 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semi-supervised Contrastive Learning for Label-efficient Medical Image Segmentation
Sep 15, 2021
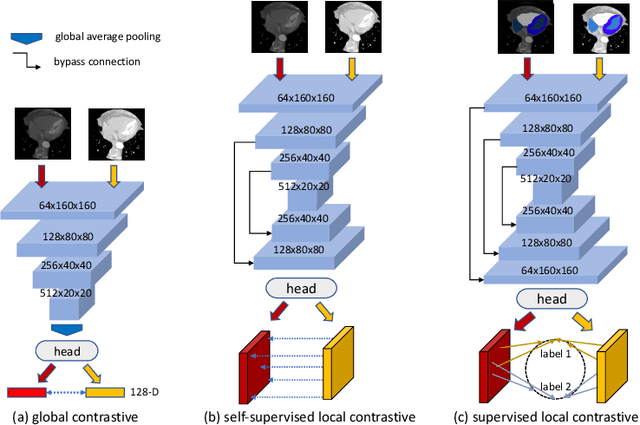
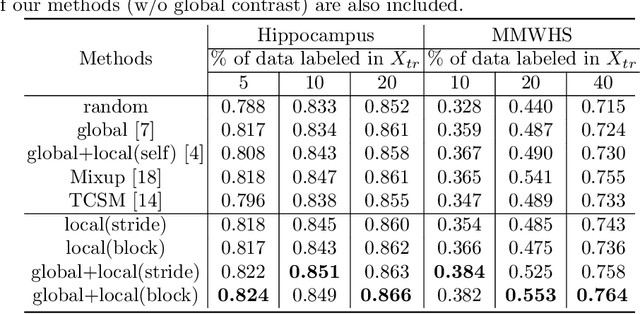
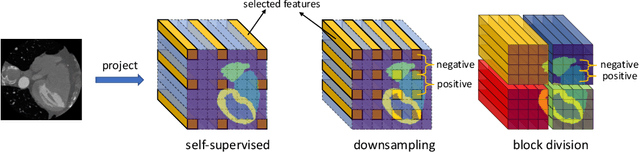
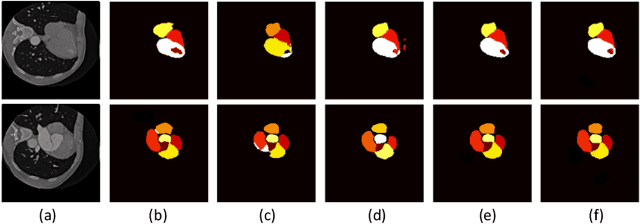
The success of deep learning methods in medical image segmentation tasks heavily depends on a large amount of labeled data to supervise the training. On the other hand, the annotation of biomedical images requires domain knowledge and can be laborious. Recently, contrastive learning has demonstrated great potential in learning latent representation of images even without any label. Existing works have explored its application to biomedical image segmentation where only a small portion of data is labeled, through a pre-training phase based on self-supervised contrastive learning without using any labels followed by a supervised fine-tuning phase on the labeled portion of data only. In this paper, we establish that by including the limited label in formation in the pre-training phase, it is possible to boost the performance of contrastive learning. We propose a supervised local contrastive loss that leverages limited pixel-wise annotation to force pixels with the same label to gather around in the embedding space. Such loss needs pixel-wise computation which can be expensive for large images, and we further propose two strategies, downsampling and block division, to address the issue. We evaluate our methods on two public biomedical image datasets of different modalities. With different amounts of labeled data, our methods consistently outperform the state-of-the-art contrast-based methods and other semi-supervised learning techniques.
