 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pixel-level Correspondence for Self-Supervised Learning from Video
Jul 08, 2022

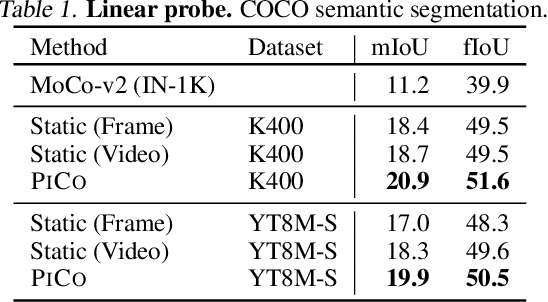


While self-supervised learning has enabled effective representation learning in the absence of labels, for vision, video remains a relatively untapped source of supervision. To address this, we propose Pixel-level Correspondence (PiCo), a method for dense contrastive learning from video. By tracking points with optical flow, we obtain a correspondence map which can be used to match local features at different points in time. We validate PiCo on standard benchmarks, outperforming self-supervised baselines on multiple dense prediction tasks, without compromising performance on image classification.
Multitask Identity-Aware Image Steganography via Minimax Optimization
Jul 13, 2021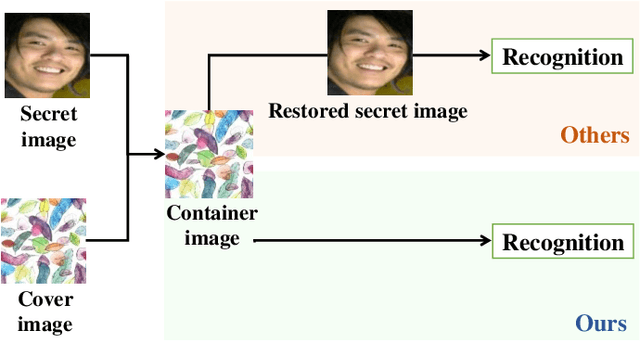

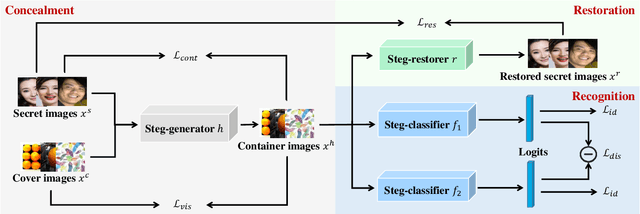
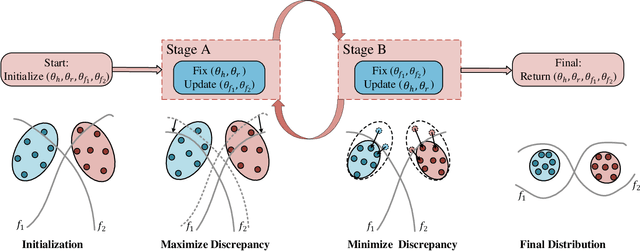
High-capacity image steganography, aimed at concealing a secret image in a cover image, is a technique to preserve sensitive data, e.g., faces and fingerprints. Previous methods focus on the security during transmission and subsequently run a risk of privacy leakage after the restoration of secret images at the receiving end. To address this issue, we propose a framework, called Multitask Identity-Aware Image Steganography (MIAIS), to achieve direct recognition on container images without restoring secret images. The key issue of the direct recognition is to preserve identity information of secret images into container images and make container images look similar to cover images at the same time. Thus, we introduce a simple content loss to preserve the identity information, and design a minimax optimization to deal with the contradictory aspects. We demonstrate that the robustness results can be transferred across different cover datasets. In order to be flexible for the secret image restoration in some cases, we incorporate an optional restoration network into our method, providing a multitask framework. The experiments under the multitask scenario show the effectiveness of our framework compared with other visual information hiding methods and state-of-the-art high-capacity image steganography methods.
