 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators
Aug 02, 2021

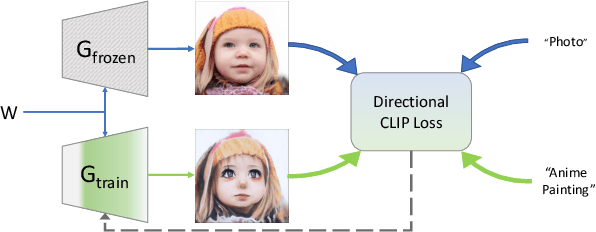
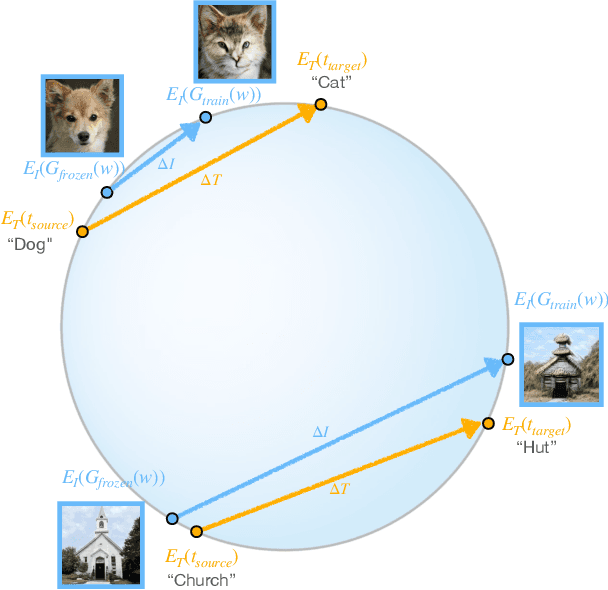
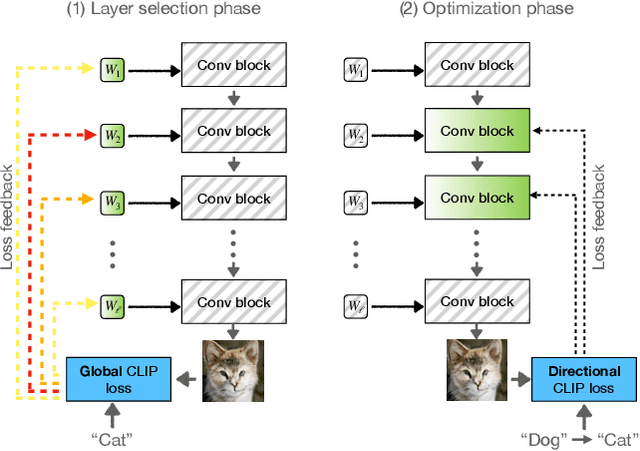
Can a generative model be trained to produce images from a specific domain, guided by a text prompt only, without seeing any image? In other words: can an image generator be trained blindly? Leveraging the semantic power of large scale Contrastive-Language-Image-Pre-training (CLIP) models, we present a text-driven method that allows shifting a generative model to new domains, without having to collect even a single image from those domains. We show that through natural language prompts and a few minutes of training, our method can adapt a generator across a multitude of domains characterized by diverse styles and shapes. Notably, many of these modifications would be difficult or outright impossible to reach with existing methods. We conduct an extensive set of experiments and comparisons across a wide range of domains. These demonstrate the effectiveness of our approach and show that our shifted models maintain the latent-space properties that make generative models appealing for downstream tasks.
