 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Feature-Aligned Video Raindrop Removal with Temporal Constraints
May 29, 2022

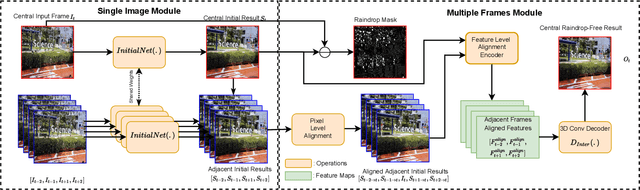
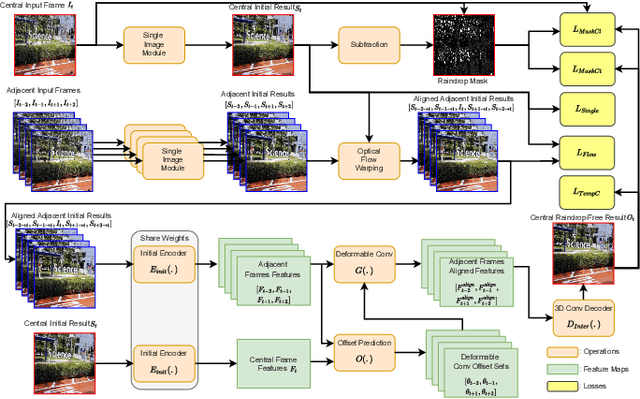

Existing adherent raindrop removal methods focus on the detection of the raindrop locations, and then use inpainting techniques or generative networks to recover the background behind raindrops. Yet, as adherent raindrops are diverse in sizes and appearances, the detection is challenging for both single image and video. Moreover, unlike rain streaks, adherent raindrops tend to cover the same area in several frames. Addressing these problems, our method employs a two-stage video-based raindrop removal method. The first stage is the single image module, which generates initial clean results. The second stage is the multiple frame module, which further refines the initial results using temporal constraints, namely, by utilizing multiple input frames in our process and applying temporal consistency between adjacent output frames. Our single image module employs a raindrop removal network to generate initial raindrop removal results, and create a mask representing the differences between the input and initial output. Once the masks and initial results for consecutive frames are obtained, our multiple-frame module aligns the frames in both the image and feature levels and then obtains the clean background. Our method initially employs optical flow to align the frames, and then utilizes deformable convolution layers further to achieve feature-level frame alignment. To remove small raindrops and recover correct backgrounds, a target frame is predicted from adjacent frames. A series of unsupervised losses are proposed so that our second stage, which is the video raindrop removal module, can self-learn from video data without ground truths. Experimental results on real videos demonstrate the state-of-art performance of our method both quantitatively and qualitatively.
Almost-Orthogonal Layers for Efficient General-Purpose Lipschitz Networks
Aug 05, 2022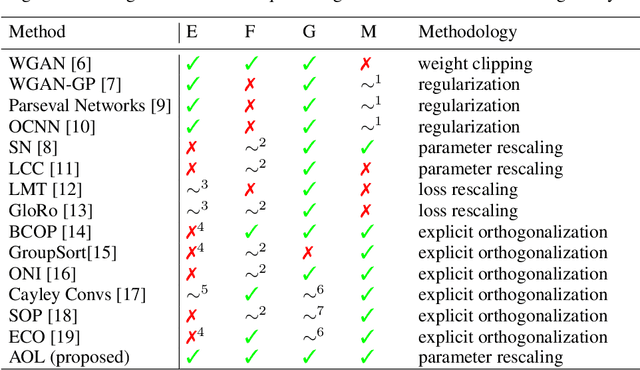
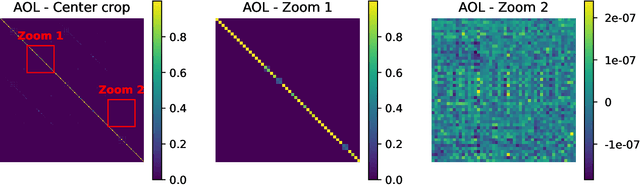

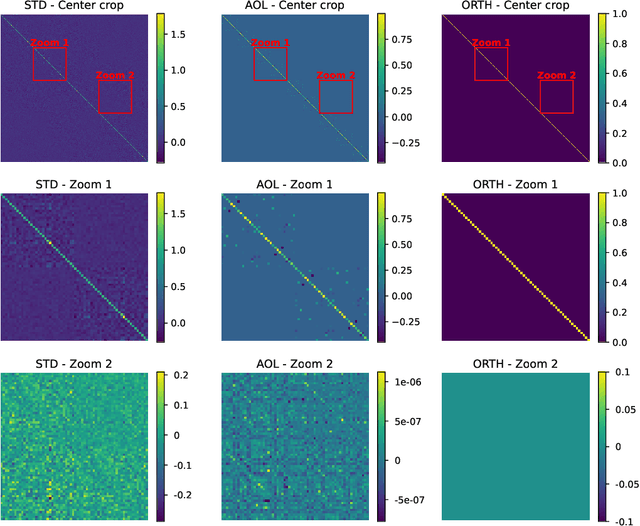
