 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Automatically Discovering Novel Visual Categories with Self-supervised Prototype Learning
Aug 01, 2022
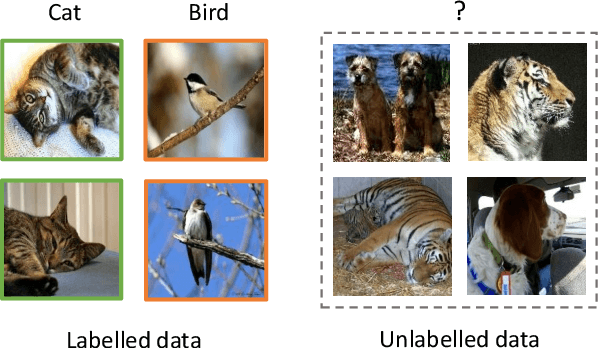
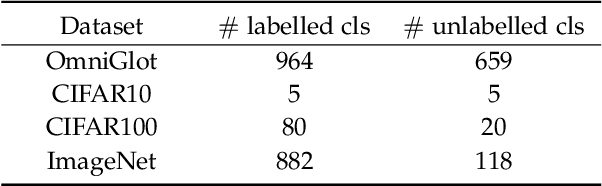
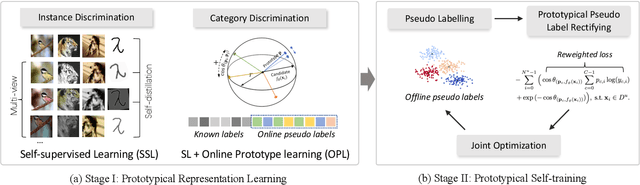
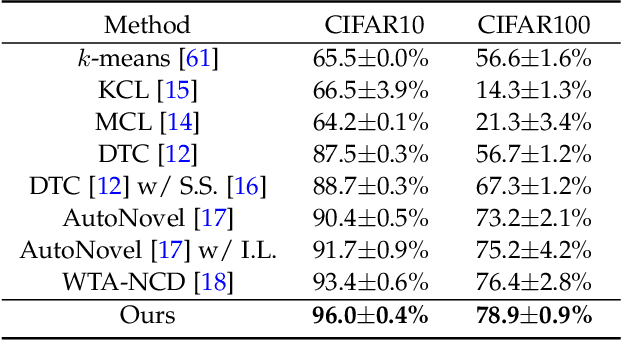
This paper tackles the problem of novel category discovery (NCD), which aims to discriminate unknown categories in large-scale image collections. The NCD task is challenging due to the closeness to the real-world scenarios, where we have only encountered some partial classes and images. Unlike other works on the NCD, we leverage the prototypes to emphasize the importance of category discrimination and alleviate the issue of missing annotations of novel classes. Concretely, we propose a novel adaptive prototype learning method consisting of two main stages: prototypical representation learning and prototypical self-training. In the first stage, we obtain a robust feature extractor, which could serve for all images with base and novel categories. This ability of instance and category discrimination of the feature extractor is boosted by self-supervised learning and adaptive prototypes. In the second stage, we utilize the prototypes again to rectify offline pseudo labels and train a final parametric classifier for category clustering. We conduct extensive experiments on four benchmark datasets and demonstrate the effectiveness and robustness of the proposed method with state-of-the-art performance.
