 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
GSmooth: Certified Robustness against Semantic Transformations via Generalized Randomized Smoothing
Jun 09, 2022
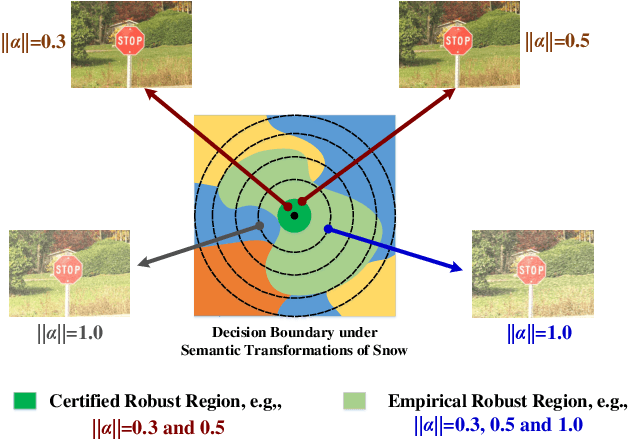
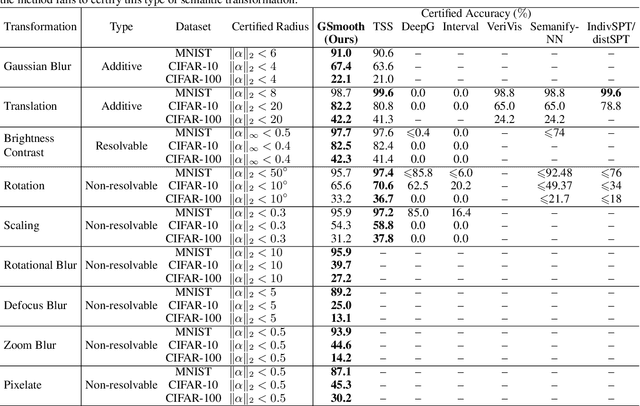
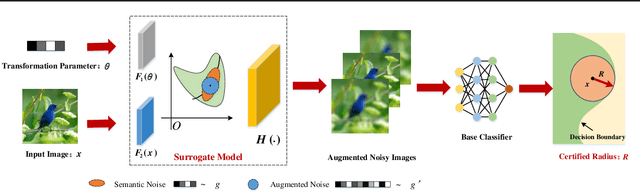
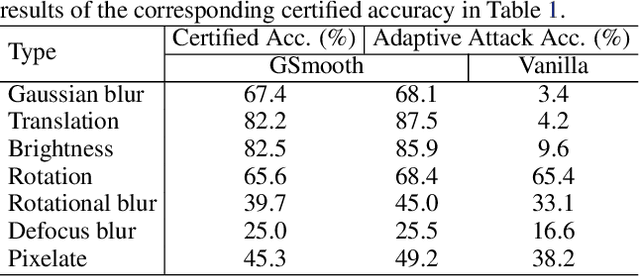
Certified defenses such as randomized smoothing have shown promise towards building reliable machine learning systems against $\ell_p$-norm bounded attacks. However, existing methods are insufficient or unable to provably defend against semantic transformations, especially those without closed-form expressions (such as defocus blur and pixelate), which are more common in practice and often unrestricted. To fill up this gap, we propose generalized randomized smoothing (GSmooth), a unified theoretical framework for certifying robustness against general semantic transformations via a novel dimension augmentation strategy. Under the GSmooth framework, we present a scalable algorithm that uses a surrogate image-to-image network to approximate the complex transformation. The surrogate model provides a powerful tool for studying the properties of semantic transformations and certifying robustness. Experimental results on several datasets demonstrate the effectiveness of our approach for robustness certification against multiple kinds of semantic transformations and corruptions, which is not achievable by the alternative baselines.
