 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Position Labels for Self-Supervised Vision Transformer
Jun 10, 2022
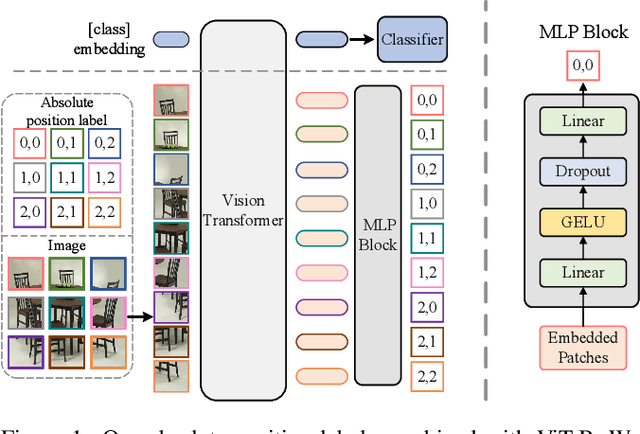
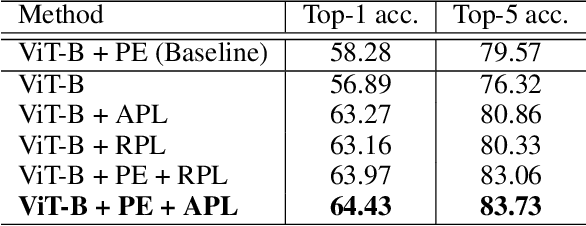
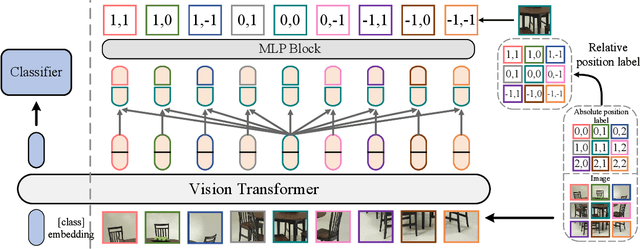
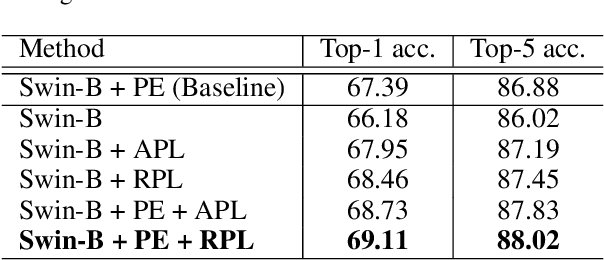
Position encoding is important for vision transformer (ViT) to capture the spatial structure of the input image. General efficacy has been proven in ViT. In our work we propose to train ViT to recognize the 2D position encoding of patches of the input image, this apparently simple task actually yields a meaningful self-supervisory task. Based on previous work on ViT position encoding, we propose two position labels dedicated to 2D images including absolute position and relative position. Our position labels can be easily plugged into transformer, combined with the various current ViT variants. It can work in two ways: 1.As an auxiliary training target for vanilla ViT (e.g., ViT-B and Swin-B) to improve model performance. 2. Combine the self-supervised ViT (e.g., MAE) to provide a more powerful self-supervised signal for semantic feature learning. Experiments demonstrate that solely due to the proposed self-supervised methods, Swin-B and ViT-B obtained improvements of 1.9% (top-1 Acc) and 5.6% (top-1 Acc) on Mini-ImageNet, respectively.
