 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Black-box Few-shot Knowledge Distillation
Jul 25, 2022
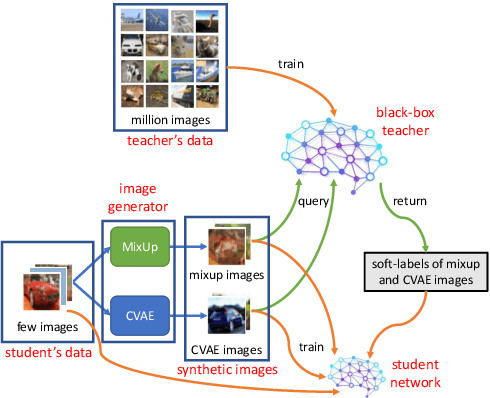
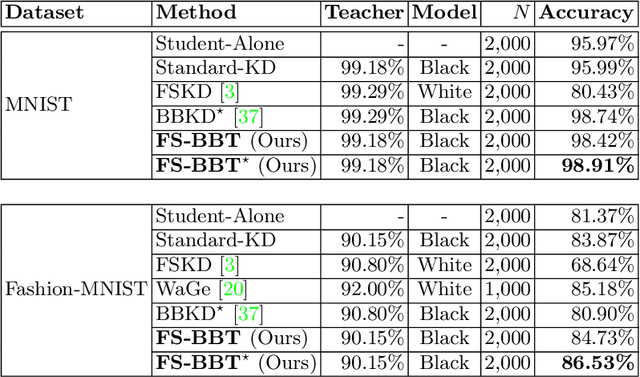
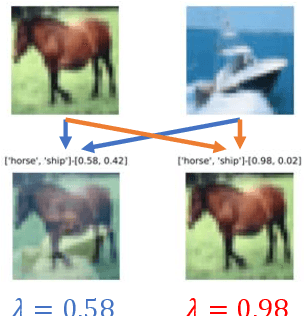
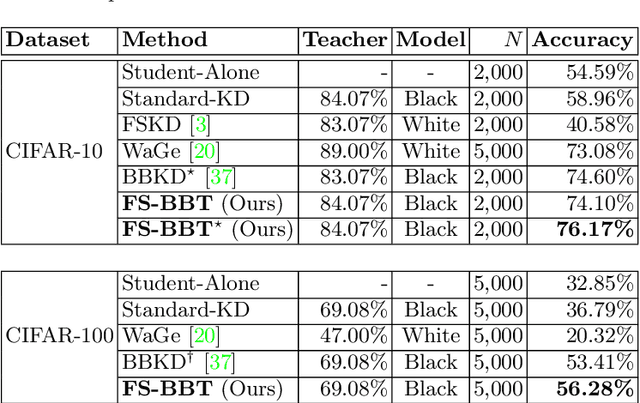
Knowledge distillation (KD) is an efficient approach to transfer the knowledge from a large "teacher" network to a smaller "student" network. Traditional KD methods require lots of labeled training samples and a white-box teacher (parameters are accessible) to train a good student. However, these resources are not always available in real-world applications. The distillation process often happens at an external party side where we do not have access to much data, and the teacher does not disclose its parameters due to security and privacy concerns. To overcome these challenges, we propose a black-box few-shot KD method to train the student with few unlabeled training samples and a black-box teacher. Our main idea is to expand the training set by generating a diverse set of out-of-distribution synthetic images using MixUp and a conditional variational auto-encoder. These synthetic images along with their labels obtained from the teacher are used to train the student. We conduct extensive experiments to show that our method significantly outperforms recent SOTA few/zero-shot KD methods on image classification tasks. The code and models are available at: https://github.com/nphdang/FS-BBT
Dynamic Degradation for Image Restoration and Fusion
Apr 28, 2021
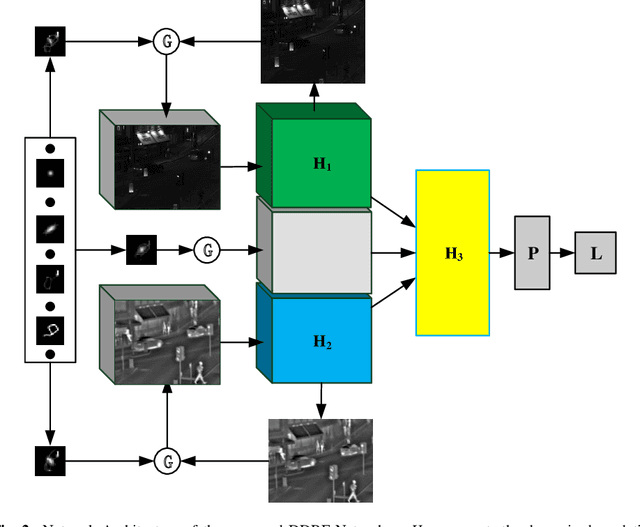


The deep-learning-based image restoration and fusion methods have achieved remarkable results. However, the existing restoration and fusion methods paid little research attention to the robustness problem caused by dynamic degradation. In this paper, we propose a novel dynamic image restoration and fusion neural network, termed as DDRF-Net, which is capable of solving two problems, i.e., static restoration and fusion, dynamic degradation. In order to solve the static fusion problem of existing methods, dynamic convolution is introduced