 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CKD-TransBTS: Clinical Knowledge-Driven Hybrid Transformer with Modality-Correlated Cross-Attention for Brain Tumor Segmentation
Jul 15, 2022
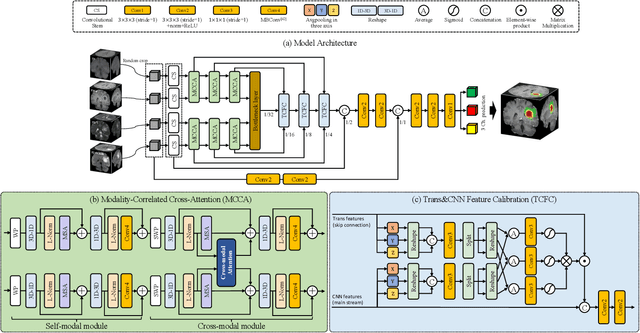
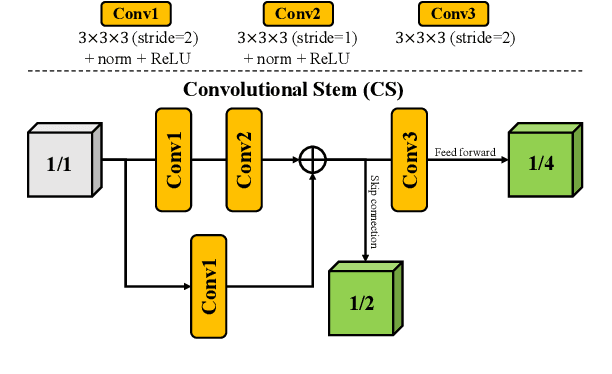
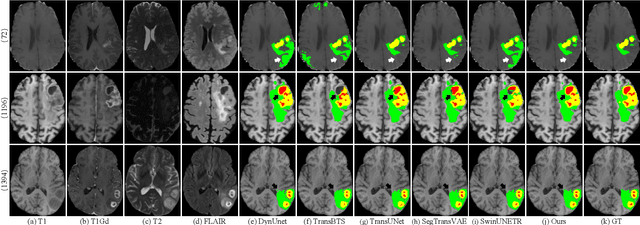
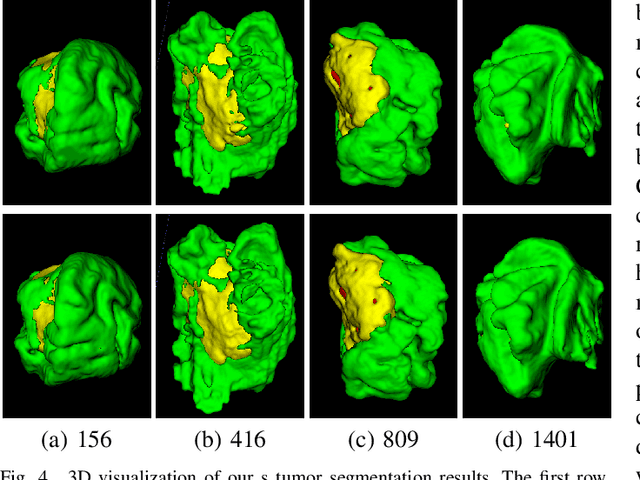
Brain tumor segmentation (BTS) in magnetic resonance image (MRI) is crucial for brain tumor diagnosis, cancer management and research purposes. With the great success of the ten-year BraTS challenges as well as the advances of CNN and Transformer algorithms, a lot of outstanding BTS models have been proposed to tackle the difficulties of BTS in different technical aspects. However, existing studies hardly consider how to fuse the multi-modality images in a reasonable manner. In this paper, we leverage the clinical knowledge of how radiologists diagnose brain tumors from multiple MRI modalities and propose a clinical knowledge-driven brain tumor segmentation model, called CKD-TransBTS. Instead of directly concatenating all the modalities, we re-organize the input modalities by separating them into two groups according to the imaging principle of MRI. A dual-branch hybrid encoder with the proposed modality-correlated cross-attention block (MCCA) is designed to extract the multi-modality image features. The proposed model inherits the strengths from both Transformer and CNN with the local feature representation ability for precise lesion boundaries and long-range feature extraction for 3D volumetric images. To bridge the gap between Transformer and CNN features, we propose a Trans&CNN Feature Calibration block (TCFC) in the decoder. We compare the proposed model with five CNN-based models and six transformer-based models on the BraTS 2021 challenge dataset. Extensive experiments demonstrate that the proposed model achieves state-of-the-art brain tumor segmentation performance compared with all the competitors.