Hamiltonian prior to Disentangle Content and Motion in Image Sequences
Dec 02, 2021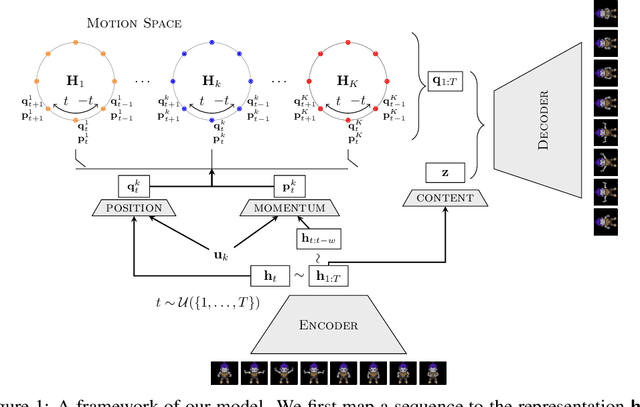
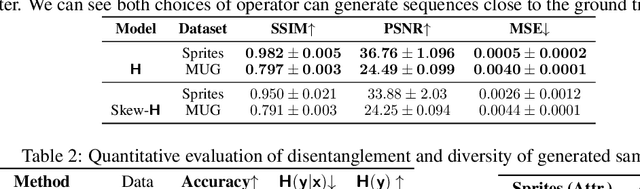


We present a deep latent variable model for high dimensional sequential data. Our model factorises the latent space into content and motion variables. To model the diverse dynamics, we split the motion space into subspaces, and introduce a unique Hamiltonian operator for each subspace. The Hamiltonian formulation provides reversible dynamics that learn to constrain the motion path to conserve invariant properties. The explicit split of the motion space decomposes the Hamiltonian into symmetry groups and gives long-term separability of the dynamics. This split also means representations can be learnt that are easy to interpret and control. We demonstrate the utility of our model for swapping the motion of two videos, generating sequences of various actions from a given image and unconditional sequence generation.
One-Trimap Video Matting
Jul 27, 2022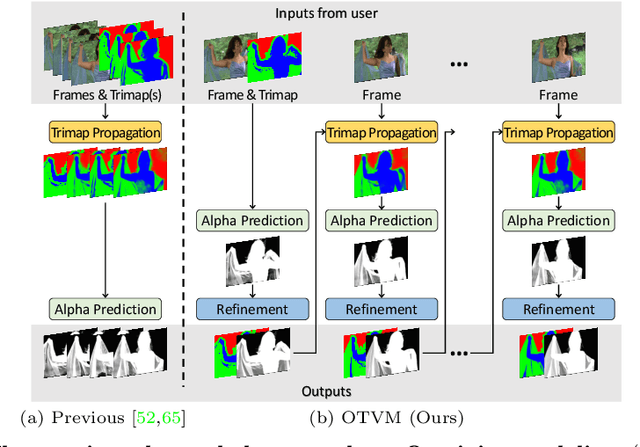
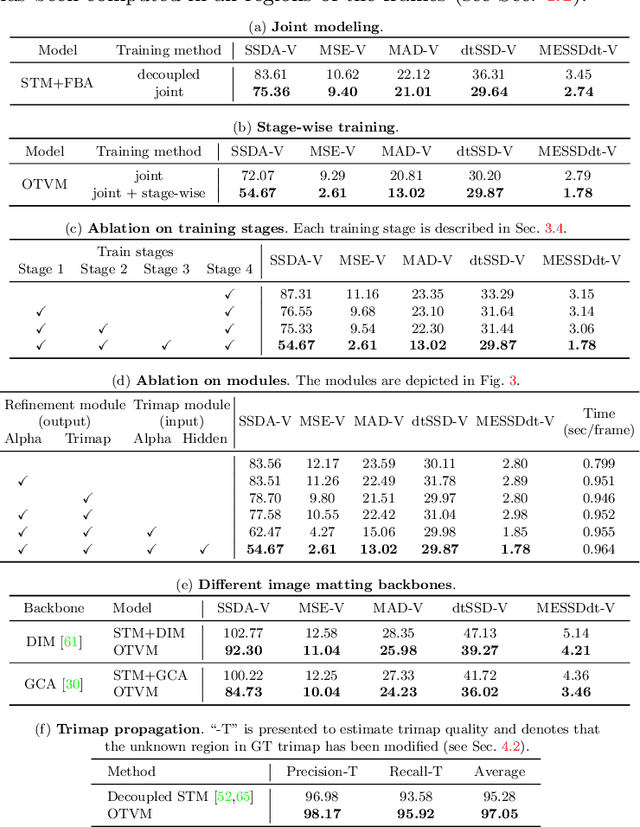
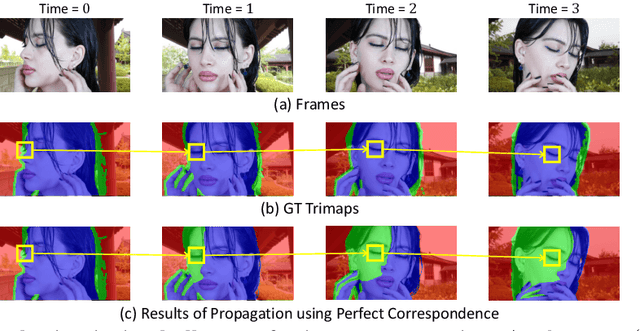
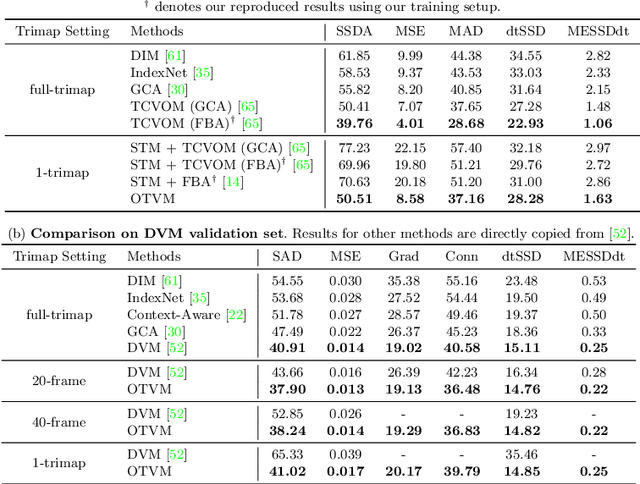
Recent studies made great progress in video matting by extending the success of trimap-based image matting to the video domain. In this paper, we push this task toward a more practical setting and propose One-Trimap Video Matting network (OTVM) that performs video matting robustly using only one user-annotated trimap. A key of OTVM is the joint modeling of trimap propagation and alpha prediction. Starting from baseline trimap propagation and alpha prediction networks, our OTVM combines