Design of Supervision-Scalable Learning Systems: Methodology and Performance Benchmarking
Jun 18, 2022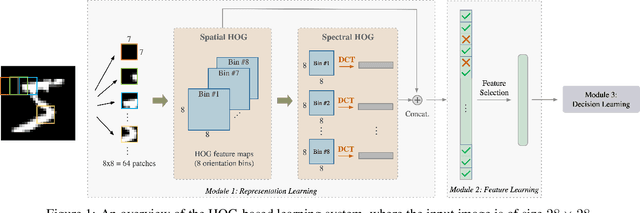
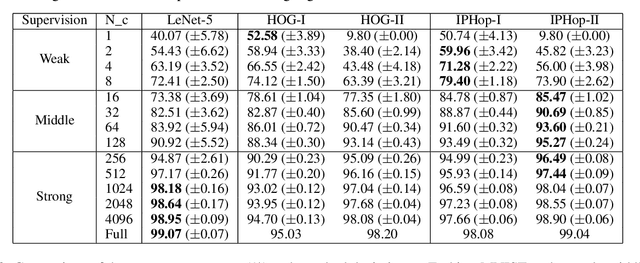
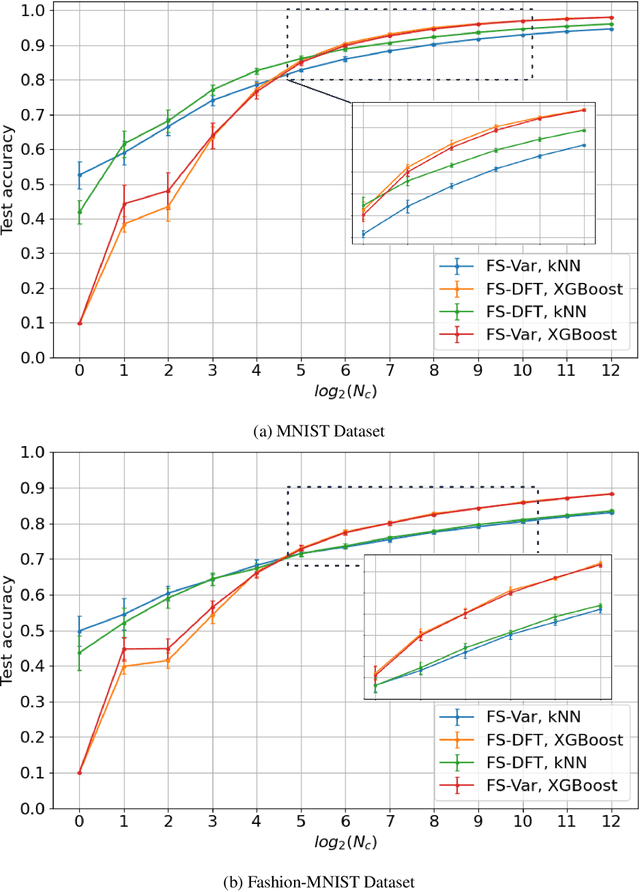
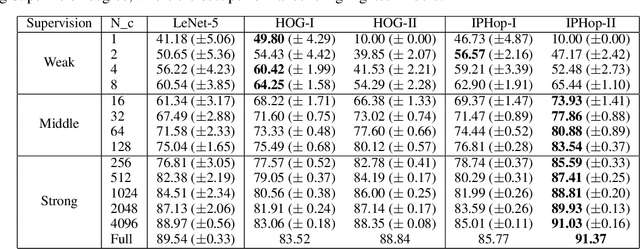
The design of robust learning systems that offer stable performance under a wide range of supervision degrees is investigated in this work. We choose the image classification problem as an illustrative example and focus on the design of modularized systems that consist of three learning modules: representation learning, feature learning and decision learning. We discuss ways to adjust each module so that the design is robust with respect to different training sample numbers. Based on these ideas, we propose two families of learning systems. One adopts the classical histogram of oriented gradients (HOG) features while the other uses successive-subspace-learning (SSL) features. We test their performance against LeNet-5, which is an end-to-end optimized neural network, for MNIST and Fashion-MNIST datasets. The number of training samples per image class goes from the extremely weak supervision condition (i.e., 1 labeled sample per class) to the strong supervision condition (i.e., 4096 labeled sample per class) with gradual transition in between (i.e., $2^n$, $n=0, 1, \cdots, 12$). Experimental results show that the two families of modularized learning systems have more robust performance than LeNet-5. They both outperform LeNet-5 by a large margin for small $n$ and have performance comparable with that of LeNet-5 for large $n$.
