 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Prefix Language Models are Unified Modal Learners
Jun 15, 2022
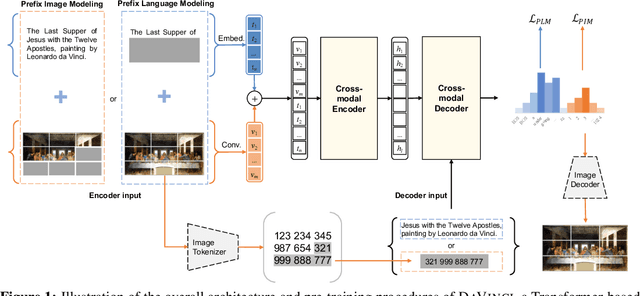
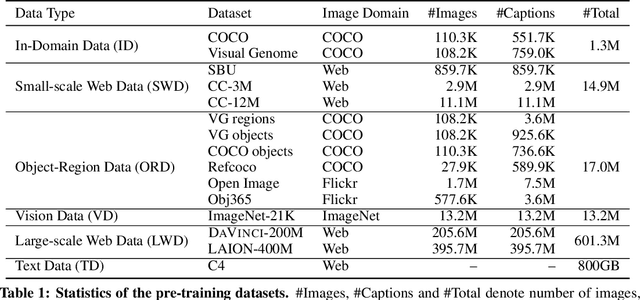
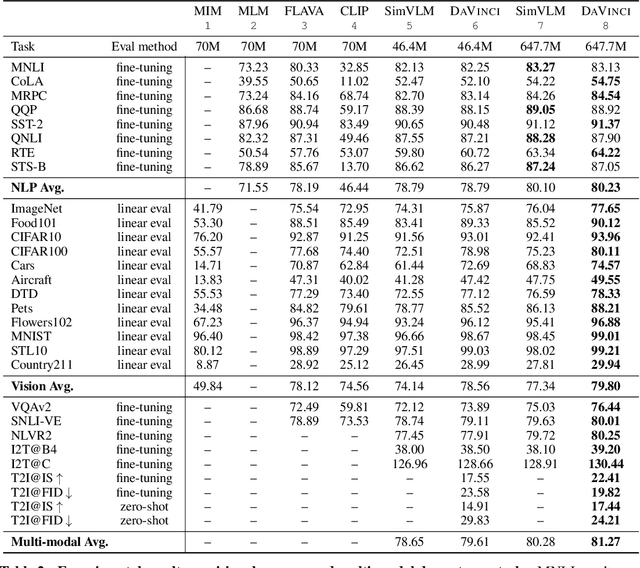

With the success of vision-language pre-training, we have witnessed the state-of-the-art has been pushed on multi-modal understanding and generation. However, the current pre-training paradigm is either incapable of targeting all modalities at once (e.g., text generation and image generation), or requires multi-fold well-designed tasks which significantly limits the scalability. We demonstrate that a unified modal model could be learned with a prefix language modeling objective upon text and image sequences. Thanks to the simple but powerful pre-training paradigm, our proposed model, DaVinci, is simple to train, scalable to huge data, and adaptable to a variety of downstream tasks across modalities (language / vision / vision+language), types (understanding / generation) and settings (e.g., zero-shot, fine-tuning, linear evaluation) with a single unified architecture. DaVinci achieves the competitive performance on a wide range of 26 understanding / generation tasks, and outperforms previous unified vision-language models on most tasks, including ImageNet classification (+1.6%), VQAv2 (+1.4%), COCO caption generation (BLEU@4 +1.1%, CIDEr +1.5%) and COCO image generation (IS +0.9%, FID -1.0%), at the comparable model and data scale. Furthermore, we offer a well-defined benchmark for future research by reporting the performance on different scales of the pre-training dataset on a heterogeneous and wide distribution coverage. Our results establish new, stronger baselines for future comparisons at different data scales and shed light on the difficulties of comparing VLP models more generally.
