 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Physics-Inspired Unsupervised Classification for Region of Interest in X-Ray Ptychography
Jun 29, 2022
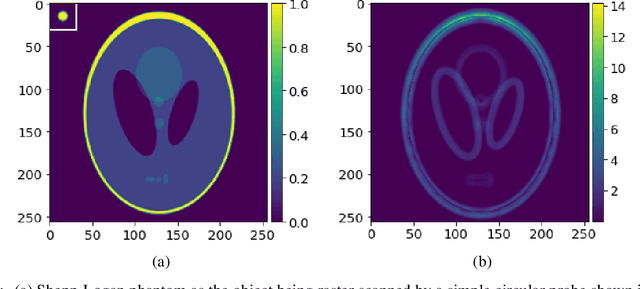
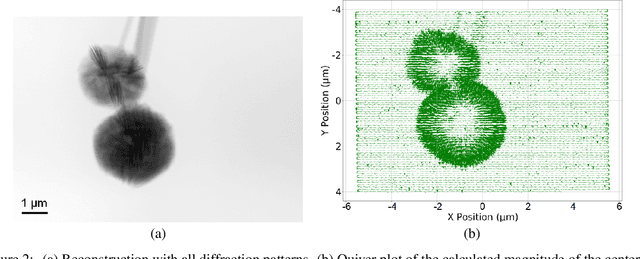
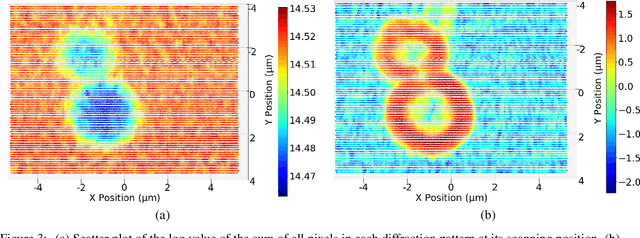
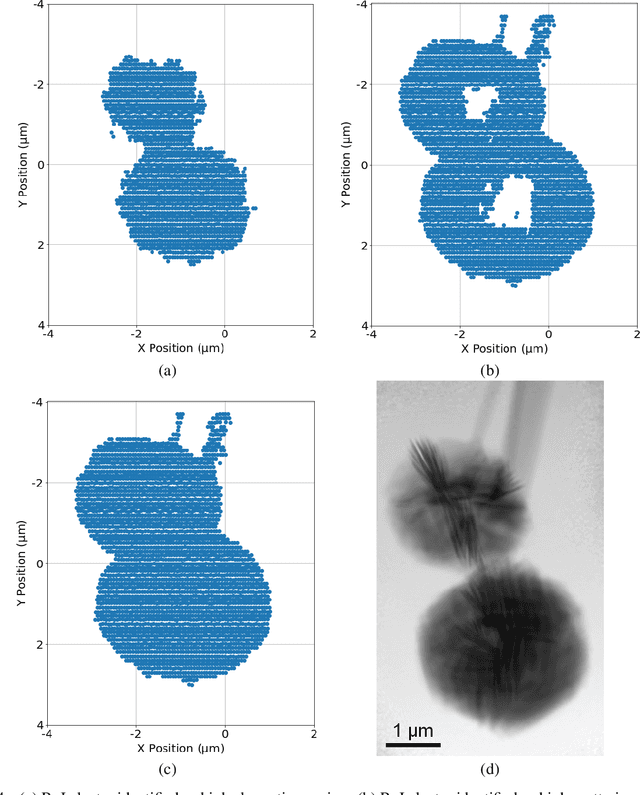
X-ray ptychography allows for large fields to be imaged at high resolution at the cost of additional computational expense due to the large volume of data. Given limited information regarding the object, the acquired data often has an excessive amount of information that is outside the region of interest (RoI). In this work we propose a physics-inspired unsupervised learning algorithm to identify the RoI of an object using only diffraction patterns from a ptychography dataset before committing computational resources to reconstruction. Obtained diffraction patterns that are automatically identified as not within the RoI are filtered out, allowing efficient reconstruction by focusing only on important data within the RoI while preserving image quality.