the two networks with an alpha-trimap refinement module to facilitate information flow. We also present an end-to-end training strategy to take full advantage of the joint model. Our joint modeling greatly improves the temporal stability of trimap propagation compared to the previous decoupled methods. We evaluate our model on two latest video matting benchmarks, Deep Video Matting and VideoMatting108, and outperform state-of-the-art by significant margins (MSE improvements of 56.4% and 56.7%, respectively). The source code and model are available online: https://github.com/Hongje/OTVM.
Few-Shot Unsupervised Image-to-Image Translation on complex scenes
Jun 07, 2021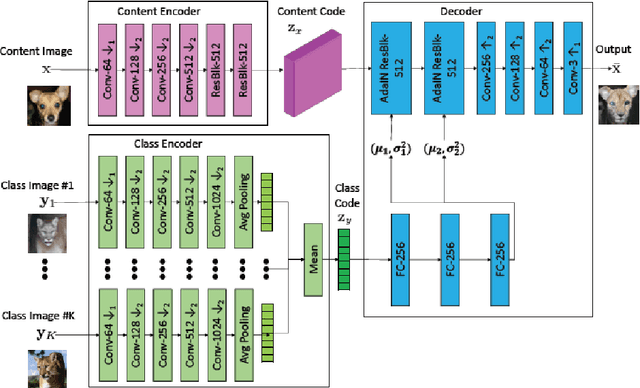

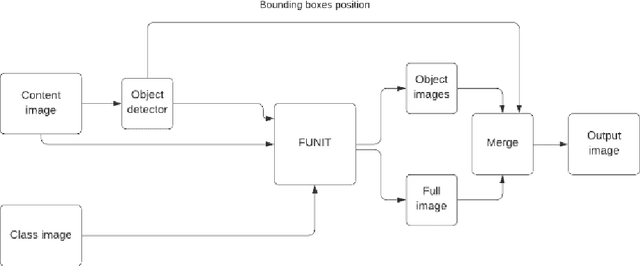
Unsupervised image-to-image translation methods have received a lot of attention in the last few years. Multiple techniques emerged tackling the initial challenge from different perspectives. Some focus on learning as much as possible from several target style images for translations while other make use of object detection in order to produce more realistic results on content-rich scenes. In this work, we assess how a method that has initially been developed for single object translation performs on more diverse and content-rich images. Our work is based on the FUNIT[1] framework and we train it with a more diverse dataset. This helps understanding how such method behaves beyond their initial frame of application. We present a way to extend a dataset based on object detection. Moreover, we propose a way to adapt the FUNIT framework in order to leverage the power of object detection that one can see in other methods.
