 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Variable-Rate Deep Image Compression through Spatially-Adaptive Feature Transform
Aug 21, 2021
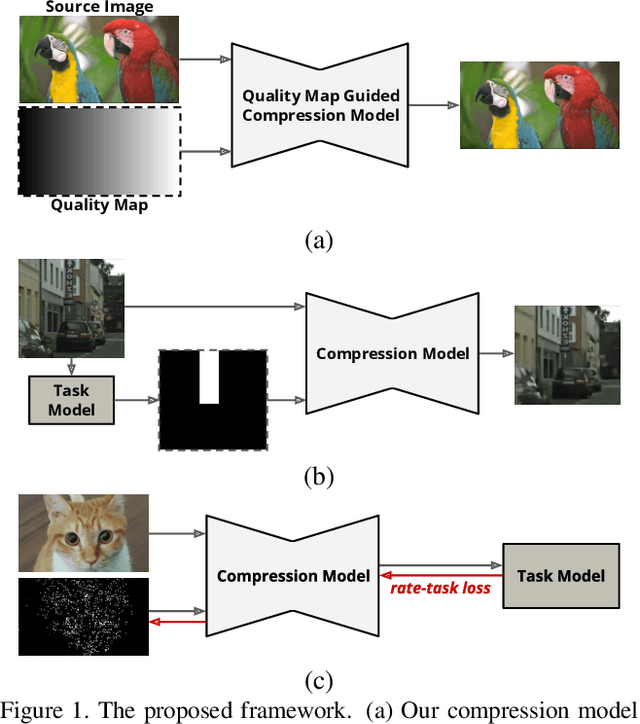


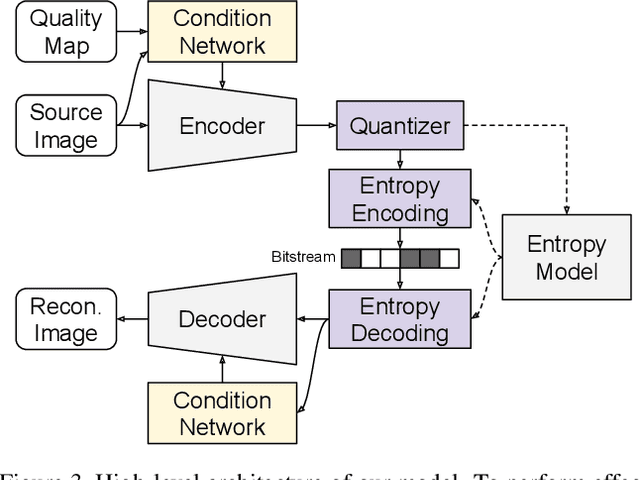
We propose a versatile deep image compression network based on Spatial Feature Transform (SFT arXiv:1804.02815), which takes a source image and a corresponding quality map as inputs and produce a compressed image with variable rates. Our model covers a wide range of compression rates using a single model, which is controlled by arbitrary pixel-wise quality maps. In addition, the proposed framework allows us to perform task-aware image compressions for various tasks, e.g., classification, by efficiently estimating optimized quality maps specific to target tasks for our encoding network. This is even possible with a pretrained network without learning separate models for individual tasks. Our algorithm achieves outstanding rate-distortion trade-off compared to the approaches based on multiple models that are optimized separately for several different target rates. At the same level of compression, the proposed approach successfully improves performance on image classification and text region quality preservation via task-aware quality map estimation without additional model training. The code is available at the project website: https://github.com/micmic123/QmapCompression
CropMix: Sampling a Rich Input Distribution via Multi-Scale Cropping
May 31, 2022
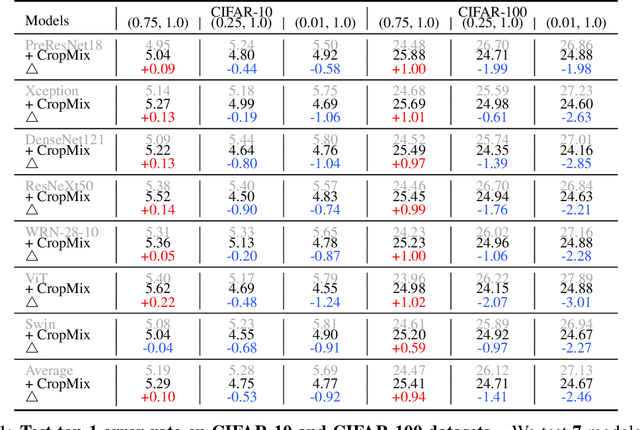