Knowledge Distillation for 6D Pose Estimation by Keypoint Distribution Alignment
May 30, 2022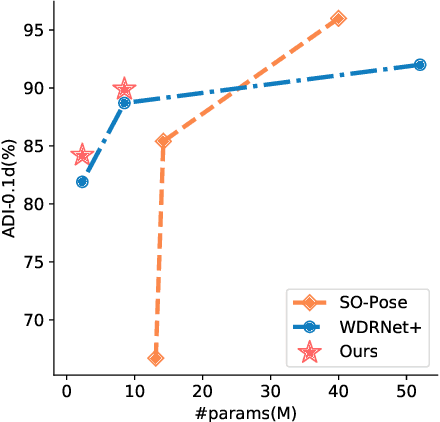
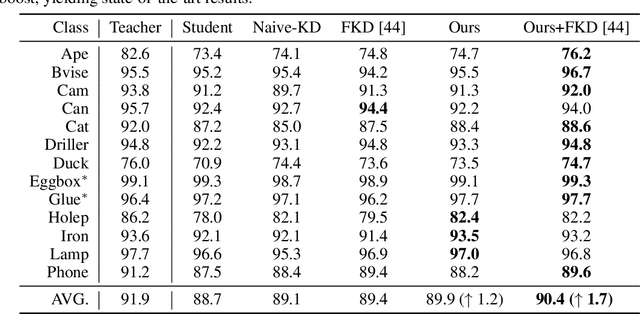

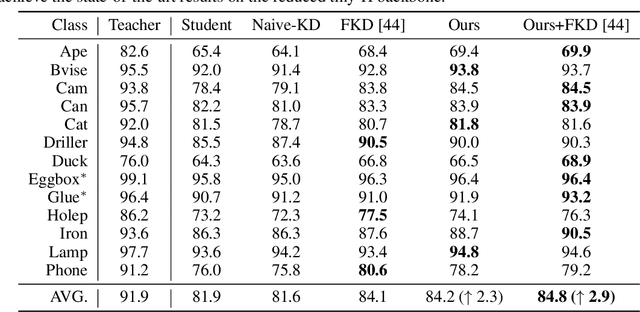
Knowledge distillation facilitates the training of a compact student network by using a deep teacher one. While this has achieved great success in many tasks, it remains completely unstudied for image-based 6D object pose estimation. In this work, we introduce the first knowledge distillation method for 6D pose estimation. Specifically, we follow a standard approach to 6D pose estimation, consisting of predicting the 2D image locations of object keypoints. In this context, we observe the compact student network to struggle predicting precise 2D keypoint locations. Therefore, to address this, instead of training the student with keypoint-to-keypoint supervision, we introduce a strategy based the optimal transport theory that distills the teacher's keypoint \emph{distribution} into the student network, facilitating its training. Our experiments on several benchmarks show that our distillation method yields state-of-the-art results with different compact student models.
Seed Classification using Synthetic Image Datasets Generated from Low-Altitude UAV Imagery
Oct 06, 2021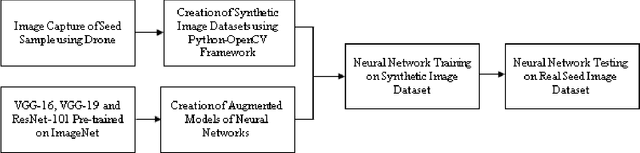
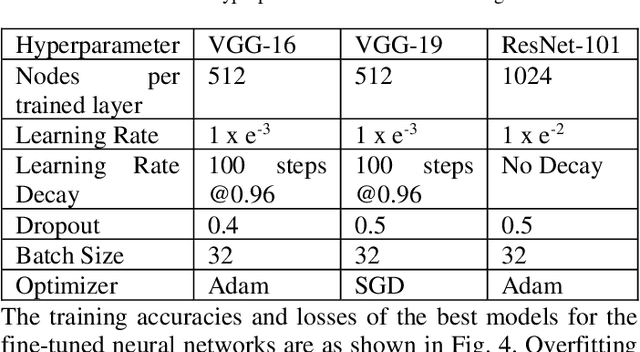

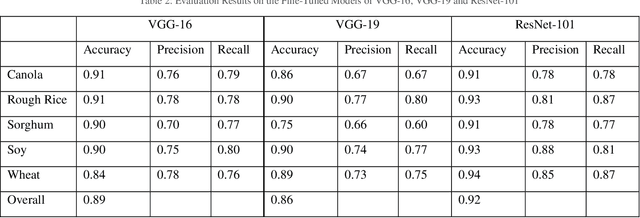
Plant breeding programs extensively monitor the evolution of seed kernels for seed certification, wherein lies the need to appropriately label the seed kernels by type and quality. However, the breeding environments are large where the monitoring of seed kernels can be challenging due to the minuscule size of seed kernels. The use of unmanned aerial vehicles aids in seed monitoring and labeling since they can capture images at low altitudes whilst being able to access even the remotest areas in the environment. A key bottleneck in the labeling of seeds using UAV imagery is drone altitude i.e. the classification accuracy decreases as the altitude increases due to lower image detail. Convolutional neural networks are a great tool for multi-class image classification when there is a training dataset that closely represents the different scenarios that the network might encounter during evaluation. The article addresses the challenge of training data creation using Domain Randomization wherein synthetic image datasets are generated from a meager sample of seeds captured by the bottom camera of an autonomously driven Parrot AR Drone 2.0. Besides, the article proposes a seed classification framework as a proof-of-concept using the convolutional neural networks of Microsoft's ResNet-100, Oxford's VGG-16, and VGG-19. To enhance the classification accuracy of the framework, an ensemble model is developed resulting in an overall accuracy of 94.6%.