Evaluating Systemic Error Detection Methods using Synthetic Images
Jul 08, 2022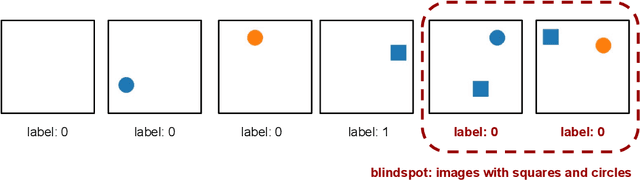
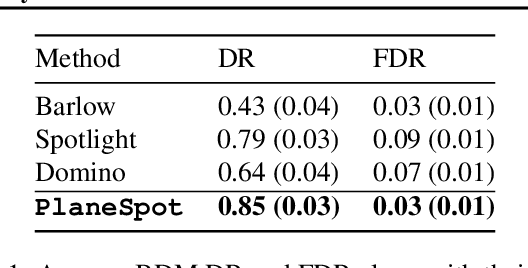
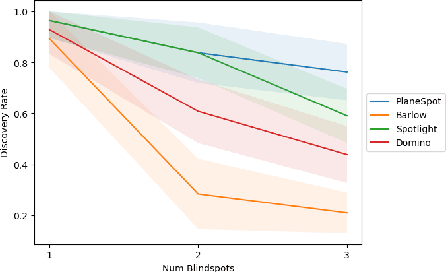

We introduce SpotCheck, a framework for generating synthetic datasets to use for evaluating methods for discovering blindspots (i.e., systemic errors) in image classifiers. We use SpotCheck to run controlled studies of how various factors influence the performance of blindspot discovery methods. Our experiments reveal several shortcomings of existing methods, such as relatively poor performance in settings with multiple blindspots and sensitivity to hyperparameters. Further, we find that a method based on dimensionality reduction, PlaneSpot, is competitive with existing methods, which has promising implications for the development of interactive tools.
Contrastive Semi-supervised Learning for Domain Adaptive Segmentation Across Similar Anatomical Structures
Aug 18, 2022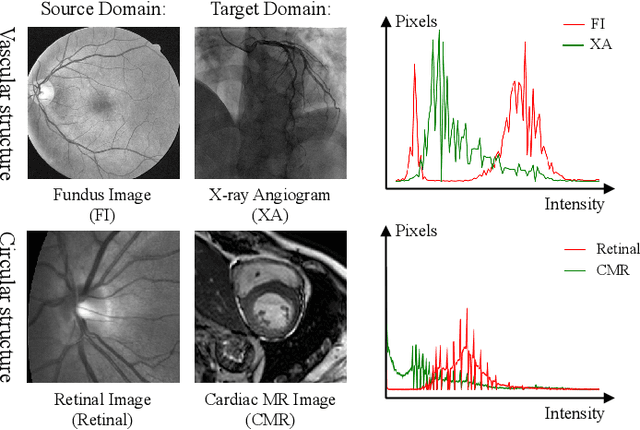
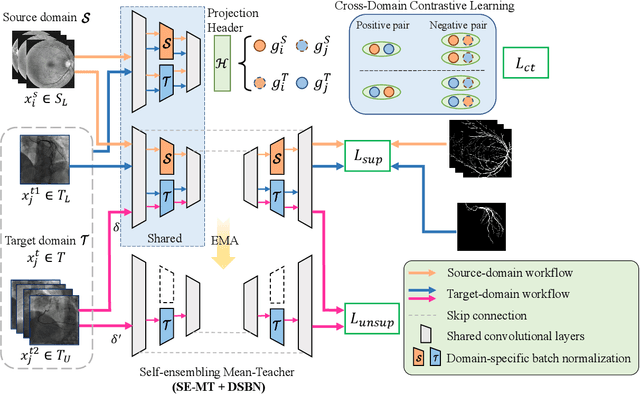
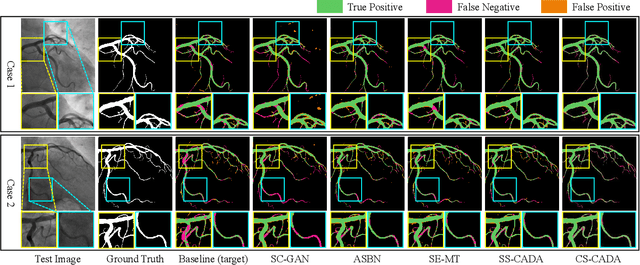
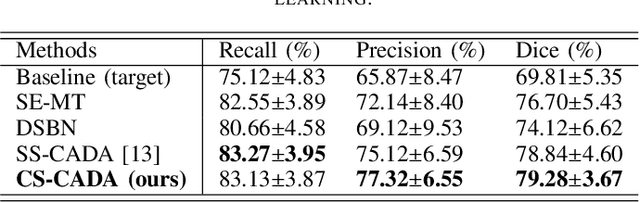
Convolutional Neural Networks (CNNs) have achieved state-of-the-art performance for medical image segmentation, yet need plenty of manual annotations for training. Semi-Supervised Learning (SSL) methods are promising to reduce the requirement of annotations, but their performance is still limited when the dataset size and the number of annotated images are small. Leveraging existing annotated datasets with similar anatomical structures to assist training has a potential for improving the model's performance. However, it is further challenged by the cross-anatomy domain shift due to the different appearance and even imaging modalities from the target structure. To solve this problem, we propose Contrastive Semi-supervised learning for Cross Anatomy Domain Adaptation (CS-CADA) that adapts a model to segment similar structures in a target domain, which requires only limited annotations