Towards Lightweight Super-Resolution with Dual Regression Learning
Jul 16, 2022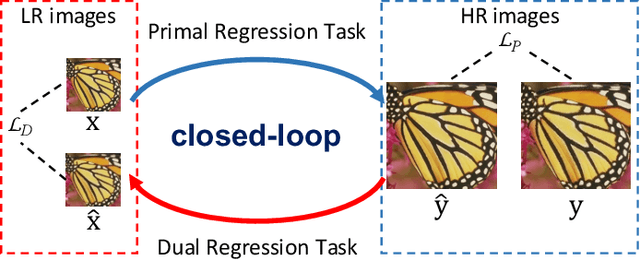
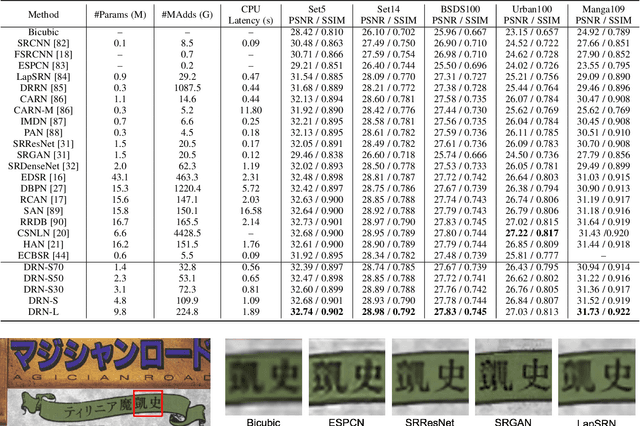
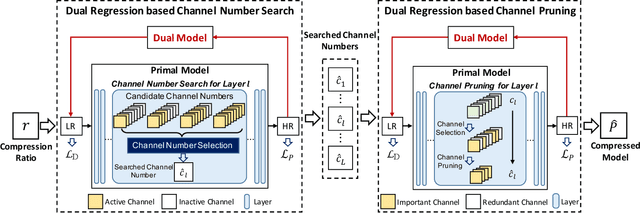
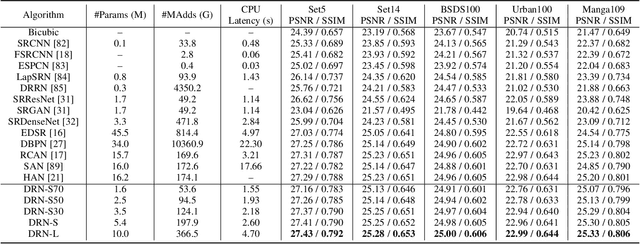
Deep neural networks have exhibited remarkable performance in image super-resolution (SR) tasks by learning a mapping from low-resolution (LR) images to high-resolution (HR) images. However, the SR problem is typically an ill-posed problem and existing methods would come with several limitations. First, the possible mapping space of SR can be extremely large since there may exist many different HR images that can be downsampled to the same LR image. As a result, it is hard to directly learn a promising SR mapping from such a large space. Second, it is often inevitable to develop very large models with extremely high computational cost to yield promising SR performance. In practice, one can use model compression techniques to obtain compact models by reducing model redundancy. Nevertheless, it is hard for existing model compression methods to accurately identify the redundant components due to the extremely large SR mapping space. To alleviate the first challenge, we propose a dual regression learning scheme to reduce the space of possible SR mappings. Specifically, in addition to the mapping from LR to HR images, we learn an additional dual regression mapping to estimate the downsampling kernel and reconstruct LR images. In this way, the dual mapping acts as a constraint to reduce the space of possible mappings. To address the second challenge, we propose a lightweight dual regression compression method to reduce model redundancy in both layer-level and channel-level based on channel pruning. Specifically, we first develop a channel number search method that minimizes the dual regression loss to determine the redundancy of each layer. Given the searched channel numbers, we further exploit the dual regression manner to evaluate the importance of channels and prune the redundant ones. Extensive experiments show the effectiveness of our method in obtaining accurate and efficient SR models.
Fast Two-step Blind Optical Aberration Correction
Aug 01, 2022

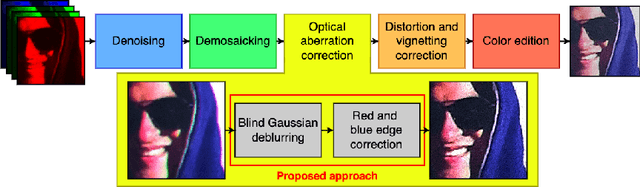

The optics of any camera degrades the sharpness of photographs, which is a key visual quality criterion. This degradation is characterized by the point-spread function (PSF), which depends on the wavelengths of light and is variable across the imaging field. In this paper, we propose a two-step scheme to correct optical aberrations in a single raw or JPEG image, i.e., without any prior information on the camera or lens. First, we estimate local Gaussian blur kernels for overlapping patches and sharpen them with a non-blind deblurring technique. Based on the measurements of the PSFs of dozens of lenses, these blur kernels are modeled as RGB Gaussians defined by seven parameters. Second, we remove the remaining lateral chromatic aberrations (not contemplated in the first step) with a convolutional neural network, trained to minimize the red/green and blue/green residual images. Experiments on both synthetic and real images show that the combination of these two stages yields a fast state-of-the-art blind optical aberration compensation technique that competes with commercial non-blind algorithms.
