 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SHREC 2022: pothole and crack detection in the road pavement using images and RGB-D data
May 27, 2022
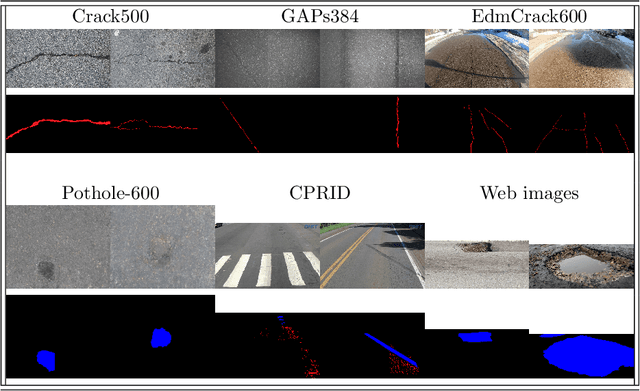
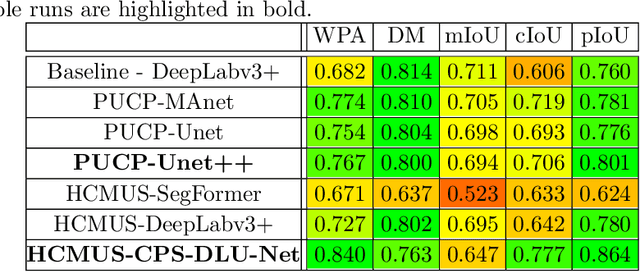

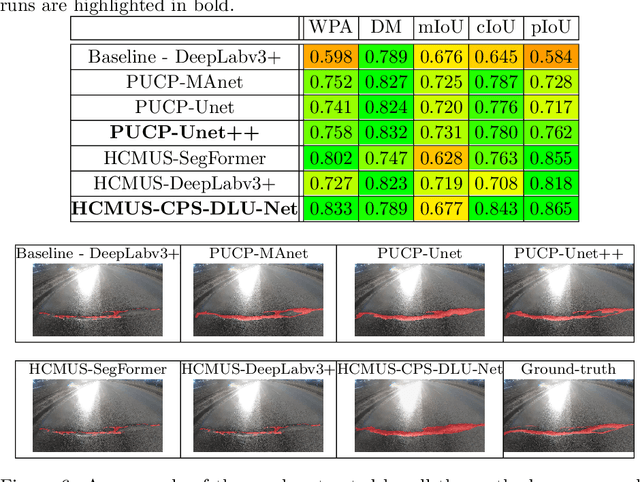
This paper describes the methods submitted for evaluation to the SHREC 2022 track on pothole and crack detection in the road pavement. A total of 7 different runs for the semantic segmentation of the road surface are compared, 6 from the participants plus a baseline method. All methods exploit Deep Learning techniques and their performance is tested using the same environment (i.e.: a single Jupyter notebook). A training set, composed of 3836 semantic segmentation image/mask pairs and 797 RGB-D video clips collected with the latest depth cameras was made available to the participants. The methods are then evaluated on the 496 image/mask pairs in the validation set, on the 504 pairs in the test set and finally on 8 video clips. The analysis of the results is based on quantitative metrics for image segmentation and qualitative analysis of the video clips. The participation and the results show that the scenario is of great interest and that the use of RGB-D data is still challenging in this context.
Is current research on adversarial robustness addressing the right problem?