to learn dynamic restoration and fusion weights. In addition, a dynamic degradation kernel is proposed to improve the robustness of image restoration and fusion. Our network framework can effectively combine image degradation with image fusion tasks, provide more detailed information for image fusion tasks through image restoration loss, and optimize image restoration tasks through image fusion loss. Therefore, the stumbling blocks of deep learning in image fusion, e.g., static fusion weight and specifically designed network architecture, are greatly mitigated. Extensive experiments show that our method is more superior compared with the state-of-the-art methods.
Exploring Fine-Grained Audiovisual Categorization with the SSW60 Dataset
Jul 21, 2022
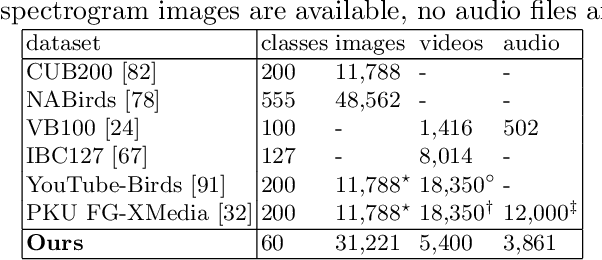
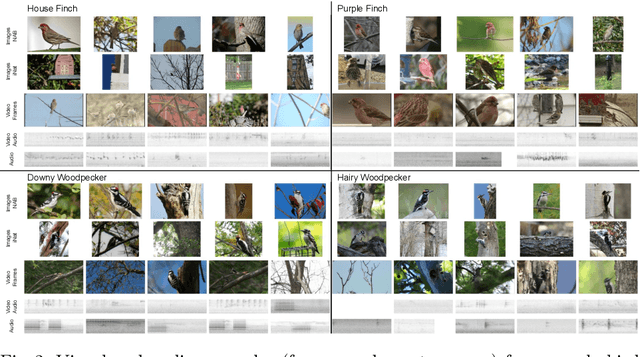
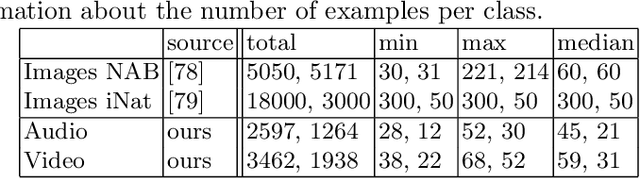
We present a new benchmark dataset, Sapsucker Woods 60 (SSW60), for advancing research on audiovisual fine-grained categorization. While our community has made great strides in fine-grained visual categorization on images, the counterparts in audio and video fine-grained categorization are relatively unexplored. To encourage advancements in this space, we have carefully constructed the SSW60 dataset to enable researchers to experiment with classifying the same set of categories in three different modalities: images, audio, and video. The dataset covers 60 species of birds and is comprised of images from existing datasets, and brand new, expert-curated audio and video datasets. We thoroughly benchmark audiovisual classification performance and modality fusion experiments through the use of state-of-the-art transformer methods. Our findings show that performance of audiovisual fusion methods is better than using exclusively image or audio based methods for the task of video classification. We also present interesting modality transfer experiments, enabled by the unique construction of SSW60 to encompass three different modalities. We hope the SSW60 dataset and accompanying baselines spur research in this fascinating area.
