 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fine-Grained Image Generation from Bangla Text Description using Attentional Generative Adversarial Network
Sep 24, 2021

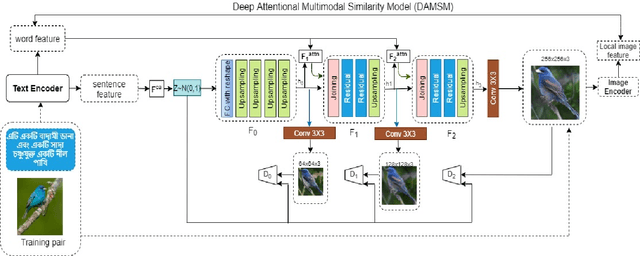


Generating fine-grained, realistic images from text has many applications in the visual and semantic realm. Considering that, we propose Bangla Attentional Generative Adversarial Network (AttnGAN) that allows intensified, multi-stage processing for high-resolution Bangla text-to-image generation. Our model can integrate the most specific details at different sub-regions of the image. We distinctively concentrate on the relevant words in the natural language description. This framework has achieved a better inception score on the CUB dataset. For the first time, a fine-grained image is generated from Bangla text using attentional GAN. Bangla has achieved 7th position among 100 most spoken languages. This inspires us to explicitly focus on this language, which will ensure the inevitable need of many people. Moreover, Bangla has a more complex syntactic structure and less natural language processing resource that validates our work more.
FastHyMix: Fast and Parameter-free Hyperspectral Image Mixed Noise Removal
Sep 18, 2021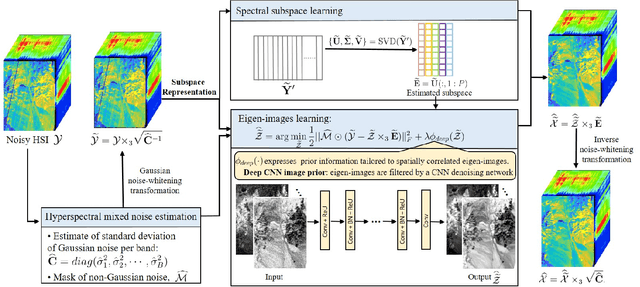
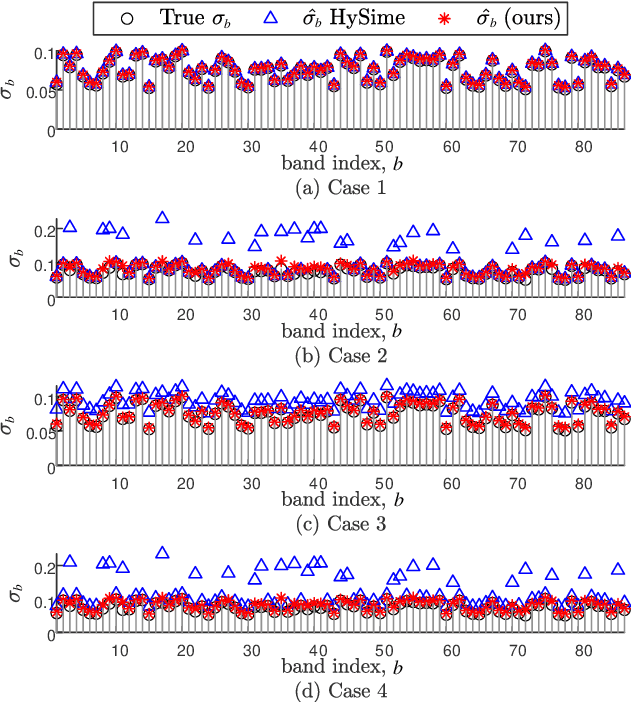

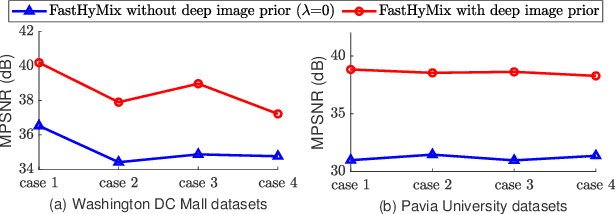
Hyperspectral imaging with high spectral resolution plays an important role in finding objects, identifying materials, or detecting processes. The decrease of the widths of spectral bands leads to a decrease in the signal-to-noise ratio (SNR) of measurements. The decreased SNR reduces the reliability of measured features or information extracted from HSIs. Furthermore, the image degradations linked with various mechanisms also result in different types of noise, such as Gaussian noise, impulse noise, deadlines, and stripes. This paper introduces a fast and parameter-free hyperspectral image mixed noise removal method (termed FastHyMix), which characterizes the complex distribution of mixed noise by using a Gaussian mixture model and exploits two main characteristics of hyperspectral data, namely low-rankness in the spectral domain and high correlation in the spatial domain. The Gaussian mixture model enables us to make a good estimation of Gaussian noise intensity and the location of sparse noise. The proposed method takes advantage of the low-rankness using subspace representation and the spatial correlation of HSIs by adding a powerful deep image prior, which is extracted from a neural denoising network. An exhaustive array of experiments and comparisons with state-of-the-art denoisers were carried out. The experimental results show significant improvement in both synthetic and real datasets. A MATLAB demo of this work will be available at https://github.com/LinaZhuang for the sake of reproducibility.