Generalized Multi-Task Learning from Substantially Unlabeled Multi-Source Medical Image Data
Oct 25, 2021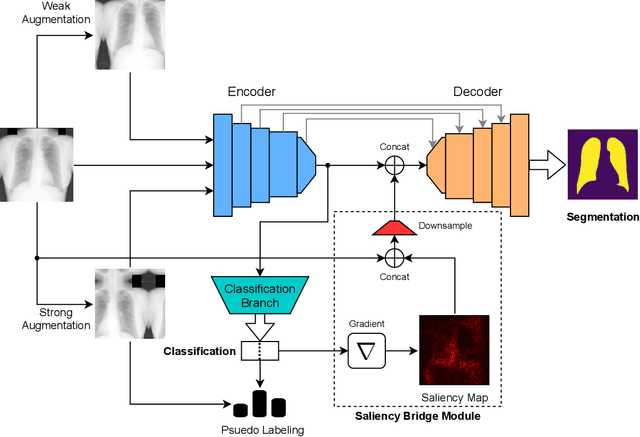
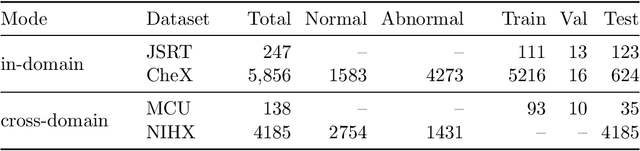
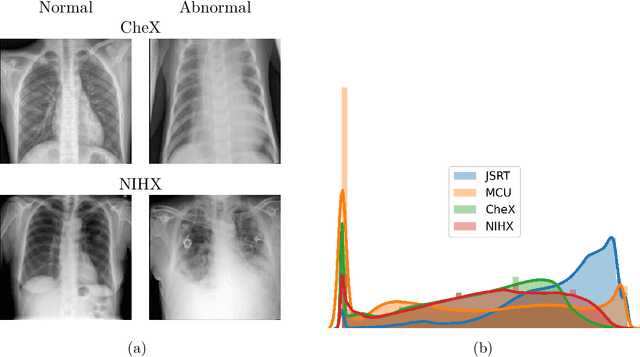
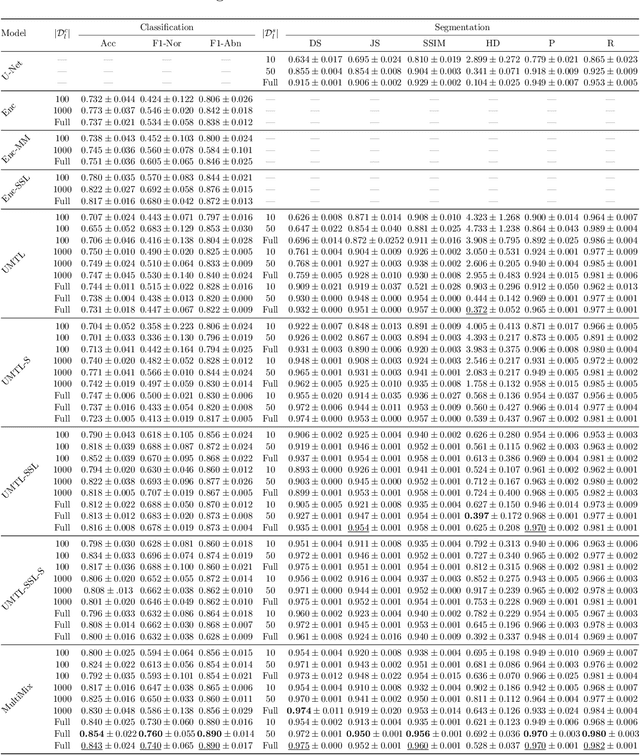
Deep learning-based models, when trained in a fully-supervised manner, can be effective in performing complex image analysis tasks, although contingent upon the availability of large labeled datasets. Especially in the medical imaging domain, however, expert image annotation is expensive, time-consuming, and prone to variability. Semi-supervised learning from limited quantities of labeled data has shown promise as an alternative. Maximizing knowledge gains from copious unlabeled data benefits semi-supervised learning models. Moreover, learning multiple tasks within the same model further improves its generalizability. We propose MultiMix, a new multi-task learning model that jointly learns disease classification and anatomical segmentation in a semi-supervised manner, while preserving explainability through a novel saliency bridge between the two tasks. Our experiments with varying quantities of multi-source labeled data in the training sets confirm the effectiveness of MultiMix in the simultaneous classification of pneumonia and segmentation of the lungs in chest X-ray images. Moreover, both in-domain and cross-domain evaluations across these tasks further showcase the potential of our model to adapt to challenging generalization scenarios.