RIAV-MVS: Recurrent-Indexing an Asymmetric Volume for Multi-View Stereo
May 28, 2022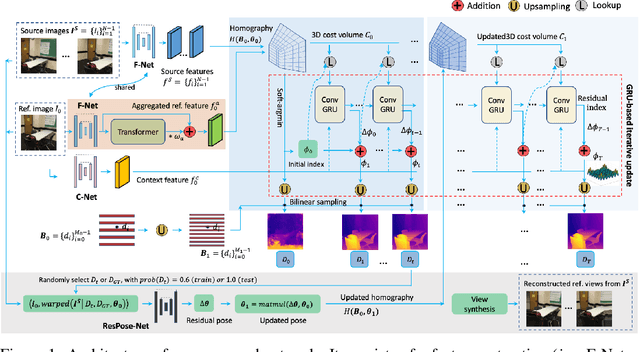
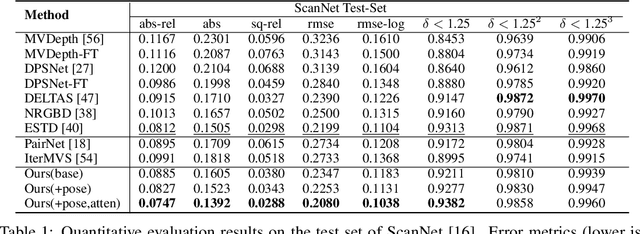
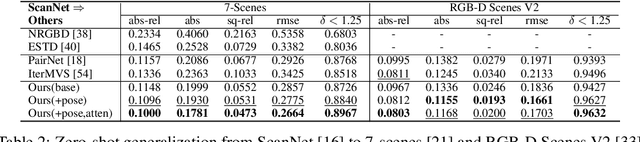

In this paper, we present a learning-based approach for multi-view stereo (MVS), i.e., estimate the depth map of a reference frame using posed multi-view images. Our core idea lies in leveraging a "learning-to-optimize" paradigm to iteratively index a plane-sweeping cost volume and regress the depth map via a convolutional Gated Recurrent Unit (GRU). Since the cost volume plays a paramount role in encoding the multi-view geometry, we aim to improve its construction both in pixel- and frame- levels. In the pixel level, we propose to break the symmetry of the Siamese network (which is typically used in MVS to extract image features) by introducing a transformer block to the reference image (but not to the source images). Such an asymmetric volume allows the network to extract global features from the reference image to predict its depth map. In view of the inaccuracy of poses between reference and source images, we propose to incorporate a residual pose network to make corrections to the relative poses, which essentially rectifies the cost volume in the frame-level. We conduct extensive experiments on real-world MVS datasets and show that our method achieves state-of-the-art performance in terms of both within-dataset evaluation and cross-dataset generalization.
Deep Bayesian Image Set Classification: A Defence Approach against Adversarial Attacks
