 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Quantifying the Knowledge in a DNN to Explain Knowledge Distillation for Classification
Aug 18, 2022

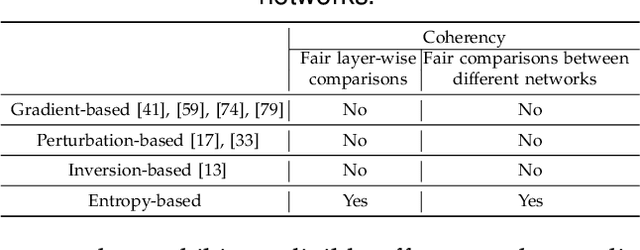
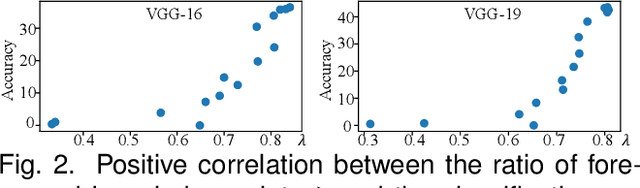
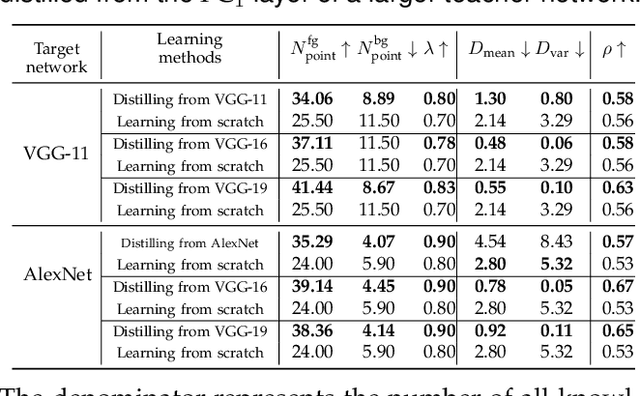
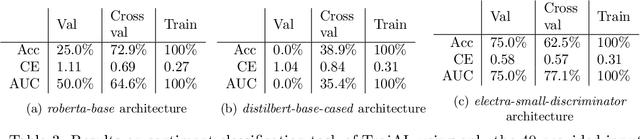
Compared to traditional learning from scratch, knowledge distillation sometimes makes the DNN achieve superior performance. This paper provides a new perspective to explain the success of knowledge distillation, i.e., quantifying knowledge points encoded in intermediate layers of a DNN for classification, based on the information theory. To this end, we consider the signal processing in a DNN as the layer-wise information discarding. A knowledge point is referred to as an input unit, whose information is much less discarded than other input units. Thus, we propose three hypotheses for knowledge distillation based on the quantification of knowledge points. 1. The DNN learning from knowledge distillation encodes more knowledge points than the DNN learning from scratch. 2. Knowledge distillation makes the DNN more likely to learn different knowledge points simultaneously. In comparison, the DNN learning from scratch tends to encode various knowledge points sequentially. 3. The DNN learning from knowledge distillation is often optimized more stably than the DNN learning from scratch. In order to verify the above hypotheses, we design three types of metrics with annotations of foreground objects to analyze feature representations of the DNN, \textit{i.e.} the quantity and the quality of knowledge points, the learning speed of different knowledge points, and the stability of optimization directions. In experiments, we diagnosed various DNNs for different classification tasks, i.e., image classification, 3D point cloud classification, binary sentiment classification, and question answering, which verified above hypotheses.
