 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Neglectable effect of brain MRI data prepreprocessing for tumor segmentation
Apr 11, 2022
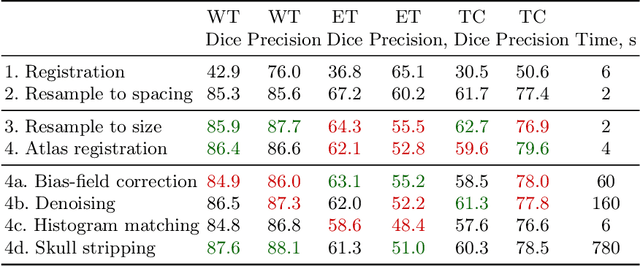
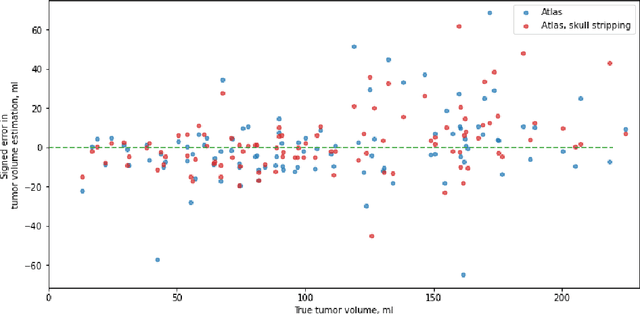

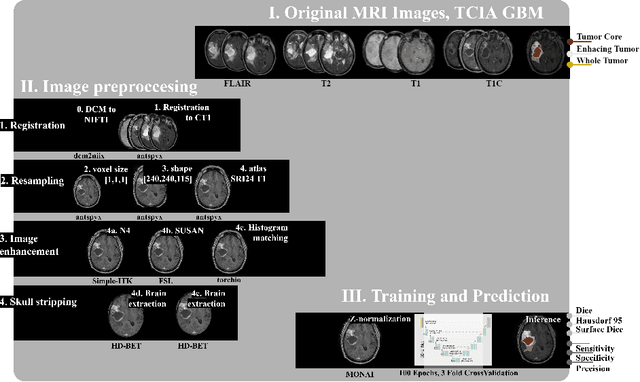
Magnetic resonance imaging (MRI) data is heterogeneous due to the differences in device manufacturers, scanning protocols, and inter-subject variability. A conventional way to mitigate MR image heterogeneity is to apply preprocessing transformations, such as anatomy alignment, voxel resampling, signal intensity equalization, image denoising, and localization of regions of interest (ROI). Although preprocessing pipeline standardizes image appearance, its influence on the quality of image segmentation and other downstream tasks on deep neural networks (DNN) has never been rigorously studied. Here we report a comprehensive study of multimodal MRI brain cancer image segmentation on TCIA-GBM open-source dataset. Our results demonstrate that most popular standardization steps add no value to artificial neural network performance; moreover, preprocessing can hamper model performance. We suggest that image intensity normalization approaches do not contribute to model accuracy because of the reduction of signal variance with image standardization. Finally, we show the contribution of scull-stripping in data preprocessing is almost negligible if measured in terms of clinically relevant metrics. We show that the only essential transformation for accurate analysis is the unification of voxel spacing across the dataset. In contrast, anatomy alignment in form of non-rigid atlas registration is not necessary and most intensity equalization steps do not improve model productiveness.
