 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visual Knowledge Tracing
Jul 22, 2022
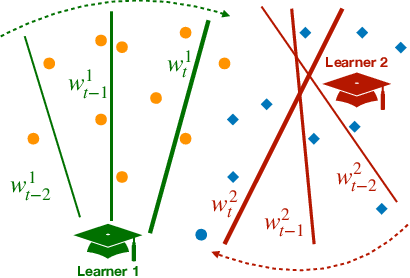
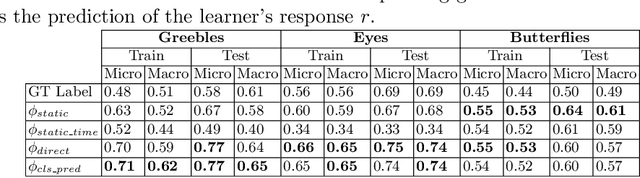
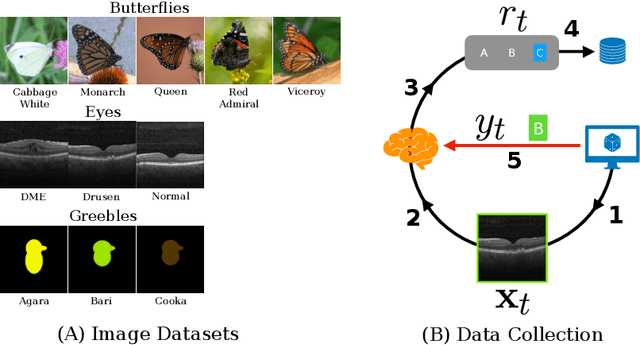
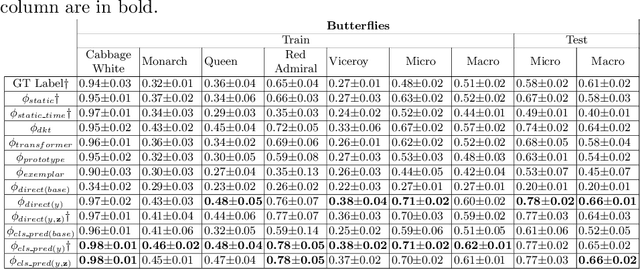
Each year, thousands of people learn new visual categorization tasks -- radiologists learn to recognize tumors, birdwatchers learn to distinguish similar species, and crowd workers learn how to annotate valuable data for applications like autonomous driving. As humans learn, their brain updates the visual features it extracts and attend to, which ultimately informs their final classification decisions. In this work, we propose a novel task of tracing the evolving classification behavior of human learners as they engage in challenging visual classification tasks. We propose models that jointly extract the visual features used by learners as well as predicting the classification functions they utilize. We collect three challenging new datasets from real human learners in order to evaluate the performance of different visual knowledge tracing methods. Our results show that our recurrent models are able to predict the classification behavior of human learners on three challenging medical image and species identification tasks.