Aug 23, 2021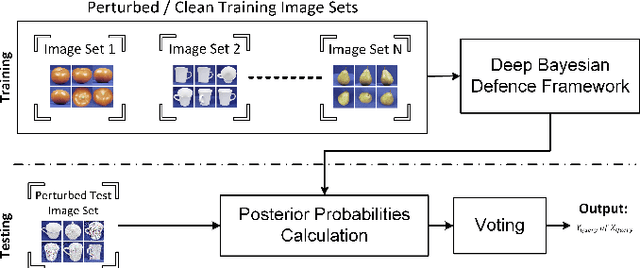
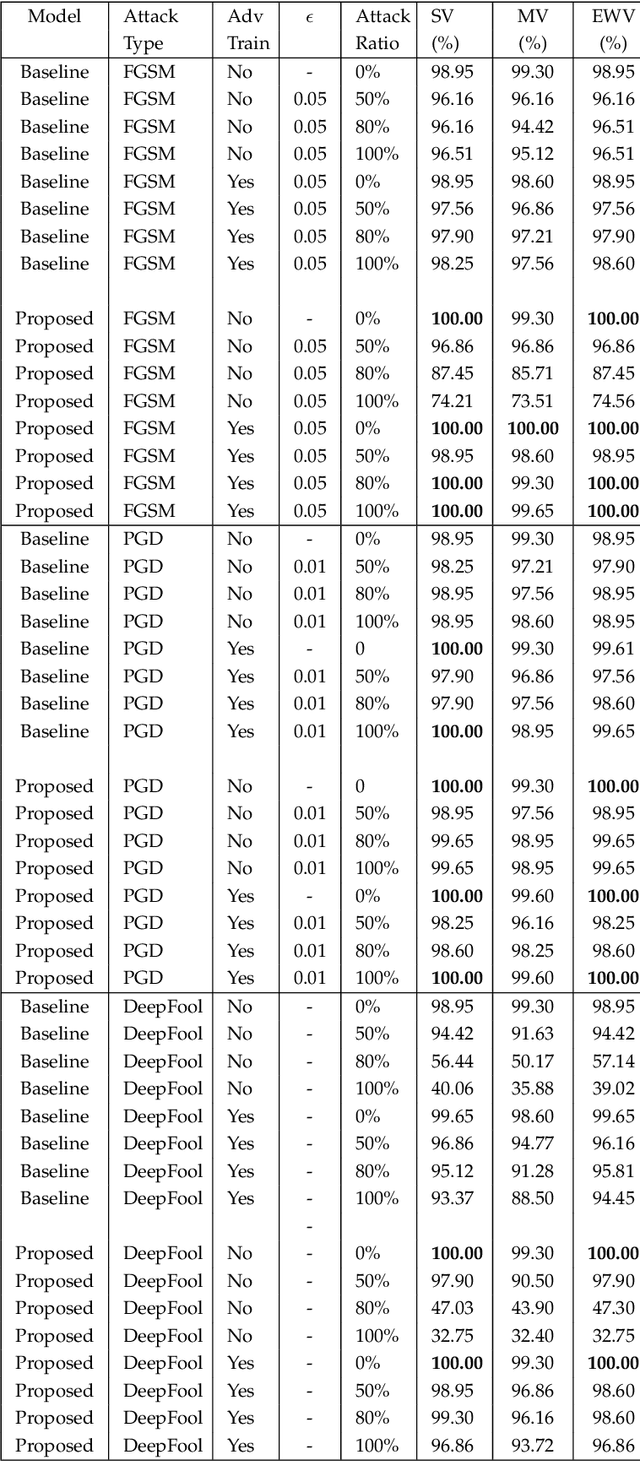
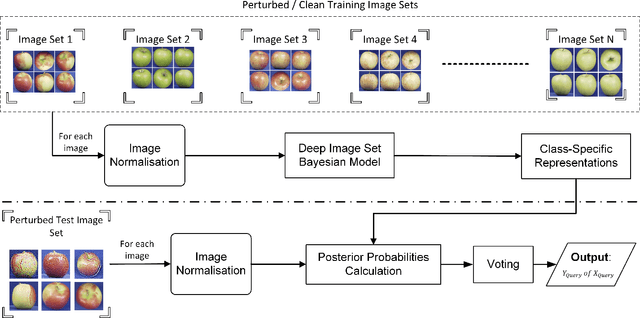
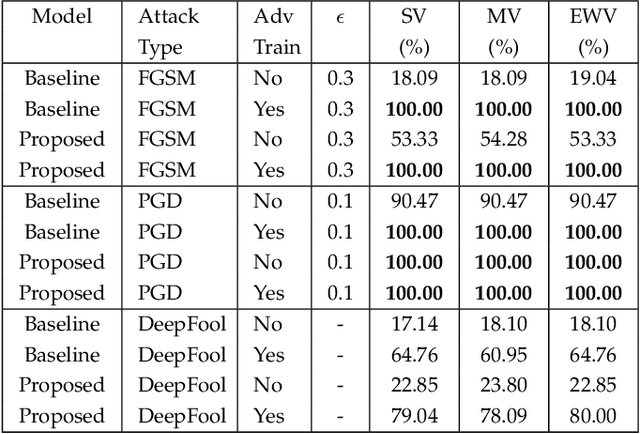
Deep learning has become an integral part of various computer vision systems in recent years due to its outstanding achievements for object recognition, facial recognition, and scene understanding. However, deep neural networks (DNNs) are susceptible to be fooled with nearly high confidence by an adversary. In practice, the vulnerability of deep learning systems against carefully perturbed images, known as adversarial examples, poses a dire security threat in the physical world applications. To address this phenomenon, we present, what to our knowledge, is the first ever image set based adversarial defence approach. Image set classification has shown an exceptional performance for object and face recognition, owing to its intrinsic property of handling appearance variability. We propose a robust deep Bayesian image set classification as a defence framework against a broad range of adversarial attacks. We extensively experiment the performance of the proposed technique with several voting strategies. We further analyse the effects of image size, perturbation magnitude, along with the ratio of perturbed images in each image set. We also evaluate our technique with the recent state-of-the-art defence methods, and single-shot recognition task. The empirical results demonstrate superior performance on CIFAR-10, MNIST, ETH-80, and Tiny ImageNet datasets.