It is a highly desirable property for deep networks to be robust against small input changes. One popular way to achieve this property is by designing networks with a small Lipschitz constant. In this work, we propose a new technique for constructing such Lipschitz networks that has a number of desirable properties: it can be applied to any linear network layer (fully-connected or convolutional), it provides formal guarantees on the Lipschitz constant, it is easy to implement and efficient to run, and it can be combined with any training objective and optimization method. In fact, our technique is the first one in the literature that achieves all of these properties simultaneously. Our main contribution is a rescaling-based weight matrix parametrization that guarantees each network layer to have a Lipschitz constant of at most 1 and results in the learned weight matrices to be close to orthogonal. Hence we call such layers almost-orthogonal Lipschitz (AOL). Experiments and ablation studies in the context of image classification with certified robust accuracy confirm that AOL layers achieve results that are on par with most existing methods. Yet, they are simpler to implement and more broadly applicable, because they do not require computationally expensive matrix orthogonalization or inversion steps as part of the network architecture. We provide code at https://github.com/berndprach/AOL.
Adversarially-Aware Robust Object Detector
Jul 22, 2022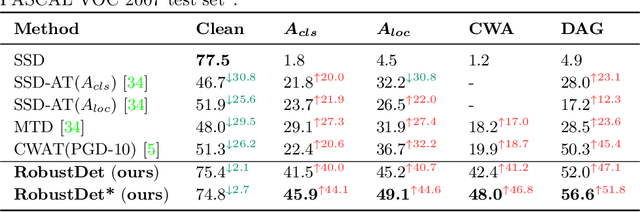
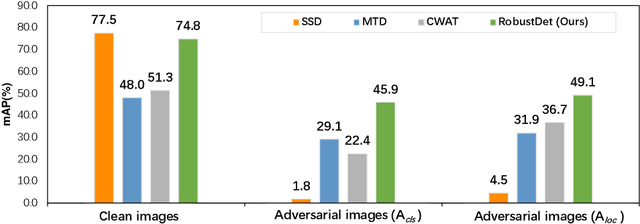
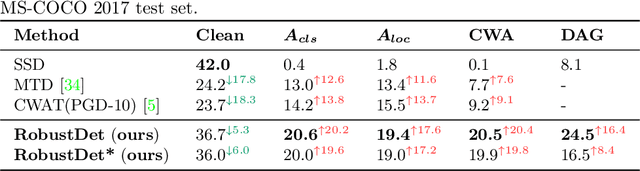
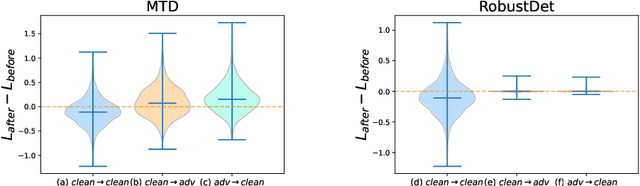
Object detection, as a fundamental computer vision task, has achieved a remarkable progress with the emergence of deep neural networks. Nevertheless, few works explore the adversarial robustness of object detectors to resist adversarial attacks for practical applications in various real-world scenarios. Detectors have been greatly challenged by unnoticeable perturbation, with sharp performance drop on clean images and extremely poor performance on adversarial images. In this work, we empirically explore the model training for adversarial robustness in object detection, which greatly attributes to the conflict between learning clean images and adversarial images. To mitigate this issue, we propose a Robust Detector (RobustDet) based on adversarially-aware convolution to disentangle gradients for model learning on clean and adversarial images. RobustDet also employs the Adversarial Image Discriminator (AID) and Consistent Features with Reconstruction (CFR) to ensure a reliable robustness. Extensive experiments on PASCAL VOC and MS-COCO demonstrate that our model effectively disentangles gradients and significantly enhances the detection robustness with maintaining the detection ability on clean images.
