 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Almost-Orthogonal Layers for Efficient General-Purpose Lipschitz Networks
Aug 05, 2022
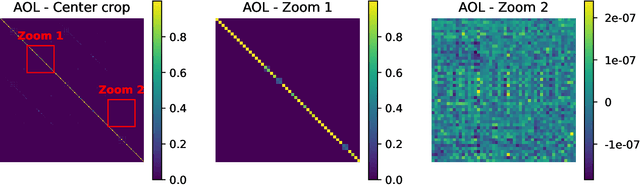

It is a highly desirable property for deep networks to be robust against small input changes. One popular way to achieve this property is by designing networks with a small Lipschitz constant. In this work, we propose a new technique for constructing such Lipschitz networks that has a number of desirable properties: it can be applied to any linear network layer (fully-connected or convolutional), it provides formal guarantees on the Lipschitz constant, it is easy to implement and efficient to run, and it can be combined with any training objective and optimization method. In fact, our technique is the first one in the literature that achieves all of these properties simultaneously. Our main contribution is a rescaling-based weight matrix parametrization that guarantees each network layer to have a Lipschitz constant of at most 1 and results in the learned weight matrices to be close to orthogonal. Hence we call such layers almost-orthogonal Lipschitz (AOL). Experiments and ablation studies in the context of image classification with certified robust accuracy confirm that AOL layers achieve results that are on par with most existing methods. Yet, they are simpler to implement and more broadly applicable, because they do not require computationally expensive matrix orthogonalization or inversion steps as part of the network architecture. We provide code at https://github.com/berndprach/AOL.
Survey: Image Mixing and Deleting for Data Augmentation
Jun 13, 2021
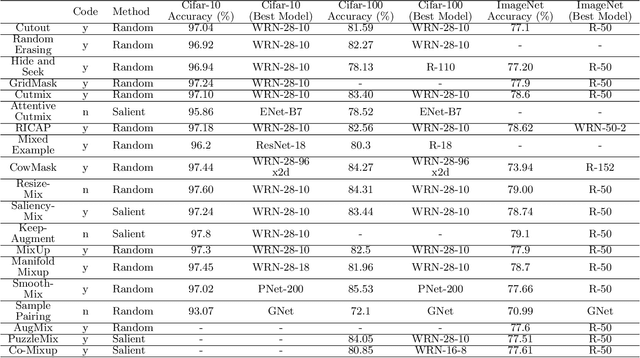
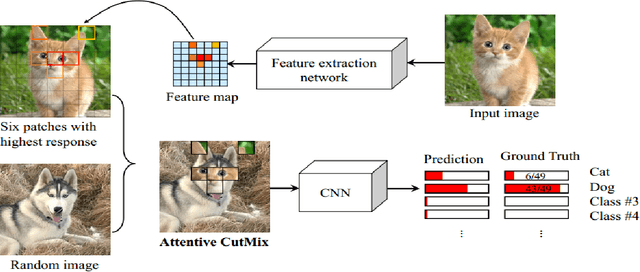
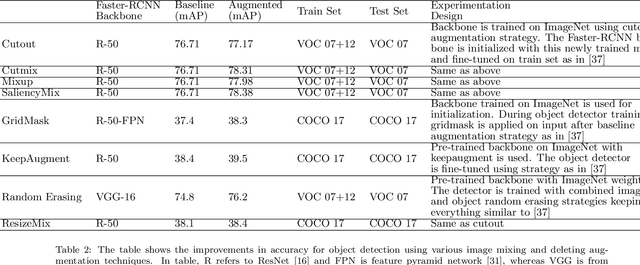
Data augmentation has been widely used to improve deep nerual networks performance. Numerous approaches are suggested, for example, dropout, regularization and image augmentation, to avoid over-ftting and enhancing generalization of neural networks. One of the sub-area within data augmentation is image mixing and deleting. This specific type of augmentation either mixes two images or delete image regions to hide or make certain characteristics of images confusing for the network to force it to emphasize on overall structure of object in image. The model trained with this approach has shown to perform and generalize well as compared to one trained without imgage mixing or deleting. Additional benefit achieved with this method of training is robustness against image corruptions. Due to its low compute cost and success in recent past, many techniques of image mixing and deleting are proposed. This paper provides detailed review on these devised approaches, dividing augmentation strategies in three main categories cut and delete, cut and mix and mixup. The second part of paper emprically evaluates these approaches for image classification, finegrained image recognition and object detection where it is shown that this category of data augmentation improves the overall performance for deep neural networks.