Exploiting Domain Transferability for Collaborative Inter-level Domain Adaptive Object Detection
Jul 20, 2022
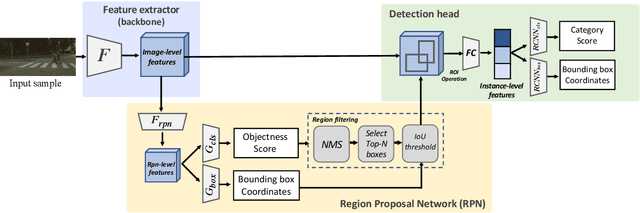
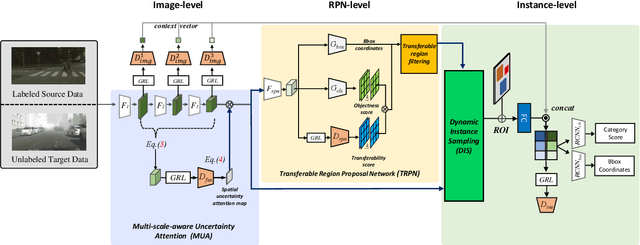
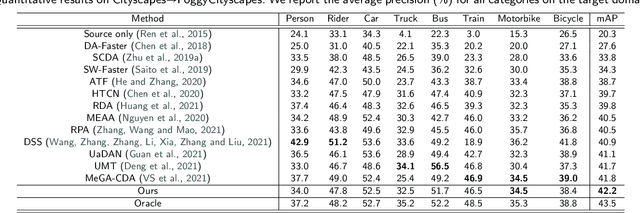
Domain adaptation for object detection (DAOD) has recently drawn much attention owing to its capability of detecting target objects without any annotations. To tackle the problem, previous works focus on aligning features extracted from partial levels (e.g., image-level, instance-level, RPN-level) in a two-stage detector via adversarial training. However, individual levels in the object detection pipeline are closely related to each other and this inter-level relation is unconsidered yet. To this end, we introduce a novel framework for DAOD with three proposed components: Multi-scale-aware Uncertainty Attention (MUA), Transferable Region Proposal Network (TRPN), and Dynamic Instance Sampling (DIS). With these modules, we seek to reduce the negative transfer effect during training while maximizing transferability as well as discriminability in both domains. Finally, our framework implicitly learns domain invariant regions for object detection via exploiting the transferable information and enhances the complementarity between different detection levels by collaboratively utilizing their domain information. Through ablation studies and experiments, we show that the proposed modules contribute to the performance improvement in a synergic way, demonstrating the effectiveness of our method. Moreover, our model achieves a new state-of-the-art performance on various benchmarks.