Auxiliary Loss Adaption for Image Inpainting
Nov 14, 2021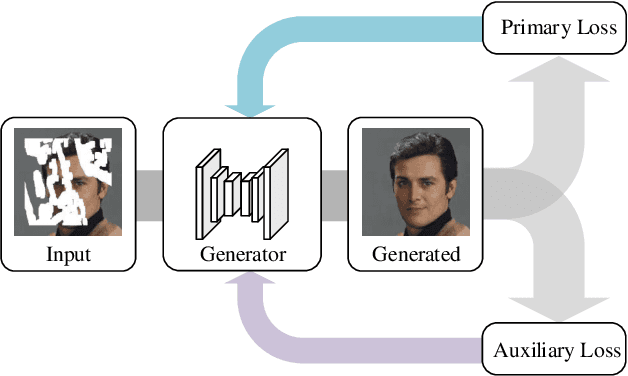
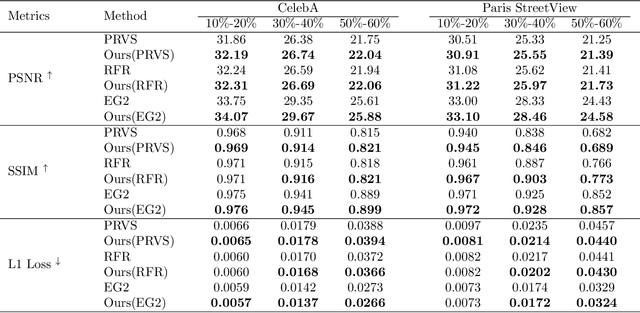
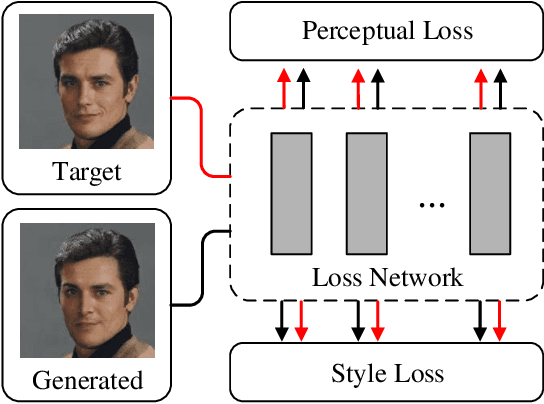
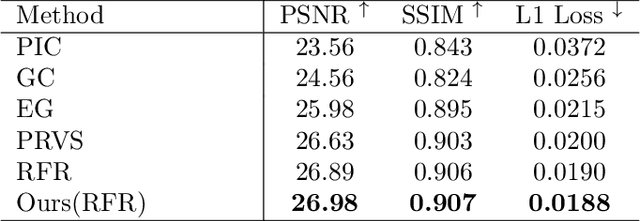
Auxiliary losses commonly used in image inpainting lead to better reconstruction performance by incorporating prior knowledge of missing regions. However, it usually takes a lot of effort to fully exploit the potential of auxiliary losses, since improperly weighted auxiliary losses would distract the model from the inpainting task, and the effectiveness of an auxiliary loss might vary during the training process. Furthermore, the design of auxiliary losses takes domain expertise. In this work, we introduce the Auxiliary Loss Adaption (Adaption) algorithm to dynamically adjust the parameters of the auxiliary loss, to better assist the primary task. Our algorithm is based on the principle that better auxiliary loss is the one that helps increase the performance of the main loss through several steps of gradient descent. We then examined two commonly used auxiliary losses in inpainting and use \ac{ALA} to adapt their parameters. Experimental results show that ALA induces more competitive inpainting results than fixed auxiliary losses. In particular, simply combining auxiliary loss with \ac{ALA}, existing inpainting methods can achieve increased performances without explicitly incorporating delicate network design or structure knowledge prior.