Solving Image PDEs with a Shallow Network
Oct 15, 2021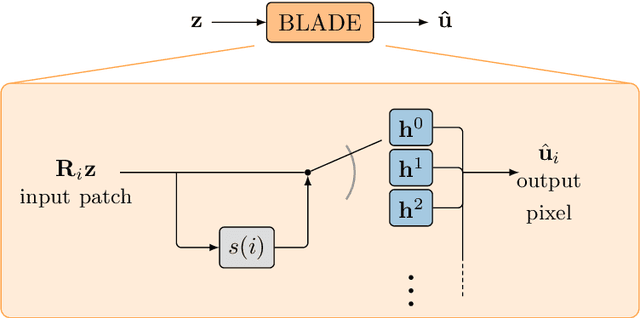
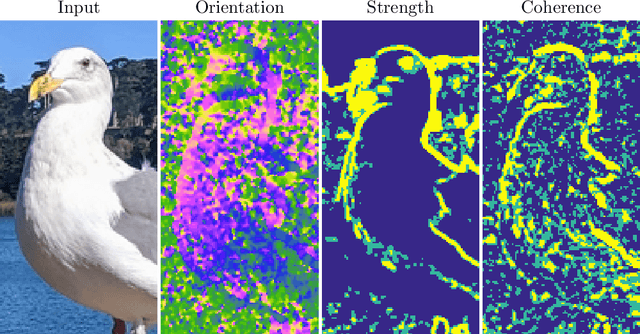
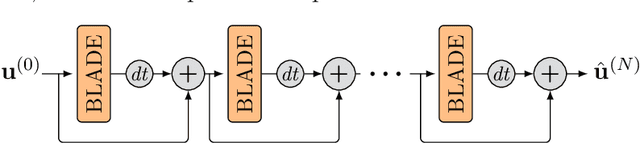
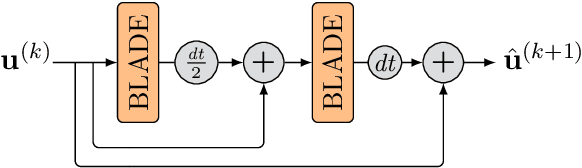
Partial differential equations (PDEs) are typically used as models of physical processes but are also of great interest in PDE-based image processing. However, when it comes to their use in imaging, conventional numerical methods for solving PDEs tend to require very fine grid resolution for stability, and as a result have impractically high computational cost. This work applies BLADE (Best Linear Adaptive Enhancement), a shallow learnable filtering framework, to PDE solving, and shows that the resulting approach is efficient and accurate, operating more reliably at coarse grid resolutions than classical methods. As such, the model can be flexibly used for a wide variety of problems in imaging.