Benchmarking Scientific Image Forgery Detectors
May 26, 2021The scientific image integrity area presents a challenging research bottleneck, the lack of available datasets to design and evaluate forensic techniques. Its data sensitivity creates a legal hurdle that prevents one to rely on real tampered cases to build any sort of accessible forensic benchmark. To mitigate this bottleneck, we present an extendable open-source library that reproduces the most common image forgery operations reported by the research integrity community: duplication, retouching, and cleaning. Using this library and realistic scientific images, we create a large scientific forgery image benchmark (39,423 images) with an enriched ground-truth. In addition, concerned about the high number of retracted papers due to image duplication, this work evaluates the state-of-the-art copy-move detection methods in the proposed dataset, using a new metric that asserts consistent match detection between the source and the copied region. The dataset and source-code will be freely available upon acceptance of the paper.
Two-dimensional total absorption spectroscopy with conditional generative adversarial networks
Jun 23, 2022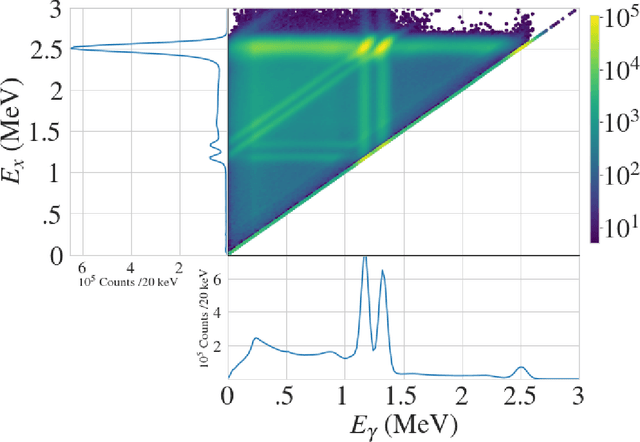
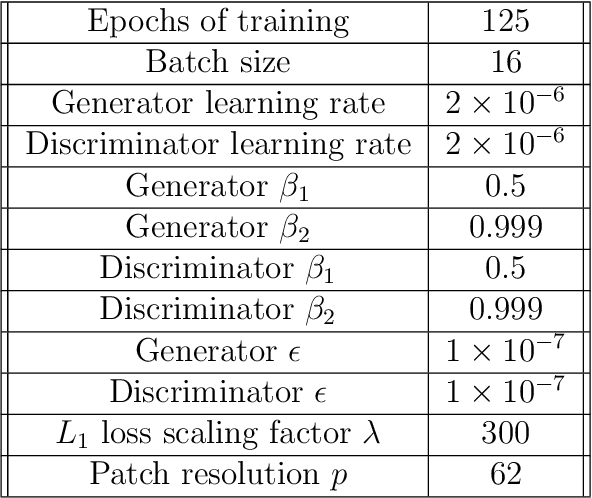
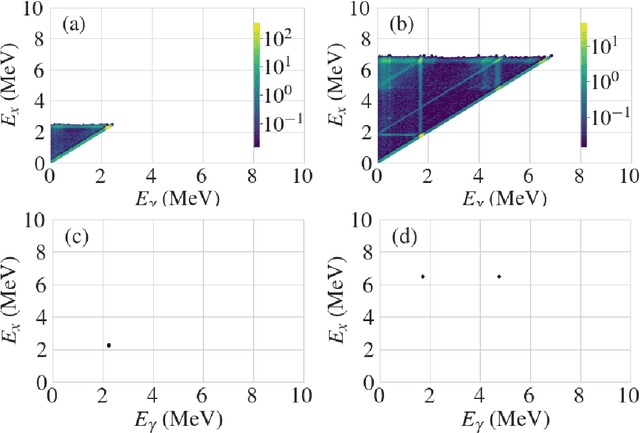
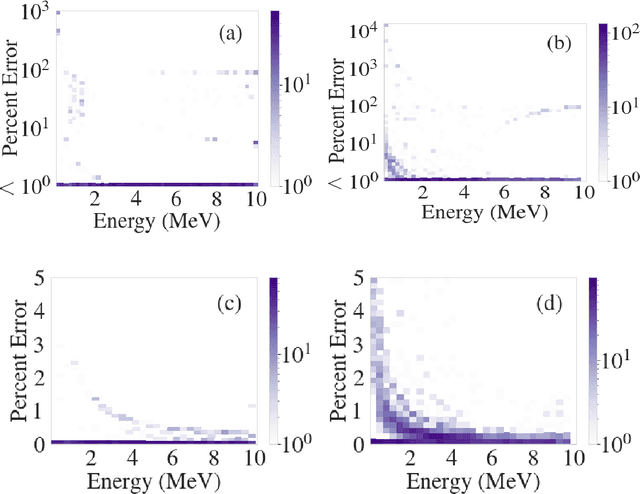
We explore the use of machine learning techniques to remove the response of large volume $\gamma$-ray detectors from experimental spectra. Segmented $\gamma$-ray total absorption spectrometers (TAS) allow for the simultaneous measurement of individual $\gamma$-ray energy (E$_\gamma$) and total excitation energy (E$_x$). Analysis of TAS detector data is complicated by the fact that the E$_x$ and E$_\gamma$ quantities are correlated, and therefore, techniques that simply unfold using E$_x$ and E$_\gamma$ response functions independently are not as accurate. In this work, we investigate the use of