 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Nonuniform Defocus Removal for Image Classification
Jun 03, 2021

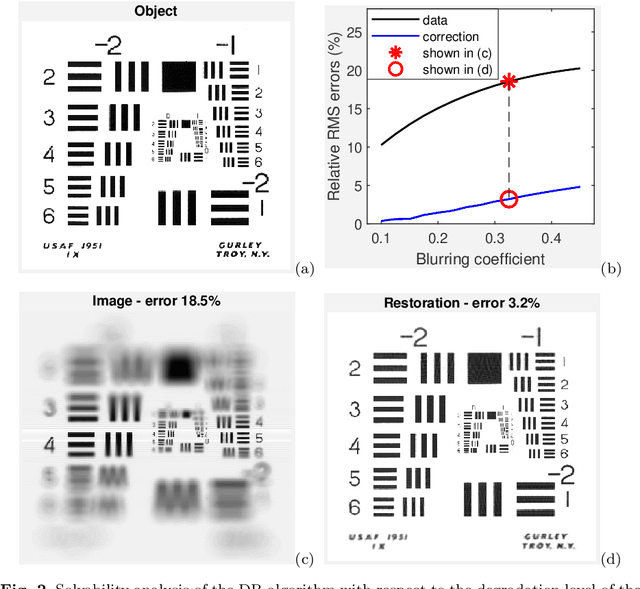
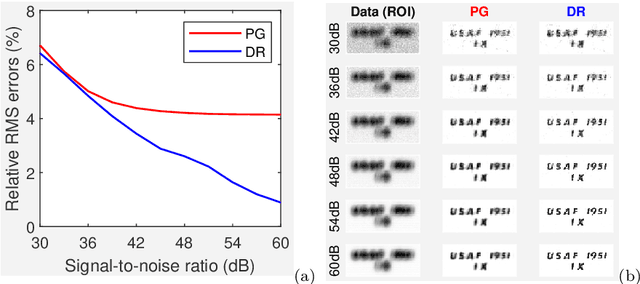
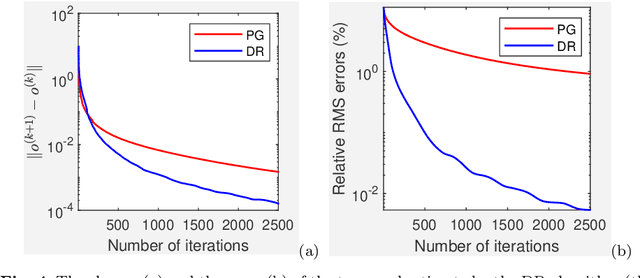
We propose and study the single-frame anisoplanatic deconvolution problem associated with image classification using machine learning algorithms, named the nonuniform defocus removal (NDR) problem. Mathematical analysis of the NDR problem is done and the so-called defocus removal (DR) algorithm for solving it is proposed. Global convergence of the DR algorithm is established without imposing any unverifiable assumption. Numerical results on simulation data show significant features of DR including solvability, noise robustness, convergence, model insensitivity and computational efficiency. Physical relevance of the NDR problem and practicability of the DR algorithm are tested on experimental data. Back to the application that originally motivated the investigation of the NDR problem, we show that the DR algorithm can improve the accuracy of classifying distorted images using convolutional neural networks. The key difference of this paper compared to most existing works on single-frame anisoplanatic deconvolution is that the new method does not require the data image to be decomposable into isoplanatic subregions. Therefore, solution approaches partitioning the image into isoplanatic zones are not applicable to the NDR problem and those handling the entire image such as the DR algorithm need to be developed and analyzed.
