 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Discrete Contrastive Diffusion for Cross-Modal and Conditional Generation
Jun 15, 2022

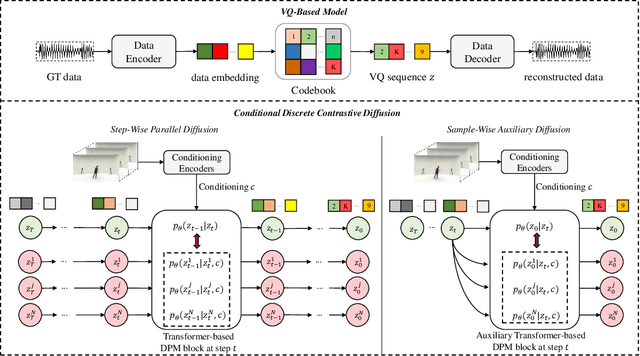

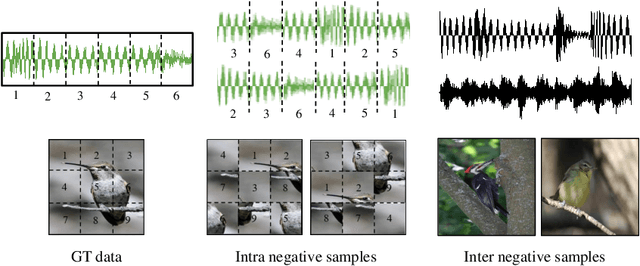
Diffusion probabilistic models (DPMs) have become a popular approach to conditional generation, due to their promising results and support for cross-modal synthesis. A key desideratum in conditional synthesis is to achieve high correspondence between the conditioning input and generated output. Most existing methods learn such relationships implicitly, by incorporating the prior into the variational lower bound. In this work, we take a different route -- we enhance input-output connections by maximizing their mutual information using contrastive learning. To this end, we introduce a Conditional Discrete Contrastive Diffusion (CDCD) loss and design two contrastive diffusion mechanisms to effectively incorporate it into the denoising process. We formulate CDCD by connecting it with the conventional variational objectives. We demonstrate the efficacy of our approach in evaluations with three diverse, multimodal conditional synthesis tasks: dance-to-music generation, text-to-image synthesis, and class-conditioned image synthesis. On each, we achieve state-of-the-art or higher synthesis quality and improve the input-output correspondence. Furthermore, the proposed approach improves the convergence of diffusion models, reducing the number of required diffusion steps by more than 35% on two benchmarks, significantly increasing the inference speed.
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
May 29, 2022
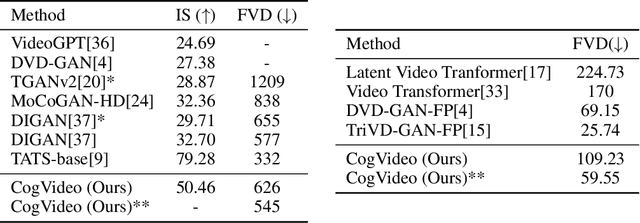
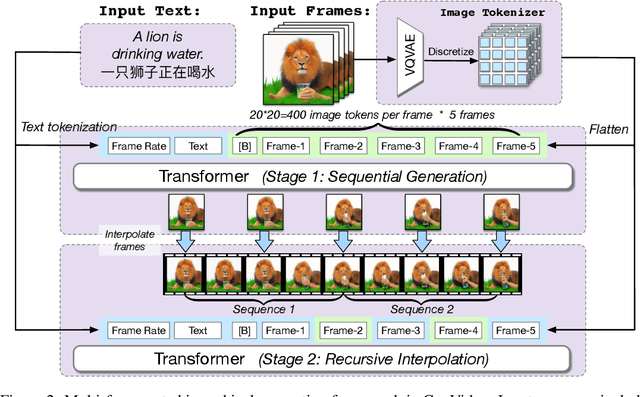

Large-scale pretrained transformers have created milestones in text (GPT-3) and text-to-image (DALL-E and CogView) generation. Its application to video generation is still facing many challenges: The potential huge computation cost makes the training from scratch unaffordable; The scarcity and weak relevance of text-video datasets hinder the model understanding complex movement semantics. In this work, we present 9B-parameter transformer CogVideo, trained by inheriting a pretrained text-to-image model, CogView2. We also propose multi-frame-rate hierarchical training strategy to better align text and video clips. As (probably) the first open-source large-scale pretrained text-to-video model, CogVideo outperforms all publicly available models at a large margin in machine and human evaluations.