conditional generative adversarial networks (cGANs) to simultaneously unfold $E_{x}$ and $E_{\gamma}$ data in TAS detectors. Specifically, we employ a Pix2Pix cGAN, a generative modeling technique based on recent advances in deep learning, to treat $(E_x, E_{\gamma})$ matrix unfolding as an image-to-image translation problem. We present results for simulated and experimental matrices of single-$\gamma$ and double-$\gamma$ decay cascades. Our model demonstrates characterization capabilities within detector resolution limits for upwards of $90\%$ of simulated test cases.
Transformers as Meta-Learners for Implicit Neural Representations
Aug 05, 2022



Implicit Neural Representations (INRs) have emerged and shown their benefits over discrete representations in recent years. However, fitting an INR to the given observations usually requires optimization with gradient descent from scratch, which is inefficient and does not generalize well with sparse observations. To address this problem, most of the prior works train a hypernetwork that generates a single vector to modulate the INR weights, where the single vector becomes an information bottleneck that limits the reconstruction precision of the output INR. Recent work shows that the whole set of weights in INR can be precisely inferred without the single-vector bottleneck by gradient-based meta-learning. Motivated by a generalized formulation of gradient-based meta-learning, we propose a formulation that uses Transformers as hypernetworks for INRs, where it can directly build the whole set of INR weights with Transformers specialized as set-to-set mapping. We demonstrate the effectiveness of our method for building INRs in different tasks and domains, including 2D image regression and view synthesis for 3D objects. Our work draws connections between the Transformer hypernetworks and gradient-based meta-learning algorithms and we provide further analysis for understanding the generated INRs.