A Generative Adversarial Framework for Optimizing Image Matting and Harmonization Simultaneously
Aug 13, 2021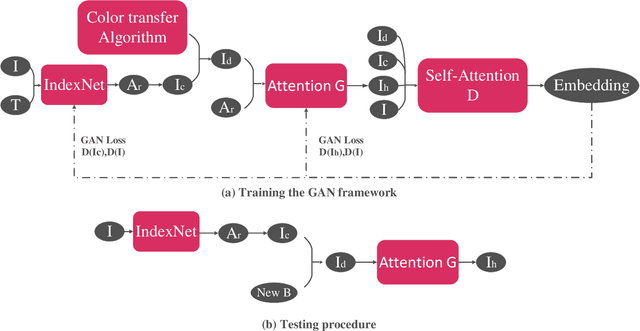
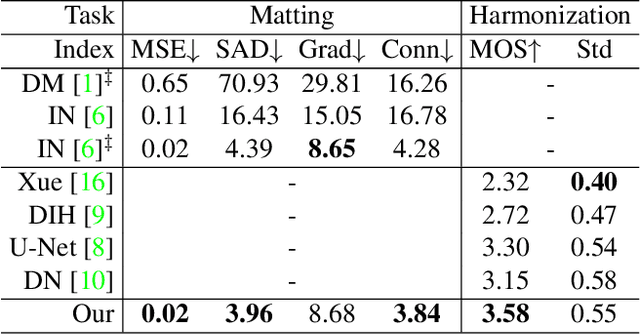
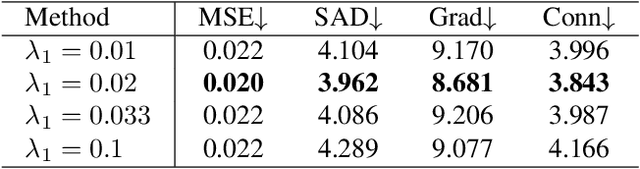
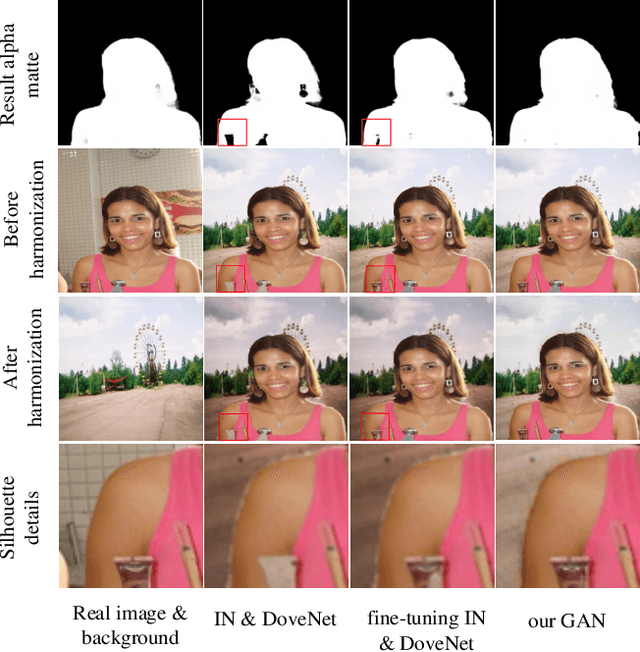
Image matting and image harmonization are two important tasks in image composition. Image matting, aiming to achieve foreground boundary details, and image harmonization, aiming to make the background compatible with the foreground, are both promising yet challenging tasks. Previous works consider optimizing these two tasks separately, which may lead to a sub-optimal solution. We propose to optimize matting and harmonization simultaneously to get better performance on both the two tasks and achieve more natural results. We propose a new Generative Adversarial (GAN) framework which optimizing the matting network and the harmonization network based on a self-attention discriminator. The discriminator is required to distinguish the natural images from different types of fake synthesis images. Extensive experiments on our constructed dataset demonstrate the effectiveness of our proposed method. Our dataset and dataset generating pipeline can be found in \url{https://git.io/HaMaGAN}
* Extension for accepted ICIP 2021
Online Video Super-Resolution with Convolutional Kernel Bypass Graft
Aug 04, 2022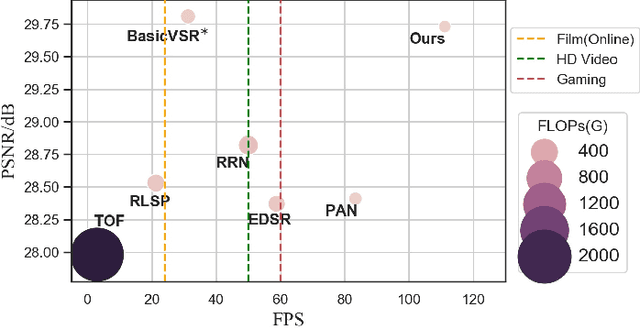

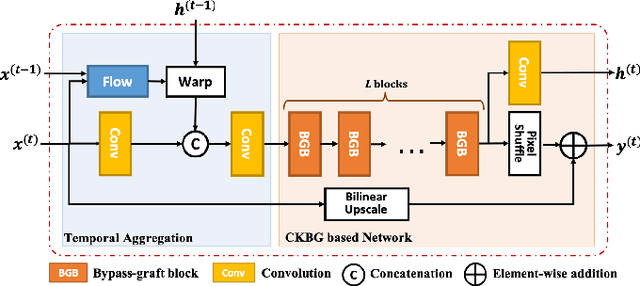
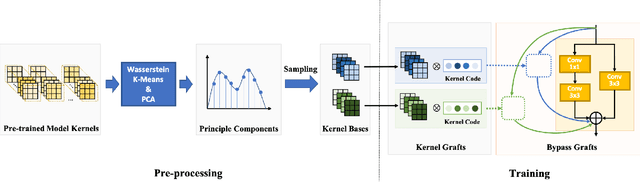
Deep learning-based models have achieved remarkable performance in video super-resolution (VSR) in recent years, but most of these models are less applicable to online video applications. These methods solely consider the distortion quality and ignore crucial requirements for online applications, e.g., low latency and low model complexity. In this paper, we focus on online video transmission, in which VSR algorithms are required to generate high-resolution video sequences frame by frame in real time. To address such challenges, we propose an extremely low-latency VSR algorithm based on a novel kernel knowledge transfer method, named convolutional kernel bypass graft (CKBG). First, we design a lightweight network structure that does not require future frames as inputs and saves extra time costs for caching