Untrained, physics-informed neural networks for structured illumination microscopy
Jul 15, 2022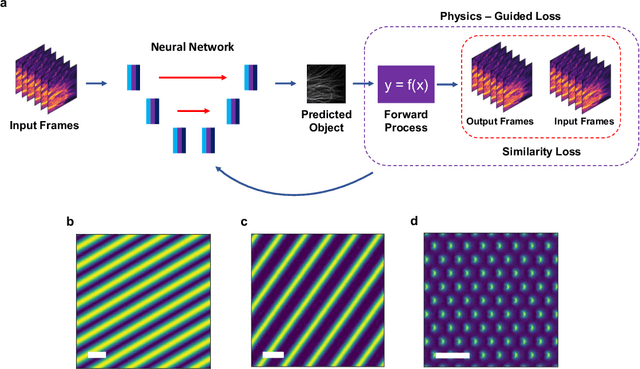
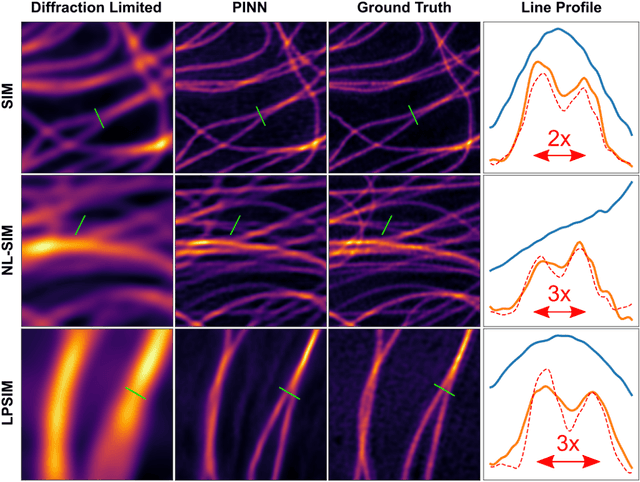

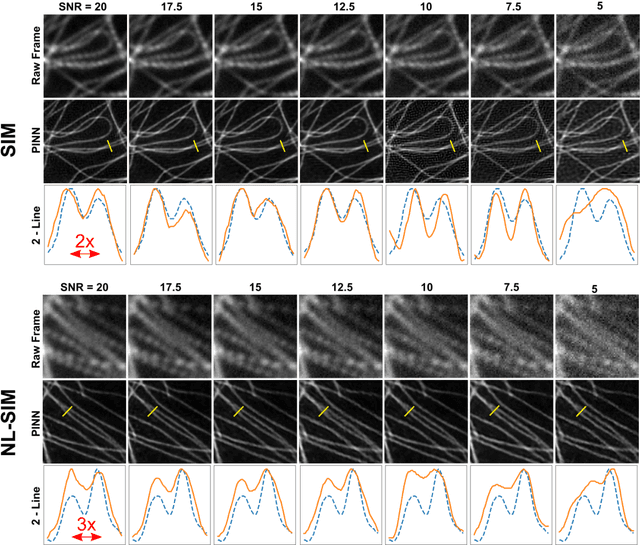
In recent years there has been great interest in using deep neural networks (DNN) for super-resolution image reconstruction including for structured illumination microscopy (SIM). While these methods have shown very promising results, they all rely on data-driven, supervised training strategies that need a large number of ground truth images, which is experimentally difficult to realize. For SIM imaging, there exists a need for a flexible, general, and open-source reconstruction method that can be readily adapted to different forms of structured illumination. We demonstrate that we can combine a deep neural network with the forward model of the structured illumination process to reconstruct sub-diffraction images without training data. The resulting physics-informed neural network (PINN) can be optimized on a single set of diffraction limited sub-images and thus doesn't require any training set. We show with simulated and experimental data that this PINN can be applied to a wide variety of SIM methods by simply changing the known illumination patterns used in the loss function and can achieve resolution improvements that match well with theoretical expectations.
TileGen: Tileable, Controllable Material Generation and Capture
Jun 20, 2022



Recent methods (e.g. MaterialGAN) have used unconditional GANs to generate per-pixel material maps, or as a prior to reconstruct materials from input photographs. These models can generate varied random material appearance, but do not have any mechanism to constrain the generated material to a specific category or to control the coarse structure of the generated material, such as the exact brick layout on a brick wall. Furthermore, materials reconstructed from a single input photo commonly have artifacts and are generally not tileable, which limits their use in practical content creation pipelines. We propose TileGen, a generative model for SVBRDFs that is specific to a material category, always tileable, and optionally conditional on a provided input structure pattern. TileGen is a variant of StyleGAN whose architecture is modified to always produce tileable (periodic) material maps. In addition to the standard "style" latent code, TileGen can optionally take a condition image, giving a user direct control over the dominant spatial (and optionally color) features of the material. For example, in brick materials, the user can specify a brick layout and the brick color, or in leather materials, the locations of wrinkles and folds. Our inverse rendering approach can find a material perceptually matching a single target photograph by optimization. This reconstruction can also be conditional on a user-provided pattern. The resulting materials are tileable, can be larger than the target image, and are editable by varying the condition.