C3-DINO: Joint Contrastive and Non-contrastive Self-Supervised Learning for Speaker Verification
Aug 15, 2022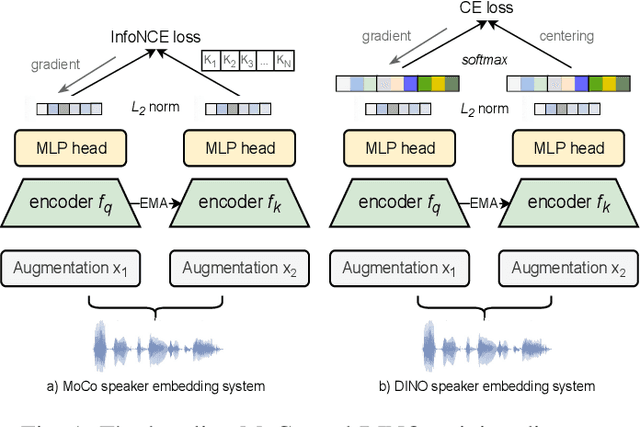
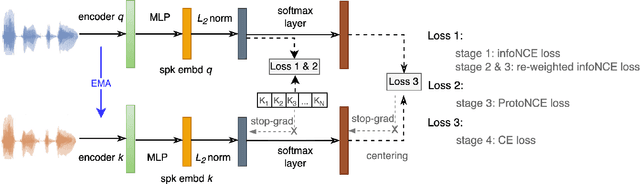
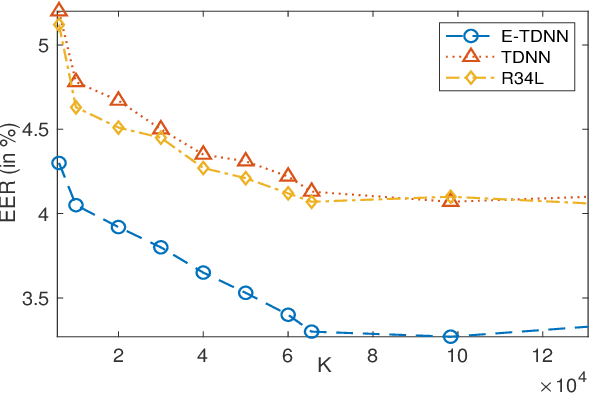
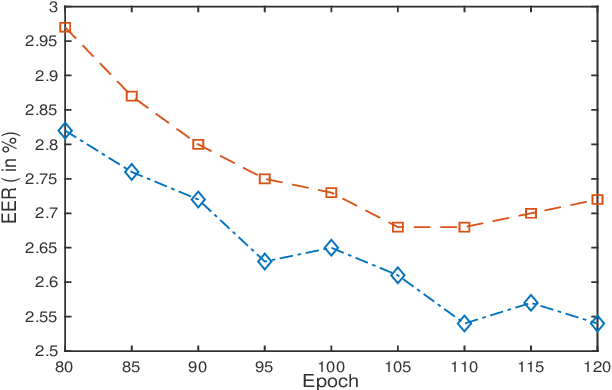
Self-supervised learning (SSL) has drawn an increased attention in the field of speech processing. Recent studies have demonstrated that contrastive learning is able to learn discriminative speaker embeddings in a self-supervised manner. However, base contrastive self-supervised learning (CSSL) assumes that the pairs generated from a view of anchor instance and any view of other instances are all negative, which introduces many false negative pairs in constructing the loss function. The problem is referred as $class$-$collision$, which remains as one major issue that impedes the CSSL based speaker verification (SV) systems from achieving better performances. In the meanwhile, studies reveal that negative sample free SSL frameworks perform well in learning speaker or image representations. In this study, we investigate SSL techniques that lead to an improved SV performance. We first analyse the impact of false negative pairs in the CSSL systems. Then, a multi-stage Class-Collision Correction (C3) method is proposed, which leads to the state-of-the-art CSSL based speaker embedding system. On the basis of the pretrained CSSL model, we further propose to employ a negative sample free SSL objective (i.e., DINO) to fine-tune the speaker embedding network. The resulting speaker embedding system (C3-DINO) achieves 2.5% EER with a simple Cosine Distance Scoring method on Voxceleb1 test set, which outperforms the previous SOTA SSL system (4.86%) by a significant +45% relative improvement. With speaker clustering and pseudo labeling on Voxceleb2 training set, a LDA/CDS back-end applying on the C3-DINO speaker embeddings is able to further push the EER to 2.2%. Comprehensive experimental investigations of the Voxceleb benchmarks and our internal dataset demonstrate the effectiveness of our proposed methods, and the performance gap between the SSL SV and the supervised counterpart narrows further.