AFTer-UNet: Axial Fusion Transformer UNet for Medical Image Segmentation
Oct 20, 2021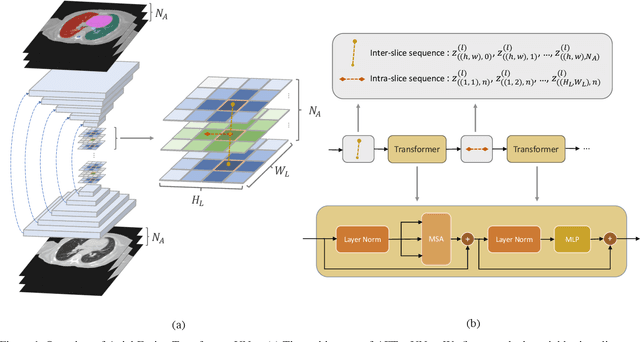
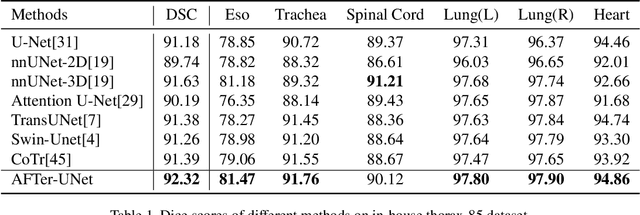

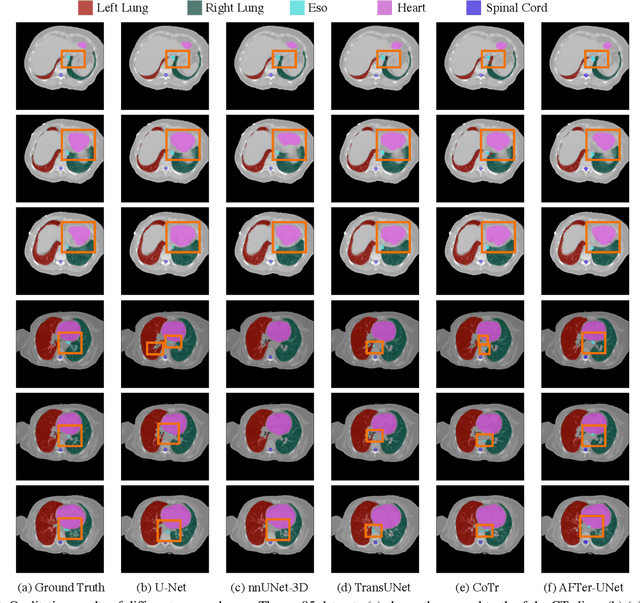
Recent advances in transformer-based models have drawn attention to exploring these techniques in medical image segmentation, especially in conjunction with the U-Net model (or its variants), which has shown great success in medical image segmentation, under both 2D and 3D settings. Current 2D based methods either directly replace convolutional layers with pure transformers or consider a transformer as an additional intermediate encoder between the encoder and decoder of U-Net. However, these approaches only consider the attention encoding within one single slice and do not utilize the axial-axis information naturally provided by a 3D volume. In the 3D setting, convolution on volumetric data and transformers both consume large GPU memory. One has to either downsample the image or use cropped local patches to reduce GPU memory usage, which limits its performance. In this paper, we propose Axial Fusion Transformer UNet (AFTer-UNet), which takes both advantages of convolutional layers' capability of extracting detailed features and transformers' strength on long sequence modeling. It considers both intra-slice and inter-slice long-range cues to guide the segmentation. Meanwhile, it has fewer parameters and takes less GPU memory to train than the previous transformer-based models. Extensive experiments on three multi-organ segmentation datasets demonstrate that our method outperforms current state-of-the-art methods.