* ECCV2022 oral paper
FOVEA: Foveated Image Magnification for Autonomous Navigation
Aug 27, 2021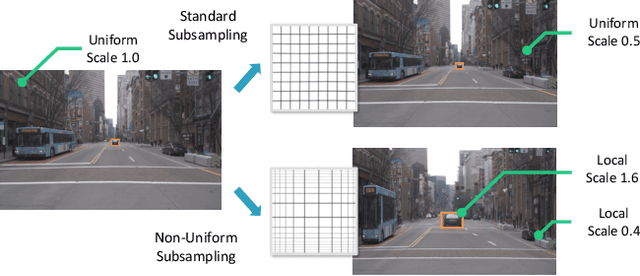
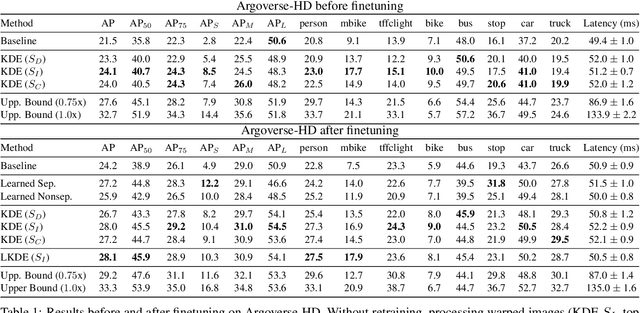
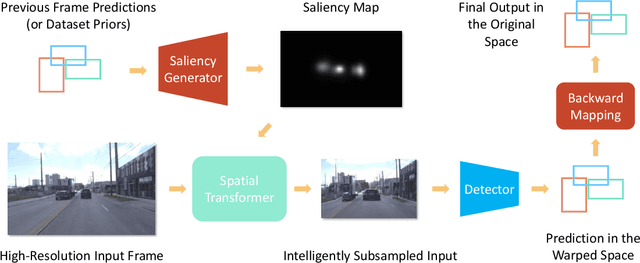
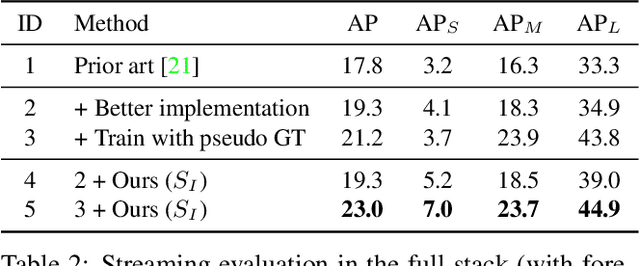
Efficient processing of high-resolution video streams is safety-critical for many robotics applications such as autonomous driving. Image downsampling is a commonly adopted technique to ensure the latency constraint is met. However, this naive approach greatly restricts an object detector's capability to identify small objects. In this paper, we propose an attentional approach that elastically magnifies certain regions while maintaining a small input canvas. The magnified regions are those that are believed to have a high probability of containing an object, whose signal can come from a dataset-wide prior or frame-level prior computed from recent object predictions. The magnification is implemented by a KDE-based mapping to transform the bounding boxes into warping parameters, which are then fed into an image sampler with anti-cropping regularization. The detector is then fed with the warped image and we apply a differentiable backward mapping to get bounding box outputs in the original space. Our regional magnification allows algorithms to make better use of high-resolution input without incurring the cost of high-resolution processing. On the autonomous driving datasets Argoverse-HD and BDD100K, we show our proposed method boosts the detection AP over standard Faster R-CNN, with and without finetuning. Additionally, building on top of the previous state-of-the-art in streaming detection, our method sets a new record for streaming AP on Argoverse-HD (from 17.8 to 23.0 on a GTX 1080 Ti GPU), suggesting that it has achieved a superior accuracy-latency tradeoff.