Pseudo-labelling and Meta Reweighting Learning for Image Aesthetic Quality Assessment
Jan 08, 2022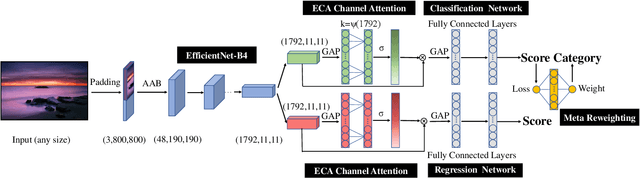

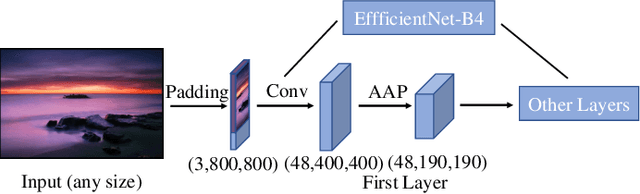
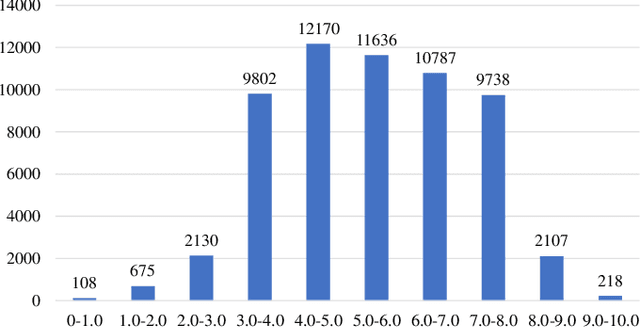
In the tasks of image aesthetic quality evaluation, it is difficult to reach both the high score area and low score area due to the normal distribution of aesthetic datasets. To reduce the error in labeling and solve the problem of normal data distribution, we propose a new aesthetic mixed dataset with classification and regression called AMD-CR, and we train a meta reweighting network to reweight the loss of training data differently. In addition, we provide a training strategy acccording to different stages, based on pseudo labels of the binary classification task, and then we use it for aesthetic training acccording to different stages in classification and regression tasks. In the construction of the network structure, we construct an aesthetic adaptive block (AAB) structure that can adapt to any size of the input images. Besides, we also use the efficient channel attention (ECA) to strengthen the feature extracting ability of each task. The experimental result shows that our method improves 0.1112 compared with the conventional methods in SROCC. The method can also help to find best aesthetic path planning for unmanned aerial vehicles (UAV) and vehicles.
StyleGAN-V: A Continuous Video Generator with the Price, Image Quality and Perks of StyleGAN2
Dec 29, 2021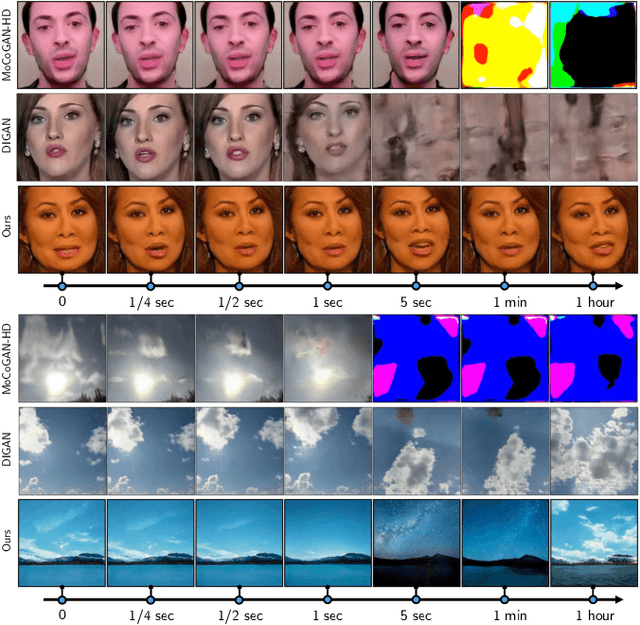
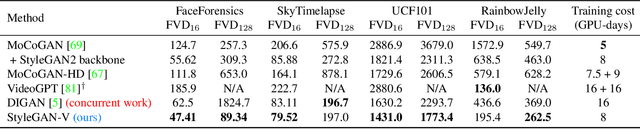

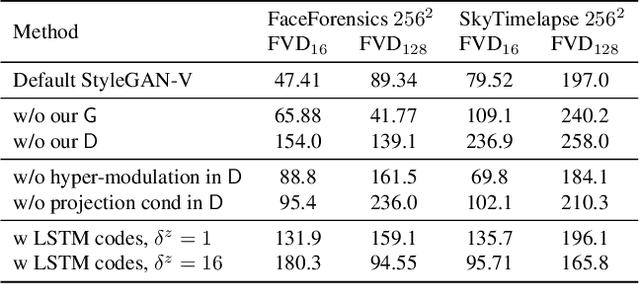
Videos show continuous events, yet most - if not all - video synthesis frameworks treat them discretely in time. In this work, we think of videos of what they should be - time-continuous signals, and extend the paradigm of neural representations to build a continuous-time video generator. For this, we first design continuous motion representations through the lens of positional embeddings. Then, we explore the question of training on very sparse videos and demonstrate that a good generator can be learned by using as few as 2 frames per clip. After that, we rethink the traditional image and video discriminators pair and propose to use a single hypernetwork-based one. This decreases the training cost and provides richer learning signal to the generator, making it possible to train directly on 1024$^2$ videos for the first time. We build our model on top of StyleGAN2 and it is just 5% more expensive to train at the same resolution while achieving almost the same image quality. Moreover, our latent space features similar properties, enabling spatial manipulations that our method can propagate in time. We can generate arbitrarily long videos at arbitrary high frame rate, while prior work struggles to generate even 64 frames at a fixed rate. Our model achieves state-of-the-art results on four modern 256$^2$ video synthesis benchmarks and one 1024$^2$ resolution one. Videos and the source code are available at the project website: https://universome.github.io/stylegan-v.
StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators
Aug 02, 2021
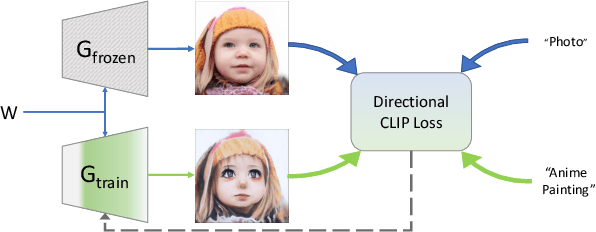
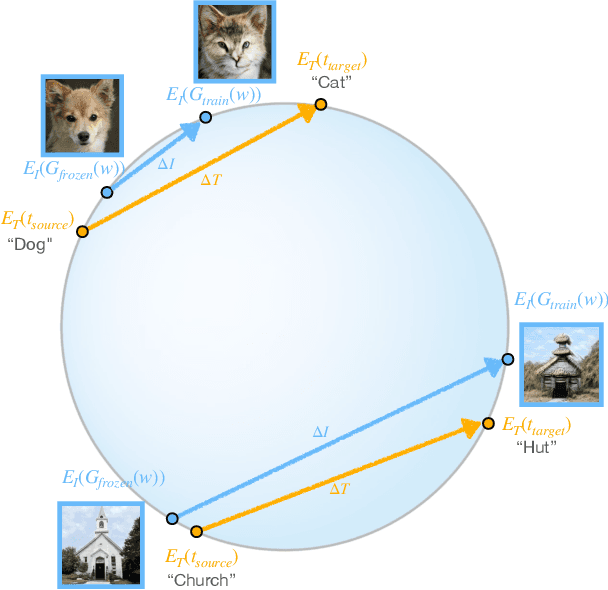
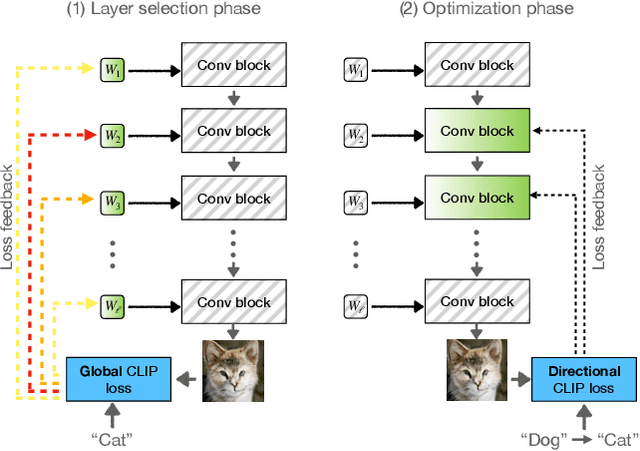
Can a generative model be trained to produce images from a specific domain, guided by a text prompt only, without seeing any image? In other words: can an image generator be trained blindly? Leveraging the semantic power of large scale Contrastive-Language-Image-Pre-training (CLIP) models, we present a text-driven method that allows shifting a generative model to new domains, without having to collect even a single image from those domains. We show that through natural language prompts and a few minutes of training, our method can adapt a generator across a multitude of domains characterized by diverse styles and shapes. Notably, many of these modifications would be difficult or outright impossible to reach with existing methods. We conduct an extensive set of experiments and comparisons across a wide range of domains. These demonstrate the effectiveness of our approach and show that our shifted models maintain the latent-space properties that make generative models appealing for downstream tasks.
