 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Supervised laser-speckle image sampling of skin tissue to detect very early stage of diabetes by its effects on skin subcellular properties
Dec 18, 2021
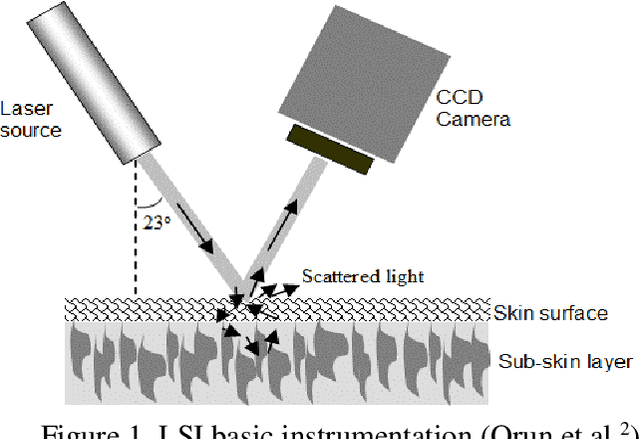
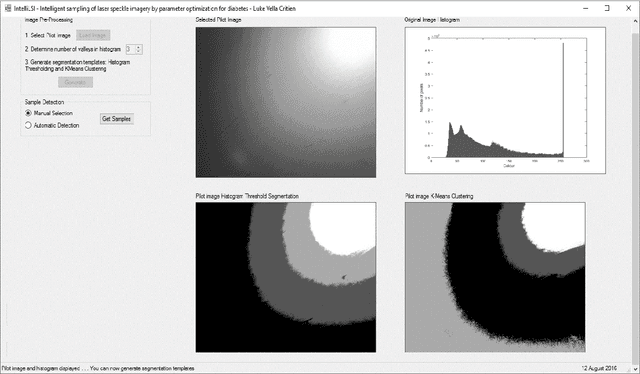
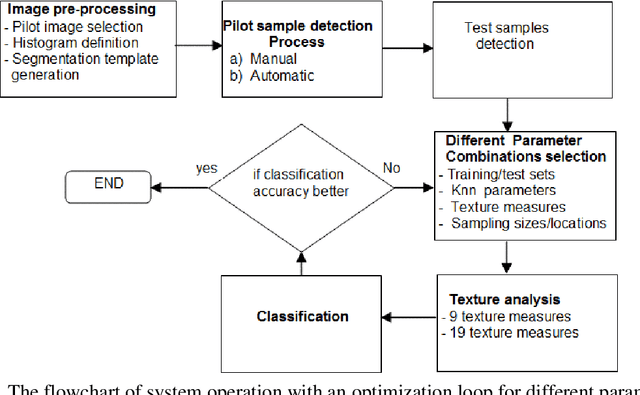
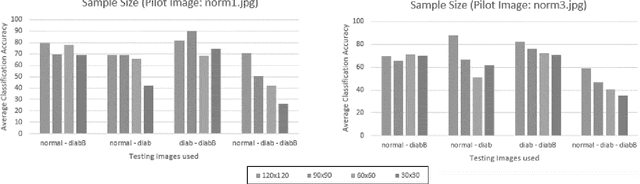
This paper investigates the effectiveness of an expert system based on K-nearest neighbors algorithm for laser speckle image sampling applied to the early detection of diabetes. With the latest developments in artificial intelligent guided laser speckle imaging technologies, it may be possible to optimise laser parameters, such as wavelength, energy level and image texture measures in association with a suitable AI technique to interact effectively with the subcellular properties of a skin tissue to detect early signs of diabetes. The new approach is potentially more effective than the classical skin glucose level observation because of its optimised combination of laser physics and AI techniques, and additionally, it allows non-expert individuals to perform more frequent skin tissue tests for an early detection of diabetes.