From Heatmaps to Structural Explanations of Image Classifiers
Sep 13, 2021
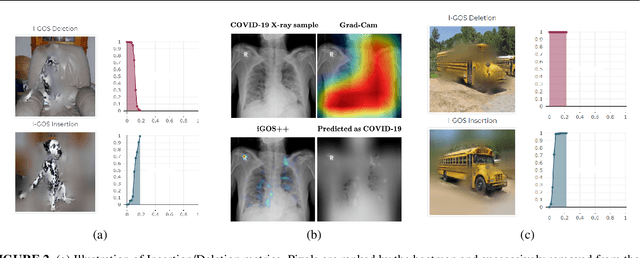

This paper summarizes our endeavors in the past few years in terms of explaining image classifiers, with the aim of including negative results and insights we have gained. The paper starts with describing the explainable neural network (XNN), which attempts to extract and visualize several high-level concepts purely from the deep network, without relying on human linguistic concepts. This helps users understand network classifications that are less intuitive and substantially improves user performance on a difficult fine-grained classification task of discriminating among different species of seagulls. Realizing that an important missing piece is a reliable heatmap visualization tool, we have developed I-GOS and iGOS++ utilizing integrated gradients to avoid local optima in heatmap generation, which improved the performance across all resolutions. During the development of those visualizations, we realized that for a significant number of images, the classifier has multiple different paths to reach a confident prediction. This has lead to our recent development of structured attention graphs (SAGs), an approach that utilizes beam search to locate multiple coarse heatmaps for a single image, and compactly visualizes a set of heatmaps by capturing how different combinations of image regions impact the confidence of a classifier. Through the research process, we have learned much about insights in building deep network explanations, the existence and frequency of multiple explanations, and various tricks of the trade that make explanations work. In this paper, we attempt to share those insights and opinions with the readers with the hope that some of them will be informative for future researchers on explainable deep learning.
FA-GAN: Feature-Aware GAN for Text to Image Synthesis
Sep 02, 2021

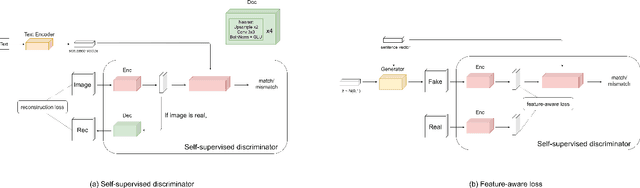

Text-to-image synthesis aims to generate a photo-realistic image from a given natural language description. Previous works have made significant progress with Generative Adversarial Networks (GANs). Nonetheless, it is still hard to generate intact objects or clear textures (Fig 1). To address this issue, we propose Feature-Aware Generative Adversarial Network (FA-GAN) to synthesize a high-quality image by integrating two techniques: a self-supervised discriminator and a feature-aware loss. First, we design a self-supervised discriminator with an auxiliary decoder so that the discriminator can extract better representation. Secondly, we introduce a feature-aware loss to provide the generator more direct supervision by employing the feature representation from the self-supervised discriminator. Experiments on the MS-COCO dataset show that our proposed method significantly advances the state-of-the-art FID score from 28.92 to 24.58.