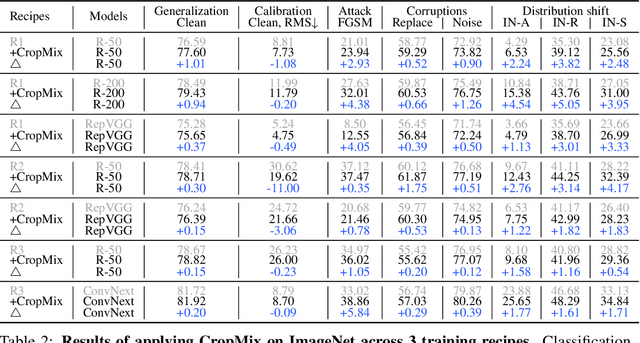
We present a simple method, CropMix, for the purpose of producing a rich input distribution from the original dataset distribution. Unlike single random cropping, which may inadvertently capture only limited information, or irrelevant information, like pure background, unrelated objects, etc, we crop an image multiple times using distinct crop scales, thereby ensuring that multi-scale information is captured. The new input distribution, serving as training data, useful for a number of vision tasks, is then formed by simply mixing multiple cropped views. We first demonstrate that CropMix can be seamlessly applied to virtually any training recipe and neural network architecture performing classification tasks. CropMix is shown to improve the performance of image classifiers on several benchmark tasks across-the-board without sacrificing computational simplicity and efficiency. Moreover, we show that CropMix is of benefit to both contrastive learning and masked image modeling towards more powerful representations, where preferable results are achieved when learned representations are transferred to downstream tasks. Code is available at GitHub.
Instance-weighted Central Similarity for Multi-label Image Retrieval
Aug 11, 2021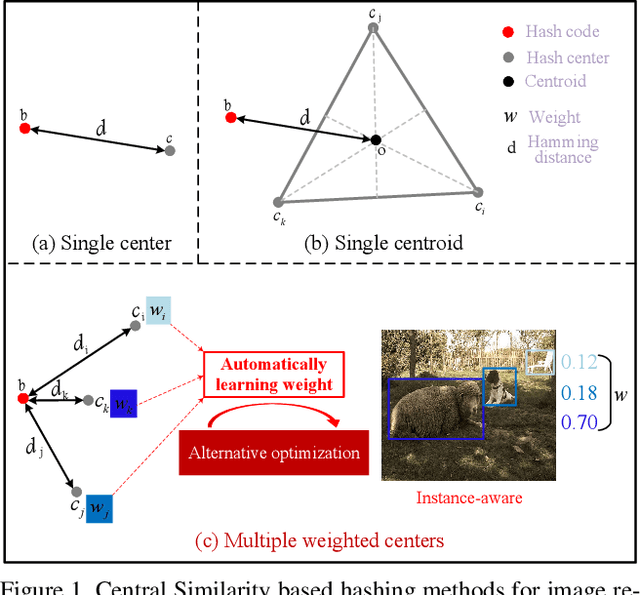

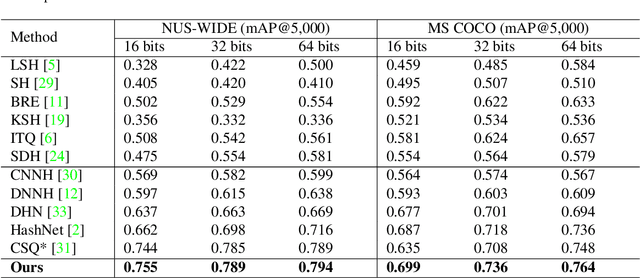
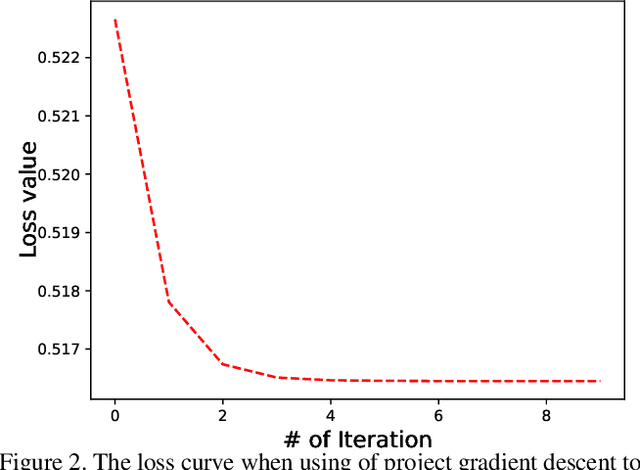