Variational Transfer Learning using Cross-Domain Latent Modulation
May 31, 2022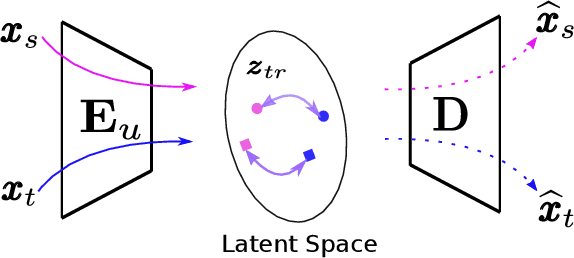
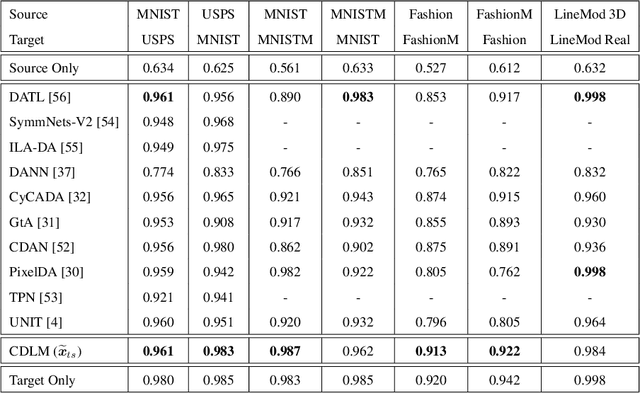
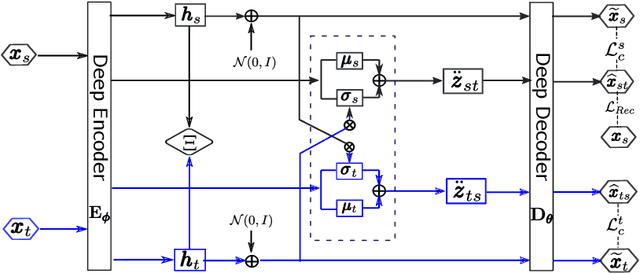
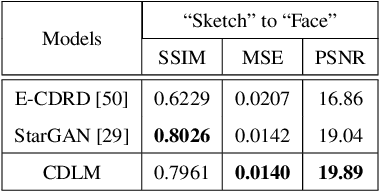
To successfully apply trained neural network models to new domains, powerful transfer learning solutions are essential. We propose to introduce a novel cross-domain latent modulation mechanism to a variational autoencoder framework so as to achieve effective transfer learning. Our key idea is to procure deep representations from one data domain and use it to influence the reparameterization of the latent variable of another domain. Specifically, deep representations of the source and target domains are first extracted by a unified inference model and aligned by employing gradient reversal. The learned deep representations are then cross-modulated to the latent encoding of the alternative domain, where consistency constraints are also applied. In the empirical validation that includes a number of transfer learning benchmark tasks for unsupervised domain adaptation and image-to-image translation, our model demonstrates competitive performance, which is also supported by evidence obtained from visualization.
Intrusion Detection: Machine Learning Baseline Calculations for Image Classification
Nov 03, 2021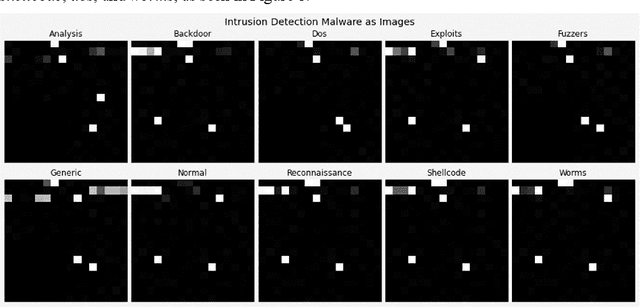
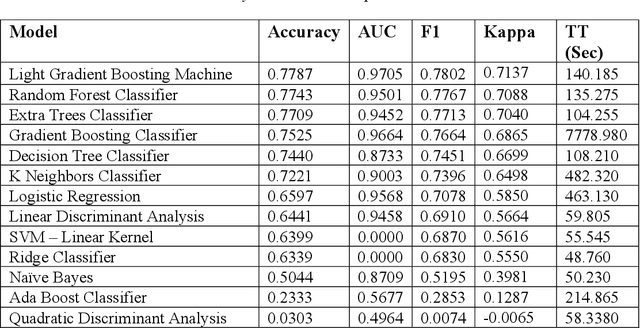
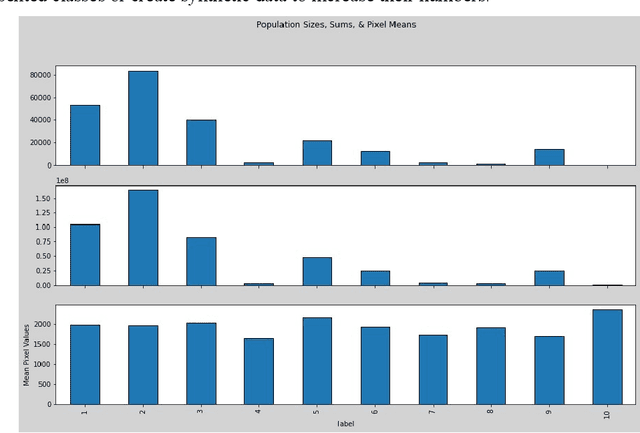

Cyber security can be enhanced through application of machine learning by recasting network attack data into an image format, then applying supervised computer vision and other machine learning techniques to detect malicious specimens. Exploratory data analysis reveals little correlation and few distinguishing characteristics between the ten classes of malware used in this study. A general model comparison demonstrates that the most promising candidates for consideration are Light Gradient Boosting Machine, Random Forest Classifier, and Extra Trees Classifier. Convolutional networks fail to deliver their outstanding classification ability, being surpassed by a simple, fully connected architecture. Most tests fail to break 80% categorical accuracy and present low F1 scores, indicating more sophisticated approaches (e.g., bootstrapping, random samples, and feature selection) may be required to maximize performance.
