 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Federated Learning Method for Preserving Privacy in Face Recognition System
Mar 08, 2024
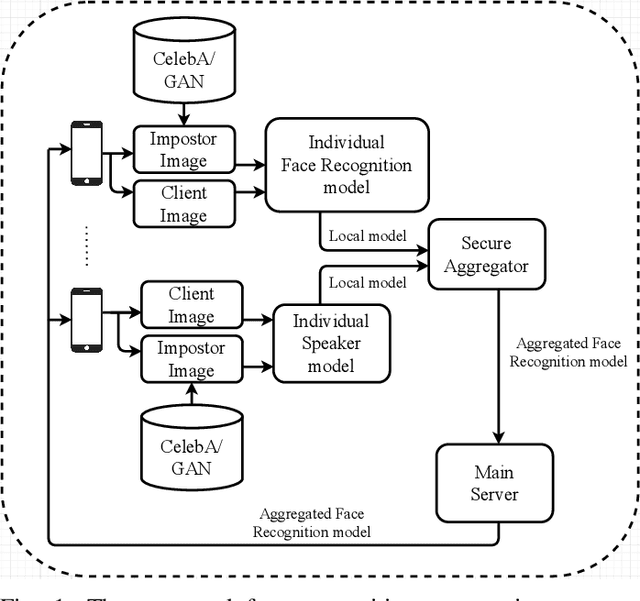
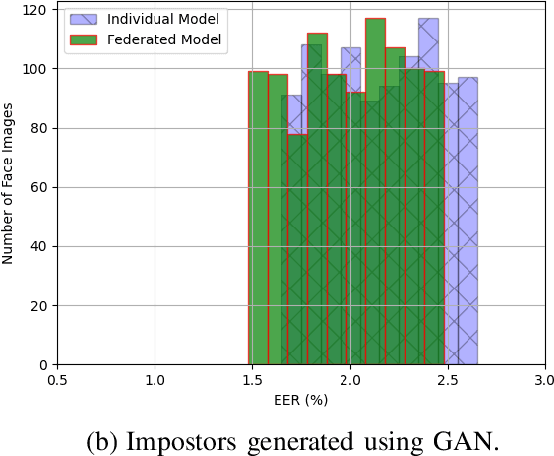
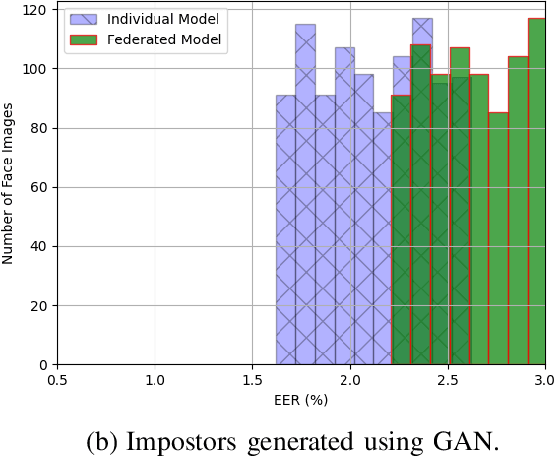
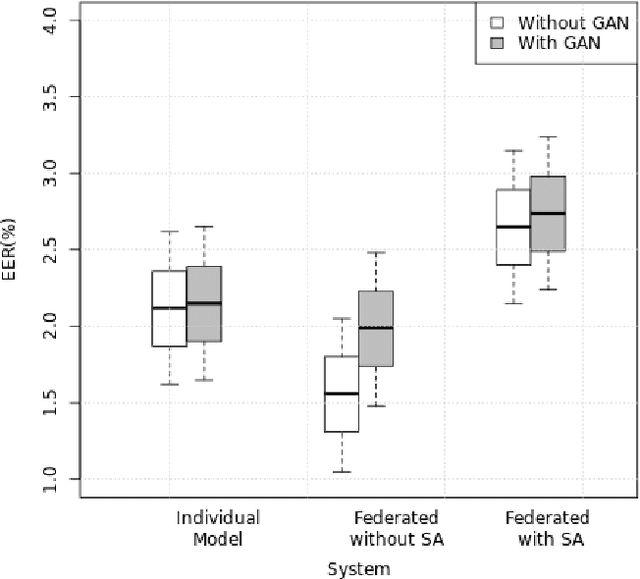
The state-of-the-art face recognition systems are typically trained on a single computer, utilizing extensive image datasets collected from various number of users. However, these datasets often contain sensitive personal information that users may hesitate to disclose. To address potential privacy concerns, we explore the application of federated learning, both with and without secure aggregators, in the context of both supervised and unsupervised face recognition systems. Federated learning facilitates the training of a shared model without necessitating the sharing of individual private data, achieving this by training models on decentralized edge devices housing the data. In our proposed system, each edge device independently trains its own model, which is subsequently transmitted either to a secure aggregator or directly to the central server. To introduce diverse data without the need for data transmission, we employ generative adversarial networks to generate imposter data at the edge. Following this, the secure aggregator or central server combines these individual models to construct a global model, which is then relayed back to the edge devices. Experimental findings based on the CelebA datasets reveal that employing federated learning in both supervised and unsupervised face recognition systems offers dual benefits. Firstly, it safeguards privacy since the original data remains on the edge devices. Secondly, the experimental results demonstrate that the aggregated model yields nearly identical performance compared to the individual models, particularly when the federated model does not utilize a secure aggregator. Hence, our results shed light on the practical challenges associated with privacy-preserving face image training, particularly in terms of the balance between privacy and accuracy.
Direct Consistency Optimization for Compositional Text-to-Image Personalization