Illumination Adaptive Transformer
May 30, 2022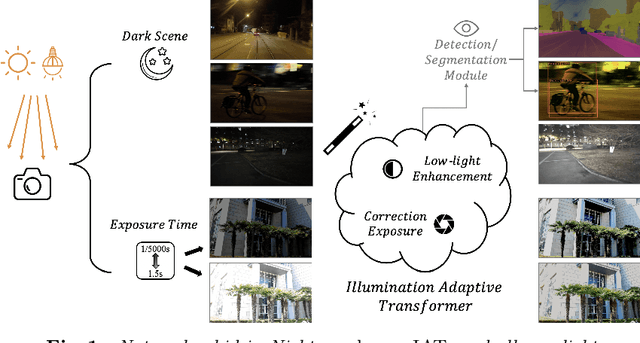
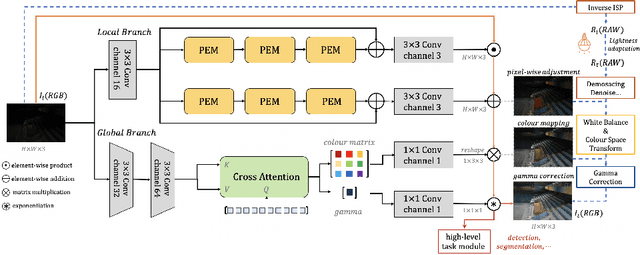
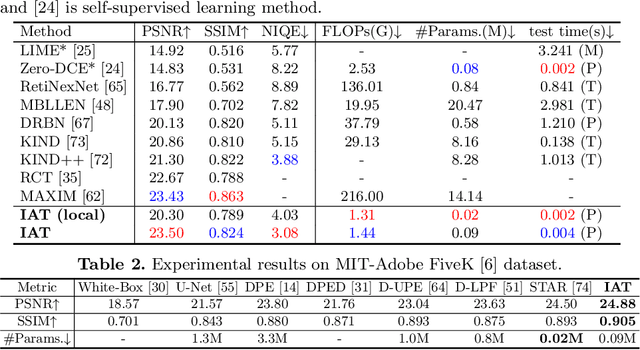
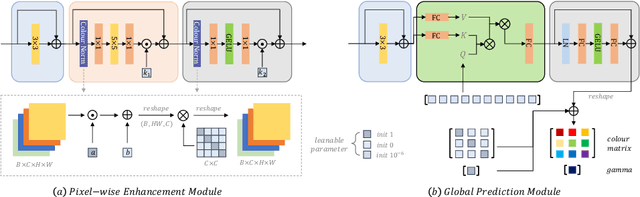
Challenging illumination conditions (low light, underexposure and overexposure) in the real world not only cast an unpleasant visual appearance but also taint the computer vision tasks. Existing light adaptive methods often deal with each condition individually. What is more, most of them often operate on a RAW image or over-simplify the camera image signal processing (ISP) pipeline. By decomposing the light transformation pipeline into local and global ISP components, we propose a lightweight fast Illumination Adaptive Transformer (IAT) which comprises two transformer-style branches: local estimation branch and global ISP branch. While the local branch estimates the pixel-wise local components relevant to illumination, the global branch defines learnable quires that attend the whole image to decode the parameters. Our IAT could also conduct both object detection and semantic segmentation under various light conditions. We have extensively evaluated IAT on multiple real-world datasets on 2 low-level tasks and 3 high-level tasks. With only 90k parameters and 0.004s processing speed (excluding high-level module), our IAT has consistently achieved superior performance over SOTA. Code is available at https://github.com/cuiziteng/IlluminationAdaptive-Transformer.
Edge-preserving Near-light Photometric Stereo with Neural Surfaces
Jul 11, 2022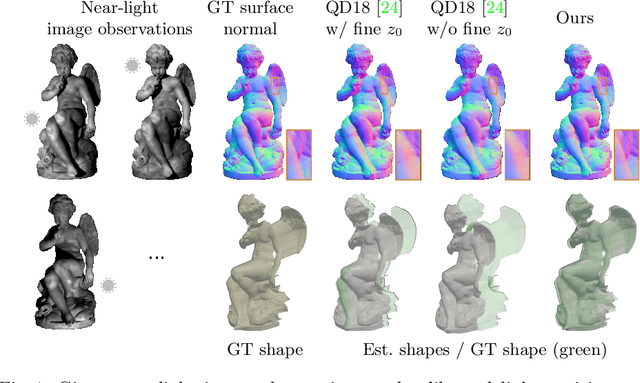
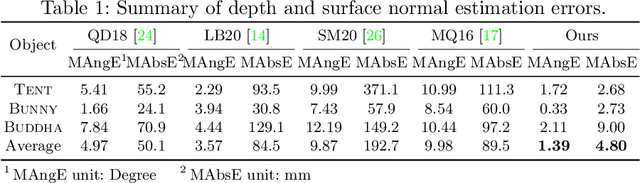
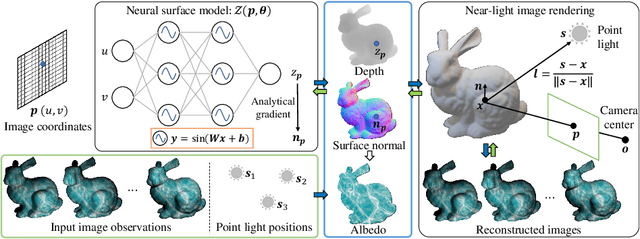
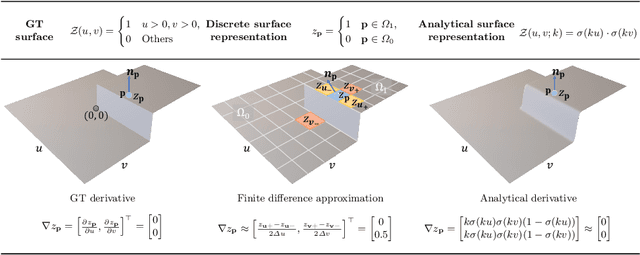