Semantic Image Alignment for Vehicle Localization
Oct 08, 2021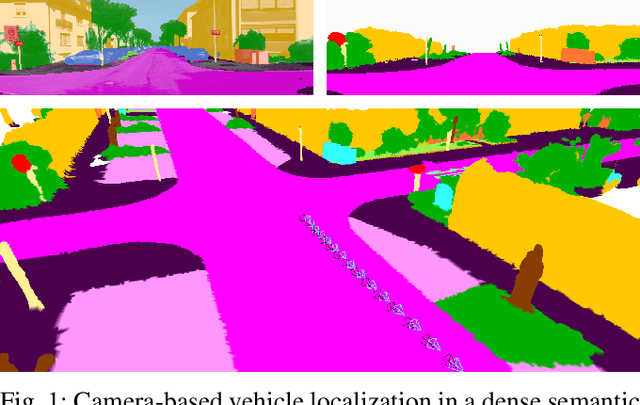
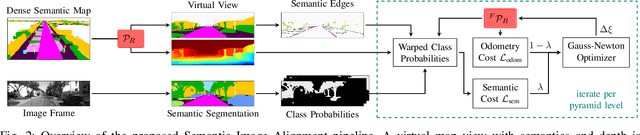
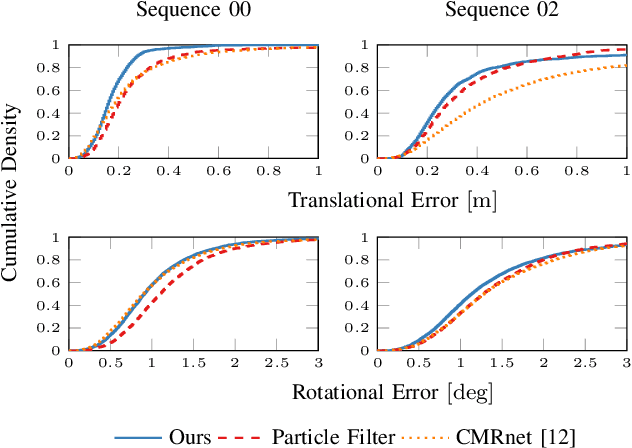
Accurate and reliable localization is a fundamental requirement for autonomous vehicles to use map information in higher-level tasks such as navigation or planning. In this paper, we present a novel approach to vehicle localization in dense semantic maps, including vectorized high-definition maps or 3D meshes, using semantic segmentation from a monocular camera. We formulate the localization task as a direct image alignment problem on semantic images, which allows our approach to robustly track the vehicle pose in semantically labeled maps by aligning virtual camera views rendered from the map to sequences of semantically segmented camera images. In contrast to existing visual localization approaches, the system does not require additional keypoint features, handcrafted localization landmark extractors or expensive LiDAR sensors. We demonstrate the wide applicability of our method on a diverse set of semantic mesh maps generated from stereo or LiDAR as well as manually annotated HD maps and show that it achieves reliable and accurate localization in real-time.
Dual Decomposition of Convex Optimization Layers for Consistent Attention in Medical Images
Jun 07, 2022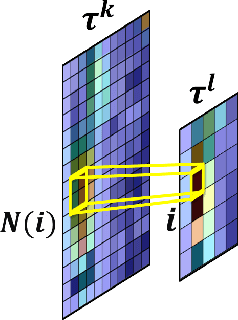
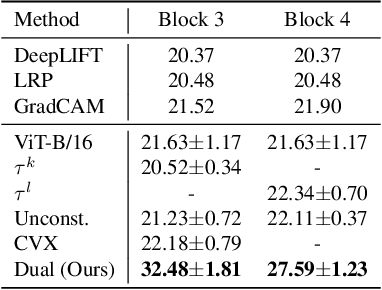
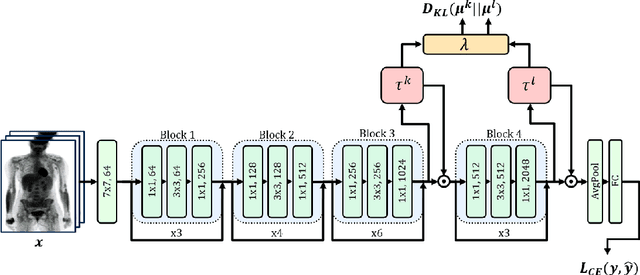
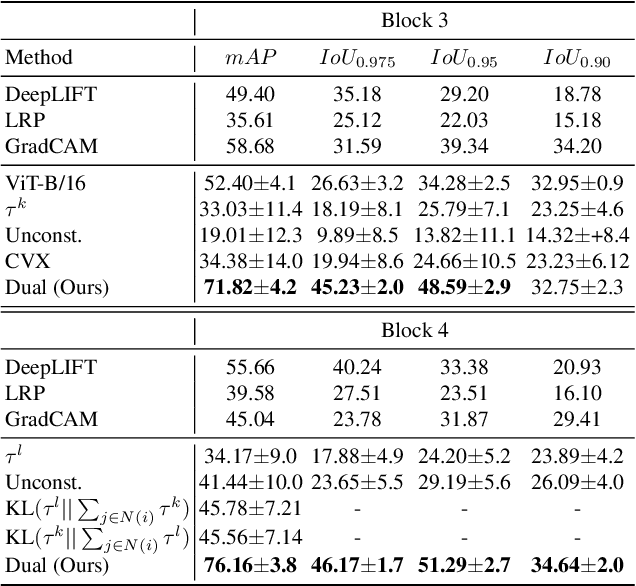
A key concern in integrating machine learning models in medicine is the ability to interpret their reasoning. Popular explainability methods have demonstrated satisfactory results in natural image recognition, yet in medical image analysis, many of these approaches provide partial and noisy explanations. Recently, attention mechanisms have shown compelling results both in their predictive performance and in their interpretable qualities. A fundamental trait of attention is that it leverages salient parts of the input which contribute to the model's prediction. To this end, our work focuses on the explanatory value of attention weight distributions. We propose a multi-layer attention mechanism that enforces consistent interpretations between attended convolutional layers using convex