Seeing Far in the Dark with Patterned Flash
Jul 25, 2022
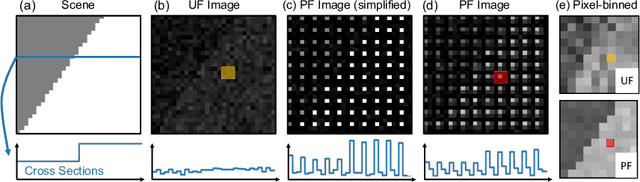
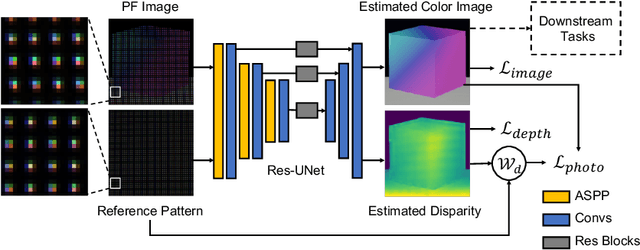
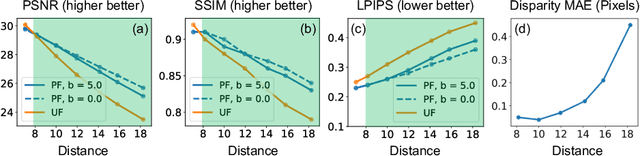
Flash illumination is widely used in imaging under low-light environments. However, illumination intensity falls off with propagation distance quadratically, which poses significant challenges for flash imaging at a long distance. We propose a new flash technique, named ``patterned flash'', for flash imaging at a long distance. Patterned flash concentrates optical power into a dot array. Compared with the conventional uniform flash where the signal is overwhelmed by the noise everywhere, patterned flash provides stronger signals at sparsely distributed points across the field of view to ensure the signals at those points stand out from the sensor noise. This enables post-processing to resolve important objects and details. Additionally, the patterned flash projects texture onto the scene, which can be treated as a structured light system for depth perception. Given the novel system, we develop a joint image reconstruction and depth estimation algorithm with a convolutional neural network. We build a hardware prototype and test the proposed flash technique on various scenes. The experimental results demonstrate that our patterned flash has significantly better performance at long distances in low-light environments.
An Efficient Pattern Mining Convolution Neural Network (CNN) algorithm with Grey Wolf Optimization (GWO)
Apr 10, 2022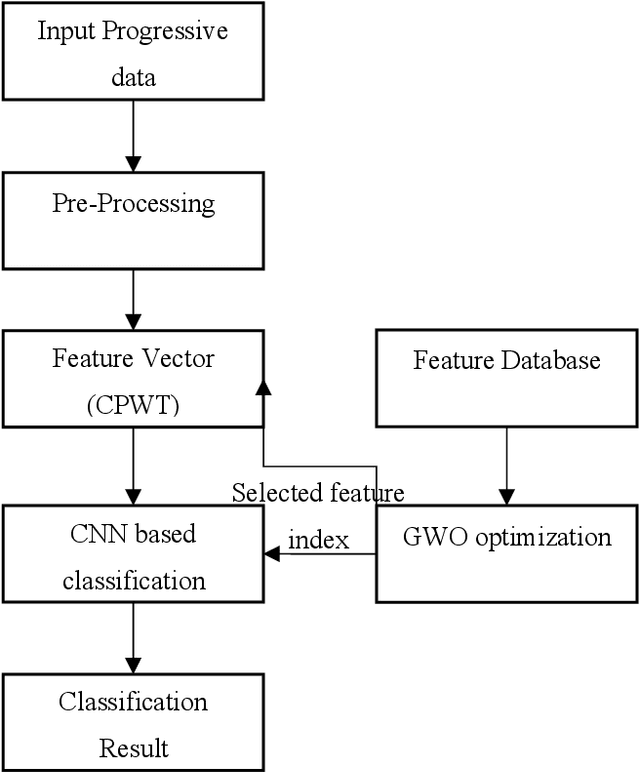
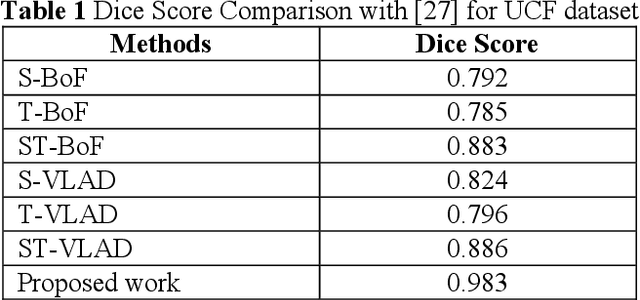