This paper presents a near-light photometric stereo method that faithfully preserves sharp depth edges in the 3D reconstruction. Unlike previous methods that rely on finite differentiation for approximating depth partial derivatives and surface normals, we introduce an analytically differentiable neural surface in near-light photometric stereo for avoiding differentiation errors at sharp depth edges, where the depth is represented as a neural function of the image coordinates. By further formulating the Lambertian albedo as a dependent variable resulting from the surface normal and depth, our method is insusceptible to inaccurate depth initialization. Experiments on both synthetic and real-world scenes demonstrate the effectiveness of our method for detailed shape recovery with edge preservation.
OCFormer: One-Class Transformer Network for Image Classification
Apr 25, 2022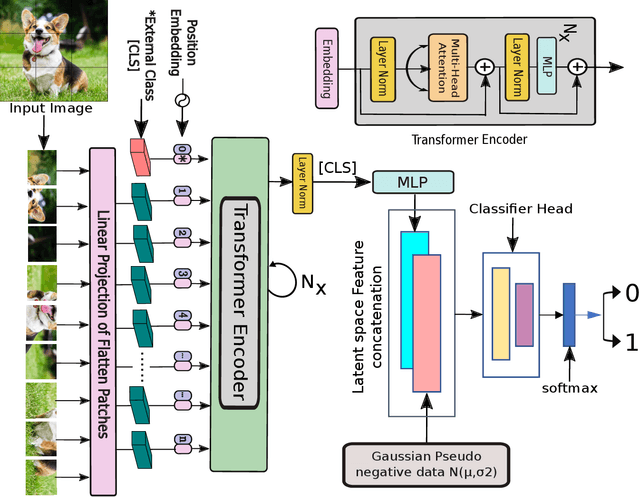
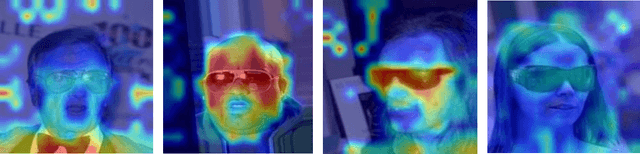
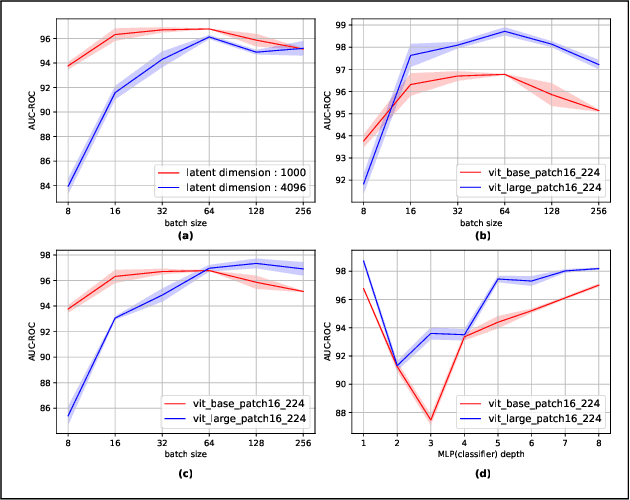
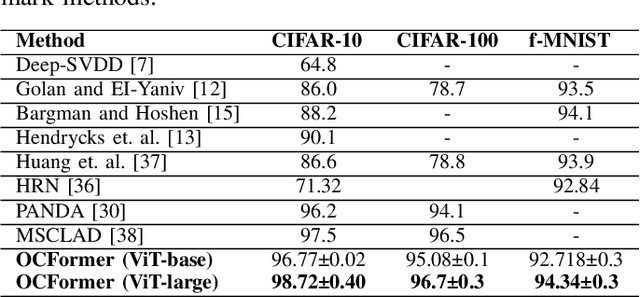
We propose a novel deep learning framework based on Vision Transformers (ViT) for one-class classification. The core idea is to use zero-centered Gaussian noise as a pseudo-negative class for latent space representation and then train the network using the optimal loss function. In prior works, there have been tremendous efforts to learn a good representation using varieties of loss functions, which ensures both discriminative and compact properties. The proposed one-class Vision Transformer (OCFormer) is exhaustively experimented on CIFAR-10, CIFAR-100, Fashion-MNIST and CelebA eyeglasses datasets. Our method has shown significant improvements over competing CNN based one-class classifier approaches.
