neural networks continues to be a major challenge. Under these circumstances, the predicted class probabilities may be biased toward the majority class. Calibration has been suggested to alleviate some of these effects. However, there is insufficient analysis explaining when and whether calibrating a model would be beneficial in improving performance. In this study, we perform a systematic analysis of the effect of model calibration on its performance on two medical image modalities, namely, chest X-rays and fundus images, using various deep learning classifier backbones. For this, we study the following variations: (i) the degree of imbalances in the dataset used for training; (ii) calibration methods; and (iii) two classification thresholds, namely, default decision threshold of 0.5, and optimal threshold from precision-recall curves. Our results indicate that at the default operating threshold of 0.5, the performance achieved through calibration is significantly superior (p < 0.05) to using uncalibrated probabilities. However, at the PR-guided threshold, these gains are not significantly different (p > 0.05). This finding holds for both image modalities and at varying degrees of imbalance.
GradICON: Approximate Diffeomorphisms via Gradient Inverse Consistency
Jun 13, 2022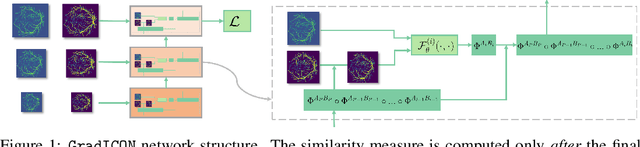
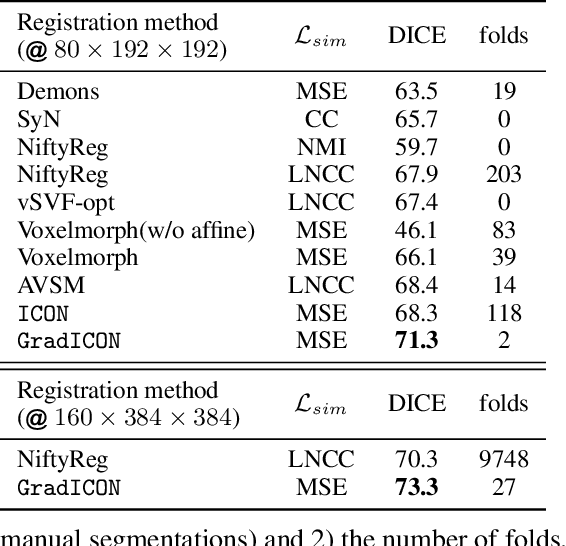
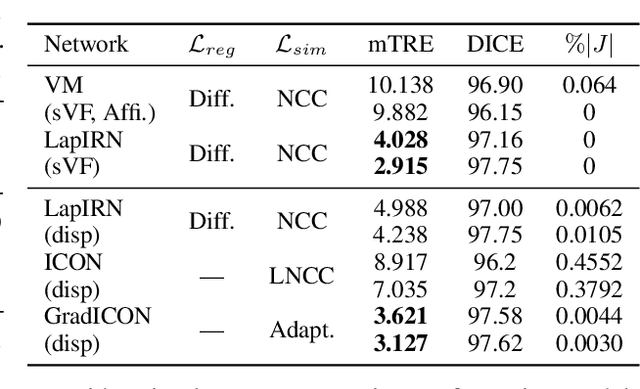
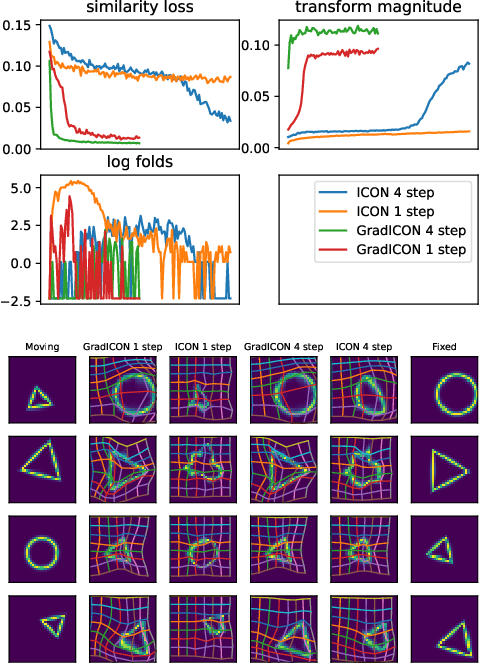
Many registration approaches exist with early work focusing on optimization-based approaches for image pairs. Recent work focuses on deep registration networks to predict spatial transformations. In both cases, commonly used non-parametric registration models, which estimate transformation functions instead of low-dimensional transformation parameters, require choosing a suitable regularizer (to encourage smooth transformations) and its parameters. This makes models difficult to tune and restricts deformations to the deformation space permissible by the chosen regularizer. While deep-learning models for optical flow exist that do not regularize transformations and instead entirely rely on the data these might not yield diffeomorphic transformations which are desirable for medical image registration. In this work, we therefore develop GradICON building upon the unsupervised ICON deep-learning registration approach, which only uses inverse-consistency for regularization. However, in contrast to ICON, we prove and empirically verify that using a gradient inverse-consistency loss not only significantly improves convergence, but also results in a similar implicit regularization of the resulting transformation map. Synthetic experiments and experiments on magnetic resonance (MR) knee images and computed tomography (CT) lung images show the excellent performance of GradICON. We achieve state-of-the-art (SOTA) accuracy while retaining a simple registration formulation, which is practically important.