Few-shot Transfer Learning for Holographic Image Reconstruction using a Recurrent Neural Network
Jan 27, 2022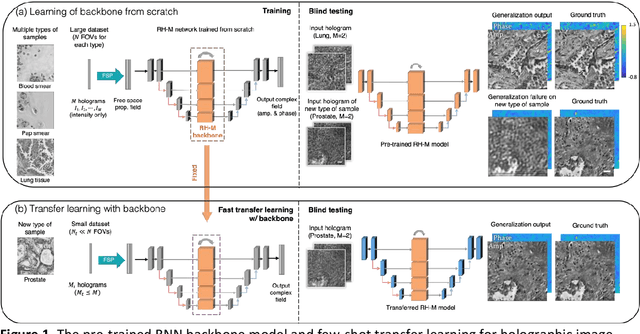
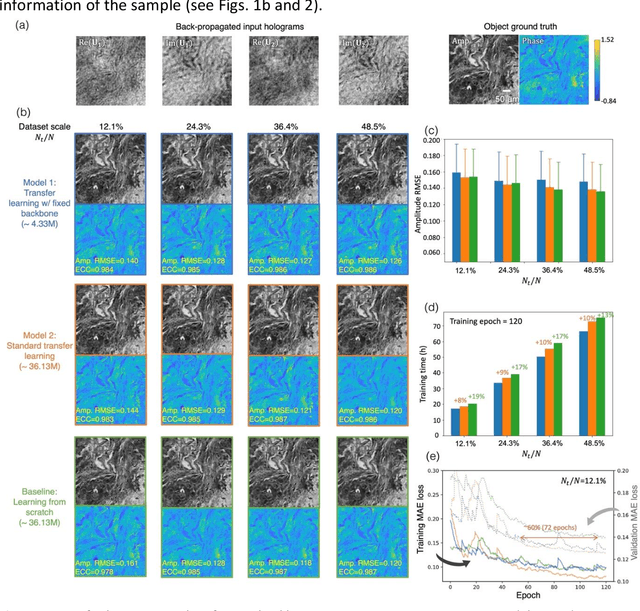
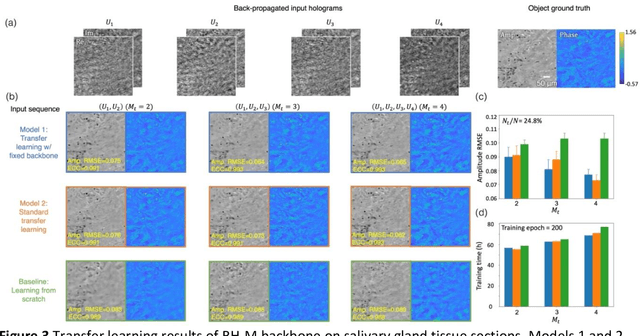
Deep learning-based methods in computational microscopy have been shown to be powerful but in general face some challenges due to limited generalization to new types of samples and requirements for large and diverse training data. Here, we demonstrate a few-shot transfer learning method that helps a holographic image reconstruction deep neural network rapidly generalize to new types of samples using small datasets. We pre-trained a convolutional recurrent neural network on a large dataset with diverse types of samples, which serves as the backbone model. By fixing the recurrent blocks and transferring the rest of the convolutional blocks of the pre-trained model, we reduced the number of trainable parameters by ~90% compared with standard transfer learning, while achieving equivalent generalization. We validated the effectiveness of this approach by successfully generalizing to new types of samples using small holographic datasets for training, and achieved (i) ~2.5-fold convergence speed acceleration, (ii) ~20% computation time reduction per epoch, and (iii) improved reconstruction performance over baseline network models trained from scratch. This few-shot transfer learning approach can potentially be applied in other microscopic imaging methods, helping to generalize to new types of samples without the need for extensive training time and data.