Generative Domain Adaptation for Face Anti-Spoofing
Jul 20, 2022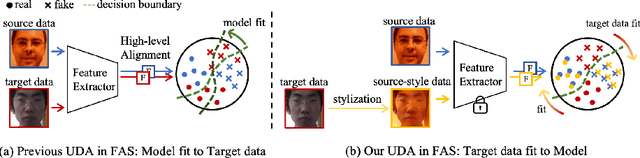
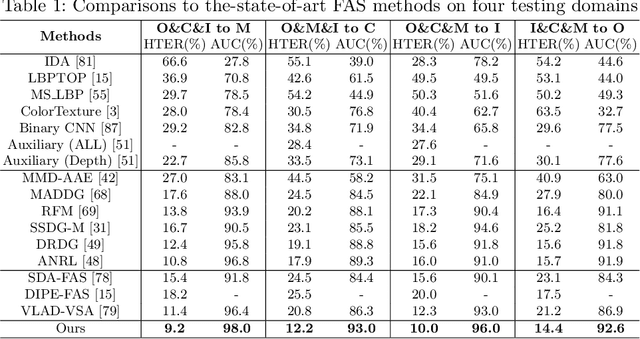
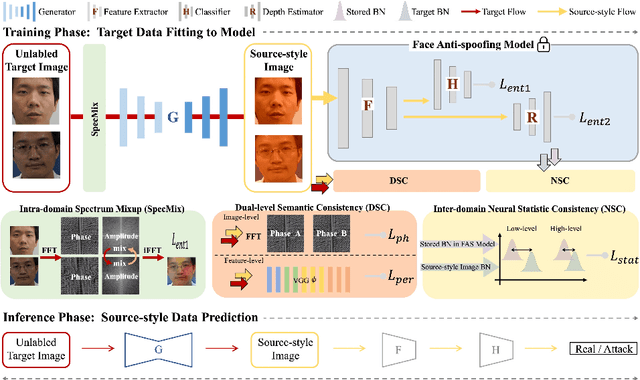
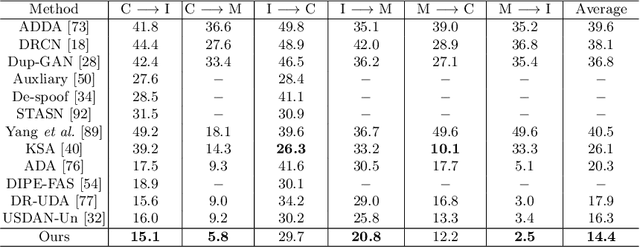
Face anti-spoofing (FAS) approaches based on unsupervised domain adaption (UDA) have drawn growing attention due to promising performances for target scenarios. Most existing UDA FAS methods typically fit the trained models to the target domain via aligning the distribution of semantic high-level features. However, insufficient supervision of unlabeled target domains and neglect of low-level feature alignment degrade the performances of existing methods. To address these issues, we propose a novel perspective of UDA FAS that directly fits the target data to the models, i.e., stylizes the target data to the source-domain style via image translation, and further feeds the stylized data into the well-trained source model for classification. The proposed Generative Domain Adaptation (GDA) framework combines two carefully designed consistency constraints: 1) Inter-domain neural statistic consistency guides the generator in narrowing the inter-domain gap. 2) Dual-level semantic consistency ensures the semantic quality of stylized images. Besides, we propose intra-domain spectrum mixup to further expand target data distributions to ensure generalization and reduce the intra-domain gap. Extensive experiments and visualizations demonstrate the effectiveness of our method against the state-of-the-art methods.