Predict, Prevent, and Evaluate: Disentangled Text-Driven Image Manipulation Empowered by Pre-Trained Vision-Language Model
Nov 26, 2021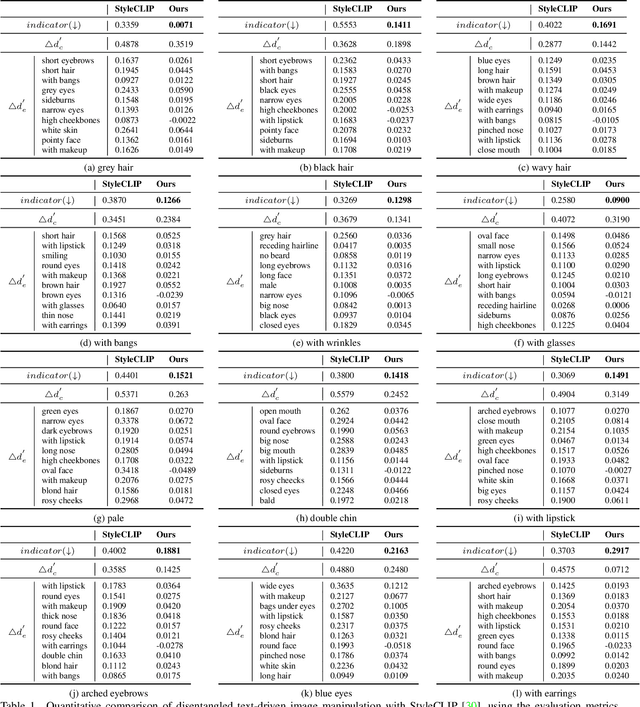
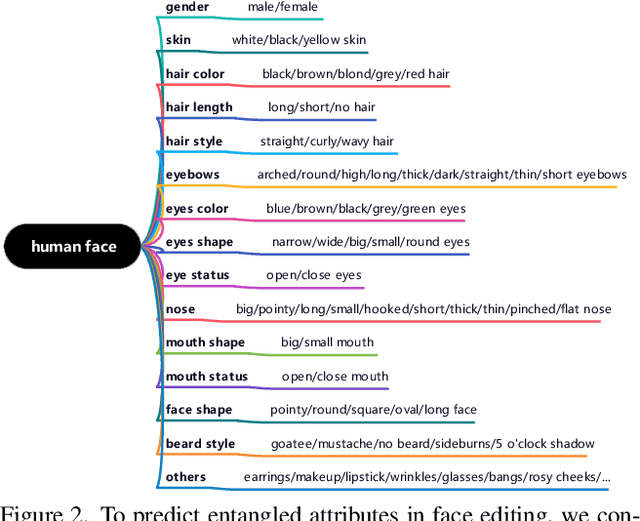
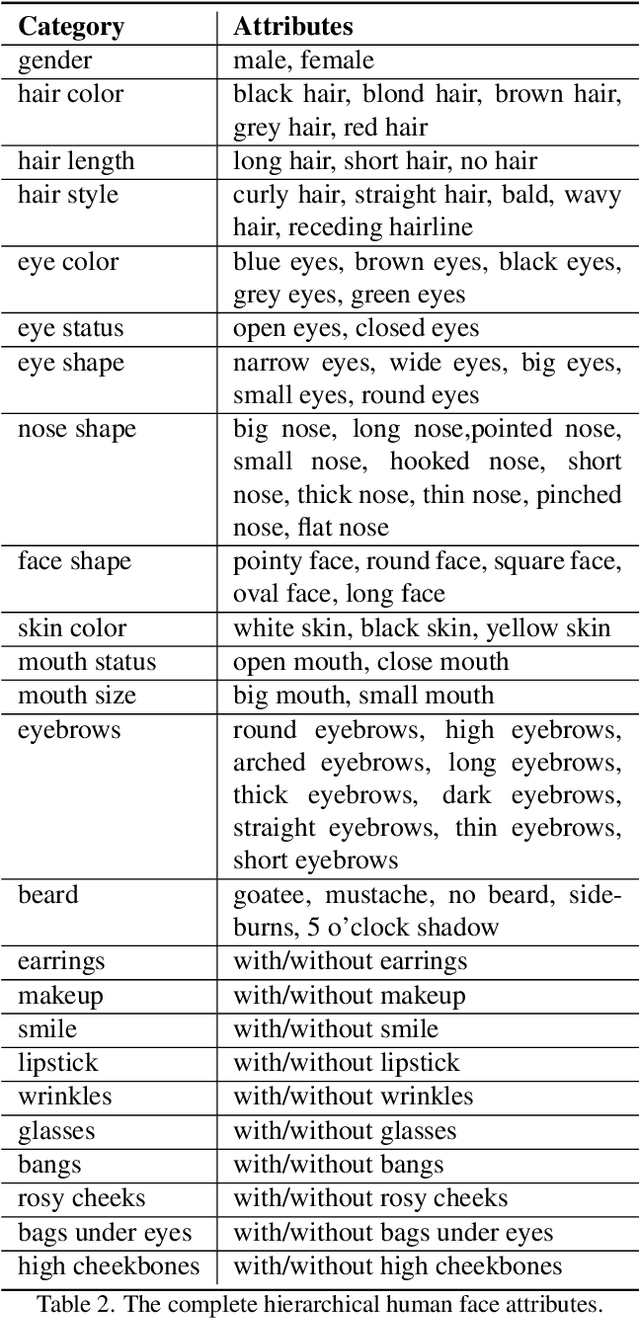

To achieve disentangled image manipulation, previous works depend heavily on manual annotation. Meanwhile, the available manipulations are limited to a pre-defined set the models were trained for. In this paper, we propose a novel framework, i.e., Predict, Prevent, and Evaluate (PPE), for disentangled text-driven image manipulation, which does not need manual annotation and thus is not limited to fixed manipulations. Our method approaches the targets by deeply exploiting the power of the large scale pre-trained vision-language model CLIP. Concretely, we firstly Predict the possibly entangled attributes for a given text command. Then, based on the predicted attributes, we introduce an entanglement loss to Prevent entanglements during training. Finally, we propose a new evaluation metric to Evaluate the disentangled image manipulation. We verify the effectiveness of our method on the challenging face editing task. Extensive experiments show that the proposed PPE framework achieves much better quantitative and qualitative results than the up-to-date StyleCLIP baseline.