Barbershop: GAN-based Image Compositing using Segmentation Masks
Jun 02, 2021
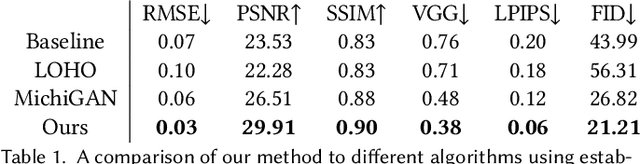
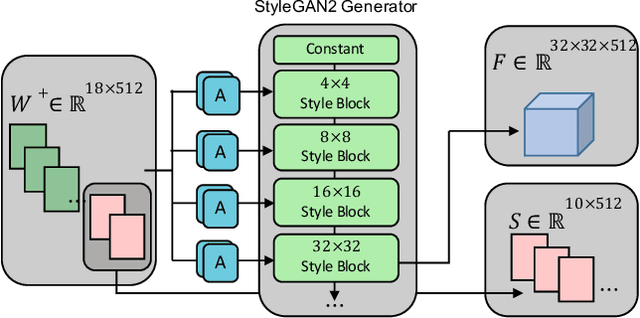

Seamlessly blending features from multiple images is extremely challenging because of complex relationships in lighting, geometry, and partial occlusion which cause coupling between different parts of the image. Even though recent work on GANs enables synthesis of realistic hair or faces, it remains difficult to combine them into a single, coherent, and plausible image rather than a disjointed set of image patches. We present a novel solution to image blending, particularly for the problem of hairstyle transfer, based on GAN-inversion. We propose a novel latent space for image blending which is better at preserving detail and encoding spatial information, and propose a new GAN-embedding algorithm which is able to slightly modify images to conform to a common segmentation mask. Our novel representation enables the transfer of the visual properties from multiple reference images including specific details such as moles and wrinkles, and because we do image blending in a latent-space we are able to synthesize images that are coherent. Our approach avoids blending artifacts present in other approaches and finds a globally consistent image. Our results demonstrate a significant improvement over the current state of the art in a user study, with users preferring our blending solution over 95 percent of the time.
Image Quality Assessment in the Modern Age
Oct 19, 2021This tutorial provides the audience with the basic theories, methodologies, and current progresses of image quality assessment (IQA). From an actionable perspective, we will first revisit several subjective quality assessment methodologies, with emphasis on how to properly select visual stimuli. We will then present in detail the design principles of objective quality assessment models, supplemented by an in-depth analysis of their advantages and disadvantages. Both hand-engineered and (deep) learning-based methods will be covered. Moreover, the limitations with the conventional model comparison