Domain and Content Adaptive Convolution for Domain Generalization in Medical Image Segmentation
Sep 13, 2021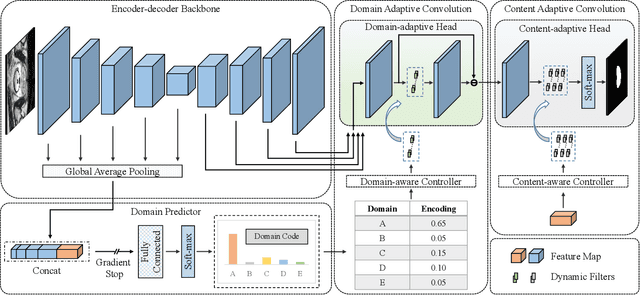

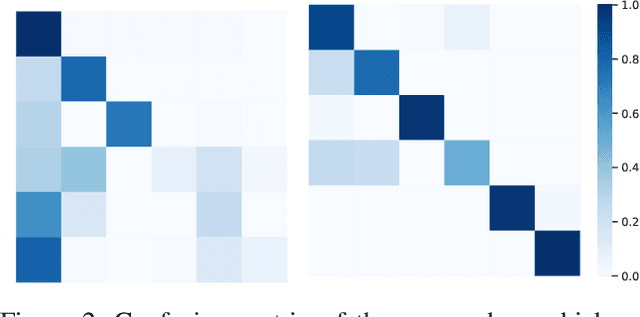
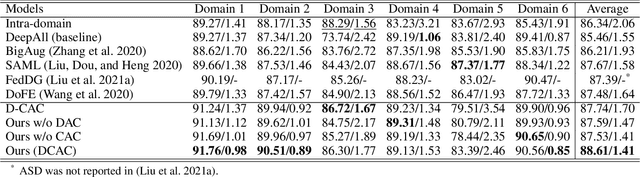
The domain gap caused mainly by variable medical image quality renders a major obstacle on the path between training a segmentation model in the lab and applying the trained model to unseen clinical data. To address this issue, domain generalization methods have been proposed, which however usually use static convolutions and are less flexible. In this paper, we propose a multi-source domain generalization model, namely domain and content adaptive convolution (DCAC), for medical image segmentation. Specifically, we design the domain adaptive convolution (DAC) module and content adaptive convolution (CAC) module and incorporate both into an encoder-decoder backbone. In the DAC module, a dynamic convolutional head is conditioned on the predicted domain code of the input to make our model adapt to the unseen target domain. In the CAC module, a dynamic convolutional head is conditioned on the global image features to make our model adapt to the test image. We evaluated the DCAC model against the baseline and four state-of-the-art domain generalization methods on the prostate segmentation, COVID-19 lesion segmentation, and optic cup/optic disc segmentation tasks. Our results indicate that the proposed DCAC model outperforms all competing methods on each segmentation task, and also demonstrate the effectiveness of the DAC and CAC modules.