Multimodal Open-Vocabulary Video Classification via Pre-Trained Vision and Language Models
Jul 15, 2022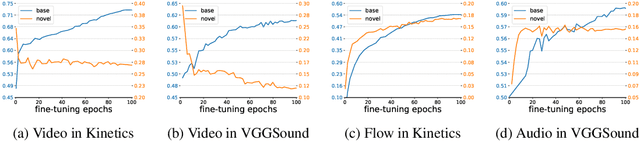
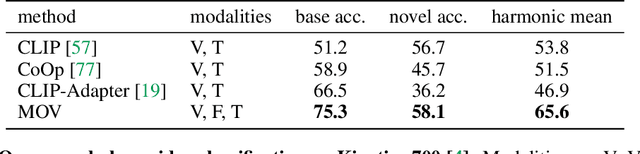
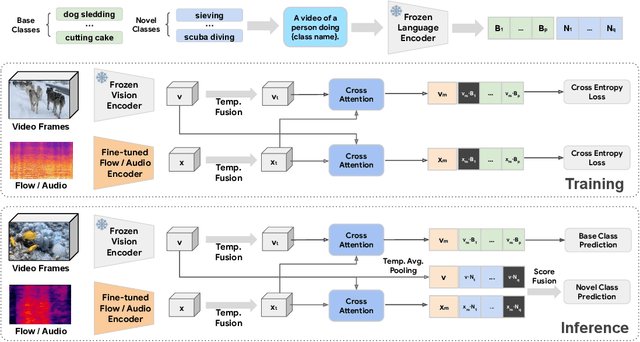
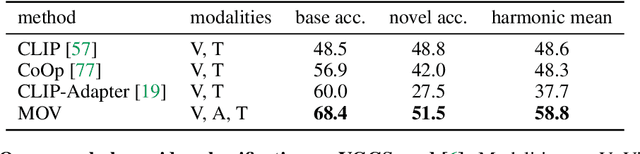
Utilizing vision and language models (VLMs) pre-trained on large-scale image-text pairs is becoming a promising paradigm for open-vocabulary visual recognition. In this work, we extend this paradigm by leveraging motion and audio that naturally exist in video. We present \textbf{MOV}, a simple yet effective method for \textbf{M}ultimodal \textbf{O}pen-\textbf{V}ocabulary video classification. In MOV, we directly use the vision encoder from pre-trained VLMs with minimal modifications to encode video, optical flow and audio spectrogram. We design a cross-modal fusion mechanism to aggregate complimentary multimodal information. Experiments on Kinetics-700 and VGGSound show that introducing flow or audio modality brings large performance gains over the pre-trained VLM and existing methods. Specifically, MOV greatly improves the accuracy on base classes, while generalizes better on novel classes. MOV achieves state-of-the-art results on UCF and HMDB zero-shot video classification benchmarks, significantly outperforming both traditional zero-shot methods and recent methods based on VLMs. Code and models will be released.
Accelerating Magnetic Resonance Parametric Mapping Using Simultaneously Spatial Patch-based and Parametric Group-based Low-rank Tensors (SMART)
Jul 19, 2022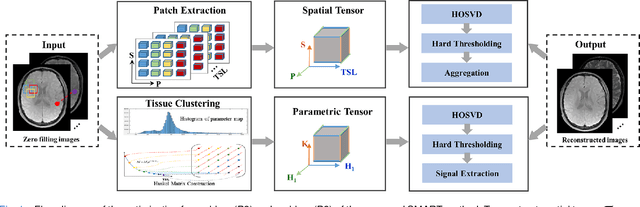
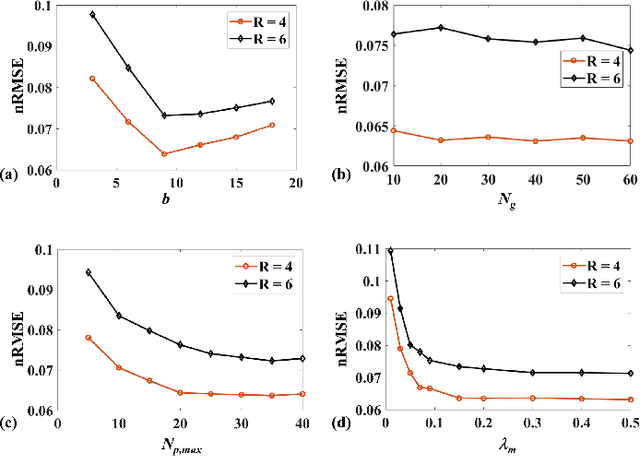
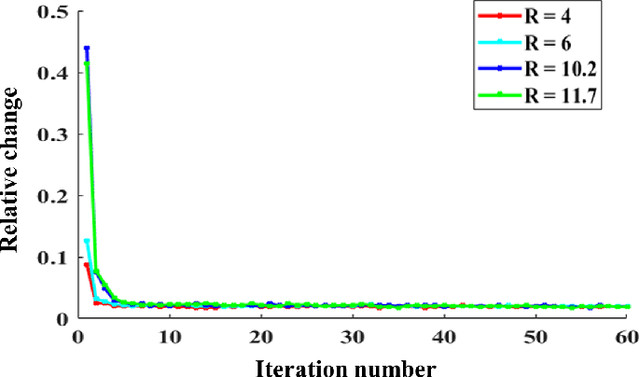
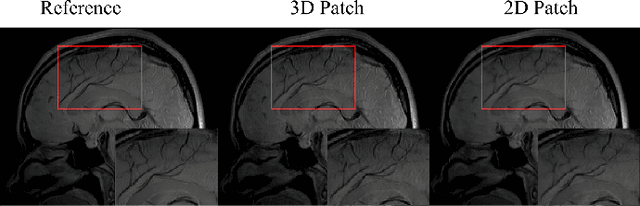