Computer vision-based analysis of buildings and built environments: A systematic review of current approaches
Aug 01, 2022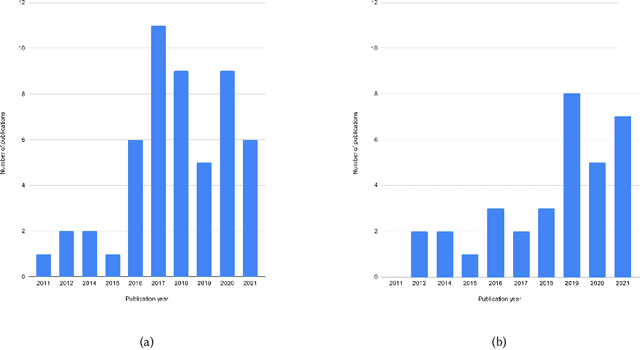
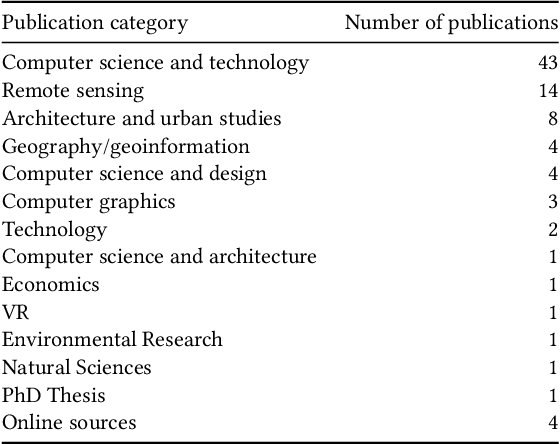
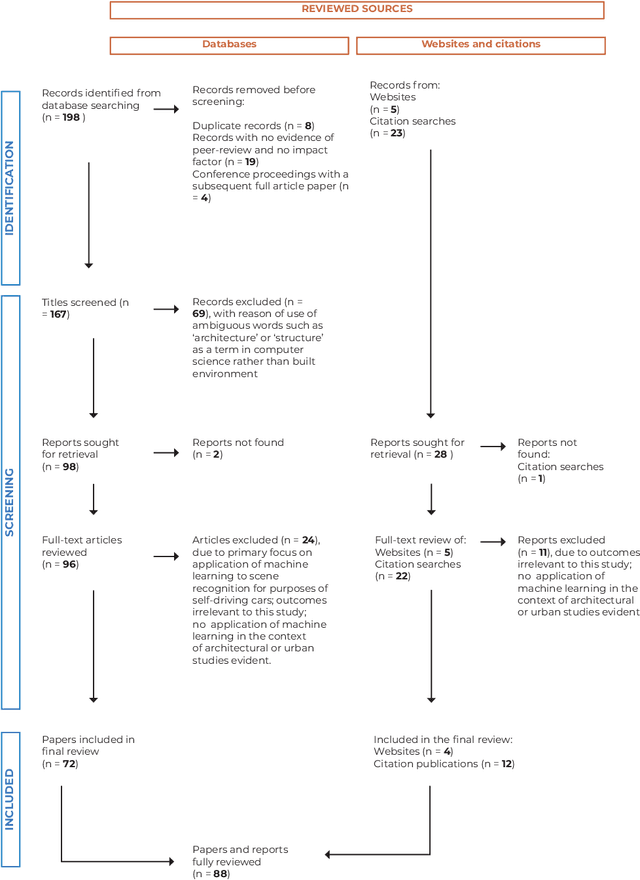
Analysing 88 sources published from 2011 to 2021, this paper presents a first systematic review of the computer vision-based analysis of buildings and the built environments to assess its value to architectural and urban design studies. Following a multi-stage selection process, the types of algorithms and data sources used are discussed in respect to architectural applications such as a building classification, detail classification, qualitative environmental analysis, building condition survey, and building value estimation. This reveals current research gaps and trends, and highlights two main categories of research aims. First, to use or optimise computer vision methods for architectural image data, which can then help automate time-consuming, labour-intensive, or complex tasks of visual analysis. Second, to explore the methodological benefits of machine learning approaches to investigate new questions about the built environment by finding patterns and relationships between visual, statistical, and qualitative data, which can overcome limitations of conventional manual analysis. The growing body of research offers new methods to architectural and design studies, with the paper identifying future challenges and directions of research.