in the target domain by leveraging a set of existing annotated images of similar structures in a source domain. We use Domain-Specific Batch Normalization (DSBN) to individually normalize feature maps for the two anatomical domains, and propose a cross-domain contrastive learning strategy to encourage extracting domain invariant features. They are integrated into a Self-Ensembling Mean-Teacher (SE-MT) framework to exploit unlabeled target domain images with a prediction consistency constraint. Extensive experiments show that our CS-CADA is able to solve the challenging cross-anatomy domain shift problem, achieving accurate segmentation of coronary arteries in X-ray images with the help of retinal vessel images and cardiac MR images with the help of fundus images, respectively, given only a small number of annotations in the target domain.
Implicit Channel Learning for Machine Learning Applications in 6G Wireless Networks
Jun 24, 2022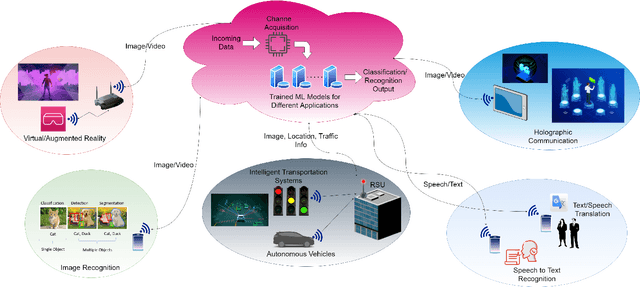
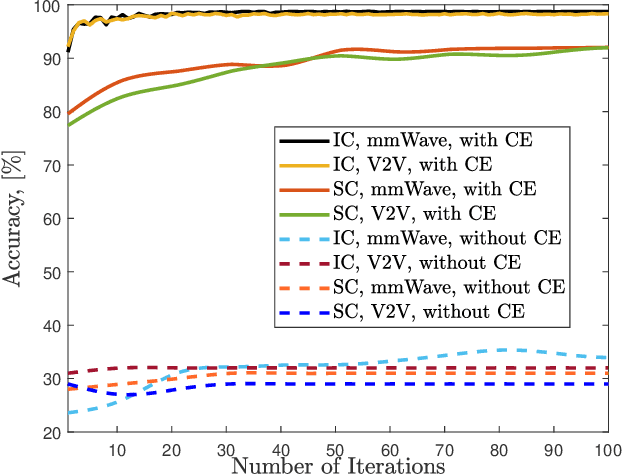
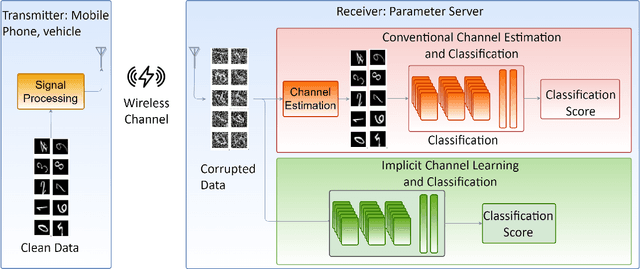
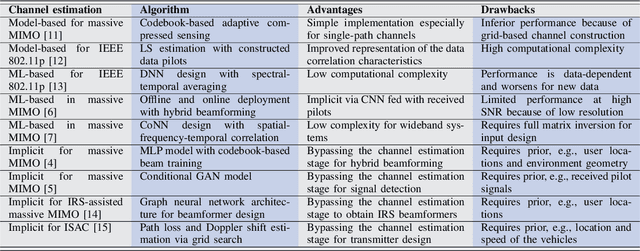
With the deployment of the fifth generation (5G) wireless systems gathering momentum across the world, possible technologies for 6G are under active research discussions. In particular, the role of machine learning (ML) in 6G is expected to enhance and aid emerging applications such as virtual and augmented reality, vehicular autonomy, and computer vision. This will result in large segments of wireless data traffic comprising image, video and speech. The ML algorithms process these for classification/recognition/estimation through the learning models located on cloud servers. This requires wireless transmission of data from edge devices to the cloud server. Channel estimation, handled separately from recognition step, is critical for accurate learning performance. Toward combining the learning for both channel and the ML data, we introduce implicit channel learning to perform the ML tasks without estimating