optimization. We apply duality to decompose the consistency constraints between the layers by reparameterizing their attention probability distributions. We further suggest learning the dual witness by optimizing with respect to our objective; thus, our implementation uses standard back-propagation, hence it is highly efficient. While preserving predictive performance, our proposed method leverages weakly annotated medical imaging data and provides complete and faithful explanations to the model's prediction.
Luminance Attentive Networks for HDR Image and Panorama Reconstruction
Sep 14, 2021
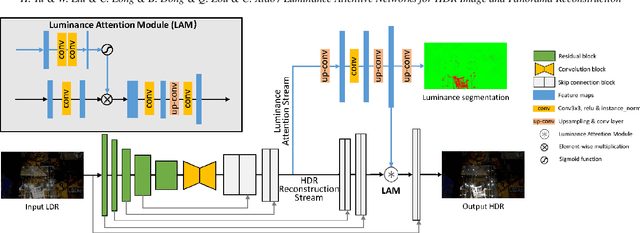
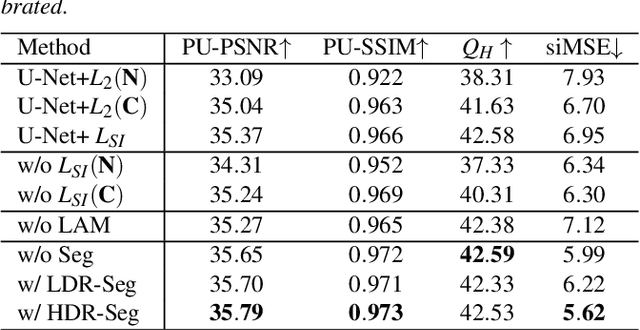
It is very challenging to reconstruct a high dynamic range (HDR) from a low dynamic range (LDR) image as an ill-posed problem. This paper proposes a luminance attentive network named LANet for HDR reconstruction from a single LDR image. Our method is based on two fundamental observations: (1) HDR images stored in relative luminance are scale-invariant, which means the HDR images will hold the same information when multiplied by any positive real number. Based on this observation, we propose a novel normalization method called " HDR calibration " for HDR images stored in relative luminance, calibrating HDR images into a similar luminance scale according to the LDR images. (2) The main difference between HDR images and LDR images is in under-/over-exposed areas, especially those highlighted. Following this observation, we propose a luminance attention module with a two-stream structure for LANet to pay more attention to the under-/over-exposed areas. In addition, we propose an extended network called panoLANet for HDR panorama reconstruction from an LDR panorama and build a dualnet structure for panoLANet to solve the distortion problem caused by the equirectangular panorama. Extensive experiments show that our proposed approach LANet can reconstruct visually convincing HDR images and demonstrate its superiority over state-of-the-art approaches in terms of all metrics in inverse tone mapping. The image-based lighting application with our proposed panoLANet also demonstrates that our method can simulate natural scene lighting using only LDR panorama. Our source code is available at https://github.com/LWT3437/LANet.