Using adversarial images to improve outcomes of federated learning for non-IID data
Jun 16, 2022

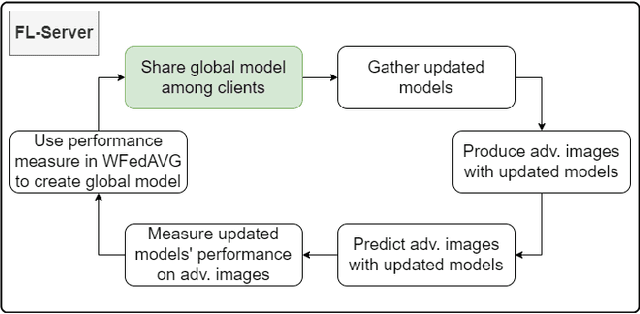
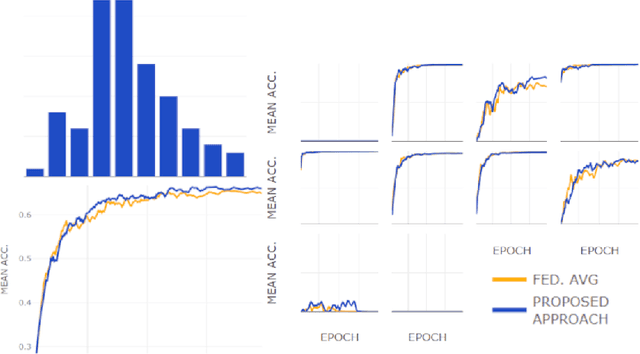
One of the important problems in federated learning is how to deal with unbalanced data. This contribution introduces a novel technique designed to deal with label skewed non-IID data, using adversarial inputs, created by the I-FGSM method. Adversarial inputs guide the training process and allow the Weighted Federated Averaging to give more importance to clients with 'selected' local label distributions. Experimental results, gathered from image classification tasks, for MNIST and CIFAR-10 datasets, are reported and analyzed.
Action Recognition with Domain Invariant Features of Skeleton Image
Nov 19, 2021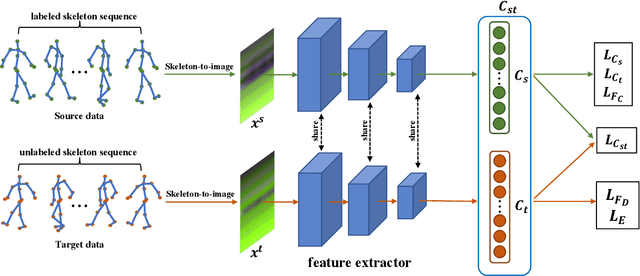
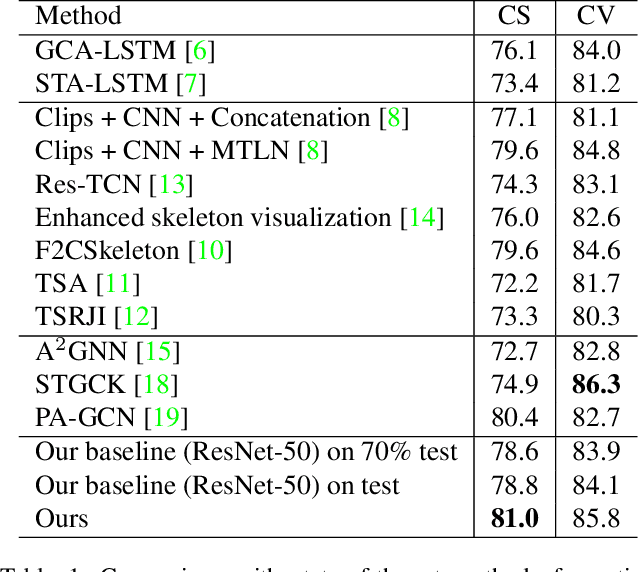
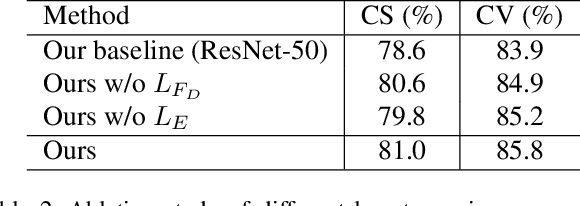
Due to the fast processing-speed and robustness it can achieve, skeleton-based action recognition has recently received the attention of the computer vision community. The recent Convolutional Neural Network (CNN)-based methods have shown commendable performance in learning spatio-temporal representations for skeleton sequence, which use skeleton image as input to a CNN. Since the CNN-based methods mainly encoding the temporal and skeleton joints simply as rows and columns, respectively, the latent correlation related to all joints may be lost caused by the 2D convolution. To solve this problem, we propose a novel CNN-based method with adversarial training for action recognition. We introduce a two-level domain adversarial learning to align the features of skeleton images from different view angles or subjects, respectively, thus further improve the generalization. We evaluated our proposed method on NTU RGB+D. It achieves competitive results compared with state-of-the-art methods and 2.4$\%$, 1.9$\%$ accuracy gain than the baseline for cross-subject and cross-view.