Deep hashing has been widely applied to large-scale image retrieval by encoding high-dimensional data points into binary codes for efficient retrieval. Compared with pairwise/triplet similarity based hash learning, central similarity based hashing can more efficiently capture the global data distribution. For multi-label image retrieval, however, previous methods only use multiple hash centers with equal weights to generate one centroid as the learning target, which ignores the relationship between the weights of hash centers and the proportion of instance regions in the image. To address the above issue, we propose a two-step alternative optimization approach, Instance-weighted Central Similarity (ICS), to automatically learn the center weight corresponding to a hash code. Firstly, we apply the maximum entropy regularizer to prevent one hash center from dominating the loss function, and compute the center weights via projection gradient descent. Secondly, we update neural network parameters by standard back-propagation with fixed center weights. More importantly, the learned center weights can well reflect the proportion of foreground instances in the image. Our method achieves the state-of-the-art performance on the image retrieval benchmarks, and especially improves the mAP by 1.6%-6.4% on the MS COCO dataset.
COBRA: Cpu-Only aBdominal oRgan segmentAtion
Jul 21, 2022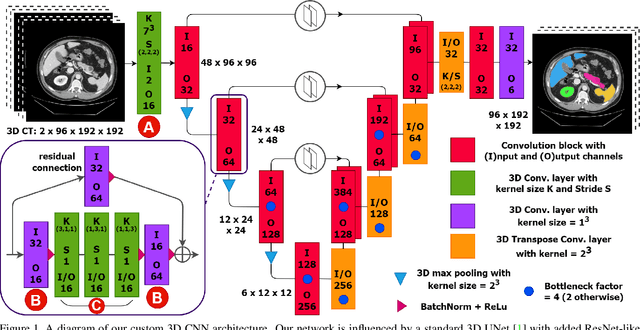

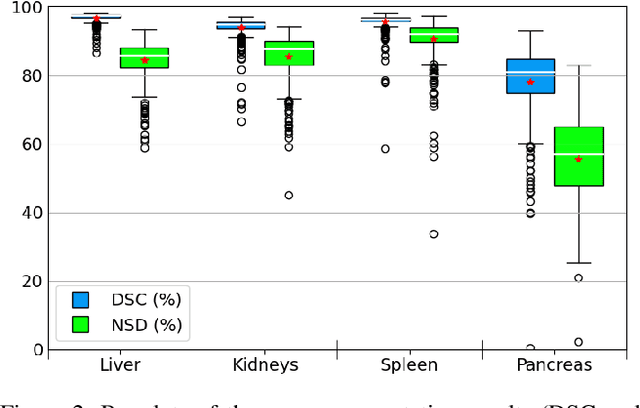
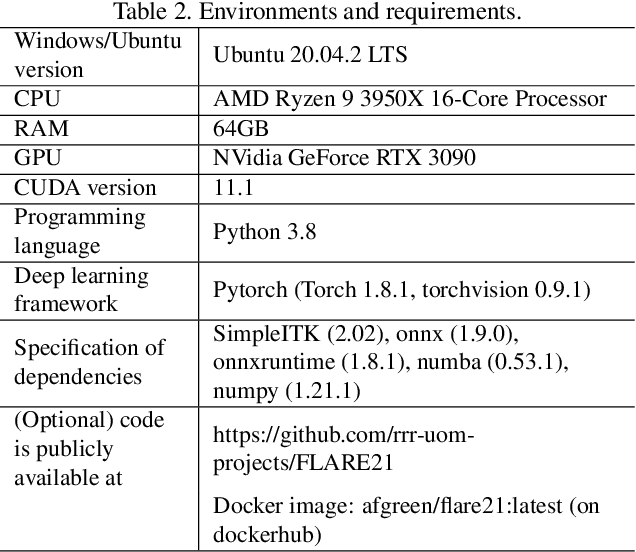