these frames. Then, our proposed CKBG method enhances this lightweight base model by bypassing the original network with ``kernel grafts'', which are extra convolutional kernels containing the prior knowledge of external pretrained image SR models. In the testing phase, we further accelerate the grafted multi-branch network by converting it into a simple single-path structure. Experiment results show that our proposed method can process online video sequences up to 110 FPS, with very low model complexity and competitive SR performance.
It Isn't Sh!tposting, It's My CAT Posting
May 18, 2022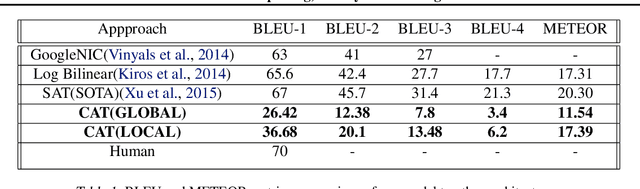


In this paper, we describe a novel architecture which can generate hilarious captions for a given input image. The architecture is split into two halves, i.e. image captioning and hilarious text conversion. The architecture starts with a pre-trained CNN model, VGG16 in this implementation, and applies attention LSTM on it to generate normal caption. These normal captions then are fed forward to our hilarious text conversion transformer which converts this text into something hilarious while maintaining the context of the input image. The architecture can also be split into two halves and only the seq2seq transformer can be used to generate hilarious caption by inputting a sentence.This paper aims to help everyday user to be more lazy and hilarious at the same time by generating captions using CATNet.
A Survey of Deep Fake Detection for Trial Courts
May 31, 2022
Recently, image manipulation has achieved rapid growth due to the advancement of sophisticated image editing tools. A recent surge of generated fake imagery and videos using neural networks is DeepFake. DeepFake algorithms can create fake images and videos that humans cannot distinguish from authentic ones. (GANs) have been extensively used for creating realistic images without accessing the original images. Therefore, it is become essential to detect fake videos to avoid spreading false information. This paper presents a survey of methods used to detect DeepFakes and datasets available for detecting DeepFakes in the literature to date. We present extensive discussions and research trends related to DeepFake technologies.
Is current research on adversarial robustness addressing the right problem?