the wireless channel. Here, the ML models are trained with channel-corrupted datasets in place of nominal data. Without channel estimation, the proposed approach exhibits approximately 60% improvement in image and speech classification tasks for diverse scenarios such as millimeter wave and IEEE 802.11p vehicular channels.
A Semantic Consistency Feature Alignment Object Detection Model Based on Mixed-Class Distribution Metrics
Jun 12, 2022
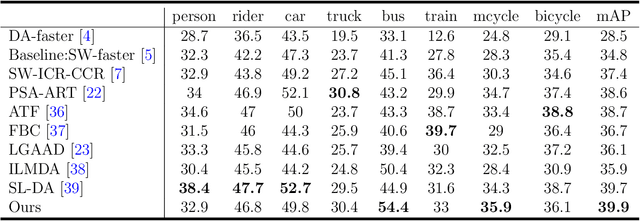
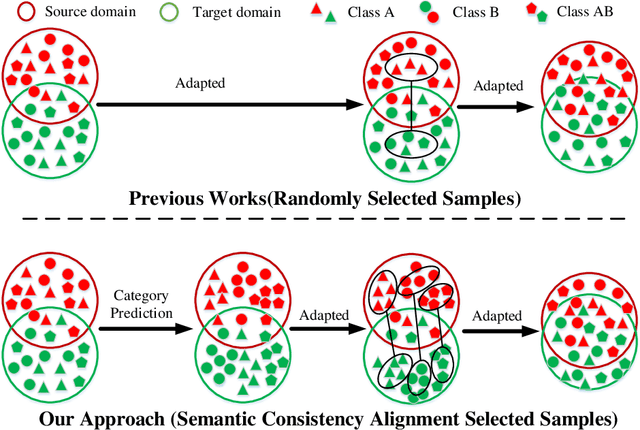
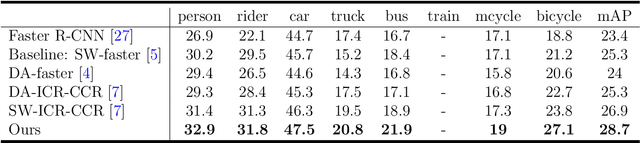
Unsupervised domain adaptation is critical in various computer vision tasks, such as object detection, instance segmentation, etc. They attempt to reduce domain bias-induced performance degradation while also promoting model application speed. Previous works in domain adaptation object detection attempt to align image-level and instance-level shifts to eventually minimize the domain discrepancy, but they may align single-class features to mixed-class features in image-level domain adaptation because each image in the object detection task may be more than one class and object. In order to achieve single-class with single-class alignment and mixed-class with mixed-class alignment, we treat the mixed-class of the feature as a new class and propose a mixed-classes $H-divergence$ for object detection to achieve homogenous feature alignment and reduce negative transfer. Then, a Semantic Consistency Feature Alignment Model (SCFAM) based on mixed-classes $H-divergence$ was also presented. To improve single-class and mixed-class semantic information and accomplish semantic separation, the SCFAM model proposes Semantic Prediction Models (SPM) and Semantic Bridging Components (SBC). And the weight of the pix domain discriminator loss is then changed based on the SPM result to reduce sample imbalance. Extensive unsupervised domain adaption experiments on widely used datasets illustrate our proposed approach's robust object detection in domain bias settings.