Adversarially-Aware Robust Object Detector
Jul 22, 2022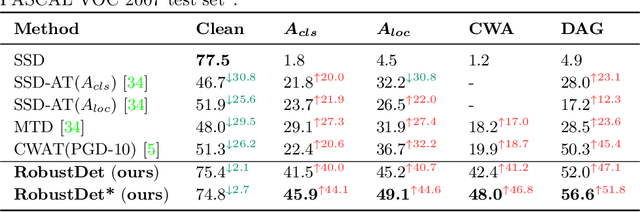
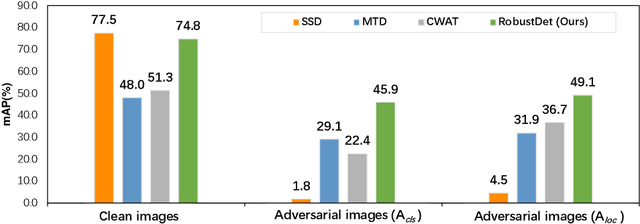
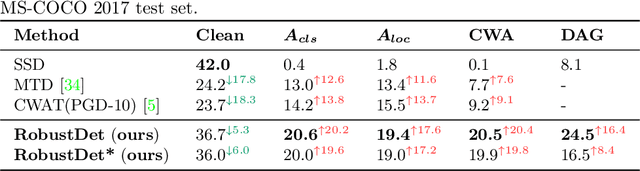
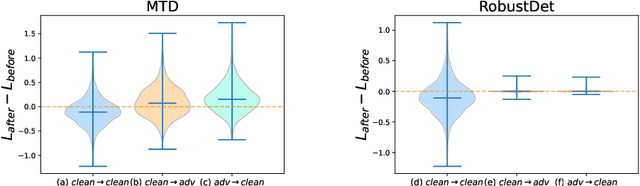
Object detection, as a fundamental computer vision task, has achieved a remarkable progress with the emergence of deep neural networks. Nevertheless, few works explore the adversarial robustness of object detectors to resist adversarial attacks for practical applications in various real-world scenarios. Detectors have been greatly challenged by unnoticeable perturbation, with sharp performance drop on clean images and extremely poor performance on adversarial images. In this work, we empirically explore the model training for adversarial robustness in object detection, which greatly attributes to the conflict between learning clean images and adversarial images. To mitigate this issue, we propose a Robust Detector (RobustDet) based on adversarially-aware convolution to disentangle gradients for model learning on clean and adversarial images. RobustDet also employs the Adversarial Image Discriminator (AID) and Consistent Features with Reconstruction (CFR) to ensure a reliable robustness. Extensive experiments on PASCAL VOC and MS-COCO demonstrate that our model effectively disentangles gradients and significantly enhances the detection robustness with maintaining the detection ability on clean images.
* ECCV2022 oral paper
Multi-Classification of Brain Tumor Images Using Transfer Learning Based Deep Neural Network
Jun 17, 2022
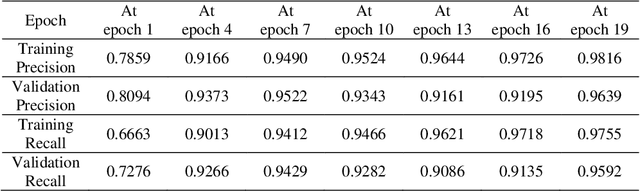
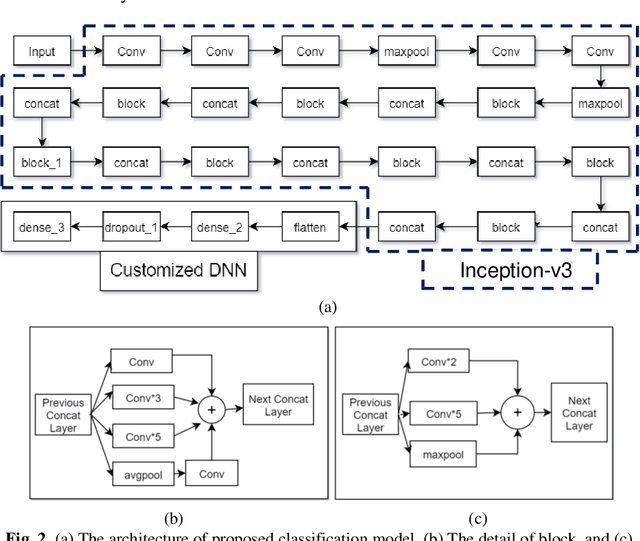