Unsupervised Spike Depth Estimation via Cross-modality Cross-domain Knowledge Transfer
Aug 26, 2022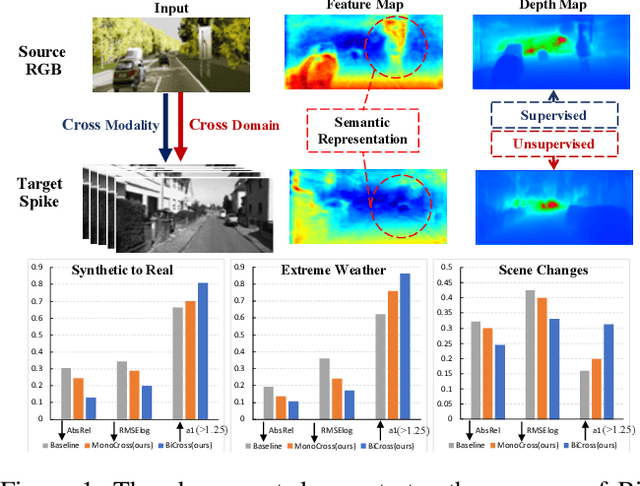

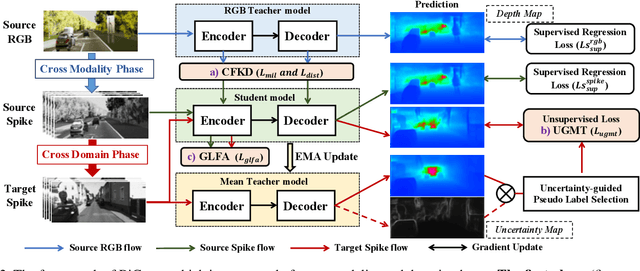
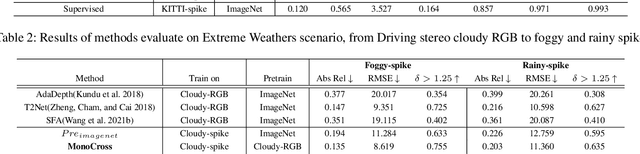
The neuromorphic spike camera generates data streams with high temporal resolution in a bio-inspired way, which has vast potential in the real-world applications such as autonomous driving. In contrast to RGB streams, spike streams have an inherent advantage to overcome motion blur, leading to more accurate depth estimation for high-velocity objects. However, training the spike depth estimation network in a supervised manner is almost impossible since it is extremely laborious and challenging to obtain paired depth labels for temporally intensive spike streams. In this paper, instead of building a spike stream dataset with full depth labels, we transfer knowledge from the open-source RGB datasets (e.g., KITTI) and estimate spike depth in an unsupervised manner. The key challenges for such problem lie in the modality gap between RGB and spike modalities, and the domain gap between labeled source RGB and unlabeled target spike domains. To overcome these challenges, we introduce a cross-modality cross-domain (BiCross) framework for unsupervised spike depth estimation. Our method narrows the enormous gap between source RGB and target spike by introducing the mediate simulated source spike domain. To be specific, for the cross-modality phase, we propose a novel Coarse-to-Fine Knowledge Distillation (CFKD), which transfers the image and pixel level knowledge from source RGB to source spike. Such design leverages the abundant semantic and dense temporal information of RGB and spike modalities respectively. For the cross-domain phase, we introduce the Uncertainty Guided Mean-Teacher (UGMT) to generate reliable pseudo labels with uncertainty estimation, alleviating the shift between the source spike and target spike domains. Besides, we propose a Global-Level Feature Alignment method (GLFA) to align the feature between two domains and generate more reliable pseudo labels.