Diversity aware image generation
Feb 19, 2022
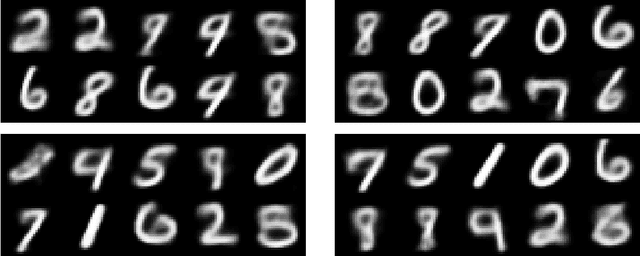
The machine learning generative algorithms such as GAN and VAE show impressive results in practice when constructing images similar to those in a training set. However, the generation of new images builds mainly on the understanding of the hidden structure of the training database followed by a mere sampling from a multi-dimensional normal variable. In particular each sample is independent from the other ones and can repeatedly propose same type of images. To cure this drawback we propose a kernel-based measure representation method that can produce new objects from a given target measure by approximating the measure as a whole and even staying away from objects already drawn from that distribution. This ensures a better variety of the produced images. The method is tested on some classic machine learning benchmarks.\end{abstract}
Learning Convolutional Neural Networks in the Frequency Domain
Apr 28, 2022
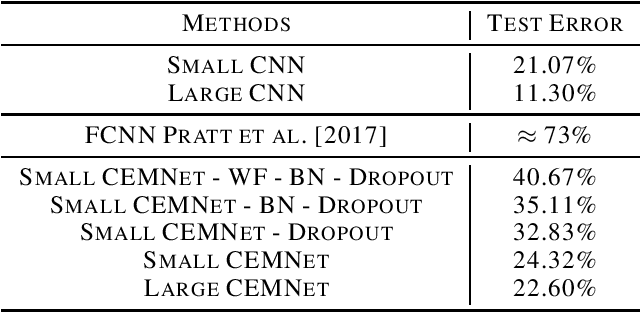
Convolutional neural network (CNN) has achieved impressive success in computer vision during the past few decades. The image convolution operation helps CNNs to get good performance on image-related tasks. However, the image convolution has high computation complexity and hard to be implemented. This paper proposes the CEMNet, which can be trained in the frequency domain. The most important motivation of this research is that we can use the straightforward element-wise multiplication operation to replace the image convolution in the frequency domain based on the Cross-Correlation Theorem, which obviously reduces the computation complexity. We further introduce a Weight Fixation mechanism to alleviate the problem of over-fitting, and analyze the working behavior of Batch Normalization, Leaky ReLU, and Dropout in the frequency domain to design their counterparts for CEMNet. Also, to deal with complex inputs brought by Discrete Fourier Transform, we design a two-branches network structure for CEMNet. Experimental results imply that CEMNet achieves good performance on MNIST and CIFAR-10 databases.
Luminance Attentive Networks for HDR Image and Panorama Reconstruction
Sep 14, 2021
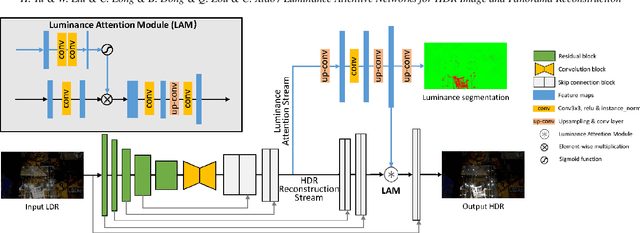
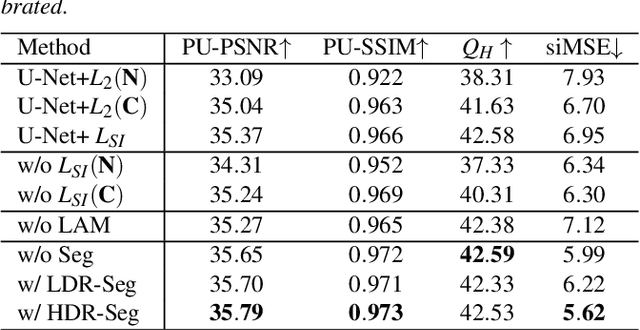
It is very challenging to reconstruct a high dynamic range (HDR) from a low dynamic range (LDR) image as an ill-posed problem. This paper proposes a luminance attentive network named LANet for HDR reconstruction from a single LDR image. Our method is based on two fundamental observations: (1) HDR images stored in relative luminance are scale-invariant, which means the HDR images will hold the same information when multiplied by any positive real number. Based on this observation, we propose a novel normalization method called " HDR calibration " for HDR images stored in relative luminance, calibrating HDR images into a similar luminance scale according to the LDR images. (2) The main difference between HDR images and LDR images is in under-/over-exposed areas, especially those highlighted. Following this observation, we propose a luminance attention module with a two-stream structure for LANet to pay more attention to the under-/over-exposed areas. In addition, we propose an extended network called panoLANet for HDR panorama reconstruction from an LDR panorama and build a dualnet structure for panoLANet to solve the distortion problem caused by the equirectangular panorama. Extensive experiments show that our proposed approach LANet can reconstruct visually convincing HDR images and demonstrate its superiority over state-of-the-art approaches in terms of all metrics in inverse tone mapping. The image-based lighting application with our proposed panoLANet also demonstrates that our method can simulate natural scene lighting using only LDR panorama. Our source code is available at https://github.com/LWT3437/LANet.