Aug 04, 2022
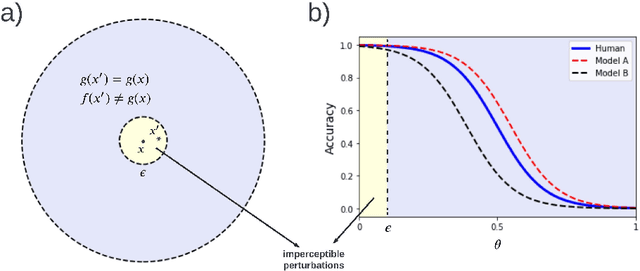
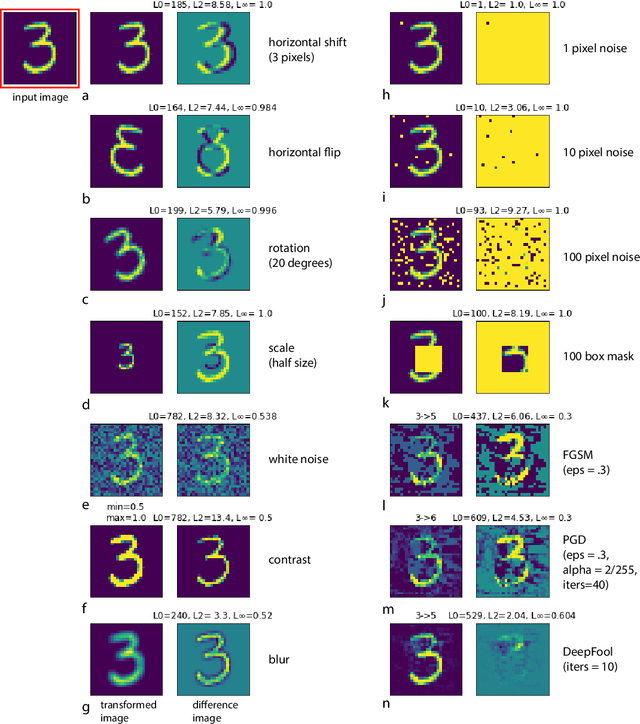
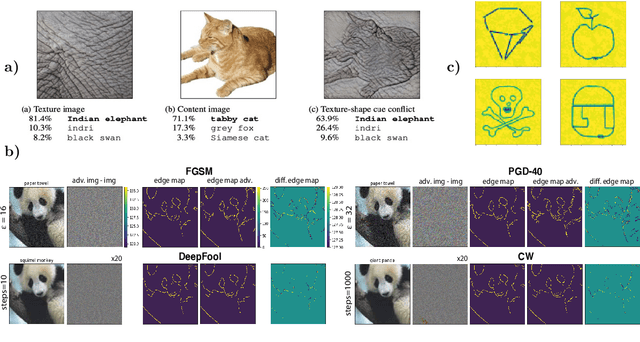
Short answer: Yes, Long answer: No! Indeed, research on adversarial robustness has led to invaluable insights helping us understand and explore different aspects of the problem. Many attacks and defenses have been proposed over the last couple of years. The problem, however, remains largely unsolved and poorly understood. Here, I argue that the current formulation of the problem serves short term goals, and needs to be revised for us to achieve bigger gains. Specifically, the bound on perturbation has created a somewhat contrived setting and needs to be relaxed. This has misled us to focus on model classes that are not expressive enough to begin with. Instead, inspired by human vision and the fact that we rely more on robust features such as shape, vertices, and foreground objects than non-robust features such as texture, efforts should be steered towards looking for significantly different classes of models. Maybe instead of narrowing down on imperceptible adversarial perturbations, we should attack a more general problem which is finding architectures that are simultaneously robust to perceptible perturbations, geometric transformations (e.g. rotation, scaling), image distortions (lighting, blur), and more (e.g. occlusion, shadow). Only then we may be able to solve the problem of adversarial vulnerability.
Contour-guided Image Completion with Perceptual Grouping
Nov 22, 2021
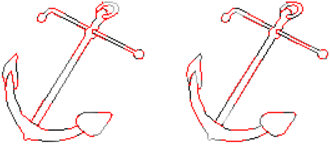

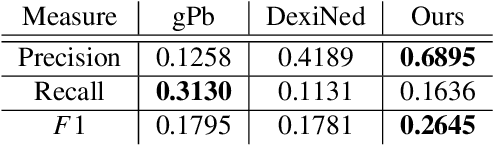
Humans are excellent at perceiving illusory outlines. We are readily able to complete contours, shapes, scenes, and even unseen objects when provided with images that contain broken fragments of a connected appearance. In vision science, this ability is largely explained by perceptual grouping: a foundational set of processes in human vision that describes how separated elements can be grouped. In this paper, we revisit an algorithm called Stochastic Completion Fields (SCFs) that mechanizes a set of such processes -- good continuity, closure, and proximity -- through contour completion. This paper implements a modernized model of the SCF algorithm, and uses it in an image editing framework where we propose novel methods to complete fragmented contours. We show how the SCF algorithm plausibly mimics results in human perception. We use the SCF completed contours as guides for inpainting, and show that our guides improve the performance of state-of-the-art models. Additionally, we show that the SCF aids in finding edges in high-noise environments. Overall, our described algorithms resemble an important mechanism in the human visual system, and offer a novel framework that modern computer vision models can benefit from.