Keypoint-less Camera Calibration for Sports Field Registration in Soccer
Jul 24, 2022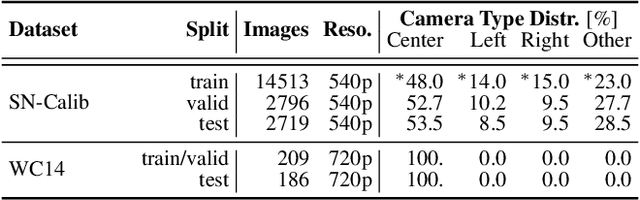
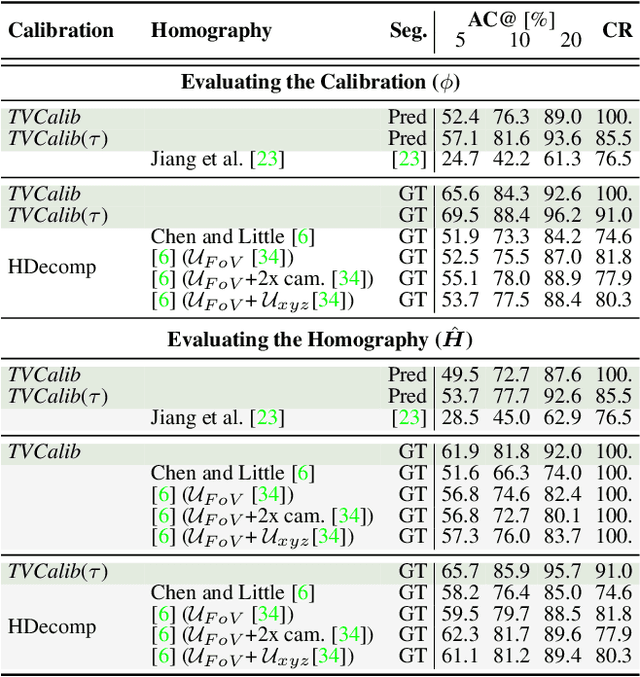
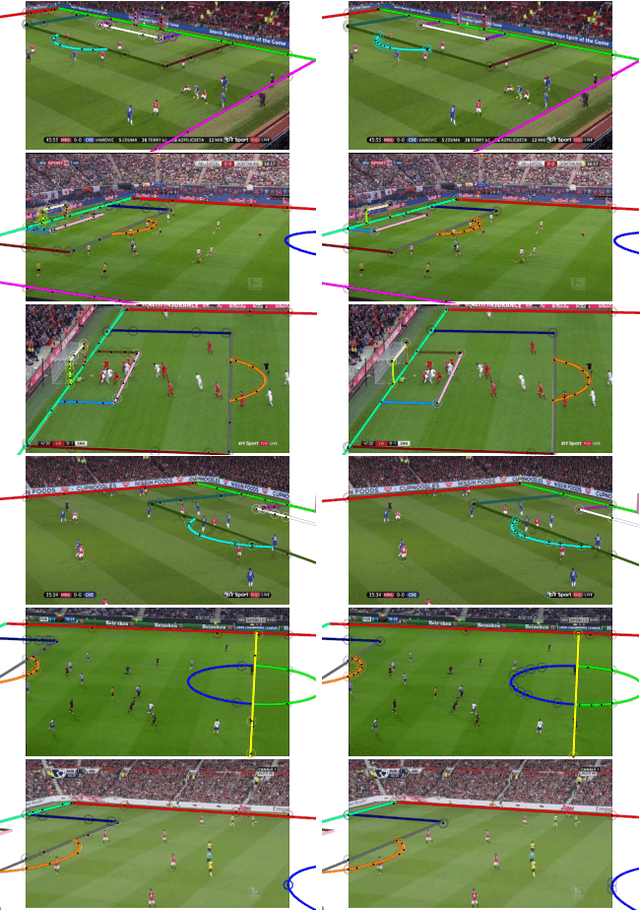
Sports field registration in broadcast videos is typically interpreted as the task of homography estimation, which provides a mapping between a planar field and the corresponding visible area of the image. In contrast to previous approaches, we consider the task as a camera calibration problem. First, we introduce a differentiable objective function that is able to learn the camera pose and focal length from segment correspondences (e.g., lines, point clouds), based on pixel-level annotations for segments of a known calibration object, i.e., the sports field. The calibration module iteratively minimizes the segment reprojection error induced by the estimated camera parameters. Second, we propose a novel approach for 3D sports field registration from broadcast soccer images. The calibration module does not require any training data and compared to the typical solution, which subsequently refines an initial estimation, our solution does it in one step. The proposed method is evaluated for sports field registration on two datasets and achieves superior results compared to two state-of-the-art approaches.