Unsupervised Deep Learning Meets Chan-Vese Model
Apr 14, 2022

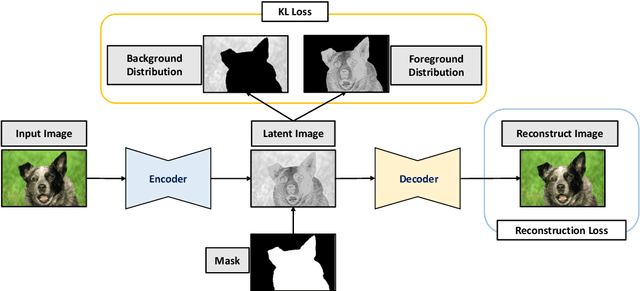
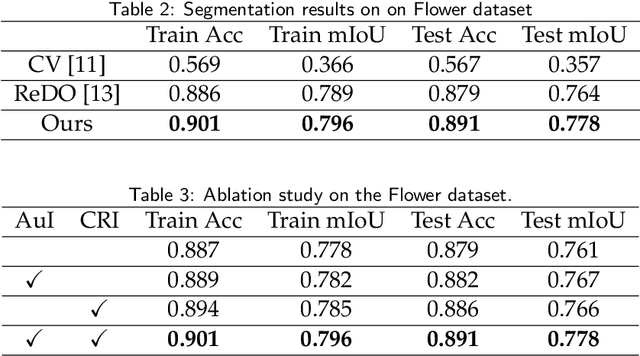
The Chan-Vese (CV) model is a classic region-based method in image segmentation. However, its piecewise constant assumption does not always hold for practical applications. Many improvements have been proposed but the issue is still far from well solved. In this work, we propose an unsupervised image segmentation approach that integrates the CV model with deep neural networks, which significantly improves the original CV model's segmentation accuracy. Our basic idea is to apply a deep neural network that maps the image into a latent space to alleviate the violation of the piecewise constant assumption in image space. We formulate this idea under the classic Bayesian framework by approximating the likelihood with an evidence lower bound (ELBO) term while keeping the prior term in the CV model. Thus, our model only needs the input image itself and does not require pre-training from external datasets. Moreover, we extend the idea to multi-phase case and dataset based unsupervised image segmentation. Extensive experiments validate the effectiveness of our model and show that the proposed method is noticeably better than other unsupervised segmentation approaches.
DAS: Densely-Anchored Sampling for Deep Metric Learning
Jul 30, 2022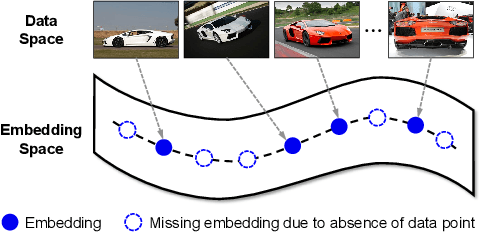
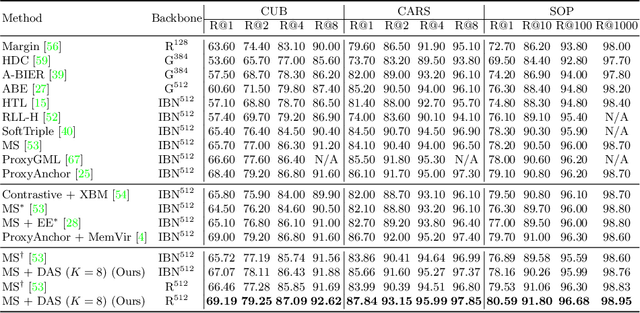
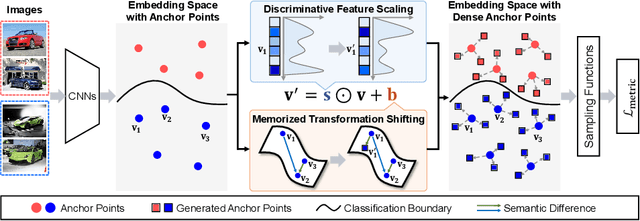
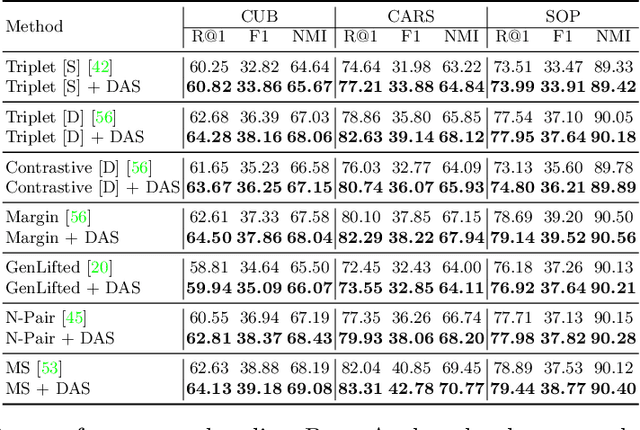
Deep Metric Learning (DML) serves to learn an embedding function to project semantically similar data into nearby embedding space and plays a vital role in many applications, such as image retrieval and face recognition. However, the performance of DML methods often highly depends on sampling methods to choose effective data from the embedding space in the training. In practice, the embeddings in the embedding space are obtained by some deep models, where the embedding space is often with barren area due to the absence of training points, resulting in so called "missing embedding" issue. This issue may impair the sample quality, which leads to degenerated DML performance. In this work, we investigate how to alleviate the "missing