methodology for objective quality models will be pointed out, and novel comparison methodologies such as those based on the theory of "analysis by synthesis" will be introduced. We will last discuss the real-world multimedia applications of IQA, and give a list of open challenging problems, in the hope of encouraging more and more talented researchers and engineers devoting to this exciting and rewarding research field.
Class-Difficulty Based Methods for Long-Tailed Visual Recognition
Jul 29, 2022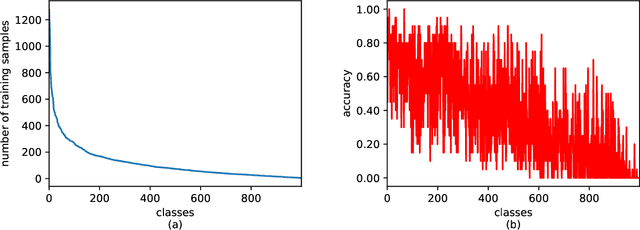
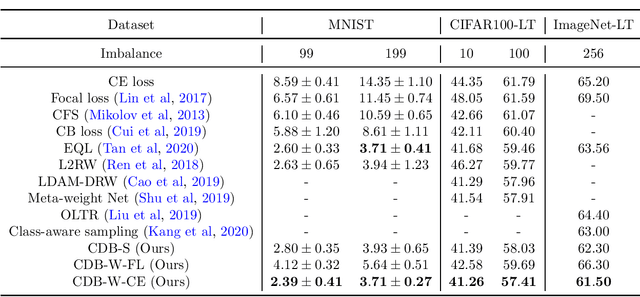
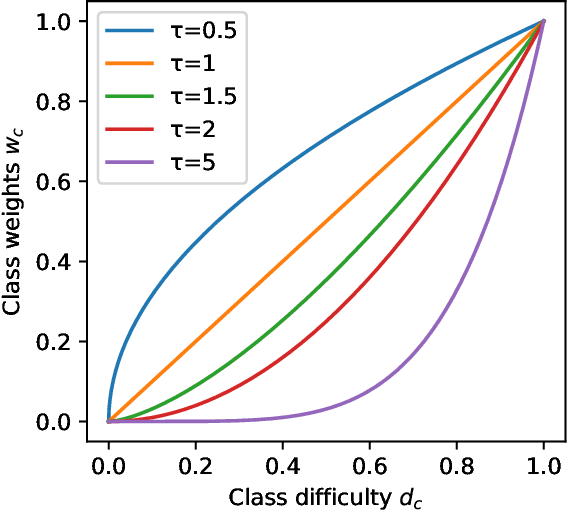
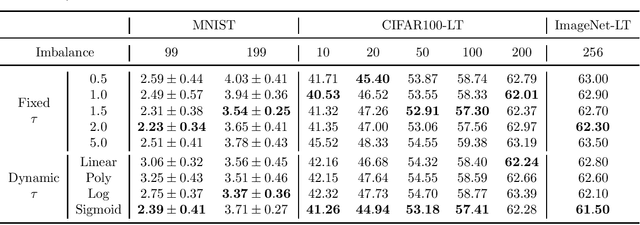
Long-tailed datasets are very frequently encountered in real-world use cases where few classes or categories (known as majority or head classes) have higher number of data samples compared to the other classes (known as minority or tail classes). Training deep neural networks on such datasets gives results biased towards the head classes. So far, researchers have come up with multiple weighted loss and data re-sampling techniques in efforts to reduce the bias. However, most of such techniques assume that the tail classes are always the most difficult classes to learn and therefore need more weightage or attention. Here, we argue that the assumption might not always hold true. Therefore, we propose a novel approach to dynamically measure the instantaneous difficulty of each class during the training phase of the model. Further, we use the difficulty measures of each class to design a novel weighted loss technique called `class-wise difficulty based weighted (CDB-W) loss' and a novel data sampling technique called `class-wise difficulty based sampling (CDB-S)'. To verify the wide-scale usability of our CDB methods, we conducted extensive experiments on multiple tasks such as image classification, object detection, instance segmentation and video-action classification. Results verified that CDB-W loss and CDB-S could achieve state-of-the-art results on many class-imbalanced datasets such as ImageNet-LT, LVIS and EGTEA, that resemble real-world use cases.