Abdominal organ segmentation is a difficult and time-consuming task. To reduce the burden on clinical experts, fully-automated methods are highly desirable. Current approaches are dominated by Convolutional Neural Networks (CNNs) however the computational requirements and the need for large data sets limit their application in practice. By implementing a small and efficient custom 3D CNN, compiling the trained model and optimizing the computational graph: our approach produces high accuracy segmentations (Dice Similarity Coefficient (%): Liver: 97.3$\pm$1.3, Kidneys: 94.8$\pm$3.6, Spleen: 96.4$\pm$3.0, Pancreas: 80.9$\pm$10.1) at a rate of 1.6 seconds per image. Crucially, we are able to perform segmentation inference solely on CPU (no GPU required), thereby facilitating easy and widespread deployment of the model without specialist hardware.
CoMoGAN: continuous model-guided image-to-image translation
Mar 11, 2021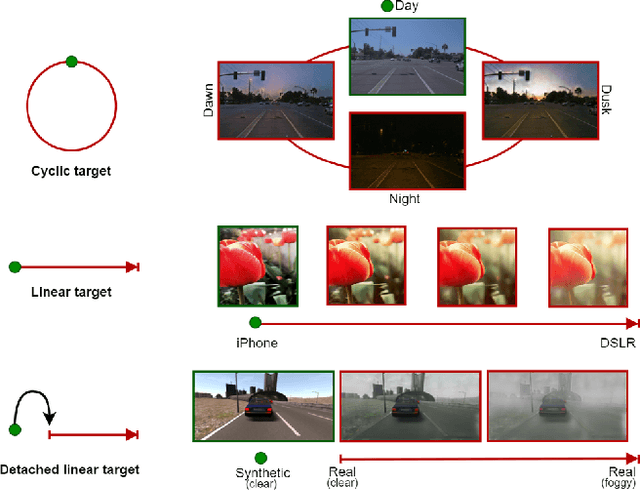

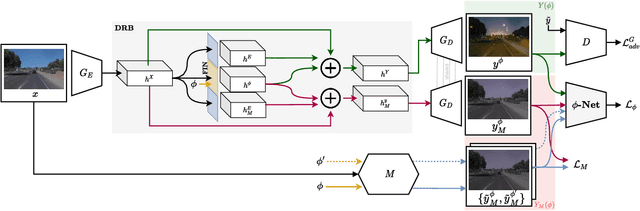
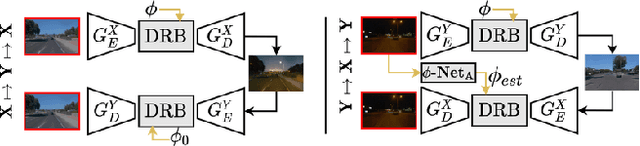
CoMoGAN is a continuous GAN relying on the unsupervised reorganization of the target data on a functional manifold. To that matter, we introduce a new Functional Instance Normalization layer and residual mechanism, which together disentangle image content from position on target manifold. We rely on naive physics-inspired models to guide the training while allowing private model/translations features. CoMoGAN can be used with any GAN backbone and allows new types of image translation, such as cyclic image translation like timelapse generation, or detached linear translation. On all datasets and metrics, it outperforms the literature. Our code is available at http://github.com/cv-rits/CoMoGAN .