Feb 19, 2024Text-to-image (T2I) diffusion models, when fine-tuned on a few personal images, are able to generate visuals with a high degree of consistency. However, they still lack in synthesizing images of different scenarios or styles that are possible in the original pretrained models. To address this, we propose to fine-tune the T2I model by maximizing consistency to reference images, while penalizing the deviation from the pretrained model. We devise a novel training objective for T2I diffusion models that minimally fine-tunes the pretrained model to achieve consistency. Our method, dubbed \emph{Direct Consistency Optimization}, is as simple as regular diffusion loss, while significantly enhancing the compositionality of personalized T2I models. Also, our approach induces a new sampling method that controls the tradeoff between image fidelity and prompt fidelity. Lastly, we emphasize the necessity of using a comprehensive caption for reference images to further enhance the image-text alignment. We show the efficacy of the proposed method on the T2I personalization for subject, style, or both. In particular, our method results in a superior Pareto frontier to the baselines. Generated examples and codes are in our project page( https://dco-t2i.github.io/).
A unified framework of non-local parametric methods for image denoising
Feb 21, 2024We propose a unified view of non-local methods for single-image denoising, for which BM3D is the most popular representative, that operate by gathering noisy patches together according to their similarities in order to process them collaboratively. Our general estimation framework is based on the minimization of the quadratic risk, which is approximated in two steps, and adapts to photon and electronic noises. Relying on unbiased risk estimation (URE) for the first step and on ``internal adaptation'', a concept borrowed from deep learning theory, for the second, we show that our approach enables to reinterpret and reconcile previous state-of-the-art non-local methods. Within this framework, we propose a novel denoiser called NL-Ridge that exploits linear combinations of patches. While conceptually simpler, we show that NL-Ridge can outperform well-established state-of-the-art single-image denoisers.