Quantitative magnetic resonance (MR) parametric mapping is a promising approach for characterizing intrinsic tissue-dependent information. However, long scan time significantly hinders its widespread applications. Recently, low-rank tensor has been employed and demonstrated good performance in accelerating MR parametricmapping. In this study, we propose a novel method that uses spatial patch-based and parametric group-based low rank tensors simultaneously (SMART) to reconstruct images from highly undersampled k-space data. The spatial patch-based low-rank tensor exploits the high local and nonlocal redundancies and similarities between the contrast images in parametric mapping. The parametric group based low-rank tensor, which integrates similar exponential behavior of the image signals, is jointly used to enforce the multidimensional low-rankness in the reconstruction process. In vivo brain datasets were used to demonstrate the validity of the proposed method. Experimental results have demonstrated that the proposed method achieves 11.7-fold and 13.21-fold accelerations in two-dimensional and three-dimensional acquisitions, respectively, with more accurate reconstructed images and maps than several state-of-the-art methods. Prospective reconstruction results further demonstrate the capability of the SMART method in accelerating MR quantitative imaging.
Class-Difficulty Based Methods for Long-Tailed Visual Recognition
Jul 29, 2022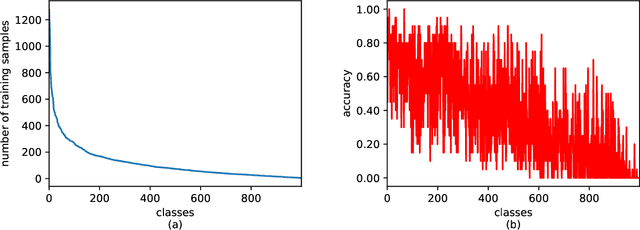
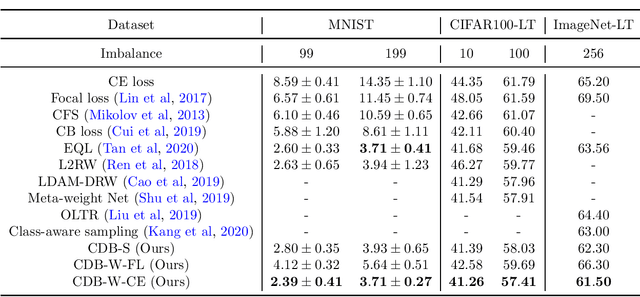
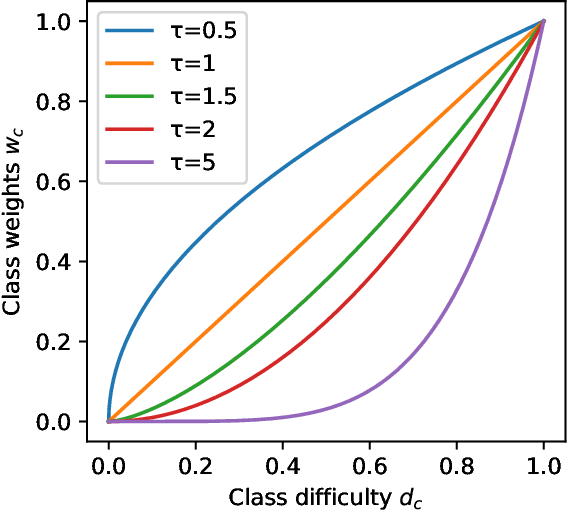
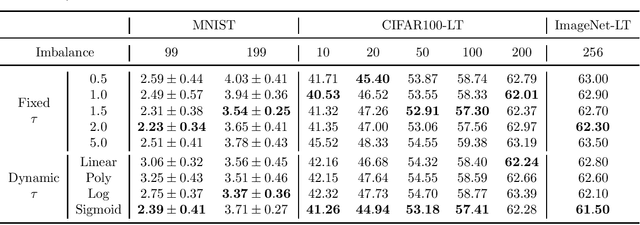
Long-tailed datasets are very frequently encountered in real-world use cases where few classes or categories (known as majority or head classes) have higher number of data samples compared to the other classes (known as minority or tail classes). Training deep neural networks on such datasets gives results biased towards the head classes. So far, researchers have come up with multiple weighted loss and data re-sampling techniques in efforts to reduce the bias. However, most of such techniques assume that the tail classes are always the most difficult classes to learn and therefore need more weightage or attention. Here, we argue that the assumption