 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hybrid CNN Bi-LSTM neural network for Hyperspectral image classification
Feb 15, 2024
Hyper spectral images have drawn the attention of the researchers for its complexity to classify. It has nonlinear relation between the materials and the spectral information provided by the HSI image. Deep learning methods have shown superiority in learning this nonlinearity in comparison to traditional machine learning methods. Use of 3-D CNN along with 2-D CNN have shown great success for learning spatial and spectral features. However, it uses comparatively large number of parameters. Moreover, it is not effective to learn inter layer information. Hence, this paper proposes a neural network combining 3-D CNN, 2-D CNN and Bi-LSTM. The performance of this model has been tested on Indian Pines(IP) University of Pavia(PU) and Salinas Scene(SA) data sets. The results are compared with the state of-the-art deep learning-based models. This model performed better in all three datasets. It could achieve 99.83, 99.98 and 100 percent accuracy using only 30 percent trainable parameters of the state-of-art model in IP, PU and SA datasets respectively.
CIC: A framework for Culturally-aware Image Captioning
Feb 08, 2024Image Captioning generates descriptive sentences from images using Vision-Language Pre-trained models (VLPs) such as BLIP, which has improved greatly. However, current methods lack the generation of detailed descriptive captions for the cultural elements depicted in the images, such as the traditional clothing worn by people from Asian cultural groups. In this paper, we propose a new framework, \textbf{Culturally-aware Image Captioning (CIC)}, that generates captions and describes cultural elements extracted from cultural visual elements in images representing cultures. Inspired by methods combining visual modality and Large Language Models (LLMs) through appropriate prompts, our framework (1) generates questions based on cultural categories from images, (2) extracts cultural visual elements from Visual Question Answering (VQA) using generated questions, and (3) generates culturally-aware captions using LLMs with the prompts. Our human evaluation conducted on 45 participants from 4 different cultural groups with a high understanding of the corresponding culture shows that our proposed framework generates more culturally descriptive captions when compared to the image captioning baseline based on VLPs. Our code and dataset will be made publicly available upon acceptance.
Deep Learning for Medical Image Segmentation with Imprecise Annotation
Feb 11, 2024Medical image segmentation (MIS) plays an instrumental role in medical image analysis, where considerable efforts have been devoted to automating the process. Currently, mainstream MIS approaches are based on deep neural networks (DNNs) which are typically trained on a dataset that contains annotation masks produced by doctors. However, in the medical domain, the annotation masks generated by different doctors can inherently vary because a doctor may unnecessarily produce precise and unique annotations to meet the goal of diagnosis. Therefore, the DNN model trained on the data annotated by certain doctors, often just a single doctor, could undesirably favour those doctors who annotate the training data, leading to the unsatisfaction of a new doctor who will use the trained model. To address this issue, this work investigates the utilization of multi-expert annotation to enhance the adaptability of the model to a new doctor and we conduct a pilot study on the MRI brain segmentation task. Experimental results demonstrate that the model trained on a dataset with multi-expert annotation can efficiently cater for a new doctor, after lightweight fine-tuning on just a few annotations from the new doctor.
Consistent and Asymptotically Statistically-Efficient Solution to Camera Motion Estimation
Mar 02, 2024
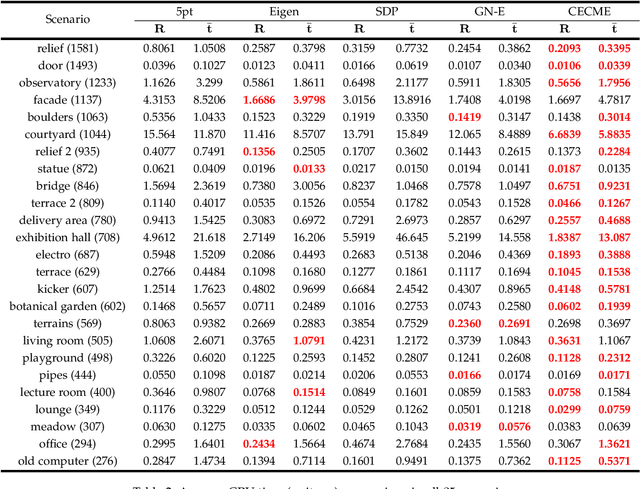
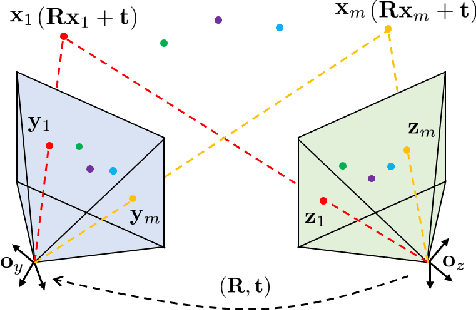
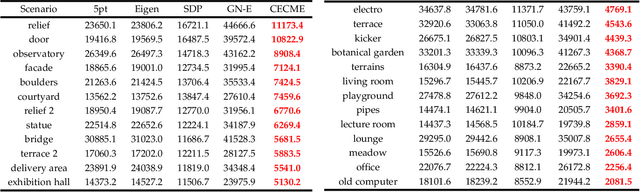
Given 2D point correspondences between an image pair, inferring the camera motion is a fundamental issue in the computer vision community. The existing works generally set out from the epipolar constraint and estimate the essential matrix, which is not optimal in the maximum likelihood (ML) sense. In this paper, we dive into the original measurement model with respect to the rotation matrix and normalized translation vector and formulate the ML problem. We then propose a two-step algorithm to solve it: In the first step, we estimate the variance of measurement noises and devise a consistent estimator based on bias elimination; In the second step, we execute a one-step Gauss-Newton iteration on manifold to refine the consistent estimate. We prove that the proposed estimate owns the same asymptotic statistical properties as the ML estimate: The first is consistency, i.e., the estimate converges to the ground truth as the point number increases; The second is asymptotic efficiency, i.e., the mean squared error of the estimate converges to the theoretical lower bound -- Cramer-Rao bound. In addition, we show that our algorithm has linear time complexity. These appealing characteristics endow our estimator with a great advantage in the case of dense point correspondences. Experiments on both synthetic data and real images demonstrate that when the point number reaches the order of hundreds, our estimator outperforms the state-of-the-art ones in terms of estimation accuracy and CPU time.