CoSMix: Compositional Semantic Mix for Domain Adaptation in 3D LiDAR Segmentation
Jul 20, 20223D LiDAR semantic segmentation is fundamental for autonomous driving. Several Unsupervised Domain Adaptation (UDA) methods for point cloud data have been recently proposed to improve model generalization for different sensors and environments. Researchers working on UDA problems in the image domain have shown that sample mixing can mitigate domain shift. We propose a new approach of sample mixing for point cloud UDA, namely Compositional Semantic Mix (CoSMix), the first UDA approach for point cloud segmentation based on sample mixing. CoSMix consists of a two-branch symmetric network that can process labelled synthetic data (source) and real-world unlabelled point clouds (target) concurrently. Each branch operates on one domain by mixing selected pieces of data from the other one, and by using the semantic information derived from source labels and target pseudo-labels. We evaluate CoSMix on two large-scale datasets, showing that it outperforms state-of-the-art methods by a large margin. Our code is available at https://github.com/saltoricristiano/cosmix-uda.
mPLUG: Effective and Efficient Vision-Language Learning by Cross-modal Skip-connections
May 24, 2022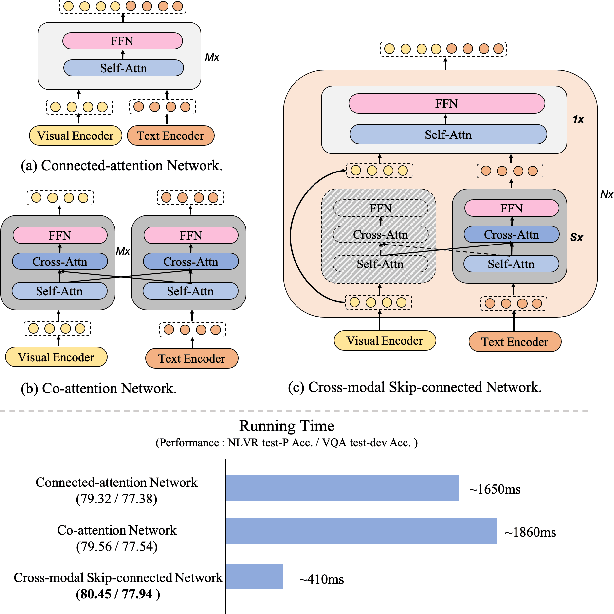
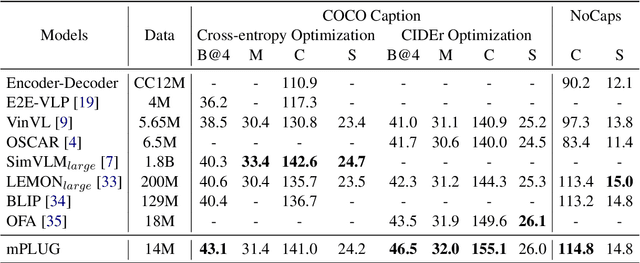
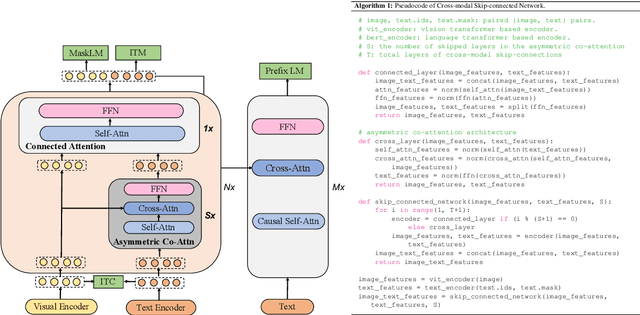
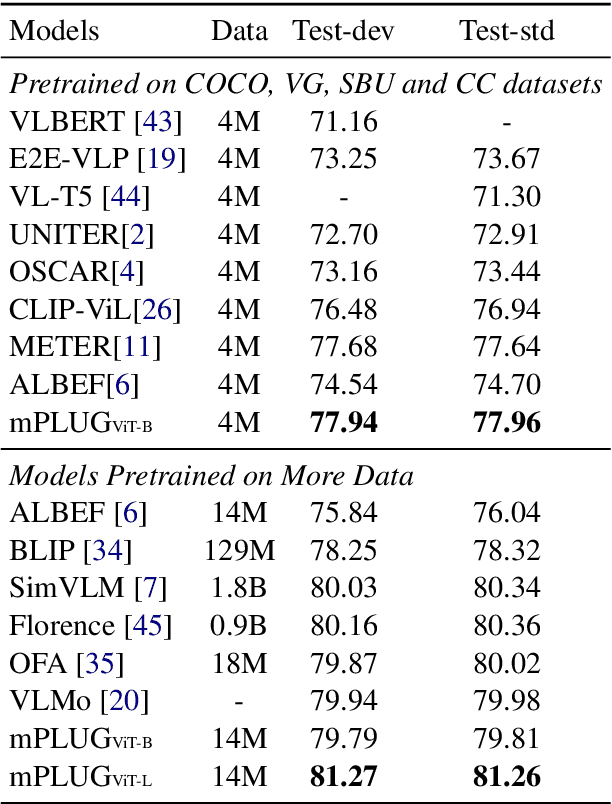
Large-scale pretrained foundation models have been an emerging paradigm for building artificial intelligence (AI) systems, which can be quickly adapted to a wide range of downstream tasks. This paper presents mPLUG, a new vision-language foundation model for both cross-modal understanding and generation. Most existing pre-trained models suffer from the problems of low computational efficiency and information asymmetry brought by the long visual sequence in cross-modal alignment. To address these problems, mPLUG introduces an effective and efficient vision-language architecture with novel cross-modal skip-connections, which creates inter-layer shortcuts that skip a certain number of layers for time-consuming full self-attention on the vision side. mPLUG is pre-trained end-to-end on large-scale image-text pairs with both discriminative and generative objectives. It achieves state-of-the-art results on a wide range of vision-language downstream tasks, such as image captioning, image-text retrieval, visual grounding and visual question answering. mPLUG also demonstrates strong zero-shot transferability when directly transferred to multiple video-language tasks.