Matching in the Dark: A Dataset for Matching Image Pairs of Low-light Scenes
Sep 14, 2021
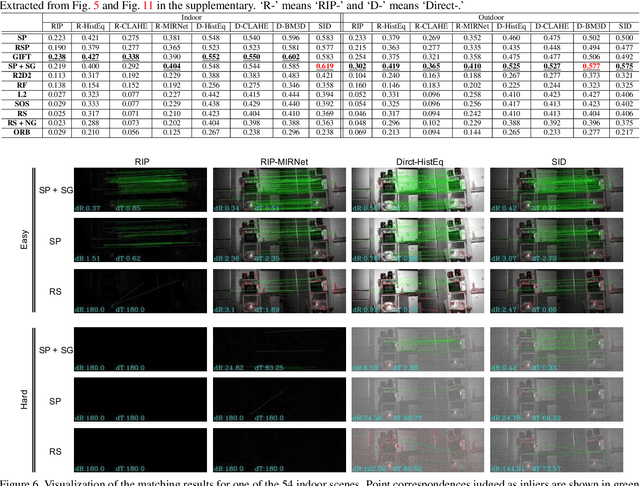
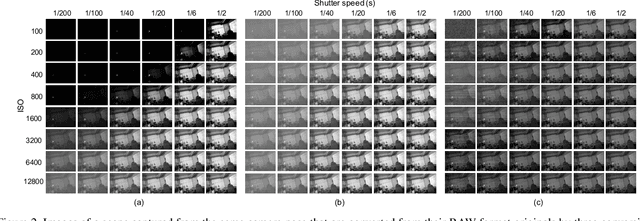
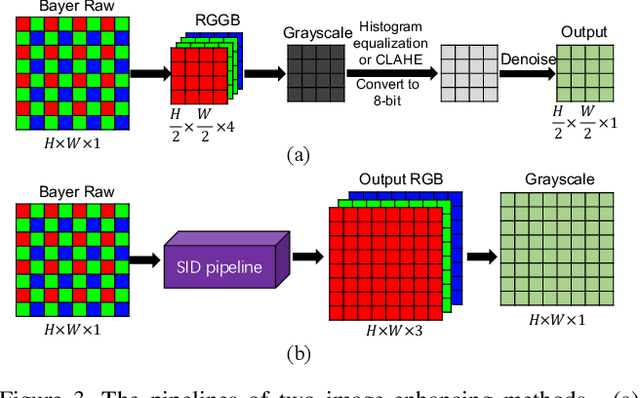
This paper considers matching images of low-light scenes, aiming to widen the frontier of SfM and visual SLAM applications. Recent image sensors can record the brightness of scenes with more than eight-bit precision, available in their RAW-format image. We are interested in making full use of such high-precision information to match extremely low-light scene images that conventional methods cannot handle. For extreme low-light scenes, even if some of their brightness information exists in the RAW format images' low bits, the standard raw image processing on cameras fails to utilize them properly. As was recently shown by Chen et al., CNNs can learn to produce images with a natural appearance from such RAW-format images. To consider if and how well we can utilize such information stored in RAW-format images for image matching, we have created a new dataset named MID (matching in the dark). Using it, we experimentally evaluated combinations of eight image-enhancing methods and eleven image matching methods consisting of classical/neural local descriptors and classical/neural initial point-matching methods. The results show the advantage of using the RAW-format images and the strengths and weaknesses of the above component methods. They also imply there is room for further research.