DOLG: Single-Stage Image Retrieval with Deep Orthogonal Fusion of Local and Global Features
Aug 06, 2021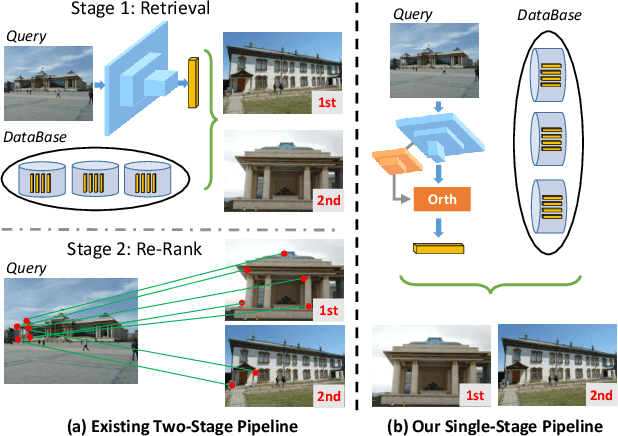
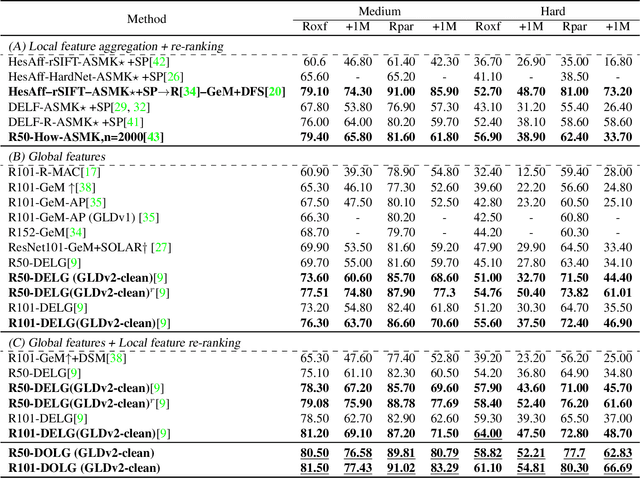
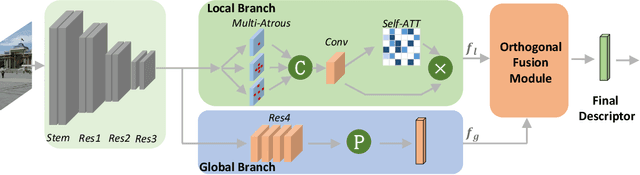
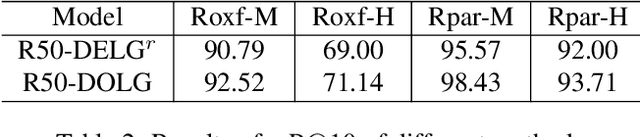
Image Retrieval is a fundamental task of obtaining images similar to the query one from a database. A common image retrieval practice is to firstly retrieve candidate images via similarity search using global image features and then re-rank the candidates by leveraging their local features. Previous learning-based studies mainly focus on either global or local image representation learning to tackle the retrieval task. In this paper, we abandon the two-stage paradigm and seek to design an effective single-stage solution by integrating local and global information inside images into compact image representations. Specifically, we propose a Deep Orthogonal Local and Global (DOLG) information fusion framework for end-to-end image retrieval. It attentively extracts representative local information with multi-atrous convolutions and self-attention at first. Components orthogonal to the global image representation are then extracted from the local information. At last, the orthogonal components are concatenated with the global representation as a complementary, and then aggregation is performed to generate the final representation. The whole framework is end-to-end differentiable and can be trained with image-level labels. Extensive experimental results validate the effectiveness of our solution and show that our model achieves state-of-the-art image retrieval performances on Revisited Oxford and Paris datasets.