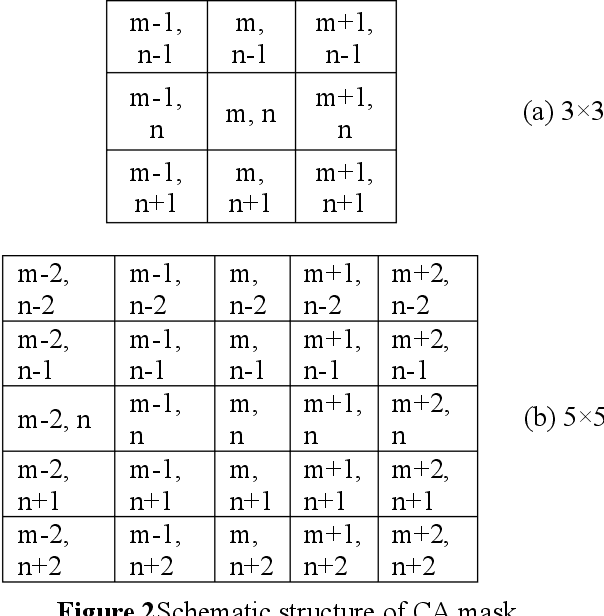
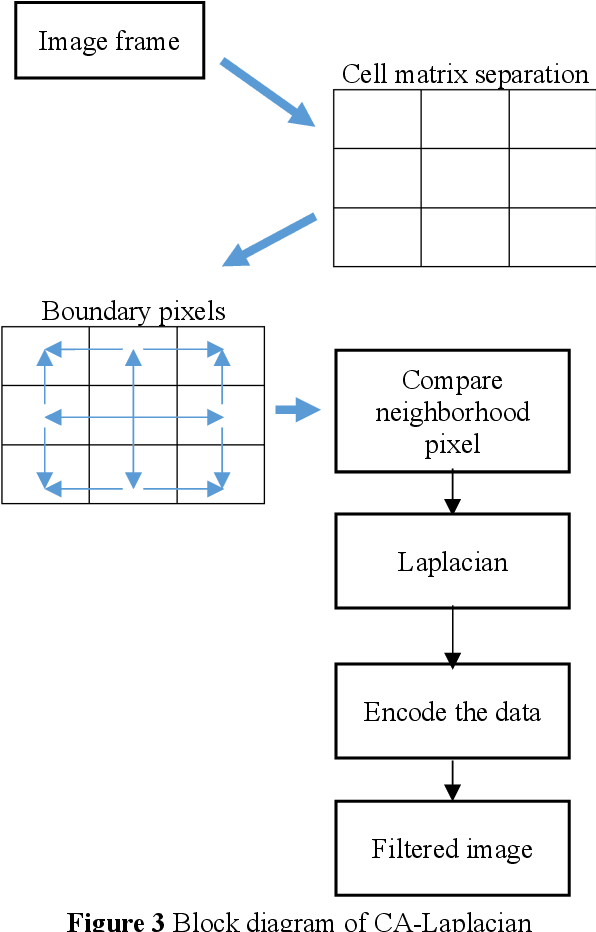
Automation of feature analysis in the dynamic image frame dataset deals with complexity of intensity mapping with normal and abnormal class. The threshold-based data clustering and feature analysis requires iterative model to learn the component of image frame in multi-pattern for different image frame data type. This paper proposed a novel model of feature analysis method with the CNN based on Convoluted Pattern of Wavelet Transform (CPWT) feature vectors that are optimized by Grey Wolf Optimization (GWO) algorithm. Initially, the image frame gets normalized by applying median filter to the image frame that reduce the noise and apply smoothening on it. From that, the edge information represents the boundary region of bright spot in the image frame. Neural network-based image frame classification performs repeated learning of the feature with minimum training of dataset to cluster the image frame pixels. Features of the filtered image frame was analyzed in different pattern of feature extraction model based on the convoluted model of wavelet transformation method. These features represent the different class of image frame in spatial and textural pattern of it. Convolutional Neural Network (CNN) classifier supports to analyze the features and classify the action label for the image frame dataset. This process enhances the classification with minimum number of training dataset. The performance of this proposed method can be validated by comparing with traditional state-of-art methods.