Splicing Detection and Localization In Satellite Imagery Using Conditional GANs
May 03, 2022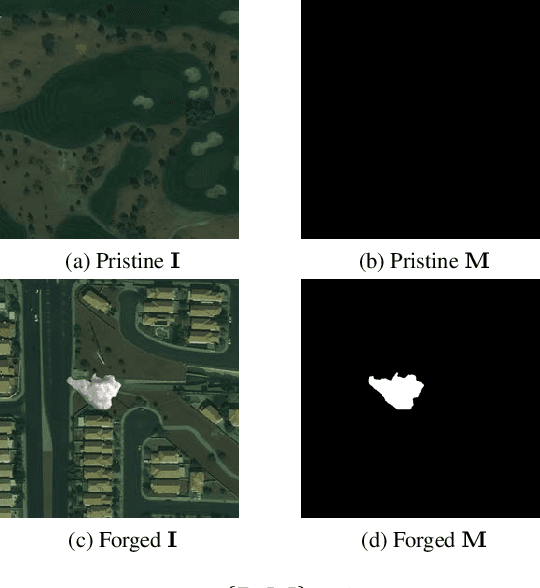
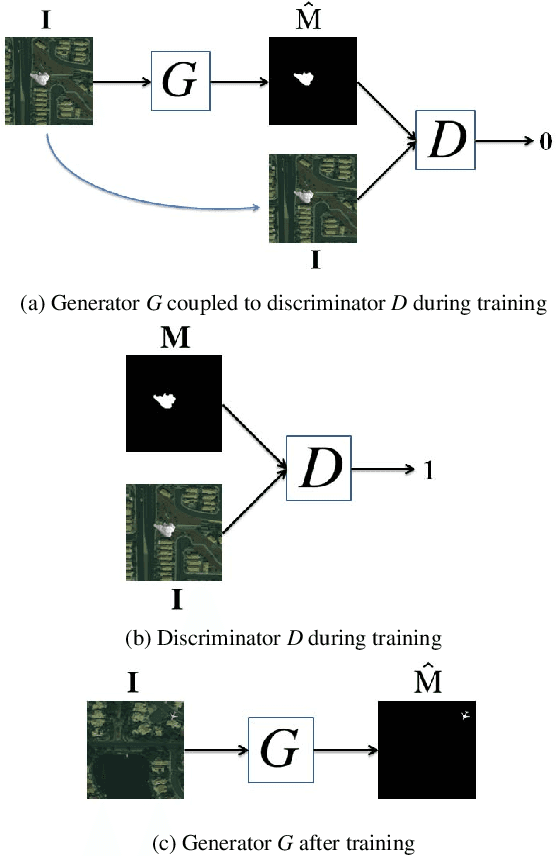

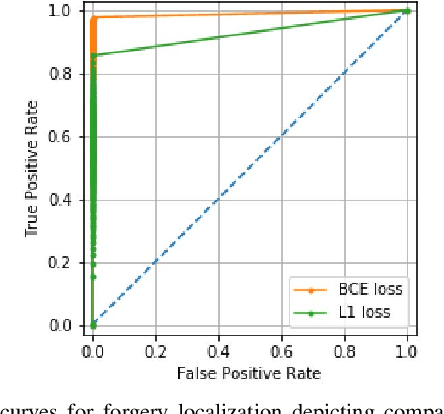
The widespread availability of image editing tools and improvements in image processing techniques allow image manipulation to be very easy. Oftentimes, easy-to-use yet sophisticated image manipulation tools yields distortions/changes imperceptible to the human observer. Distribution of forged images can have drastic ramifications, especially when coupled with the speed and vastness of the Internet. Therefore, verifying image integrity poses an immense and important challenge to the digital forensic community. Satellite images specifically can be modified in a number of ways, including the insertion of objects to hide existing scenes and structures. In this paper, we describe the use of a Conditional Generative Adversarial Network (cGAN) to identify the presence of such spliced forgeries within satellite images. Additionally, we identify their locations and shapes. Trained on pristine and falsified images, our method achieves high success on these detection and localization objectives.