Simplicity in Complexity
Mar 05, 2024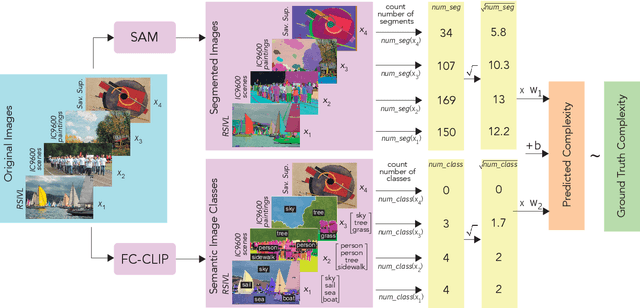
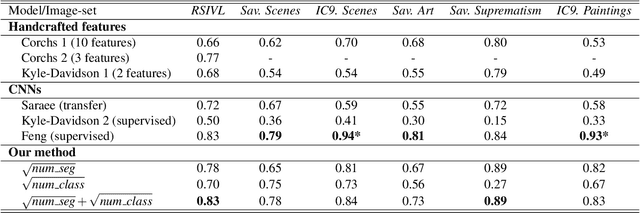
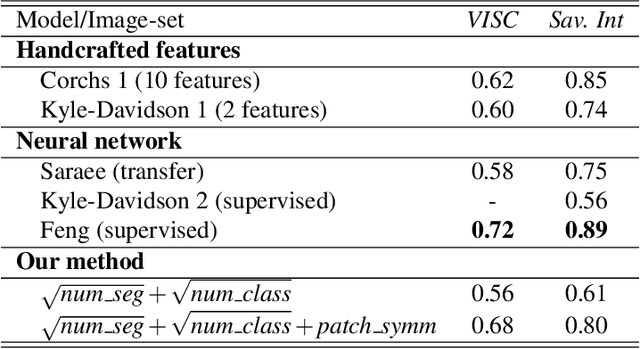

The complexity of visual stimuli plays an important role in many cognitive phenomena, including attention, engagement, memorability, time perception and aesthetic evaluation. Despite its importance, complexity is poorly understood and ironically, previous models of image complexity have been quite \textit{complex}. There have been many attempts to find handcrafted features that explain complexity, but these features are usually dataset specific, and hence fail to generalise. On the other hand, more recent work has employed deep neural networks to predict complexity, but these models remain difficult to interpret, and do not guide a theoretical understanding of the problem. Here we propose to model complexity using segment-based representations of images. We use state-of-the-art segmentation models, SAM and FC-CLIP, to quantify the number of segments at multiple granularities, and the number of classes in an image respectively. We find that complexity is well-explained by a simple linear model with these two features across six diverse image-sets of naturalistic scene and art images. This suggests that the complexity of images can be surprisingly simple.
Learning with Noisy Foundation Models
Mar 11, 2024Foundation models are usually pre-trained on large-scale datasets and then adapted to downstream tasks through tuning. However, the large-scale pre-training datasets, often inaccessible or too expensive to handle, can contain label noise that may adversely affect the generalization of the model and pose unexpected risks. This paper stands out as the first work to comprehensively understand and analyze the nature of noise in pre-training datasets and then effectively mitigate its impacts on downstream tasks. Specifically, through extensive experiments of fully-supervised and image-text contrastive pre-training on synthetic noisy ImageNet-1K, YFCC15M, and CC12M datasets, we demonstrate that, while slight noise in pre-training can benefit in-domain (ID) performance, where the training and testing data share a similar distribution, it always deteriorates out-of-domain (OOD) performance, where training and testing distributions are significantly different. These observations are agnostic to scales of pre-training datasets, pre-training noise types, model architectures, pre-training objectives, downstream tuning methods, and downstream applications. We empirically ascertain that the reason behind this is that the pre-training noise shapes the feature space differently. We then propose a tuning method (NMTune) to affine the feature space to mitigate the malignant effect of noise and improve generalization, which is applicable in both parameter-efficient and black-box tuning manners. We additionally conduct extensive experiments on popular vision and language models, including APIs, which are supervised and self-supervised pre-trained on realistic noisy data for evaluation. Our analysis and results demonstrate the importance of this novel and fundamental research direction, which we term as Noisy Model Learning.
