 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Context-Aware Transformers For Spinal Cancer Detection and Radiological Grading
Jun 27, 2022
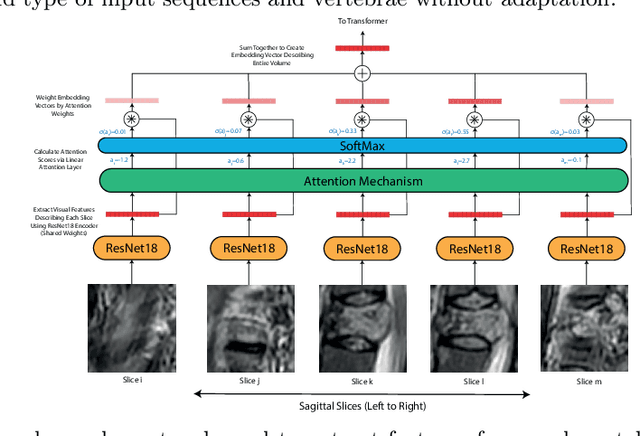

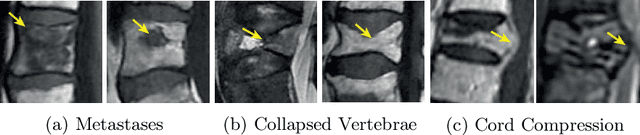
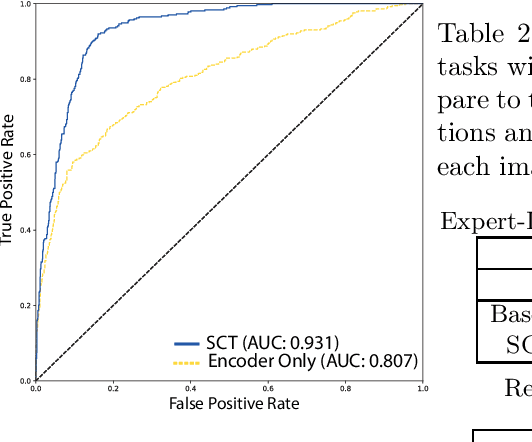
This paper proposes a novel transformer-based model architecture for medical imaging problems involving analysis of vertebrae. It considers two applications of such models in MR images: (a) detection of spinal metastases and the related conditions of vertebral fractures and metastatic cord compression, (b) radiological grading of common degenerative changes in intervertebral discs. Our contributions are as follows: (i) We propose a Spinal Context Transformer (SCT), a deep-learning architecture suited for the analysis of repeated anatomical structures in medical imaging such as vertebral bodies (VBs). Unlike previous related methods, SCT considers all VBs as viewed in all available image modalities together, making predictions for each based on context from the rest of the spinal column and all available imaging modalities. (ii) We apply the architecture to a novel and important task: detecting spinal metastases and the related conditions of cord compression and vertebral fractures/collapse from multi-series spinal MR scans. This is done using annotations extracted from free-text radiological reports as opposed to bespoke annotation. However, the resulting model shows strong agreement with vertebral-level bespoke radiologist annotations on the test set. (iii) We also apply SCT to an existing problem: radiological grading of inter-vertebral discs (IVDs) in lumbar MR scans for common degenerative changes.We show that by considering the context of vertebral bodies in the image, SCT improves the accuracy for several gradings compared to previously published model.
ORFD: A Dataset and Benchmark for Off-Road Freespace Detection
Jun 20, 2022



Freespace detection is an essential component of autonomous driving technology and plays an important role in trajectory planning. In the last decade, deep learning-based free space detection methods have been proved feasible. However, these efforts were focused on urban road environments and few deep learning-based methods were specifically designed for off-road free space detection due to the lack of off-road benchmarks. In this paper, we present the ORFD dataset, which, to our knowledge, is the first off-road free space detection dataset. The dataset was collected in different scenes (woodland, farmland, grassland, and countryside), different weather conditions (sunny, rainy, foggy, and snowy), and different light conditions (bright light, daylight, twilight, darkness), which totally contains 12,198 LiDAR point cloud and RGB image pairs with the traversable area, non-traversable area and unreachable area annotated in detail. We propose a novel network named OFF-Net, which unifies Transformer architecture to aggregate local and global information, to meet the requirement of large receptive fields for free space detection tasks. We also propose the cross-attention to dynamically fuse LiDAR and RGB image information for accurate off-road free space detection. Dataset and code are publicly available athttps://github.com/chaytonmin/OFF-Net.