LaneSNNs: Spiking Neural Networks for Lane Detection on the Loihi Neuromorphic Processor
Aug 03, 2022

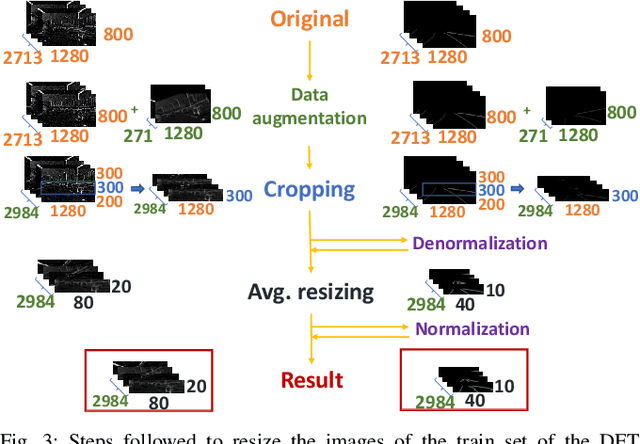
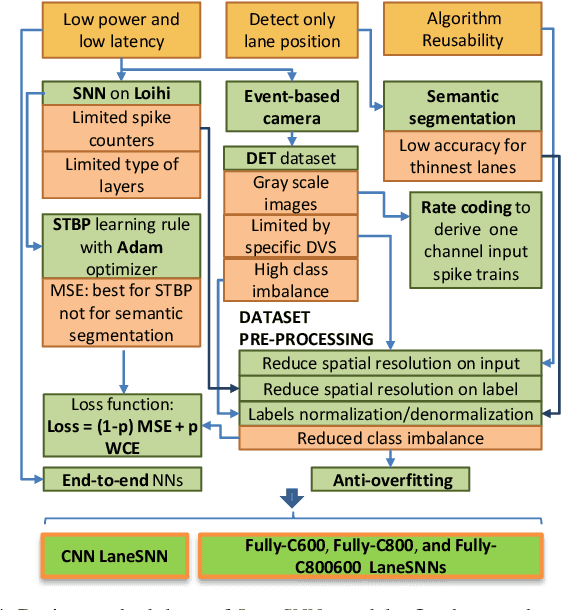
Autonomous Driving (AD) related features represent important elements for the next generation of mobile robots and autonomous vehicles focused on increasingly intelligent, autonomous, and interconnected systems. The applications involving the use of these features must provide, by definition, real-time decisions, and this property is key to avoid catastrophic accidents. Moreover, all the decision processes must require low power consumption, to increase the lifetime and autonomy of battery-driven systems. These challenges can be addressed through efficient implementations of Spiking Neural Networks (SNNs) on Neuromorphic Chips and the use of event-based cameras instead of traditional frame-based cameras. In this paper, we present a new SNN-based approach, called LaneSNN, for detecting the lanes marked on the streets using the event-based camera input. We develop four novel SNN models characterized by low complexity and fast response, and train them using an offline supervised learning rule. Afterward, we implement and map the learned SNNs models onto the Intel Loihi Neuromorphic Research Chip. For the loss function, we develop a novel method based on the linear composition of Weighted binary Cross Entropy (WCE) and Mean Squared Error (MSE) measures. Our experimental results show a maximum Intersection over Union (IoU) measure of about 0.62 and very low power consumption of about 1 W. The best IoU is achieved with an SNN implementation that occupies only 36 neurocores on the Loihi processor while providing a low latency of less than 8 ms to recognize an image, thereby enabling real-time performance. The IoU measures provided by our networks are comparable with the state-of-the-art, but at a much low power consumption of 1 W.
Audio-visual scene classification via contrastive event-object alignment and semantic-based fusion
Aug 03, 2022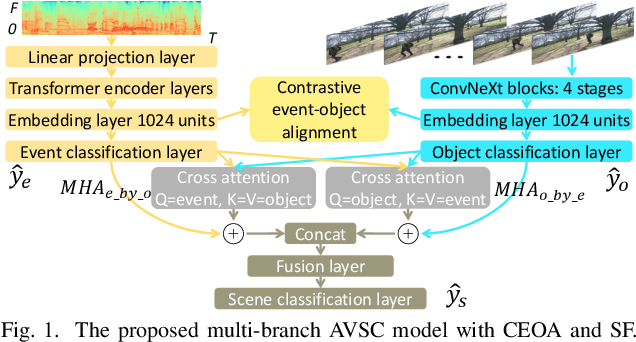

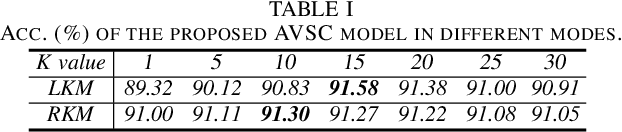
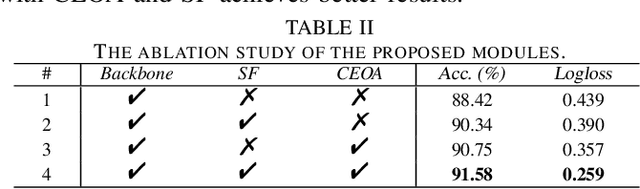