Are Classification Robustness and Explanation Robustness Really Strongly Correlated? An Analysis Through Input Loss Landscape
Mar 09, 2024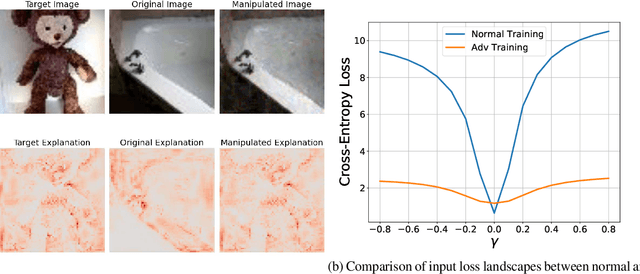
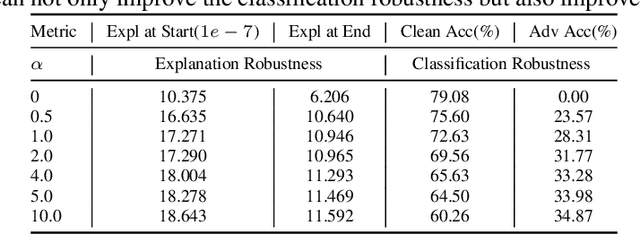
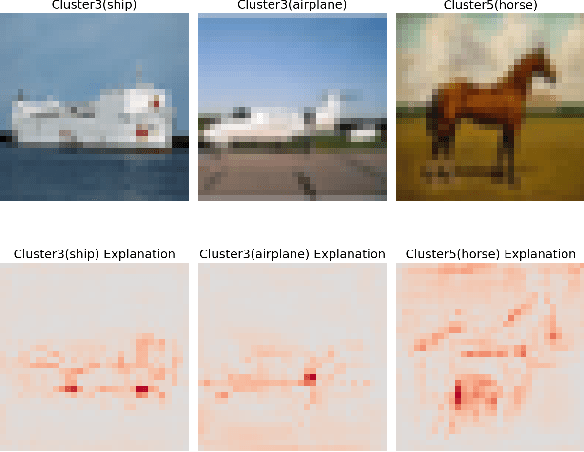
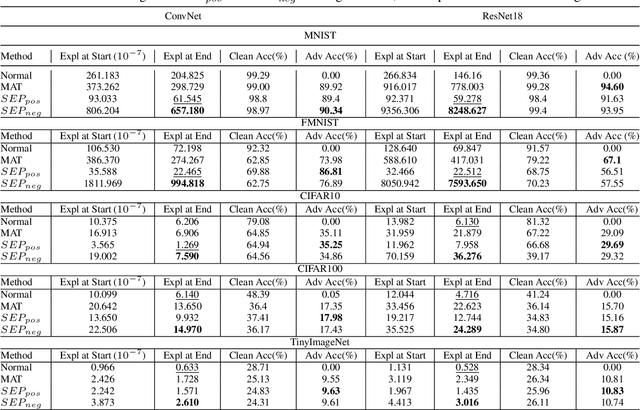
This paper delves into the critical area of deep learning robustness, challenging the conventional belief that classification robustness and explanation robustness in image classification systems are inherently correlated. Through a novel evaluation approach leveraging clustering for efficient assessment of explanation robustness, we demonstrate that enhancing explanation robustness does not necessarily flatten the input loss landscape with respect to explanation loss - contrary to flattened loss landscapes indicating better classification robustness. To deeply investigate this contradiction, a groundbreaking training method designed to adjust the loss landscape with respect to explanation loss is proposed. Through the new training method, we uncover that although such adjustments can impact the robustness of explanations, they do not have an influence on the robustness of classification. These findings not only challenge the prevailing assumption of a strong correlation between the two forms of robustness but also pave new pathways for understanding relationship between loss landscape and explanation loss.