Combining Variational Modeling with Partial Gradient Perturbation to Prevent Deep Gradient Leakage
Aug 09, 2022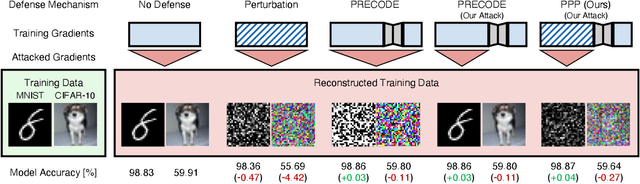
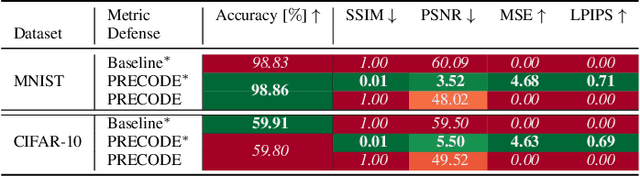
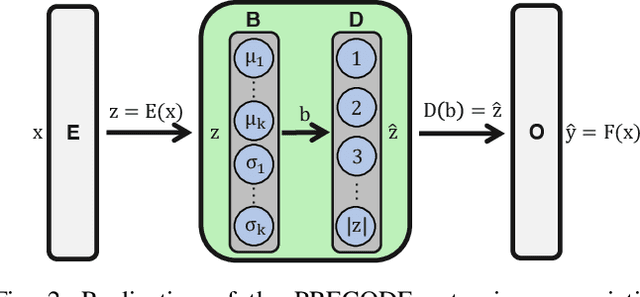
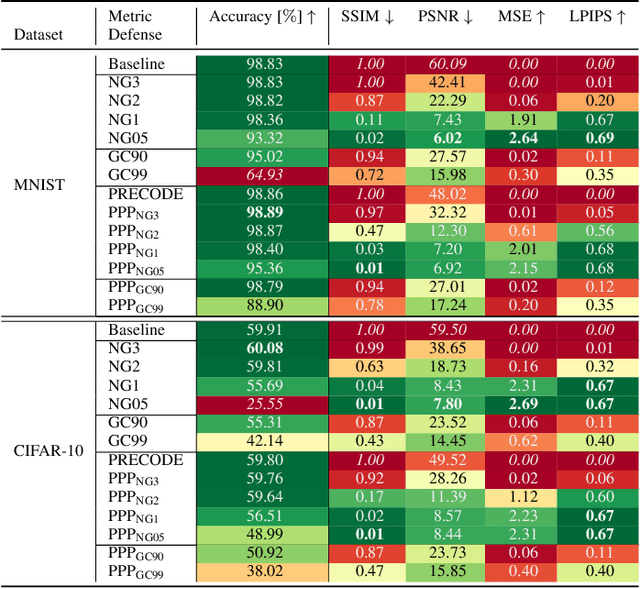
Exploiting gradient leakage to reconstruct supposedly private training data, gradient inversion attacks are an ubiquitous threat in collaborative learning of neural networks. To prevent gradient leakage without suffering from severe loss in model performance, recent work proposed a PRivacy EnhanCing mODulE (PRECODE) based on variational modeling as extension for arbitrary model architectures. In this work, we investigate the effect of PRECODE on gradient inversion attacks to reveal its underlying working principle. We show that variational modeling induces stochasticity on PRECODE's and its subsequent layers' gradients that prevents gradient attacks from convergence. By purposefully omitting those stochastic gradients during attack optimization, we formulate an attack that can disable PRECODE's privacy preserving effects. To ensure privacy preservation against such targeted attacks, we propose PRECODE with Partial Perturbation (PPP), as strategic combination of variational modeling and partial gradient perturbation. We conduct an extensive empirical study on four seminal model architectures and two image classification datasets. We find all architectures to be prone to gradient leakage, which can be prevented by PPP. In result, we show that our approach requires less gradient perturbation to effectively preserve privacy without harming model performance.