Aug 04, 2022
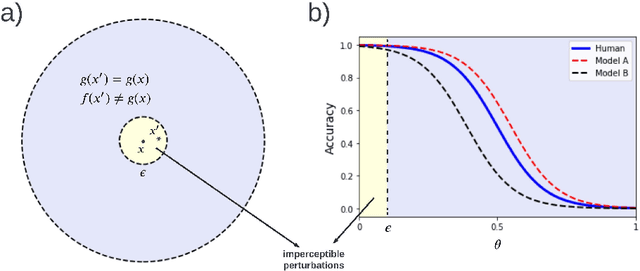
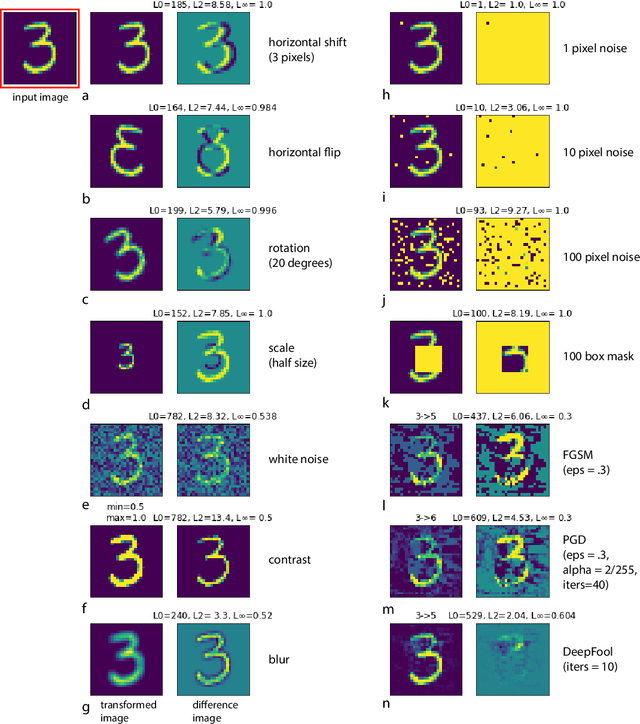
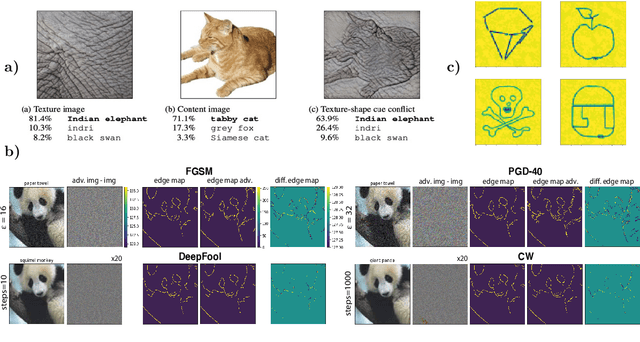
Short answer: Yes, Long answer: No! Indeed, research on adversarial robustness has led to invaluable insights helping us understand and explore different aspects of the problem. Many attacks and defenses have been proposed over the last couple of years. The problem, however, remains largely unsolved and poorly understood. Here, I argue that the current formulation of the problem serves short term goals, and needs to be revised for us to achieve bigger gains. Specifically, the bound on perturbation has created a somewhat contrived setting and needs to be relaxed. This has misled us to focus on model classes that are not expressive enough to begin with. Instead, inspired by human vision and the fact that we rely more on robust features such as shape, vertices, and foreground objects than non-robust features such as texture, efforts should be steered towards looking for significantly different classes of models. Maybe instead of narrowing down on imperceptible adversarial perturbations, we should attack a more general problem which is finding architectures that are simultaneously robust to perceptible perturbations, geometric transformations (e.g. rotation, scaling), image distortions (lighting, blur), and more (e.g. occlusion, shadow). Only then we may be able to solve the problem of adversarial vulnerability.