ALBench: A Framework for Evaluating Active Learning in Object Detection
Jul 27, 2022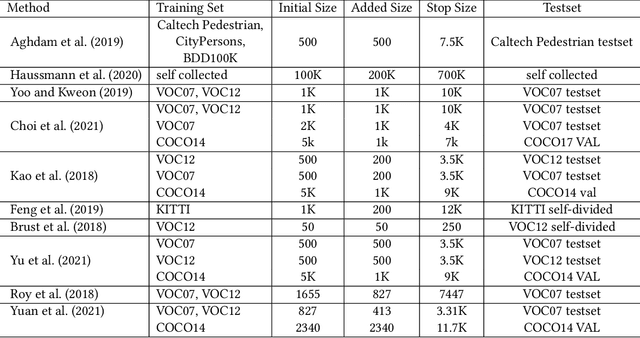
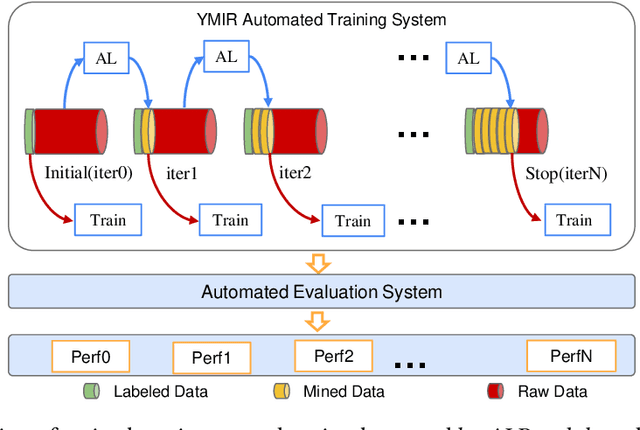
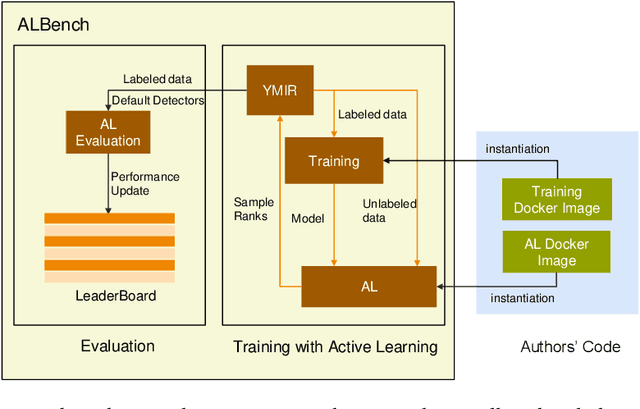
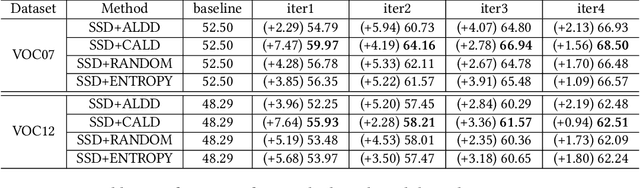
Active learning is an important technology for automated machine learning systems. In contrast to Neural Architecture Search (NAS) which aims at automating neural network architecture design, active learning aims at automating training data selection. It is especially critical for training a long-tailed task, in which positive samples are sparsely distributed. Active learning alleviates the expensive data annotation issue through incrementally training models powered with efficient data selection. Instead of annotating all unlabeled samples, it iteratively selects and annotates the most valuable samples. Active learning has been popular in image classification, but has not been fully explored in object detection. Most of current approaches on object detection are evaluated with different settings, making it difficult to fairly compare their performance. To facilitate the research in this field, this paper contributes an active learning benchmark framework named as ALBench for evaluating active learning in object detection. Developed on an automatic deep model training system, this ALBench framework is easy-to-use, compatible with different active learning algorithms, and ensures the same training and testing protocols. We hope this automated benchmark system help researchers to easily reproduce literature's performance and have objective comparisons with prior arts. The code will be release through Github.