Single Underwater Image Enhancement Using an Analysis-Synthesis Network
Aug 20, 2021



Most deep models for underwater image enhancement resort to training on synthetic datasets based on underwater image formation models. Although promising performances have been achieved, they are still limited by two problems: (1) existing underwater image synthesis models have an intrinsic limitation, in which the homogeneous ambient light is usually randomly generated and many important dependencies are ignored, and thus the synthesized training data cannot adequately express characteristics of real underwater environments; (2) most of deep models disregard lots of favorable underwater priors and heavily rely on training data, which extensively limits their application ranges. To address these limitations, a new underwater synthetic dataset is first established, in which a revised ambient light synthesis equation is embedded. The revised equation explicitly defines the complex mathematical relationship among intensity values of the ambient light in RGB channels and many dependencies such as surface-object depth, water types, etc, which helps to better simulate real underwater scene appearances. Secondly, a unified framework is proposed, named ANA-SYN, which can effectively enhance underwater images under collaborations of priors (underwater domain knowledge) and data information (underwater distortion distribution). The proposed framework includes an analysis network and a synthesis network, one for priors exploration and another for priors integration. To exploit more accurate priors, the significance of each prior for the input image is explored in the analysis network and an adaptive weighting module is designed to dynamically recalibrate them. Meanwhile, a novel prior guidance module is introduced in the synthesis network, which effectively aggregates the prior and data features and thus provides better hybrid information to perform the more reasonable image enhancement.
Frequency-Aware Physics-Inspired Degradation Model for Real-World Image Super-Resolution
Nov 05, 2021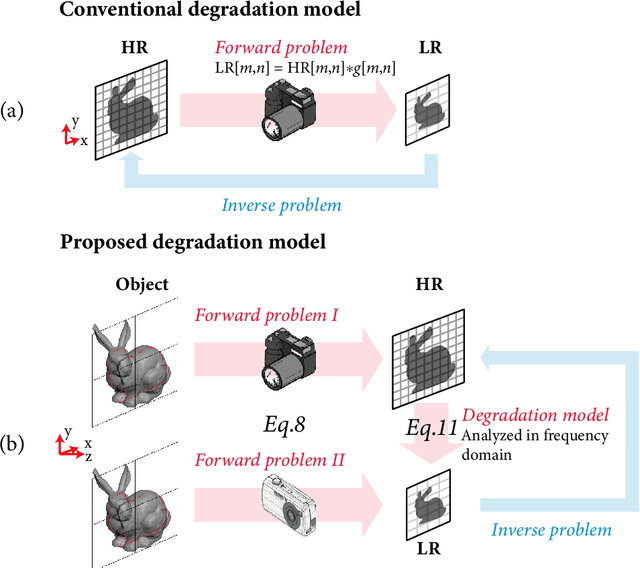

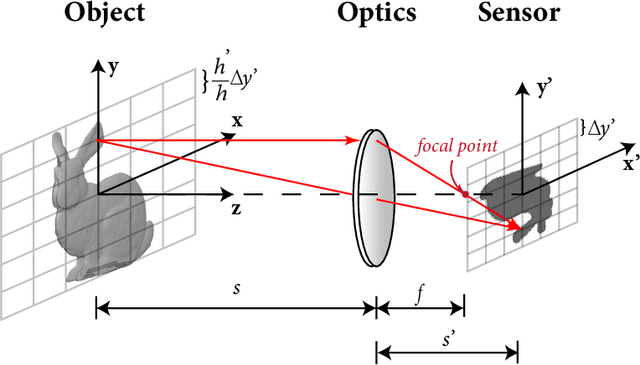
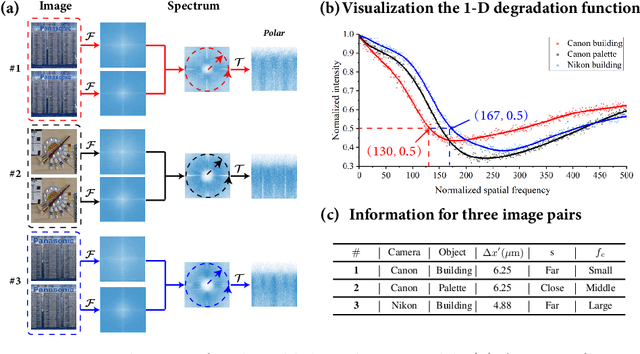
Current learning-based single image super-resolution (SISR) algorithms underperform on real data due to the deviation in the assumed degrada-tion process from that in the real-world scenario. Conventional degradation processes consider applying blur, noise, and downsampling (typicallybicubic downsampling) on high-resolution (HR) images to synthesize low-resolution (LR) counterparts. However, few works on degradation modelling have taken the physical aspects of the optical imaging system intoconsideration. In this paper, we analyze the