embedding" issue to improve the sampling quality and achieve effective DML. To this end, we propose a Densely-Anchored Sampling (DAS) scheme that considers the embedding with corresponding data point as "anchor" and exploits the anchor's nearby embedding space to densely produce embeddings without data points. Specifically, we propose to exploit the embedding space around single anchor with Discriminative Feature Scaling (DFS) and multiple anchors with Memorized Transformation Shifting (MTS). In this way, by combing the embeddings with and without data points, we are able to provide more embeddings to facilitate the sampling process thus boosting the performance of DML. Our method is effortlessly integrated into existing DML frameworks and improves them without bells and whistles. Extensive experiments on three benchmark datasets demonstrate the superiority of our method.
Multimodal Transformer for Automatic 3D Annotation and Object Detection
Jul 20, 2022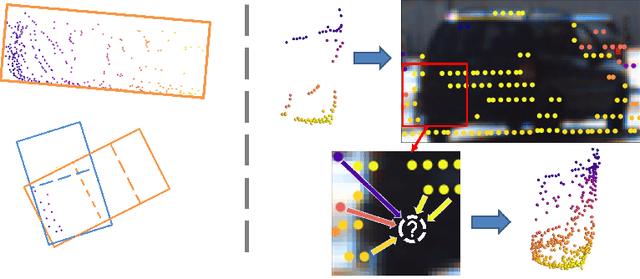
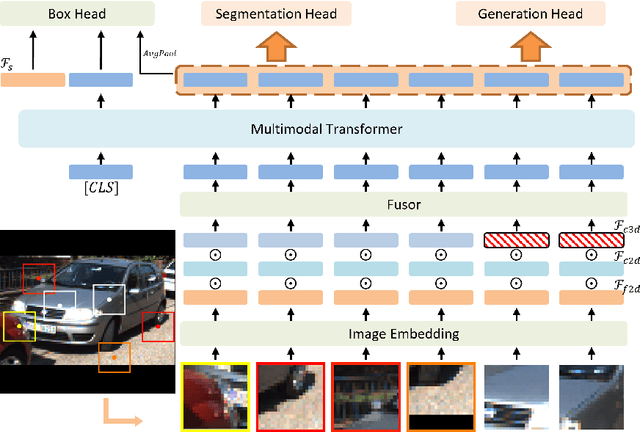
Despite a growing number of datasets being collected for training 3D object detection models, significant human effort is still required to annotate 3D boxes on LiDAR scans. To automate the annotation and facilitate the production of various customized datasets, we propose an end-to-end multimodal transformer (MTrans) autolabeler, which leverages both LiDAR scans and images to generate precise 3D box annotations from weak 2D bounding boxes. To alleviate the pervasive sparsity problem that hinders existing autolabelers, MTrans densifies the sparse point clouds by generating new 3D points based on 2D image information. With a multi-task design, MTrans segments the foreground/background, densifies LiDAR point clouds, and regresses 3D boxes simultaneously. Experimental results verify the effectiveness of the MTrans for improving the quality of the generated labels. By enriching the sparse point clouds, our method achieves 4.48\% and 4.03\% better 3D AP on KITTI moderate and hard samples, respectively, versus the state-of-the-art autolabeler. MTrans can also be extended to improve the accuracy for 3D object detection, resulting in a remarkable 89.45\% AP on KITTI hard samples. Codes are at \url{https://github.com/Cliu2/MTrans}.