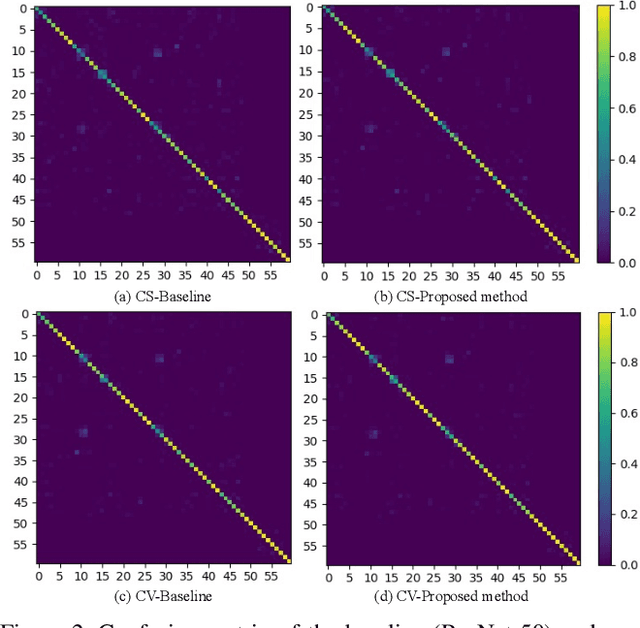
Discover and Mitigate Unknown Biases with Debiasing Alternate Networks
Jul 20, 2022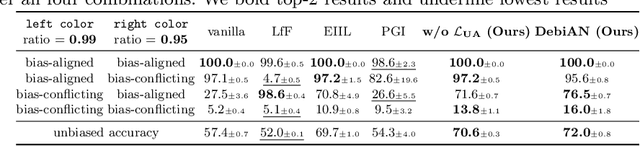
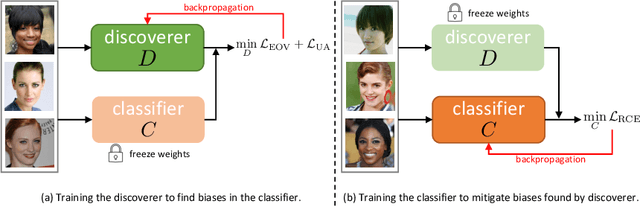
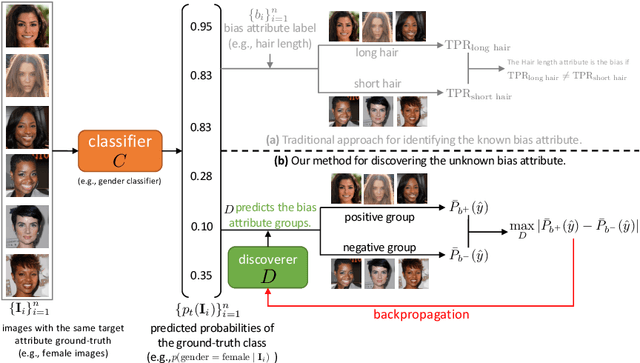

Deep image classifiers have been found to learn biases from datasets. To mitigate the biases, most previous methods require labels of protected attributes (e.g., age, skin tone) as full-supervision, which has two limitations: 1) it is infeasible when the labels are unavailable; 2) they are incapable of mitigating unknown biases -- biases that humans do not preconceive. To resolve those problems, we propose Debiasing Alternate Networks (DebiAN), which comprises two networks -- a Discoverer and a Classifier. By training in an alternate manner, the discoverer tries to find multiple unknown biases of the classifier without any annotations of biases, and the classifier aims at unlearning the biases identified by the discoverer. While previous works evaluate debiasing results in terms of a single bias, we create Multi-Color MNIST dataset to better benchmark mitigation of multiple biases in a multi-bias setting, which not only reveals the problems in previous methods but also demonstrates the advantage of DebiAN in identifying and mitigating multiple biases simultaneously. We further conduct extensive experiments on real-world datasets, showing that the discoverer in DebiAN can identify unknown biases that may be hard to be found by humans. Regarding debiasing, DebiAN achieves strong bias mitigation performance.