ZSON: Zero-Shot Object-Goal Navigation using Multimodal Goal Embeddings
Jun 24, 2022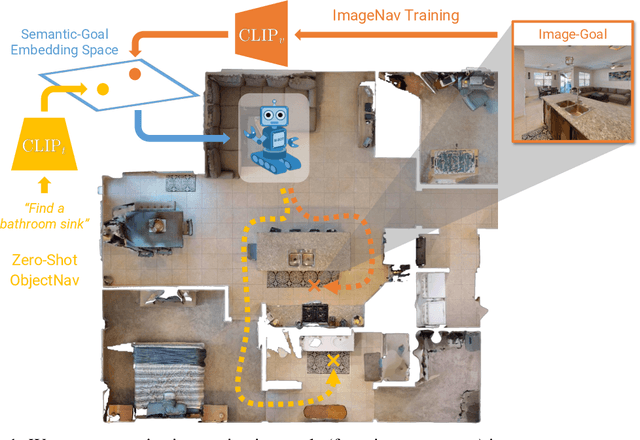

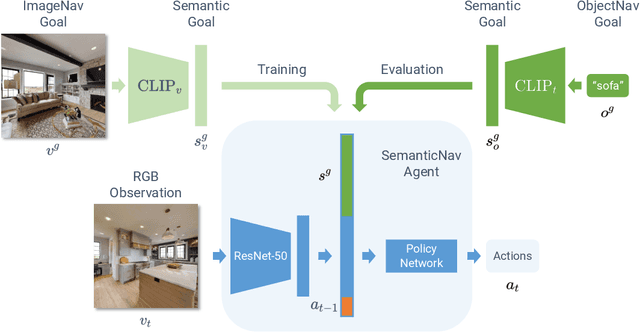
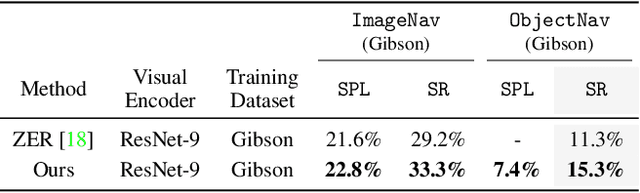
We present a scalable approach for learning open-world object-goal navigation (ObjectNav) -- the task of asking a virtual robot (agent) to find any instance of an object in an unexplored environment (e.g., "find a sink"). Our approach is entirely zero-shot -- i.e., it does not require ObjectNav rewards or demonstrations of any kind. Instead, we train on the image-goal navigation (ImageNav) task, in which agents find the location where a picture (i.e., goal image) was captured. Specifically, we encode goal images into a multimodal, semantic embedding space to enable training semantic-goal navigation (SemanticNav) agents at scale in unannotated 3D environments (e.g., HM3D). After training, SemanticNav agents can be instructed to find objects described in free-form natural language (e.g., "sink", "bathroom sink", etc.) by projecting language goals into the same multimodal, semantic embedding space. As a result, our approach enables open-world ObjectNav. We extensively evaluate our agents on three ObjectNav datasets (Gibson, HM3D, and MP3D) and observe absolute improvements in success of 4.2% - 20.0% over existing zero-shot methods. For reference, these gains are similar or better than the 5% improvement in success between the Habitat 2020 and 2021 ObjectNav challenge winners. In an open-world setting, we discover that our agents can generalize to compound instructions with a room explicitly mentioned (e.g., "Find a kitchen sink") and when the target room can be inferred (e.g., "Find a sink and a stove").
Subgroup Discovery in Unstructured Data
Jul 15, 2022


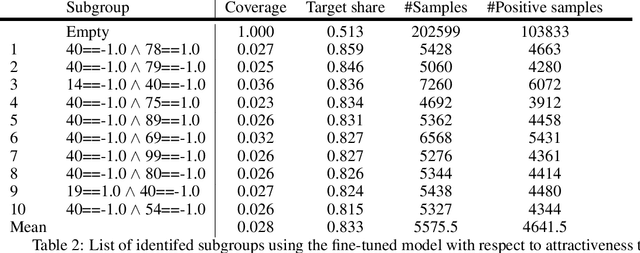
Subgroup discovery is a descriptive and exploratory data mining technique to identify subgroups in a population that exhibit interesting behavior with respect to a variable of interest. Subgroup discovery has numerous applications in knowledge discovery and hypothesis generation, yet it remains inapplicable for unstructured, high-dimensional data such as images. This is because subgroup discovery algorithms rely on defining descriptive rules based on (attribute, value) pairs, however, in unstructured data, an attribute is not well defined. Even in cases where the notion of attribute intuitively exists in the data, such as a pixel in an image, due to the high dimensionality of the data, these attributes are not informative enough to be used in a rule. In this paper, we introduce the subgroup-aware variational autoencoder, a novel variational autoencoder that learns a representation of unstructured data which leads to subgroups with higher quality. Our experimental results demonstrate the effectiveness of the method at learning subgroups with high quality while supporting the interpretability of the concepts.