Image Inpainting via Conditional Texture and Structure Dual Generation
Aug 22, 2021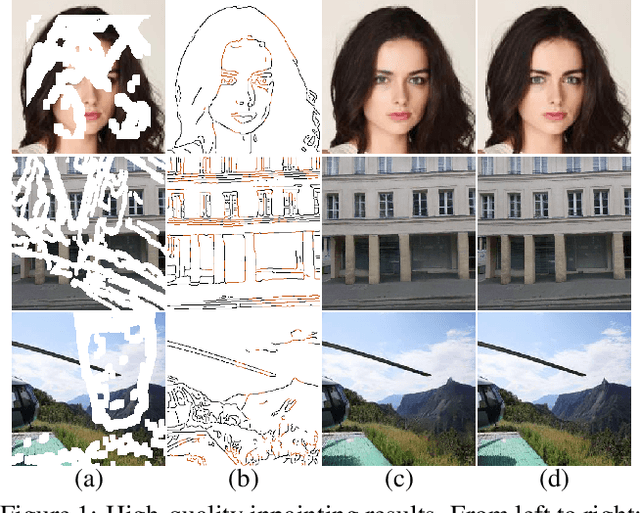
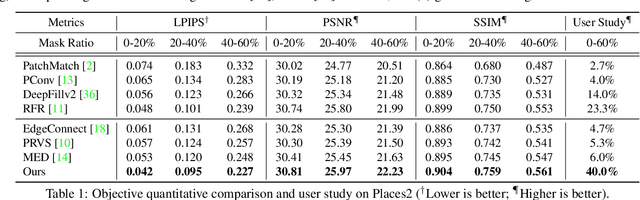
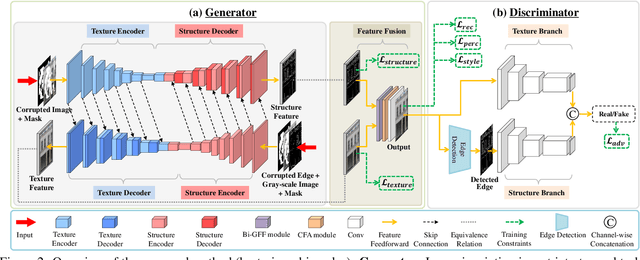
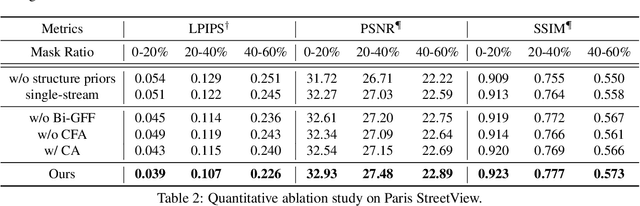
Deep generative approaches have recently made considerable progress in image inpainting by introducing structure priors. Due to the lack of proper interaction with image texture during structure reconstruction, however, current solutions are incompetent in handling the cases with large corruptions, and they generally suffer from distorted results. In this paper, we propose a novel two-stream network for image inpainting, which models the structure-constrained texture synthesis and texture-guided structure reconstruction in a coupled manner so that they better leverage each other for more plausible generation. Furthermore, to enhance the global consistency, a Bi-directional Gated Feature Fusion (Bi-GFF) module is designed to exchange and combine the structure and texture information and a Contextual Feature Aggregation (CFA) module is developed to refine the generated contents by region affinity learning and multi-scale feature aggregation. Qualitative and quantitative experiments on the CelebA, Paris StreetView and Places2 datasets demonstrate the superiority of the proposed method. Our code is available at https://github.com/Xiefan-Guo/CTSDG.