C3-DINO: Joint Contrastive and Non-contrastive Self-Supervised Learning for Speaker Verification
Aug 15, 2022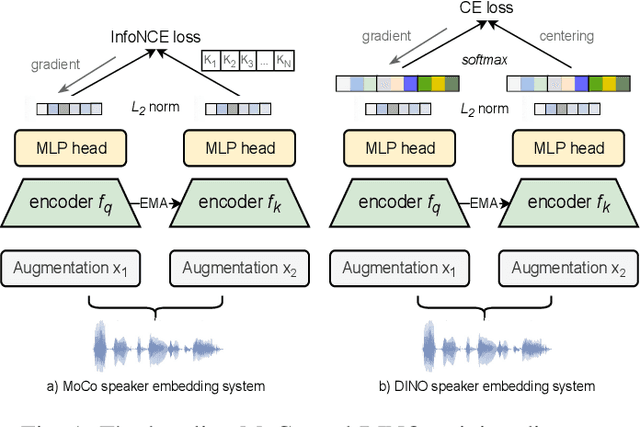
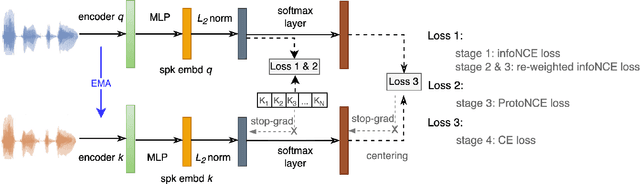
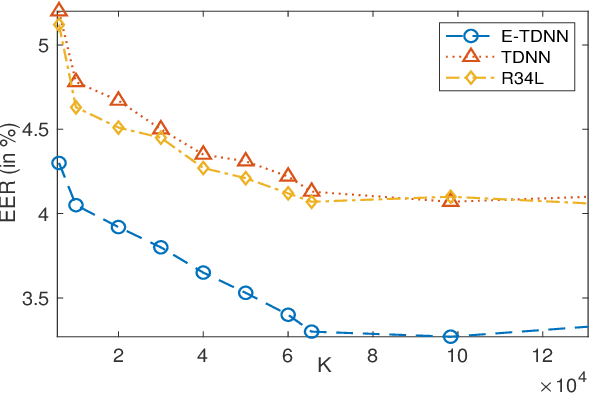
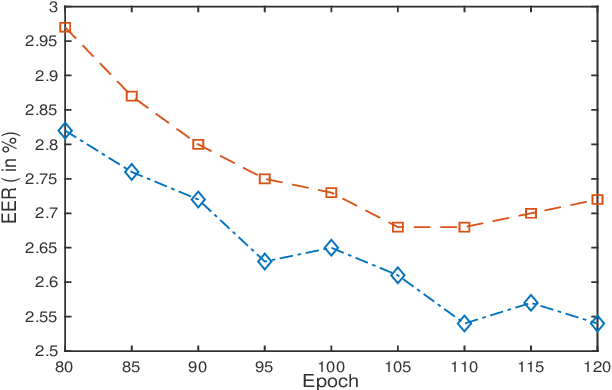
Self-supervised learning (SSL) has drawn an increased attention in the field of speech processing. Recent studies have demonstrated that contrastive learning is able to learn discriminative speaker embeddings in a self-supervised manner. However, base contrastive self-supervised learning (CSSL) assumes that the pairs generated from a view of anchor instance and any view of other instances are all negative, which introduces many false negative pairs in constructing the loss function. The problem is referred as $class$-$collision$, which remains as one major issue that impedes the CSSL based speaker verification (SV) systems from achieving better performances. In the meanwhile, studies reveal that negative sample free SSL frameworks perform well in learning speaker or image representations. In this study, we investigate SSL techniques that lead to an improved SV performance. We first analyse the impact of false negative pairs in the CSSL systems. Then, a multi-stage Class-Collision Correction (C3) method is proposed, which leads to the state-of-the-art CSSL based speaker embedding system. On the basis of the pretrained CSSL model, we further propose to employ a negative sample free SSL objective (i.e., DINO) to fine-tune the speaker embedding network. The resulting speaker embedding system (C3-DINO) achieves 2.5% EER with a simple Cosine Distance Scoring method on Voxceleb1 test set, which outperforms the previous SOTA SSL system (4.86%) by a significant +45% relative improvement. With speaker clustering and pseudo labeling on Voxceleb2 training set, a LDA/CDS back-end applying on the C3-DINO speaker embeddings is able to further push the EER to 2.2%. Comprehensive experimental investigations of the Voxceleb benchmarks and our internal dataset demonstrate the effectiveness of our proposed methods, and the performance gap between the SSL SV and the supervised counterpart narrows further.