Neural Strands: Learning Hair Geometry and Appearance from Multi-View Images
Jul 28, 2022

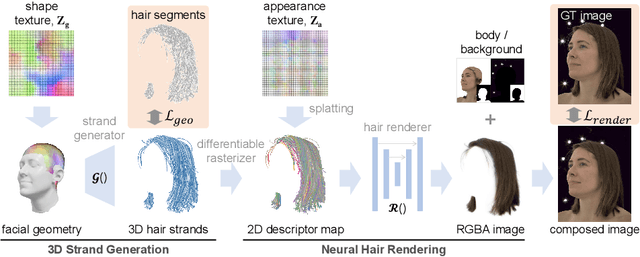
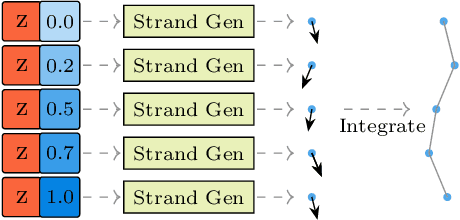
We present Neural Strands, a novel learning framework for modeling accurate hair geometry and appearance from multi-view image inputs. The learned hair model can be rendered in real-time from any viewpoint with high-fidelity view-dependent effects. Our model achieves intuitive shape and style control unlike volumetric counterparts. To enable these properties, we propose a novel hair representation based on a neural scalp texture that encodes the geometry and appearance of individual strands at each texel location. Furthermore, we introduce a novel neural rendering framework based on rasterization of the learned hair strands. Our neural rendering is strand-accurate and anti-aliased, making the rendering view-consistent and photorealistic. Combining appearance with a multi-view geometric prior, we enable, for the first time, the joint learning of appearance and explicit hair geometry from a multi-view setup. We demonstrate the efficacy of our approach in terms of fidelity and efficiency for various hairstyles.
Learning to Grasp on the Moon from 3D Octree Observations with Deep Reinforcement Learning
Aug 01, 2022
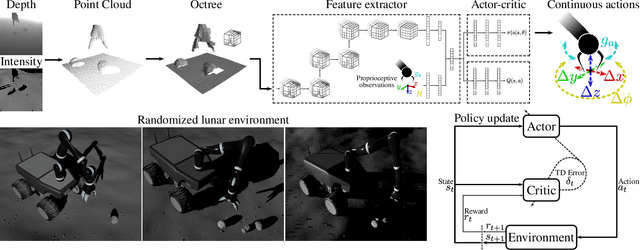
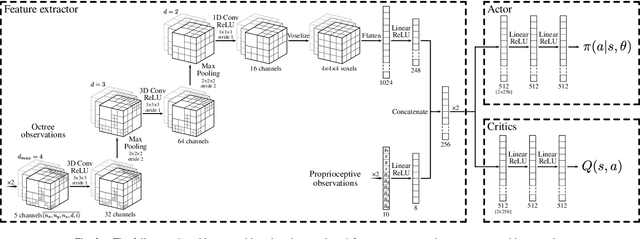
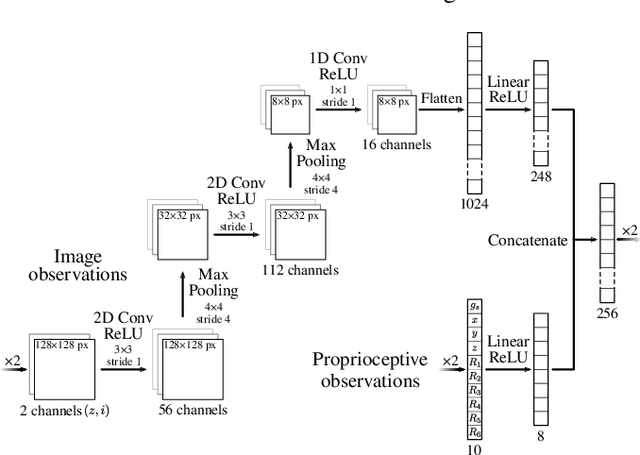
Extraterrestrial rovers with a general-purpose robotic arm have many potential applications in lunar and planetary exploration. Introducing autonomy into such systems is desirable for increasing the time that rovers can spend gathering scientific data and collecting samples. This work investigates the applicability of deep reinforcement learning for vision-based robotic grasping of objects on the Moon. A novel simulation environment with procedurally-generated datasets is created to train agents under challenging conditions in unstructured scenes with uneven terrain and harsh illumination. A model-free off-policy actor-critic algorithm is then employed for end-to-end learning of a policy that directly maps compact octree observations to continuous actions in Cartesian space. Experimental evaluation indicates that 3D data representations enable more effective learning of manipulation skills when compared to traditionally used image-based observations. Domain randomization improves the generalization of learned policies to novel scenes with previously unseen objects and different illumination conditions. To this end, we demonstrate zero-shot sim-to-real transfer by evaluating trained agents on a real robot in a Moon-analogue facility.