Watermark Vaccine: Adversarial Attacks to Prevent Watermark Removal
Jul 17, 2022
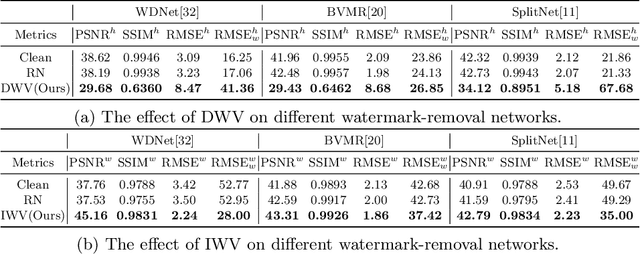
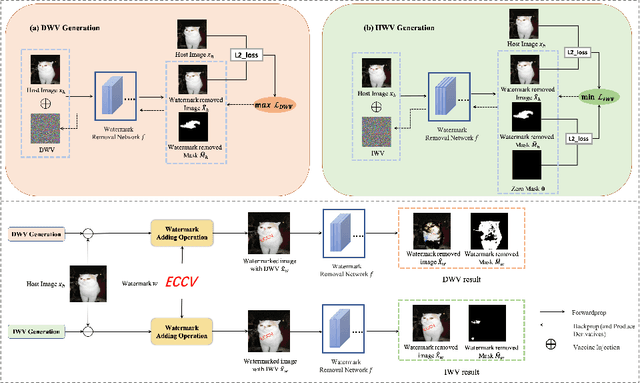

As a common security tool, visible watermarking has been widely applied to protect copyrights of digital images. However, recent works have shown that visible watermarks can be removed by DNNs without damaging their host images. Such watermark-removal techniques pose a great threat to the ownership of images. Inspired by the vulnerability of DNNs on adversarial perturbations, we propose a novel defence mechanism by adversarial machine learning for good. From the perspective of the adversary, blind watermark-removal networks can be posed as our target models; then we actually optimize an imperceptible adversarial perturbation on the host images to proactively attack against watermark-removal networks, dubbed Watermark Vaccine. Specifically, two types of vaccines are proposed. Disrupting Watermark Vaccine (DWV) induces to ruin the host image along with watermark after passing through watermark-removal networks. In contrast, Inerasable Watermark Vaccine (IWV) works in another fashion of trying to keep the watermark not removed and still noticeable. Extensive experiments demonstrate the effectiveness of our DWV/IWV in preventing watermark removal, especially on various watermark removal networks.
WG-VITON: Wearing-Guide Virtual Try-On for Top and Bottom Clothes
May 10, 2022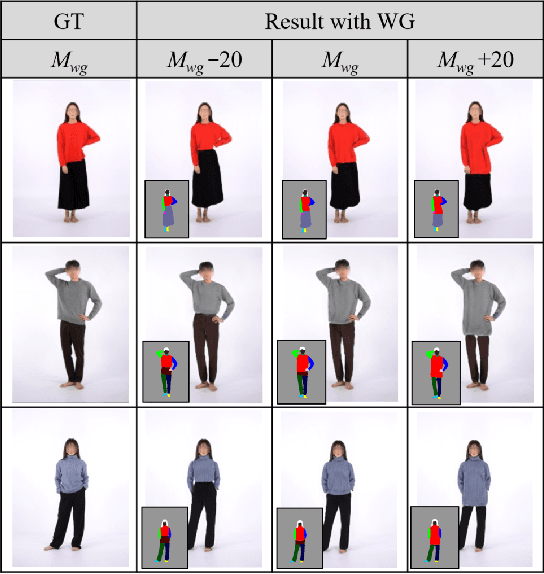
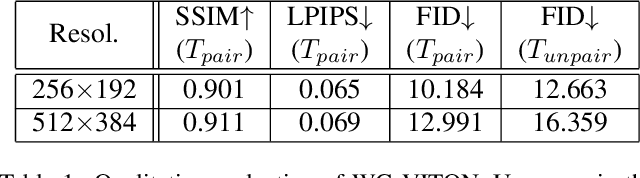
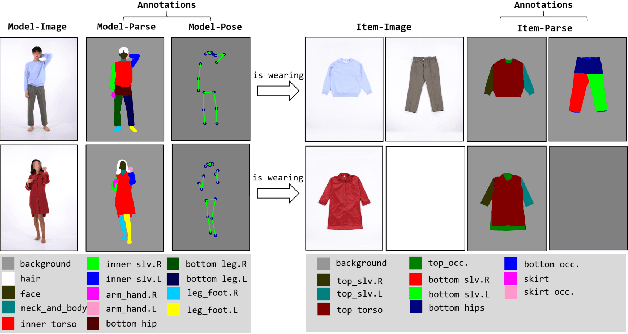
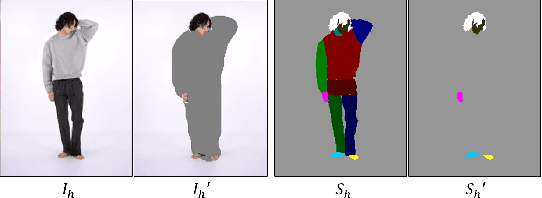
Studies of virtual try-on (VITON) have been shown their effectiveness in utilizing the generative neural network for virtually exploring fashion products, and some of recent researches of VITON attempted to synthesize human image wearing given multiple types of garments (e.g., top and bottom clothes). However, when replacing the top and bottom clothes of the target human, numerous wearing styles are possible with a certain combination of the clothes. In this paper, we address the problem of variation in wearing style when simultaneously replacing the top and bottom clothes of the model. We introduce Wearing-Guide VITON (i.e., WG-VITON) which utilizes an additional input binary mask to control the wearing styles of the generated image. Our experiments show that WG-VITON effectively generates an image of the model wearing given top and bottom clothes, and create complicated wearing styles such as partly tucking in the top to the bottom