Revisiting the "Video" in Video-Language Understanding
Jun 03, 2022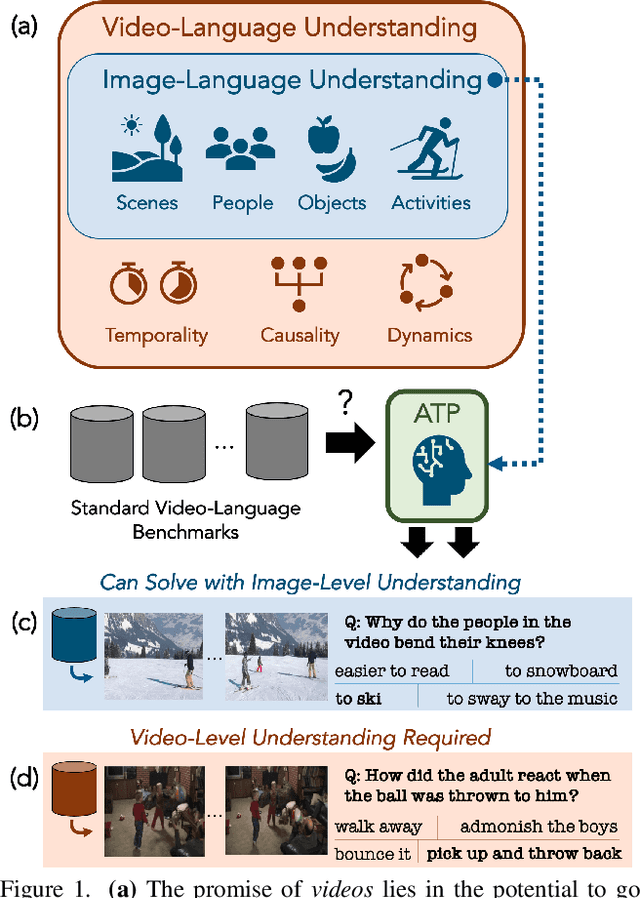


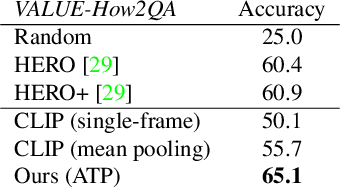
What makes a video task uniquely suited for videos, beyond what can be understood from a single image? Building on recent progress in self-supervised image-language models, we revisit this question in the context of video and language tasks. We propose the atemporal probe (ATP), a new model for video-language analysis which provides a stronger bound on the baseline accuracy of multimodal models constrained by image-level understanding. By applying this model to standard discriminative video and language tasks, such as video question answering and text-to-video retrieval, we characterize the limitations and potential of current video-language benchmarks. We find that understanding of event temporality is often not necessary to achieve strong or state-of-the-art performance, even compared with recent large-scale video-language models and in contexts intended to benchmark deeper video-level understanding. We also demonstrate how ATP can improve both video-language dataset and model design. We describe a technique for leveraging ATP to better disentangle dataset subsets with a higher concentration of temporally challenging data, improving benchmarking efficacy for causal and temporal understanding. Further, we show that effectively integrating ATP into full video-level temporal models can improve efficiency and state-of-the-art accuracy.
Synthetic Dataset Generation for Adversarial Machine Learning Research
Jul 21, 2022
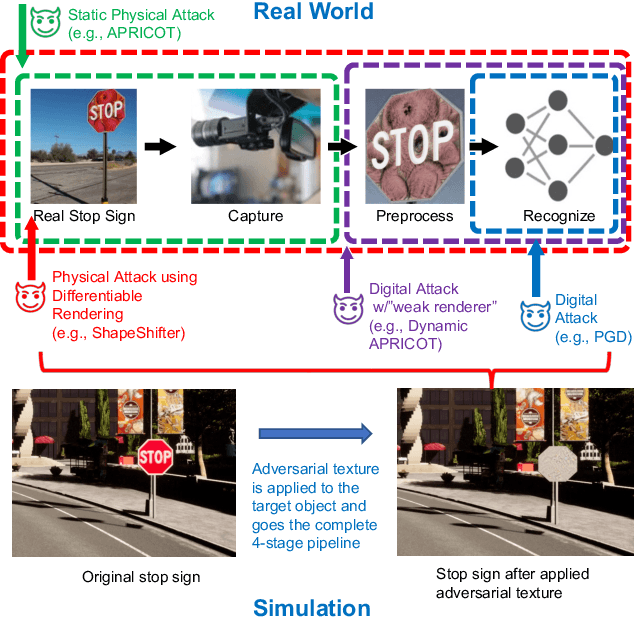


Existing adversarial example research focuses on digitally inserted perturbations on top of existing natural image datasets. This construction of adversarial examples is not realistic because it may be difficult, or even impossible, for an attacker to deploy such an attack in the real-world due to sensing and environmental effects. To better understand adversarial examples against cyber-physical systems, we propose approximating the real-world through simulation. In this paper we describe our synthetic dataset generation tool that enables scalable collection of such a synthetic dataset with realistic adversarial examples. We use the CARLA simulator to collect such a dataset and demonstrate simulated attacks that undergo the same environmental transforms and processing as real-world images. Our tools have been used to collect datasets to help evaluate the efficacy of adversarial examples, and can be found at https://github.com/carla-simulator/carla/pull/4992.