Vision Checklist: Towards Testable Error Analysis of Image Models to Help System Designers Interrogate Model Capabilities
Jan 31, 2022



Using large pre-trained models for image recognition tasks is becoming increasingly common owing to the well acknowledged success of recent models like vision transformers and other CNN-based models like VGG and Resnet. The high accuracy of these models on benchmark tasks has translated into their practical use across many domains including safety-critical applications like autonomous driving and medical diagnostics. Despite their widespread use, image models have been shown to be fragile to changes in the operating environment, bringing their robustness into question. There is an urgent need for methods that systematically characterise and quantify the capabilities of these models to help designers understand and provide guarantees about their safety and robustness. In this paper, we propose Vision Checklist, a framework aimed at interrogating the capabilities of a model in order to produce a report that can be used by a system designer for robustness evaluations. This framework proposes a set of perturbation operations that can be applied on the underlying data to generate test samples of different types. The perturbations reflect potential changes in operating environments, and interrogate various properties ranging from the strictly quantitative to more qualitative. Our framework is evaluated on multiple datasets like Tinyimagenet, CIFAR10, CIFAR100 and Camelyon17 and for models like ViT and Resnet. Our Vision Checklist proposes a specific set of evaluations that can be integrated into the previously proposed concept of a model card. Robustness evaluations like our checklist will be crucial in future safety evaluations of visual perception modules, and be useful for a wide range of stakeholders including designers, deployers, and regulators involved in the certification of these systems. Source code of Vision Checklist would be open for public use.
Detect-and-Segment: a Deep Learning Approach to Automate Wound Image Segmentation
Nov 02, 2021


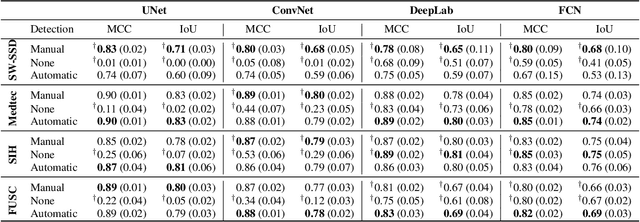
Chronic wounds significantly impact quality of life. If not properly managed, they can severely deteriorate. Image-based wound analysis could aid in objectively assessing the wound status by quantifying important features that are related to healing. However, the high heterogeneity of the wound types, image background composition, and capturing conditions challenge the robust segmentation of wound images. We present Detect-and-Segment (DS), a deep learning approach to produce wound segmentation maps with high generalization capabilities. In our approach, dedicated deep neural networks detected the wound position, isolated the wound from the uninformative background, and computed the wound segmentation map. We evaluated this approach using one data set with images of diabetic foot ulcers. For further testing, 4 supplemental independent data sets with larger variety of wound types from different body locations were used. The Matthews' correlation coefficient (MCC) improved from 0.29 when computing the segmentation on the full image to 0.85 when combining detection and segmentation in the same approach. When tested on the wound images drawn from the supplemental data sets, the DS approach increased the mean MCC from 0.17 to 0.85. Furthermore, the DS approach enabled the training of segmentation models with up to 90% less training data while maintaining the segmentation performance.