Leveraging Smartphone Sensors for Detecting Abnormal Gait for Smart Wearable Mobile Technologies
Aug 03, 2022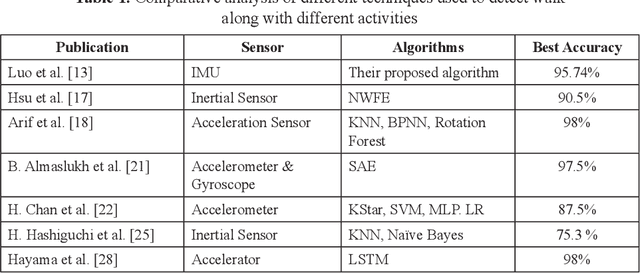
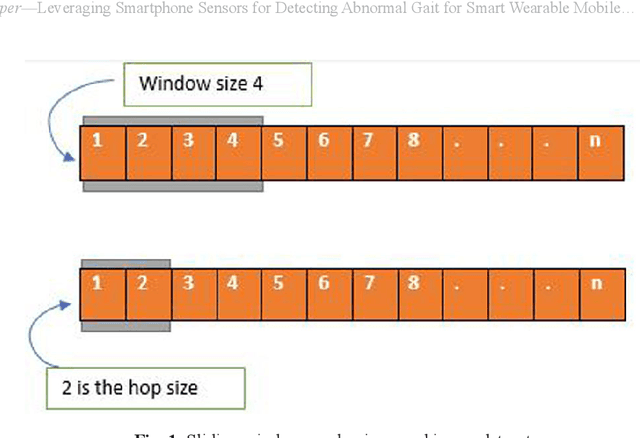
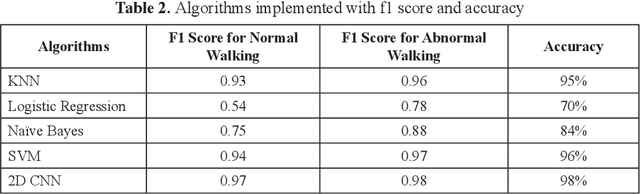
Walking is one of the most common modes of terrestrial locomotion for humans. Walking is essential for humans to perform most kinds of daily activities. When a person walks, there is a pattern in it, and it is known as gait. Gait analysis is used in sports and healthcare. We can analyze this gait in different ways, like using video captured by the surveillance cameras or depth image cameras in the lab environment. It also can be recognized by wearable sensors. e.g., accelerometer, force sensors, gyroscope, flexible goniometer, magneto resistive sensors, electromagnetic tracking system, force sensors, and electromyography (EMG). Analysis through these sensors required a lab condition, or users must wear these sensors. For detecting abnormality in gait action of a human, we need to incorporate the sensors separately. We can know about one's health condition by abnormal human gait after detecting it. Understanding a regular gait vs. abnormal gait may give insights to the health condition of the subject using the smart wearable technologies. Therefore, in this paper, we proposed a way to analyze abnormal human gait through smartphone sensors. Though smart devices like smartphones and smartwatches are used by most of the person nowadays. So, we can track down their gait using sensors of these intelligent wearable devices.