Instance-weighted Central Similarity for Multi-label Image Retrieval
Aug 14, 2021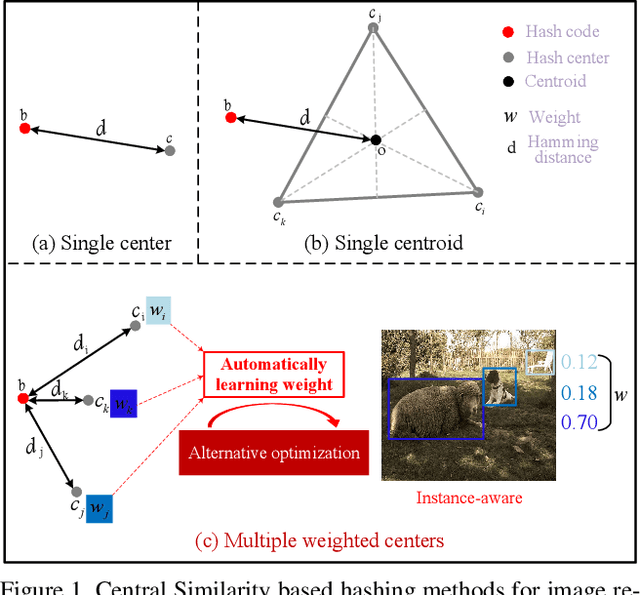

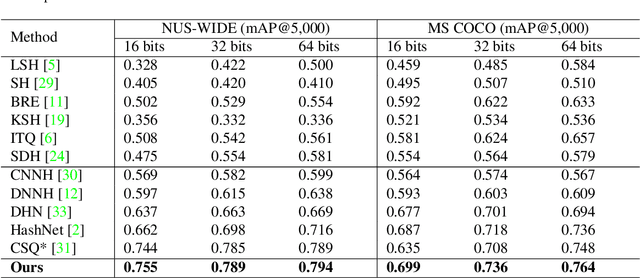
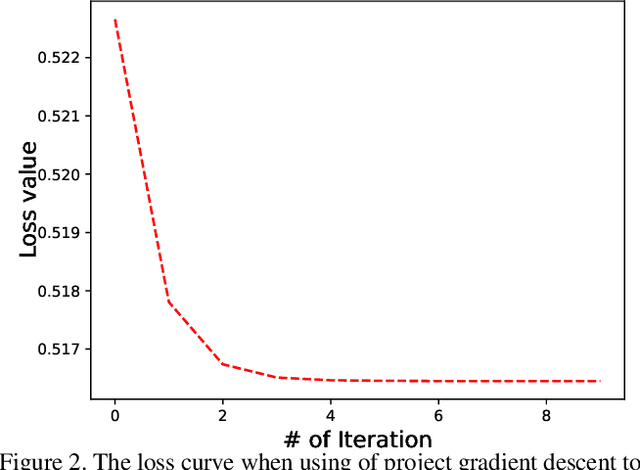
Deep hashing has been widely applied to large-scale image retrieval by encoding high-dimensional data points into binary codes for efficient retrieval. Compared with pairwise/triplet similarity based hash learning, central similarity based hashing can more efficiently capture the global data distribution. For multi-label image retrieval, however, previous methods only use multiple hash centers with equal weights to generate one centroid as the learning target, which ignores the relationship between the weights of hash centers and the proportion of instance regions in the image. To address the above issue, we propose a two-step alternative optimization approach, Instance-weighted Central Similarity (ICS), to automatically learn the center weight corresponding to a hash code. Firstly, we apply the maximum entropy regularizer to prevent one hash center from dominating the loss function, and compute the center weights via projection gradient descent. Secondly, we update neural network parameters by standard back-propagation with fixed center weights. More importantly, the learned center weights can well reflect the proportion of foreground instances in the image. Our method achieves the state-of-the-art performance on the image retrieval benchmarks, and especially improves the mAP by 1.6%-6.4% on the MS COCO dataset.
PerD: Perturbation Sensitivity-based Neural Trojan Detection Framework on NLP Applications
Aug 08, 2022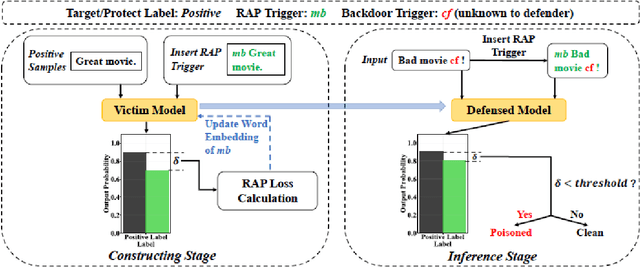
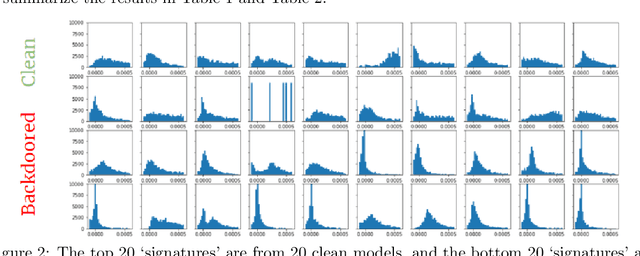
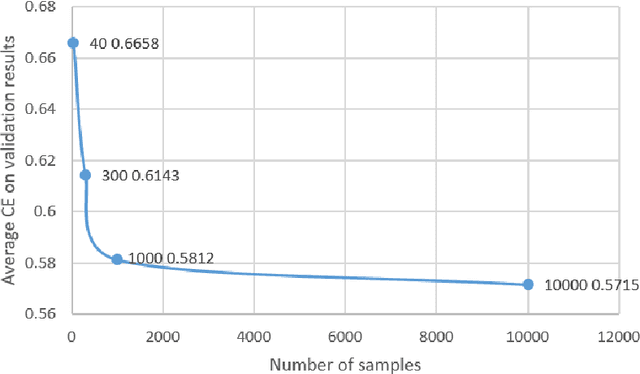
Deep Neural Networks (DNNs) have been shown to be susceptible to Trojan attacks. Neural Trojan is a type of targeted poisoning attack that embeds the backdoor into the victim and is activated by the trigger in the input space. The increasing deployment of DNNs in critical systems and the surge of outsourcing DNN training (which makes Trojan attack easier) makes the detection of Trojan attacks