Previous works on scene classification are mainly based on audio or visual signals, while humans perceive the environmental scenes through multiple senses. Recent studies on audio-visual scene classification separately fine-tune the largescale audio and image pre-trained models on the target dataset, then either fuse the intermediate representations of the audio model and the visual model, or fuse the coarse-grained decision of both models at the clip level. Such methods ignore the detailed audio events and visual objects in audio-visual scenes (AVS), while humans often identify different scenes through audio events and visual objects within and the congruence between them. To exploit the fine-grained information of audio events and visual objects in AVS, and coordinate the implicit relationship between audio events and visual objects, this paper proposes a multibranch model equipped with contrastive event-object alignment (CEOA) and semantic-based fusion (SF) for AVSC. CEOA aims to align the learned embeddings of audio events and visual objects by comparing the difference between audio-visual event-object pairs. Then, visual objects associated with certain audio events and vice versa are accentuated by cross-attention and undergo SF for semantic-level fusion. Experiments show that: 1) the proposed AVSC model equipped with CEOA and SF outperforms the results of audio-only and visual-only models, i.e., the audio-visual results are better than the results from a single modality. 2) CEOA aligns the embeddings of audio events and related visual objects on a fine-grained level, and the SF effectively integrates both; 3) Compared with other large-scale integrated systems, the proposed model shows competitive performance, even without using additional datasets and data augmentation tricks.
Untrained, physics-informed neural networks for structured illumination microscopy
Jul 15, 2022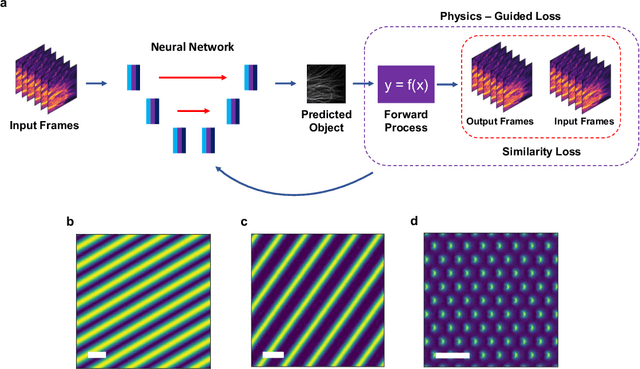
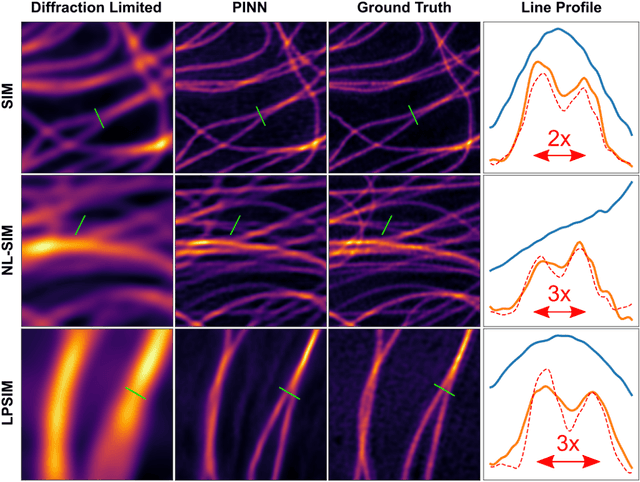

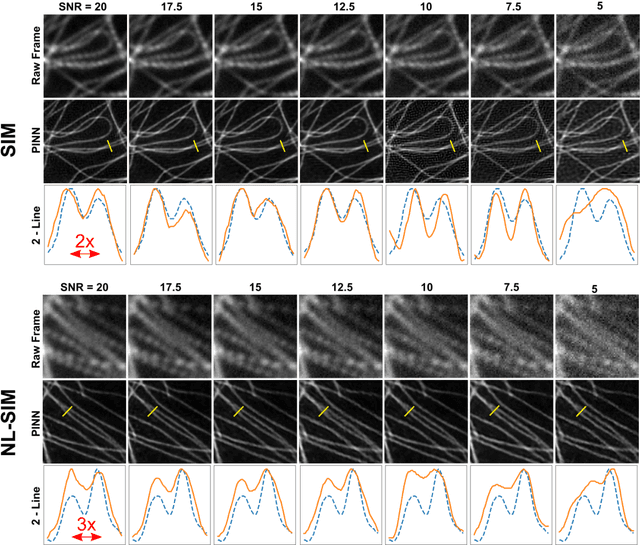