Variational AutoEncoder for Reference based Image Super-Resolution
Jun 08, 2021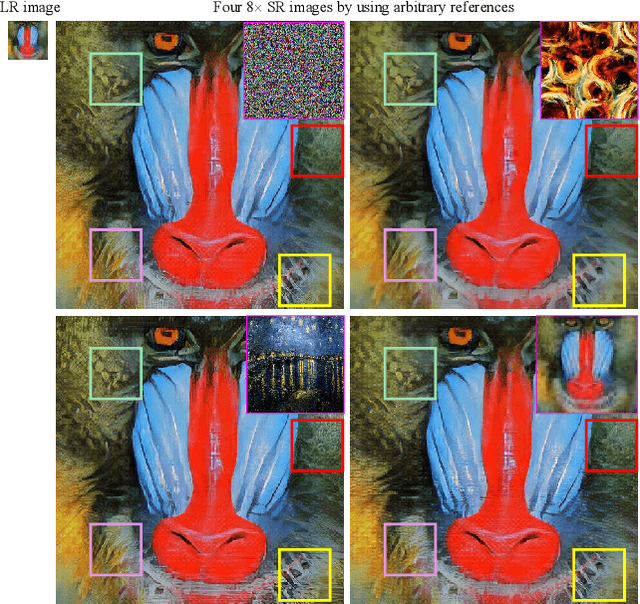

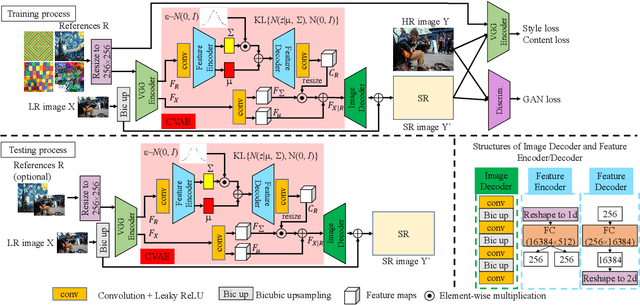
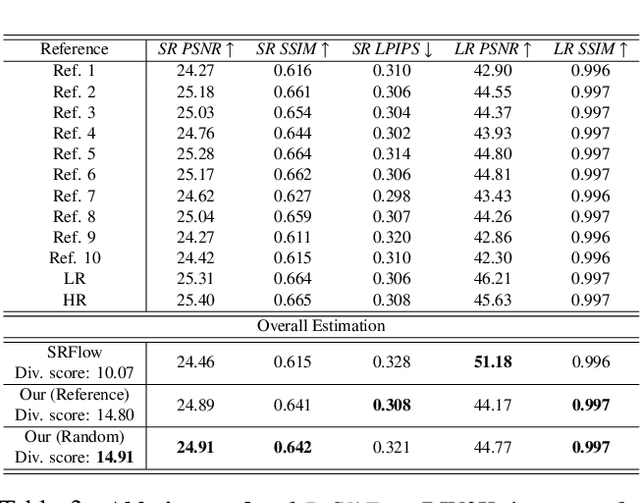
In this paper, we propose a novel reference based image super-resolution approach via Variational AutoEncoder (RefVAE). Existing state-of-the-art methods mainly focus on single image super-resolution which cannot perform well on large upsampling factors, e.g., 8$\times$. We propose a reference based image super-resolution, for which any arbitrary image can act as a reference for super-resolution. Even using random map or low-resolution image itself, the proposed RefVAE can transfer the knowledge from the reference to the super-resolved images. Depending upon different references, the proposed method can generate different versions of super-resolved images from a hidden super-resolution space. Besides using different datasets for some standard evaluations with PSNR and SSIM, we also took part in the NTIRE2021 SR Space challenge and have provided results of the randomness evaluation of our approach. Compared to other state-of-the-art methods, our approach achieves higher diverse scores.