In recent advancement towards computer based diagnostics system, the classification of brain tumor images is a challenging task. This paper mainly focuses on elevating the classification accuracy of brain tumor images with transfer learning based deep neural network. The classification approach is started with the image augmentation operation including rotation, zoom, hori-zontal flip, width shift, height shift, and shear to increase the diversity in image datasets. Then the general features of the input brain tumor images are extracted based on a pre-trained transfer learning method comprised of Inception-v3. Fi-nally, the deep neural network with 4 customized layers is employed for classi-fying the brain tumors in most frequent brain tumor types as meningioma, glioma, and pituitary. The proposed model acquires an effective performance with an overall accuracy of 96.25% which is much improved than some existing multi-classification methods. Whereas, the fine-tuning of hyper-parameters and inclusion of customized DNN with the Inception-v3 model results in an im-provement of the classification accuracy.
* 7 pages, 4 figures, 2 tables, International Virtual Conference on ARTIFICIAL INTELLIGENCE FOR SMART COMMUNITY, Malaysia
A Generative Adversarial Framework for Optimizing Image Matting and Harmonization Simultaneously
Aug 13, 2021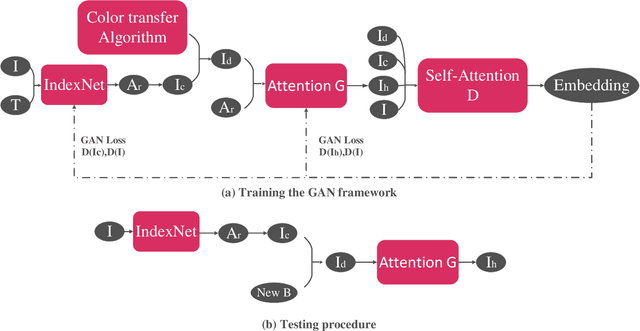
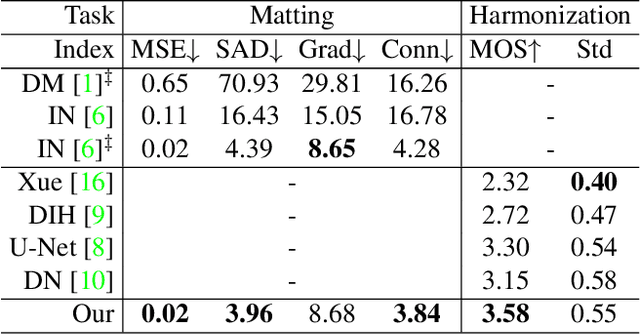
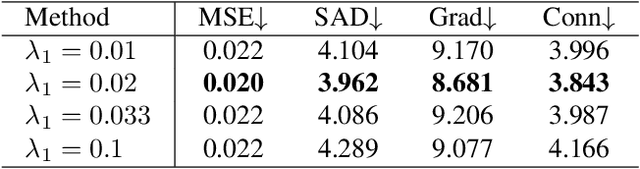
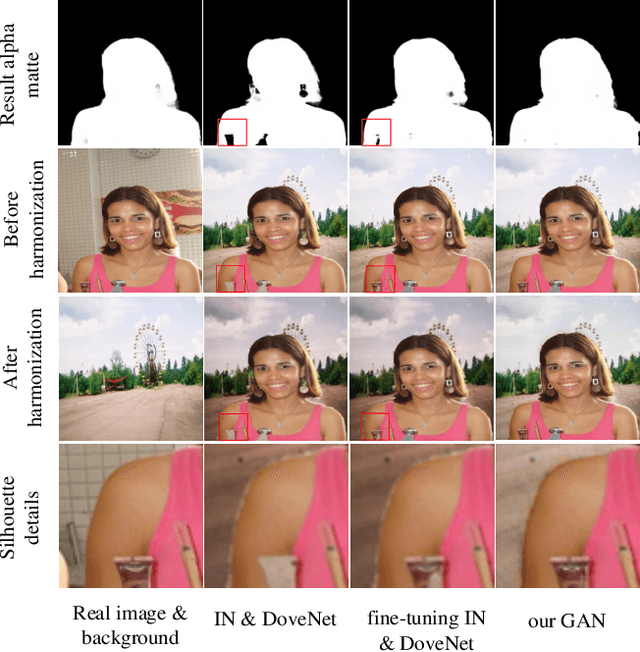
Image matting and image harmonization are two important tasks in image composition. Image matting, aiming to achieve foreground boundary details, and image harmonization, aiming to make the background compatible with the foreground, are both promising yet challenging tasks. Previous works consider optimizing these two tasks separately, which may lead to a sub-optimal solution. We propose to optimize matting and harmonization simultaneously to get better performance on both the two tasks and achieve more natural results. We propose a new Generative