Unsupervised Deep Learning Meets Chan-Vese Model
Apr 14, 2022

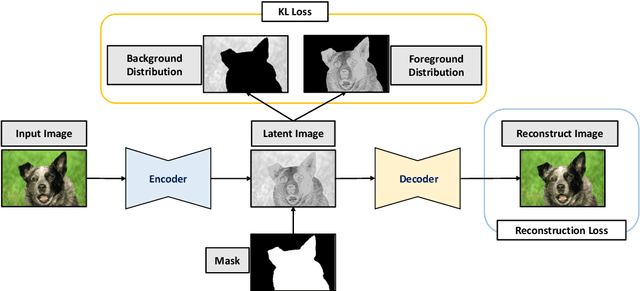
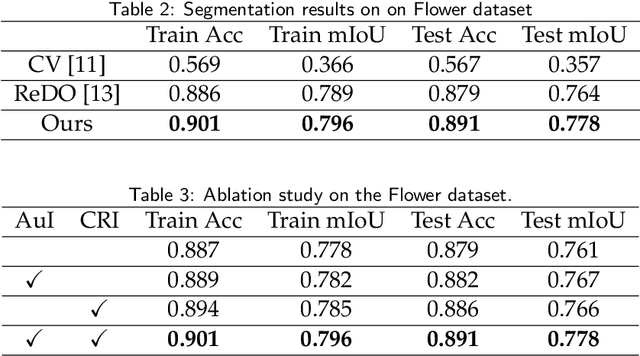
The Chan-Vese (CV) model is a classic region-based method in image segmentation. However, its piecewise constant assumption does not always hold for practical applications. Many improvements have been proposed but the issue is still far from well solved. In this work, we propose an unsupervised image segmentation approach that integrates the CV model with deep neural networks, which significantly improves the original CV model's segmentation accuracy. Our basic idea is to apply a deep neural network that maps the image into a latent space to alleviate the violation of the piecewise constant assumption in image space. We formulate this idea under the classic Bayesian framework by approximating the likelihood with an evidence lower bound (ELBO) term while keeping the prior term in the CV model. Thus, our model only needs the input image itself and does not require pre-training from external datasets. Moreover, we extend the idea to multi-phase case and dataset based unsupervised image segmentation. Extensive experiments validate the effectiveness of our model and show that the proposed method is noticeably better than other unsupervised segmentation approaches.
Instance Shadow Detection with A Single-Stage Detector
Jul 11, 2022



This paper formulates a new problem, instance shadow detection, which aims to detect shadow instance and the associated object instance that cast each shadow in the input image. To approach this task, we first compile a new dataset with the masks for shadow instances, object instances, and shadow-object associations. We then design an evaluation metric for quantitative evaluation of the performance of instance shadow detection. Further, we design a single-stage detector to perform instance shadow detection in an end-to-end manner, where the bidirectional relation learning module and the deformable maskIoU head are proposed in the detector to directly learn the relation between shadow instances and object instances and to improve the accuracy of the predicted masks. Finally, we quantitatively and qualitatively evaluate our method on the benchmark dataset of instance shadow detection and show the applicability of our method on light direction estimation and photo editing.