Separable Quaternion Matrix Factorization for Polarization Images
Jul 28, 2022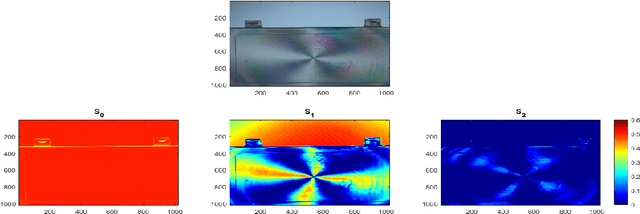
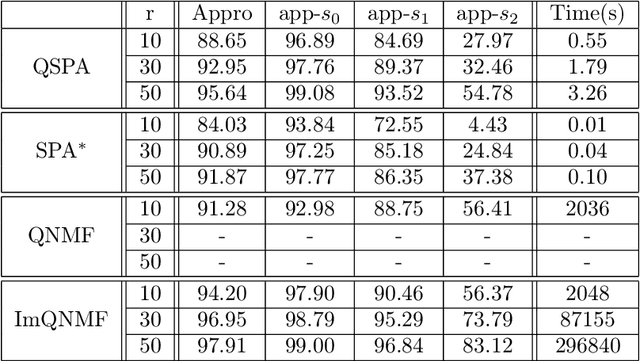
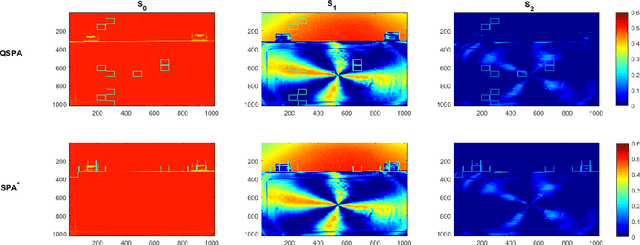
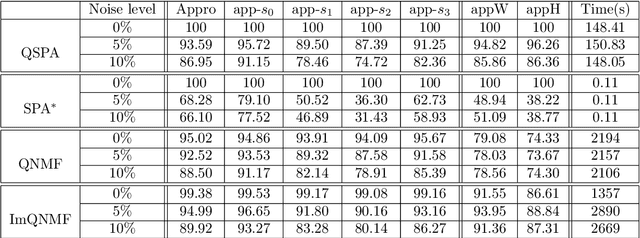
Polarization is a unique characteristic of transverse wave and is represented by Stokes parameters. Analysis of polarization states can reveal valuable information about the sources. In this paper, we propose a separable low-rank quaternion linear mixing model to polarized signals: we assume each column of the source factor matrix equals a column of polarized data matrix and refer to the corresponding problem as separable quaternion matrix factorization (SQMF). We discuss some properties of the matrix that can be decomposed by SQMF. To determine the source factor matrix in quaternion space, we propose a heuristic algorithm called quaternion successive projection algorithm (QSPA) inspired by the successive projection algorithm. To guarantee the effectiveness of QSPA, a new normalization operator is proposed for the quaternion matrix. We use a block coordinate descent algorithm to compute nonnegative factor activation matrix in real number space. We test our method on the applications of polarization image representation and spectro-polarimetric imaging unmixing to verify its effectiveness.