Learning Unsupervised Hierarchies of Audio Concepts
Jul 21, 2022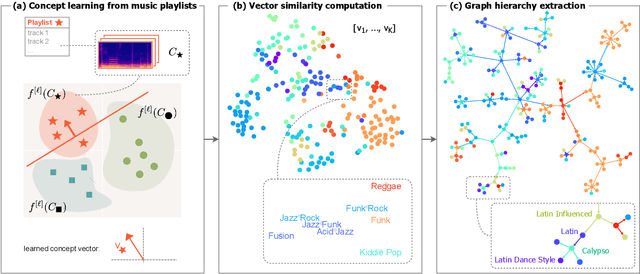
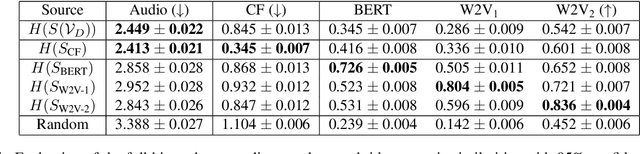
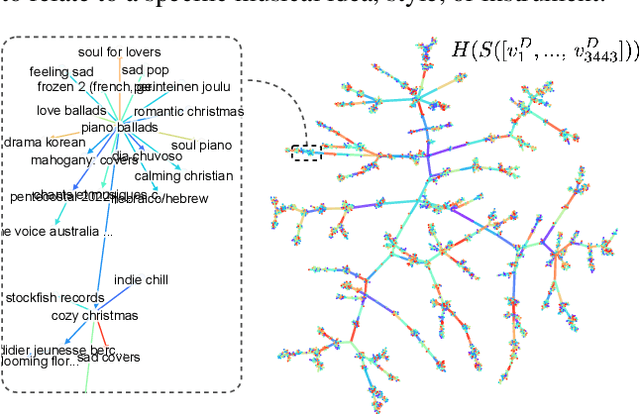
Music signals are difficult to interpret from their low-level features, perhaps even more than images: e.g. highlighting part of a spectrogram or an image is often insufficient to convey high-level ideas that are genuinely relevant to humans. In computer vision, concept learning was therein proposed to adjust explanations to the right abstraction level (e.g. detect clinical concepts from radiographs). These methods have yet to be used for MIR. In this paper, we adapt concept learning to the realm of music, with its particularities. For instance, music concepts are typically non-independent and of mixed nature (e.g. genre, instruments, mood), unlike previous work that assumed disentangled concepts. We propose a method to learn numerous music concepts from audio and then automatically hierarchise them to expose their mutual relationships. We conduct experiments on datasets of playlists from a music streaming service, serving as a few annotated examples for diverse concepts. Evaluations show that the mined hierarchies are aligned with both ground-truth hierarchies of concepts -- when available -- and with proxy sources of concept similarity in the general case.
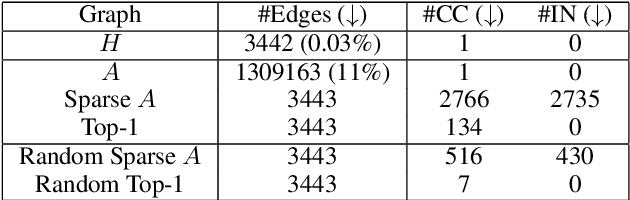
Pruning for Interpretable, Feature-Preserving Circuits in CNNs
Jun 03, 2022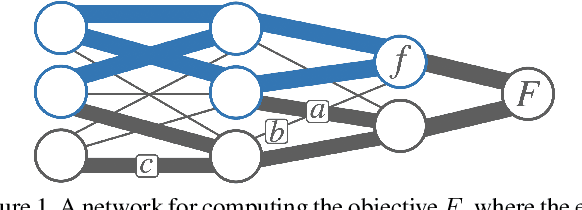
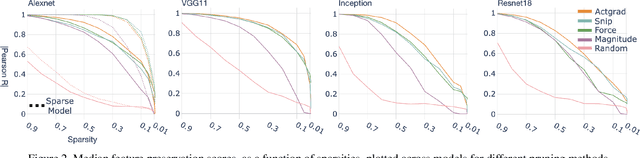
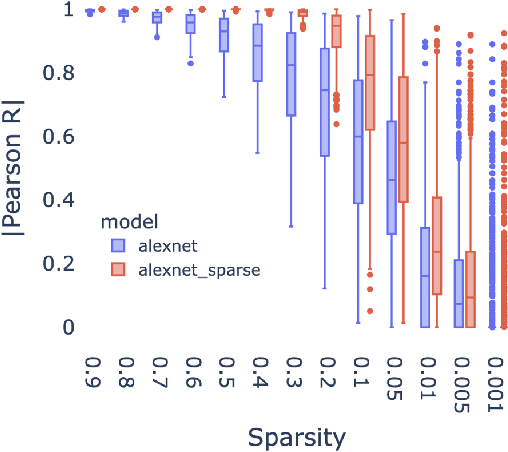
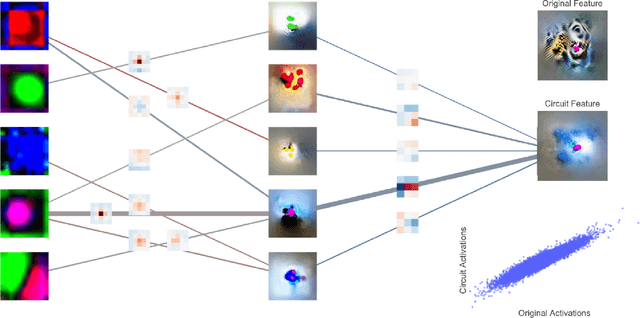