* Accepted to the 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR)
Vision Transformers in 2022: An Update on Tiny ImageNet
May 21, 2022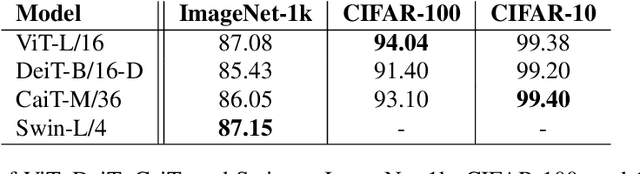
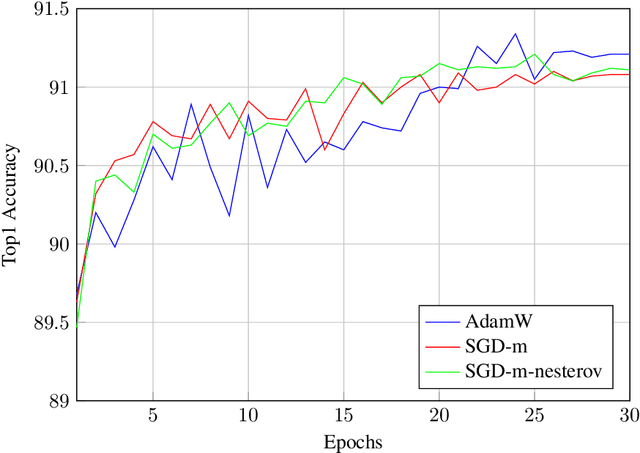
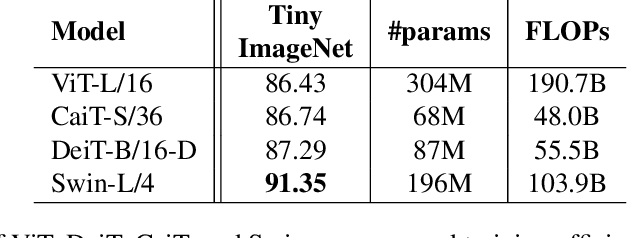
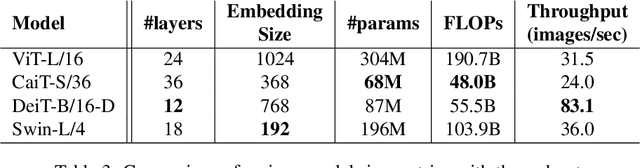
The recent advances in image transformers have shown impressive results and have largely closed the gap between traditional CNN architectures. The standard procedure is to train on large datasets like ImageNet-21k and then finetune on ImageNet-1k. After finetuning, researches will often consider the transfer learning performance on smaller datasets such as CIFAR-10/100 but have left out Tiny ImageNet. This paper offers an update on vision transformers' performance on Tiny ImageNet. I include Vision Transformer (ViT) , Data Efficient Image Transformer (DeiT), Class Attention in Image Transformer (CaiT), and Swin Transformers. In addition, Swin Transformers beats the current state-of-the-art result with a validation accuracy of 91.35%. Code is available here: https://github.com/ehuynh1106/TinyImageNet-Transformers
How GNNs Facilitate CNNs in Mining Geometric Information from Large-Scale Medical Images
Jun 15, 2022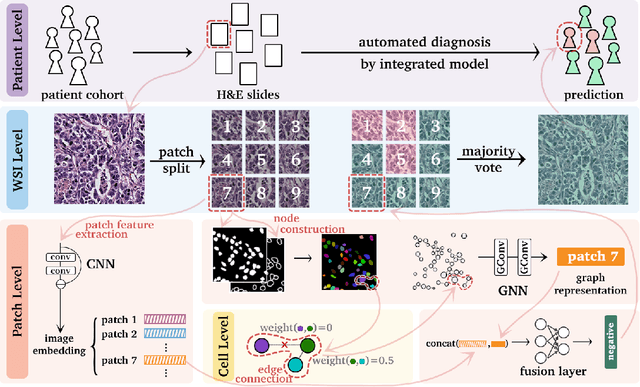
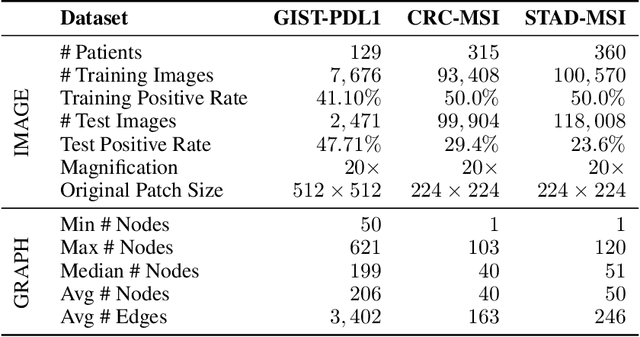
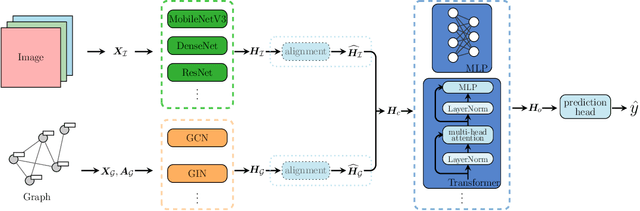
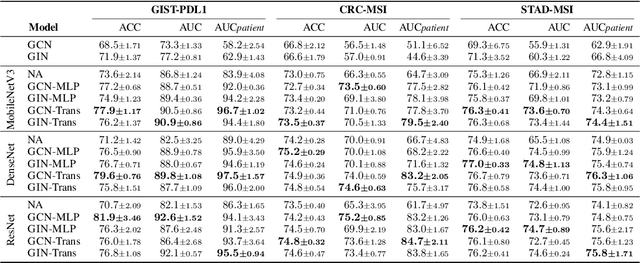
Gigapixel medical images provide massive data, both morphological textures and spatial information, to be mined. Due to the large data scale in histology, deep learning methods play an increasingly significant role as feature extractors. Existing solutions heavily rely on convolutional neural networks (CNNs) for global pixel-level analysis, leaving the underlying local geometric structure such as the interaction between cells in the tumor microenvironment unexplored. The topological structure in medical images, as proven to be closely related to tumor evolution, can be well characterized by graphs. To obtain a more comprehensive representation for downstream oncology tasks, we propose a fusion framework for enhancing