Generative Extraction of Audio Classifiers for Speaker Identification
Jul 26, 2022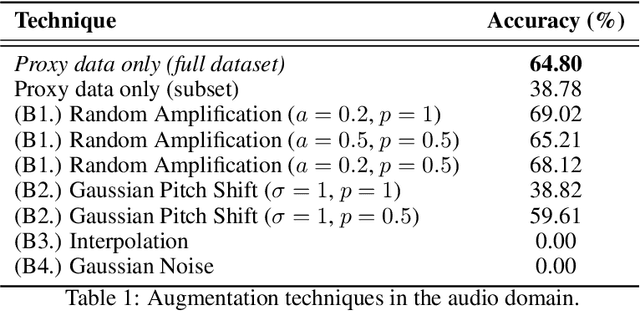
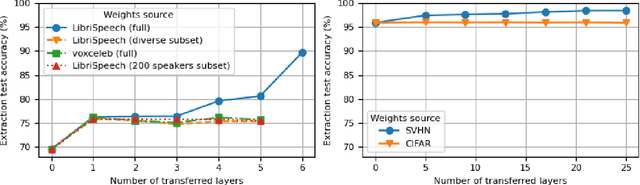

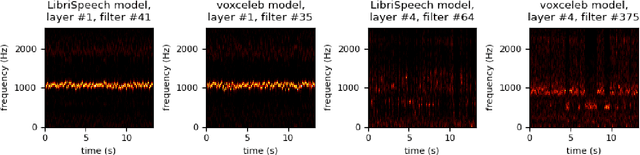
It is perhaps no longer surprising that machine learning models, especially deep neural networks, are particularly vulnerable to attacks. One such vulnerability that has been well studied is model extraction: a phenomenon in which the attacker attempts to steal a victim's model by training a surrogate model to mimic the decision boundaries of the victim model. Previous works have demonstrated the effectiveness of such an attack and its devastating consequences, but much of this work has been done primarily for image and text processing tasks. Our work is the first attempt to perform model extraction on {\em audio classification models}. We are motivated by an attacker whose goal is to mimic the behavior of the victim's model trained to identify a speaker. This is particularly problematic in security-sensitive domains such as biometric authentication. We find that prior model extraction techniques, where the attacker \textit{naively} uses a proxy dataset to attack a potential victim's model, fail. We therefore propose the use of a generative model to create a sufficiently large and diverse pool of synthetic attack queries. We find that our approach is able to extract a victim's model trained on \texttt{LibriSpeech} using queries synthesized with a proxy dataset based off of \texttt{VoxCeleb}; we achieve a test accuracy of 84.41\% with a budget of 3 million queries.