Semantic Self-adaptation: Enhancing Generalization with a Single Sample
Aug 10, 2022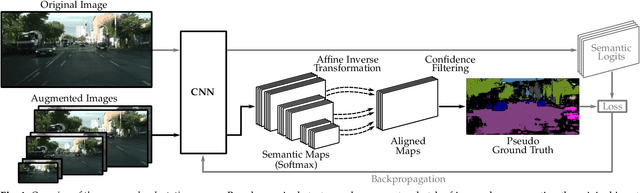

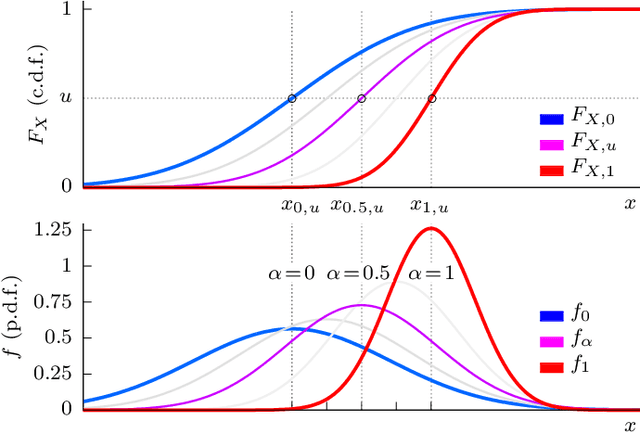
Despite years of research, out-of-domain generalization remains a critical weakness of deep networks for semantic segmentation. Previous studies relied on the assumption of a static model, i.e. once the training process is complete, model parameters remain fixed at test time. In this work, we challenge this premise with a self-adaptive approach for semantic segmentation that adjusts the inference process to each input sample. Self-adaptation operates on two levels. First, it employs a self-supervised loss that customizes the parameters of convolutional layers in the network to the input image. Second, in Batch Normalization layers, self-adaptation approximates the mean and the variance of the entire test data, which is assumed unavailable. It achieves this by interpolating between the training and the reference distribution derived from a single test sample. To empirically analyze our self-adaptive inference strategy, we develop and follow a rigorous evaluation protocol that addresses serious limitations of previous work. Our extensive analysis leads to a surprising conclusion: Using a standard training procedure, self-adaptation significantly outperforms strong baselines and sets new state-of-the-art accuracy on multi-domain benchmarks. Our study suggests that self-adaptive inference may complement the established practice of model regularization at training time for improving deep network generalization to out-of-domain data.
A semi-supervised Teacher-Student framework for surgical tool detection and localization
Aug 21, 2022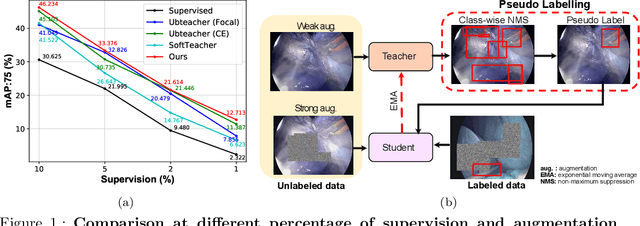
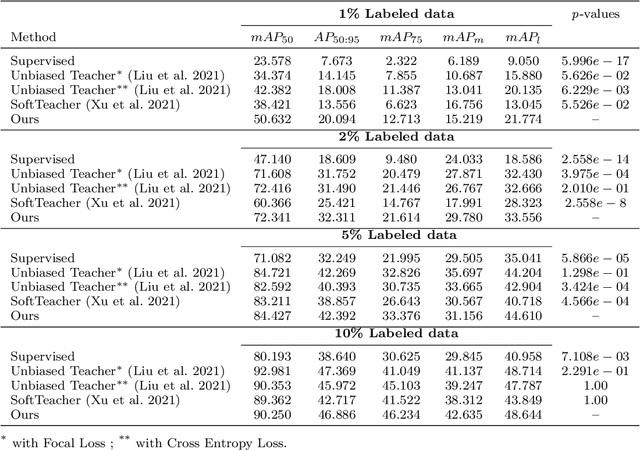
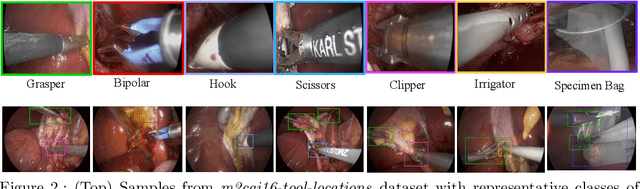
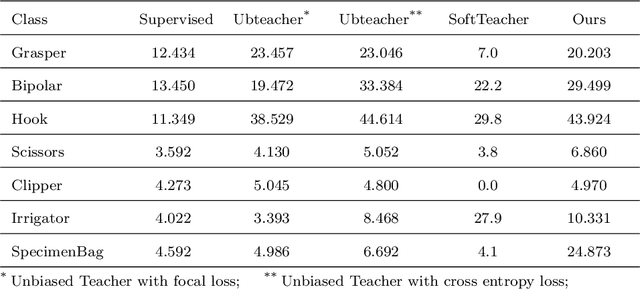
Surgical tool detection in minimally invasive surgery is an essential part of computer-assisted interventions. Current approaches are mostly based on supervised methods which require large fully labeled data to train supervised models and suffer from pseudo label bias because of class imbalance issues. However large image datasets with bounding box annotations are often scarcely available. Semi-supervised learning (SSL) has recently emerged as a means for training large models using only a modest amount of annotated data; apart from reducing the annotation cost. SSL has also shown promise to produce