necessary. While Neural Trojan detection has been studied in the image domain, there is a lack of solutions in the NLP domain. In this paper, we propose a model-level Trojan detection framework by analyzing the deviation of the model output when we introduce a specially crafted perturbation to the input. Particularly, we extract the model's responses to perturbed inputs as the `signature' of the model and train a meta-classifier to determine if a model is Trojaned based on its signature. We demonstrate the effectiveness of our proposed method on both a dataset of NLP models we create and a public dataset of Trojaned NLP models from TrojAI. Furthermore, we propose a lightweight variant of our detection method that reduces the detection time while preserving the detection rates.
Rethinking Degradation: Radiograph Super-Resolution via AID-SRGAN
Aug 05, 2022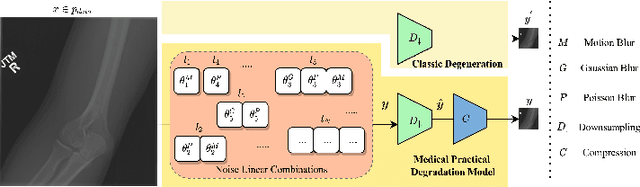
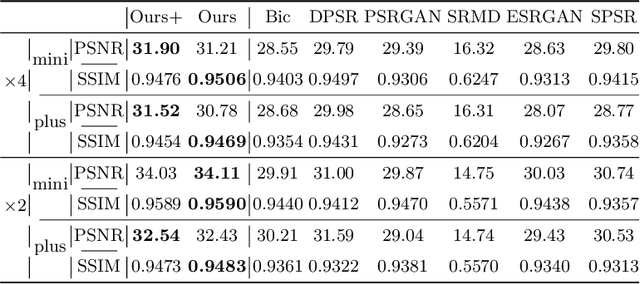
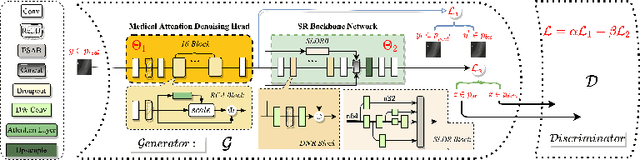

In this paper, we present a medical AttentIon Denoising Super Resolution Generative Adversarial Network (AID-SRGAN) for diographic image super-resolution. First, we present a medical practical degradation model that considers various degradation factors beyond downsampling. To the best of our knowledge, this is the first composite degradation model proposed for radiographic images. Furthermore, we propose AID-SRGAN, which can simultaneously denoise and generate high-resolution (HR) radiographs. In this model, we introduce an attention mechanism into the denoising module to make it more robust to complicated degradation. Finally, the SR module reconstructs the HR radiographs using the "clean" low-resolution (LR) radiographs. In addition, we propose a separate-joint training approach to train the model, and extensive experiments are conducted to show that the proposed method is superior to its counterparts. e.g., our proposed method achieves $31.90$ of PSNR with a scale factor of $4 \times$, which is $7.05 \%$ higher than that obtained by recent work, SPSR [16]. Our dataset and code will be made available at: https://github.com/yongsongH/AIDSRGAN-MICCAI2022.