might not always hold true. Therefore, we propose a novel approach to dynamically measure the instantaneous difficulty of each class during the training phase of the model. Further, we use the difficulty measures of each class to design a novel weighted loss technique called `class-wise difficulty based weighted (CDB-W) loss' and a novel data sampling technique called `class-wise difficulty based sampling (CDB-S)'. To verify the wide-scale usability of our CDB methods, we conducted extensive experiments on multiple tasks such as image classification, object detection, instance segmentation and video-action classification. Results verified that CDB-W loss and CDB-S could achieve state-of-the-art results on many class-imbalanced datasets such as ImageNet-LT, LVIS and EGTEA, that resemble real-world use cases.
MaskOCR: Text Recognition with Masked Encoder-Decoder Pretraining
Jun 01, 2022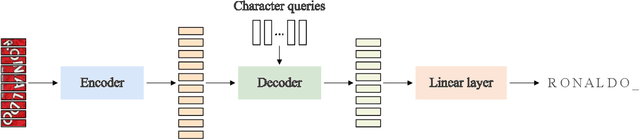


In this paper, we present a model pretraining technique, named MaskOCR, for text recognition. Our text recognition architecture is an encoder-decoder transformer: the encoder extracts the patch-level representations, and the decoder recognizes the text from the representations. Our approach pretrains both the encoder and the decoder in a sequential manner. (i) We pretrain the encoder in a self-supervised manner over a large set of unlabeled real text images. We adopt the masked image modeling approach, which shows the effectiveness for general images, expecting that the representations take on semantics. (ii) We pretrain the decoder over a large set of synthesized text images in a supervised manner and enhance the language modeling capability of the decoder by randomly masking some text image patches occupied by characters input to the encoder and accordingly the representations input to the decoder. Experiments show that the proposed MaskOCR approach achieves superior results on the benchmark datasets, including Chinese and English text images.