Image Comes Dancing with Collaborative Parsing-Flow Video Synthesis
Oct 28, 2021
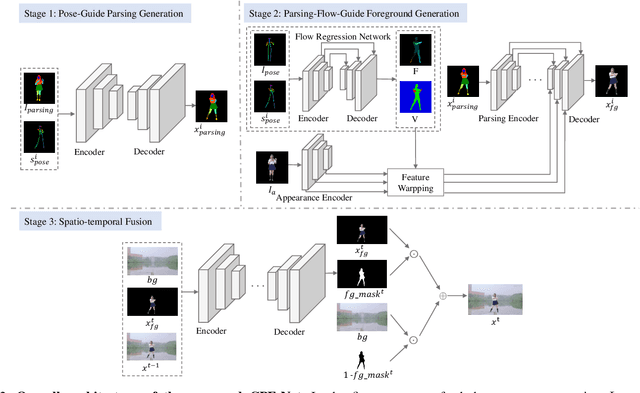


Transferring human motion from a source to a target person poses great potential in computer vision and graphics applications. A crucial step is to manipulate sequential future motion while retaining the appearance characteristic.Previous work has either relied on crafted 3D human models or trained a separate model specifically for each target person, which is not scalable in practice.This work studies a more general setting, in which we aim to learn a single model to parsimoniously transfer motion from a source video to any target person given only one image of the person, named as Collaborative Parsing-Flow Network (CPF-Net). The paucity of information regarding the target person makes the task particularly challenging to faithfully preserve the appearance in varying designated poses. To address this issue, CPF-Net integrates the structured human parsing and appearance flow to guide the realistic foreground synthesis which is merged into the background by a spatio-temporal fusion module. In particular, CPF-Net decouples the problem into stages of human parsing sequence generation, foreground sequence generation and final video generation. The human parsing generation stage captures both the pose and the body structure of the target. The appearance flow is beneficial to keep details in synthesized frames. The integration of human parsing and appearance flow effectively guides the generation of video frames with realistic appearance. Finally, the dedicated designed fusion network ensure the temporal coherence. We further collect a large set of human dancing videos to push forward this research field. Both quantitative and qualitative results show our method substantially improves over previous approaches and is able to generate appealing and photo-realistic target videos given any input person image. All source code and dataset will be released at https://github.com/xiezhy6/CPF-Net.
Automatic Preprocessing and Ensemble Learning for Low Quality Cell Image Segmentation
Aug 30, 2021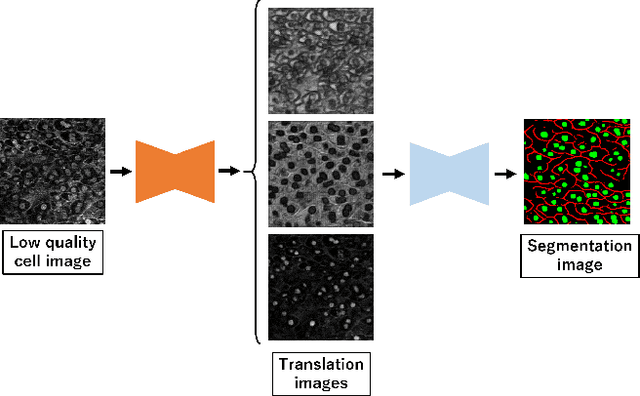
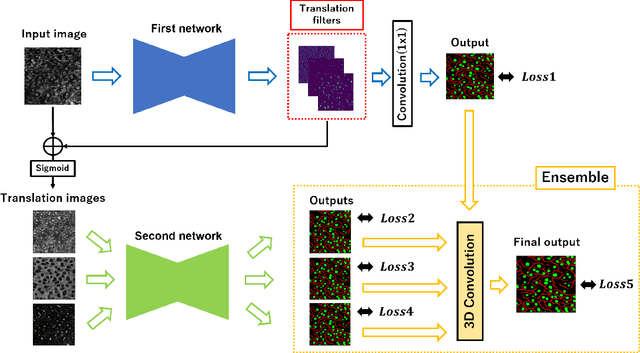
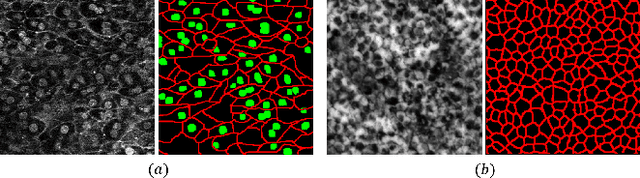
We propose an automatic preprocessing and ensemble learning for segmentation of cell images with low quality. It is difficult to capture cells with strong light. Therefore, the microscopic images of cells tend to have low image quality but these images are not good for semantic segmentation. Here we propose a method to translate an input image to the images that are easy to recognize by deep learning. The proposed method consists of two deep neural networks. The first network is the usual training for semantic segmentation, and penultimate feature maps of the first network are used as filters to translate an input image to the images that emphasize each class. This is the automatic preprocessing and translated cell images are easily classified. The input cell image with low quality is translated by the feature maps in the first network, and the translated images are fed into the second network for semantic segmentation. Since the outputs of the second network are multiple segmentation results, we conduct the weighted ensemble of those segmentation images. Two networks are trained by end-to-end manner, and we do not need to prepare images with high quality for the translation. We confirmed that our proposed method can translate cell images with low quality to the images that are easy to segment, and segmentation accuracy has improved using the weighted ensemble learning.