Self-Supervised Learning of Echocardiogram Videos Enables Data-Efficient Clinical Diagnosis
Jul 23, 2022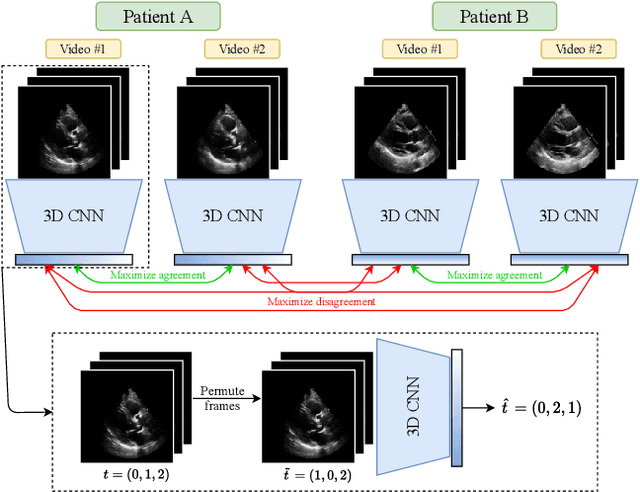
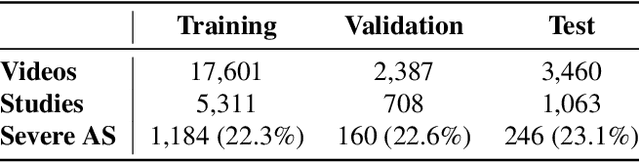
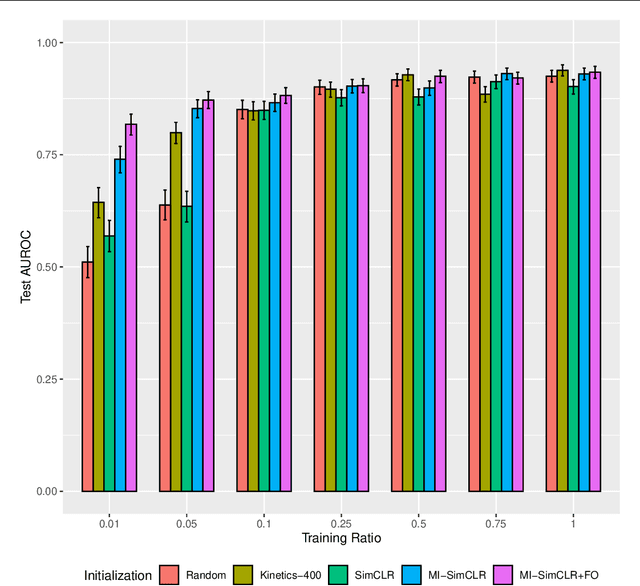
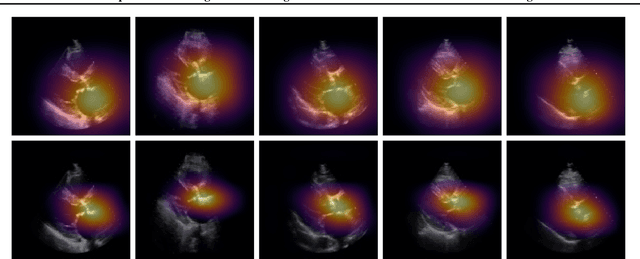
Given the difficulty of obtaining high-quality labels for medical image recognition tasks, there is a need for deep learning techniques that can be adequately fine-tuned on small labeled data sets. Recent advances in self-supervised learning techniques have shown that such an in-domain representation learning approach can provide a strong initialization for supervised fine-tuning, proving much more data-efficient than standard transfer learning from a supervised pretraining task. However, these applications are not adapted to applications to medical diagnostics captured in a video format. With this progress in mind, we developed a self-supervised learning approach catered to echocardiogram videos with the goal of learning strong representations for downstream fine-tuning on the task of diagnosing aortic stenosis (AS), a common and dangerous disease of the aortic valve. When fine-tuned on 1% of the training data, our best self-supervised learning model achieves 0.818 AUC (95% CI: 0.794, 0.840), while the standard transfer learning approach reaches 0.644 AUC (95% CI: 0.610, 0.677). We also find that our self-supervised model attends more closely to the aortic valve when predicting severe AS as demonstrated by saliency map visualizations.