models that are more robust and generalizable. Therefore, in this paper we introduce a semi-supervised learning (SSL) framework in surgical tool detection paradigm which aims to mitigate the scarcity of training data and the data imbalance through a knowledge distillation approach. In the proposed work, we train a model with labeled data which initialises the Teacher-Student joint learning, where the Student is trained on Teacher-generated pseudo labels from unlabeled data. We propose a multi-class distance with a margin based classification loss function in the region-of-interest head of the detector to effectively segregate foreground classes from background region. Our results on m2cai16-tool-locations dataset indicate the superiority of our approach on different supervised data settings (1%, 2%, 5%, 10% of annotated data) where our model achieves overall improvements of 8%, 12% and 27% in mAP (on 1% labeled data) over the state-of-the-art SSL methods and a fully supervised baseline, respectively. The code is available at https://github.com/Mansoor-at/Semi-supervised-surgical-tool-det
Patch-based medical image segmentation using Quantum Tensor Networks
Sep 15, 2021
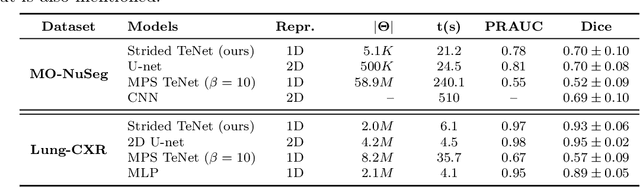
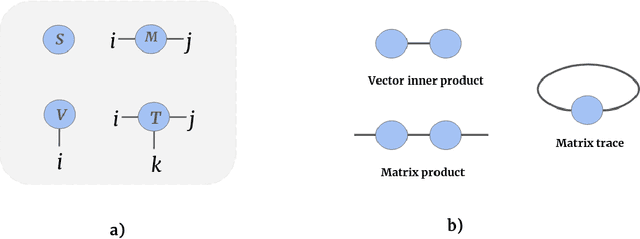
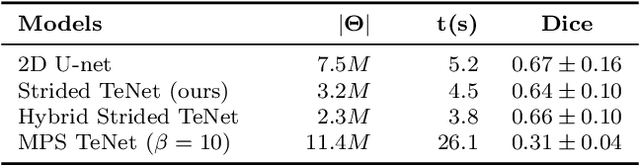
Tensor networks are efficient factorisations of high dimensional tensors into a network of lower order tensors. They have been most commonly used to model entanglement in quantum many-body systems and more recently are witnessing increased applications in supervised machine learning. In this work, we formulate image segmentation in a supervised setting with tensor networks. The key idea is to first lift the pixels in image patches to exponentially high dimensional feature spaces and using a linear decision hyper-plane to classify the input pixels into foreground and background classes. The high dimensional linear model itself is approximated using the matrix product state (MPS) tensor network. The MPS is weight-shared between the non-overlapping image patches resulting in our strided tensor network model. The performance of the proposed model is evaluated on three 2D- and one 3D- biomedical imaging datasets. The performance of the proposed tensor network segmentation model is compared with relevant baseline methods. In the 2D experiments, the tensor network model yeilds competitive performance compared to the baseline methods while being more resource efficient.