* 10 pages, 6 figures
SDTP: Semantic-aware Decoupled Transformer Pyramid for Dense Image Prediction
Sep 18, 2021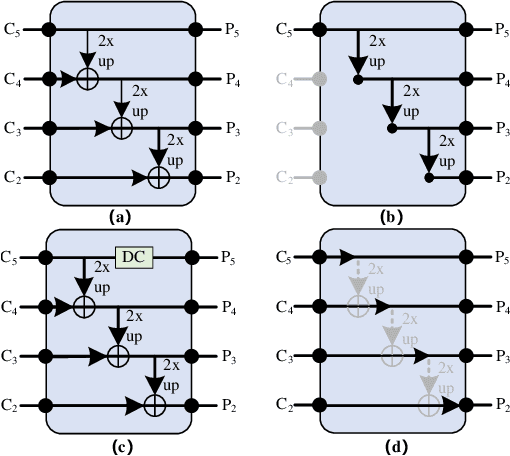
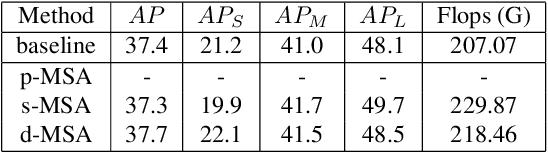
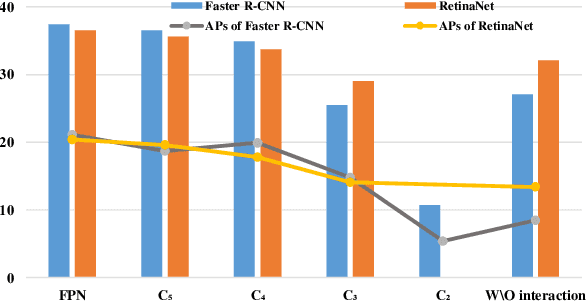
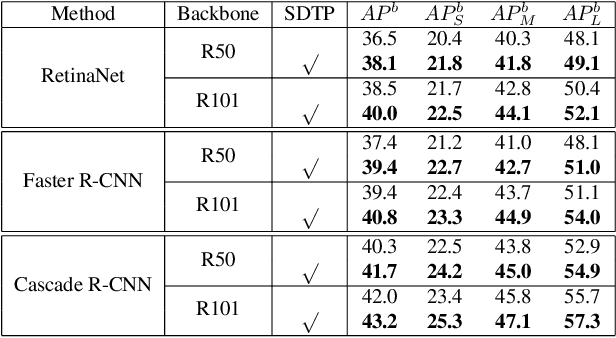
Although transformer has achieved great progress on computer vision tasks, the scale variation in dense image prediction is still the key challenge. Few effective multi-scale techniques are applied in transformer and there are two main limitations in the current methods. On one hand, self-attention module in vanilla transformer fails to sufficiently exploit the diversity of semantic information because of its rigid mechanism. On the other hand, it is hard to build attention and interaction among different levels due to the heavy computational burden. To alleviate this problem, we first revisit multi-scale problem in dense prediction, verifying the significance of diverse semantic representation and multi-scale interaction, and exploring the adaptation of transformer to pyramidal structure. Inspired by these findings, we propose a novel Semantic-aware Decoupled Transformer Pyramid (SDTP) for dense image prediction, consisting of Intra-level Semantic Promotion (ISP), Cross-level Decoupled Interaction (CDI) and Attention Refinement Function (ARF). ISP explores the semantic diversity in different receptive space. CDI builds the global attention and interaction among different levels in decoupled space which also solves the problem of heavy computation. Besides, ARF is further added to refine the attention in transformer. Experimental results demonstrate the validity and generality of the proposed method, which outperforms the state-of-the-art by a significant margin in dense image prediction tasks. Furthermore, the proposed components are all plug-and-play, which can be embedded in other methods.