In recent years there has been great interest in using deep neural networks (DNN) for super-resolution image reconstruction including for structured illumination microscopy (SIM). While these methods have shown very promising results, they all rely on data-driven, supervised training strategies that need a large number of ground truth images, which is experimentally difficult to realize. For SIM imaging, there exists a need for a flexible, general, and open-source reconstruction method that can be readily adapted to different forms of structured illumination. We demonstrate that we can combine a deep neural network with the forward model of the structured illumination process to reconstruct sub-diffraction images without training data. The resulting physics-informed neural network (PINN) can be optimized on a single set of diffraction limited sub-images and thus doesn't require any training set. We show with simulated and experimental data that this PINN can be applied to a wide variety of SIM methods by simply changing the known illumination patterns used in the loss function and can achieve resolution improvements that match well with theoretical expectations.
Accelerating Magnetic Resonance Parametric Mapping Using Simultaneously Spatial Patch-based and Parametric Group-based Low-rank Tensors (SMART)
Jul 19, 2022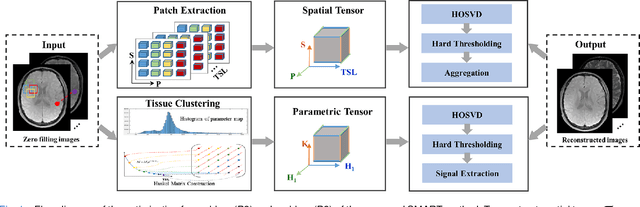
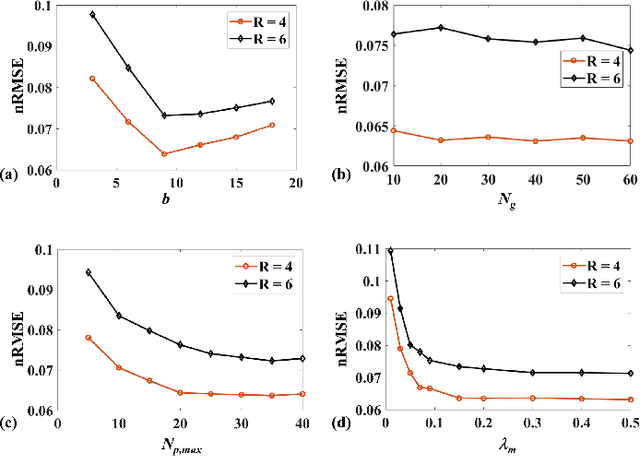
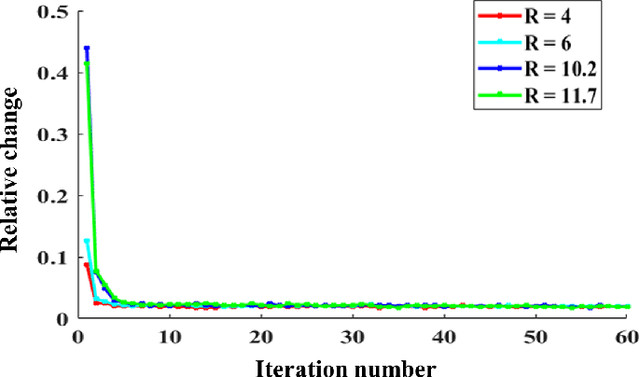
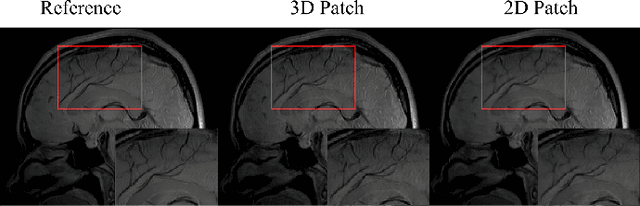
Quantitative magnetic resonance (MR) parametric mapping is a promising approach for characterizing intrinsic tissue-dependent information. However, long scan time significantly hinders its widespread applications. Recently, low-rank tensor has been employed and demonstrated good performance in accelerating MR parametricmapping. In this study, we propose a novel method that uses spatial patch-based and parametric group-based low rank tensors simultaneously (SMART) to reconstruct images from highly undersampled k-space data. The spatial patch-based low-rank tensor exploits the high local and nonlocal redundancies and similarities between the contrast images in parametric mapping. The parametric group based low-rank tensor, which integrates