Deep convolutional neural networks are a powerful model class for a range of computer vision problems, but it is difficult to interpret the image filtering process they implement, given their sheer size. In this work, we introduce a method for extracting 'feature-preserving circuits' from deep CNNs, leveraging methods from saliency-based neural network pruning. These circuits are modular sub-functions, embedded within the network, containing only a subset of convolutional kernels relevant to a target feature. We compare the efficacy of 3 saliency-criteria for extracting these sparse circuits. Further, we show how 'sub-feature' circuits can be extracted, that preserve a feature's responses to particular images, dividing the feature into even sparser filtering processes. We also develop a tool for visualizing 'circuit diagrams', which render the entire image filtering process implemented by circuits in a parsable format.
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
May 29, 2022
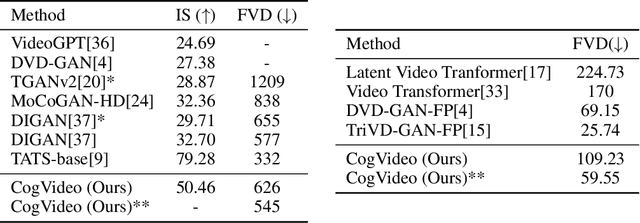
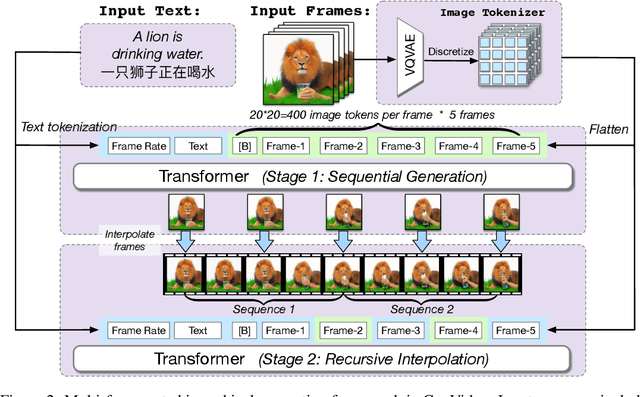

Large-scale pretrained transformers have created milestones in text (GPT-3) and text-to-image (DALL-E and CogView) generation. Its application to video generation is still facing many challenges: The potential huge computation cost makes the training from scratch unaffordable; The scarcity and weak relevance of text-video datasets hinder the model understanding complex movement semantics. In this work, we present 9B-parameter transformer CogVideo, trained by inheriting a pretrained text-to-image model, CogView2. We also propose multi-frame-rate hierarchical training strategy to better align text and video clips. As (probably) the first open-source large-scale pretrained text-to-video model, CogVideo outperforms all publicly available models at a large margin in machine and human evaluations.