A comparative study of paired versus unpaired deep learning methods for physically enhancing digital rock image resolution
Dec 16, 2021

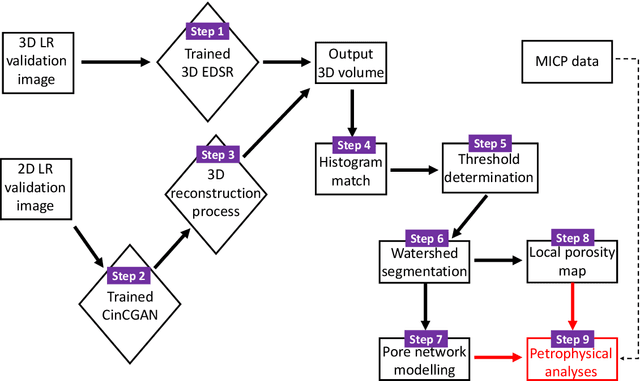
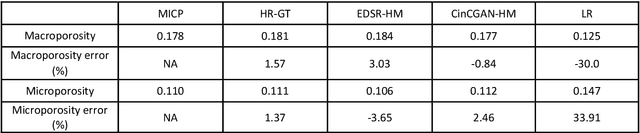
X-ray micro-computed tomography (micro-CT) has been widely leveraged to characterise pore-scale geometry in subsurface porous rock. Recent developments in super resolution (SR) methods using deep learning allow the digital enhancement of low resolution (LR) images over large spatial scales, creating SR images comparable to the high resolution (HR) ground truth. This circumvents traditional resolution and field-of-view trade-offs. An outstanding issue is the use of paired (registered) LR and HR data, which is often required in the training step of such methods but is difficult to obtain. In this work, we rigorously compare two different state-of-the-art SR deep learning techniques, using both paired and unpaired data, with like-for-like ground truth data. The first approach requires paired images to train a convolutional neural network (CNN) while the second approach uses unpaired images to train a generative adversarial network (GAN). The two approaches are compared using a micro-CT carbonate rock sample with complicated micro-porous textures. We implemented various image based and numerical verifications and experimental validation to quantitatively evaluate the physical accuracy and sensitivities of the two methods. Our quantitative results show that unpaired GAN approach can reconstruct super-resolution images as precise as paired CNN method, with comparable training times and dataset requirement. This unlocks new applications for micro-CT image enhancement using unpaired deep learning methods; image registration is no longer needed during the data processing stage. Decoupled images from data storage platforms can be exploited more efficiently to train networks for SR digital rock applications. This opens up a new pathway for various applications of multi-scale flow simulation in heterogeneous porous media.