End-to-End 3D Hand Pose Estimation from Stereo Cameras
Jun 03, 2022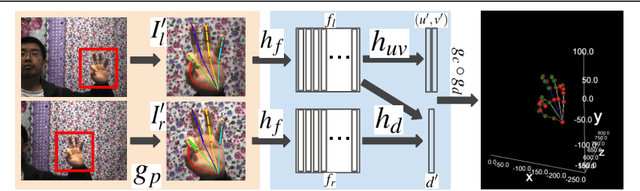
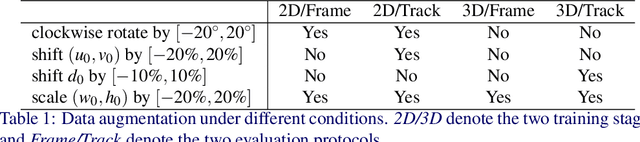

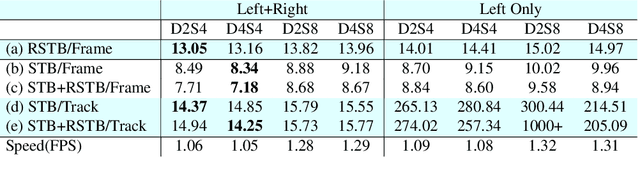
This work proposes an end-to-end approach to estimate full 3D hand pose from stereo cameras. Most existing methods of estimating hand pose from stereo cameras apply stereo matching to obtain depth map and use depth-based solution to estimate hand pose. In contrast, we propose to bypass the stereo matching and directly estimate the 3D hand pose from the stereo image pairs. The proposed neural network architecture extends from any keypoint predictor to estimate the sparse disparity of the hand joints. In order to effectively train the model, we propose a large scale synthetic dataset that is composed of stereo image pairs and ground truth 3D hand pose annotations. Experiments show that the proposed approach outperforms the existing methods based on the stereo depth.