* Accepted to Expert Systems with Applications. The first three authors contributed equally
Two Souls in an Adversarial Image: Towards Universal Adversarial Example Detection using Multi-view Inconsistency
Oct 11, 2021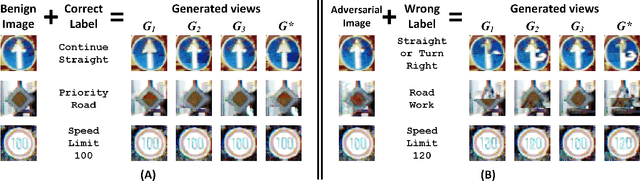
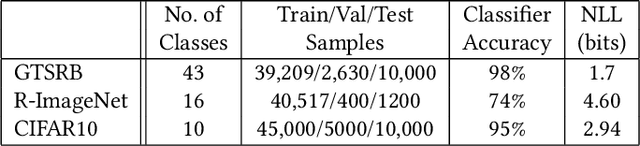
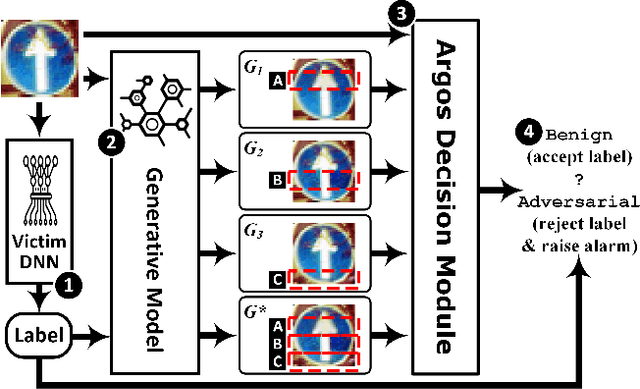
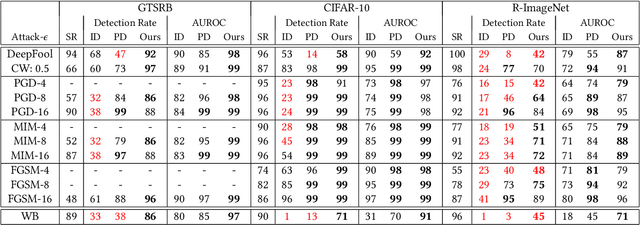
In the evasion attacks against deep neural networks (DNN), the attacker generates adversarial instances that are visually indistinguishable from benign samples and sends them to the target DNN to trigger misclassifications. In this paper, we propose a novel multi-view adversarial image detector, namely Argos, based on a novel observation. That is, there exist two "souls" in an adversarial instance, i.e., the visually unchanged content, which corresponds to the true label, and the added invisible perturbation, which corresponds to the misclassified label. Such inconsistencies could be further amplified through an autoregressive generative approach that generates images with seed pixels selected from the original image, a selected label, and pixel distributions learned from the training data. The generated images (i.e., the "views") will deviate significantly from the original one if the label is adversarial, demonstrating inconsistencies that Argos expects to detect. To this end, Argos first amplifies the discrepancies between the visual content of an image and its misclassified label induced by the attack using a set of regeneration mechanisms and then identifies an image as adversarial if the reproduced views deviate to a preset degree. Our experimental results show that Argos significantly outperforms two representative adversarial detectors in both detection accuracy and robustness against six well-known adversarial attacks. Code is available at: https://github.com/sohaib730/Argos-Adversarial_Detection