Learning Convolutional Neural Networks in the Frequency Domain
Apr 28, 2022
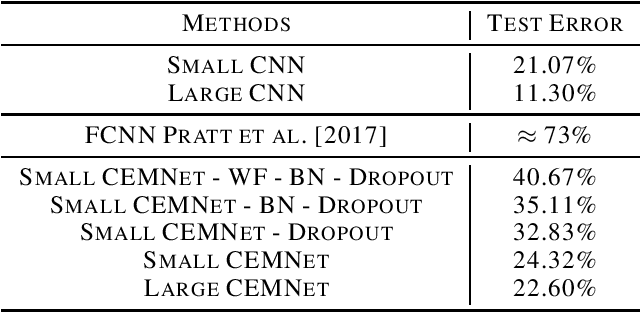
Convolutional neural network (CNN) has achieved impressive success in computer vision during the past few decades. The image convolution operation helps CNNs to get good performance on image-related tasks. However, the image convolution has high computation complexity and hard to be implemented. This paper proposes the CEMNet, which can be trained in the frequency domain. The most important motivation of this research is that we can use the straightforward element-wise multiplication operation to replace the image convolution in the frequency domain based on the Cross-Correlation Theorem, which obviously reduces the computation complexity. We further introduce a Weight Fixation mechanism to alleviate the problem of over-fitting, and analyze the working behavior of Batch Normalization, Leaky ReLU, and Dropout in the frequency domain to design their counterparts for CEMNet. Also, to deal with complex inputs brought by Discrete Fourier Transform, we design a two-branches network structure for CEMNet. Experimental results imply that CEMNet achieves good performance on MNIST and CIFAR-10 databases.
Improved Generative Model for Weakly Supervised Chest Anomaly Localization via Pseudo-paired Registration with Bilaterally Symmetrical Data Augmentation
Jul 21, 2022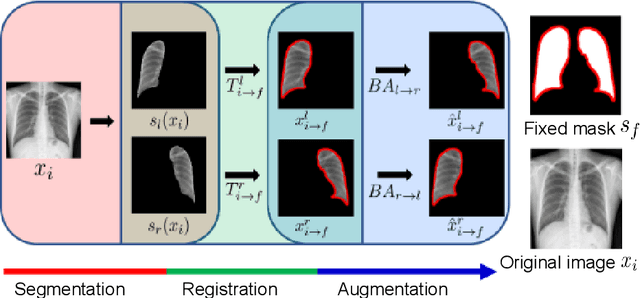

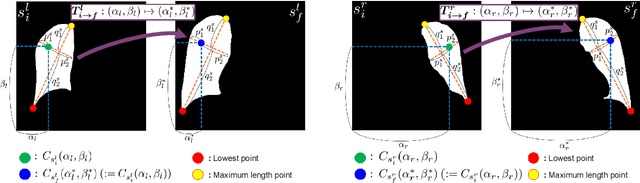
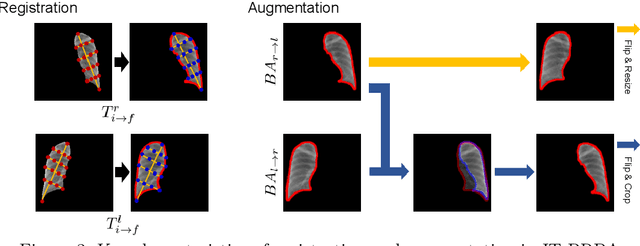
Image translation based on a generative adversarial network (GAN-IT) is a promising method for precise localization of abnormal regions in chest X-ray images (AL-CXR). However, heterogeneous unpaired datasets undermine existing methods to extract key features and distinguish normal from abnormal cases, resulting in inaccurate and unstable AL-CXR. To address this problem, we propose an improved two-stage GAN-IT involving registration and data augmentation. For the first stage, we introduce an invertible deep-learning-based registration technique that virtually and reasonably converts unpaired data into paired data for learning registration maps. This novel approach achieves high registration performance. For the second stage, we apply data augmentation to diversify anomaly locations by swapping the left and right lung regions on the uniform registered frames, further improving the performance by alleviating imbalance in data distribution showing left and right lung lesions. Our method is intended for application to existing GAN-IT models, allowing existing architecture to benefit from key features for translation. By showing that the AL-CXR performance is uniformly improved when applying the proposed method, we believe that GAN-IT for AL-CXR can be deployed in clinical environments, even if learning data are scarce.