imaging system optically andexploit the characteristics of the real-world LR-HR pairs in the spatial frequency domain. We formulate a real-world physics-inspired degradationmodel by considering bothopticsandsensordegradation; The physical degradation of an imaging system is modelled as a low-pass filter, whose cut-off frequency is dictated by the object distance, the focal length of thelens, and the pixel size of the image sensor. In particular, we propose to use a convolutional neural network (CNN) to learn the cutoff frequency of real-world degradation process. The learned network is then applied to synthesize LR images from unpaired HR images. The synthetic HR-LR image pairs are later used to train an SISR network. We evaluatethe effectiveness and generalization capability of the proposed degradation model on real-world images captured by different imaging systems. Experimental results showcase that the SISR network trained by using our synthetic data performs favorably against the network using the traditional degradation model. Moreover, our results are comparable to that obtained by the same network trained by using real-world LR-HR pairs, which are challenging to obtain in real scenes.
VPIT: Real-time Embedded Single Object 3D Tracking Using Voxel Pseudo Images
Jun 06, 2022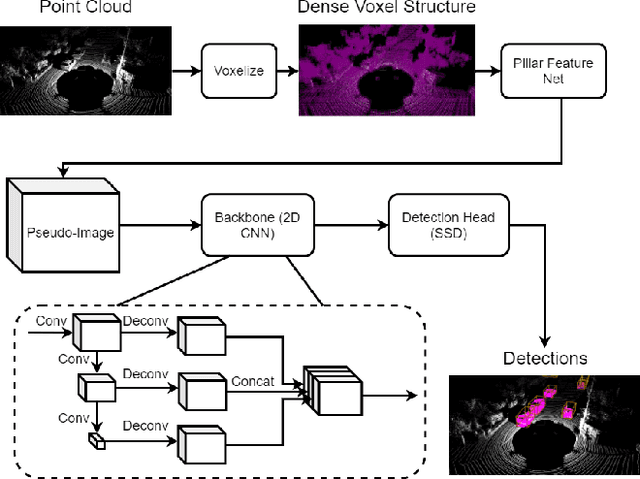
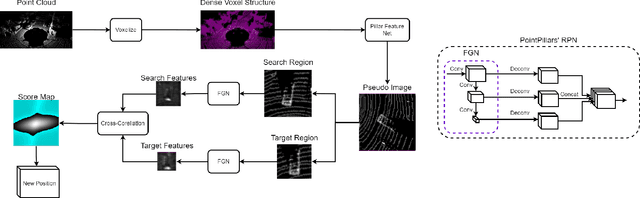


In this paper, we propose a novel voxel-based 3D single object tracking (3D SOT) method called Voxel Pseudo Image Tracking (VPIT). VPIT is the first method that uses voxel pseudo images for 3D SOT. The input point cloud is structured by pillar-based voxelization, and the resulting pseudo image is used as an input to a 2D-like Siamese SOT method. The pseudo image is created in the Bird's-eye View (BEV) coordinates, and therefore the objects in it have constant size. Thus, only the object rotation can change in the new coordinate system and not the object scale. For this reason, we replace multi-scale search with a multi-rotation search, where differently rotated search regions are compared against a single target representation to predict both position and rotation of the object. Experiments on KITTI Tracking dataset show that VPIT is the fastest 3D SOT method and maintains competitive Success and Precision values. Application of a SOT method in a real-world scenario meets with limitations such as lower computational capabilities of embedded devices and a latency-unforgiving environment, where the method is forced to skip certain data frames if the inference speed is not high enough. We implement a real-time evaluation protocol and show that other methods lose most of their performance on embedded devices, while VPIT maintains its ability to track the object.