Efficient Spatial-Temporal Information Fusion for LiDAR-Based 3D Moving Object Segmentation
Jul 05, 2022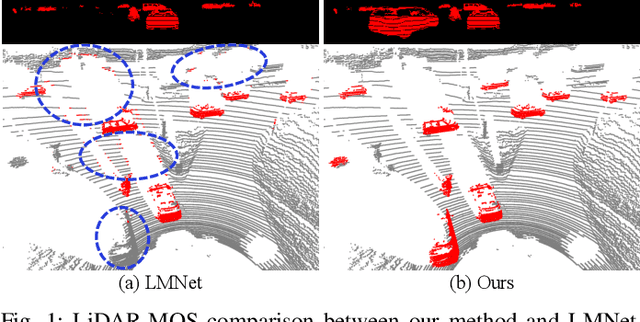
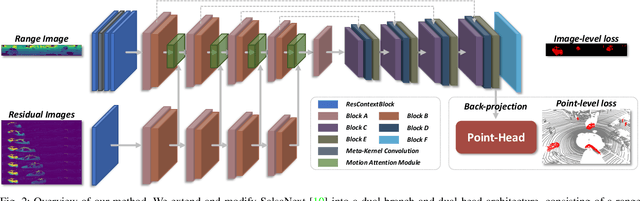
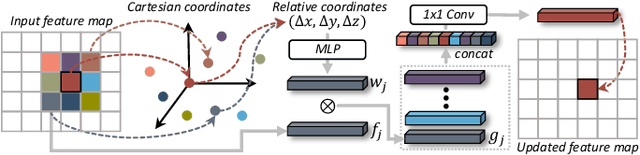
Accurate moving object segmentation is an essential task for autonomous driving. It can provide effective information for many downstream tasks, such as collision avoidance, path planning, and static map construction. How to effectively exploit the spatial-temporal information is a critical question for 3D LiDAR moving object segmentation (LiDAR-MOS). In this work, we propose a novel deep neural network exploiting both spatial-temporal information and different representation modalities of LiDAR scans to improve LiDAR-MOS performance. Specifically, we first use a range image-based dual-branch structure to separately deal with spatial and temporal information that can be obtained from sequential LiDAR scans, and later combine them using motion-guided attention modules. We also use a point refinement module via 3D sparse convolution to fuse the information from both LiDAR range image and point cloud representations and reduce the artifacts on the borders of the objects. We verify the effectiveness of our proposed approach on the LiDAR-MOS benchmark of SemanticKITTI. Our method outperforms the state-of-the-art methods significantly in terms of LiDAR-MOS IoU. Benefiting from the devised coarse-to-fine architecture, our method operates online at sensor frame rate. The implementation of our method is available as open source at: https://github.com/haomo-ai/MotionSeg3D.
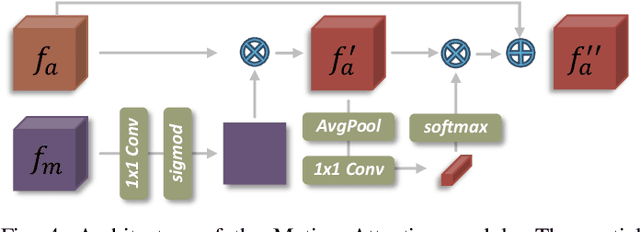
Robust and Decomposable Average Precision for Image Retrieval
Oct 01, 2021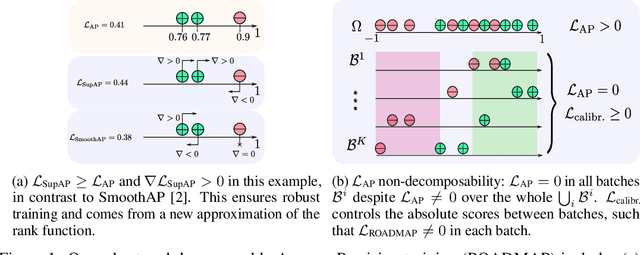
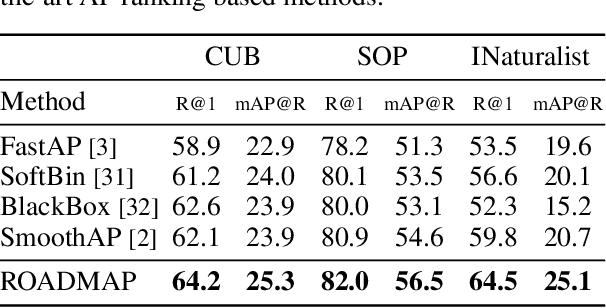
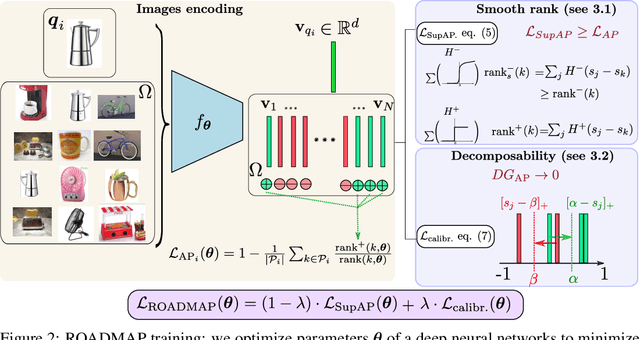
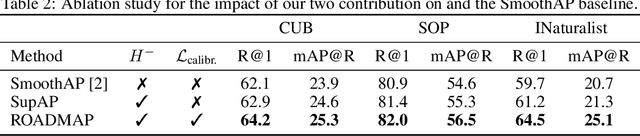