Online Knowledge Distillation via Mutual Contrastive Learning for Visual Recognition
Jul 23, 2022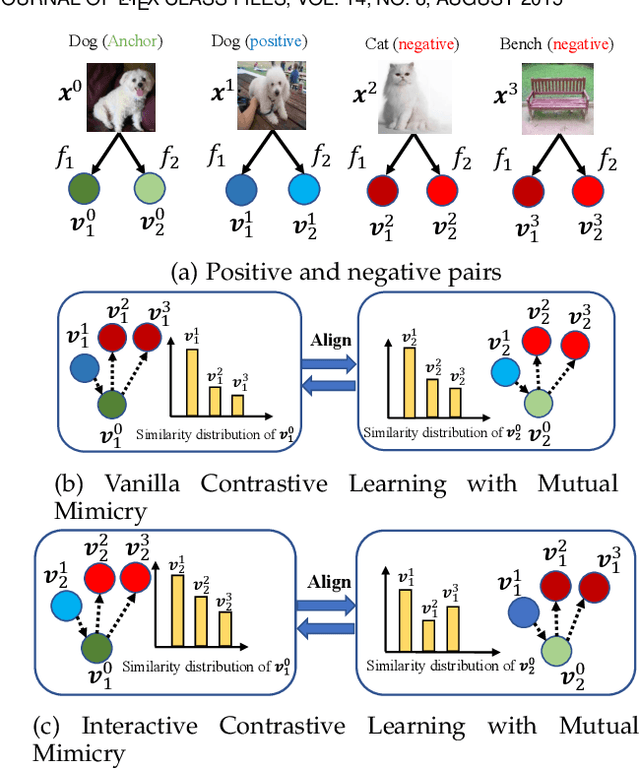

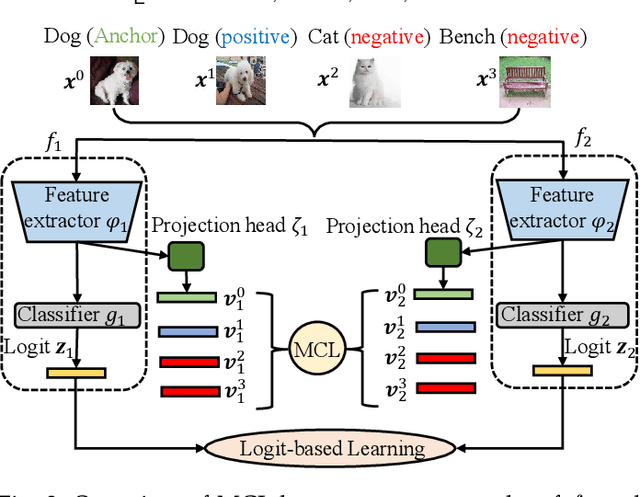
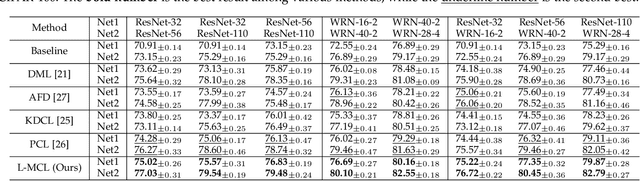
The teacher-free online Knowledge Distillation (KD) aims to train an ensemble of multiple student models collaboratively and distill knowledge from each other. Although existing online KD methods achieve desirable performance, they often focus on class probabilities as the core knowledge type, ignoring the valuable feature representational information. We present a Mutual Contrastive Learning (MCL) framework for online KD. The core idea of MCL is to perform mutual interaction and transfer of contrastive distributions among a cohort of networks in an online manner. Our MCL can aggregate cross-network embedding information and maximize the lower bound to the mutual information between two networks. This enables each network to learn extra contrastive knowledge from others, leading to better feature representations, thus improving the performance of visual recognition tasks. Beyond the final layer, we extend MCL to several intermediate layers assisted by auxiliary feature refinement modules. This further enhances the ability of representation learning for online KD. Experiments on image classification and transfer learning to visual recognition tasks show that MCL can lead to consistent performance gains against state-of-the-art online KD approaches. The superiority demonstrates that MCL can guide the network to generate better feature representations. Our code is publicly available at https://github.com/winycg/MCL.
Does deep learning model calibration improve performance in class-imbalanced medical image classification?