GMML is All you Need
May 30, 2022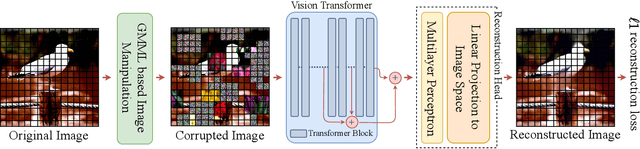
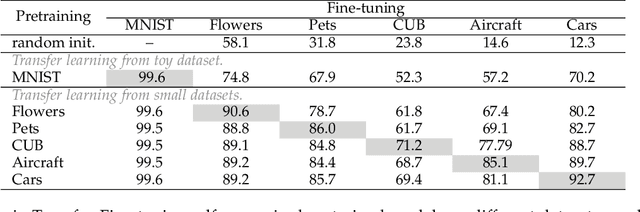
Vision transformers have generated significant interest in the computer vision community because of their flexibility in exploiting contextual information, whether it is sharply confined local, or long range global. However, they are known to be data hungry. This has motivated the research in self-supervised transformer pretraining, which does not need to decode the semantic information conveyed by labels to link it to the image properties, but rather focuses directly on extracting a concise representation of the image data that reflects the notion of similarity, and is invariant to nuisance factors. The key vehicle for the self-learning process used by the majority of self-learning methods is the generation of multiple views of the training data and the creation of pretext tasks which use these views to define the notion of image similarity, and data integrity. However, this approach lacks the natural propensity to extract contextual information. We propose group masked model learning (GMML), a self-supervised learning (SSL) mechanism for pretraining vision transformers with the ability to extract the contextual information present in all the concepts in an image. GMML achieves this by manipulating randomly groups of connected tokens, ensuingly covering a meaningful part of a semantic concept, and then recovering the hidden semantic information from the visible part of the concept. GMML implicitly introduces a novel data augmentation process. Unlike most of the existing SSL approaches, GMML does not require momentum encoder, nor rely on careful implementation details such as large batches and gradient stopping, which are all artefacts of most of the current self-supervised learning techniques. The source code is publicly available for the community to train on bigger corpora: https://github.com/Sara-Ahmed/GMML.