Supervised laser-speckle image sampling of skin tissue to detect very early stage of diabetes by its effects on skin subcellular properties
Dec 18, 2021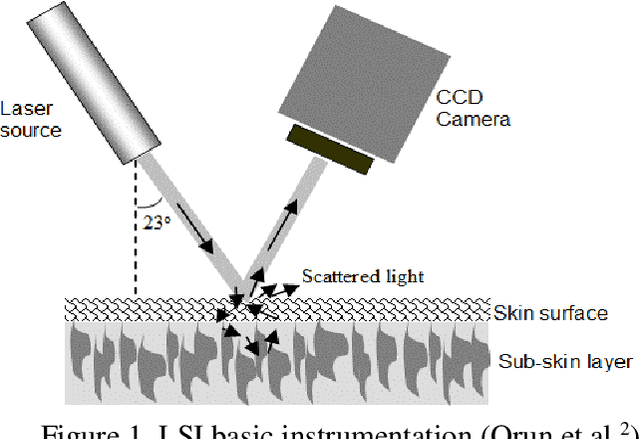
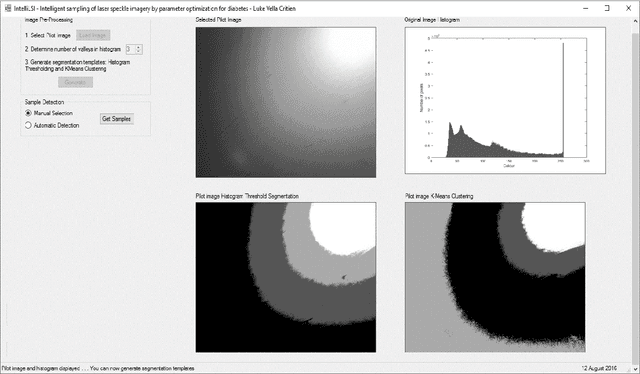
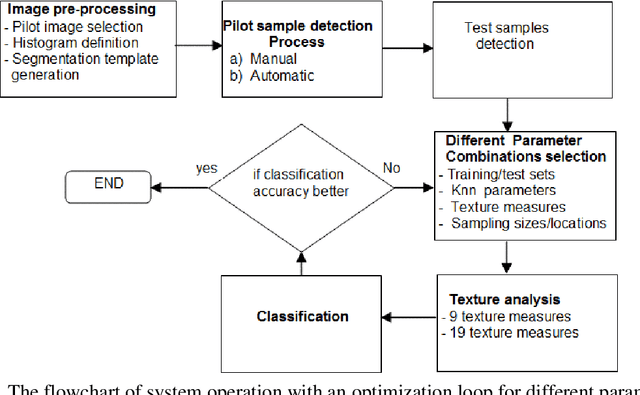
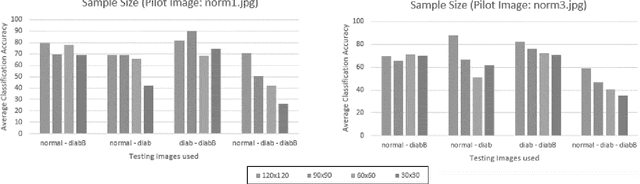
This paper investigates the effectiveness of an expert system based on K-nearest neighbors algorithm for laser speckle image sampling applied to the early detection of diabetes. With the latest developments in artificial intelligent guided laser speckle imaging technologies, it may be possible to optimise laser parameters, such as wavelength, energy level and image texture measures in association with a suitable AI technique to interact effectively with the subcellular properties of a skin tissue to detect early signs of diabetes. The new approach is potentially more effective than the classical skin glucose level observation because of its optimised combination of laser physics and AI techniques, and additionally, it allows non-expert individuals to perform more frequent skin tissue tests for an early detection of diabetes.
Thermal Image Processing via Physics-Inspired Deep Networks
Aug 25, 2021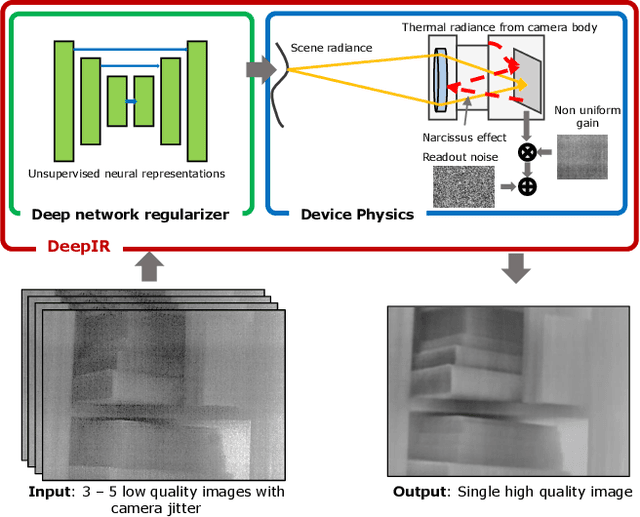



We introduce DeepIR, a new thermal image processing framework that combines physically accurate sensor modeling with deep network-based image representation. Our key enabling observations are that the images captured by thermal sensors can be factored into slowly changing, scene-independent sensor non-uniformities (that can be accurately modeled using physics) and a scene-specific radiance flux (that is well-represented using a deep network-based regularizer). DeepIR requires neither training data nor periodic ground-truth calibration with a known black body target--making it well suited for practical computer vision tasks. We demonstrate the power of going DeepIR by developing new denoising and super-resolution algorithms that exploit multiple images of the scene captured with camera jitter. Simulated and real data experiments demonstrate that DeepIR can perform high-quality non-uniformity correction with as few as three images, achieving a 10dB PSNR improvement over competing approaches.