HyperSegNAS: Bridging One-Shot Neural Architecture Search with 3D Medical Image Segmentation using HyperNet
Dec 20, 2021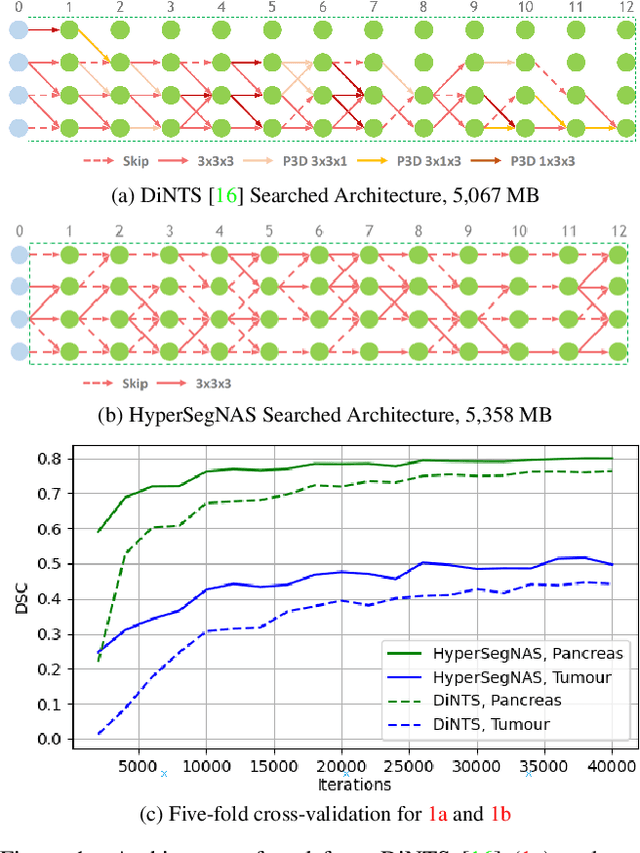
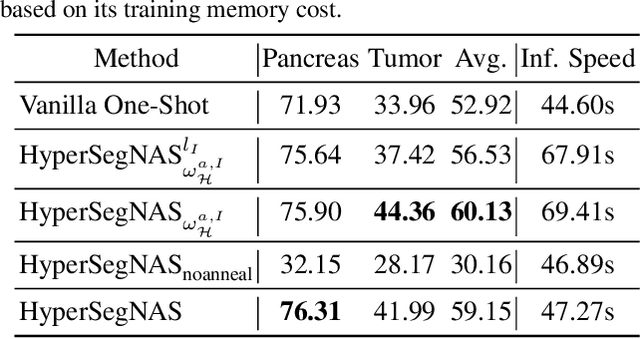
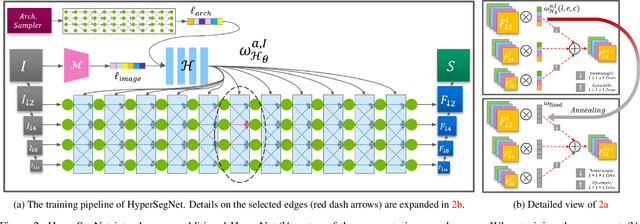
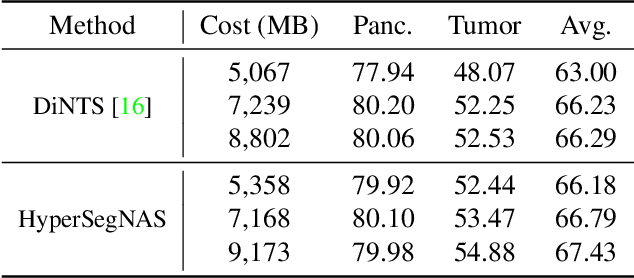
Semantic segmentation of 3D medical images is a challenging task due to the high variability of the shape and pattern of objects (such as organs or tumors). Given the recent success of deep learning in medical image segmentation, Neural Architecture Search (NAS) has been introduced to find high-performance 3D segmentation network architectures. However, because of the massive computational requirements of 3D data and the discrete optimization nature of architecture search, previous NAS methods require a long search time or necessary continuous relaxation, and commonly lead to sub-optimal network architectures. While one-shot NAS can potentially address these disadvantages, its application in the segmentation domain has not been well studied in the expansive multi-scale multi-path search space. To enable one-shot NAS for medical image segmentation, our method, named HyperSegNAS, introduces a HyperNet to assist super-net training by incorporating architecture topology information. Such a HyperNet can be removed once the super-net is trained and introduces no overhead during architecture search. We show that HyperSegNAS yields better performing and more intuitive architectures compared to the previous state-of-the-art (SOTA) segmentation networks; furthermore, it can quickly and accurately find good architecture candidates under different computing constraints. Our method is evaluated on public datasets from the Medical Segmentation Decathlon (MSD) challenge, and achieves SOTA performances.
AI-based computer-aided diagnostic system of chest digital tomography synthesis: Demonstrating comparative advantage with X-ray-based AI systems