SatMAE: Pre-training Transformers for Temporal and Multi-Spectral Satellite Imagery
Jul 17, 2022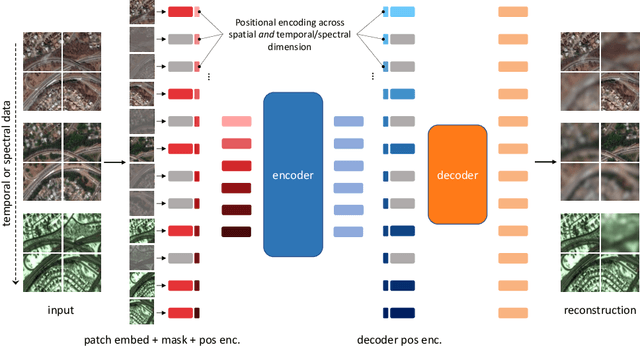

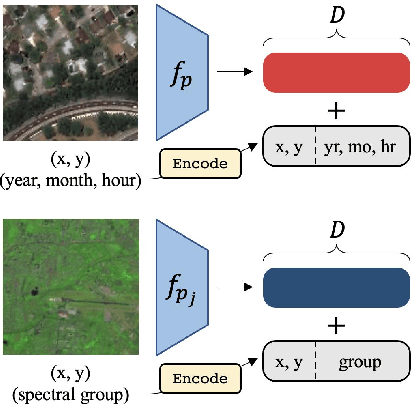
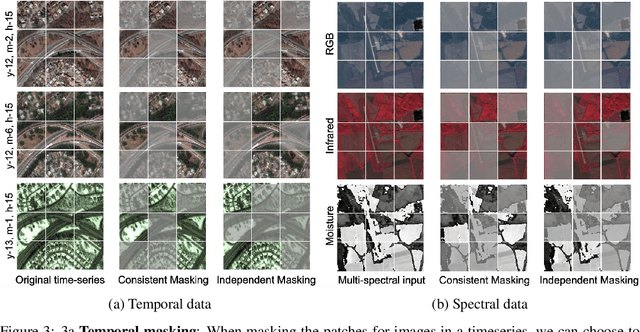
Unsupervised pre-training methods for large vision models have shown to enhance performance on downstream supervised tasks. Developing similar techniques for satellite imagery presents significant opportunities as unlabelled data is plentiful and the inherent temporal and multi-spectral structure provides avenues to further improve existing pre-training strategies. In this paper, we present SatMAE, a pre-training framework for temporal or multi-spectral satellite imagery based on Masked Autoencoder (MAE). To leverage temporal information, we include a temporal embedding along with independently masking image patches across time. In addition, we demonstrate that encoding multi-spectral data as groups of bands with distinct spectral positional encodings is beneficial. Our approach yields strong improvements over previous state-of-the-art techniques, both in terms of supervised learning performance on benchmark datasets (up to $\uparrow$ 7\%), and transfer learning performance on downstream remote sensing tasks, including land cover classification (up to $\uparrow$ 14\%) and semantic segmentation.