the global image-level representation captured by CNNs with the geometry of cell-level spatial information learned by graph neural networks (GNN). The fusion layer optimizes an integration between collaborative features of global images and cell graphs. Two fusion strategies have been developed: one with MLP which is simple but turns out efficient through fine-tuning, and the other with Transformer gains a champion in fusing multiple networks. We evaluate our fusion strategies on histology datasets curated from large patient cohorts of colorectal and gastric cancers for three biomarker prediction tasks. Both two models outperform plain CNNs or GNNs, reaching a consistent AUC improvement of more than 5% on various network backbones. The experimental results yield the necessity for combining image-level morphological features with cell spatial relations in medical image analysis. Codes are available at https://github.com/yiqings/HEGnnEnhanceCnn.
Towards Domain-agnostic Depth Completion
Jul 29, 2022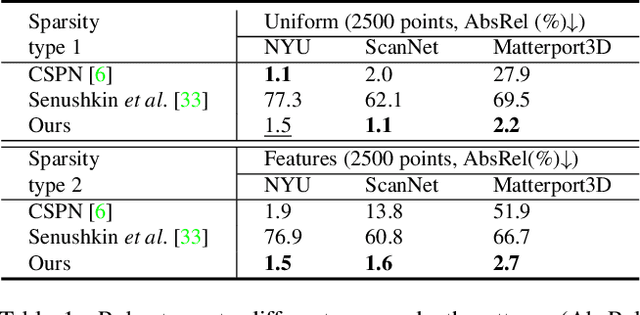

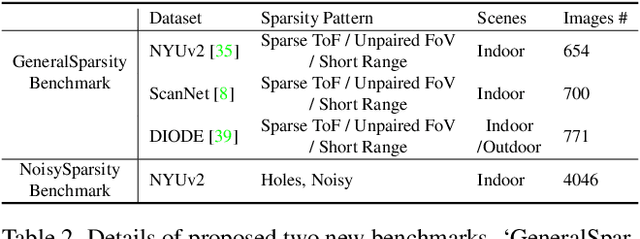

Existing depth completion methods are often targeted at a specific sparse depth type, and generalize poorly across task domains. We present a method to complete sparse/semi-dense, noisy, and potentially low-resolution depth maps obtained by various range sensors, including those in modern mobile phones, or by multi-view reconstruction algorithms. Our method leverages a data driven prior in the form of a single image depth prediction network trained on large-scale datasets, the output of which is used as an input to our model. We propose an effective training scheme where we simulate various sparsity patterns in typical task domains. In addition, we design two new benchmarks to evaluate the generalizability and the robustness of depth completion methods. Our simple method shows superior cross-domain generalization ability against state-of-the-art depth completion methods, introducing a practical solution to high quality depth capture on a mobile device. Code is available at: https://github.com/YvanYin/FillDepth.