LaneSNNs: Spiking Neural Networks for Lane Detection on the Loihi Neuromorphic Processor
Aug 03, 2022

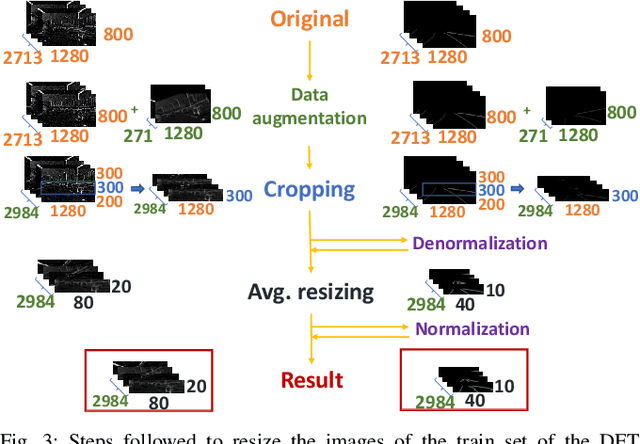
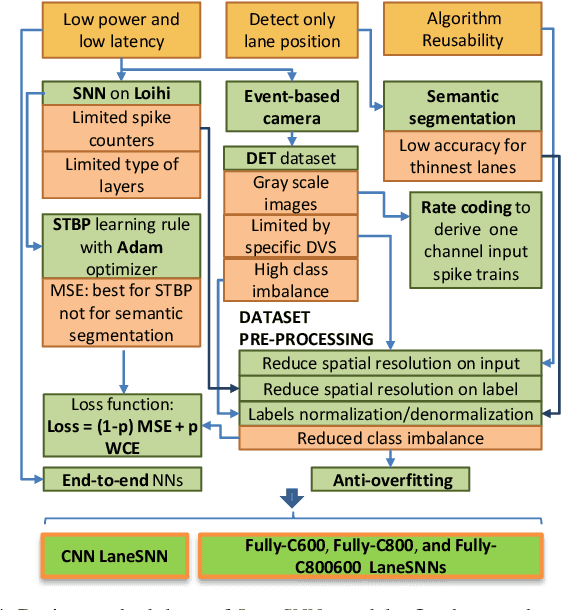
Autonomous Driving (AD) related features represent important elements for the next generation of mobile robots and autonomous vehicles focused on increasingly intelligent, autonomous, and interconnected systems. The applications involving the use of these features must provide, by definition, real-time decisions, and this property is key to avoid catastrophic accidents. Moreover, all the decision processes must require low power consumption, to increase the lifetime and autonomy of battery-driven systems. These challenges can be addressed through efficient implementations of Spiking Neural Networks (SNNs) on Neuromorphic Chips and the use of event-based cameras instead of traditional frame-based cameras. In this paper, we present a new SNN-based approach, called LaneSNN, for detecting the lanes marked on the streets using the event-based camera input. We develop four novel SNN models characterized by low complexity and fast response, and train them using an offline supervised learning rule. Afterward, we implement and map the learned SNNs models onto the Intel Loihi Neuromorphic Research Chip. For the loss function, we develop a novel method based on the linear composition of Weighted binary Cross Entropy (WCE) and Mean Squared Error (MSE) measures. Our experimental results show a maximum Intersection over Union (IoU) measure of about 0.62 and very low power consumption of about 1 W. The best IoU is achieved with an SNN implementation that occupies only 36 neurocores on the Loihi processor while providing a low latency of less than 8 ms to recognize an image, thereby enabling real-time performance. The IoU measures provided by our networks are comparable with the state-of-the-art, but at a much low power consumption of 1 W.