A Medical Pre-Diagnosis System for Histopathological Image of Breast Cancer
Sep 16, 2021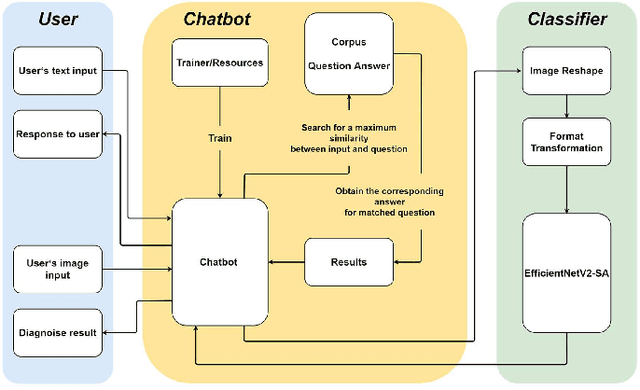
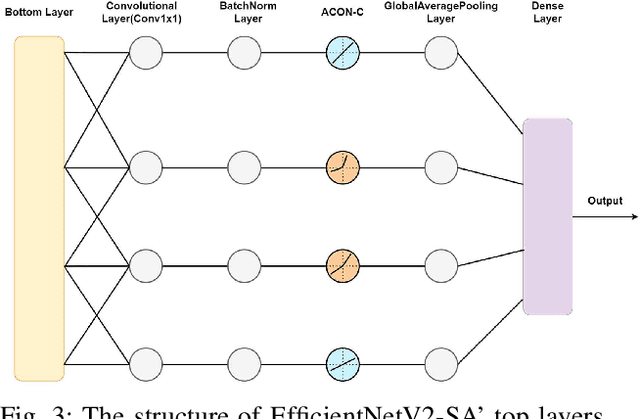

This paper constructs a novel intelligent medical diagnosis system, which can realize automatic communication and breast cancer pathological image recognition. This system contains two main parts, including a pre-training chatbot called M-Chatbot and an improved neural network model of EfficientNetV2-S named EfficientNetV2-SA, in which the activation function in top layers is replaced by ACON-C. Using information retrieval mechanism, M-Chatbot instructs patients to send breast pathological image to EfficientNetV2-SA network, and then the classifier trained by transfer learning will return the diagnosis results. We verify the performance of our chatbot and classification on the extrinsic metrics and BreaKHis dataset, respectively. The task completion rate of M-Chatbot reached 63.33\%. For the BreaKHis dataset, the highest accuracy of EfficientNetV2-SA network have achieved 84.71\%. All these experimental results illustrate that the proposed model can improve the accuracy performance of image recognition and our new intelligent medical diagnosis system is successful and efficient in providing automatic diagnosis of breast cancer.
Sociable and Ergonomic Human-Robot Collaboration through Action Recognition and Augmented Hierarchical Quadratic Programming
Jul 07, 2022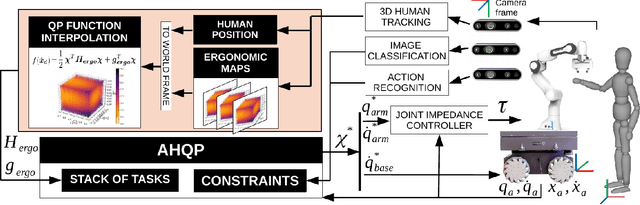
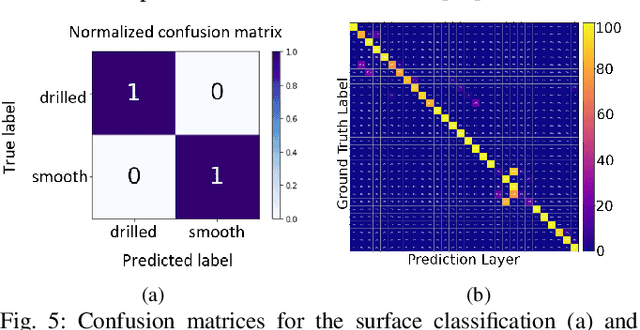
The recognition of actions performed by humans and the anticipation of their intentions are important enablers to yield sociable and successful collaboration in human-robot teams. Meanwhile, robots should have the capacity to deal with multiple objectives and constraints, arising from the collaborative task or the human. In this regard, we propose vision techniques to perform human action recognition and image classification, which are integrated into an Augmented Hierarchical Quadratic Programming (AHQP) scheme to hierarchically optimize the robot's reactive behavior and human ergonomics. The proposed framework allows one to intuitively command the robot in space while a task is being executed. The experiments confirm increased human ergonomics and usability, which are fundamental parameters for reducing musculoskeletal diseases and increasing trust in automation.