A Survey on Masked Autoencoder for Self-supervised Learning in Vision and Beyond
Jul 30, 2022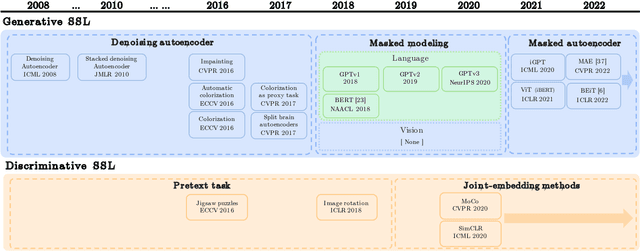

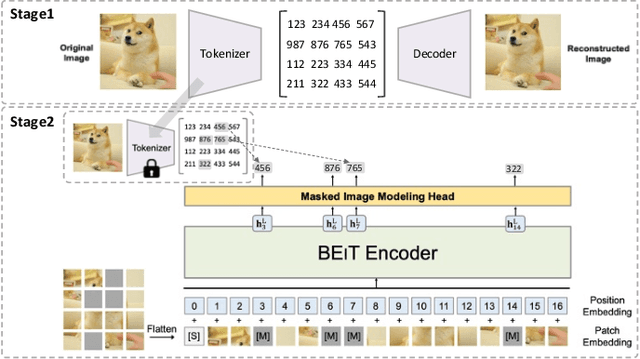
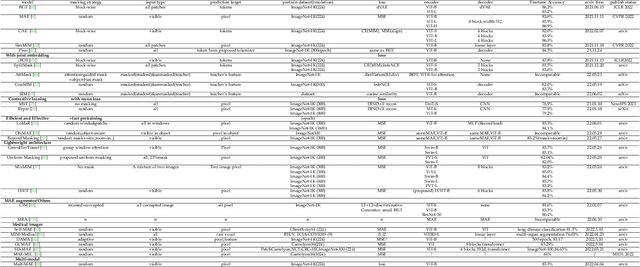
Masked autoencoders are scalable vision learners, as the title of MAE \cite{he2022masked}, which suggests that self-supervised learning (SSL) in vision might undertake a similar trajectory as in NLP. Specifically, generative pretext tasks with the masked prediction (e.g., BERT) have become a de facto standard SSL practice in NLP. By contrast, early attempts at generative methods in vision have been buried by their discriminative counterparts (like contrastive learning); however, the success of mask image modeling has revived the masking autoencoder (often termed denoising autoencoder in the past). As a milestone to bridge the gap with BERT in NLP, masked autoencoder has attracted unprecedented attention for SSL in vision and beyond. This work conducts a comprehensive survey of masked autoencoders to shed insight on a promising direction of SSL. As the first to review SSL with masked autoencoders, this work focuses on its application in vision by discussing its historical developments, recent progress, and implications for diverse applications.