ELA: Efficient Local Attention for Deep Convolutional Neural Networks
Mar 02, 2024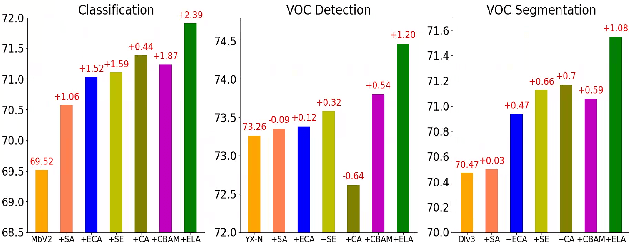

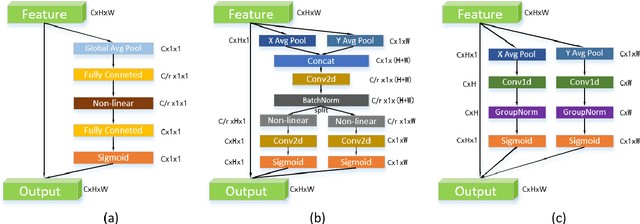
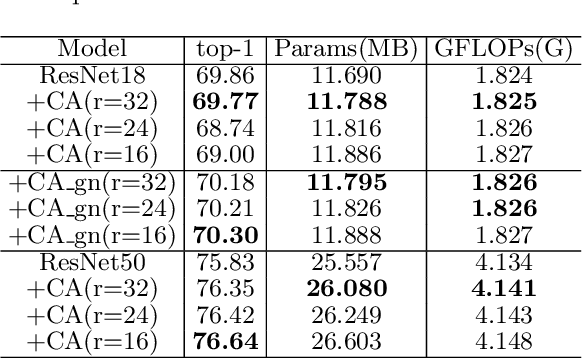
The attention mechanism has gained significant recognition in the field of computer vision due to its ability to effectively enhance the performance of deep neural networks. However, existing methods often struggle to effectively utilize spatial information or, if they do, they come at the cost of reducing channel dimensions or increasing the complexity of neural networks. In order to address these limitations, this paper introduces an Efficient Local Attention (ELA) method that achieves substantial performance improvements with a simple structure. By analyzing the limitations of the Coordinate Attention method, we identify the lack of generalization ability in Batch Normalization, the adverse effects of dimension reduction on channel attention, and the complexity of attention generation process. To overcome these challenges, we propose the incorporation of 1D convolution and Group Normalization feature enhancement techniques. This approach enables accurate localization of regions of interest by efficiently encoding two 1D positional feature maps without the need for dimension reduction, while allowing for a lightweight implementation. We carefully design three hyperparameters in ELA, resulting in four different versions: ELA-T, ELA-B, ELA-S, and ELA-L, to cater to the specific requirements of different visual tasks such as image classification, object detection and sementic segmentation. ELA can be seamlessly integrated into deep CNN networks such as ResNet, MobileNet, and DeepLab. Extensive evaluations on the ImageNet, MSCOCO, and Pascal VOC datasets demonstrate the superiority of the proposed ELA module over current state-of-the-art methods in all three aforementioned visual tasks.