In image retrieval, standard evaluation metrics rely on score ranking, e.g. average precision (AP). In this paper, we introduce a method for robust and decomposable average precision (ROADMAP) addressing two major challenges for end-to-end training of deep neural networks with AP: non-differentiability and non-decomposability. Firstly, we propose a new differentiable approximation of the rank function, which provides an upper bound of the AP loss and ensures robust training. Secondly, we design a simple yet effective loss function to reduce the decomposability gap between the AP in the whole training set and its averaged batch approximation, for which we provide theoretical guarantees. Extensive experiments conducted on three image retrieval datasets show that ROADMAP outperforms several recent AP approximation methods and highlight the importance of our two contributions. Finally, using ROADMAP for training deep models yields very good performances, outperforming state-of-the-art results on the three datasets.
Attribute-specific Control Units in StyleGAN for Fine-grained Image Manipulation
Nov 25, 2021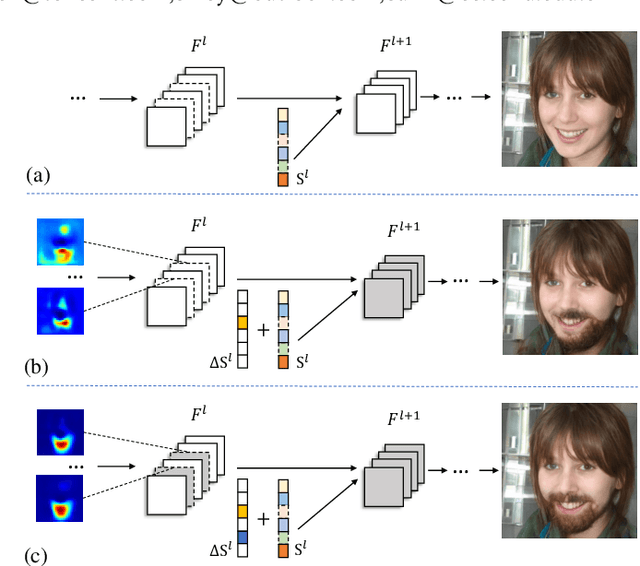



Image manipulation with StyleGAN has been an increasing concern in recent years.Recent works have achieved tremendous success in analyzing several semantic latent spaces to edit the attributes of the generated images.However, due to the limited semantic and spatial manipulation precision in these latent spaces, the existing endeavors are defeated in fine-grained StyleGAN image manipulation, i.e., local attribute translation.To address this issue, we discover attribute-specific control units, which consist of multiple channels of feature maps and modulation styles. Specifically, we collaboratively manipulate the modulation style channels and feature maps in control units rather than individual ones to obtain the semantic and spatial disentangled controls. Furthermore, we propose a simple yet effective method to detect the attribute-specific control units. We move the modulation style along a specific sparse direction vector and replace the filter-wise styles used to compute the feature maps to manipulate these control units. We evaluate our proposed method in various face attribute manipulation tasks. Extensive qualitative and quantitative results demonstrate that our proposed method performs favorably against the state-of-the-art methods. The manipulation results of real images further show the effectiveness of our method.