Unsupervised Foggy Scene Understanding via Self Spatial-Temporal Label Diffusion
Jun 10, 2022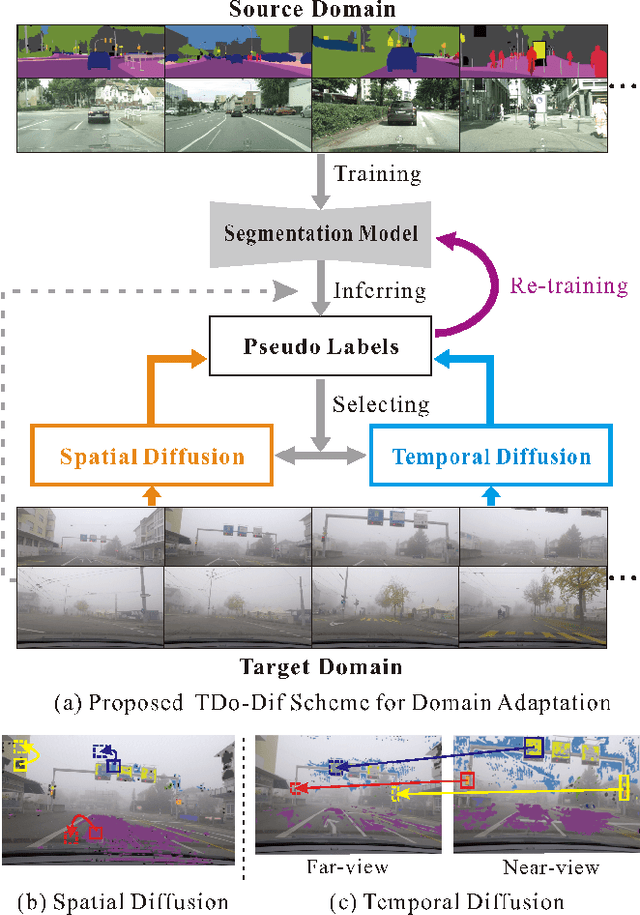
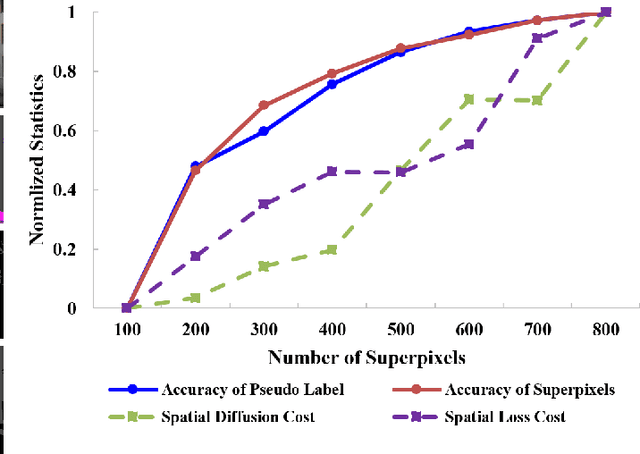
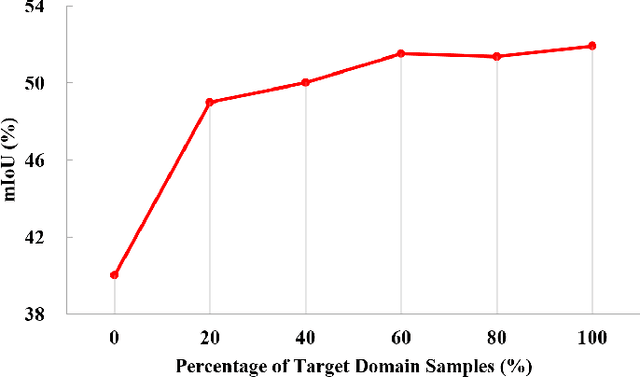
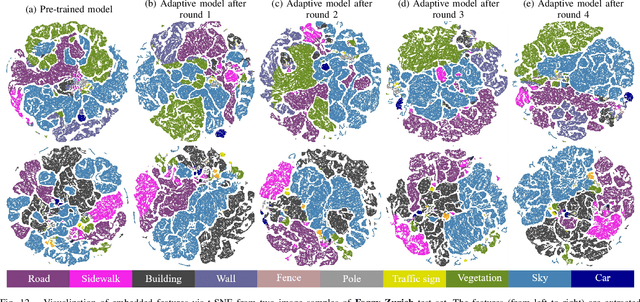
Understanding foggy image sequence in the driving scenes is critical for autonomous driving, but it remains a challenging task due to the difficulty in collecting and annotating real-world images of adverse weather. Recently, the self-training strategy has been considered a powerful solution for unsupervised domain adaptation, which iteratively adapts the model from the source domain to the target domain by generating target pseudo labels and re-training the model. However, the selection of confident pseudo labels inevitably suffers from the conflict between sparsity and accuracy, both of which will lead to suboptimal models. To tackle this problem, we exploit the characteristics of the foggy image sequence of driving scenes to densify the confident pseudo labels. Specifically, based on the two discoveries of local spatial similarity and adjacent temporal correspondence of the sequential image data, we propose a novel Target-Domain driven pseudo label Diffusion (TDo-Dif) scheme. It employs superpixels and optical flows to identify the spatial similarity and temporal correspondence, respectively and then diffuses the confident but sparse pseudo labels within a superpixel or a temporal corresponding pair linked by the flow. Moreover, to ensure the feature similarity of the diffused pixels, we introduce local spatial similarity loss and temporal contrastive loss in the model re-training stage. Experimental results show that our TDo-Dif scheme helps the adaptive model achieve 51.92% and 53.84% mean intersection-over-union (mIoU) on two publicly available natural foggy datasets (Foggy Zurich and Foggy Driving), which exceeds the state-of-the-art unsupervised domain adaptive semantic segmentation methods. Models and data can be found at https://github.com/velor2012/TDo-Dif.