similar exponential behavior of the image signals, is jointly used to enforce the multidimensional low-rankness in the reconstruction process. In vivo brain datasets were used to demonstrate the validity of the proposed method. Experimental results have demonstrated that the proposed method achieves 11.7-fold and 13.21-fold accelerations in two-dimensional and three-dimensional acquisitions, respectively, with more accurate reconstructed images and maps than several state-of-the-art methods. Prospective reconstruction results further demonstrate the capability of the SMART method in accelerating MR quantitative imaging.
Image Deformation Estimation via Multi-Objective Optimization
Jun 08, 2021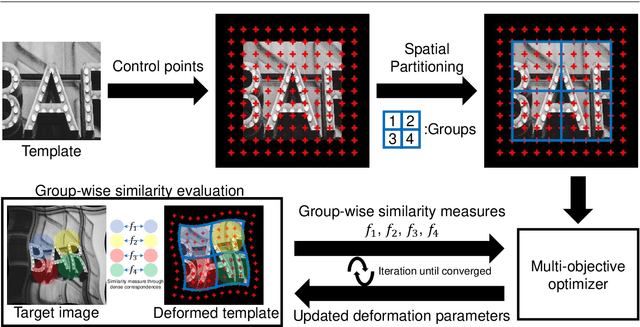
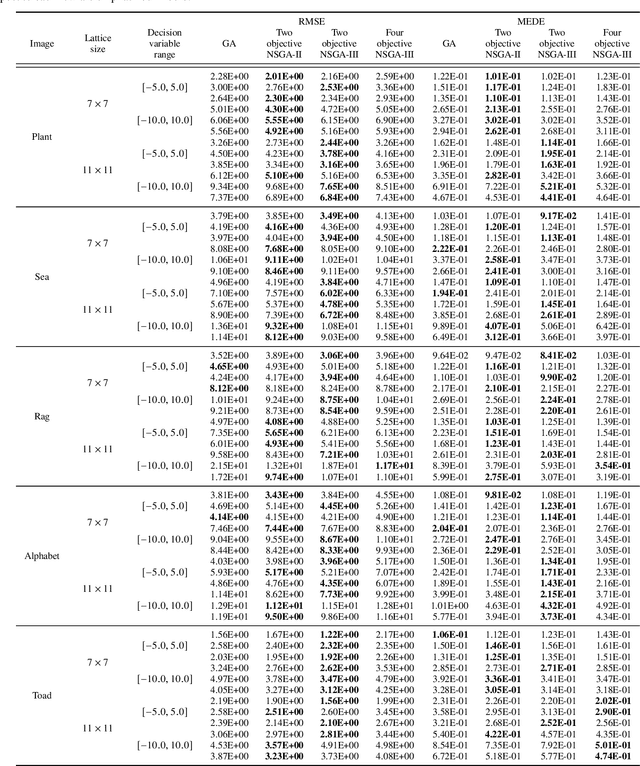

The free-form deformation model can represent a wide range of non-rigid deformations by manipulating a control point lattice over the image. However, due to a large number of parameters, it is challenging to fit the free-form deformation model directly to the deformed image for deformation estimation because of the complexity of the fitness landscape. In this paper, we cast the registration task as a multi-objective optimization problem (MOP) according to the fact that regions affected by each control point overlap with each other. Specifically, by partitioning the template image into several regions and measuring the similarity of each region independently, multiple objectives are built and deformation estimation can thus be realized by solving the MOP with off-the-shelf multi-objective evolutionary algorithms (MOEAs). In addition, a coarse-to-fine strategy is realized by image pyramid combined with control point mesh subdivision. Specifically, the optimized candidate solutions of the current image level are inherited by the next level, which increases the ability to deal with large deformation. Also, a post-processing procedure is proposed to generate a single output utilizing the Pareto optimal solutions. Comparative experiments on both synthetic and real-world images show the effectiveness and usefulness of our deformation estimation method.