Self-Supervised Pre-training of Vision Transformers for Dense Prediction Tasks
Jun 07, 2022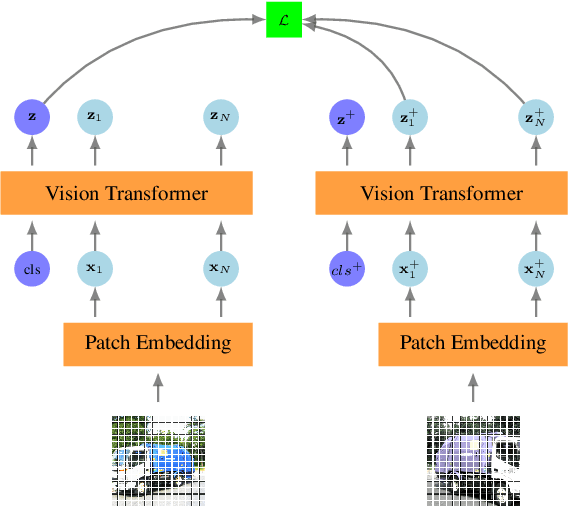
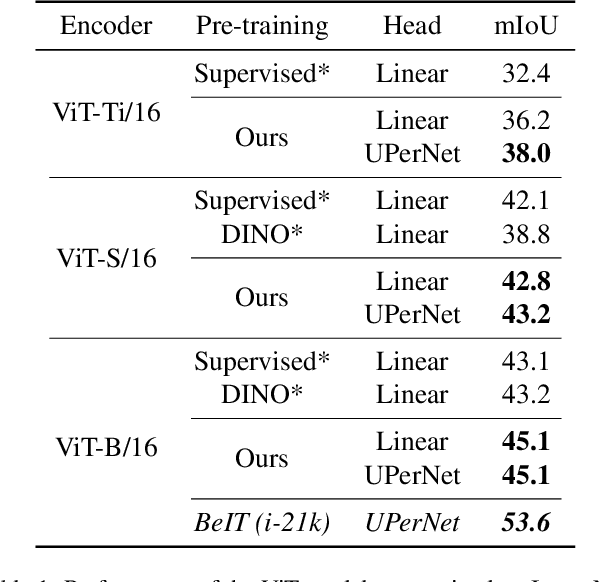
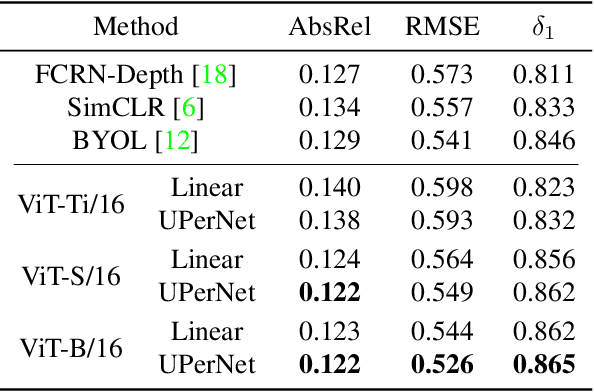
We present a new self-supervised pre-training of Vision Transformers for dense prediction tasks. It is based on a contrastive loss across views that compares pixel-level representations to global image representations. This strategy produces better local features suitable for dense prediction tasks as opposed to contrastive pre-training based on global image representation only. Furthermore, our approach does not suffer from a reduced batch size since the number of negative examples needed in the contrastive loss is in the order of the number of local features. We demonstrate the effectiveness of our pre-training strategy on two dense prediction tasks: semantic segmentation and monocular depth estimation.
Unified 2D and 3D Pre-training for Medical Image classification and Segmentation
Dec 17, 2021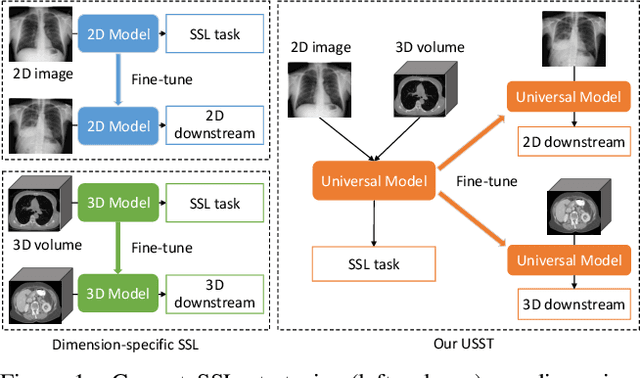
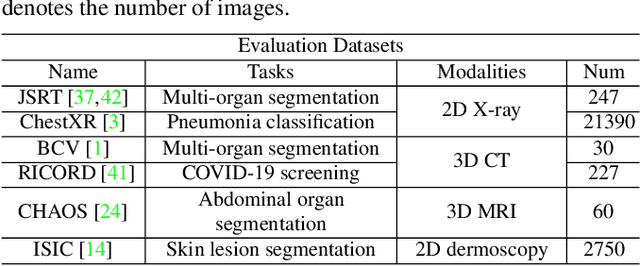
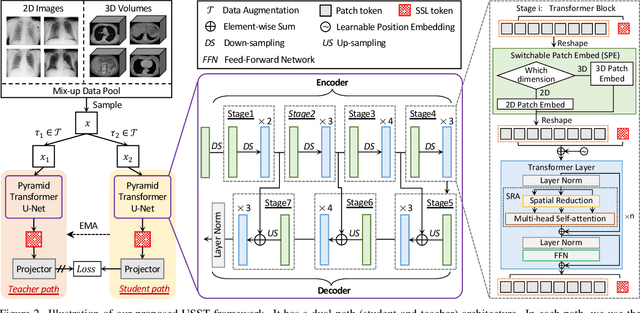
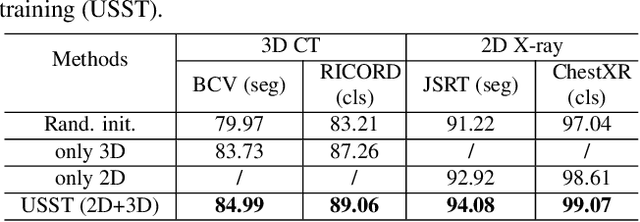
Self-supervised learning (SSL) opens up huge opportunities for better utilizing unlabeled data. It is essential for medical image analysis that is generally known for its lack of annotations. However, when we attempt to use as many as possible unlabeled medical images in SSL, breaking the dimension barrier (\ie, making it possible to jointly use both 2D and 3D images) becomes a must. In this paper, we propose a Universal Self-Supervised Transformer (USST) framework based on the student-teacher paradigm, aiming to leverage a huge of unlabeled medical data with multiple dimensions to learn rich representations. To achieve this, we design a Pyramid Transformer U-Net (PTU) as the backbone, which is composed of switchable patch embedding (SPE) layers and Transformer layers. The SPE layer switches to either 2D or 3D patch embedding depending on the input dimension. After that, the images are converted to a sequence regardless of their original dimensions. The Transformer layer then models the long-term dependencies in a sequence-to-sequence manner, thus enabling USST to learn representations