Few-Shot Unsupervised Image-to-Image Translation on complex scenes
Jun 07, 2021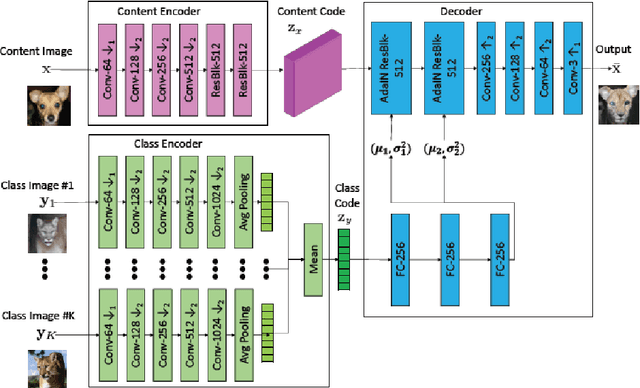

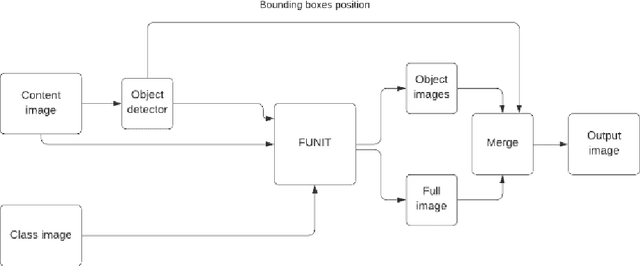
Unsupervised image-to-image translation methods have received a lot of attention in the last few years. Multiple techniques emerged tackling the initial challenge from different perspectives. Some focus on learning as much as possible from several target style images for translations while other make use of object detection in order to produce more realistic results on content-rich scenes. In this work, we assess how a method that has initially been developed for single object translation performs on more diverse and content-rich images. Our work is based on the FUNIT[1] framework and we train it with a more diverse dataset. This helps understanding how such method behaves beyond their initial frame of application. We present a way to extend a dataset based on object detection. Moreover, we propose a way to adapt the FUNIT framework in order to leverage the power of object detection that one can see in other methods.
A Transformer-based Neural Language Model that Synthesizes Brain Activation Maps from Free-Form Text Queries
Jul 24, 2022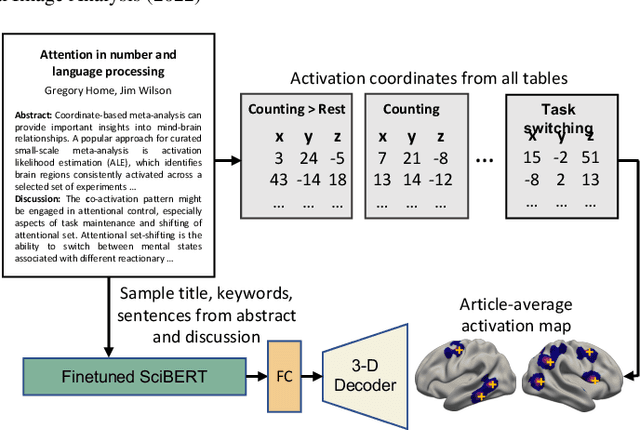
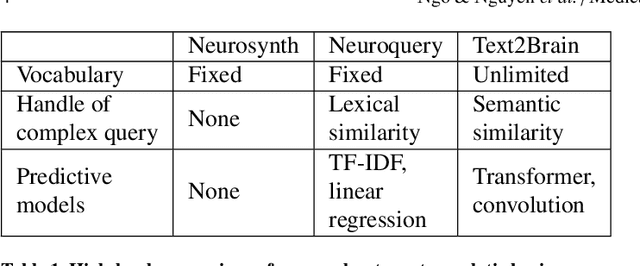
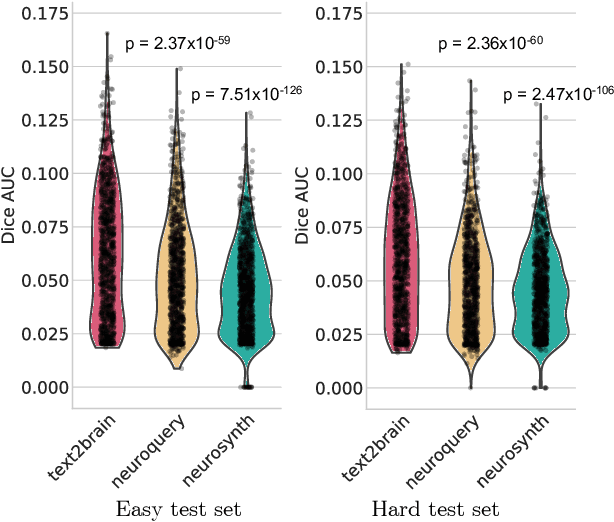