Dual Graph Convolutional Networks with Transformer and Curriculum Learning for Image Captioning
Aug 05, 2021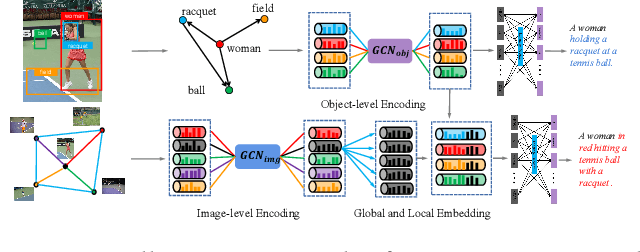

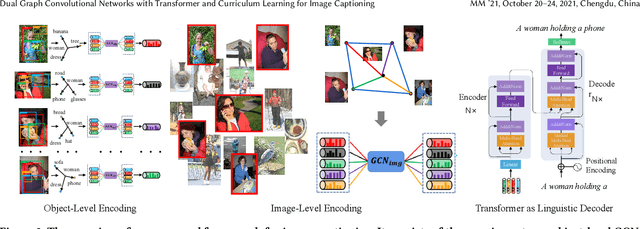
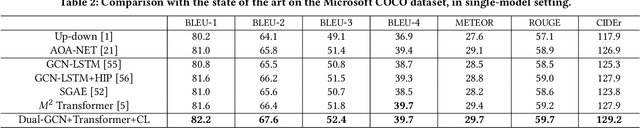
Existing image captioning methods just focus on understanding the relationship between objects or instances in a single image, without exploring the contextual correlation existed among contextual image. In this paper, we propose Dual Graph Convolutional Networks (Dual-GCN) with transformer and curriculum learning for image captioning. In particular, we not only use an object-level GCN to capture the object to object spatial relation within a single image, but also adopt an image-level GCN to capture the feature information provided by similar images. With the well-designed Dual-GCN, we can make the linguistic transformer better understand the relationship between different objects in a single image and make full use of similar images as auxiliary information to generate a reasonable caption description for a single image. Meanwhile, with a cross-review strategy introduced to determine difficulty levels, we adopt curriculum learning as the training strategy to increase the robustness and generalization of our proposed model. We conduct extensive experiments on the large-scale MS COCO dataset, and the experimental results powerfully demonstrate that our proposed method outperforms recent state-of-the-art approaches. It achieves a BLEU-1 score of 82.2 and a BLEU-2 score of 67.6. Our source code is available at {\em \color{magenta}{\url{https://github.com/Unbear430/DGCN-for-image-captioning}}}.
Controllable Data Generation by Deep Learning: A Review
Jul 25, 2022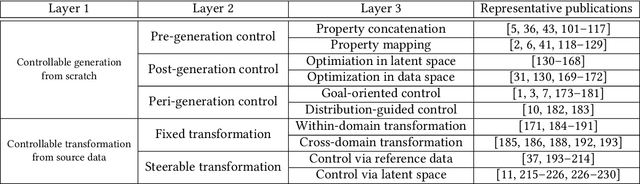
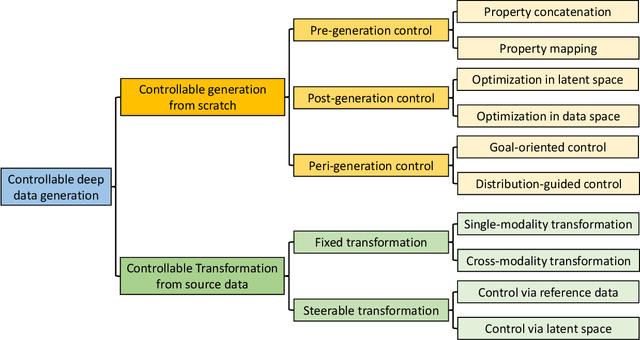
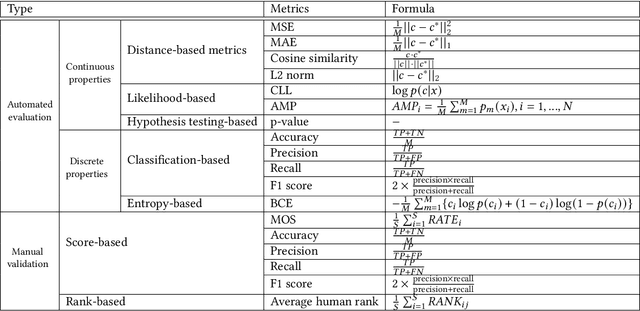
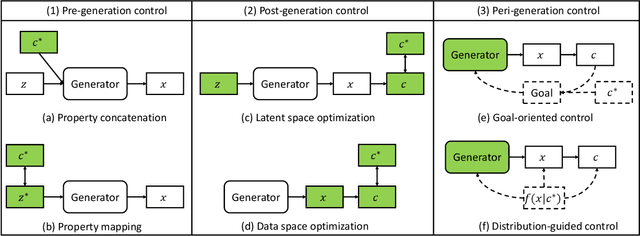
Designing and generating new data under targeted properties has been attracting various critical applications such as molecule design, image editing and speech synthesis. Traditional hand-crafted approaches heavily rely on expertise experience and intensive human efforts, yet still suffer from the insufficiency of scientific knowledge and low throughput to support effective and efficient data generation. Recently, the advancement of deep learning induces expressive methods that can learn the underlying representation and properties of data. Such capability provides new opportunities in figuring out the mutual relationship between the structural patterns and functional properties of the data and leveraging such relationship to generate structural data given the desired properties. This article provides a systematic review of this promising research area, commonly known as controllable deep data generation. Firstly, the potential challenges are raised and preliminaries are provided. Then the controllable deep data generation is formally defined, a taxonomy on various techniques is proposed and the evaluation metrics in this specific domain are summarized. After that, exciting applications of controllable deep data generation are introduced and existing works are experimentally analyzed and compared. Finally, the promising future directions of controllable deep data generation are highlighted and five potential challenges are identified.