Multimodal Open-Vocabulary Video Classification via Pre-Trained Vision and Language Models
Jul 15, 2022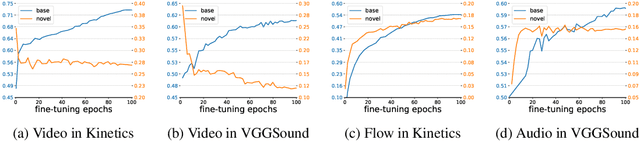
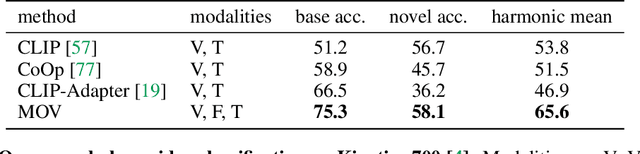
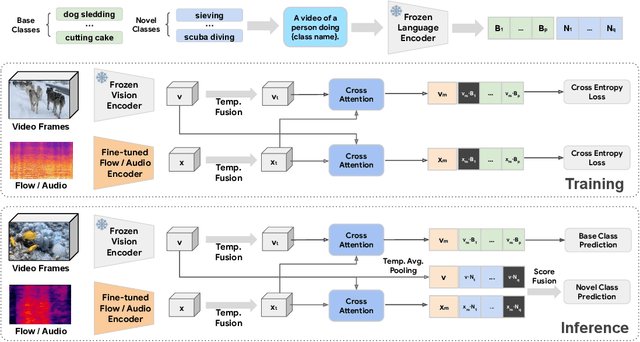
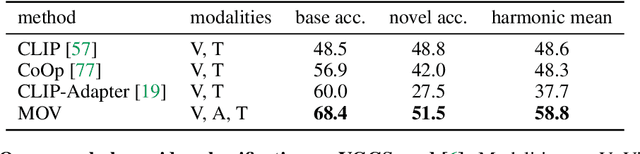
Utilizing vision and language models (VLMs) pre-trained on large-scale image-text pairs is becoming a promising paradigm for open-vocabulary visual recognition. In this work, we extend this paradigm by leveraging motion and audio that naturally exist in video. We present \textbf{MOV}, a simple yet effective method for \textbf{M}ultimodal \textbf{O}pen-\textbf{V}ocabulary video classification. In MOV, we directly use the vision encoder from pre-trained VLMs with minimal modifications to encode video, optical flow and audio spectrogram. We design a cross-modal fusion mechanism to aggregate complimentary multimodal information. Experiments on Kinetics-700 and VGGSound show that introducing flow or audio modality brings large performance gains over the pre-trained VLM and existing methods. Specifically, MOV greatly improves the accuracy on base classes, while generalizes better on novel classes. MOV achieves state-of-the-art results on UCF and HMDB zero-shot video classification benchmarks, significantly outperforming both traditional zero-shot methods and recent methods based on VLMs. Code and models will be released.