Slice-level Detection of Intracranial Hemorrhage on CT Using Deep Descriptors of Adjacent Slices
Aug 05, 2022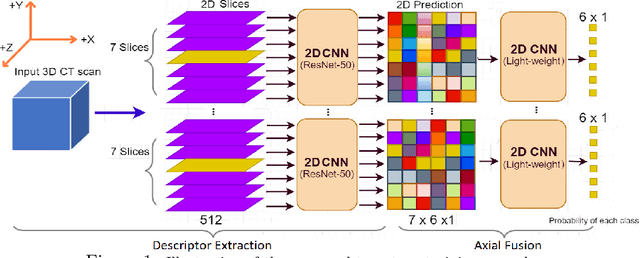
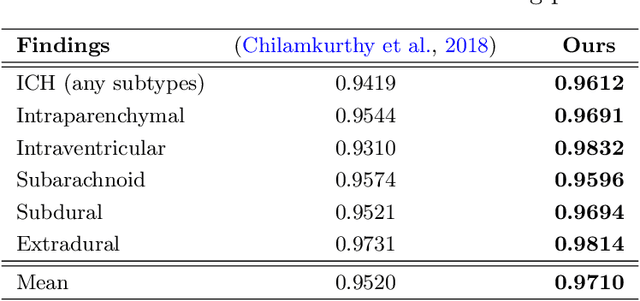
The rapid development in representation learning techniques and the availability of large-scale medical imaging data have to a rapid increase in the use of machine learning in the 3D medical image analysis. In particular, deep convolutional neural networks (D-CNNs) have been key players and were adopted by the medical imaging community to assist clinicians and medical experts in disease diagnosis. However, training deep neural networks such as D-CNN on high-resolution 3D volumes of Computed Tomography (CT) scans for diagnostic tasks poses formidable computational challenges. This raises the need of developing deep learning-based approaches that are robust in learning representations in 2D images, instead 3D scans. In this paper, we propose a new strategy to train \emph{slice-level} classifiers on CT scans based on the descriptors of the adjacent slices along the axis. In particular, each of which is extracted through a convolutional neural network (CNN). This method is applicable to CT datasets with per-slice labels such as the RSNA Intracranial Hemorrhage (ICH) dataset, which aims to predict the presence of ICH and classify it into 5 different sub-types. We obtain a single model in the top 4\% best-performing solutions of the RSNA ICH challenge, where model ensembles are allowed. Experiments also show that the proposed method significantly outperforms the baseline model on CQ500. The proposed method is general and can be applied for other 3D medical diagnosis tasks such as MRI imaging. To encourage new advances in the field, we will make our codes and pre-trained model available upon acceptance of the paper.
ROCA: Robust CAD Model Retrieval and Alignment from a Single Image
Dec 03, 2021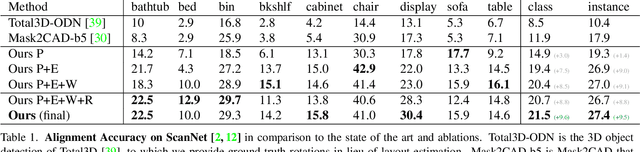
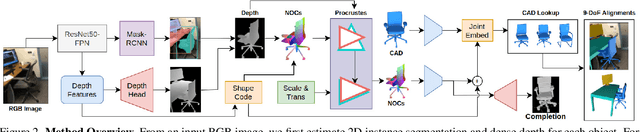


We present ROCA, a novel end-to-end approach that retrieves and aligns 3D CAD models from a shape database to a single input image. This enables 3D perception of an observed scene from a 2D RGB observation, characterized as a lightweight, compact, clean CAD representation. Core to our approach is our differentiable alignment optimization based on dense 2D-3D object correspondences and Procrustes alignment. ROCA can thus provide a robust CAD alignment while simultaneously informing CAD retrieval by leveraging the 2D-3D correspondences to learn geometrically similar CAD models. Experiments on challenging, real-world imagery from ScanNet show that ROCA significantly improves on state of the art, from 9.5% to 17.6% in retrieval-aware CAD alignment accuracy.