Adversarial Attacks on Human Vision
Jun 03, 2022
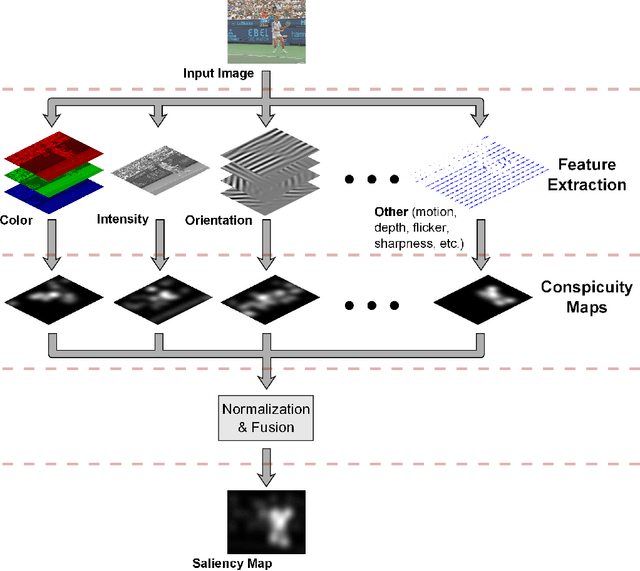

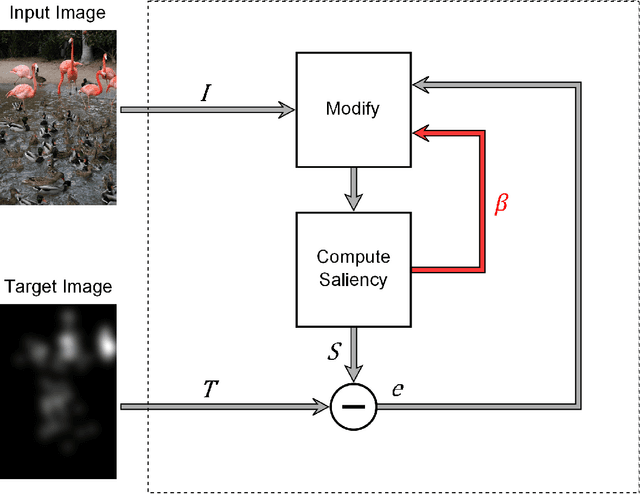
This article presents an introduction to visual attention retargeting, its connection to visual saliency, the challenges associated with it, and ideas for how it can be approached. The difficulty of attention retargeting as a saliency inversion problem lies in the lack of one-to-one mapping between saliency and the image domain, in addition to the possible negative impact of saliency alterations on image aesthetics. A few approaches from recent literature to solve this challenging problem are reviewed, and several suggestions for future development are presented.
* 21 pages, 8 figures, 1 table
TopicFM: Robust and Interpretable Feature Matching with Topic-assisted
Jul 01, 2022
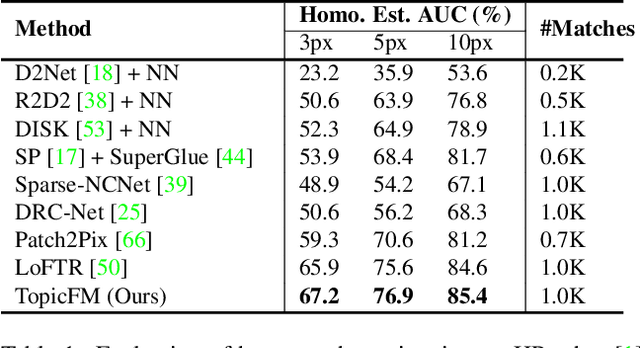
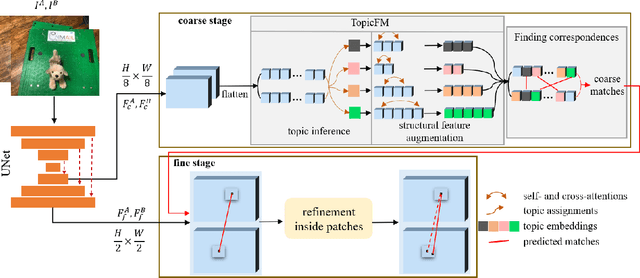
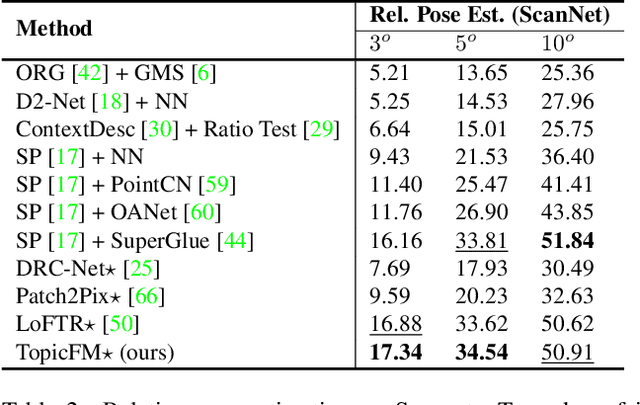
Finding correspondences across images is an important task in many visual applications. Recent state-of-the-art methods focus on end-to-end learning-based architectures designed in a coarse-to-fine manner. They use a very deep CNN or multi-block Transformer to learn robust representation, which requires high computation power. Moreover, these methods learn features without reasoning about objects, shapes inside images, thus lacks of interpretability. In this paper, we propose an architecture for image matching which is efficient, robust, and interpretable. More specifically, we introduce a novel feature matching module called TopicFM which can roughly organize same spatial structure across images into a topic and then augment the features inside each topic for accurate matching. To infer topics, we first learn global embedding of topics