Deep Audio Waveform Prior
Jul 21, 2022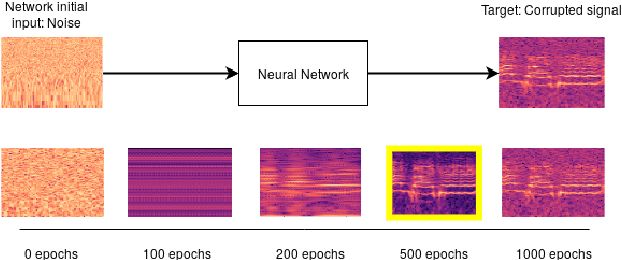
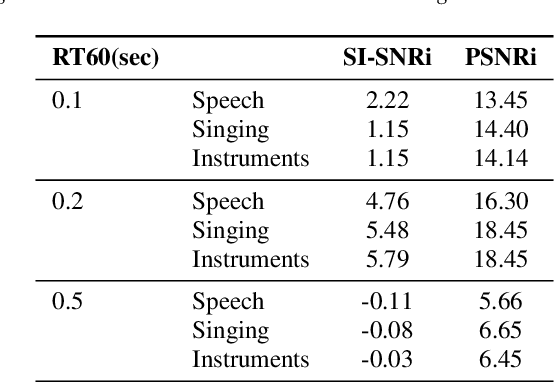
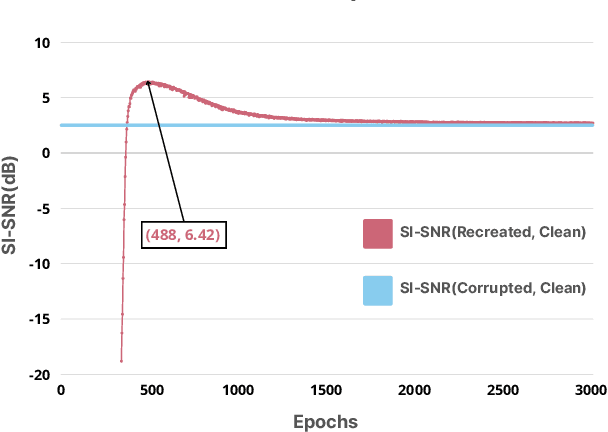
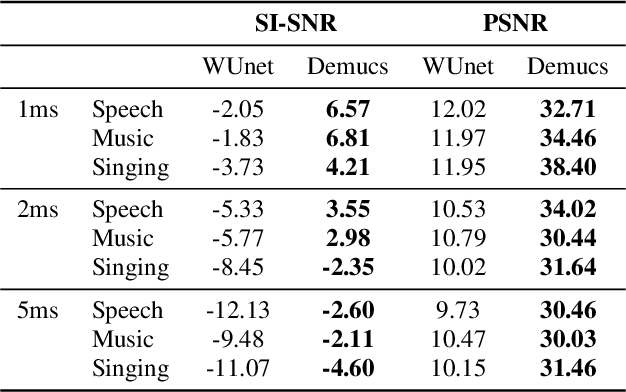
Convolutional neural networks contain strong priors for generating natural looking images [1]. These priors enable image denoising, super resolution, and inpainting in an unsupervised manner. Previous attempts to demonstrate similar ideas in audio, namely deep audio priors, (i) use hand picked architectures such as harmonic convolutions, (ii) only work with spectrogram input, and (iii) have been used mostly for eliminating Gaussian noise [2]. In this work we show that existing SOTA architectures for audio source separation contain deep priors even when working with the raw waveform. Deep priors can be discovered by training a neural network to generate a single corrupted signal when given white noise as input. A network with relevant deep priors is likely to generate a cleaner version of the signal before converging on the corrupted signal. We demonstrate this restoration effect with several corruptions: background noise, reverberations, and a gap in the signal (audio inpainting).