SIDER: Single-Image Neural Optimization for Facial Geometric Detail Recovery
Aug 11, 2021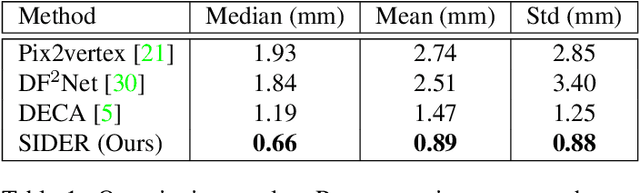
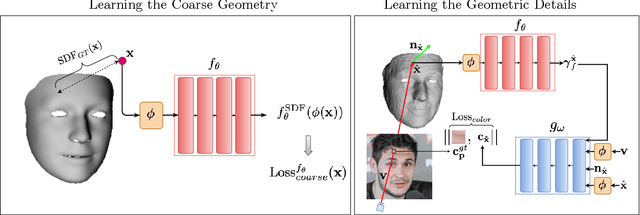


We present SIDER(Single-Image neural optimization for facial geometric DEtail Recovery), a novel photometric optimization method that recovers detailed facial geometry from a single image in an unsupervised manner. Inspired by classical techniques of coarse-to-fine optimization and recent advances in implicit neural representations of 3D shape, SIDER combines a geometry prior based on statistical models and Signed Distance Functions (SDFs) to recover facial details from single images. First, it estimates a coarse geometry using a morphable model represented as an SDF. Next, it reconstructs facial geometry details by optimizing a photometric loss with respect to the ground truth image. In contrast to prior work, SIDER does not rely on any dataset priors and does not require additional supervision from multiple views, lighting changes or ground truth 3D shape. Extensive qualitative and quantitative evaluation demonstrates that our method achieves state-of-the-art on facial geometric detail recovery, using only a single in-the-wild image.
Imperceptible Adversarial Examples for Fake Image Detection
Jun 03, 2021
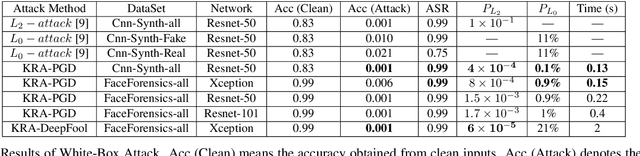

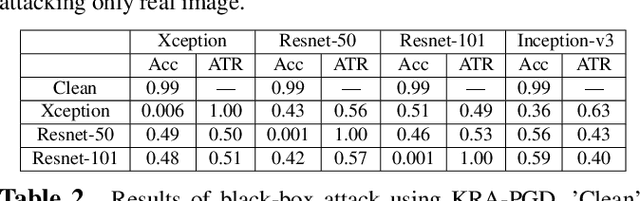
Fooling people with highly realistic fake images generated with Deepfake or GANs brings a great social disturbance to our society. Many methods have been proposed to detect fake images, but they are vulnerable to adversarial perturbations -- intentionally designed noises that can lead to the wrong prediction. Existing methods of attacking fake image detectors usually generate adversarial perturbations to perturb almost the entire image. This is redundant and increases the perceptibility of perturbations. In this paper, we propose a novel method to disrupt the fake image detection by determining key pixels to a fake image detector and attacking only the key pixels, which results in the $L_0$ and the $L_2$ norms of adversarial perturbations much less than those of existing works. Experiments on two public datasets with three fake image detectors indicate that our proposed method achieves state-of-the-art performance in both white-box and black-box attacks.