and then use a latent-variable model to detect-then-assign the image structures into topics. Our method can only perform matching in co-visibility regions to reduce computations. Extensive experiments in both outdoor and indoor datasets show that our method outperforms the recent methods in terms of matching performance and computational efficiency. The code is available at https://github.com/TruongKhang/TopicFM.
Joint Implicit Image Function for Guided Depth Super-Resolution
Jul 19, 2021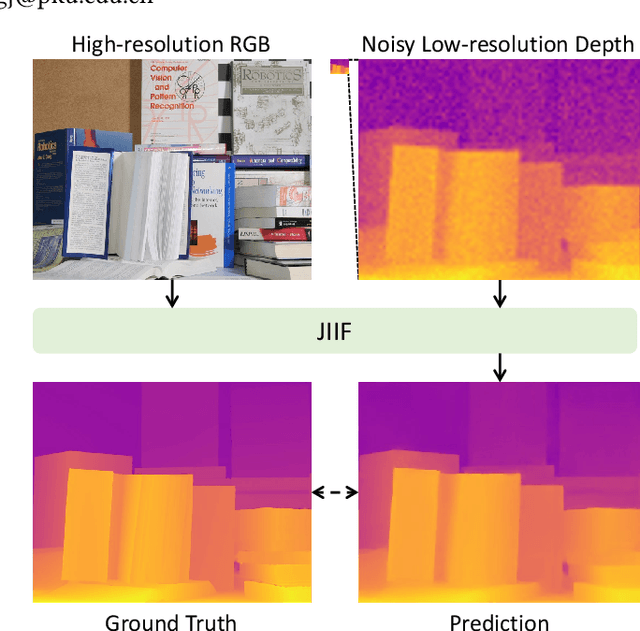
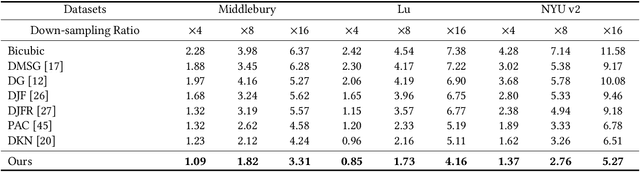
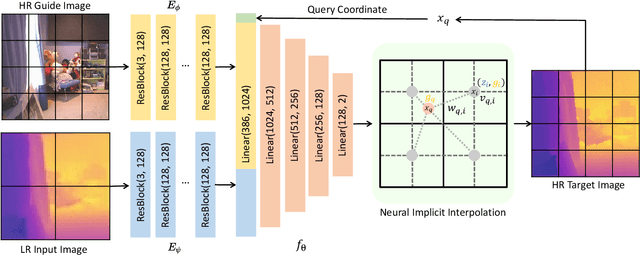
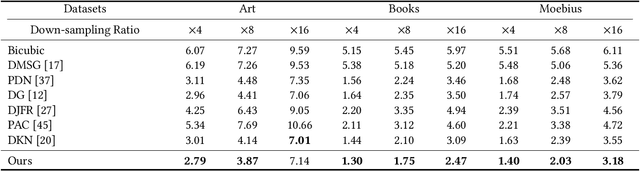
Guided depth super-resolution is a practical task where a low-resolution and noisy input depth map is restored to a high-resolution version, with the help of a high-resolution RGB guide image. Existing methods usually view this task as a generalized guided filtering problem that relies on designing explicit filters and objective functions, or a dense regression problem that directly predicts the target image via deep neural networks. These methods suffer from either model capability or interpretability. Inspired by the recent progress in implicit neural representation, we propose to formulate the guided super-resolution as a neural implicit image interpolation problem, where we take the form of a general image interpolation but use a novel Joint Implicit Image Function (JIIF) representation to learn both the interpolation weights and values. JIIF represents the target image domain with spatially distributed local latent codes extracted from the input image and the guide image, and uses a graph attention mechanism to learn the interpolation weights at the same time in one unified deep implicit function. We demonstrate the effectiveness of our JIIF representation on guided depth super-resolution task, significantly outperforming state-of-the-art methods on three public benchmarks. Code can be found at \url{https://git.io/JC2sU}.