Oct 11, 2021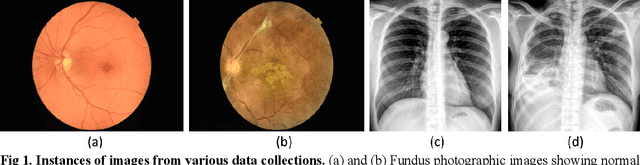
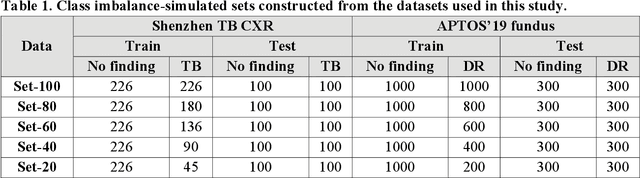
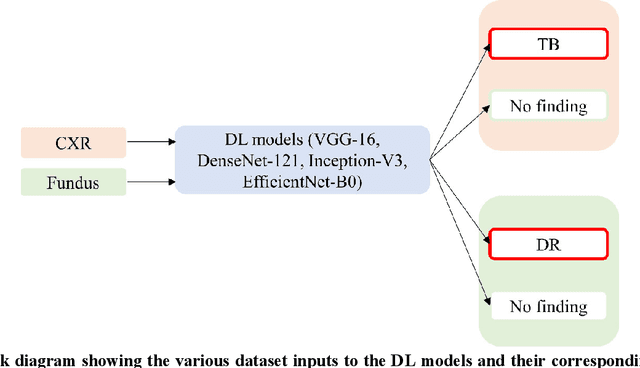
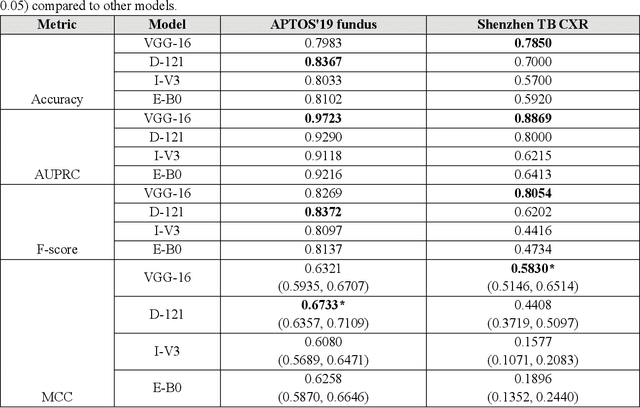
In medical image classification tasks, it is common to find that the number of normal samples far exceeds the number of abnormal samples. In such class-imbalanced situations, reliable training of deep neural networks continues to be a major challenge. Under these circumstances, the predicted class probabilities may be biased toward the majority class. Calibration has been suggested to alleviate some of these effects. However, there is insufficient analysis explaining when and whether calibrating a model would be beneficial in improving performance. In this study, we perform a systematic analysis of the effect of model calibration on its performance on two medical image modalities, namely, chest X-rays and fundus images, using various deep learning classifier backbones. For this, we study the following variations: (i) the degree of imbalances in the dataset used for training; (ii) calibration methods; and (iii) two classification thresholds, namely, default decision threshold of 0.5, and optimal threshold from precision-recall curves. Our results indicate that at the default operating threshold of 0.5, the performance achieved through calibration is significantly superior (p < 0.05) to using uncalibrated probabilities. However, at the PR-guided threshold, these gains are not significantly different (p > 0.05). This finding holds for both image modalities and at varying degrees of imbalance.
Regression Metric Loss: Learning a Semantic Representation Space for Medical Images
Jul 12, 2022
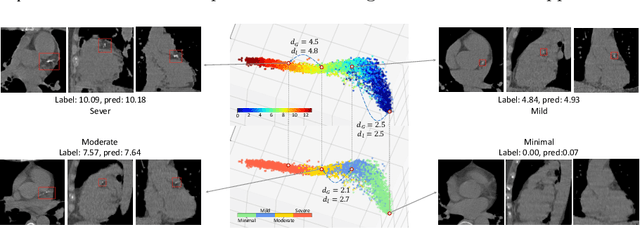
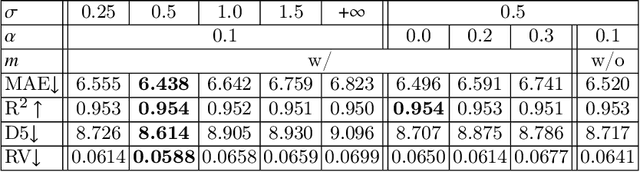
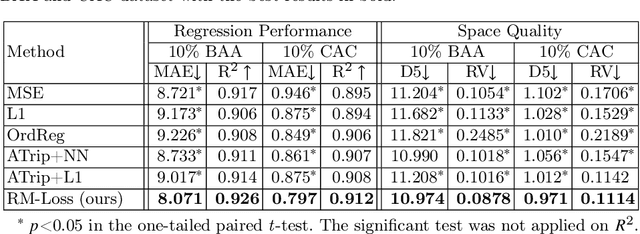
Regression plays an essential role in many medical imaging applications for estimating various clinical risk or measurement scores. While training strategies and loss functions have been studied for the deep neural networks in medical image classification tasks, options for regression tasks are very limited. One of the key challenges is that the high-dimensional feature representation learned by existing popular loss functions like Mean Squared Error or L1 loss is hard to interpret. In this paper, we propose a novel Regression Metric Loss (RM-Loss), which endows the representation space with the semantic meaning of the label space by finding a representation manifold that is isometric to the label space. Experiments on two regression tasks, i.e. coronary artery calcium score estimation and bone age assessment, show that RM-Loss is superior to the existing popular regression losses on both performance and interpretability. Code is available at https://github.com/DIAL-RPI/Regression-Metric-Loss.