An Interactive Image-based Modeling System
Mar 28, 2022


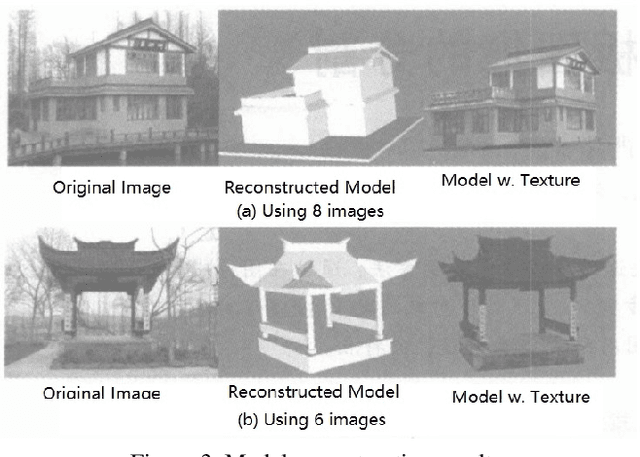
This paper propose a interactive 3D modeling method and corresponding system based on single or multiple uncalibrated images. The main feature of this method is that, according to the modeling habits of ordinary people, the 3D model of the target is reconstructed from coarse to fine images. On the basis of determining the approximate shape, the user adds or modify projection constraints and spatial constraints, and apply topology modification, gradually realize camera calibration, refine rough model, and finally complete the reconstruction of objects with arbitrary geometry and topology. During the interactive process, the geometric parameters and camera projection matrix are solved in real time, and the reconstruction results are displayed in a 3D window.
Multiscale Analysis for Improving Texture Classification
Apr 21, 2022

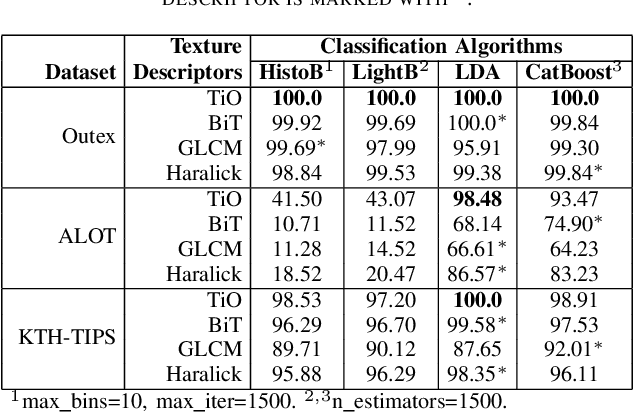

Information from an image occurs over multiple and distinct spatial scales. Image pyramid multiresolution representations are a useful data structure for image analysis and manipulation over a spectrum of spatial scales. This paper employs the Gaussian-Laplacian pyramid to treat different spatial frequency bands of a texture separately. First, we generate three images corresponding to three levels of the Gaussian-Laplacian pyramid for an input image to capture intrinsic details. Then we aggregate features extracted from gray and color texture images using bio-inspired texture descriptors, information-theoretic measures, gray-level co-occurrence matrix features, and Haralick statistical features into a single feature vector. Such an aggregation aims at producing features that characterize textures to their maximum extent, unlike employing each descriptor separately, which may lose some relevant textural information and reduce the classification performance. The experimental results on texture and histopathologic image datasets have shown the advantages of the proposed method compared to state-of-the-art approaches. Such findings emphasize the importance of multiscale image analysis and corroborate that the descriptors mentioned above are complementary.