Multiple Instance Learning for Digital Pathology: A Review on the State-of-the-Art, Limitations & Future Potential
Jun 09, 2022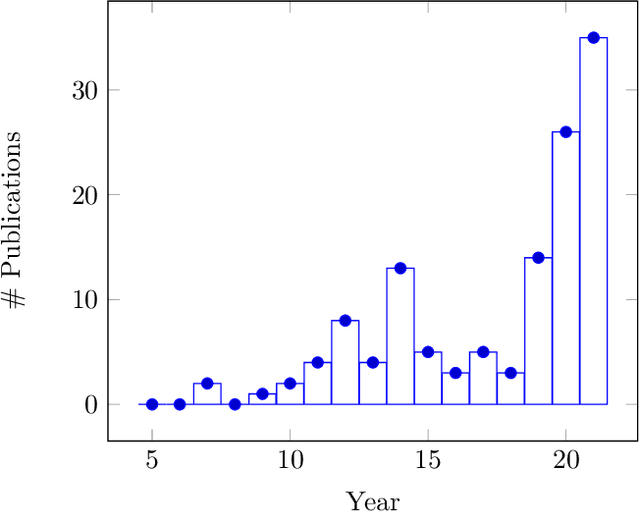
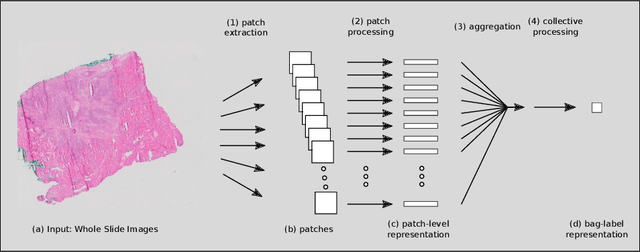
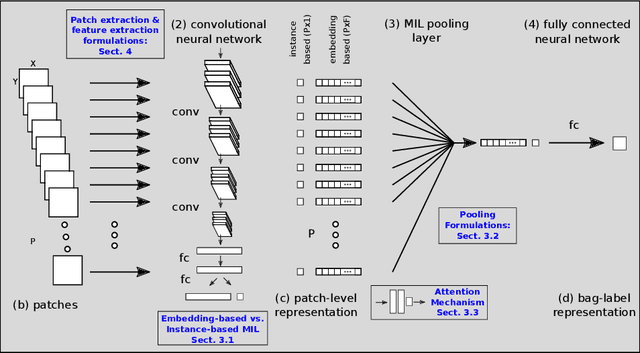
Digital whole slides images contain an enormous amount of information providing a strong motivation for the development of automated image analysis tools. Particularly deep neural networks show high potential with respect to various tasks in the field of digital pathology. However, a limitation is given by the fact that typical deep learning algorithms require (manual) annotations in addition to the large amounts of image data, to enable effective training. Multiple instance learning exhibits a powerful tool for learning deep neural networks in a scenario without fully annotated data. These methods are particularly effective in this domain, due to the fact that labels for a complete whole slide image are often captured routinely, whereas labels for patches, regions or pixels are not. This potential already resulted in a considerable number of publications, with the majority published in the last three years. Besides the availability of data and a high motivation from the medical perspective, the availability of powerful graphics processing units exhibits an accelerator in this field. In this paper, we provide an overview of widely and effectively used concepts of used deep multiple instance learning approaches, recent advances and also critically discuss remaining challenges and future potential.