Learn2Reg: comprehensive multi-task medical image registration challenge, dataset and evaluation in the era of deep learning
Dec 08, 2021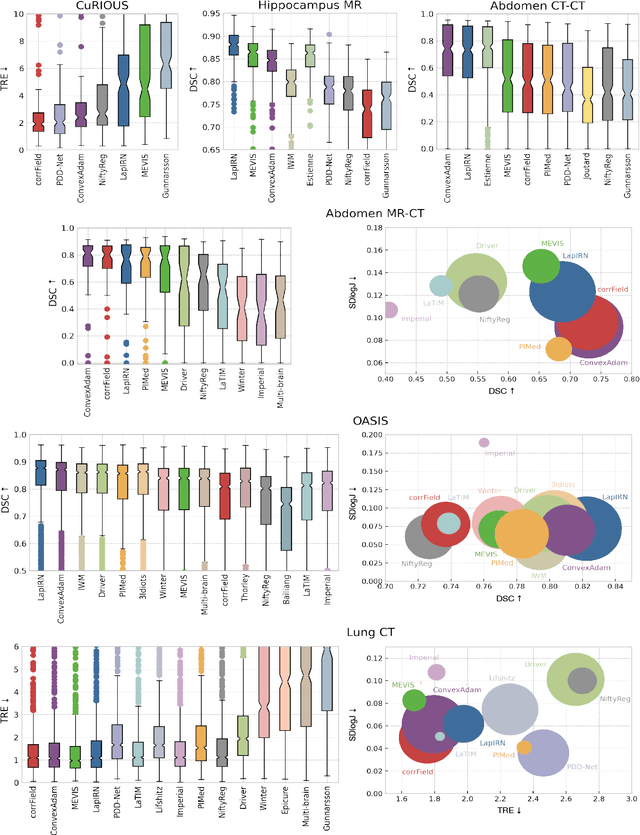
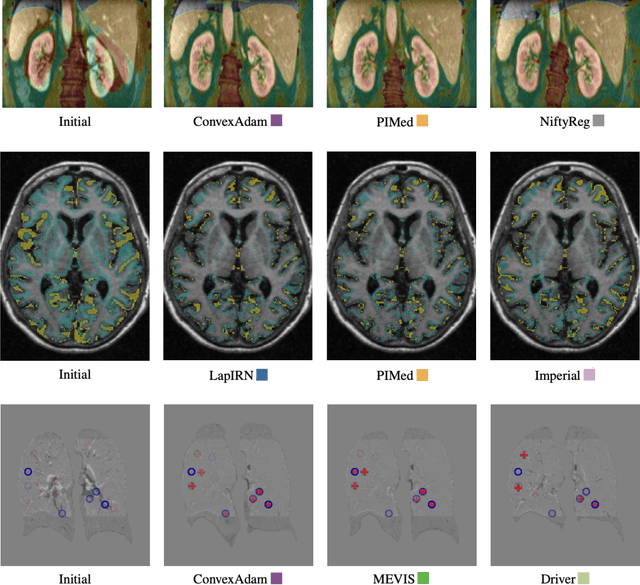
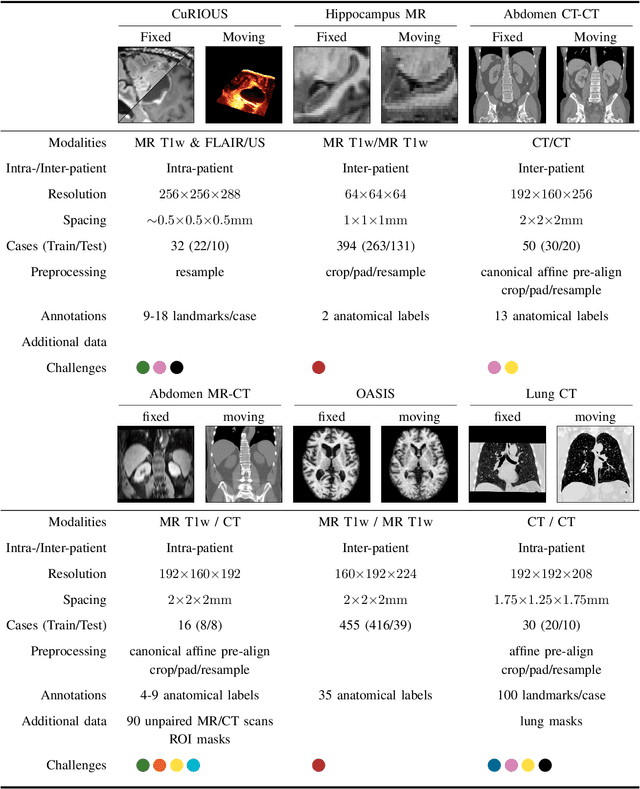
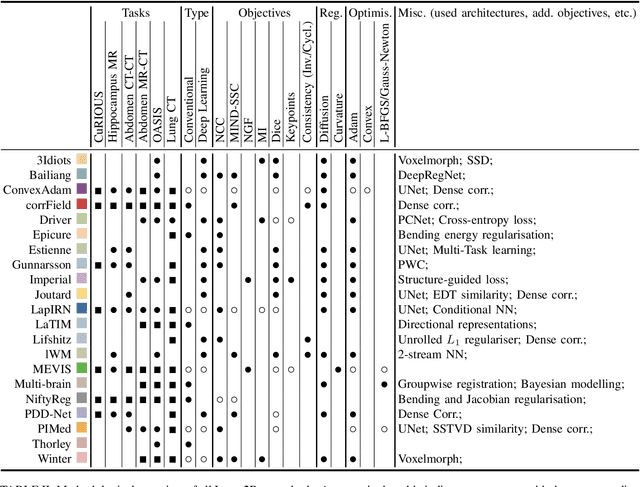
To date few studies have comprehensively compared medical image registration approaches on a wide-range of complementary clinically relevant tasks. This limits the adoption of advances in research into practice and prevents fair benchmarks across competing approaches. Many newer learning-based methods have been explored within the last five years, but the question which optimisation, architectural or metric strategy is ideally suited remains open. Learn2Reg covers a wide range of anatomies: brain, abdomen and thorax, modalities: ultrasound, CT, MRI, populations: intra- and inter-patient and levels of supervision. We established a lower entry barrier for training and validation of 3D registration, which helped us compile results of over 65 individual method submissions from more than 20 unique teams. Our complementary set of metrics, including robustness, accuracy, plausibility and speed enables unique insight into the current-state-of-the-art of medical image registration. Further analyses into transferability, bias and importance of supervision question the superiority of primarily deep learning based approaches and open exiting new research directions into hybrid methods that leverage GPU-accelerated conventional optimisation.