Multitask Identity-Aware Image Steganography via Minimax Optimization
Jul 13, 2021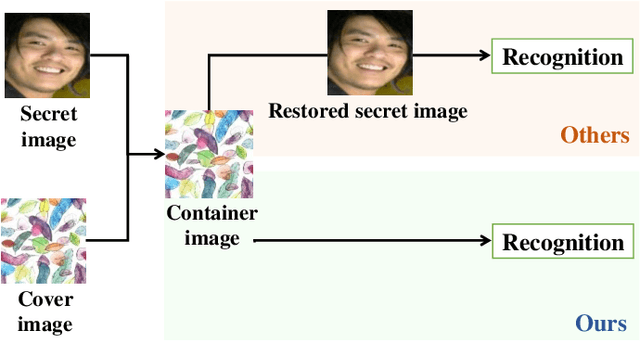

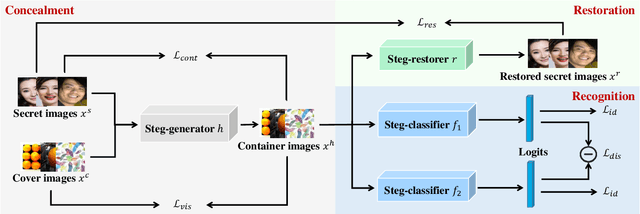
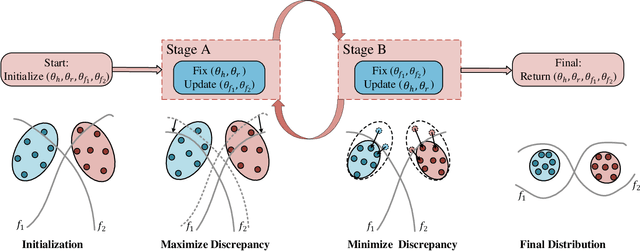
High-capacity image steganography, aimed at concealing a secret image in a cover image, is a technique to preserve sensitive data, e.g., faces and fingerprints. Previous methods focus on the security during transmission and subsequently run a risk of privacy leakage after the restoration of secret images at the receiving end. To address this issue, we propose a framework, called Multitask Identity-Aware Image Steganography (MIAIS), to achieve direct recognition on container images without restoring secret images. The key issue of the direct recognition is to preserve identity information of secret images into container images and make container images look similar to cover images at the same time. Thus, we introduce a simple content loss to preserve the identity information, and design a minimax optimization to deal with the contradictory aspects. We demonstrate that the robustness results can be transferred across different cover datasets. In order to be flexible for the secret image restoration in some cases, we incorporate an optional restoration network into our method, providing a multitask framework. The experiments under the multitask scenario show the effectiveness of our framework compared with other visual information hiding methods and state-of-the-art high-capacity image steganography methods.
An Architecture for the detection of GAN-generated Flood Images with Localization Capabilities
May 14, 2022
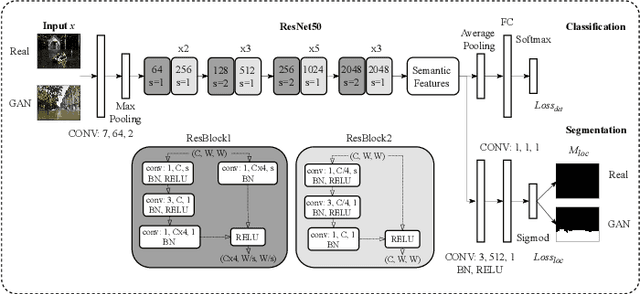
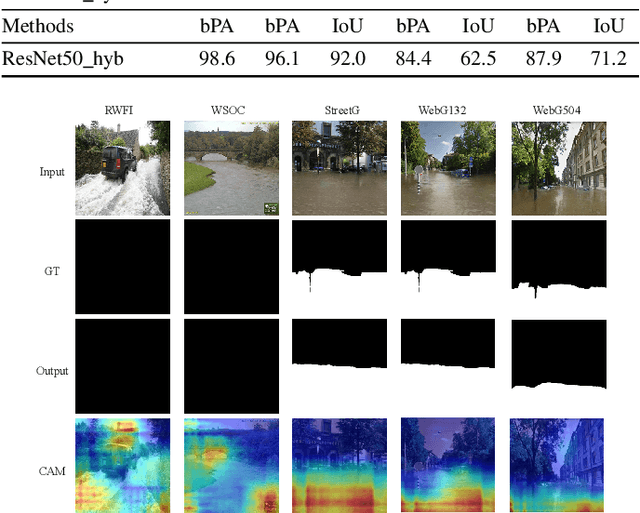
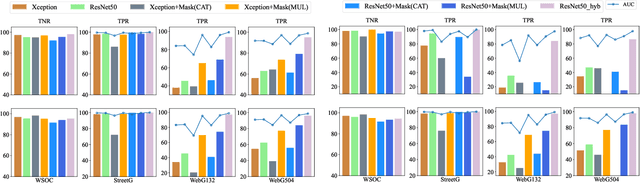