Adversarial (GAN) framework which optimizing the matting network and the harmonization network based on a self-attention discriminator. The discriminator is required to distinguish the natural images from different types of fake synthesis images. Extensive experiments on our constructed dataset demonstrate the effectiveness of our proposed method. Our dataset and dataset generating pipeline can be found in \url{https://git.io/HaMaGAN}
* Extension for accepted ICIP 2021
Contour-guided Image Completion with Perceptual Grouping
Nov 22, 2021
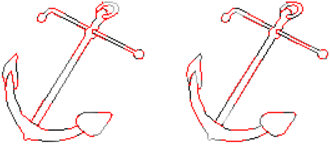

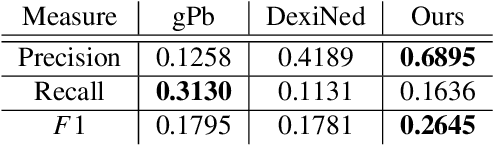
Humans are excellent at perceiving illusory outlines. We are readily able to complete contours, shapes, scenes, and even unseen objects when provided with images that contain broken fragments of a connected appearance. In vision science, this ability is largely explained by perceptual grouping: a foundational set of processes in human vision that describes how separated elements can be grouped. In this paper, we revisit an algorithm called Stochastic Completion Fields (SCFs) that mechanizes a set of such processes -- good continuity, closure, and proximity -- through contour completion. This paper implements a modernized model of the SCF algorithm, and uses it in an image editing framework where we propose novel methods to complete fragmented contours. We show how the SCF algorithm plausibly mimics results in human perception. We use the SCF completed contours as guides for inpainting, and show that our guides improve the performance of state-of-the-art models. Additionally, we show that the SCF aids in finding edges in high-noise environments. Overall, our described algorithms resemble an important mechanism in the human visual system, and offer a novel framework that modern computer vision models can benefit from.