Irrelevant Pixels are Everywhere: Find and Exclude Them for More Efficient Computer Vision
Jul 21, 2022

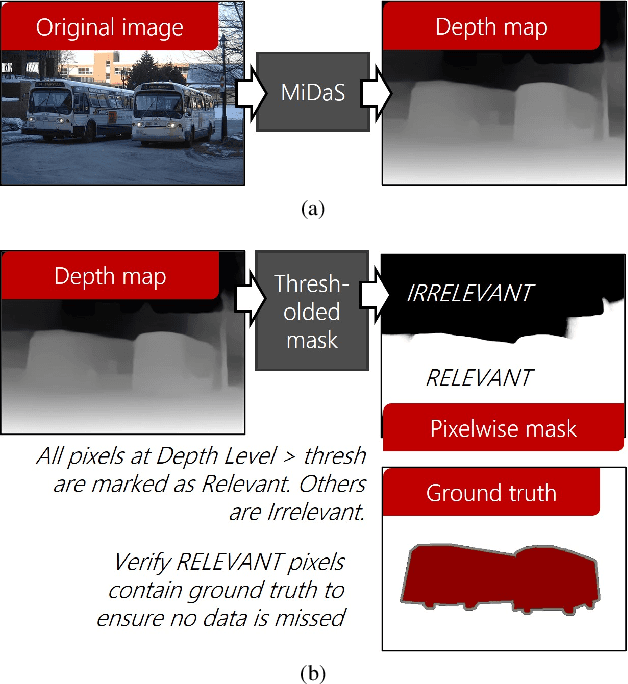
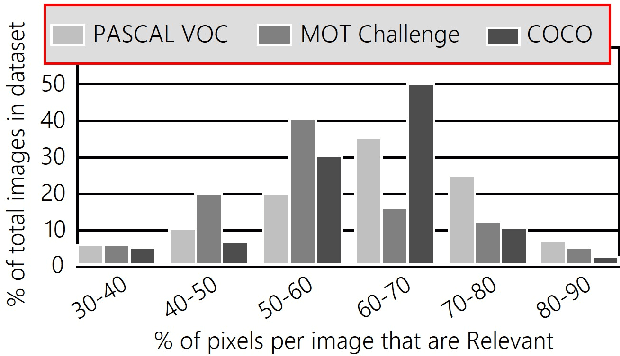
Computer vision is often performed using Convolutional Neural Networks (CNNs). CNNs are compute-intensive and challenging to deploy on power-contrained systems such as mobile and Internet-of-Things (IoT) devices. CNNs are compute-intensive because they indiscriminately compute many features on all pixels of the input image. We observe that, given a computer vision task, images often contain pixels that are irrelevant to the task. For example, if the task is looking for cars, pixels in the sky are not very useful. Therefore, we propose that a CNN be modified to only operate on relevant pixels to save computation and energy. We propose a method to study three popular computer vision datasets, finding that 48% of pixels are irrelevant. We also propose the focused convolution to modify a CNN's convolutional layers to reject the pixels that are marked irrelevant. On an embedded device, we observe no loss in accuracy, while inference latency, energy consumption, and multiply-add count are all reduced by about 45%.
An Efficient Dual-reference Training Data Acquisition Method for CNN Image Super-Resolution
Aug 24, 2021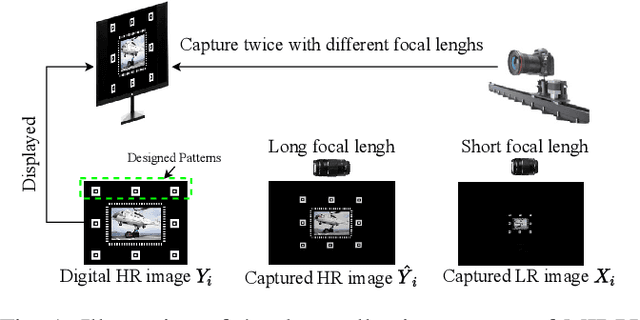



For deep learning methods of image super-resolution, the most critical issue is whether the paired low and high resolution images for training accurately reflect the sampling process of real cameras. Low and high resolution (LR$\sim$HR) image pairs synthesized by existing degradation models (e.g. bicubic downsampling) deviate from those in reality; thus the super-resolution CNN trained by these synthesized LR$\sim$HR image pairs does not perform well when being applied to real images. In this paper, we propose a novel method to capture a large set of realistic LR$\sim$HR image pairs using real cameras. The data acquisition is carried out under controllable lab conditions with minimum human intervention and at high throughput (about 500 image pairs per hour). The high level of automation makes it easy to produce a set of real LR$\sim$HR training image pairs for each camera.Our innovation is to shoot images displayed on an ultra-high quality screen at different resolutions. There are three distinctive advantages of our method for image super-resolution. First, as the LR and HR images are taken of a 3D planar surface (the screen) the registration problem fits exactly to a homography model and we can display specially designed markers on the image to improve the registration precision. Second, the displayed digital image file can be exploited as a reference to optimize the high frequency content of the restored image. Third, this high-efficiency data collection method makes it possible to collect a customized dataset for each camera sensor, for which one can train a specific model for the intended camera sensor. Experimental results show that training a super-resolution CNN by our LR$\sim$HR dataset has superior restoration performance than training it by existing datasets on real world images at the inference stage.