Improving Fine-Grained Visual Recognition in Low Data Regimes via Self-Boosting Attention Mechanism
Aug 01, 2022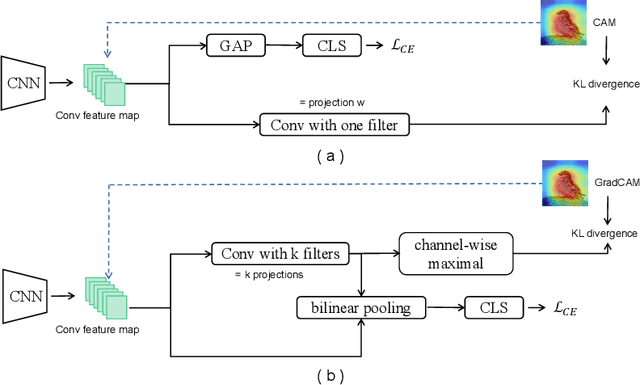
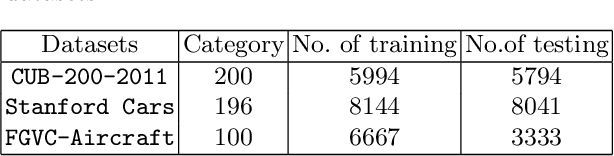
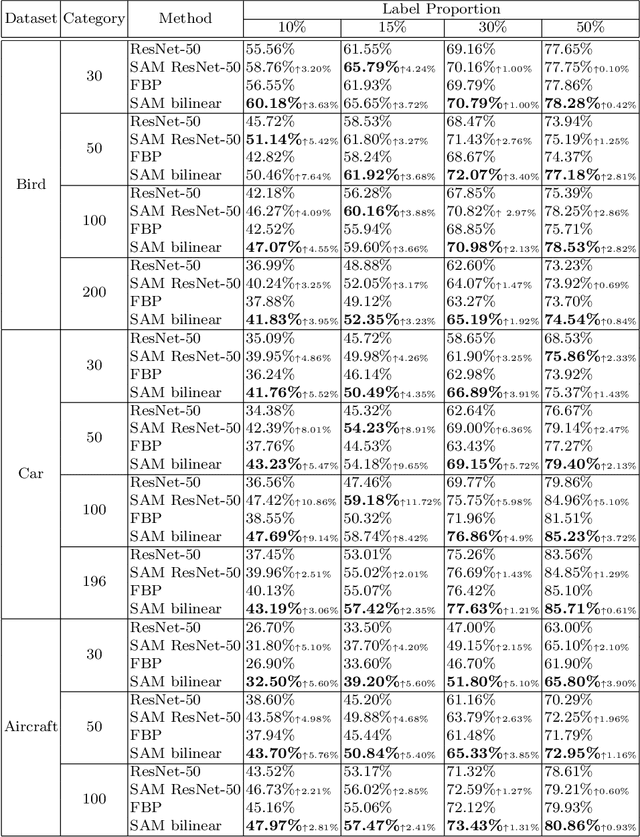
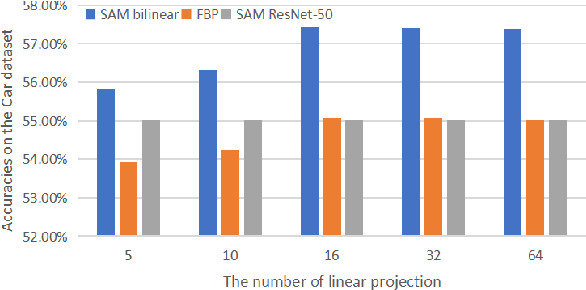
The challenge of fine-grained visual recognition often lies in discovering the key discriminative regions. While such regions can be automatically identified from a large-scale labeled dataset, a similar method might become less effective when only a few annotations are available. In low data regimes, a network often struggles to choose the correct regions for recognition and tends to overfit spurious correlated patterns from the training data. To tackle this issue, this paper proposes the self-boosting attention mechanism, a novel method for regularizing the network to focus on the key regions shared across samples and classes. Specifically, the proposed method first generates an attention map for each training image, highlighting the discriminative part for identifying the ground-truth object category. Then the generated attention maps are used as pseudo-annotations. The network is enforced to fit them as an auxiliary task. We call this approach the self-boosting attention mechanism (SAM). We also develop a variant by using SAM to create multiple attention maps to pool convolutional maps in a style of bilinear pooling, dubbed SAM-Bilinear. Through extensive experimental studies, we show that both methods can significantly improve fine-grained visual recognition performance on low data regimes and can be incorporated into existing network architectures. The source code is publicly available at: https://github.com/GANPerf/SAM