Image Fusion via Vision-Language Model
Feb 03, 2024Image fusion integrates essential information from multiple source images into a single composite, emphasizing the highlighting structure and textures, and refining imperfect areas. Existing methods predominantly focus on pixel-level and semantic visual features for recognition. However, they insufficiently explore the deeper semantic information at a text-level beyond vision. Therefore, we introduce a novel fusion paradigm named image Fusion via vIsion-Language Model (FILM), for the first time, utilizing explicit textual information in different source images to guide image fusion. In FILM, input images are firstly processed to generate semantic prompts, which are then fed into ChatGPT to obtain rich textual descriptions. These descriptions are fused in the textual domain and guide the extraction of crucial visual features from the source images through cross-attention, resulting in a deeper level of contextual understanding directed by textual semantic information. The final fused image is created by vision feature decoder. This paradigm achieves satisfactory results in four image fusion tasks: infrared-visible, medical, multi-exposure, and multi-focus image fusion. We also propose a vision-language dataset containing ChatGPT-based paragraph descriptions for the ten image fusion datasets in four fusion tasks, facilitating future research in vision-language model-based image fusion. Code and dataset will be released.
Multimodal Learned Sparse Retrieval with Probabilistic Expansion Control
Feb 27, 2024Learned sparse retrieval (LSR) is a family of neural methods that encode queries and documents into sparse lexical vectors that can be indexed and retrieved efficiently with an inverted index. We explore the application of LSR to the multi-modal domain, with a focus on text-image retrieval. While LSR has seen success in text retrieval, its application in multimodal retrieval remains underexplored. Current approaches like LexLIP and STAIR require complex multi-step training on massive datasets. Our proposed approach efficiently transforms dense vectors from a frozen dense model into sparse lexical vectors. We address issues of high dimension co-activation and semantic deviation through a new training algorithm, using Bernoulli random variables to control query expansion. Experiments with two dense models (BLIP, ALBEF) and two datasets (MSCOCO, Flickr30k) show that our proposed algorithm effectively reduces co-activation and semantic deviation. Our best-performing sparsified model outperforms state-of-the-art text-image LSR models with a shorter training time and lower GPU memory requirements. Our approach offers an effective solution for training LSR retrieval models in multimodal settings. Our code and model checkpoints are available at github.com/thongnt99/lsr-multimodal
Intelligent Known and Novel Aircraft Recognition -- A Shift from Classification to Similarity Learning for Combat Identification
Feb 26, 2024Precise aircraft recognition in low-resolution remote sensing imagery is a challenging yet crucial task in aviation, especially combat identification. This research addresses this problem with a novel, scalable, and AI-driven solution. The primary hurdle in combat identification in remote sensing imagery is the accurate recognition of Novel/Unknown types of aircraft in addition to Known types. Traditional methods, human expert-driven combat identification and image classification, fall short in identifying Novel classes. Our methodology employs similarity learning to discern features of a broad spectrum of military and civilian aircraft. It discerns both Known and Novel aircraft types, leveraging metric learning for the identification and supervised few-shot learning for aircraft type classification. To counter the challenge of limited low-resolution remote sensing data, we propose an end-to-end framework that adapts to the diverse and versatile process of military aircraft recognition by training a generalized embedder in fully supervised manner. Comparative analysis with earlier aircraft image classification methods shows that our approach is effective for aircraft image classification (F1-score Aircraft Type of 0.861) and pioneering for quantifying the identification of Novel types (F1-score Bipartitioning of 0.936). The proposed methodology effectively addresses inherent challenges in remote sensing data, thereby setting new standards in dataset quality. The research opens new avenues for domain experts and demonstrates unique capabilities in distinguishing various aircraft types, contributing to a more robust, domain-adapted potential for real-time aircraft recognition.
Disentangled 3D Scene Generation with Layout Learning
Feb 26, 2024We introduce a method to generate 3D scenes that are disentangled into their component objects. This disentanglement is unsupervised, relying only on the knowledge of a large pretrained text-to-image model. Our key insight is that objects can be discovered by finding parts of a 3D scene that, when rearranged spatially, still produce valid configurations of the same scene. Concretely, our method jointly optimizes multiple NeRFs from scratch - each representing its own object - along with a set of layouts that composite these objects into scenes. We then encourage these composited scenes to be in-distribution according to the image generator. We show that despite its simplicity, our approach successfully generates 3D scenes decomposed into individual objects, enabling new capabilities in text-to-3D content creation. For results and an interactive demo, see our project page at https://dave.ml/layoutlearning/
Training-free image style alignment for self-adapting domain shift on handheld ultrasound devices
Feb 17, 2024Handheld ultrasound devices face usage limitations due to user inexperience and cannot benefit from supervised deep learning without extensive expert annotations. Moreover, the models trained on standard ultrasound device data are constrained by training data distribution and perform poorly when directly applied to handheld device data. In this study, we propose the Training-free Image Style Alignment (TISA) framework to align the style of handheld device data to those of standard devices. The proposed TISA can directly infer handheld device images without extra training and is suited for clinical applications. We show that TISA performs better and more stably in medical detection and segmentation tasks for handheld device data. We further validate TISA as the clinical model for automatic measurements of spinal curvature and carotid intima-media thickness. The automatic measurements agree well with manual measurements made by human experts and the measurement errors remain within clinically acceptable ranges. We demonstrate the potential for TISA to facilitate automatic diagnosis on handheld ultrasound devices and expedite their eventual widespread use.