Masked Autoencoders that Listen
Jul 13, 2022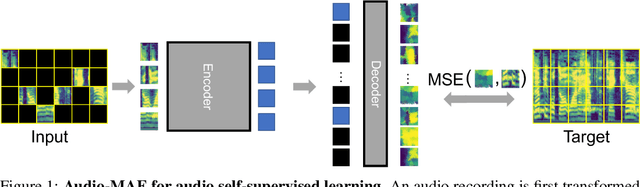
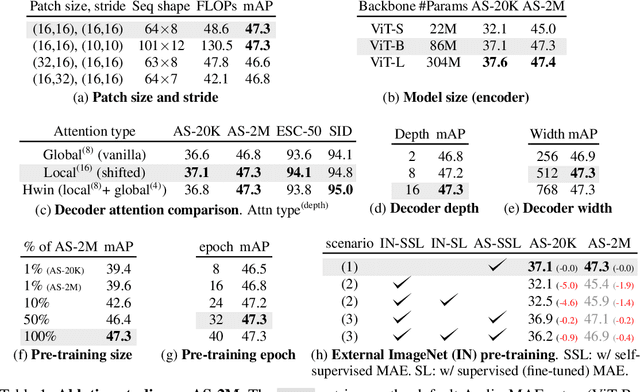

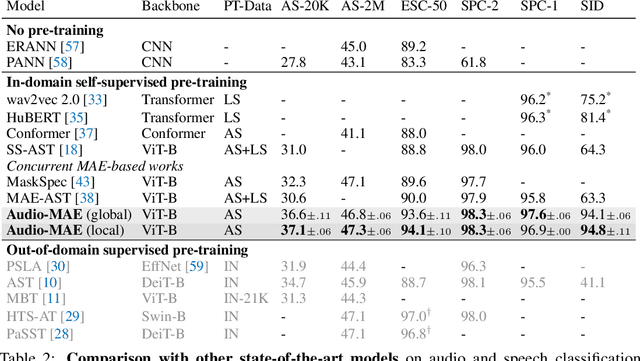
This paper studies a simple extension of image-based Masked Autoencoders (MAE) to self-supervised representation learning from audio spectrograms. Following the Transformer encoder-decoder design in MAE, our Audio-MAE first encodes audio spectrogram patches with a high masking ratio, feeding only the non-masked tokens through encoder layers. The decoder then re-orders and decodes the encoded context padded with mask tokens, in order to reconstruct the input spectrogram. We find it beneficial to incorporate local window attention in the decoder, as audio spectrograms are highly correlated in local time and frequency bands. We then fine-tune the encoder with a lower masking ratio on target datasets. Empirically, Audio-MAE sets new state-of-the-art performance on six audio and speech classification tasks, outperforming other recent models that use external supervised pre-training. The code and models will be at https://github.com/facebookresearch/AudioMAE.
Shadow Image Enlargement Distortion Removal
Feb 22, 2021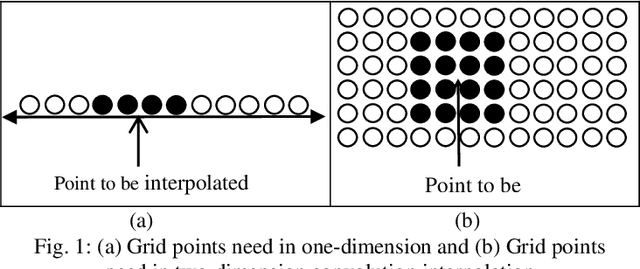
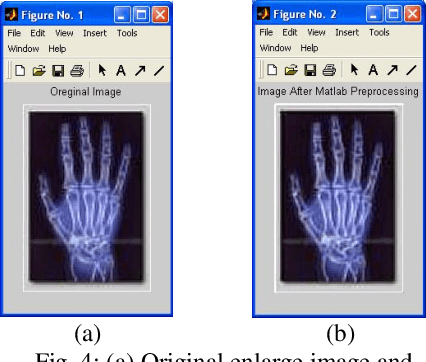
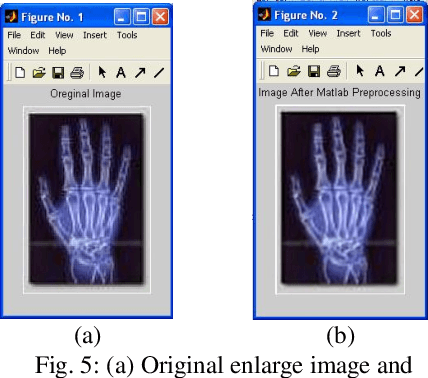
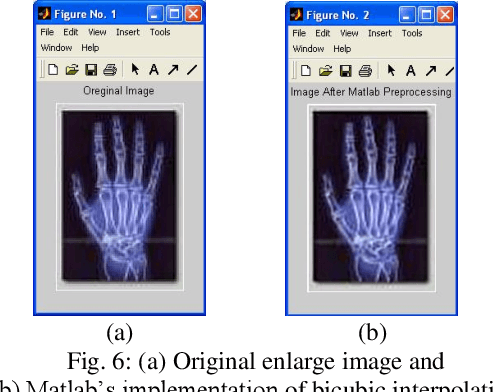
This project aims to adopt preprocessing operations to get less distortions for shadow image enlargement. The preprocessing operations consists of three main steps: first enlarge the original shadow image by using any kind of interpolation methods, second apply average filter to the enlargement image and finally apply the unsharp filter to the previous averaged image. These preprocessing operations leads to get an enlargement image very close to the original enlarge image for the same shadow image. Then comparisons established between the adopted image and original image by using different types of interpolation and different alfa values for unsharp filter to reach the best way which have less different errors between the two images.