VoCo: A Simple-yet-Effective Volume Contrastive Learning Framework for 3D Medical Image Analysis
Feb 27, 2024Self-Supervised Learning (SSL) has demonstrated promising results in 3D medical image analysis. However, the lack of high-level semantics in pre-training still heavily hinders the performance of downstream tasks. We observe that 3D medical images contain relatively consistent contextual position information, i.e., consistent geometric relations between different organs, which leads to a potential way for us to learn consistent semantic representations in pre-training. In this paper, we propose a simple-yet-effective Volume Contrast (VoCo) framework to leverage the contextual position priors for pre-training. Specifically, we first generate a group of base crops from different regions while enforcing feature discrepancy among them, where we employ them as class assignments of different regions. Then, we randomly crop sub-volumes and predict them belonging to which class (located at which region) by contrasting their similarity to different base crops, which can be seen as predicting contextual positions of different sub-volumes. Through this pretext task, VoCo implicitly encodes the contextual position priors into model representations without the guidance of annotations, enabling us to effectively improve the performance of downstream tasks that require high-level semantics. Extensive experimental results on six downstream tasks demonstrate the superior effectiveness of VoCo. Code will be available at https://github.com/Luffy03/VoCo.
BAGS: Blur Agnostic Gaussian Splatting through Multi-Scale Kernel Modeling
Mar 07, 2024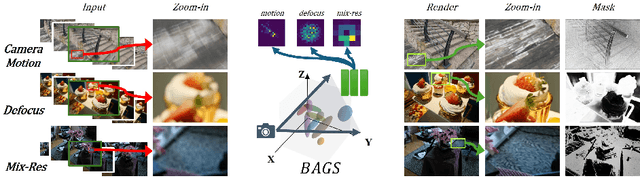
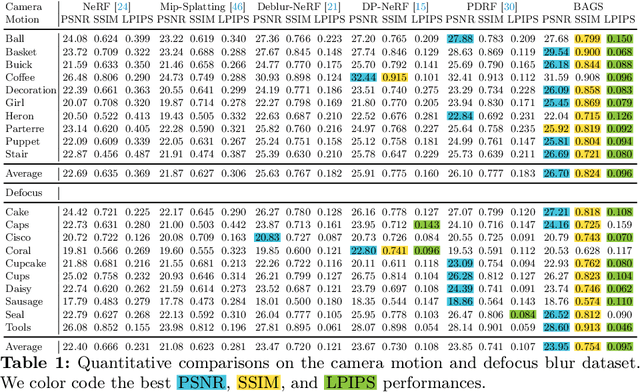
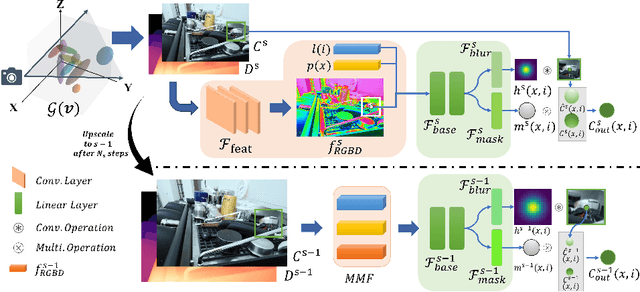

Recent efforts in using 3D Gaussians for scene reconstruction and novel view synthesis can achieve impressive results on curated benchmarks; however, images captured in real life are often blurry. In this work, we analyze the robustness of Gaussian-Splatting-based methods against various image blur, such as motion blur, defocus blur, downscaling blur, \etc. Under these degradations, Gaussian-Splatting-based methods tend to overfit and produce worse results than Neural-Radiance-Field-based methods. To address this issue, we propose Blur Agnostic Gaussian Splatting (BAGS). BAGS introduces additional 2D modeling capacities such that a 3D-consistent and high quality scene can be reconstructed despite image-wise blur. Specifically, we model blur by estimating per-pixel convolution kernels from a Blur Proposal Network (BPN). BPN is designed to consider spatial, color, and depth variations of the scene to maximize modeling capacity. Additionally, BPN also proposes a quality-assessing mask, which indicates regions where blur occur. Finally, we introduce a coarse-to-fine kernel optimization scheme; this optimization scheme is fast and avoids sub-optimal solutions due to a sparse point cloud initialization, which often occurs when we apply Structure-from-Motion on blurry images. We demonstrate that BAGS achieves photorealistic renderings under various challenging blur conditions and imaging geometry, while significantly improving upon existing approaches.