Jun 18, 2022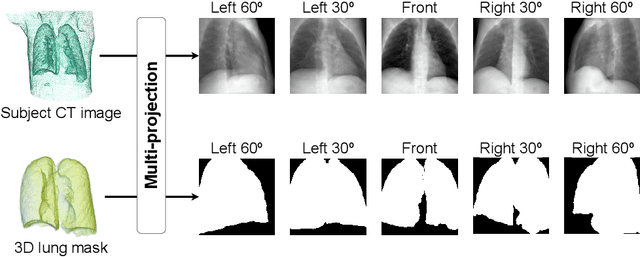
Compared with chest X-ray (CXR) imaging, which is a single image projected from the front of the patient, chest digital tomosynthesis (CDTS) imaging can be more advantageous for lung lesion detection because it acquires multiple images projected from multiple angles of the patient. Various clinical comparative analysis and verification studies have been reported to demonstrate this, but there were no artificial intelligence (AI)-based comparative analysis studies. Existing AI-based computer-aided detection (CAD) systems for lung lesion diagnosis have been developed mainly based on CXR images; however, CAD-based on CDTS, which uses multi-angle images of patients in various directions, has not been proposed and verified for its usefulness compared to CXR-based counterparts. This study develops/tests a CDTS-based AI CAD system to detect lung lesions to demonstrate performance improvements compared to CXR-based AI CAD. We used multiple projection images as input for the CDTS-based AI model and a single-projection image as input for the CXR-based AI model to fairly compare and evaluate the performance between models. The proposed CDTS-based AI CAD system yielded sensitivities of 0.782 and 0.785 and accuracies of 0.895 and 0.837 for the performance of detecting tuberculosis and pneumonia, respectively, against normal subjects. These results show higher performance than sensitivities of 0.728 and 0.698 and accuracies of 0.874 and 0.826 for detecting tuberculosis and pneumonia through the CXR-based AI CAD, which only uses a single projection image in the frontal direction. We found that CDTS-based AI CAD improved the sensitivity of tuberculosis and pneumonia by 5.4% and 8.7% respectively, compared to CXR-based AI CAD without loss of accuracy. Therefore, we comparatively prove that CDTS-based AI CAD technology can improve performance more than CXR, enhancing the clinical applicability of CDTS.