See What You See: Self-supervised Cross-modal Retrieval of Visual Stimuli from Brain Activity
Aug 07, 2022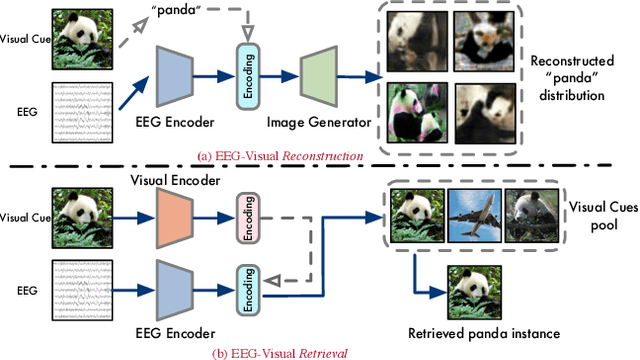
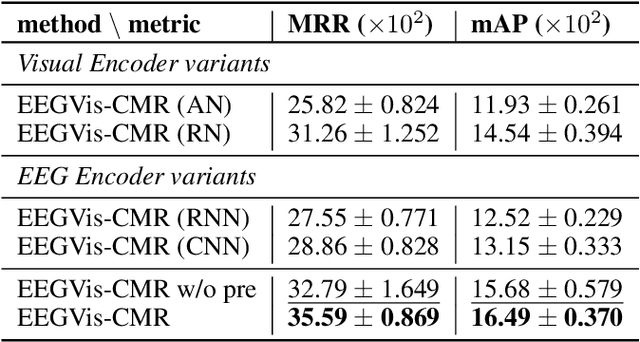
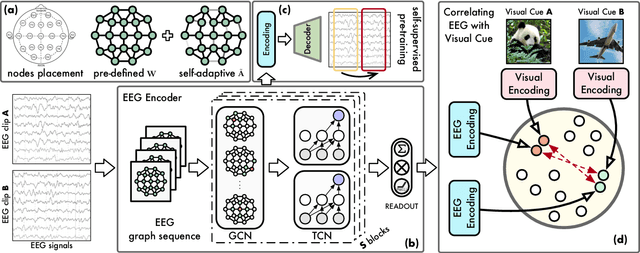
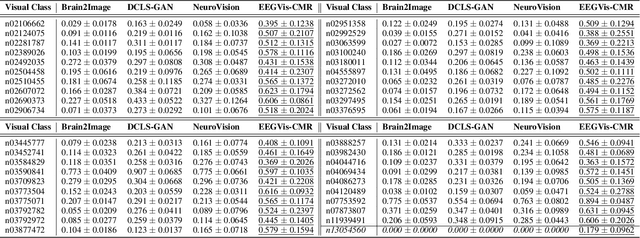
Recent studies demonstrate the use of a two-stage supervised framework to generate images that depict human perception to visual stimuli from EEG, referring to EEG-visual reconstruction. They are, however, unable to reproduce the exact visual stimulus, since it is the human-specified annotation of images, not their data, that determines what the synthesized images are. Moreover, synthesized images often suffer from noisy EEG encodings and unstable training of generative models, making them hard to recognize. Instead, we present a single-stage EEG-visual retrieval paradigm where data of two modalities are correlated, as opposed to their annotations, allowing us to recover the exact visual stimulus for an EEG clip. We maximize the mutual information between the EEG encoding and associated visual stimulus through optimization of a contrastive self-supervised objective, leading to two additional benefits. One, it enables EEG encodings to handle visual classes beyond seen ones during training, since learning is not directed at class annotations. In addition, the model is no longer required to generate every detail of the visual stimulus, but rather focuses on cross-modal alignment and retrieves images at the instance level, ensuring distinguishable model output. Empirical studies are conducted on the largest single-subject EEG dataset that measures brain activities evoked by image stimuli. We demonstrate the proposed approach completes an instance-level EEG-visual retrieval task which existing methods cannot. We also examine the implications of a range of EEG and visual encoder structures. Furthermore, for a mostly studied semantic-level EEG-visual classification task, despite not using class annotations, the proposed method outperforms state-of-the-art supervised EEG-visual reconstruction approaches, particularly on the capability of open class recognition.