CLIP the Bias: How Useful is Balancing Data in Multimodal Learning?
Mar 07, 2024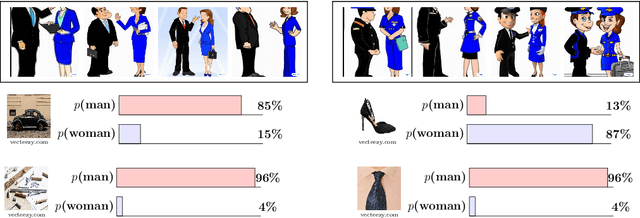
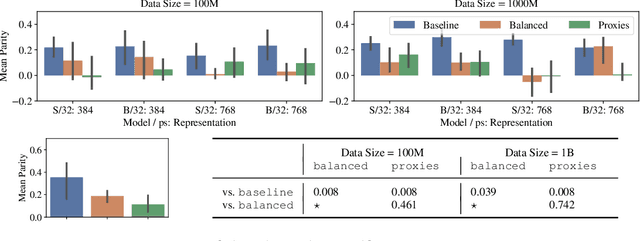

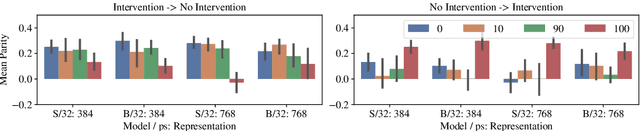
We study the effectiveness of data-balancing for mitigating biases in contrastive language-image pretraining (CLIP), identifying areas of strength and limitation. First, we reaffirm prior conclusions that CLIP models can inadvertently absorb societal stereotypes. To counter this, we present a novel algorithm, called Multi-Modal Moment Matching (M4), designed to reduce both representation and association biases (i.e. in first- and second-order statistics) in multimodal data. We use M4 to conduct an in-depth analysis taking into account various factors, such as the model, representation, and data size. Our study also explores the dynamic nature of how CLIP learns and unlearns biases. In particular, we find that fine-tuning is effective in countering representation biases, though its impact diminishes for association biases. Also, data balancing has a mixed impact on quality: it tends to improve classification but can hurt retrieval. Interestingly, data and architectural improvements seem to mitigate the negative impact of data balancing on performance; e.g. applying M4 to SigLIP-B/16 with data quality filters improves COCO image-to-text retrieval @5 from 86% (without data balancing) to 87% and ImageNet 0-shot classification from 77% to 77.5%! Finally, we conclude with recommendations for improving the efficacy of data balancing in multimodal systems.
* 32 pages, 20 figures, 7 tables
T-TAME: Trainable Attention Mechanism for Explaining Convolutional Networks and Vision Transformers
Mar 07, 2024The development and adoption of Vision Transformers and other deep-learning architectures for image classification tasks has been rapid. However, the "black box" nature of neural networks is a barrier to adoption in applications where explainability is essential. While some techniques for generating explanations have been proposed, primarily for Convolutional Neural Networks, adapting such techniques to the new paradigm of Vision Transformers is non-trivial. This paper presents T-TAME, Transformer-compatible Trainable Attention Mechanism for Explanations, a general methodology for explaining deep neural networks used in image classification tasks. The proposed architecture and training technique can be easily applied to any convolutional or Vision Transformer-like neural network, using a streamlined training approach. After training, explanation maps can be computed in a single forward pass; these explanation maps are comparable to or outperform the outputs of computationally expensive perturbation-based explainability techniques, achieving SOTA performance. We apply T-TAME to three popular deep learning classifier architectures, VGG-16, ResNet-50, and ViT-B-16, trained on the ImageNet dataset, and we demonstrate improvements over existing state-of-the-art explainability methods. A detailed analysis of the results and an ablation study provide insights into how the T-TAME design choices affect the quality of the generated explanation maps.