Neural Architecture Adaptation for Object Detection by Searching Channel Dimensions and Mapping Pre-trained Parameters
Jun 17, 2022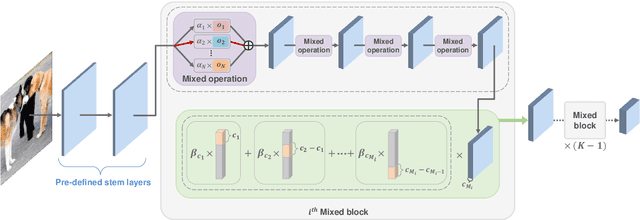

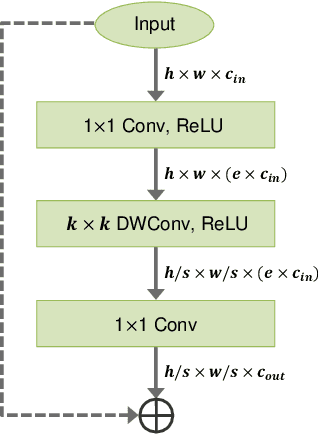
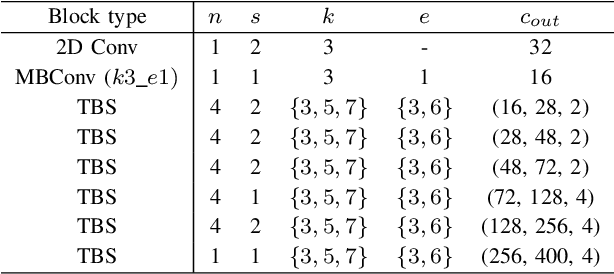
Most object detection frameworks use backbone architectures originally designed for image classification, conventionally with pre-trained parameters on ImageNet. However, image classification and object detection are essentially different tasks and there is no guarantee that the optimal backbone for classification is also optimal for object detection. Recent neural architecture search (NAS) research has demonstrated that automatically designing a backbone specifically for object detection helps improve the overall accuracy. In this paper, we introduce a neural architecture adaptation method that can optimize the given backbone for detection purposes, while still allowing the use of pre-trained parameters. We propose to adapt both the micro- and macro-architecture by searching for specific operations and the number of layers, in addition to the output channel dimensions of each block. It is important to find the optimal channel depth, as it greatly affects the feature representation capability and computation cost. We conduct experiments with our searched backbone for object detection and demonstrate that our backbone outperforms both manually designed and searched state-of-the-art backbones on the COCO dataset.
A Robust Ensemble Model for Patasitic Egg Detection and Classification
Jul 04, 2022
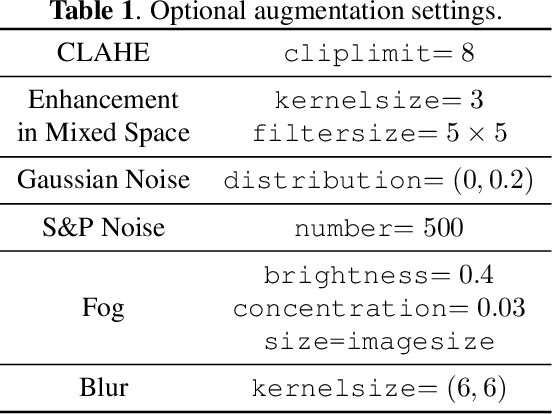
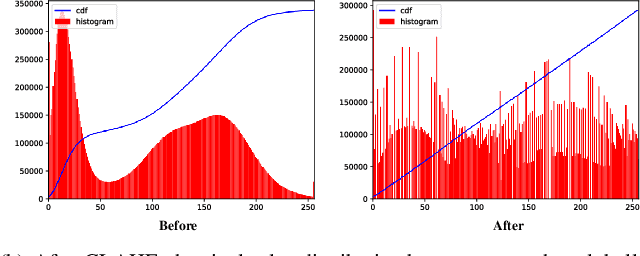
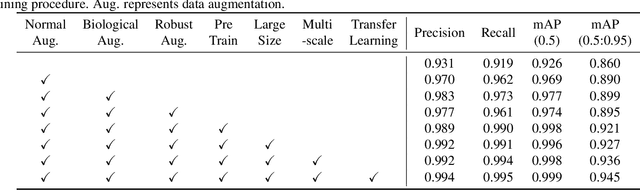
Intestinal parasitic infections, as a leading causes of morbidity worldwide, still lacks time-saving, high-sensitivity and user-friendly examination method. The development of deep learning technique reveals its broad application potential in biological image. In this paper, we apply several object detectors such as YOLOv5 and variant cascadeRCNNs to automatically discriminate parasitic eggs in microscope images. Through specially-designed optimization including raw data augmentation, model ensemble, transfer learning and test time augmentation, our model achieves excellent performance on challenge dataset. In addition, our model trained with added noise gains a high robustness against polluted input, which further broaden its applicability in practice.