Untrained, physics-informed neural networks for structured illumination microscopy
Jul 15, 2022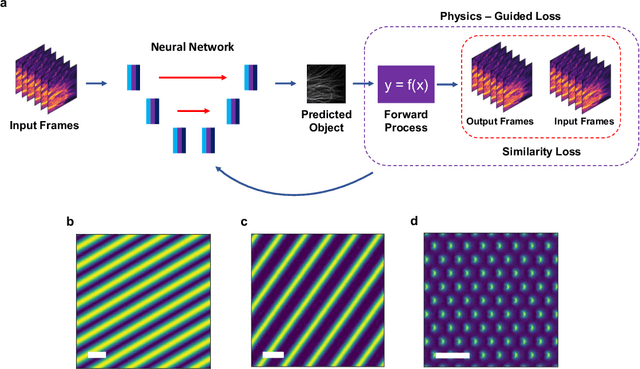
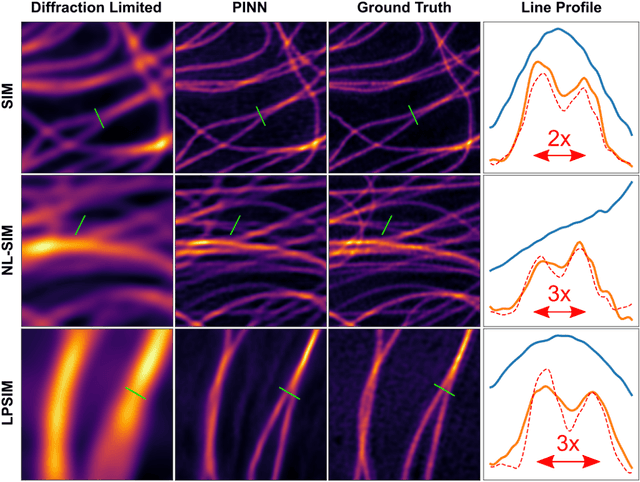

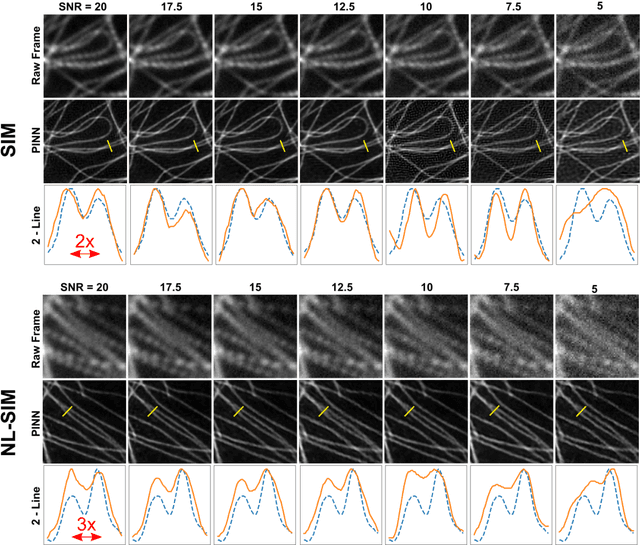
In recent years there has been great interest in using deep neural networks (DNN) for super-resolution image reconstruction including for structured illumination microscopy (SIM). While these methods have shown very promising results, they all rely on data-driven, supervised training strategies that need a large number of ground truth images, which is experimentally difficult to realize. For SIM imaging, there exists a need for a flexible, general, and open-source reconstruction method that can be readily adapted to different forms of structured illumination. We demonstrate that we can combine a deep neural network with the forward model of the structured illumination process to reconstruct sub-diffraction images without training data. The resulting physics-informed neural network (PINN) can be optimized on a single set of diffraction limited sub-images and thus doesn't require any training set. We show with simulated and experimental data that this PINN can be applied to a wide variety of SIM methods by simply changing the known illumination patterns used in the loss function and can achieve resolution improvements that match well with theoretical expectations.