giMLPs: Gate with Inhibition Mechanism in MLPs
Aug 02, 2022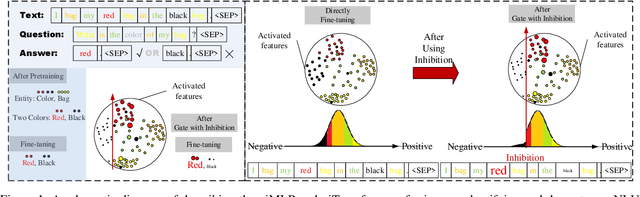
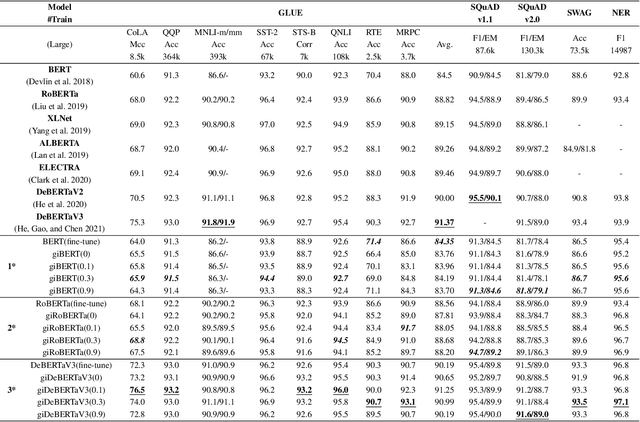
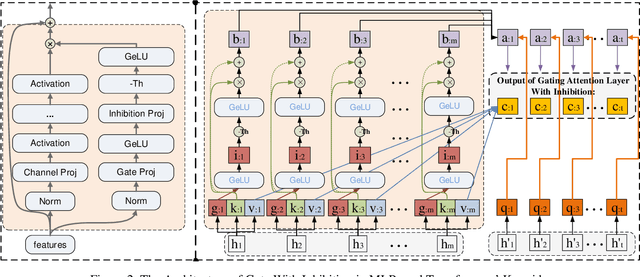
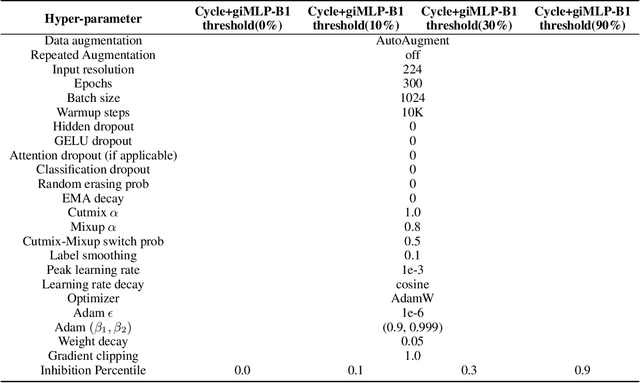
This paper presents a new model architecture, gate with inhibition MLP (giMLP).The gate with inhibition on CycleMLP (gi-CycleMLP) can produce equal performance on the ImageNet classification task, and it also improves the BERT, Roberta, and DeBERTaV3 models depending on two novel techniques. The first is the gating MLP, where matrix multiplications between the MLP and the trunk Attention input in further adjust models' adaptation. The second is inhibition which inhibits or enhances the branch adjustment, and with the inhibition levels increasing, it offers models more muscular features restriction. We show that the giCycleMLP with a lower inhibition level can be competitive with the original CycleMLP in terms of ImageNet classification accuracy. In addition, we also show through a comprehensive empirical study that these techniques significantly improve the performance of fine-tuning NLU downstream tasks. As for the gate with inhibition MLPs on DeBERTa (giDeBERTa) fine-tuning, we find it can achieve appealing results on most parts of NLU tasks without any extra pretraining again. We also find that with the use of Gate With Inhibition, the activation function should have a short and smooth negative tail, with which the unimportant features or the features that hurt models can be moderately inhibited. The experiments on ImageNet and twelve language downstream tasks demonstrate the effectiveness of Gate With Inhibition, both for image classification and for enhancing the capacity of nature language fine-tuning without any extra pretraining.