L$_0$onie: Compressing COINs with L$_0$-constraints
Jul 08, 2022



Advances in Implicit Neural Representations (INR) have motivated research on domain-agnostic compression techniques. These methods train a neural network to approximate an object, and then store the weights of the trained model. For example, given an image, a network is trained to learn the mapping from pixel locations to RGB values. In this paper, we propose L$_0$onie, a sparsity-constrained extension of the COIN compression method. Sparsity allows to leverage the faster learning of overparameterized networks, while retaining the desirable compression rate of smaller models. Moreover, our constrained formulation ensures that the final model respects a pre-determined compression rate, dispensing of the need for expensive architecture search.
On the robustness of self-supervised representations for multi-view object classification
Jul 27, 2022
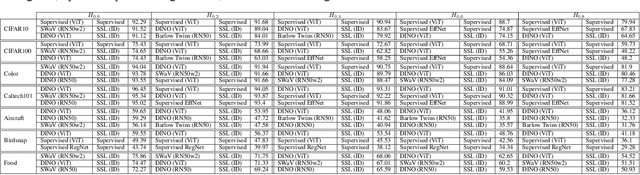
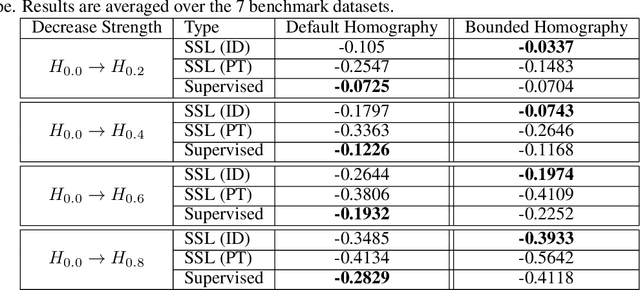
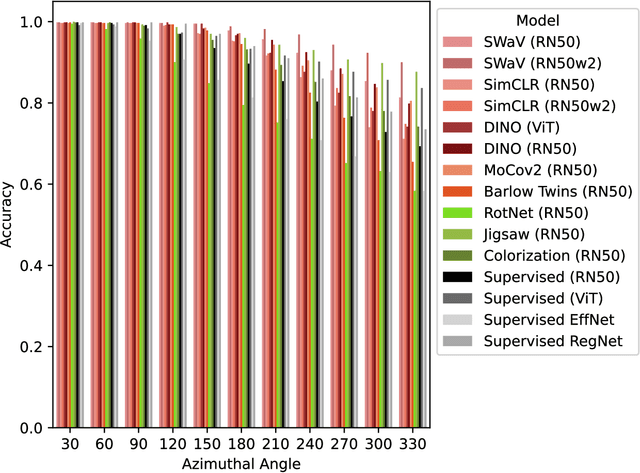
It is known that representations from self-supervised pre-training can perform on par, and often better, on various downstream tasks than representations from fully-supervised pre-training. This has been shown in a host of settings such as generic object classification and detection, semantic segmentation, and image retrieval. However, some issues have recently come to the fore that demonstrate some of the failure modes of self-supervised representations, such as performance on non-ImageNet-like data, or complex scenes. In this paper, we show that self-supervised representations based on the instance discrimination objective lead to better representations of objects that are more robust to changes in the viewpoint and perspective of the object. We perform experiments of modern self-supervised methods against multiple supervised baselines to demonstrate this, including approximating object viewpoint variation through homographies, and real-world tests based on several multi-view datasets. We find that self-supervised representations are more robust to object viewpoint and appear to encode more pertinent information about objects that facilitate the recognition of objects from novel views.