In this paper, we address a new image forensics task, namely the detection of fake flood images generated by ClimateGAN architecture. We do so by proposing a hybrid deep learning architecture including both a detection and a localization branch, the latter being devoted to the identification of the image regions manipulated by ClimateGAN. Even if our goal is the detection of fake flood images, in fact, we found that adding a localization branch helps the network to focus on the most relevant image regions with significant improvements in terms of generalization capabilities and robustness against image processing operations. The good performance of the proposed architecture is validated on two datasets of pristine flood images downloaded from the internet and three datasets of fake flood images generated by ClimateGAN starting from a large set of diverse street images.
Patch-based medical image segmentation using Quantum Tensor Networks
Sep 15, 2021
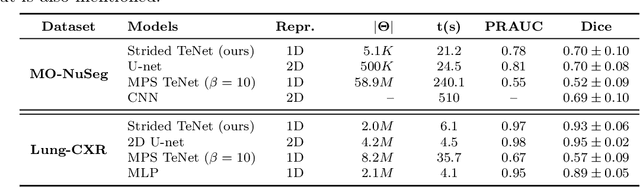
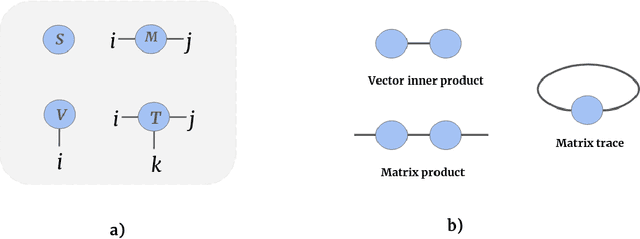
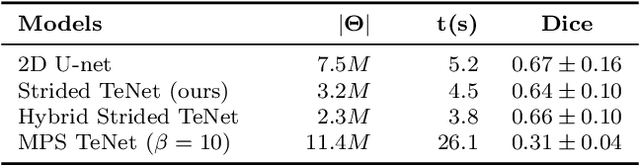
Tensor networks are efficient factorisations of high dimensional tensors into a network of lower order tensors. They have been most commonly used to model entanglement in quantum many-body systems and more recently are witnessing increased applications in supervised machine learning. In this work, we formulate image segmentation in a supervised setting with tensor networks. The key idea is to first lift the pixels in image patches to exponentially high dimensional feature spaces and using a linear decision hyper-plane to classify the input pixels into foreground and background classes. The high dimensional linear model itself is approximated using the matrix product state (MPS) tensor network. The MPS is weight-shared between the non-overlapping image patches resulting in our strided tensor network model. The performance of the proposed model is evaluated on three 2D- and one 3D- biomedical imaging datasets. The performance of the proposed tensor network segmentation model is compared with relevant baseline methods. In the 2D experiments, the tensor network model yeilds competitive performance compared to the baseline methods while being more resource efficient.