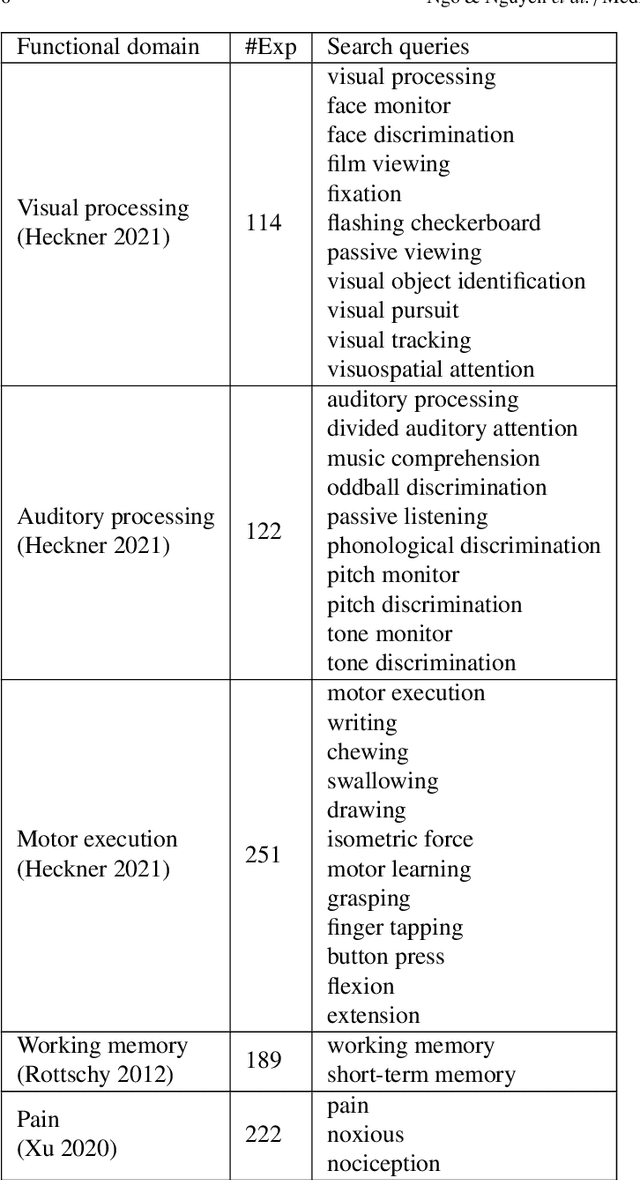
Neuroimaging studies are often limited by the number of subjects and cognitive processes that can be feasibly interrogated. However, a rapidly growing number of neuroscientific studies have collectively accumulated an extensive wealth of results. Digesting this growing literature and obtaining novel insights remains to be a major challenge, since existing meta-analytic tools are constrained to keyword queries. In this paper, we present Text2Brain, an easy to use tool for synthesizing brain activation maps from open-ended text queries. Text2Brain was built on a transformer-based neural network language model and a coordinate-based meta-analysis of neuroimaging studies. Text2Brain combines a transformer-based text encoder and a 3D image generator, and was trained on variable-length text snippets and their corresponding activation maps sampled from 13,000 published studies. In our experiments, we demonstrate that Text2Brain can synthesize meaningful neural activation patterns from various free-form textual descriptions. Text2Brain is available at https://braininterpreter.com as a web-based tool for efficiently searching through the vast neuroimaging literature and generating new hypotheses.
* arXiv admin note: text overlap with arXiv:2109.13814