Image scaling by de la Vallée-Poussin filtered interpolation
Sep 28, 2021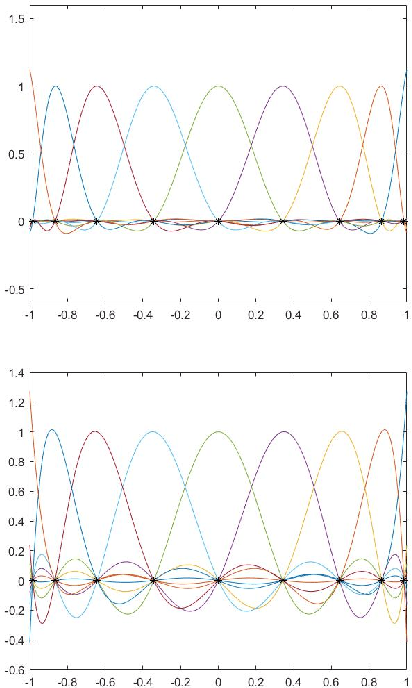
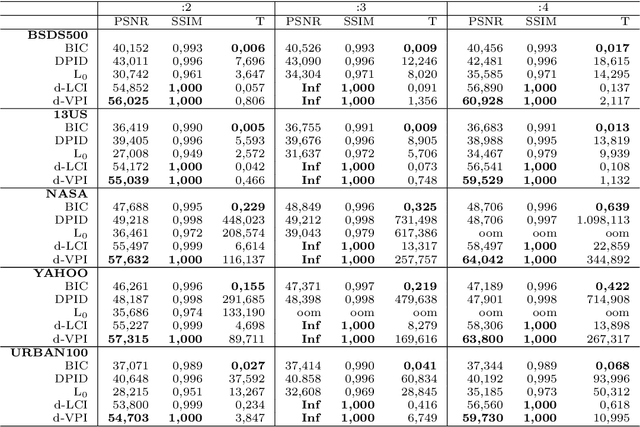
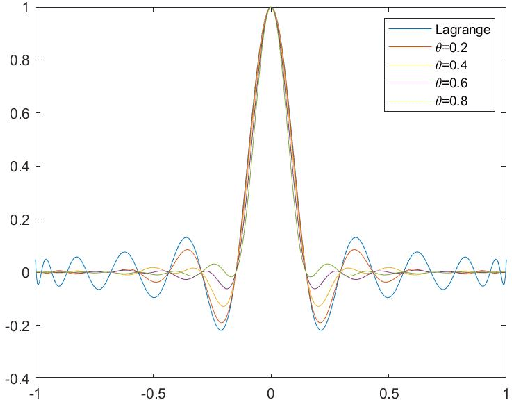
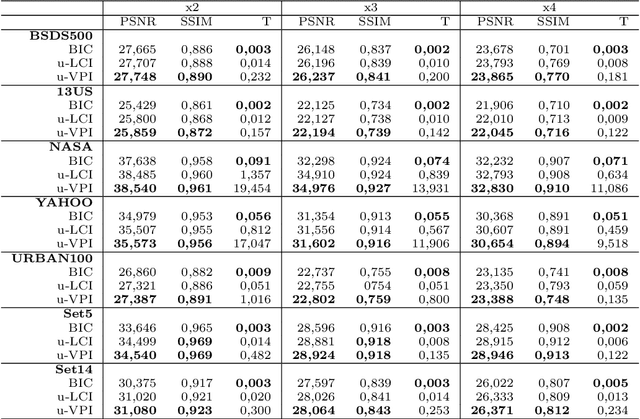
We present a new image scaling method both for downscaling and upscaling, running with any scale factor or desired size. It is based on the sampling of an approximating bivariate polynomial, which globally interpolates the data and is defined by a filter of de la Vall\'ee Poussin type whose action ray is suitable regulated to improve the approximation. The method has been tested on a significant number of different image datasets. The results are evaluated in qualitative and quantitative terms and compared with other available competitive methods. The perceived quality of the resulting scaled images is such that important details are preserved, and the appearance of artifacts is low. Very high-quality measure values in downscaling and the competitive ones in upscaling evidence the effectiveness of the method. Good visual quality, limited computational effort, and moderate memory demanding make the method suitable for real-world applications.