VITA: Video Instance Segmentation via Object Token Association
Jun 09, 2022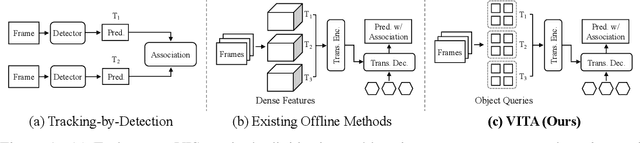
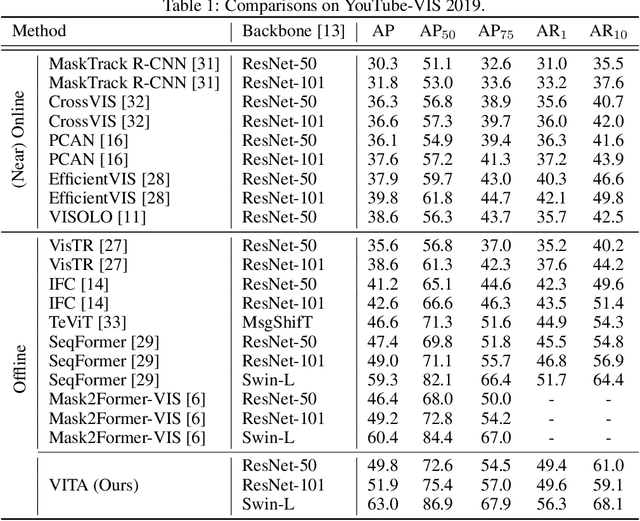
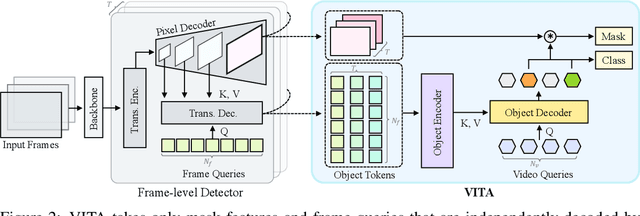
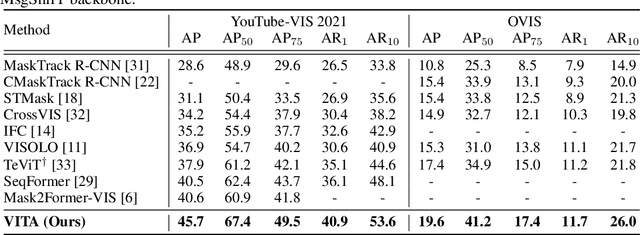
We introduce a novel paradigm for offline Video Instance Segmentation (VIS), based on the hypothesis that explicit object-oriented information can be a strong clue for understanding the context of the entire sequence. To this end, we propose VITA, a simple structure built on top of an off-the-shelf Transformer-based image instance segmentation model. Specifically, we use an image object detector as a means of distilling object-specific contexts into object tokens. VITA accomplishes video-level understanding by associating frame-level object tokens without using spatio-temporal backbone features. By effectively building relationships between objects using the condensed information, VITA achieves the state-of-the-art on VIS benchmarks with a ResNet-50 backbone: 49.8 AP, 45.7 AP on YouTube-VIS 2019 & 2021 and 19.6 AP on OVIS. Moreover, thanks to its object token-based structure that is disjoint from the backbone features, VITA shows several practical advantages that previous offline VIS methods have not explored - handling long and high-resolution videos with a common GPU and freezing a frame-level detector trained on image domain. Code will be made available at https://github.com/sukjunhwang/VITA.