A Novel Application of Image-to-Image Translation: Chromosome Straightening Framework by Learning from a Single Image
Mar 04, 2021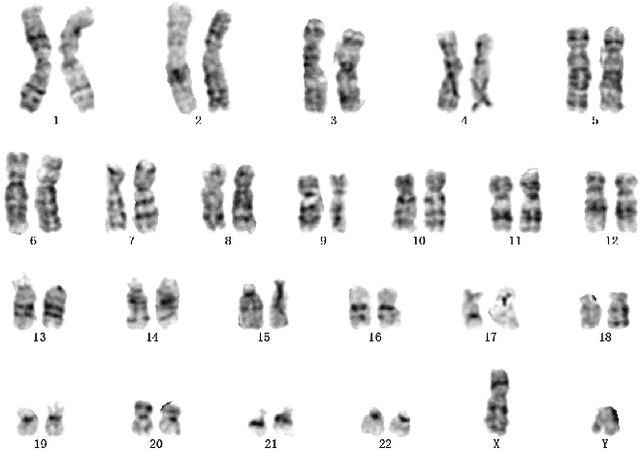

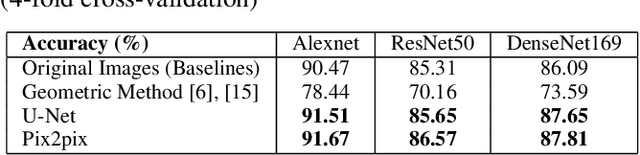
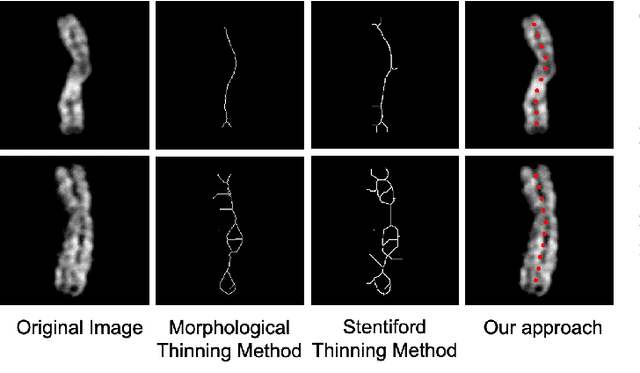
In medical imaging, chromosome straightening plays a significant role in the pathological study of chromosomes and in the development of cytogenetic maps. Whereas different approaches exist for the straightening task, they are mostly geometric algorithms whose outputs are characterized by jagged edges or fragments with discontinued banding patterns. To address the flaws in the geometric algorithms, we propose a novel framework based on image-to-image translation to learn a pertinent mapping dependence for synthesizing straightened chromosomes with uninterrupted banding patterns and preserved details. In addition, to avoid the pitfall of deficient input chromosomes, we construct an augmented dataset using only one single curved chromosome image for training models. Based on this framework, we apply two popular image-to-image translation architectures, U-shape networks and conditional generative adversarial networks, to assess its efficacy. Experiments on a dataset comprising of 642 real-world chromosomes demonstrate the superiority of our framework as compared to the geometric method in straightening performance by rendering realistic and continued chromosome details. Furthermore, our straightened results improve the chromosome classification, achieving 0.98%-1.39% in mean accuracy.