Virtual Correspondence: Humans as a Cue for Extreme-View Geometry
Jun 16, 2022



Recovering the spatial layout of the cameras and the geometry of the scene from extreme-view images is a longstanding challenge in computer vision. Prevailing 3D reconstruction algorithms often adopt the image matching paradigm and presume that a portion of the scene is co-visible across images, yielding poor performance when there is little overlap among inputs. In contrast, humans can associate visible parts in one image to the corresponding invisible components in another image via prior knowledge of the shapes. Inspired by this fact, we present a novel concept called virtual correspondences (VCs). VCs are a pair of pixels from two images whose camera rays intersect in 3D. Similar to classic correspondences, VCs conform with epipolar geometry; unlike classic correspondences, VCs do not need to be co-visible across views. Therefore VCs can be established and exploited even if images do not overlap. We introduce a method to find virtual correspondences based on humans in the scene. We showcase how VCs can be seamlessly integrated with classic bundle adjustment to recover camera poses across extreme views. Experiments show that our method significantly outperforms state-of-the-art camera pose estimation methods in challenging scenarios and is comparable in the traditional densely captured setup. Our approach also unleashes the potential of multiple downstream tasks such as scene reconstruction from multi-view stereo and novel view synthesis in extreme-view scenarios.
Improving Semantic Segmentation in Transformers using Hierarchical Inter-Level Attention
Jul 05, 2022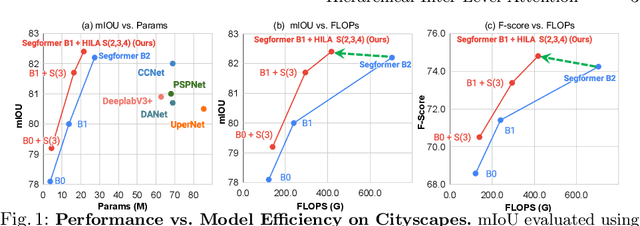
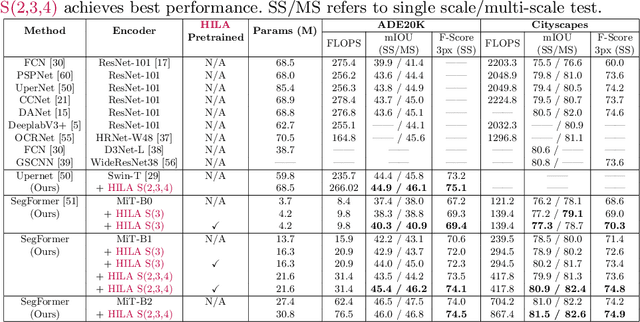
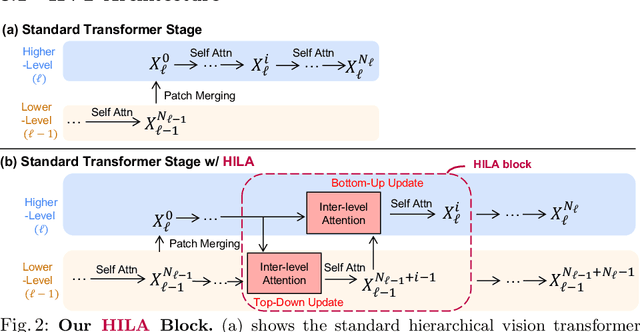
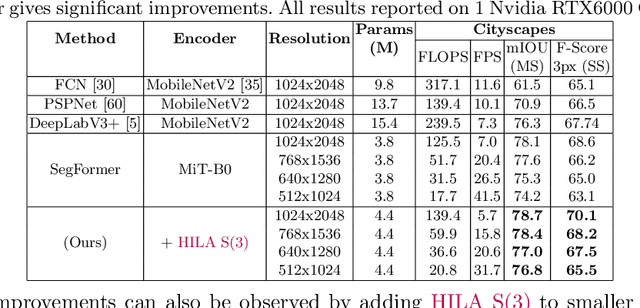
Existing transformer-based image backbones typically propagate feature information in one direction from lower to higher-levels. This may not be ideal since the localization ability to delineate accurate object boundaries, is most prominent in the lower, high-resolution feature maps, while the semantics that can disambiguate image signals belonging to one object vs. another, typically emerges in a higher level of processing. We present Hierarchical Inter-Level Attention (HILA), an attention-based method that captures Bottom-Up and Top-Down Updates between features of different levels. HILA extends hierarchical vision transformer architectures by adding local connections between features of higher and lower levels to the backbone encoder. In each iteration, we construct a hierarchy by having higher-level features compete for assignments to update lower-level features belonging to them, iteratively resolving object-part relationships. These improved lower-level features are then used to re-update the higher-level features. HILA can be integrated into the majority of hierarchical architectures without requiring any changes to the base model. We add HILA into SegFormer and the Swin Transformer and show notable improvements in accuracy in semantic segmentation with fewer parameters and FLOPS. Project website and code: https://www.cs.toronto.edu/~garyleung/hila/