DualCoOp: Fast Adaptation to Multi-Label Recognition with Limited Annotations
Jun 20, 2022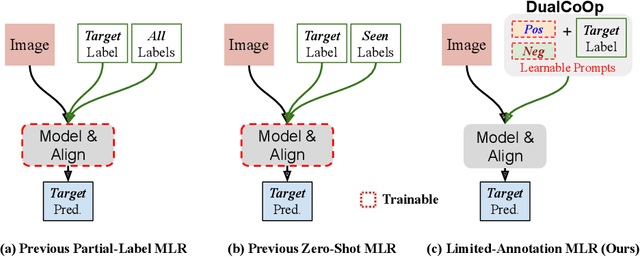
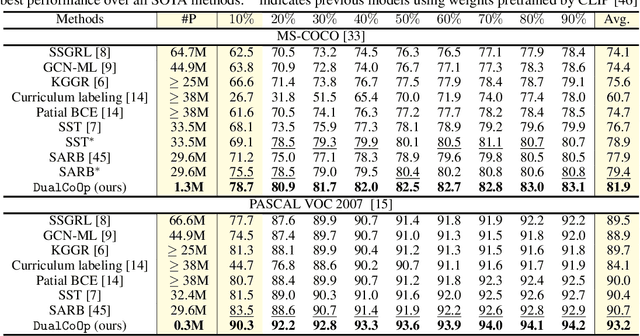
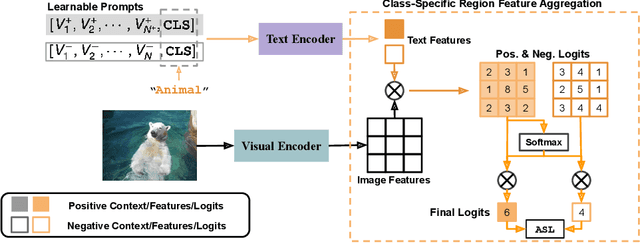
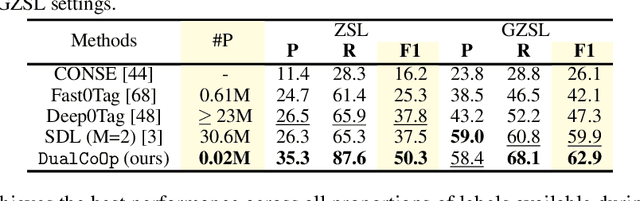
Solving multi-label recognition (MLR) for images in the low-label regime is a challenging task with many real-world applications. Recent work learns an alignment between textual and visual spaces to compensate for insufficient image labels, but loses accuracy because of the limited amount of available MLR annotations. In this work, we utilize the strong alignment of textual and visual features pretrained with millions of auxiliary image-text pairs and propose Dual Context Optimization (DualCoOp) as a unified framework for partial-label MLR and zero-shot MLR. DualCoOp encodes positive and negative contexts with class names as part of the linguistic input (i.e. prompts). Since DualCoOp only introduces a very light learnable overhead upon the pretrained vision-language framework, it can quickly adapt to multi-label recognition tasks that have limited annotations and even unseen classes. Experiments on standard multi-label recognition benchmarks across two challenging low-label settings demonstrate the advantages of our approach over state-of-the-art methods.