from both 2D and 3D images. USST has two obvious merits compared to current dimension-specific SSL: (1) \textbf{more effective} - can learn representations from more and diverse data; and (2) \textbf{more versatile} - can be transferred to various downstream tasks. The results show that USST provides promising results on six 2D/3D medical image classification and segmentation tasks, outperforming the supervised ImageNet pre-training and advanced SSL counterparts substantially.
Robust and efficient computation of retinal fractal dimension through deep approximation
Jul 12, 2022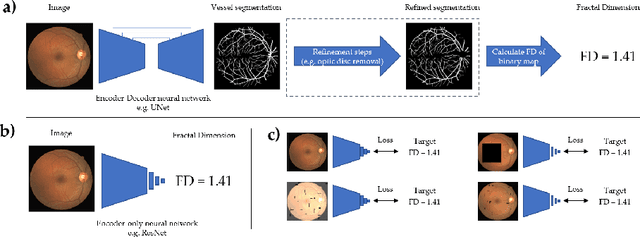

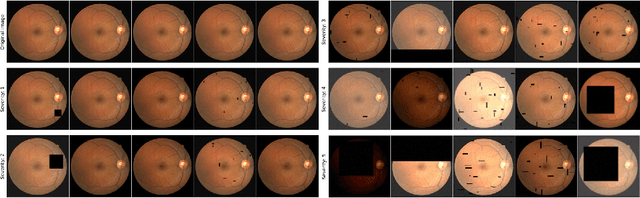
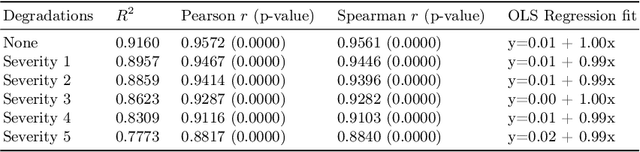
A retinal trait, or phenotype, summarises a specific aspect of a retinal image in a single number. This can then be used for further analyses, e.g. with statistical methods. However, reducing an aspect of a complex image to a single, meaningful number is challenging. Thus, methods for calculating retinal traits tend to be complex, multi-step pipelines that can only be applied to high quality images. This means that researchers often have to discard substantial portions of the available data. We hypothesise that such pipelines can be approximated with a single, simpler step that can be made robust to common quality issues. We propose Deep Approximation of Retinal Traits (DART) where a deep neural network is used predict the output of an existing pipeline on high quality images from synthetically degraded versions of these images. We demonstrate DART on retinal Fractal Dimension (FD) calculated by VAMPIRE, using retinal images from UK Biobank that previous work identified as high quality. Our method shows very high agreement with FD VAMPIRE on unseen test images (Pearson r=0.9572). Even when those images are severely degraded, DART can still recover an FD estimate that shows good agreement with FD VAMPIRE obtained from the original images (Pearson r=0.8817). This suggests that our method could enable researchers to discard fewer images in the future. Our method can compute FD for over 1,000img/s using a single GPU. We consider these to be very encouraging initial results and hope to develop this approach into a useful tool for retinal analysis.