DOLG: Single-Stage Image Retrieval with Deep Orthogonal Fusion of Local and Global Features
Aug 06, 2021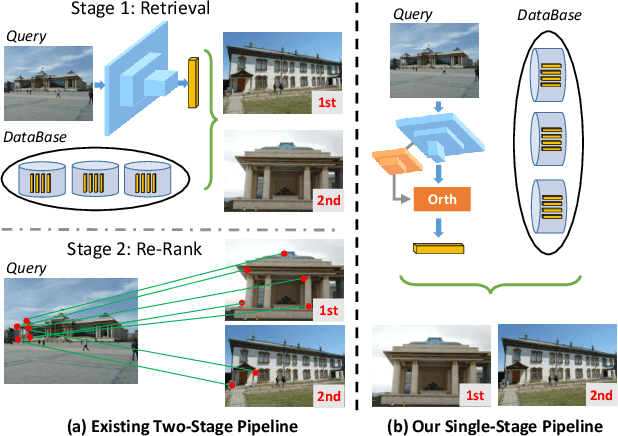
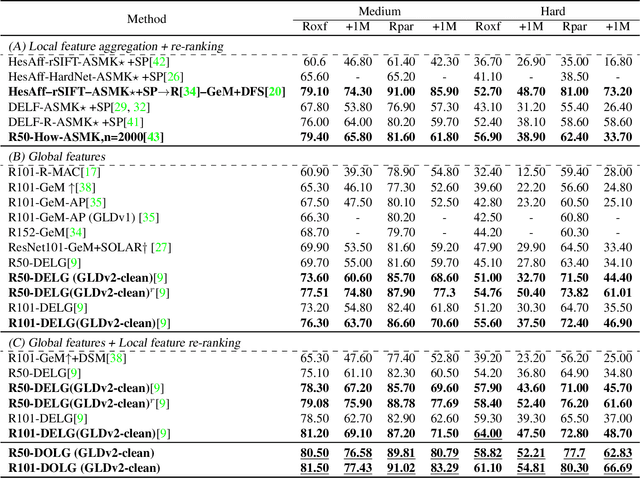
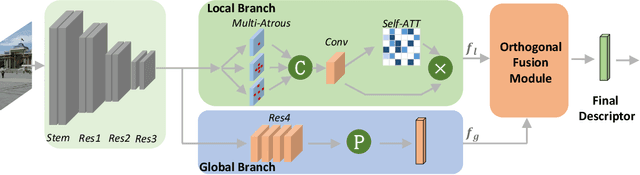
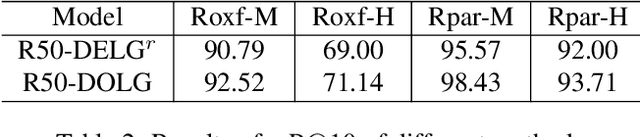
Image Retrieval is a fundamental task of obtaining images similar to the query one from a database. A common image retrieval practice is to firstly retrieve candidate images via similarity search using global image features and then re-rank the candidates by leveraging their local features. Previous learning-based studies mainly focus on either global or local image representation learning to tackle the retrieval task. In this paper, we abandon the two-stage paradigm and seek to design an effective single-stage solution by integrating local and global information inside images into compact image representations. Specifically, we propose a Deep Orthogonal Local and Global (DOLG) information fusion framework for end-to-end image retrieval. It attentively extracts representative local information with multi-atrous convolutions and self-attention at first. Components orthogonal to the global image representation are then extracted from the local information. At last, the orthogonal components are concatenated with the global representation as a complementary, and then aggregation is performed to generate the final representation. The whole framework is end-to-end differentiable and can be trained with image-level labels. Extensive experimental results validate the effectiveness of our solution and show that our model achieves state-of-the-art image retrieval performances on Revisited Oxford and Paris datasets.