Rewriting Geometric Rules of a GAN
Jul 28, 2022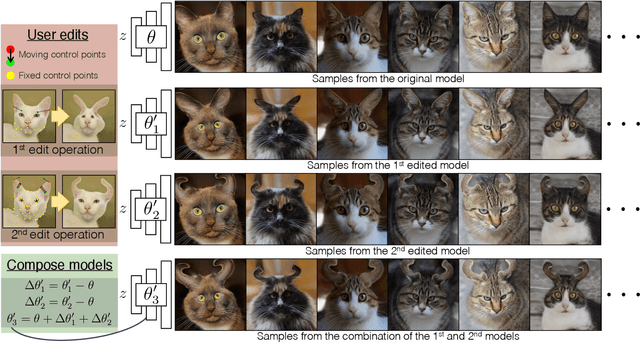
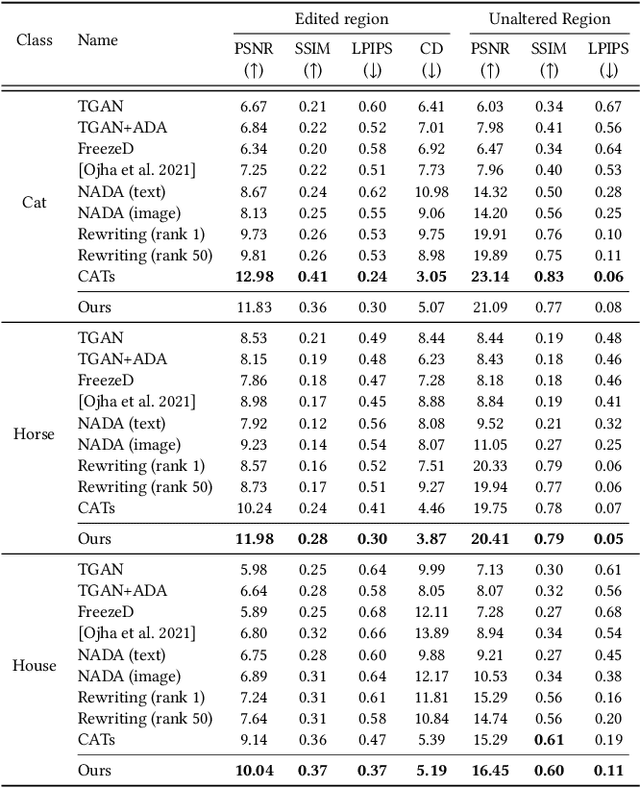
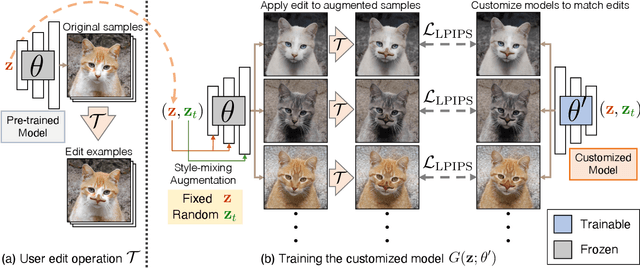
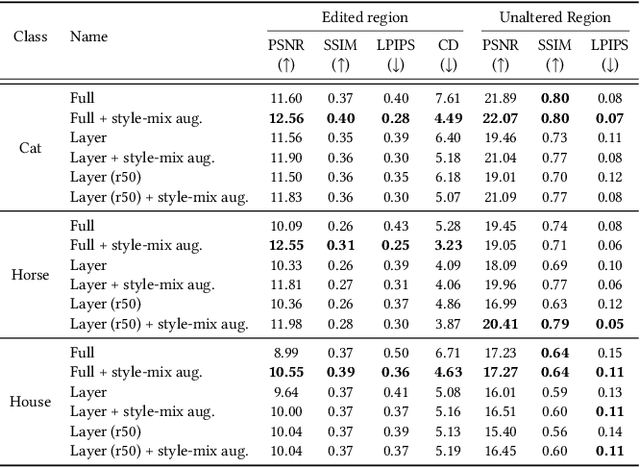
Deep generative models make visual content creation more accessible to novice users by automating the synthesis of diverse, realistic content based on a collected dataset. However, the current machine learning approaches miss a key element of the creative process -- the ability to synthesize things that go far beyond the data distribution and everyday experience. To begin to address this issue, we enable a user to "warp" a given model by editing just a handful of original model outputs with desired geometric changes. Our method applies a low-rank update to a single model layer to reconstruct edited examples. Furthermore, to combat overfitting, we propose a latent space augmentation method based on style-mixing. Our method allows a user to create a model that synthesizes endless objects with defined geometric changes, enabling the creation of a new generative model without the burden of curating a large-scale dataset. We also demonstrate that edited models can be composed to achieve aggregated effects, and we present an interactive interface to enable users to create new models through composition. Empirical measurements on multiple test cases suggest the advantage of our method against recent GAN fine-tuning methods. Finally, we showcase several applications using the edited models, including latent space interpolation and image editing.