Advancing Plain Vision Transformer Towards Remote Sensing Foundation Model
Aug 10, 2022
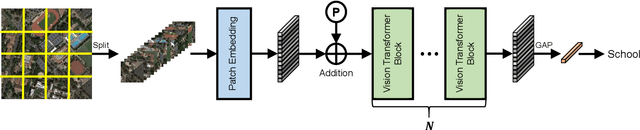
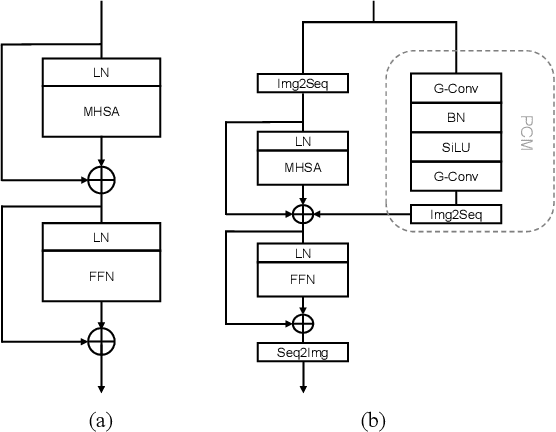
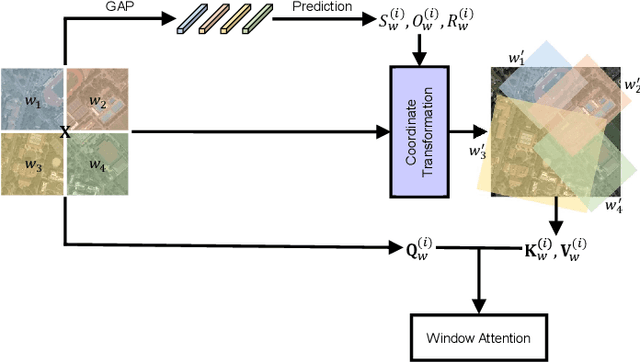
Large-scale vision foundation models have made significant progress in visual tasks on natural images, where the vision transformers are the primary choice for their good scalability and representation ability. However, the utilization of large models in the remote sensing (RS) community remains under-explored where existing models are still at small-scale, which limits the performance. In this paper, we resort to plain vision transformers with about 100 million parameters and make the first attempt to propose large vision models customized for RS tasks and explore how such large models perform. Specifically, to handle the large image size and objects of various orientations in RS images, we propose a new rotated varied-size window attention to substitute the original full attention in transformers, which could significantly reduce the computational cost and memory footprint while learn better object representation by extracting rich context from the generated diverse windows. Experiments on detection tasks demonstrate the superiority of our model over all state-of-the-art models, achieving 81.16% mAP on the DOTA-V1.0 dataset. The results of our models on downstream classification and segmentation tasks also demonstrate competitive performance compared with the existing advanced methods. Further experiments show the advantages of our models on computational complexity and few-shot learning.